Internal Target Information for AI Oversight
post by Paul Colognese (paul-colognese) · 2023-10-20T14:53:00.284Z · LW · GW · 0 commentsContents
Summary The Inner Alignment Problem and Internal Oversight Oversight Model The Agent Internal World Models and Planning/Optimization The Overseer Internal Target Information and Oversight What is Internal Target Information? Examples of Internal Target Information Example - Thermostat Example - Action Selection via Planning/Optimization How can the Overseer Leverage Internal Target Information? Conclusion None No comments
Thanks to Arun Jose for discussions and feedback.
Summary
In this short post, we discuss the concept of Internal Target Information within agentic AI systems, arguing that agentic systems possess internal information about their targets. This information, we propose, can potentially be detected and interpreted by an overseer before the target outcome is realized in the environment, offering a pathway to preempt catastrophic outcomes posed by future agentic AI systems.
This discussion aims to highlight the key idea that motivates our current research agenda [LW · GW], laying a foundation for forthcoming work.
We’ll start by introducing the inner alignment problem and why oversight of an agent’s internals is important. We’ll then introduce a model of an overseer overseeing an agent. Finally, we’ll introduce and discuss the notion of Internal Target Information in more detail and how it might be used in the oversight process.

The Inner Alignment Problem and Internal Oversight
We are concerned with the possibility of creating agents with misaligned objectives, potentially leading to catastrophic real-world outcomes. A conceivable solution lies in effective oversight: detecting misalignment early enough allows for timely intervention, preventing undesirable outcomes.
Oversight, based on behavioral observations, may fail to confidently predict future outcomes pursued by the Agent, especially in the face of goal misgeneralization and deceptive alignment [LW · GW].
In the remainder of this post, we will explore the idea that information about the agent's true objective may be contained in its internals, and so may be detectable by an overseer equipped with sufficiently strong interpretability tools.
To begin our exploration of this idea, we start by introducing a model of the oversight process.
Oversight Model
We introduce a model of an Overseer overseeing an Agent that begins to clarify what good oversight might entail, mainly focusing on the objective of the Overseer: to prevent catastrophic outcomes caused by misaligned agentic AI. Moreover, we hope that a more refined future version of this model may help establish benchmarks to evaluate oversight methods.
The Agent
The Agent is a system that has sensors that take in sensory inputs/observations of the environment and actuators that produce actions that affect the environment.
The most important property of the Agent, and that which makes it potentially dangerous, is that it robustly selects actions that steer the environment towards a set of target states.
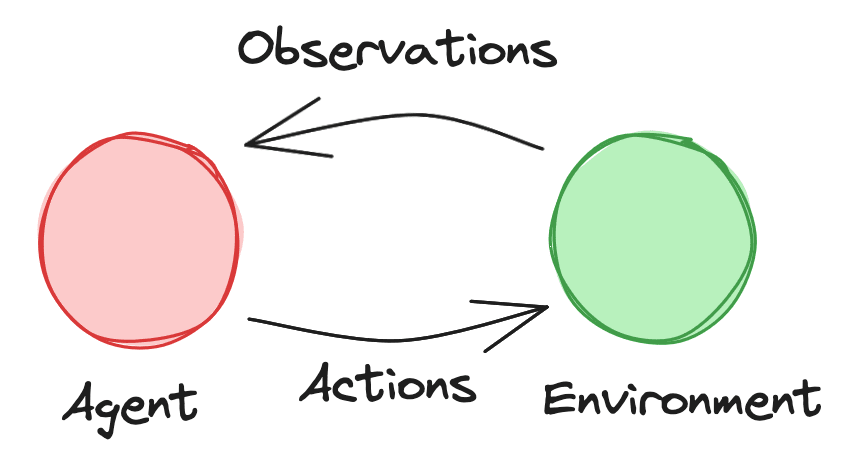
We use the abstraction of an Action-Selection Mechanism[1] to denote whatever mechanism the Agent uses to select actions that steer the world toward its target outcome.
Internal World Models and Planning/Optimization
We often make the assumption that the Agent will have an internal world model and the capacity for planning/optimization.
Others have argued that advanced agents will need to have a world model and planning capacities if they are to act competently in a complex environment and achieve goals over long time horizons. Briefly, internal world models allow agents to simulate potential outcomes or strategies before taking action, which is crucial in navigating complex, dynamic environments.
Because we’re primarily concerned with agents capable of achieving dangerous outcomes in our world, this assumption feels justified.
The Overseer
The Overseer is the system responsible for oversight of the Agent during training and deployment. It might also be well described as a particular kind of agent with its own preferences for states the environment could be in.
The Overseer’s sensors may observe the environment but must also allow for observations of the Agent’s behavior (and potentially the Agent’s internals). Its actuators must be able to affect the Agent (e.g., via the ability to shut the Agent down, update the Agent via further training, etc.)
The Overseer’s objective is to ensure that the Agent takes actions to steer the world according to the Overseer’s preferences. For the Overseer to do this successfully, it requires the capacity to accurately detect and interpret the Agent’s target and evaluate the target outcome with respect to the Overseer’s preferences.
Importantly, the Overseer needs to be able to detect if the Agent has a bad target (according to the Overseer’s preferences) before the Agent can realize the target outcome in the world.
The Overseer’s advantage is that it has prior knowledge of the Agent’s architecture, has access to the Agent’s past and current observations and actions, and can observe the Agent's internals (e.g., such as weights and activations in the case of an NN-based agent). This holds during the training process and in deployment.
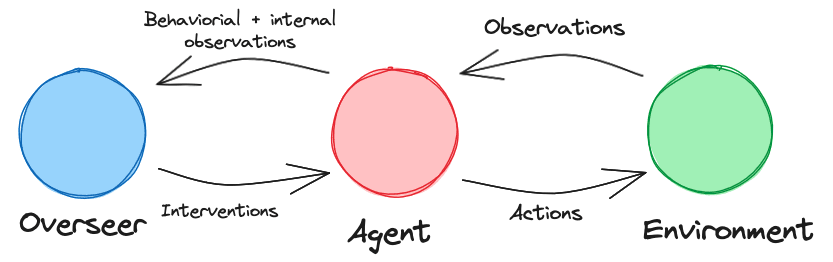
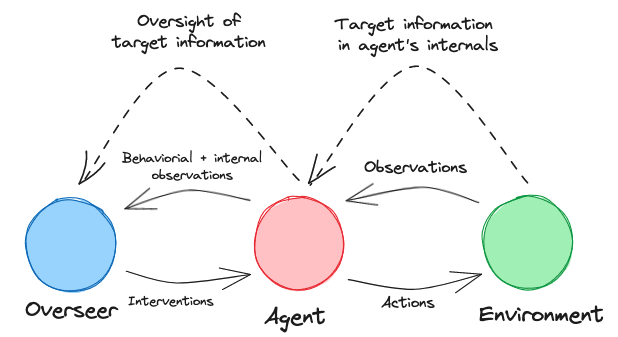
Internal Target Information and Oversight
What is Internal Target Information?
For the Agent’s Action-Selection Mechanism to select actions that lead to its target outcome, it must use some information about the target to differentiate between actions that lead to the target outcome and actions that don’t.
We call this Internal Target Information.
Examples of Internal Target Information
Example - Thermostat
Consider a fixed-temperature thermostat whose objective is to keep the room at a fixed target temperature.
It uses a thermometer to measure the current room temperature and can either turn on a radiator to increase the room’s temperature or the AC to decrease the room’s temperature.
In order to select actions that cause the room's target temperature to be maintained, the thermostat’s Action-Selection Mechanism must contain some information about the target temperature; without this information, it can’t select the correct action, even if it knows the room’s current temperature.
In particular, suppose the thermostat's Action-Selection Mechanism is an algorithm that looks something like:
if current_temperature < target_temperature:
TurnOnRadiator()
elif current_temperature > target_temperature:
TurnOnAC()
else:
DoNothing()Then, the Action-Selection Mechanism's Internal Target Information is represented as a constant (target_temperature) that the Overseer might be able to detect via reverse engineering the above algorithm from the Agent's internals.
Example - Action Selection via Planning/Optimization
Consider an agent that doesn’t have a predetermined heuristic for selecting successful actions (or action sequences) that lead to its target outcome. This could be because the environment is sufficiently complicated and/or novel.
The Agent has a set of actions/plans to choose from but doesn’t immediately know which one will lead to the target outcome, and so must use an optimization process to select the correct action/plan amongst the set of possible actions/plans it could take. Therefore, the Agent must use some procedure by which it deduces which outcomes result from which actions, and then must evaluate which outcome corresponds to the target outcome. It then uses this evaluation to select the action that leads to the target outcome.
In this case, the evaluation function contains the target information.[2]
Note that planning can be thought of as an example of optimization, where the outcomes that correspond to actions/plans are evaluated by simulating the result of the plan using a world model.
How can the Overseer Leverage Internal Target Information?
It seems clear that some Internal Target Information must exist within agents; without such information, there is no way for the Agent’s Action-Selection Mechanism to differentiate between actions that lead to the target outcome and those that don’t. Furthermore, this information is present within the internals of the Agent before the target outcome is realized in the world because it is used to select actions that lead to the target outcome.
Our hope is that the Overseer can detect this Internal Target Information and use it to deduce what the Agent’s target is before the target outcome is realized. This would allow the Overseer to achieve its objective of intervening and preventing the Agent from causing bad outcomes, as described above.[3]
See this section of this post [LW · GW] for more ways this information could be leveraged.
We conclude this section by pointing out that the Internal Target Information of an arbitrary agent (such as a neural-network-based agent) will probably be extremely hard to detect and interpret. Despite this, our current research agenda [LW · GW] aims at finding methods of detecting Internal Target Information, or demonstrating that it's too difficult of a task.
Conclusion
In this post, we introduced the notion of Internal Target Information and discussed how it might be used by an overseer to prevent catastrophic outcomes from misaligned AIs.
In future work, we intend to explore further what shape Internal Target Information takes within agents and investigate to what extent it’s possible for an overseer to detect this Internal Target Information.

- ^
Or Decision-Making Process.
- ^
- ^
The ability of the Overseer to properly evaluate the target outcome is a separate problem that could be thought of as a version of the outer alignment problem. We will discuss this further in an upcoming post.
0 comments
Comments sorted by top scores.