OpenAI: "Scaling Laws for Transfer", Hernandez et al.
post by Lukas Finnveden (Lanrian) · 2021-02-04T12:49:25.704Z · LW · GW · 3 commentsThis is a link post for https://arxiv.org/pdf/2102.01293.pdf
Contents
3 comments
OpenAI has released a paper on scaling laws for transfer learning from general English text to python code. Author's tweet summary.
Abstract: "We study empirical scaling laws for transfer learning between distributions in an unsupervised, fine-tuning setting. When we train increasingly large neural networks from-scratch on a fixed-size dataset, they eventually become data-limited and stop improving in performance (cross-entropy loss). When we do the same for models pre-trained on a large language dataset, the slope in performance gains is merely reduced rather than going to zero. We calculate the effective data "transferred" from pre-training by determining how much data a transformer of the same size would have required to achieve the same loss when training from scratch. In other words, we focus on units of data while holding everything else fixed. We find that the effective data transferred is described well in the low data regime by a power-law of parameter count and fine-tuning dataset size. We believe the exponents in these power-laws correspond to measures of the generality of a model and proximity of distributions (in a directed rather than symmetric sense). We find that pre-training effectively multiplies the fine-tuning dataset size. Transfer, like overall performance, scales predictably in terms of parameters, data, and compute."
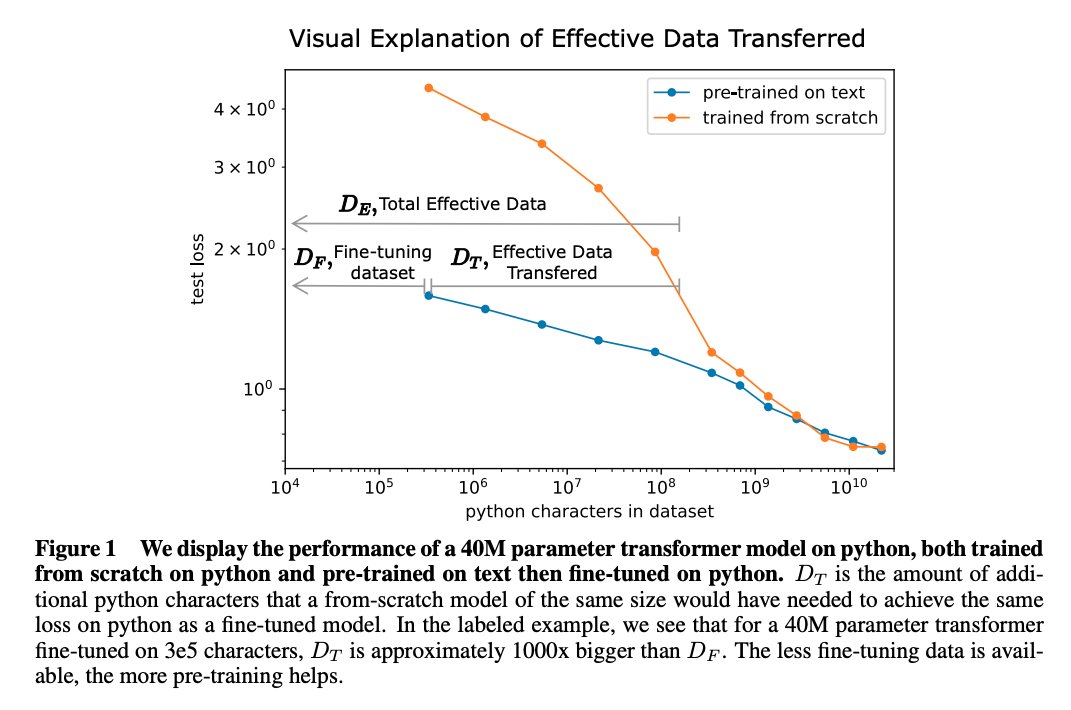
The power law they find is with coefficients

3 comments
Comments sorted by top scores.
comment by Lukas Finnveden (Lanrian) · 2021-02-04T12:59:52.026Z · LW(p) · GW(p)
It's worth noting that their language model still uses BPEs, and as far as I can tell the encoding is completely optimised for English text rather than code (see section 2). It seems like this should make coding unusually hard compared to the pretraining task; but maybe make pretraining more useful, as the model needs time to figure out how the encoding works.
comment by avturchin · 2021-02-05T09:43:20.258Z · LW(p) · GW(p)
gwern on reddit:
"The most immediate implication of this would be that you now have a scaling law for transfer learning, and so you can predict how large a general-purpose model you need in order to obtain the necessary performance on a given low-n dataset. So if you have some economic use-cases in mind where you only have, say, _n_=1000 datapoints, you can use this to estimate what scale model is necessary to make that viable. My first impression is that this power law looks quite favorable*, and so this is a serious shot across the bow to any old-style AI startups or businesses which thought "our moat is our data, no one has the millions of datapoints necessary (because everyone knows DL is so sample-inefficient) to compete with us". The curves here indicate that just training a large as possible model on broad datasets is going to absolutely smash anyone trying to hand-curate finetuning datasets, especially for the small datasets people worry most about...
* eg the text->python example: the text is basically just random Internet text (same as GPT-3), Common Crawl etc, nothing special, not particularly programming-related, and the python is Github Python code; nevertheless, the transfer learning is very impressive: a 10x model size increase in the pretrained 'text' model is worth 100x more Github data!"
comment by Viliam · 2021-02-06T17:15:34.022Z · LW(p) · GW(p)
I see a dark future of software development, when artificial intelligence will write the code, and most jobs available to humans will consist of debugging that code when something goes wrong.
But maybe even "debugging" will consist of writing plain-text suggestions for AI to fix itself, and checking whether that helped. Not sure if that makes things better or worse, but it will make software development seem like psychoanalysis.