Synthetic Media and The Future of Film
post by ifalpha · 2022-05-24T05:54:22.073Z · LW · GW · 14 commentsContents
Beyond current models Barriers to entry Preferences and death Update 1 Update 2 Update 3 None 14 comments
It was long believed that the first jobs to be obsoleted by AI would be lawyers and accountants, as those seemed the prime targets. After all, creativity has hardly been the forte of computers for the past half-century, being almost exclusively the product of human effort. However, in recent years, something has begun to change significantly. Widely introduced to the public via OpenAI's original DALL·E model, text-to-image has captured the imaginations of countless individuals who were under the impression that such advancements were still decades away. As even more advanced models rear their heads, such as DALL·E 2 and the (as of writing) brand new Imagen, we can clearly note that the quality of images is increasing at an incredibly rapid pace. While there have been many posts already written on the limitations of DALL·E 2 [LW · GW], it is worth highlighting that newly released Imagen has already solved several of the listed issues, such as text generation and object colorization. All this is to say that text-to-image models are already remarkable, and they've hardly been around for half a decade.
Beyond current models
While existing solutions to the text-to-image problem are incredible, there is clearly a lot of room left to grow. The images are almost photorealistic, and some are even close enough to fool the uninformed, but close inspection always reveals minor flaws. Let's assume that the current rate of progress continues. This realistically leaves us with only a handful of years before images can be generated that are entirely indistinguishable from real photographs. (If you believe that this point will never be reached, I would love to hear your reasoning.) Once that mountaintop is summitted, where is there left to go? Higher resolution? Quicker generation? The answer is obvious: video.
There are already models that are beginning to tackle text-to-video generation, such as NÜWA and the more recent (but not-as-appealingly named) Video Diffusion Models.


While the results are low quality and nowhere near the text-to-images models of today, they do bear a striking resemblance to the image models of just a few years ago.

If we are to be bold and assume a rate of progress identical to the text-to-image models, we should expect to see near-photorealistic video generation within the next several years, however short those videos might be. If we are slightly more pessimistic and assume it takes twice as long for video models to see the same growth, that still lands us within this decade. Regardless of whether it takes six years, sixteen years, or sixty years, the end point is inescapable: we will eventually be able to instantly create photorealistic videos of anything, on demand.
Clearly, this raises several questions. One of which is the most prominent issue we face with modern day deepfakes: how to prevent using the technology to create blackmail and other illegal material. However, since this is not an issue exclusive to AI, having existed since the birth of photo editing, we can ignore it for the purposes of this post. Instead, I would like to focus on what this will do to the future of film.
Barriers to entry
Let's assume that, eventually, text-to-video models get to the point that the end user is able to sit down at their computer and manufacture a feature length film in as much time as it would take to watch it, complete with a compelling plot and interesting score. (You can imagine this being as far away as it needs to be to fit your personal timeline, as it doesn't especially matter when it happens.) When this day arrives, a notable barrier in creativity will have been broken. What the digital camera did to the photography industry, namely increase access and decrease the skill level needed to enter the field, synthetic media will do to the film industry. While these factors have been massaged down to a manageable point for some time, with access to film equipment and editing software more ubiquitous than ever, there is still one thing that prevents most people from participating: organization.
Where almost anyone can use a few hours of their spare time to follow a couple YouTube tutorials and make incredible images in Photoshop, there are comparatively few people who are able to make movies. (Note that when I make this point, I am not exclusively referring to Hollywood quality productions. However, I do think there is an important distinction to be made between low-budget indie films and a couple teenagers recording their LARP session on an iPhone.) The main barrier that stands in the way is simply organization. Where one man can easily sit down and create a phenomenal work of art in Photoshop, it is nearly impossible for that same one man to create a feature length film on his own.
Aside from obvious elements that would require talent in multiple fields, such as the aforementioned scripting and scoring, most movies require multiple actors. This simple fact immediately causes the production of a movie to be a multi-person organizational challenge. Namely, the same one man who was having a fine time working on his own with Photoshop now has to find and coordinate actors, who each also need to have their own set of skills that make them worthy of the role. All of this takes time and money; enough of both to make most people who aspire to be filmmakers to abandon their aspirations. This is why Hollywood, as corrupt and condemnable as it might be, is so successful. Most people would probably rather make their own films than watch whatever Netflix felt like financing, but they are simply unable to.
Preferences and death
This leaves us with a fascinating question: once individuals are able to create their own movies at the push of a button, where does that leave the film industry? There are already people discussing what future versions of text-to-image models might do to stock photography companies and illustrators. Why would anyone pay $500 to get a custom image drawn by a human when DALL·E 4 is able to do it just as well for free? It would seem that the people who find themselves currently making a living off of providing these services should be considering other career options, as their time is limited. Similarly, I would expect a gradual decline in the revenue generated by studio-produced movies. The shift will be gradual, but as it is now with photos, the writing will be on the wall. Just as the illustrator and the painter will be replaced (perhaps not wholesale, but certainly to a significant degree) by the text-to-image model, the director and the actor will be replaced by the text-to-video model.
In a world where people are able to create new Star Wars movies on demand, why would anyone settle for what Disney believes is the right way to go? If you were able to insert yourself into movies, wouldn't that be something that interests you? Instead of training to be an actor, moving to California and hoping to get lucky, what if you were simply able to tell an AI model to swap you in for the role of Luke Skywalker? I'm no fortune teller, but I would contend that a majority of people would find quite a lot of value in that proposal.
The time for speculating about this potential future is nearing its end. Just as we would now be foolish to imagine that text-to-image models will not result in significant changes to the way we interact with illustrators and photographers, we will soon be equally foolish to dismiss text-to-video models. Hollywood is not yet in any danger, and their vice grip on blockbuster films will remain firm for many years to come, but it won't last forever. Just as the silver screen was the death of the live theater, AI will be the death of the movie theater.
Edit: I have decided to continuously update this post with models and published works relating to this subject, instead of making follow-up posts every time something interesting happens. Check back periodically to see if anything new has been added.
Update 1
05/27/2022
The first update I would like to add would be the extremely recently published Flexible Diffusion Modeling of Long Videos, which has already produced incredible results. One of said results, is a 90 minute photorealistic video of a car driving on the road. Granted, the video looks like a 144p YouTube video uploaded in 2008, but it might very well have just set the record for longest coherent AI generated video.

While this might seem underwhelming, it is important to keep in mind that the examples mentioned previously in this article were only able to produce videos that were several seconds long. The videos generated with this model might be boring to watch, but make no mistake - this is a sign of things to come. Coherence will forever be the greatest challenge this field of research faces, and it looks like the solution may be near.
Update 2
05/29/2022
The second update comes only a matter of days after the first, which is perhaps something important to take note of. CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers might just be the most impressive example of text-to-video so far. While it does not display the long term coherence of the Flexible Diffusion model that was presented in the first update, the results speak for themselves.
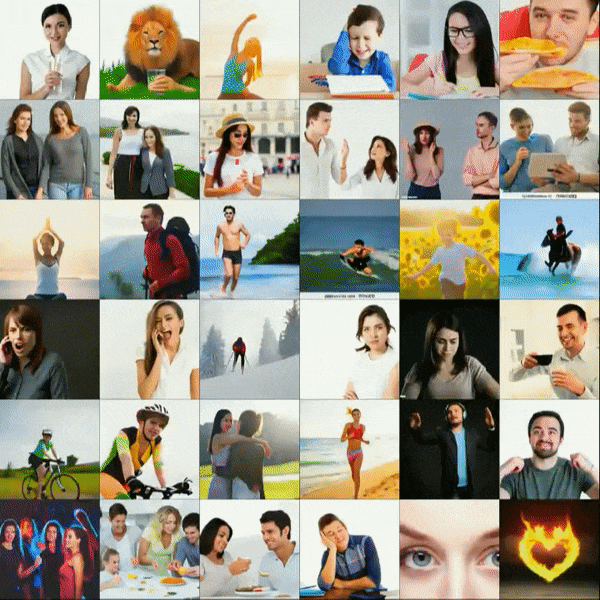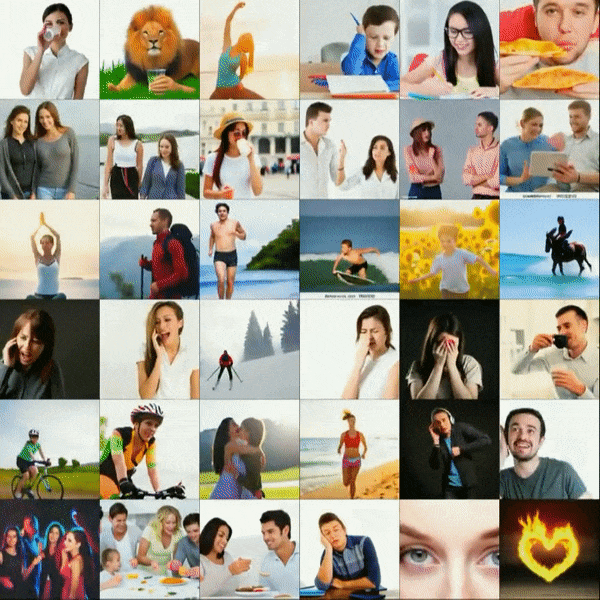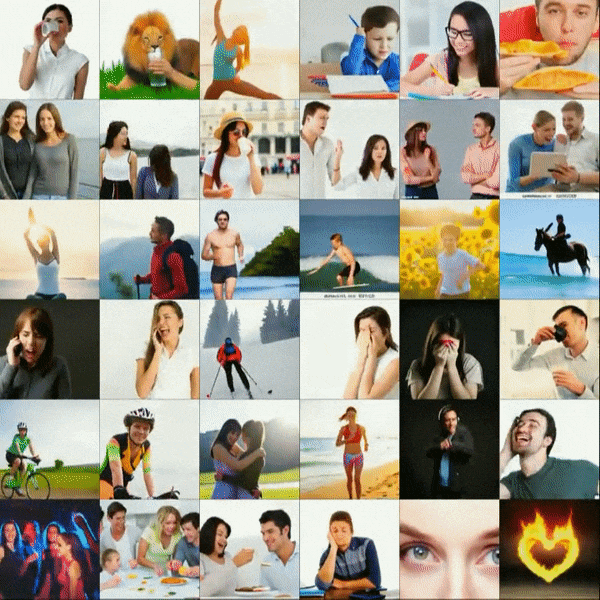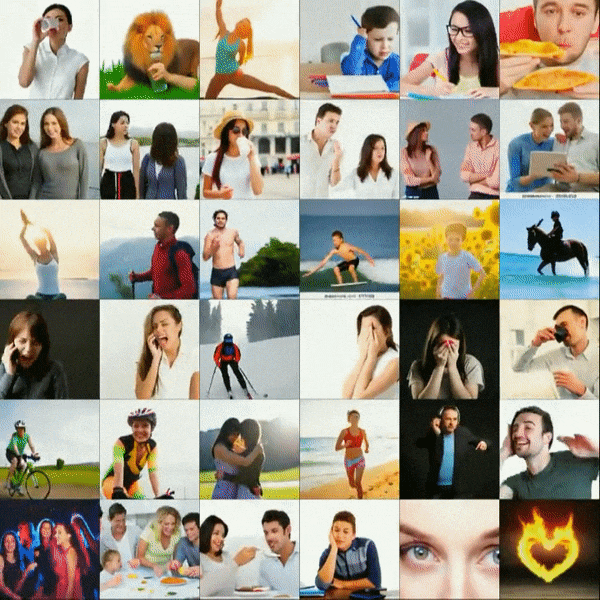
At the time of writing, there is not a substantial amount of information available about this project, aside from the actual text inputs being Chinese. Regardless of the lack of information, we can probably take a few educated guesses. In my opinion, the model was likely trained on a large set of stock videos, which would explain the more sterile appearance of the results. (Were a similar model to be trained on a corpus of videos randomly scraped off of YouTube, the results would likely be much more diverse and true to life.)
A quick visual comparison to the results generated by NÜWA, one of which can be seen in the main text of this post, this new model is certainly more capable of generating realistic results. If you blur your eyes, you might have a hard time telling these videos apart from something actually found in a stock video collection. A noticeable flaw is, while temporal coherence on a general scale seems to be under control, close inspection reveals that every generated video is having trouble staying consistent with fine details. There is an almost indescribable shimmering effect on every video.
Does this get us any closer to the aforementioned death of cinema? In truth, it's hard to tell. While this model does produce nicer looking results than anything previously seen, it is still a far cry from anything that would even be helpful in producing a film. While we will undoubtedly look back on models such as CogVideo and wonder how more people didn't see this technology coming, it is clear that there is still a far way to go.
That being said, this is probably a fire alarm [LW · GW] moment. Do with it what you will.
(Update: The paper has been published.)
Update 3
6/8/2022
For update number three, which is only slightly more than one week removed from the previous entry, it's time to look at Generating Long Videos of Dynamic Scenes. (Similar to update two, the paper is not published at the time of writing. I'll append it when it is.)

At first, the results are almost unbelievable. While there is a good amount of warping and inconsistency in the videos, the overall coherence is remarkable. When compared to StyleGAN-V, which might very well give you a headache if you watch it for too long, one could almost be forgiven for mistaking the new results for real videos recorded with bad cameras. Looking back on the model presented in update one, Flexible Diffusion Modeling of Long Videos, which also features motion combined with improved coherence, it feels as though a years worth of improvement has been made since then.
Something important to keep in mind about this model is that it isn't text-to-video quite like the other models in this post. Where everything else presented here has followed the formula of "Enter Text = Get Video", this model seems to be specifically trained on datasets finetuned to produce the desired results. Again, the paper isn't yet released, but from what is public as of writing this, it seems that in order to get a video of clouds you have to train it on a specific dataset of clouds and nothing else. Of course, this could just be an artificial limitation placed upon the model for the purposes of demonstration, with any text-to-video capabilities neutered for the sheer sake of appearances. Either way, this is unmistakably a significant step in believable video generation.
There honestly isn't much to say other than it's almost difficult to stay abreast of the progress being made in this field. When this post was made, the most advanced models were NÜWA and Video Diffusion Models, the results of which were muddy and barely passable as videos. I mentioned in update three that I believe we're currently witnessing a fire alarm moment for AI generated video, and my beliefs have only been strengthened by this release. When the first large-scale DALL·E-esque video generation model is put into the spotlight for the general public to see, it will take them by considerable surprise. Those who have been paying attention will be less surprised, but probably still not entirely ready for what comes next. I previously stated in the main post that such a moment could be several years away. Now, however, I could see this occurring by Q4 of this year, 2022.
(Update: The paper has been published.)
14 comments
Comments sorted by top scores.
comment by qmaury · 2022-05-25T14:46:22.989Z · LW(p) · GW(p)
very good post. I had a scare while reading this, remembering a conversation I had with someone a few years ago, telling them that artists and painters should all be safe, as "I don't think computers will be able to paint". This stuff is scary (and fun somehow).
Replies from: Viliam↑ comment by Viliam · 2022-05-25T18:57:14.585Z · LW(p) · GW(p)
First the artists will become unemployed, then the software developers... and the truck drivers will keep their jobs until Singularity. The opposite of what many people expected.
Replies from: qmaury↑ comment by qmaury · 2022-05-27T14:53:22.207Z · LW(p) · GW(p)
I think software developers should keep their jobs for a while. Their jobs involve a lot of 'people asking very specific requests' and I think the only reason it works is because both parties are humans and can understand each other well. I think as long as people don't know how to be specific and robotic with how they request things, software devs should be fine.
Replies from: yitz↑ comment by Yitz (yitz) · 2022-05-27T17:52:57.324Z · LW(p) · GW(p)
Idk, language models are getting increasingly good at responding to fairly vague prompts. They aren't incredible at it or anything, but I expect that skill to increase over time, probably to human-level, but maybe even above that.
comment by p.b. · 2022-05-24T14:22:50.962Z · LW(p) · GW(p)
It was pretty clear that most of Dall-e's limitations were temporary, but Imagen looks really amazing. Would love to see all the Dall-e limitations reassessed with Imagen. Also, I'd bet OpenAI will update Dall-e within 2022 (possibly without anouncing Dall-e3).
Replies from: ifalphacomment by Otto Zastrow (otto-zastrow) · 2022-06-11T09:05:01.847Z · LW(p) · GW(p)
this approach of forward thinking is what I was looking for. Does anybody know of more content like this? (youtube, blog, LW)
Speculating and writing about how and in what order these new tools can change components of future every day life seems very valuable. We all know change is coming at ever increasing rate. But there is little written speculation about the near term future. I'd love to help piece together such thinking.
Replies from: ifalpha↑ comment by ifalpha · 2022-06-16T04:09:04.336Z · LW(p) · GW(p)
I think most people on LW try to keep their speculations to a minimum mainly to avoid embarrassment for when they don't come true. I have no such worries when it comes to this technology specifically, since the outcome is so obvious that it would be more unlikely for it to not happen.
While I'm not certain about any particular other content that might scratch the same itch, I definitely plan to write more posts on other topics similar to this one.
comment by Yitz (yitz) · 2022-05-27T17:55:24.494Z · LW(p) · GW(p)
One possible barrier to that is going to be copyright laws. I have a feeling film studios won't take kindly to people creating movies using their intellectual property, and if the models required to generate such movies are larger than most private individuals can afford (which I would strongly expect, at least for a few years), then they may be able to get the entire endeavour shut down for a long while.
Replies from: ifalpha↑ comment by ifalpha · 2022-05-28T05:54:59.383Z · LW(p) · GW(p)
There's nothing stopping people from making fan films at the current moment, generally with the limitation that it isn't put up for sale. I would find them being able to shut down progress on this tech dubious at best, but certainly not outside the realm of possibility.
It's important to consider the idea that these models could also be used in tandem with actual footage as a cheap alternative to the modern CGI pipeline. Instead of paying hundreds of artists to painstakingly make your CGI alien world, you could ask a future model to inpaint the green screens with an alien world that it generates.
comment by Flaglandbase · 2022-05-24T07:59:21.420Z · LW(p) · GW(p)
Very true, the only exception I can think off is that if I wanted a movie in which I was the main character I would have to spend immense time defining and explaining every aspect of my life and interests.
Replies from: ifalpha↑ comment by ifalpha · 2022-05-24T13:39:09.792Z · LW(p) · GW(p)
I could sit here and speculate on potential workarounds, but you're probably correct. It makes sense that if you want to place yourself in movies, you would need to first build a comprehensive model of yourself for the AI to work with. Fortunately, this is the kind of thing you'd only need to do once.
comment by Jasmine Karam (jasmine-karam) · 2023-02-15T00:43:45.421Z · LW(p) · GW(p)
These systems will always have the issue of the uncanny valley, especially the closer it tries to mimick photo realism the moe uncanny valley. Not even the best CGI can go past this more or less. Hence many I causing Nyerere argue that live action movies should use less CGI or only use it as a spice cause it does not leave as good impact as practical effects, people can still see what is real and is CG. And the more real CG tries to be the greater risk for uncanny valley. The current Last of US show feels more real to asuence because they use a lot of practical effects, the clickers and bloaters are made not with CGI but with suits and prosthetics.
Progress is also a myth, degrading human arts and the value of them and striping them of the creative and artistic process is not progress, reducing the value of human skill and growth is not progress, it is just further dumbing down humanity and creating a wave mediocrity . It is simply giving every aspect of your life to companies like Open AI, these tech giants like AU researcher Gary Marcus points out have no desire to play fair, so not open their research for peer reviews release systems despite risks. It solved and serve their venture capitalists investors, many who would lsay be to see a world where they would not need artists.
Despite the human losss and cultural loss that would mean.
Now for some more ideological oriented tech utopians it is part of creating AGI and a future tech utopia which I would describe similar to the dystopia in the movies Wall E and the novel Brave New World.
Is that what we want? A future if a passive dumb down humanity reduces to a consumer in an endless stream of content. The existential risks are also there m, like Crichton’s film Westworld something could go wrong even in a robot filled theme park and you would loose control.
Where a crises of meaning will happen as human labour or activity will no longer have a real impact. This will effect mental health negatively.
Making art is good for mental health and remaining mentally sharp in older age. It is a self expression and through the creative process and friction you get growth. AI generation takes that all out of it. It focuses on output and quick gratification, but quick gratification does not make people happy in the long run. We need friction in the creative process to feel creatively fulfilled.
The Hadza in Africa who live as Hunter gatherers, sure they have problems we do not have but they suffer very little depression and anxiety disorders. A reason for that is that they feel community and they feel needed. Everyone contributes something to their society, everyone feels important. A world where machines do everything the feelings of alienation, meaningless etc will increase.
Secondly these systems are just hype, they are not creative, sentient or aware, they just probabilistic algorithms have massive datasets of others work with any permission or consent. They are as Gary Marcus puts autocorrect on steroids.
The mistakes they with image generators going from slight uncanny valley to absolute horror with dead eyes, zombie faces to not being able to do hands, Chat GPTspouting bullshit to even dangerous BS, or self driving cars not slowing down when a human holds a stop sign in front of it are inbuilt into the system. You can never get anything specific.
These models have no grasp or relationship with the outside world. It does big know why it creates or even what a hand is. It has no intentionality. Chat GPT does not know what it writes it just hopes to next most likely word or phrase.
So theme making mistakes like these is a reality as they have no grasp or knowledge of the world. Hence why image generators are the best at making horror and uncanny valley because sometimes what they make are so unhuman that no human would make them.
So please tone down the current AI hype and there has been many in many the past, a new AI winter is coming but now tabla to fools in Open AI and the rest we will deal with more dangerous forms of media manipulation, deep fakes and fake media then ever. More cheating and faking than ever. With more energy stealing systems than ever hence it good for the people environment. In fact just having everyone having self-driving cars would demand more energy production than ever. The AI utopia would not be realistic without degrading our environment and recourses. There is no free lunch and no escape from entropy.
Just like in inGen in Crichton’s novel Jurassic park or Delos his film Westworld, these companies never thought about what they should do, only what they could do to get greedy investors. This is the horror when AI research as moves from transparent universities to corporations. They have not gone through the philosophical and social implications of what they are doing. Driven by money and utopian goals.
Even worse many of these tech utopians scoff at Fields’s like psychology, neurology, anthropology and philosophy which tries to give a different perspective and show awful low respect to human values and arts.
I also see it here peoples say that artists will be replaced in the comments, making art is a human activity and something defines modern human behavior.
Humans will not stop and other humans want the human factor he connection. An AI avatar will never beat areal human actor I connecting with the real world and human feelings.
These AI systems are not creative, not sentient or have any theory of mind or insert being of human feelings, thoughts or experience. They cannot give anything specific and they are not artists or intelligent.
The amount of dual respect I have seen against especially visual artists among the tech utopians is heartbreaking, anthropomorphising these machines or even worse de-humanizing the artist, as just another algorithmic system.
We do not know how human creative process and inspiration work nor how to replicate consciousness . It is beyond the grasp of what we know. So artists will not be replaced.
Don’t fall for the current hype.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2023-02-15T22:32:53.452Z · LW(p) · GW(p)
Hi - this must be you as well? Are you an independent researcher/critic of radical technofuturism, or do you affiliate with any particular movement, like Zerzan's "primitivism"?