Phase transitions and AGI
post by Ege Erdil (ege-erdil), Metaculus · 2022-03-17T17:22:06.518Z · LW · GW · 19 commentsThis is a link post for https://www.metaculus.com/notebooks/10286/phase-transitions-and-agi/
Contents
Outside view Inside view Forecasts Discussion None 19 comments
Take a look at the following graph, from Robin Hanson's Long-Term Growth As a Sequence of Exponential Modes:
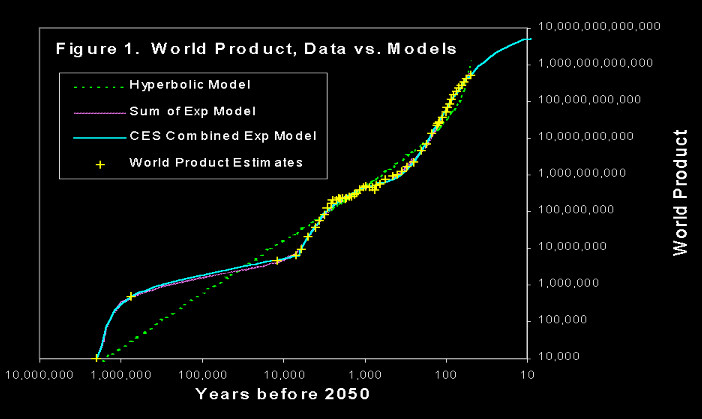
Here, "world product" is roughly the gross world product divided by the level of income necessary for one person to live at a subsistence level. It measures the total production of the human species in units of "how many people could live at a subsistence level on that much production?"
The yellow marks are historical estimates of world product that Hanson gathered from a variety of sources, and he's fit three different models to this data. What's notable is the good fit that the "sum of exponentials" type models have with this data. It looks like the world economy goes through different phases which are characterized by different rates of growth: in the first phase world product doubled every years, in the second phase it doubled every years, and in the third phase it doubled every years, where we can give or take a factor of from these estimates - they are meant only to convey the order of magnitude differences.
We also see that transitions to subsequent phases are relatively fast. The transition from the first phase to the second phase took years, much less than the doubling time of years characterizing this phase, and the transition from the second phase to the third took on the order of years, still smaller than the years of doubling time typical of the second phase. We can also observe that the timing of these events roughly matches the First Agricultural Revolution and the Industrial Revolution, so we might tentatively label the phases as corresponding to "foraging", "farming" and "industry" respectively.
The study of these past transitions is important because they are the only reference class we have for dramatic changes in the nature of the world economy and in how the human species is organized and how we coordinate our activities. Since we have two transitions to examine, we might also get a rudimentary sense of the variance of outcomes: two is the minimal value we need in order to do that.
Unfortunately, many details about the foraging phase are shrouded in mystery. There's still no consensus on the world product estimates for this phase even today: it could be that this phase was actually ten times shorter than we think it is, and it might only date back to around 200,000 BCE rather than 2,000,000 BCE. In this case, the doubling time in this phase would be higher, about years. This is still much slower than what came after, and still large compared to how long it took for the transition to take place.
Regardless, the first conclusion we should draw from this reference class is that such phase transitions are possible and they can happen surprisingly quickly compared to the pace of the changes that people who lived in a particular phase would be used to. We can draw a second conclusion by noting that while the durations of the phases vary quite a lot, the number of doublings of world product in each phase seems to be similar: , give or take a factor of . Given the small sample size and the difficulties of generalization, it's hard to extrapolate the duration of the industrial phase based on this information, but it does suggest that the phase coming to an end soon wouldn't be surprising from an outside point of view.
The question this essay is meant to answer is broadly this: how likely is a phase transition in the near future, and given that one occurs, how likely is it to be brought about by AGI? (By definition, I take transformative AI to be precisely a development in AI which triggers such a phase transition.)
Outside view
One important question we should ask is how far in advance it's possible to see phase transitions coming. The answer to this seems to be "less than half of a doubling time" given the past examples. In other words, since the world economy is currently doubling every 20 years or so, we probably shouldn't expect to see any sign of an impending phase transition until we're less than a decade away from it. Therefore, the fact that nothing special seems to be happening now shouldn't affect our assessment of the odds of a phase transition in the next century.
On the other hand, the outside view also should lead us to be cautious about what mode of organization will become dominant after the phase transition. It would have been quite difficult to anticipate in the year 1400 that the next phase would be associated with industry, since industry wasn't growing particularly fast relative to anything else in 1400.
Can we get a more precise idea about how long we can expect the industrial phase to last from an outside point of view? Here is one way to go about doing this: assume that where is the number of doublings in a phase is drawn from a Pareto distribution with an unknown tail exponent . Pareto distributions have heavy right tails and allow for a lot of uncertainty. This means the forecasts it implies will be quite conservative on transformative AI timelines, which might be a disadvantage for reasons I'll come back to shortly.
A Pareto distribution has one parameter: the exponent . If we had a lot of data then we could estimate using frequentist methods (such as maximum likelihood estimation) but since we don't, we have to use Bayesian methods to get anything useful out of this analysis.
The conjugate prior of the Pareto distribution is the same as the one of the exponential distribution, since the logarithm of a Pareto distributed random variable is exponentially distributed. This conjugate prior is given by the gamma distribution.
We start with the Jeffreys prior for the Pareto distribution, which is simply an improper prior proportional to . This formally corresponds to a gamma distribution where the distribution is characterized in terms of its shape and rate respectively. Now, we do a Bayesian update: we have two observations of past phases and they took approximately 8.9 and 7.5 doublings - these values are taken from Hanson's paper - for the foraging and farming phases respectively. Using the conjugate prior updating rule for the exponential distribution after adding 1 and taking logarithms, we update to the posterior distribution
Now we can do a Monte Carlo simulation by first sampling values of from the posterior and conditioning on there having been at least 10 doublings so far in the current phase, and then sampling some value of the number of doublings until the end of the current phase. This give us a sample from which we can infer what the percentiles of various outcomes must be.
The cumulative distribution function looks like this:
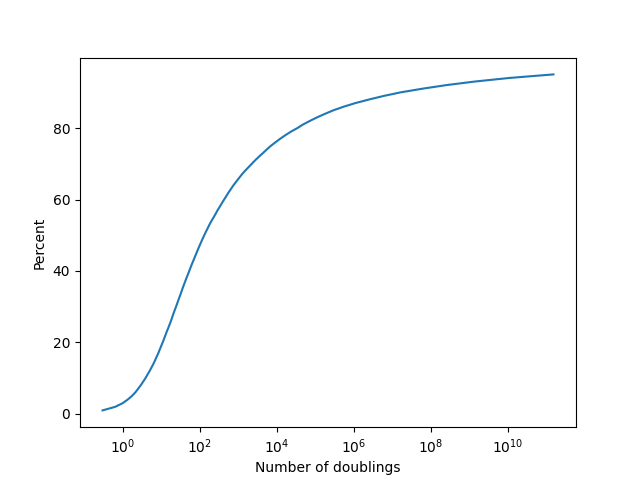
The reason the percentiles after the median get so large is because of the aforementioned property that the Pareto distribution has heavy tails. Since sustaining doublings indefinitely has a substantial chance of being outside the realm of physical possibilities, we might want to also try using a distribution which has thinner tails. A natural choice for this is the exponential distribution.
This calculation is remarkably similar since the exponential and Pareto distributions are closely related. Now we assume the number of doublings is drawn directly from an exponential distribution with an unknown rate parameter . Once again the Jeffreys prior for is , and a similar Bayesian update gets us the posterior
Repeating the Monte Carlo simulation from before in this new context gives the following cumulative distribution function:
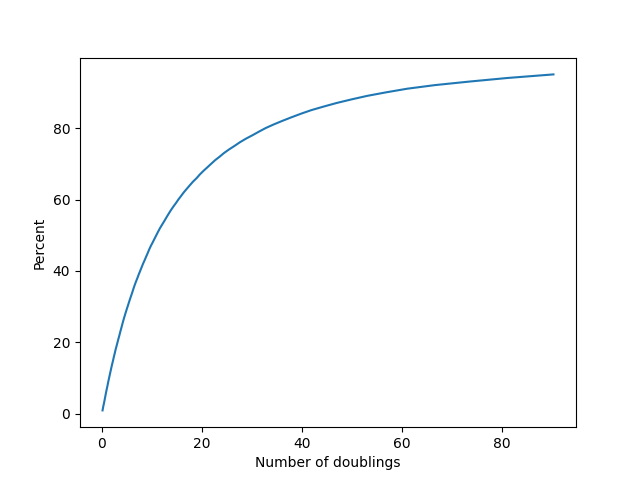
Which of these is a better choice? In my judgment the exponential distribution in this case is giving much more realistic timelines, and it's what I will be primarily relying on in order to make my forecasts. I include both models, however, as a way to show that our choice of model really affects our view of what the timeline should be like.
The main argument against using heavy tailed priors is that the number of doublings is already the base two logarithm of the factor by which world product increases by in a phase, so if we assume a heavy tailed distribution for it then we have to exponentiate that in order to get the actual growth in world product. This becomes similar to a double exponential which has a high probability of exceeding physical limits - how confident are we that, say, 9000 doublings of world product is even physically possible at all, let alone it all occurring in a single phase?
I also experimented with using a model in which is sampled from a gamma distribution, but because its Jeffreys prior doesn't belong to its family of conjugate priors Bayesian inference on it gets quite hairy. In the end the results I get are somewhat more pessimistic than using an exponential, but the difference isn't pronounced.
Inside view
I think conditional on there being a phase transition in the next hundred years or so, it's likely (around 65%) that the cause of the transition will be the development of transformative AI. However, even if this is not true, reverse causality will then become operative: it's very hard to imagine that AGI is not achieved a short time after a phase transition. Even a factor 10 increase in the growth rate of the economy would be enough for AGI timelines to become quite compressed, for instance.
The reason I would give 65% odds to AGI being the driver of such a phase transition is that it's hard for me to tell a plausible story about any other technology that's currently on the horizon doing so. Moreover, one of the signs of a part of the economy that will be responsible for a phase transition is that it should have a fast growth rate and a plausible mechanism by which that fast growth rate can be sustained and take over the whole economy, and I think the only serious contender for this position right now is AI research. I wouldn't go higher than 65% because a technology that we can't yet see could end up being responsible for the phase transition: this is the same as the point I raised earlier about how industry wasn't growing fast relative to the rest of the economy in 1400.
My opinion is that the inside view right now favors a phase transition sometime between 2 and 5 doublings. It's difficult to imagine transformative AI coming along without at least one further doubling. Some relevant milestones here come from Holden Karnofsky's post on transformative AI forecasting using biological anchors:
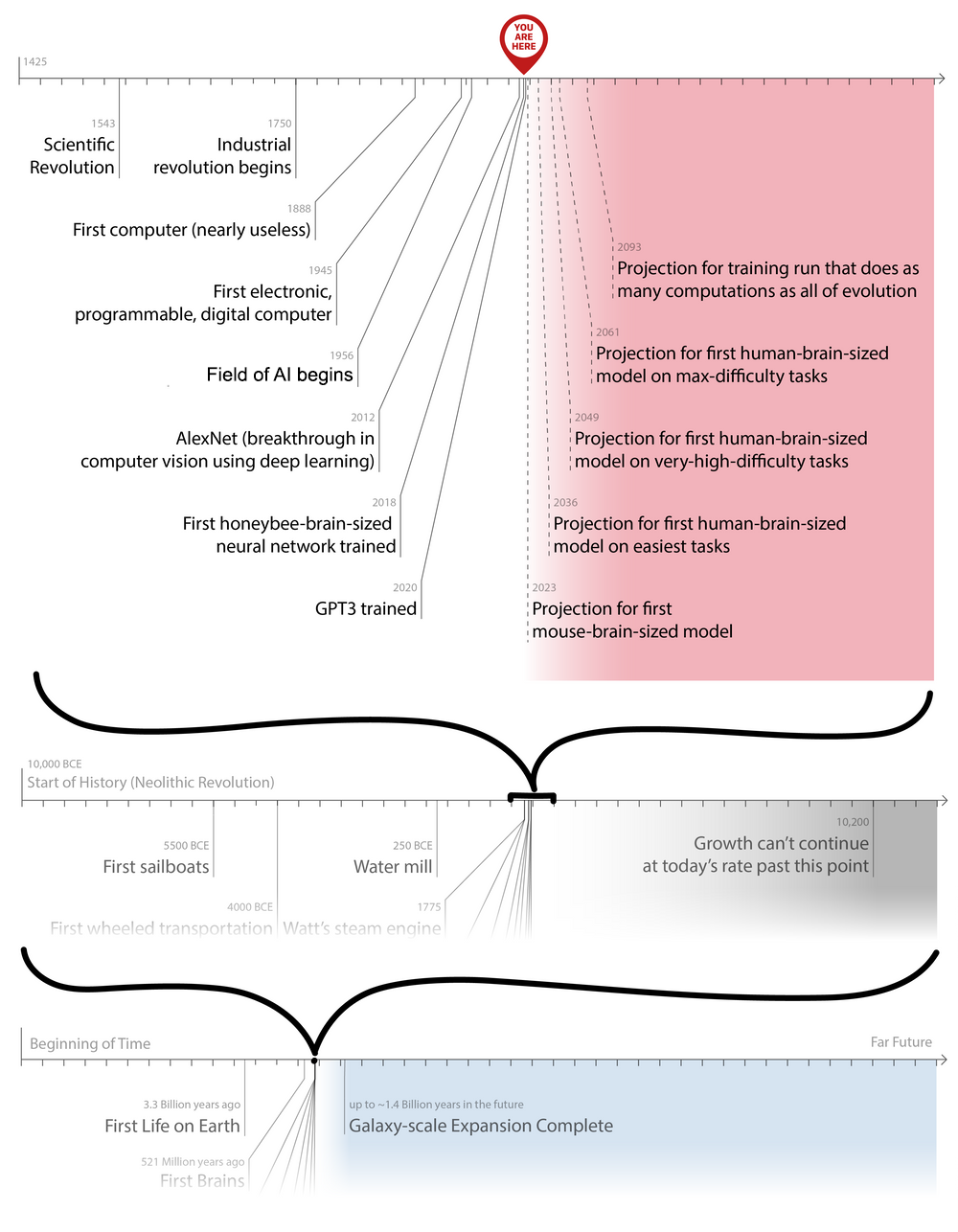
As Karnofsky says in his post:
Bio Anchors estimates a >10% chance of transformative AI by 2036, a 50% chance by 2055, and an 80% chance by 2100.
I think this is extremely optimistic. I agree with the timeline in likelihood terms: the maximum likelihood estimate on when we get transformative AI is probably "two to five doublings", which is roughly the same timeline here - again, their timeline seems a bit more optimistic, but broadly consistent. This roughly means that I think we would be most likely to be seeing the kind of world we are seeing now if we were around two to five doublings away from a phase transition.
However, a good Bayesian has to combine likelihoods with priors in order to get a posterior distribution, and this is my primary point of disagreement with the Bio Anchors timeline: the outside view, in other words the prior distribution, suggests a phase transition occuring soon is unlikely. The industrial phase is roughly 200 years old, and it has lasted for around 10 doublings already. Conditional on that, even if we just assume a constant rate of arrival for the end of the current phase (which will be rather optimistic), we should get a maximum likelihood estimate of around 10% every doubling for it to happen. The median forecast would then be around 7 doublings until the end of the current phase. If we want to go down from 7 to below 2, we need to have very strong evidence that a phase transition is going to happen, and I don't think AI developments so far provide any such evidence.
More explicitly, consider the second cumulative distribution funciton plot above. Two doublings is roughly the 14th percentile of outcomes, so . The corresponding odds ratio is or so. To update from this odds ratio to even odds requires a Bayes factor of roughly . In other words, to justify a median forecast of two more doublings, the world would have to be 6 times more likely to look as it does under the hypothesis than under the alternative . In my judgment the available evidence comes nowhere close to meeting this stringent standard, and I'm curious to hear from people who think otherwise.
Most of the expectation of imminent transformative AI rests on extrapolations such as the one in the graph: if we train a big enough model (human brain-sized, or more accurately, of a similar inferential complexity to the human brain) for a long enough time (compute used by all of evolution), we'll not only get human or superhuman performance on difficult tasks, but this performance will directly translate into a transformation of the global economy. I think the model uncertainty here is so large that updating too strongly away from the prior on this kind of argument is a bad idea.
Forecasts
There are three related questions that I'll forecast on: GWP growth to exceed 6%, GWP growth to exceed 10% and When will economic growth accelerate? You can find the cumulative distribution function of my forecasts over at the linked post on Metaculus.
I think all three of these questions are unlikely to resolve if there is no phase transition: I think the first one has around 15% chance of not resolving > in the absence of one, while the second and third are 1% or less. Therefore, my forecasts on all three questions are based on taking my outside view estimates, adjusting them slightly upwards due to the arguments given in the inside view section, and then making further adjustments based on the specific question.
I think mean GWP growth exceeding 10% per year for a sufficiently long time is approximately equivalent to there being a phase transition - it's highly unlikely that any phase transition would have a doubling time factor over the current phase that's less than 3. However, 30% growth in a single year is a stronger demand, so I've adjusted the distribution downwards to account for that. You shouldn't take the exact distribution too seriously, since it's difficult to input exact distributions and I haven't taken the effort to do so, but I've made sure that everything is consistent.
Mean GWP growth exceeding 6% could happen without a phase transition, but it's rather unlikely. It would require major governments around the world enacting wide-reaching economic reforms, or an unprecedented economic boom across most of the underdeveloped world. I put the odds of this at around 15%, and my forecast is more or less a combination of this with my estimate of the arrival time of a phase transition.
Discussion
Most transformative AI timelines focus strongly on the inside view: how long until neural networks become as big as the human brain, how long until we reach certain compute thresholds, how long do researchers in the field think we have until transformative AI, et cetera. I think the inside view is useful, but in the process the outside view is either ignored or not weighted strongly enough to balance out inside considerations.
This essay is meant to be a corrective for that: using Bayesian methods it's actually possible to get information about the timeline of when we can expect another phase transition purely based on the past two examples of such transitions. The distributions we get this way do end up being somewhat sensitive to assumptions about priors, especially at the tails, but overall I think using any standard "uninformative" prior is superior to just saying there's no outside view on the problem and focusing only on the inside view.
Addendum: Someone over at Metaculus linked Semi-informative priors over AI timelines by Tom Davidson in the comments, which has a similar flavor to what I do here and ends up with similar timelines for a phase transition & transformative AI as I do. If you're interested in this outside view perspective, his article is also worth reading.
19 comments
Comments sorted by top scores.
comment by Matthew Barnett (matthew-barnett) · 2022-03-18T02:55:21.789Z · LW(p) · GW(p)
I agree that the transition from foraging to farming probably was a relatively clear phase shift in human civilization. But the transition from farming to industry seems more murky to me, with the data being compatible with continuous acceleration (ie. hyperbolic growth). (See also this thread on the EA forum [EA · GW]).
For instance, my understanding is that European nations experienced substantial per-capita growth in the centuries leading up to the industrial revolution. And unlike farming, the industrial revolution had no single cause that we can point to that makes it a distinct technological "revolution", or phase shift. An alternative explanation is that what we call the industrial revolution is simply the latest part of the hyperbolic growth trend that humanity has experienced since roughly 10,000 BC.
Edit: Scott Alexander has a much longer discussion about this here.
One interesting fact about our era is that growth has recently slowed since 1960. But I think there's a relatively simple explanation of that fact, that sheds light on the long-run data. In particular, I am inclined towards Michael Kremer's explanation that the rate of technological progress is proportional to the total population, since a larger population supports more idea generation. Combined with the Malthusian assumption that the growth rate in the population is proportional to the rate of growth in technology, this model implies that economic growth will be hyperbolic, which is indeed what we saw until the demographic transition during the mid-20th century.
The significance of Michael Kremer's model is its parsimony: it requires fitting only a single curve to the long-run data, as opposed to multiple exponential modes. But it can also be empirically tested, as Kremer does, by comparing the rate of economic growth in geographically isolated societies, and checking whether societies with higher initial populations had higher rates of technological growth.
Compared to the exponential growth sequence model, Kremer's model provides a much stronger theoretical foundation for AI-accelerated growth. This is because if we assume that AI can substitute for labor, then the effect of declining population growth from the demographic transition can be negated by growth in AI, allowing us to proceed on our previous hyperbolic trajectory.
Relatedly, I agree that the outside view of historical economic growth provides a relatively weak reason to expect transformative growth in the relative near-term (say, the next 100 years), but I think we shouldn't rely too much on simple extrapolation in this case. The main reason why the long-run historical growth data is important is because it validates the model that population growth and technological progress work together, in a way that predicts a singularity. Since this model is the primary justification given for transformative growth under AI in economic models, the long-run data provides a relatively strong update towards the plausibility of transformative growth this century.
As you noted yourself, even if the exponential growth sequence model is correct, we have extremely sparse information about the time between each transition. Given such a weak prior, it would be no surprise that vast amounts of real world observations might be enough to overwhelm it, and cause us to be much more confident in nearer term AI. I think we have such information, and it should play a prominent role in our timelines.
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-03-18T09:18:56.137Z · LW(p) · GW(p)
For instance, my understanding is that European nations experienced substantial per-capita growth in the centuries leading up to the industrial revolution. And unlike farming, the industrial revolution had no single cause that we can point to that makes it a distinct technological "revolution", or phase shift. An alternative explanation is that what we call the industrial revolution is simply the latest part of the hyperbolic growth trend that humanity has experienced since roughly 10,000 BC.
Your first point is not correct according to the data I have. It's only the UK and the Netherlands that experienced substantial per capita growth before the end of the Napoleonic Wars, and their growth pattern is consistent with a smoother phase transition.
I don't think it's necessary for a new phase to be associated clearly with a new technology. I agree that such an association makes the break from the previous phase much clearer, but I already think the break between the last phase and the current phase is clear, so...
I really don't think hyperbolic growth fits the data well at all. I'm honestly mystified by how so many people seem to take it so seriously - how does hyperbolic growth explain two centuries of approximately constant GDP per capita growth trend in the US or in the UK? A stochastic model can just explain it as a coincidence, but then the likelihood ratio should lead you to update away from a hyperbolic model.
One interesting fact about our era is that growth has recently slowed since 1960.
I think this is very unclear because of difficulties in measuring inflation accurately due to changes in the nature of goods produced that have taken place since 1960. I think it's possible (20%) that in fact growth didn't slow down at all.
In particular, I am inclined towards Michael Kremer's explanation that the rate of technological progress is proportional to the total population.
The fact that the Industrial Revolution began in Europe and not China or India, and the fact that it was so difficult of a process for it to spread to those places once it was already here, is evidence against this view. I agree more people is good for growth for this reason and others (specialization & division of labor, for example) but it only explains a small fraction of the variance in outcomes here. Even in Europe the Industrial Revolution began in Britain and the Netherlands, not France or Spain as this population model would have led us to expect.
Compared to the exponential growth sequence model, Kremer's model provides a much stronger theoretical foundation for AI-accelerated growth. This is because if we assume that AI can substitute for labor, then the effect of declining population growth from the demographic transition can be negated by growth in AI, allowing us to proceed on our previous hyperbolic trajectory.
Even if this happened, my model of what would happen is not hyperbolic. I think it would more or less be another phase shift which would last for some number of doublings before we hit diminishing returns or something else happened. A hyperbolic trajectory just seems like wishful thinking to me.
Relatedly, I agree that the outside view of historical economic growth provides a relatively weak reason to expect transformative growth in the relative near-term (say, the next 100 years), but I think we shouldn't rely too much on simple extrapolation in this case. The main reason why the long-run historical growth data is important is because it validates the model that population growth and technological progress work together, in a way that predicts a singularity. Since this model is the primary justification given for transformative growth under AI in economic models, the long-run data provides a relatively strong update towards the plausibility of transformative growth this century.
I don't agree that long-run historical growth data actually validates this. My belief that population size matters for technological growth comes mostly from my own priors rather than any updates I've made on the basis of looking at what happened in the past.
Overall, I really want someone who is a proponent of the hyperbolic model to explain to me why this model is so popular, because to me it seems obviously wrong. I'd be happy to schedule a call with someone just for this purpose.
Replies from: paulfchristiano, paulfchristiano, matthew-barnett↑ comment by paulfchristiano · 2022-03-18T16:55:25.586Z · LW(p) · GW(p)
Overall, I really want someone who is a proponent of the hyperbolic model to explain to me why this model is so popular, because to me it seems obviously wrong. I'd be happy to schedule a call with someone just for this purpose.
Could you describe an alternative model that you think has a less bad fit to the historical data?
(If you are just saying this on the basis of qualitative data, I disagree but don't think it's going to be helpful to try to resolve here.)
I think mixture of exponentials is a significantly worse fit and have tried to do this exercise myself. If you disagree then I'd be quite happy for you to describe a probability distribution over time series which you think is better than the natural stochastic hyperbolic model (and I will bring the stochastic hyperbolic model). By default I won't include an explicit model of autocorrelations unless you do, and if I did it would be a very simple representation with a reasonable prior over any hyperparameters involved rather than hard-coding them.
You can pick the times and places where you think the data is good enough that it's worth modeling, and even provide your own time series if you think the hyperbolic growth proponents are making a mistake about which data to trust. E.g. I'd be fine if you want to do it in just the UK or europe, or using best guess global time series, or using best guess global time series since 1000 AD if you don't trust them before that (since they are quite wild guesses). Or if you want to fit to a variety of different local time series. Whichever.
I think if this exercise favored a mixture of exponentials that would be a significant update for me. So far every time I've looked into it a mixture of exponentials has seemed significantly worse, which is a large part of how I ended up with this view (e.g. it basically ends up with totally different hyperparameters for each population studied, fitting it up through year X gives you bad predictions about year X+100, when I do the calculation formally it looks bad...). But I think those exercises have been hamstrung by not having any proponent of the mixtures of exponential view write down a formal model that could be evaluated without hindsight bias.
↑ comment by paulfchristiano · 2022-03-18T17:10:11.384Z · LW(p) · GW(p)
how does hyperbolic growth explain two centuries of approximately constant GDP per capita growth trend in the US or in the UK?
It seems to me like this fact is often overstated or cherry-picked. E.g. Our world in data has UK GDP per capita at 2.3k pounds in 1800, 4.9k in 1900, and 24.4k in 2000. That's more than twice as fast in the second century as the first. Moreover, from 1800-1900 the UK seems much more plausible to me than the US as a proposal for a frontier economy (rather than one benefiting from catchup growth and expansion into new territory).
Hyperbolic models are definitely surprised that acceleration here was more like 2x instead of 4x. There are obvious factors they ignore like low fertility that seem crucial to explaining that gap. But most of all they are surprised by the apparent slowdown in growth since 1960 instead of continued acceleration.
I don't find the accusation particularly compelling unless you want to suggest an alternative model.
Broadly speaking I think that on hyperbolic models the "great stagnation" is definitely a real thing and it's a lot of noise, and it generates a lot of ongoing surprise if you don't include autocorrelations.
(Whereas on growth mode models this is the typical state of affairs punctuated by periodic transitions---unless you want to use something like Robin's model, which is also surprised by the great stagnation rather than ongoing acceleration to 12%/year growth.)
↑ comment by Matthew Barnett (matthew-barnett) · 2022-03-18T19:57:05.896Z · LW(p) · GW(p)
Even if this happened, my model of what would happen is not hyperbolic. I think it would more or less be another phase shift which would last for some number of doublings before we hit diminishing returns or something else happened. A hyperbolic trajectory just seems like wishful thinking to me.
To be clear, I don't think anyone relevant in this debate has suggested that growth will literally go to infinity. The claim is typically that we will proceed on a hyperbolic trajectory until we run into physical constraints, coupled with the claim that physical constraints aren't very limiting. For example, many people think it's plausible that with AI, we could get to >1000% world GDP growth before running out of steam.
comment by interstice · 2022-03-17T21:08:33.320Z · LW(p) · GW(p)
The choice of "discrete phase transitions with exponentially distributed waiting times" as model of the growth trajectory feels somewhat arbitrary -- why not instead, for instance, fit a power-law, which predicts a transition around mid-century? As Hanson's paper notes, the prediction for when the next stage arrives seems to depend a lot on modeling details, so I don't think "taking the outside view" should update us very strongly here.
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-03-17T21:39:06.613Z · LW(p) · GW(p)
I think the evidence for discrete phase transitions is very strong - the choice of using a model with such transitions is not arbitrary at all. My conviction here comes more from my general knowledge of history and less from this one data series, however. Since this post was length constrained I couldn't go into too much detail about why I think this particular model is good.
The reason the simple fits in Hanson's model are not great about the timing is that the industrial phase transition occured at different times in different places, and that heterogeneity causes the simple sum of exponential model to not be a great fit right around the time of transition. It's why Hanson's CES fit puts the start of the industrial phase at ~ 2020: that's because the model is doing its best to explain the spread of the Industrial Revolution throughout the world, starting from the UK and the Netherlands, then spreading to the rest of Europe and European offshoots, then to Japan, etc.
In contrast I think the power law doesn't at all fit what we know about the past. There are many stylized facts about the industrial phase that come in bulk: demographic transition, urbanization, movement away from authoritarian forms of social organization, more acceptance of sexual promiscuity, et cetera. Ditto for the foraging to farming phase transition. To me it's clear that something discontinuous is happening at these junctures.
One last thing to mention is that you can actually push the idea of phase transitions further: for example, abiogenesis (~4Gy ago?), the Cambrian explosion (~500My ago), emergence of general intelligence (~1My ago?) all seem to have a discontinuous character. However our knowledge of these episodes is very thin and so I didn't include them in the post - there really isn't much to say about them when we're so uncertain about what happened, when and how.
We also have to be cautious because the order parameter of these phase transitions can change. For instance, if you cool aluminum gas from 3000 K to 0.1 K, you'll see three phase transitions: condensation, freezing and the superconducting phase transition. The first two both have some similar order parameters but the superconducting phase transition is qualitatively very different (it's even a second order phase transition, vs. condensation and freezing being first order) and it affects a completely different order parameter of the material (conductivity vs density).
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-03-18T06:22:35.143Z · LW(p) · GW(p)
I think it's worth fitting sum of exponentials (with arbitrarily tuned CES parameters) to continuous random processes to get intuition for what the result looks like. If you draw 10 samples (e.g. from the model used by David Roodman here) I think they will look about as sum-of-exponentials-y as our actual history.
If that's right then it comes down to the qualitative data, where I disagree (I don't think it's at all clear that something discontinuous is happening) but it seems harder to settle.
(I don't think the "industrial revolution is a new exponential spreading" fits the data very well---the industrial revolution phase is much faster than growth in the places where you claim the IR started, it's like 12%/year vs <1% per year for Britain at the start of the IR!)
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-03-18T08:58:47.677Z · LW(p) · GW(p)
I think it's worth fitting sum of exponentials (with arbitrarily tuned CES parameters) to continuous random processes to get intuition for what the result looks like. If you draw 10 samples (e.g. from the model used by David Roodman here) I think they will look about as sum-of-exponentials-y as our actual history.
Roodman himself admits that his model is surprised by the data in the industrial phase. It first underestimates growth after ~ 1820 and then consistently overestimates it after ~ 1990 (most likely because it's expecting something resembling a singularity that doesn't come). That's exactly how I would expect such a model to fail if my model is correct.
That said, I think the experiment is worth doing and I'll try to run some Monte Carlo simulations to examine this more closely when I have the time.
If that's right then it comes down to the qualitative data, where I disagree (I don't think it's at all clear that something discontinuous is happening) but it seems harder to settle.
It's harder to settle in the comments for sure. All I can say is that I'm pretty convinced of it - I might write a complementary piece to this one later to try to explain why I think that way.
(I don't think the "industrial revolution is a new exponential spreading" fits the data very well---the industrial revolution phase is much faster than growth in the places where you claim the IR started, it's like 12%/year vs <1% per year for Britain at the start of the IR!)
Growth rates in the industrial phase are usually around 3%/year. The reason many countries had much faster growth than this is because they are catching up from behind: they were late to the transition, which makes explosive growth easier to achieve until you've caught up.
If you don't mean catch-up growth by countries like China and Japan, then I'm mystified by your 12%/year figure. Where does this estimate come from?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-03-18T16:09:32.394Z · LW(p) · GW(p)
12% is the estimate from Robin's model.
But even if you think the industrial mode is 3%, it seems like "started in Britain and spread out" doesn't explain the gradual nature of the transition. I don't have numbers right now but I think the UK itself didn't reach that growth rate until the 20th century. If there was a phase change it was presumably somewhere closer to 1700?
Roodman himself admits that his model is surprised by the data in the industrial phase.
I agree that the errors in this model are autocorrelated (though I think the mixture of exponentials model avoids this, to the extent it does, mostly because it has many more free parameters---8 is a huge number of parameters, so it's super unsurprising they can absorb most of the autocorrelation).
I think the "noise" reflects stuff like "how well are institutions doing?" and "does this part of the technology landscape happen to have somewhat faster or slower progress?" those factors aren't totally independent from one time to another. But I think the hypothesis "actually we're looking at a few phase transitions" is not really supported over "it's pretty noisy with mild autocorrelation."
(My further guess is that if you actually do a bayesian fit, the model class in David Roodman's data probably fits the data better despite completely giving up on the autocorrelations. E.g. if every 100 years you fit both models to history then use both of them to make a prediction about GDP growth over the next 100 years, you will get more total log loss by using the CES mixture of exponentials.)
Replies from: paulfchristiano, ege-erdil↑ comment by paulfchristiano · 2022-03-18T16:21:22.361Z · LW(p) · GW(p)
I don't have numbers right now but I think the UK itself didn't reach that growth rate until the 20th century. If there was a phase change it was presumably somewhere closer to 1700?
Here's a citation on britain GDP growth (but haven't checked them for reasonableness), see figures 2 and 7: https://academic.oup.com/ereh/article/21/2/141/3044162.
It gives 0.6% average growth from 1476 to 1781 and then 2% from 1781 to early 1900s. Though the rate isn't very constant within either period, closer to 1% at 1781 itself and then hitting 3%+ later in the 20th century.
I'm not sure what the phase transition view is saying about these cases---0.6%/year is incredibly fast growth (that's a ~100 year doubling time, contrasted with a >1000 year doubling time for other agricultural societies); has the phase transition happened or not by 1476? (You could attribute some to catch-up growth after the plague, but even peak to peak and completely ignoring the plague you have fast growth well before 1781.)
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-03-18T22:04:13.501Z · LW(p) · GW(p)
I'm not sure what the phase transition view is saying about these cases---0.6%/year is incredibly fast growth (that's a ~100 year doubling time, contrasted with a >1000 year doubling time for other agricultural societies); has the phase transition happened or not by 1476? (You could attribute some to catch-up growth after the plague, but even peak to peak and completely ignoring the plague you have fast growth well before 1781.)
My guess would be sometime around the English Civil War. The phase transition definitely hadn't happened by 1476 - I would put the date sometime in the first half of the 17th century for when it starts, and I think it ends roughly when the Napoleonic Wars are over.
That said, this data is less clear than I would have liked. The GDP per capita plot for the UK shows a very clear break with trend in the middle of the 17th century and this was one of the data points that had convinced me in the past that something discontinuous was going on, but actually this could be the Civil War messing up what otherwise would have been a smoother trend given that this uptick is not visible in the GDP plots.
Combined with the knowledge that the English Civil War happened around the time of the GDP per capita trend deviation, I agree that these plots are evidence against the phase transition model and in favor of a smoother (such as a hyperbolic) model.
Given all the evidence you've presented so far, I now think the picture is less clear than I'd previously thought it was.
↑ comment by Ege Erdil (ege-erdil) · 2022-03-18T19:27:02.701Z · LW(p) · GW(p)
But even if you think the industrial mode is 3%, it seems like "started in Britain and spread out" doesn't explain the gradual nature of the transition. I don't have numbers right now but I think the UK itself didn't reach that growth rate until the 20th century. If there was a phase change it was presumably somewhere closer to 1700?
Yes, this by itself doesn't explain it, though it plays a big role in the account for GWP. This is not inconsistent with a phase transition story, but it can be inconsistent with particular versions of it like a direct sum of exponentials model. I think the industrial phase transition was indeed more gradual even disregarding concerns of heterogeneity.
I'm deliberately being rather vague in what the content of the phase transitions are because I don't think you need a precise understanding of them for the predictions I make in the post. For other predictions, though, an exact specification of a model could be quite valuable.
I agree that the errors in this model are autocorrelated (though I think the mixture of exponentials model avoids this, to the extent it does, mostly because it has many more free parameters---8 is a huge number of parameters, so it's super unsurprising they can absorb most of the autocorrelation).
You can probably specify versions of the exponential model with much fewer free parameters. One sketch:
- An exponential distribution for the mean number of doublings in a new phase (one free parameter)
- A lognormal distribution for the growth speed factor of a new phase over the previous phase (two free parameters)
- A lognormal distribution for the gross growth factor in any given year (log-mean fixed by the phase, a new free parameter for the ratio of mean to standard deviation)
- One parameter to control in some fashion how smooth the transition from one phase to another is
That's five free parameters for a model of the "phase transition" idea that I think is quite reasonable.
(My further guess is that if you actually do a bayesian fit, the model class in David Roodman's data probably fits the data better despite completely giving up on the autocorrelations. E.g. if every 100 years you fit both models to history then use both of them to make a prediction about GDP growth over the next 100 years, you will get more total log loss by using the CES mixture of exponentials.)
I'm uncertain about whether this is true or not. I think it could be true and it would be interesting to try it, but even if it were true it would only make me think that this is because the hyperbolic model is doing well on metrics that help it earn log score and not so well on metrics that I care about in this post.
I'd be interested to see what happens if you score one exponential based model and one stochastic hyperbolic model on answering the following question:
Let be the time it took until now for GWP to double. What's the probability that GWP will increase by more than a factor of 8 in the next years?
My guess is that at parameter parity a model based on phase transitions will do better on answering this type of question compared to a hyperbolic model even though it might actually have worse log score.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-03-18T20:02:08.597Z · LW(p) · GW(p)
If the log score of the hyperbolic model was higher than the phase change model, hopefully you would at least see why some people would lean towards accepting it. I think the kind of data you are offering against the hyperbolic model (like "how does it explain X?") can be pretty well explained as "it's a low-resolution stochastic model, there's a lot of noise." If in fact the model is getting a better log probability than alternative theories, it's not clear on what grounds you'd reject it.
I think it's very reasonable to define a model over parameters per phase. To the extent that it makes the model much more complicated than the hyperbolic growth model, I'd be increasingly inclined to just add the simple autocorrelation term with a prior over strength of autocorrelation.
I'd be interested to see what happens if you score one exponential based model and one stochastic hyperbolic model on answering the following question:
It seems like the answer is almost always no and the question is just how low a probability you give. We have at most 1 yes datapoint for that question (which is based on almost complete guesswork about early populations, e.g. see Ben's critique of data behind continuous acceleration [EA · GW]), and it's going to be extremely sensitive to hyperparameter choices. So overall I'm a bit skeptical of getting something out of that comparison.
You could certainly have a take like "looking at the historical performance of models is not a helpful way to discriminate amongst them, given the small amount of highly unreliable data," but hopefully that should just make you more rather than less sympathetic to someone who adopts a different model.
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-03-18T20:26:43.909Z · LW(p) · GW(p)
First, thanks for participating in this thread. I think I now have a better sense of where the proponents of the hyperbolic model are coming from thanks to your comments.
If the log score of the hyperbolic model was higher than the phase change model, hopefully you would at least see why some people would lean towards accepting it. I think the kind of data you are offering against the hyperbolic model (like "how does it explain X?") can be pretty well explained as "it's a low-resolution stochastic model, there's a lot of noise." If in fact the model is getting a better log probability than alternative theories, it's not clear on what grounds you'd reject it.
I think it's very reasonable to define a model over parameters per phase. To the extent that it makes the model much more complicated than the hyperbolic growth model, I'd be increasingly inclined to just add the simple autocorrelation term with a prior over strength of autocorrelation.
In this case I think we wouldn't disagree: I also think the sum of exponentials model doesn't capture the details of the phase transitions I'm proposing well at all. I think actually designing a good model for the phase transition idea is a challenge and I haven't thought as much about it as I perhaps should have; I'll get back to this thread at some point in the future when I think I have a good enough model for that.
I think this kind of stochastic model does have good ingredients - in particular, even if the phase transition idea is totally correct, I think a hyperbolic model probably gets a better log score on how its dynamics of internal spread end up working out. I just don't think the model is good for answering the particular kind of question I want to answer in this post.
It seems like the answer is almost always no and the question is just how low a probability you give. We have at most 1 yes datapoint for that question (which is based on almost complete guesswork about early populations, e.g. see Ben's critique of data behind continuous acceleration), and it's going to be extremely sensitive to hyperparameter choices. So overall I'm a bit skeptical of getting something out of that comparison.
I think we have two yes datapoints: they are the time periods around the two phase transitions I'm proposing. I agree there's a lot of guesswork here but I think the range of uncertainty is not so large that we don't actually know the answer to my question in these cases.
You could certainly have a take like "looking at the historical performance of models is not a helpful way to discriminate amongst them, given the small amount of highly unreliable data," but hopefully that should just make you more rather than less sympathetic to someone who adopts a different model.
Sure. After listening to your comments and going through some of the data myself, I've changed my mind about this. I still think that I wouldn't trust the hyperbolic model with the specific kind of prediction I mentioned, however, and this just happens to be the relevant kind of prediction in this context. The issue with tuning the autocorrelation term to match recent history seems particularly dangerous to me if we're forecasting something about the next 50 or 100 years.
comment by Edward (edward-germino) · 2022-03-21T17:31:03.803Z · LW(p) · GW(p)
So the rise of AGI will mark the third phase shift to the global economy.
What will the FOURTH phase shift owe to, and according to your model, when will it happen?
Replies from: brian-holtz, ege-erdil↑ comment by Brian Holtz (brian-holtz) · 2022-04-11T21:01:20.945Z · LW(p) · GW(p)
Indeed! And what about the 7th phase shift? I must be missing something here. We're pointing to just two particular transitions in all of human history. I fear we're calling them "phase shifts" to convince ourselves that there is a simple underlying phenomenon which has law-ordained "phases". How can we assume that there will be a coherent series of N>2 such "phase shifts"? How can we assume that they will follow some simple mathematical function with just a handful of parameters?
I guess this makes me even more of a singularity skeptic than Hanson. He marshals powerful economic arguments against naive singularitarianism. But then he forecasts a similarly epochal transition to whole-brain emulations, yet seems worried that it needs more support than its own inside analysis provides. So goes back to an outside extrapolation from past data points a la Kurzweil, but he extrapolates from only 2 points, and says the resulting curve can't really tell us anything beyond the 3rd point. By contrast, Kurzweil marshals multiple technological trends each with dozens of past data points. If we call that naive, then how confidently can we extrapolate along a single trend with only 2 prior data points?
That doesn't feel like a curve to me. It just feels like a prediction of a 3rd transition that will have similar significance to two previous transitions. But being similar in significance is not really evidence of being similar in explainability by some simple underlying lawlike mechanism. The word choice of "phase" seems like sleight of hand here. If instead we talk of "epochs" or "periods", we're less likely to bias ourselves towards a phantom unifying phenomenology of what could just be three not-very-causally-related transitions.
My critique here seems obvious and unoriginal, and the people it's aimed at are very well-informed and thoughtful. So I apologize if this has been addressed elsewhere already. What am I missing?
↑ comment by Ege Erdil (ege-erdil) · 2022-04-11T21:23:06.581Z · LW(p) · GW(p)
Indeed! And what about the 7th phase shift? I must be missing something here. We're pointing to just two particular transitions in all of human history. I fear we're calling them "phase shifts" to convince ourselves that there is a simple underlying phenomenon which has law-ordained "phases". How can we assume that there will be a coherent series of N>2 such "phase shifts"? How can we assume that they will follow some simple mathematical function with just a handful of parameters?
In general you can't assume anything like this, but you also can't assume that the present growth rate will continue forever (or anything else, really) for similar reasons. The point is that to make forecasts about future economic transitions you need some kind of model, and the model in this post is meant to provide the outside view on how often such transitions have occured.
The less controversial version of this, namely people fitting a production function such as to the GDP of different countries with denoting labor stock, capital stock and total factor productivity respectively, and then assuming some law of motion like is the basis of a whole lot of macroeconomic modeling . For example, the entirety of the real business cycle school probably falls into this category. In my view this is much less plausible and in fact this model is immediately refuted by the data since has changed so much over the span of thousands of years.
If you don't like this real business cycle inspired model, what do you use instead to make forecasts? Clearly one kind of model you should keep in mind is the phase transition model, and it achieves a much better fit with data at the expense of only two or three parameters over the real business cycle model. I'm not saying you should treat the model's forecasts as gospel (and I don't, my forecasts are not identical to what the model outputs) but it's definitely valuable to see what this type of model has to say. The same goes for Roodman's stochastic hyperbolic growth model.
I guess this makes me even more of a singularity skeptic than Hanson. He marshals powerful economic arguments against naive singularitarianism. But then he forecasts a similarly epochal transition to whole-brain emulations, yet seems worried that it needs more support than its own inside analysis provides. So goes back to an outside extrapolation from past data points a la Kurzweil, but he extrapolates from only 2 points, and says the resulting curve can't really tell us anything beyond the 3rd point. By contrast, Kurzweil marshals multiple technological trends each with dozens of past data points. If we call that naive, then how confidently can we extrapolate along a single trend with only 2 prior data points?
Kurzweil's marshaled trends in individual technologies are highly unreliable because they don't tell us anything about economic transformation directly, and the supposed connections of his measures to such a transformation are quite tenuous. In my view Hanson's paper has a poor methodology and model specification (something I hope to remedy at some point in the future) but his general approach is much more justified because it looks specifically at examples of past economic transitions.
To give another remarkable example, consider abiogenesis, which is likely the most significant kind of transition that happens in the history of the universe. If you consider all the transitions of this form that have happened before humans even came to exist, I think the argument that phase transitions aren't that unusual is compelling.
That doesn't feel like a curve to me. It just feels like a prediction of a 3rd transition that will have similar significance to two previous transitions. But being similar in significance is not really evidence of being similar in explainability by some simple underlying lawlike mechanism. The word choice of "phase" seems like sleight of hand here. If instead we talk of "epochs" or "periods", we're less likely to bias ourselves towards a phantom unifying phenomenology of what could just be three not-very-causally-related transitions.
I agree that what I've presented in the post is not sufficient evidence to use the word "phase" to describe what's happening. The reason I use this word is because of higher resolution evidence. To give one example, I think any kind of hyperbolic growth model seriously struggles to explain the lack of rapid growth in China or India for most of history, while a phase transition model can explain this by diffusion dynamics.
I also don't want to present a unifying phenomenology of all the transitions and I think I haven't attempted to do anything of the sort. The only real information I've looked at when it comes to the phases is how many doublings of GWP they took to complete.
My critique here seems obvious and unoriginal, and the people it's aimed at are very well-informed and thoughtful. So I apologize if this has been addressed elsewhere already. What am I missing?
I think you're appropriately skeptical of the scant amount of evidence in this area. The problem is just that we don't have anything better to go on and we need to rely on some understanding if we want to make quantitative forecasts. This model is at least a corrective to some other models that in my view are even less reliable.
↑ comment by Ege Erdil (ege-erdil) · 2022-03-21T17:43:51.384Z · LW(p) · GW(p)
So the rise of AGI will mark the third phase shift to the global economy.
I think regardless of whether AGI is the cause of the phase shift, it will definitely be a mark of the next phase in this model, much like how atomic bombs weren't a cause of the Industrial Revolution but they are still a notable phenomenon inside it. AGI being the cause is probably ~ 65% for me.
What will the FOURTH phase shift owe to, and according to your model, when will it happen?
I have no idea. The model will obviously fail to work once growth becomes so fast that we reach physical limits, much like the hyperbolic model, but my thinking here is close to Robin Hanson's: it's ~ impossible to say what the fourth phase shift would be like, but the timing would probably be only a few decades (at most) after the third phase shift.