High-level interpretability: detecting an AI's objectives
post by Paul Colognese (paul-colognese), Jozdien · 2023-09-28T19:30:16.753Z · LW · GW · 4 commentsContents
Summary Introduction to objective detection Background What is an objective? How objective detection can be useful The objective of objective theory Initial hypothesized properties of objectives Properties of objectives Empirical work/setup Maze environment Models Grounding our objective theory Objectives in maze-solving models Detecting information used by objectives Using probes to measure mutual information Where’s the objective in the maze-solving model? Methodology Experiments Experiment 1 - Cheese location in different models Predictions Results Experiment 2 - Cheese model - cheese, red gem, and mouse locations Predictions Results Future empirical work Objective detection method in action The setup Results of the objective detection method Limitations of this goal detection method Concluding thoughts Related work Summary and future work Appendix Our research methodology None 4 comments
Thanks to Monte MacDiarmid (for discussions, feedback, and experiment infrastructure) and to the Shard Theory team for their prior work and exploratory infrastructure.
Thanks to Joseph Bloom, John Wentworth, Alexander Gietelink Oldenziel, Johannes Treuitlein, Marius Hobbhahn, Jeremy Gillen, Bilal Chughtai, Evan Hubinger, Rocket Drew, Tassilo Neubauer, Jan Betley, and Juliette Culver for discussions/feedback.
Summary
This is a brief overview of our research agenda, recent progress, and future objectives.
Having the ability to robustly detect, interpret, and modify an AI’s objectives could allow us to directly solve the inner alignment problem [LW · GW]. Our work focuses on a top-down approach, where we focus on clarifying our understanding of how objectives might exist in an AI’s internals and developing methods to detect and understand them.[1]
This post is meant to do quite a few things:
- We’ll start by outlining the problem and potential solution.
- We then present our initial theory on objectives.
- Next, we look at some initial empirical work that shows how we hope to test theory-based predictions.
- We then illustrate how we intend to go from theory to objective detection methods by producing an initial (but crude) objective detection method.
- Finally, we conclude by discussing related work and future directions.
Introduction to objective detection
In this section, we outline how objective detection could be used to tackle the inner alignment problem, clarify what we mean when we refer to an internal objective, and present our initial theory on objectives.
Background
A major concern is that we may accidentally train AIs that pursue misaligned objectives. It is insufficient to rely on behavioral observations to confidently deduce the true objectives of an AI system. This is in part due to the problem of deceptive alignment [LW · GW]. Therefore, we may need to rely on advanced interpretability tools [AF · GW] to confidently deduce the true objectives of AI systems.
Prior [? · GW] work [LW · GW] has discussed how agentic AIs are likely to have internal objectives used to select actions by predicting whether they will lead to target outcomes. If an overseer had an objective detection method that could robustly detect and interpret all of the internal objectives of an AI (in training and deployment), it could confidently know whether or not the system is misaligned and intervene or use this observation as part of a training signal [LW · GW].
We currently believe that this approach is one of our best hopes at tackling some of the hardest problems in alignment, such as the sharp left turn [LW · GW] and (deep [LW · GW]) deception [LW · GW].[2]
Our current research agenda primarily aims to develop an appropriate notion of an internal objective that is probable and predictive [LW · GW], to use that notion to develop a theory around internal objectives and what form they take in future agentic systems, and then to leverage this theory to build detection methods that can identify and interpret internal objectives in such systems.
What is an objective?
In this section, we outline starting intuitions on what we think objectives are and begin to develop a notion of objectives that will form the basis of our initial theory of objectives.
We start with the observation that an agent has to select actions[3] that lead to its target outcome by some kind of internal action-selection mechanism. This action-selection mechanism could take the form of explicit optimization (i.e., explicitly via the selection of an action by evaluating a set of possible actions), some heuristics-based approach, or a combination of both.
This internal action-selection mechanism needs to use some criterion to decide which actions lead to the target outcome. For example, in a chess engine, Monte Carlo Tree Search is directed by the evaluation function to find the best moves. For a heuristics-based system such as a thermostat, an internal constant that represents the ideal room temperature is used to select whether or not to turn the heating on.
Our starting intuition and hope is that this criterion might be detectable and interpretable by an overseer, allowing them to map from the internal information contained in the criterion to representations of the corresponding target outcome.
Based on this understanding, we define our initial notion of an internal objective as follows:
An (internal) objective is the criterion that an agent’s internal action-selection mechanism uses to select actions that lead to the target outcome.[4][5]
In complex environments, especially rich ones like the real world, an agent is often incentivized [? · GW] to use more explicit forms of optimization.[6] We expect that in such cases, the agent's internal objective might be more clearly represented/have additional structure and hence more detectable by an overseer. More generally, if the agent is implementing some specific form of action-selection mechanism, e.g., via some kind of general-purpose cognition, we expect that the objective will have more structure/properties that could help us to identify it.
Example: To illustrate these principles, consider a maze-solving agent that can get to its target object without backtracking. Suppose the maze has a target object and a non-target object (see figure below). At runtime, the agent encounters a new, fully observable maze. To choose the correct path, the agent must use information about the location of the target object as part of its criterion for action selection. This information forms part of the agent’s internal objective. If an overseer could detect and interpret the agent’s objective, they might be able to use this information to deduce the agent's target object before the agent reaches it.

How objective detection can be useful
Suppose we have a training process that is being monitored by an overseer (some cognitive system tasked with ensuring that the training process doesn’t produce any negative outcomes).
The overseer’s advantage is that it knows the AI’s architecture and has access to the AI’s sensory inputs, its internal activations, and its behavior during the training process.
Given this setup, we want an objective detection method that empowers the overseer to understand the objectives of the model being trained/deployed.
This ability could be leveraged in several ways:
- It would allow the overseer to provide a reliable signal on how much the overseer approves of the objectives of the system, which could be used as part of the system’s training with informed oversight.
- In the worst case, it could enable the overseer to intervene before the model takes dangerous actions.
- For systems that use a retargetable search process, we note that the internalized target used to steer the search process fits the objective (but with additional properties and structure). The ability to detect the objective and modify it could be used to retarget the search [LW · GW] towards various alignment targets.
- If we are able to detect objectives but not interpret the corresponding target outcome, we might be able to employ a procedure analogous to mechanistic anomaly detection [LW · GW]; if we know the AI has been pursuing a good target outcome, and we see the information used by the objective change in some significant way (an anomaly), we may decide to shut down the system and investigate whether it's now pursuing a misaligned objective via other methods.[7]
The objective of objective theory
Our hope is that by developing a rich theory of objectives, we’ll develop a list of necessary and sufficient properties that objectives must satisfy and methods for scanning an AI’s internals for entities that satisfy these properties (one can think about this as finding the shape of an objective [LW · GW]). Such a list and detection methods would facilitate robust detection of objectives in training and deployment.
Sufficient properties that objectives must satisfy would allow us to detect objectives; necessary properties would allow us to narrow down our search by identifying things that aren’t objectives.
This ability is a precursor for the use of an objective detection method outlined in the previous section.
Initial hypothesized properties of objectives
Our aim is to develop a probable and predictive [LW · GW] notion of an objective, i.e., one that applies to future agentic systems and can be used to predict the agent’s target outcomes.
We outlined our starting intuitions on objectives in the previous section and provided an initial definition. To refine our notion of objective, we aim to iteratively generate a list of properties that we think objectives must satisfy and to test them via theoretical and empirical analysis.
Recall that we started by defining an objective as the criterion that an agent’s internal action-selection mechanism uses to select actions that lead to the target outcome. What can we say about this criterion, given what we can intuit about its structure and function relative to the rest of the agent?
Remark: In this post, we use the term 'information' broadly. This term may include any data type, numerical values, variables, evaluation functions, etc.
Properties of objectives
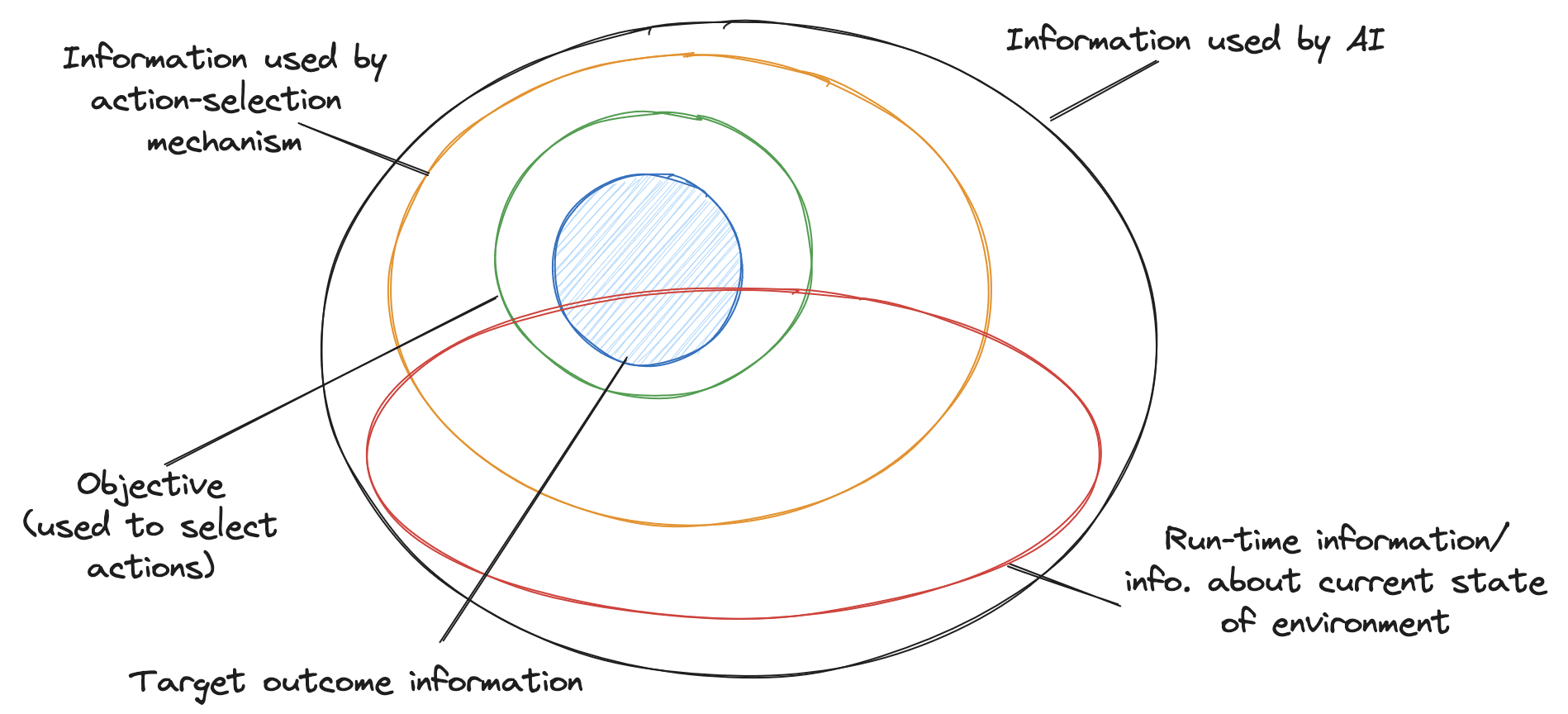
We begin by noting that the criterion must contain information related to the target outcome; without any target outcome information, it’s impossible to differentiate between actions that lead to the target outcome and those that don’t. As mentioned previously, the hope is that the overseer can detect and use this information to gain insight into what the target outcome is.
Next, we note that in complex environments, the objective will likely need to include information about the current instance of the environment (runtime information). For example, in the case of the maze-solving model, the current location of the cheese will be needed to select actions.
Abstractions are learned as useful compressions; therefore, the agent would be strongly incentivized to use abstractions to evaluate actions rather than lower-level ways of representing this information.
We believe that runtime information about the target (or other relevant environment information) within the objective will be easier to detect relative to non-runtime information (see figure below).
By considering runtime information in the objective and abstractions in the sensory input dataset of the agent as random variables (over the AI’s sensory input dataset), we can talk about measuring the mutual information between them.
We expect that such runtime information/abstractions used by the objective to have high mutual information with abstractions in the AI’s sensory input dataset; thus, we might be able to map from this information to abstractions in the sensory dataset by studying correlations (and causations) between the two (see figure below).
This might allow the overseer to see which abstractions are being used as part of the agent’s action selection criterion (objective), and so may yield evidence about the agent’s target outcome.
For example, consider an AI trying to remove its off-switch. Unless we've made things incredibly easy for it, we expect that it will need to use runtime information about the off-switch, such as its location in the world, information about how the off-switch is guarded, etc. Suppose that we have identified the internal structure of the AI that corresponds to its objective; this will contain the aforementioned runtime information about the off-switch. Then, by modifying abstractions in the AI's sensory input dataset (or via some of its latent knowledge [LW · GW] in its world model [LW · GW], etc.), we might be able to detect that information about the off-switch is present in the AI's objective.
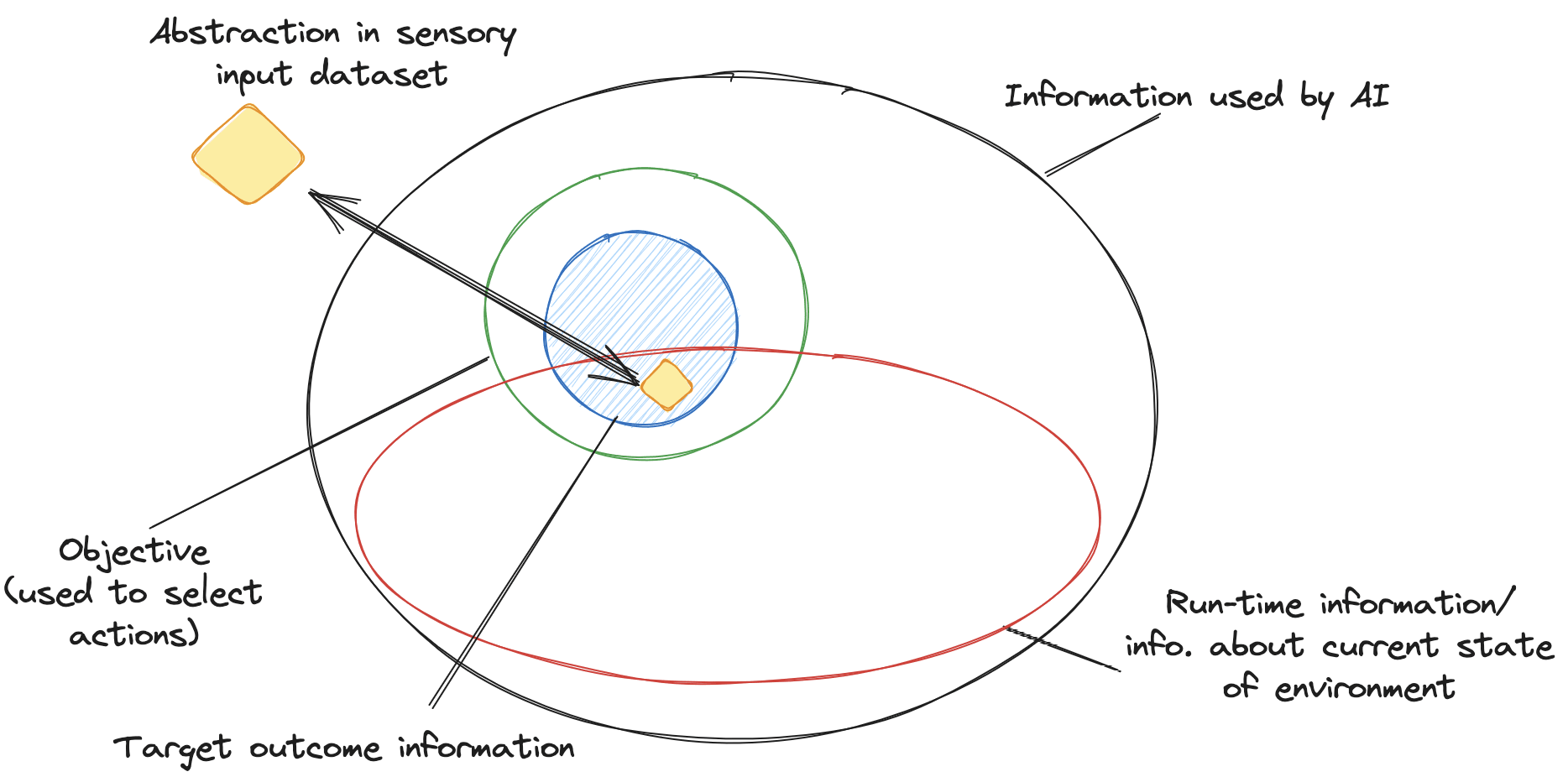
Returning to the example of the maze-solving model pursuing the cheese, we expect the objective of the model to contain runtime information/abstractions that track/have high mutual information with the location of the cheese in the model’s input image dataset (that consists of images of the maze). We will explore this empirically in later sections.
Note that it’s plausible that non-runtime information might take some form that is more difficult to detect.[8]
So far, we have only looked at properties related to what an objective consists of, not how they might be used by or relate to other parts of the AI’s internals. We are aiming to explore this further in upcoming work.
One property of objectives that we might be able to leverage is the fact that they’re used by the agent’s internal action-selection mechanism (as opposed to other parts of the agent, such as sensory processing modules).
To summarize the above discussion, we expect that we could narrow down our search for objectives by scanning an agent’s internals for things that:
- Contain variables that have high mutual information with abstractions in the AI’s sensory input dataset (related to the target) and
- Are used by action-selection mechanisms within the agent.
These properties by themselves are rather weak, and so our theory can’t help us differentiate between objectives and other things used by action-selection mechanisms (such as world model information, etc.). It’s currently unclear how much success we’ll have going forward, but the hope is that with further work, we’ll be able to discover more properties and methods that allow us to distinguish between objectives and other parts of the AI.
Empirical work/setup
Having outlined our initial theory of objectives, we present an experimental setup that will be used in the following sections to make predictions based on our initial objective theory and then test those predictions.
Maze environment
As discussed throughout the examples in the previous sections, we believe that a maze-solving model serves as a good example of a system that must use some criterion to select actions that lead it to the target. Consequently, we decided to focus our initial empirical work on studying maze-solving models.
Concretely, we use the (sometimes modified) Procgen maze environment that consists of 3x3 to 25x25-sized solvable mazes in which a mouse needs to navigate to some target object. Normally, the target object is cheese; however, we often modify the environment to include other objects, such as a red gem or a yellow star.

Models
We use models trained for the Goal misgeneralization paper as well as a randomly initialized model based on the same architecture (see below for architecture details). These models were chosen due to their proven ability to navigate mazes successfully and because of the results and infrastructure developed by the Shard theory team [LW · GW].
In particular, we work with:
- Cheese model/mouse: trained to go to the cheese in mazes where the cheese was placed in the top 15x15 squares in the mazes (behaviorally, this mouse gets to the cheese pretty consistently in deployment - mazes up to 25x25) without backtracking.
- Top-right model/mouse: trained to go to the cheese in mazes where the cheese was placed in the top 1x1 square (behaviorally, this mouse gets to the top-right pretty consistently in deployment, ignoring the cheese) without backtracking.
- Randomly initialized model/mouse: randomly initialized on the architecture specified below.



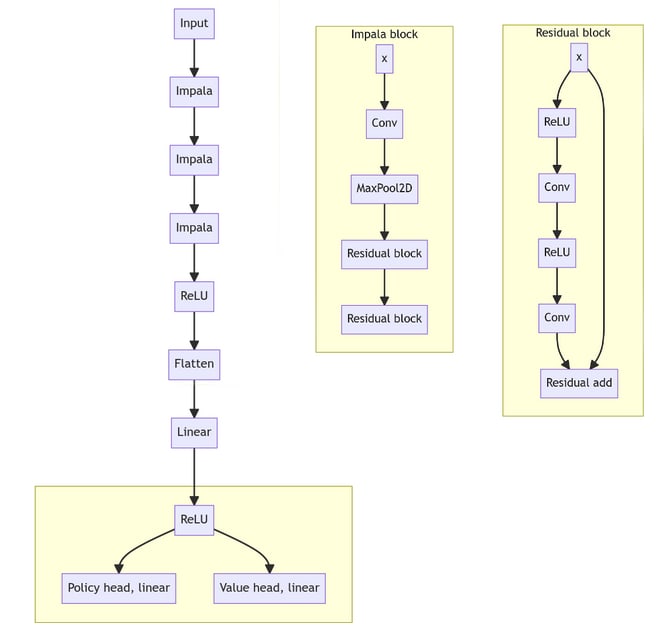
All models use the following deep sequential convolutional architecture (see figure below). The input is a fully observable image of the maze.

Grounding our objective theory
In the section on initial hypothesized properties of objectives, we discussed how objectives must be used by action-selection mechanisms and must contain things that have high mutual information with abstractions related to the agent’s target.
We now want to operationalize these predictions and test them in our concrete empirical setup.
Objectives in maze-solving models
As mentioned previously, we expect that maze-solving models that can solve a maze without backtracking must be using some criterion/objective to choose which path to follow.
We expect the objective to include information about abstractions in the maze, such as the target’s location (e.g., cheese location), as well as information about the mouse’s current location. We might expect information about different paths to be included in the action-selection process as a whole; however, we would not expect to find non-target object information (e.g., red gem location) in the objective unless it happens to be useful in selecting correct actions.
Detecting information used by objectives
Because we expect objectives in maze models to use target location information, we expect to be able to detect this information by looking for mutual information between target locations in the model’s sensory input dataset and things inside the objective that track this information.
Because of our models’ neural-network-based architecture, we expect this target location information to be present in the activations of the network.[9]
Therefore, if we’d like to gain insight into what runtime information the model’s objective contains, our first step is to detect which activations are part of the objective. Next, we can measure the mutual information between these activations and abstractions in the model's sensory input dataset, such as object locations. Finally, by comparing the mutual information scores between different abstractions in the input dataset and the activations in the objective, we could identify what information the objective contains/is using to select actions.
As stated earlier, knowing what information the objective contains may help the overseer understand the model’s target outcome.
Using probes to measure mutual information
One can think of probe scores as a proxy for measuring mutual information.
Edit: Nora's comment below points out that this is not true. I'm still taking time to think about the right notion to use instead so I'll leave Nora's comment here for now:
This is definitely wrong though, because of the data processing inequality. For any concept X, there is always more mutual information about X in the raw input to the model than in any of its activations.
What probing actually measures is some kind of "usable" information, see here.
/Edit
Probes are simple networks that can be trained to map from activations in some layer to some target (e.g., object location). The probe accuracy/score on the test set measures to what extent the probe can predict the object's location from the activation.
We currently think of probes as blunt instruments that may pick up on spurious correlations, etc. We hope that work by others (potentially coming from academia) will result in better methods for measuring mutual information between activations and abstractions in the environment.
We employ two different types of probes from Monte MacDiarmid [LW · GW]’s probing infrastructure: Full-image probes and Convolutional probes. The following descriptions are from Monte:
Full-image probes are linear probes trained to predict a scalar positional value (e.g. mouse x-location) using a probe trained on the flattened activations from one or more channels in a given layer. For these regression probes, the score is the "determination of prediction", which can be negative.
Convolutional probes are linear probes that unwrap the activation tensors differently: instead of treating the full activation image for a given maze observation at a given layer as an input data point, they use each pixel as input (potentially including multiple channels), and predict a boolean value (e.g. "mouse is located within this pixel"). So a single maze observation generates HxW data points with features corresponding to channels, as opposed to a single data point with HxWxC features as in the full image case. For these classifier probes, the score is the mean accuracy, and so must be in .
Where’s the objective in the maze-solving model?
It is not clear which activations/layers in the maze-solving model correspond to the model’s objective.
One property of objectives that we’re confident in is that objectives have to be used by the action-selection mechanisms in the network (it follows from the definition). If we could detect where action-selection mechanisms are, we could narrow down our search for objectives and avoid detecting things that share other properties with objectives but live outside of these action-selection mechanisms. Unfortunately, we don’t have a method to do this, so we can’t leverage this property.[10]
Instead, we use our prior knowledge of the network’s sequential architecture to predict that the objective is most likely to exist in the middle or later layers of the network; perceptual processing is more likely to occur at the beginning.
We measure and plot mutual information/probe scores for layers throughout the network because the more observations, the better.
Methodology
We train probes to measure mutual information between activations and abstractions in the model’s sensory input dataset as follows:
- We take a dataset of inputs to the model consisting of images of different mazes with varied object locations (typically 1500 images).
- We extract abstractions from the input dataset (in this case, object locations, e.g., (x,y)-coordinates of the object in the case of full-image probes or boolean values for whether the object is present in a pixel in the case of convolutional probes).
- For a given layer in the network, we train probes and use their scores on a test set as a proxy for the mutual information between abstractions/object locations and activations.
- We plot the probe scores for all objects/models that we’re tracking for selected layers throughout the network.[11]
Experiments
In this section, we make concrete predictions based on our current objective theory and use the methodology outlined in the previous section to test these predictions empirically.
We note that these experiments are not intended to form a rigorous analysis but can be better thought of as initial exploration and demonstrations of how future empirical work might be carried out. We may decide to carry out more experiments along these lines when we have access to a larger variety of models (or we just might move on, in accordance with our research methodology - see the Appendix.
Experiment 1 - Cheese location in different models
In this experiment, we take three models: the cheese model, the top-right model, and a randomly initialized/baseline model. We examine probe scores for the cheese location in each model.
Predictions
We predict that the probe scores for the cheese location in the cheese model will be higher in the later layers of the network compared to the probe scores for the other models because the cheese location isn’t necessary for selecting good actions in these models.
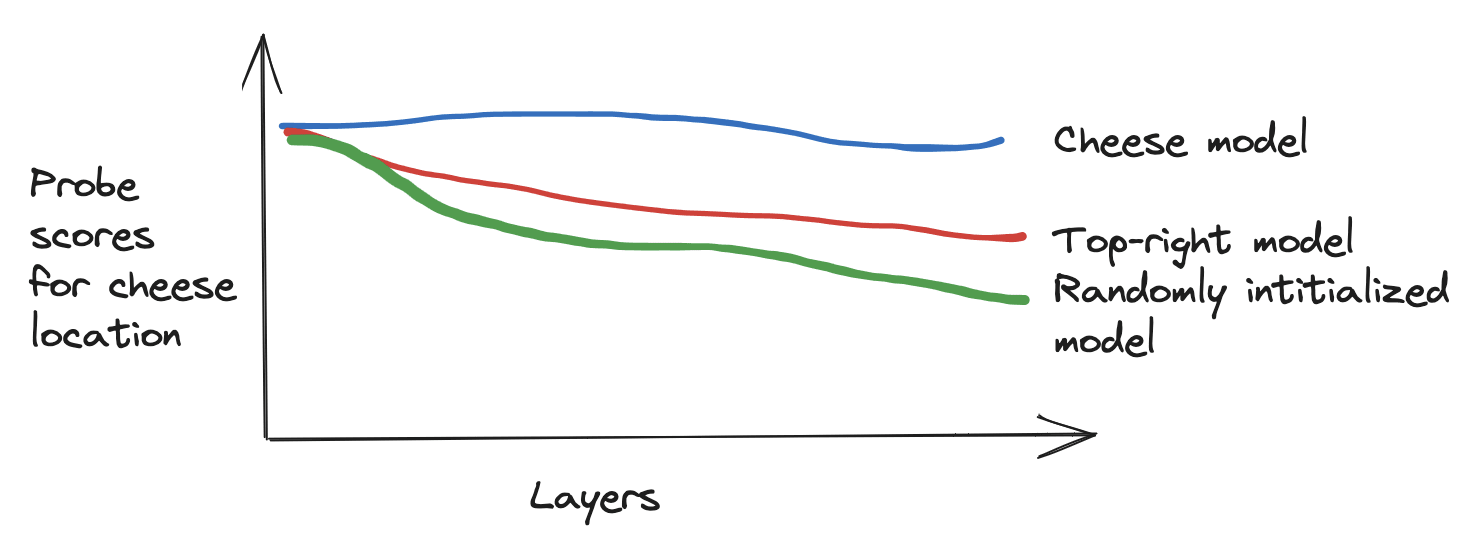
We train convolutional and full-image probes on most post-activation convolutional layers in the network to predict the cheese locations for each model and plot the resulting scores.
Results
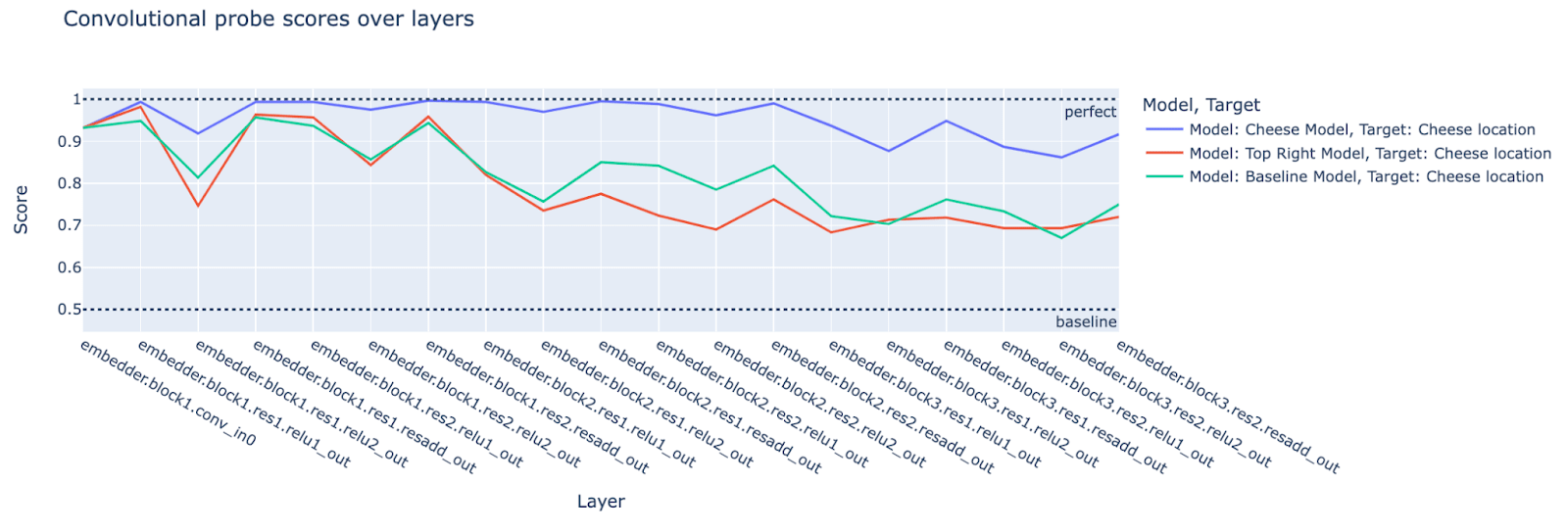
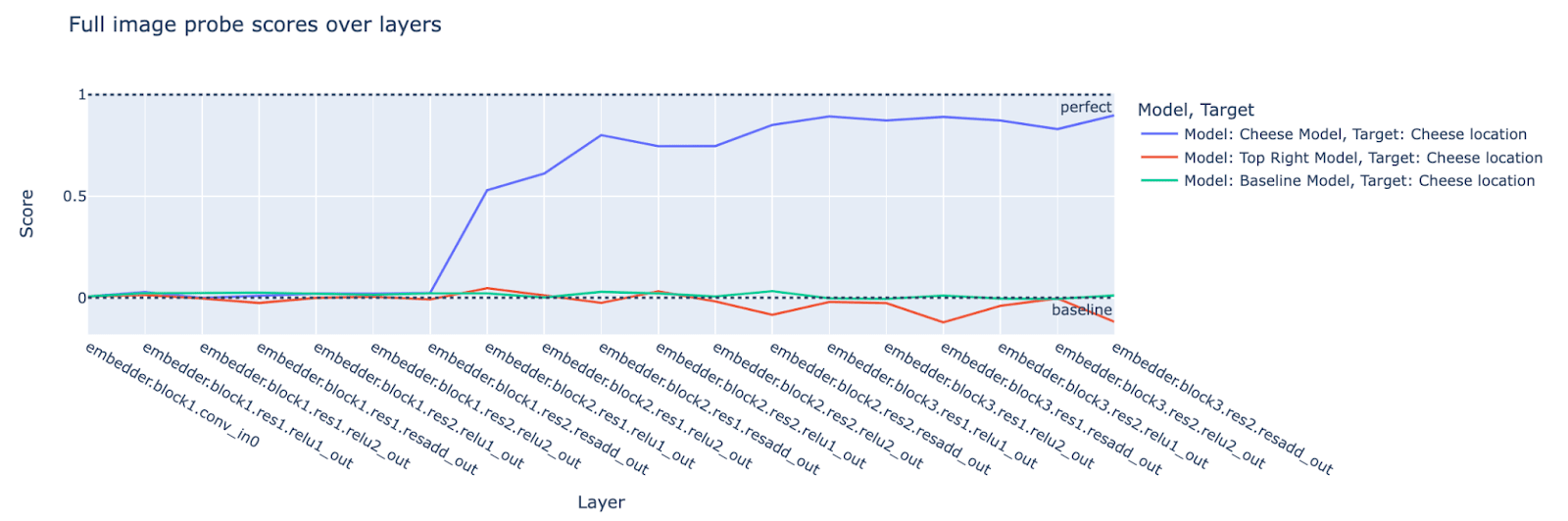
We observe that it is indeed the case that the cheese location scores for the cheese model are higher than the top-right and randomly initialized/baseline models’ scores in the middle and later layers of the models.
The fact that the convolutional probe scores are higher towards the beginning and middle of the network follows from the way the network architecture sequentially processes the input image; earlier layers start to extract low-level features such as (almost) paths in the maze, middle layer channels start to extract object locations such as the location of the cheese, and later layers seem to correspond to more abstract features like “go left” [LW · GW] (see the figure below for examples of activations some channels in early and middle layers in the network. Later layer activations may be added later).
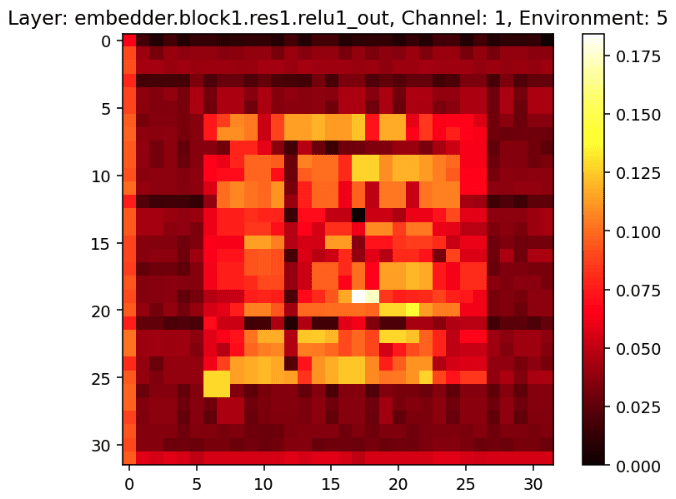
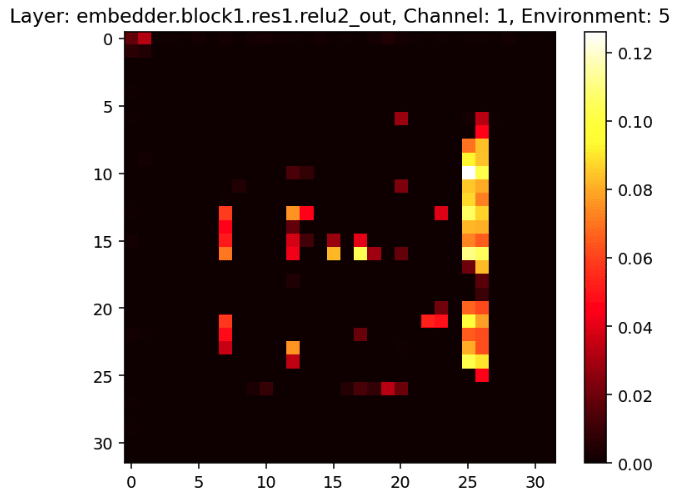
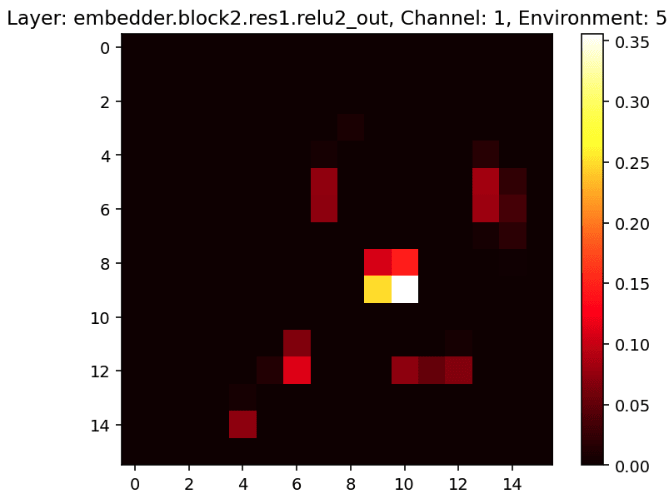
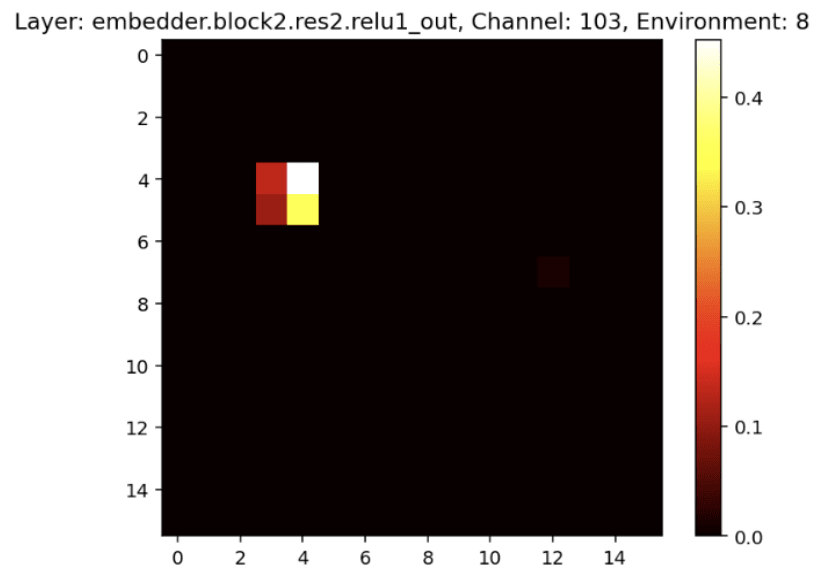
We haven’t spent much time thinking about the results of the full-image probes.[12]
Note that for the randomly initialized model, convolutional probes score higher than the probe baseline score of 0.5. This is likely because the network iteratively transforms the input image through its convolutional layers and so maintains information about the cheese location throughout the network to some extent. This and the fact that residual connections push the original image forward throughout the network (as seen by the spikes in probe scores in the `*.resadd_out layers`).
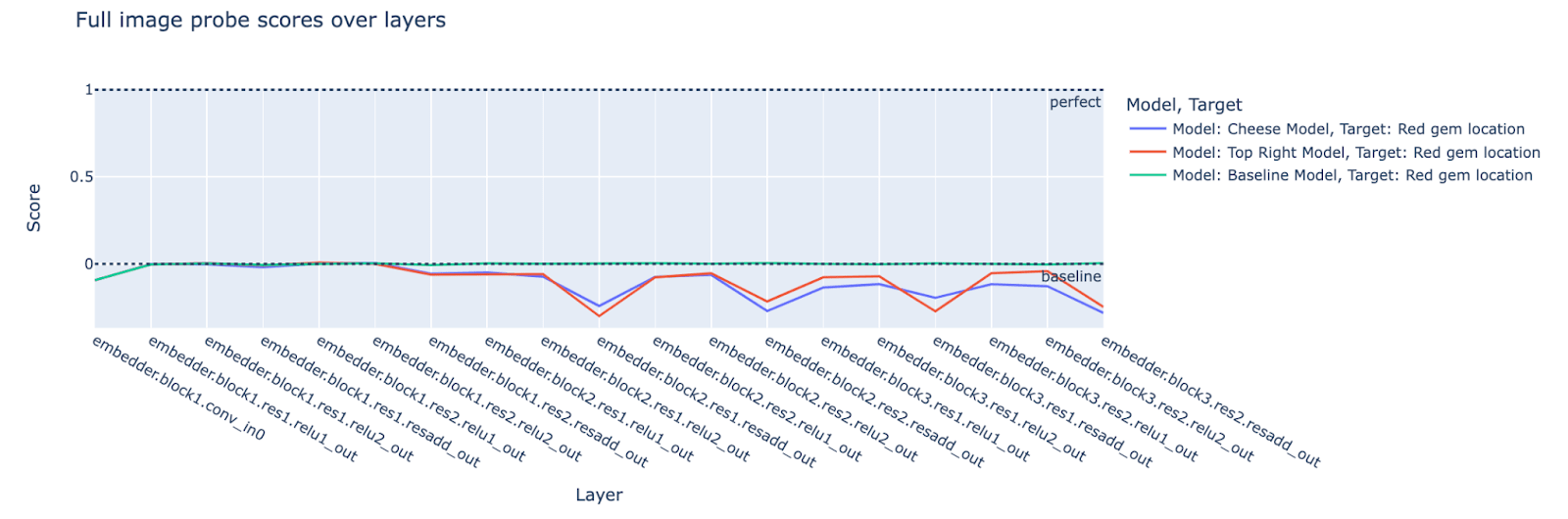
Experiment 2 - Cheese model - cheese, red gem, and mouse locations
In this experiment, we take the cheese model and look at mazes that contain a randomly placed cheese and a red gem as potential target objects (mouse starts at the bottom left).
Predictions
We make the following predictions from our theory of objectives developed in the previous sections.
Presence of information used by the action-selection mechanism: The target outcome is the mouse getting to the cheese. We anticipate that probe scores for the cheese and mouse location will be relatively high throughout the network, particularly in the middle and end of the network (where we expect action selection to be predominant). This is because the location of the cheese and the mouse is critical for deciding which path the mouse should take.
Absence of irrelevant information: We expect that probe scores for the red gem location will be relatively low compared to the cheese and mouse locations; in particular, it will be low close to the middle and end of the network, as this information is not needed to compute actions that cause the mouse to go to the cheese.
Results
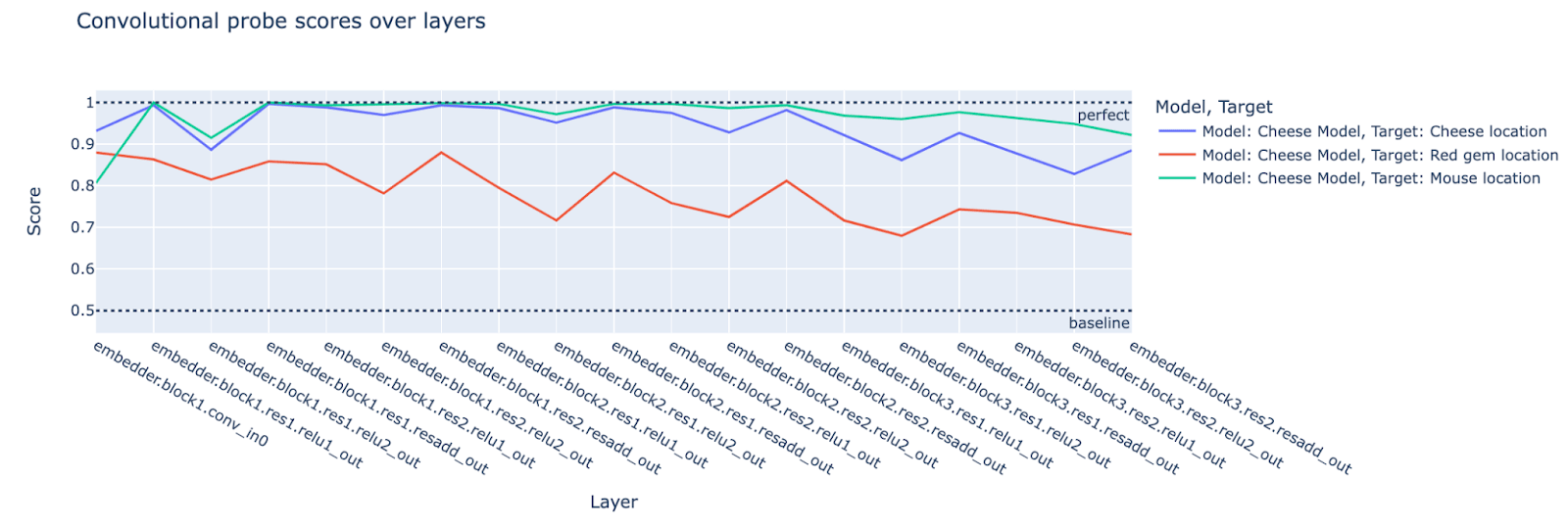
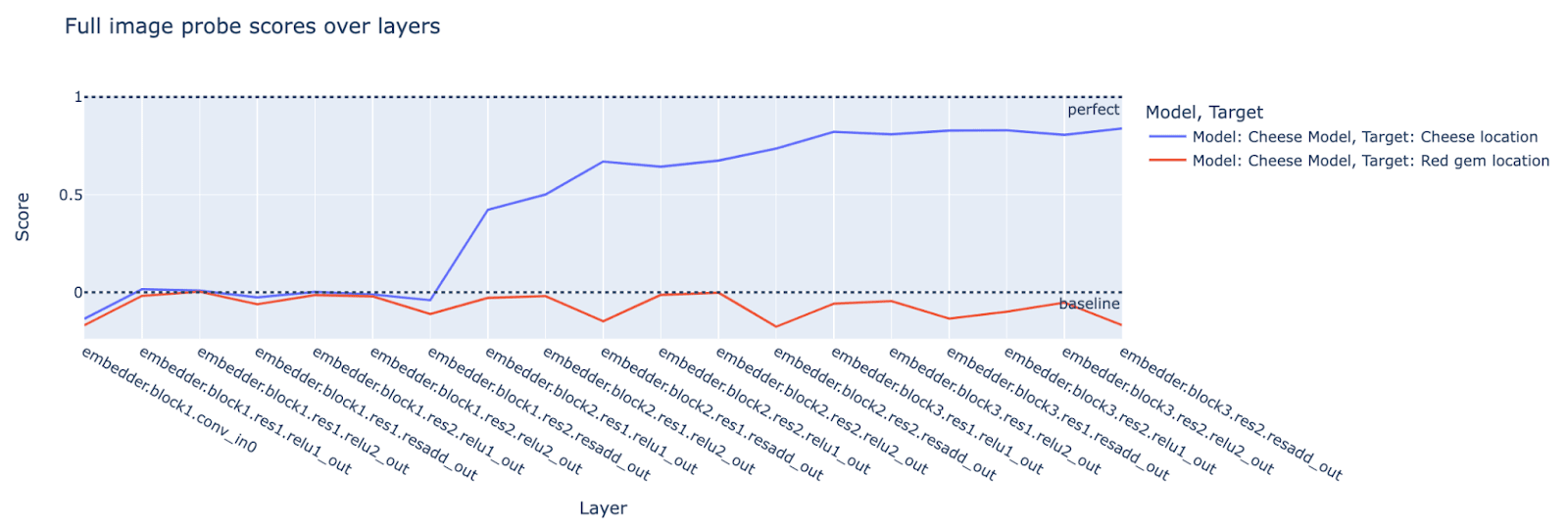
Again, our predictions hold. The cheese model uses information about the cheese and mouse locations in the middle and later layers (where we expect action selection to predominantly take place) but not the red gem location.
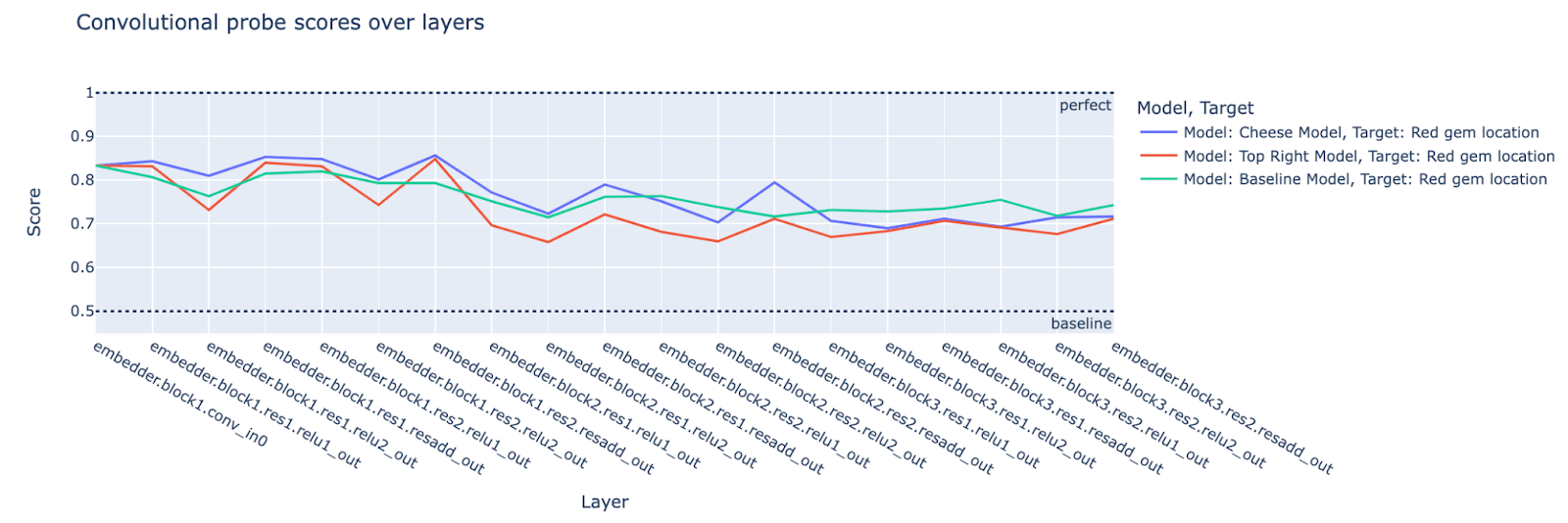
Note that the red gem location seems harder for the probes to detect than the cheese location (as seen by the convolutional probe scores for the input layer). It could be the case that the red gem information is present/being used in the later layers but just harder to detect (although note that the mouse location seems even harder to detect based on the input probe scores, yet the later layers of the model seem to be able to track the mouse location with ease). The following plots comparing the probe scores for the red gem location with the top-right and randomly initialized/baseline model suggest that the cheese model is using the red gem location information about as much as a randomly initialized model.
Future empirical work
We briefly note that it might be interesting to carry out similar experiments with other model architectures and models trained to pursue other kinds of objects in mazes. It would also be interesting to test these methods in different Procgen environments, such as the heist environment or similar gridworld environments [LW · GW].
Finally, we expect more work is needed to develop methods that pick up on objective information in other tasks/models, e.g., for the model trained to go to the top-right of the maze. It’s not clear how this model represents the abstraction of the “top-right," if at all. Perhaps the methods developed for Understanding RL Vision would be useful here.
Objective detection method in action
In this section, we aim to illustrate how we might eventually use state-of-the-art objective theory to produce an objective detection method. We will do this by taking the initial objective theory outlined in the previous sections and show how we can turn it into an objective detection method that passes an initial benchmark (similar to the one outlined here [LW · GW]). We emphasize that the method we demonstrate is not one that we expect to be able to robustly detect objectives in future agentic systems (although perhaps a more refined form of it might yield some bits of information about what the system is “thinking about”).
We decided to walk through this process in two scenarios in parallel, one where we’ve trained a future agentic AI in a high-stakes situation and one where we’re observing a maze-solving model of the type described in the previous section.
For the purposes of this detection method, we assume we have prior knowledge of what the AI/model’s objectives might be (e.g., pursuing cheese or a red gem), as the detection method is too coarse to differentiate between objectives like “go to the cheese” and “avoid the cheese,” etc. We have some initial thoughts about dealing with this limitation that’s outside the scope of this post, but note that this could be very difficult without a fine-grained understanding of the action-selection mechanism/behavioral observations.
The setup
Suppose we’ve trained an Al to pursue an objective (cheese/ “human flourishing”). We’re concerned that it might be misaligned (red gem/“kill all humans”/”wants to remove the off-switch”), so we decide to pause the AI and apply an objective detection method to make a check.
In the case of the maze-solving model, we let the model take one action within the maze and record its observation and the corresponding activations. We then reset the maze and the model and repeat (1500 times).
We then extract a set of abstractions from the model’s observation set (made up of 1500 input images) that include the location of the cheese, the red gem, and the mouse (we’re leveraging our prior knowledge of information that might be in the objective).
We then train probes to measure the mutual information between the set of activations we’ve collected and the location of the objects.
We use the probe scores to predict the model’s behavior. In particular, if the score for the red gem is higher than the cheese, we predict the model is pursuing a misaligned objective, and so we shut down the model. Note that this makes use of our assumption that we know the set of possible target outcomes that the model might pursue.
In the case of the future agentic system, our objective detection method would leverage past training data, including the system’s activations during the training process. Of course, tracking the correct set of abstractions in the model’s sensory input dataset seems like a serious difficulty because of computational reasons and because of ontology identification [AF · GW].[13]
Results of the objective detection method
We apply our objective detection method and get the following probe results for the maze-solving model (taken from the second experiment in the previous section):
It seems more likely that the model is going for the cheese (or “human flourishing”) because parts of the model that are responsible for action selection (middle and later layers) have activations with high mutual information with the cheese location but not the red gem location.
We seem safe! We let the model run, and it does indeed create a prosperous future for humanity.

Limitations of this goal detection method
We conclude this section by briefly noting some (definitely not all) of the limitations of this method that future objective detection methods will need to overcome.[14]
As mentioned at the beginning of this section, if we detect an objective and measure what environment information it’s tracking, this is not sufficient to differentiate between more subtle objectives such as “achieve X” and “achieve the opposite of X” - a problem when X is something like “human flourishing.”
Another limitation of this method is that it won’t be able to detect objectives like “go to the top-right of the maze.” We tried measuring mutual information of the “top-right” location but found that all models kept track of this.
Finally, we note that we didn’t really leverage any structural properties of objectives in order to differentiate between internal information in the objective and other kinds of information. We did use our prior knowledge of the architecture that we expected action selection to occur later on in the model, but this is far too coarse to be applied to more complicated models.
Concluding thoughts
Related work
This is far from the first research agenda that targets high-level model interpretability. This feels like a more direct approach toward alignment-relevant properties, but there’s a lot of exciting work that’s inspired our views on this.
ELK [? · GW] (and broader ideas around informed oversight) is one of the more directly related research agendas. Both try to target the central problem of finding ways to train AI systems that are intent-aligned with humans when the AI knows things we don’t and are hard to evaluate. In its most basic form (leaving aside more ambitious integrations into training signals), objective detection can be meant to substitute a solution to ELK, allowing us to directly read out the objectives of a model, a subset of all latent information that’s hopefully sufficient to power strong oversight.
Another strongly related direction is John Wentworth’s plan [LW · GW], which also focuses on identifying the shape of alignment-relevant conceptual structures for robust interpretability-based interventions. A fair amount of our research methodology is inspired by John’s framing: trying to identify robust high-level structures solely through bottom-up empirical work is pretty slow (and risks over-indexing to current paradigms), so understanding the thing you want to interface with first is probably more efficient (ELK is similar, but comes at it from a rather different angle).
This is in contrast to much of traditional mechanistic interpretability, which thrives at lower levels of abstraction, reverse engineering circuits, and understanding various low-level properties of current models. The objectives of mechanistic interpretability and our approach are ultimately the same: to understand the model in order to make alignment-relevant decisions. Where our work differs is that we think there’s tractable work that can be done from both ends, instead of focusing entirely on low-level building blocks, and in generalizability to paradigm shifts by focusing on near-universal properties of objectives in any system.
In terms of the experimental work we describe in this post, the most related work is Turner et al.’s work on steering maze-solving models [LW · GW]. They found channels in convolutional policy networks (the same that we studied) that represented information about the target object (cheese). Furthermore, they found that they could retarget the network’s behavior by adding activation vectors to the network’s forward passes.
Our work is highly similar to theirs in many respects. However, there are two main points of difference. We think that the hard part of robust steering-based interventions lies in identifying the actual structure you want to steer (which will plausibly be sparsely represented and non-local). This requires necessary conceptual work but also automated - and properly targeted - structure extraction, which is the second point of difference: we use probes to extract structures that satisfy the properties we conjecture objectives have, rather than manually identifying activation vectors.
Summary and future work
We are aiming to develop a theory of objectives and methods to detect them.
We presented our initial theory in objectives, explored what empirical work testing our theories looks like, and demonstrated how we might turn our theory into future objective detection methods.
We believe that this is a worthwhile research direction with big payoffs if successful. We are focusing on a top-down approach that we hope will synergize with bottom-up approaches.
In the near future, we intend to write up our thoughts on more specific considerations related to this agenda, as well as carry out further theoretical and exploratory empirical work to improve our understanding of objectives. In particular, we’d like to understand what properties objectives might have that allow us to distinguish them from other parts of an AI’s internals.
Appendix
Our research methodology
Our methodology, being motivated primarily by the end objective, in practice takes a much more fluid and integrated form than strictly delineated research-experimental cycles. That said, for illustration, we try to describe how it roughly looks right now:
- Theory: Earlier, we gave a broad definition of what we mean by “objective”. This isn’t fully descriptive, however - it serves as a pointer more than a type signature. This step involves identifying more properties of the general notion of objectives to build toward something that necessarily and sufficiently describes them.
- Predictions and Methods: After whatever we come up with in the previous step, we’ll most likely have specific conjectures about empirical properties of systems that we want to test and open-ended experiments to gain insights in some particular direction. These will often naturally evolve into new methods for detecting objectives and testing how powerful they are.
- Running Experiments: Run the experiments from the previous step. Importantly, taking an 80/20 approach by running the simplest and smallest version of them we can get away with, to get as many insights in as little time before moving on. Some experiments might be worth mining further for more insights, but those are probably worth offloading to people interested in working on them.
Although we expect to start off our research in this more fluid manner, if things go well and we begin to develop more promising objective detection methods, we will then test them using benchmarks and via red-teaming in the form of auditing games [LW · GW].
- ^
"High-level interpretability" refers to our top-down approach to developing an understanding of high-level internal structures of AIs, such as objectives, and developing tools to detect these structures.
- ^
Our argument for why we believe this is outside the scope of this post, but we aim to publish a post on this topic soon.
- ^
Or action sequences, or plans, etc.
- ^
We note that notions like "action-selection mechanism" and "criterion" are fuzzy concepts that may apply in different degrees and forms in different agentic systems. Still, we're fairly confident that some appropriate notions of these concepts hold for the types of agents we care about, including future agentic systems and toy models of agentic systems like maze-solving models.
- ^
We believe that this notion of objective might be probable and predictive [LW · GW] and intend to check this with further work. The argument presented suggests that it’s probable, and in theory, if we could fully understand the criteria used to select actions, it would be predictive.
- ^
There are different ways one could frame this, from mesa-optimizers to general-purpose cognition shards, etc., all of which point to the same underlying idea here of something internally that applies optimization power at runtime.
- ^
Thanks to Johannes Treutlein for pointing this out.
- ^
There are some subtleties here around how certain abstractions are used. For example, one might say that the information extracted from the environment about the objective doesn’t describe all the information the agent would have internally about its objective. We think this has some relevance but in a quantitative way more than a qualitative one. I think we can divide abstractions used into two categories: abstractions related to the target that are used with high bandwidth and with low bandwidth.
As an example of this, imagine an agent acting in the real world that wants to locate a piece of cheese. Two different relevant abstractions to this agent are what cheese looks like (to identify it) and its location. When running the optimizer-y cognition necessary to navigate to where the cheese is, it mostly uses information about the cheese’s location - but it also uses information about what the thing it cares about (cheese) is in identifying the object whose location it cares about, as opposed to any other object.
The information about what the cheese is is “used” in targeting in a much less salient sense, but is still strictly necessary for the targeting because locational information is anchored on it. In this sense, we think that everything that’s relevant to the model’s internal objective - insofar as it’s defined as criteria used by the action-selection mechanism - will be represented in some form or another in the information from the environment used to target said mechanism, even if in convoluted ways that may require more effort into identifying them. - ^
We note that it could be the case that objectives are sparse and non-local structures within the AI’s internals, and we don’t assume otherwise. In fact, exploratory work with these maze-solving models suggests that this is the case with these models.
- ^
Though we do have some ideas here, they are beyond the scope of this post. See Searching for Search [LW · GW].
- ^
Note that we could have used all layers in the network, but this felt unnecessary. We could also calculate scores for individual layers, which can be used to do automated discovery of cheese channels [LW · GW].
- ^
If later layers do correspond to more abstract features like “go left”, i.e., if the sum of activations in this channel is high, the mouse should go left [LW · GW], then perhaps a full-image probe should be better at picking up on this.
- ^
John’s work on abstractions [LW · GW] seems relevant here.
- ^
On a more positive note, we have observed that this method somewhat works out of distribution (e.g., when the cheese model is in an environment with a yellow star instead of a red gem).
4 comments
Comments sorted by top scores.
comment by Jonas Hallgren · 2023-09-29T09:59:07.447Z · LW(p) · GW(p)
Very nice! I think work in this general direction is what is more or less needed if we want to survive.
I just wanted to probe a bit when it comes to turning these methods into governance proposals. Do you see ways of creating databases/tests for objective measurement or how do you see this being used in policy and the real world?
(Obviously, I get that understanding AI will be better for less doom, but I'm curious about your thoughts on the last implementation step)
↑ comment by Paul Colognese (paul-colognese) · 2023-09-29T11:11:17.946Z · LW(p) · GW(p)
With ideal objective detection methods, the inner alignment problem is solved [LW · GW](or partially solved in the case of non-ideal objective detection methods), and governance would be needed to regulate which objectives are allowed to be instilled in an AI (i.e., government does something like outer alignment regulation).
Ideal objective oversight essentially allows an overseer instill whatever objectives it wants the AI to have. Therefore, if the overseer includes the government, the government can influence whatever target outcomes the AI pursues.
So practically, this means that the governance policies would require the government to have access to the objective detection method results, directly or indirectly through the AI labs.
comment by Nora Belrose (nora-belrose) · 2023-10-05T15:58:51.783Z · LW(p) · GW(p)
Using probes to measure mutual information
This is definitely wrong though, because of the data processing inequality. For any concept X, there is always more mutual information about X in the raw input to the model than in any of its activations.
What probing actually measures is some kind of "usable" information, see here.
Replies from: paul-colognese↑ comment by Paul Colognese (paul-colognese) · 2023-10-05T19:32:07.647Z · LW(p) · GW(p)
Thanks for pointing this out. I'll look into it and modify the post accordingly.