World-Model Interpretability Is All We Need
post by Thane Ruthenis · 2023-01-14T19:37:14.707Z · LW · GW · 22 commentsContents
1. Introduction 1A. Why Aim For This? 1B. Is It A Realistic Goal? 2. Would World-Models Look Like We Imagine? 2A. Are World-Models Necessary? 2B. How Are World-Models Useful? 2C. Are World-Models Unitary? 2D. Are World-Models Modular? 3. World-Model Structure 3A. Major Sub-Modules 3B. Abstractions As Basic Units 3C. Higher-Level Organization 3D. Laziness 4. Research Directions None 22 comments
Summary, by sections:
- Perfect world-model interpretability seems both sufficient for robust alignment (via a decent variety of approaches) and realistically attainable (compared to "perfect interpretability" in general, i. e. insight into AIs' heuristics, goals, and thoughts as well). Main arguments: the NAH [LW · GW] + internal interfaces [LW · GW].
- There's plenty of reasons to think that world-models would converge towards satisfying a lot of nice desiderata: they'd be represented as a separate module in AI cognitive architecture, and that module would consists of many consistently-formatted sub-modules representing recognizable-to-us concepts. Said "consistent formatting" may allow us to, in a certain sense, interpret the entire world-model in one fell swoop.
- We already have some rough ideas on how the data in world-models would be formatted, courtesy of the NAH. I also offer some rough speculations on possible higher-level organizing principles.
- This avenue of research also seems very tractable. It can be approached from a wide variety of directions, and should be, to an extent, decently factorizable. Optimistically, it may constitute a relatively straight path from here to a "minimum viable product" for alignment, even in words where alignment is really hard[1].
1. Introduction
1A. Why Aim For This?
Imagine that we develop interpretability tools that allow us to flexibly understand and manipulate an AGI's world-model — but only its world-model. We would be able to see what the AGI knows, add or remove concepts from its mental ontology, and perhaps even use its world-model to run simulations/counterfactuals. But its thoughts and plans, and its hard-coded values and shards [? · GW], would remain opaque to us. Would that be sufficient for robust alignment?
I argue it would be.
Primarily, this would solve the Pointers Problem [LW · GW]. A central difficulty of alignment is that our values are functions of highly abstract variables, and that makes it hard to point an AI at them, instead of at easy-to-measure, shallow functions over sense-data [LW · GW]. Cracking open a world-model would allow us to design metrics that have depth.
From there, we'd have several ways to proceed:
- Fine-tune the AI to point more precisely at what we want (such as "human values" or "faithful obedience"), instead of its shallow correlates.
- This would also solve the ELK [LW · GW], which alone can be used as a lever to solve the rest of alignment.
- Alternatively, this may lower the difficulty of retargeting the search [LW · GW] — we won't necessarily need to find the retargetable process, only the target.
- Discard everything of the AGI except the interpreted world-model, then train a new policy function over that world-model (in a fashion similar to this), that'll be pointed at the "deep" target metric from the beginning.
- The advantage of this approach over (1) is that in this case, our policy function wouldn't be led astray by any values/mesa-objectives it might've already formed.
- With some more insight into how agency/intelligence works, perhaps we'll be able to manually write a general-purpose search algorithm [LW · GW] over that world-model. In a sense, "general-purpose search" is just a principled way of drawing upon the knowledge contained in the world-model, after all — the GPS itself is probably fairly simple.
- Taking this path would give us even more control over how our AI works than (2), potentially allowing us to install some very nuanced counter-measures.
That leaves open the question of the "target metric". It primarily depends on what will be easy to specify — what concepts we'll find in the interpreted world-model. Some possibilities:
- Human values. Prima facie, "what this agent values" seems like a natural abstraction, one that we'd expect to find in the world-model of any agent that models another agent. The issue might be that humans are too incoherent and philosophically confused for their "values" to stand for anything concrete — e. g., we almost certainly don't have concrete utility functions [? · GW].
- An indirect pointer to human values. Even if the world-model would lack a pointer to "human values", already fully specified, there may be some pointer at "the process of moral philosophy", or whatever people are using to try to specify their values. If so, we may be able to task the AI with helping us complete this process, then optimize for that process' output.
- Corrigibillity. The hard problem of corrigibility suggests that it may, in some sense, be a natural concept/abstraction, not just an arbitrary list of limitations on the AI's actions. If so, we may find a concept standing for it in the AI's world-model, and just directly point the AI at it.
- Do What I Mean. Suppose that you "tell" the AI to do something (via natural language, or code, or by designing its reward function). The AI accepts that command as input, then "interprets" it in some fashion, translates it into its mental ontology, and acts on the result. If we can seize control over how the "interpretation" step happens — if we can make the AI interpret our commands faithfully, the way we intend them, instead of via some likely-misaligned "interpreter" module, or via their pure semantic meaning [LW · GW] — well, that would align it to the order-giver's intentions. That's potentially dangerous [LW · GW], but may be leveraged into a global victory from there.
- And it's almost certain that this target would be tractable. In this hypothetical, we've figured out how to do manual ontology translation (how to interpret an alien world-model). That likely means we have a mathematical specification of what "ontology translation" means. All we'd need to do is code that into the AI — tell it to correctly translate our orders from our ontology into its own!
- An oracle. Perhaps, if all of the above fails, we can use the world-model directly? Without a policy over it, it wouldn't be able to grow on its own, so it'd be stuck at the capability level at which we extracted it. But we'd be able to study it for novel insights [LW · GW], which may provide the missing pieces for the rest of the alignment problem.
- An even bigger win along this approach would be if the AGI is already highly reflective. That would mean there's a lot of self-knowledge stored in its world-model — how its mind works, what it cares about. In that case, we'd essentially get a manual on how to interpret the rest of its mind! Unfortunately, I think we shouldn't rely on that — AGIs that advanced are probably not safe to interpret [LW · GW].[2]
- (The stagnated capability growth may be a problem with approach (3) as well, where we manually design a synthetic GPS over the extracted world-model. But I expect it shouldn't be too difficult to code-in some way to improve the world-model as well — if nothing else, there'd probably be heuristics about that already in the world-model.)
1B. Is It A Realistic Goal?
Is there reason to think we can achieve perfect interpretability into an AI's world-model? Why go for the world-model specifically, instead of trying to focus on understanding the AI's plans, thoughts, values, mesa-objectives, shards?
I don't expect it'd be easy in an absolute sense, no. But when choosing from the set of targets that'd suffice for robust alignment, I do expect it's the easiest one.
As an established case for tractability, we have the natural abstraction hypothesis [LW · GW]. According to it, efficient abstractions are a feature of the territory, not the map (at least to a certain significant extent). Thus, we should expect different AI models to converge towards the same concepts, which also would make sense to us. Either because we're already using them (if the AI is trained on a domain we understand well), or because they'd be the same abstractions we'd arrive at ourselves (if it's a novel domain).
A different case is presented in my earlier post [LW · GW] on internal interfaces. In short:
- In every case where we have two complex specialized systems working in tandem, we can expect an "interface [LW · GW]" to form — a data channel for exchanging compressed messages.
- The data exchanged along such channels would follow some stable formats. Every message would have structure (the way human languages have syntactic structure, and API calls have strict specifications), reflecting the structure of the subject matter.
- The world-model specifically would need to interface with a lot of other modules [LW · GW] — with the shards, with the planner (the AGI's native GPS algorithm). All of these modules would need to know how to access any of the concepts in the world-model, which means these concepts would need to be consistently-formatted (with these formats stable in time).
- In addition, the world-model can itself be thought of as an interface — between the asymbolic ground-truth of the world and the rest of the agent. As such, there's reason to expect it to be nicely-structured by default.
- (In this framing, the natural abstraction hypothesis is a study of efficient interface-building between minds and reality.)
Crucially, if a world-model does follow consistent data formats, it should be possible to interpret it all at once. Instead of interpreting features one-by-one, we can figure out their encoding, and "crack" the world-model in one fell swoop.
By comparison, there's no reason (as far as I can currently tell) to expect the same consistent formatting for the AI's heuristics/shards/mesa-objectives. They'd have consistent inputs and outputs, but their internals? Totally incomprehensible and ad-hoc. Still interpretable in principle, but only one-by-one.
On this argument, there's another prospective target: an AGI's plans/thoughts. They'd also need to be consistently-formatted, since future instances of the AGI's planner process would need to access plans generated by its earlier instances. But there are fewer reasons to expect that, and their formats may be dramatically more complex and difficult to decode. In particular, the NAH may not apply to them as strongly — plan formats may not be convergent across humans and AGIs, or even across different AGI systems.
(Unduly optimistic possibility: Or it may be that plans would be formatted using the same formats the world-model uses. In which case "interpreting the world-model" and "learning to read the AGI's thoughts " solve each other. I wouldn't bet on that working out perfectly, though.)
In addition, consider that advanced AGI models would likely need to modify their world-models at runtime — perhaps via their native GPS algorithms. If so, we can expect advanced world-models to have built-in functionality for editing. They'd have functions like "add a new concept", "remove a concept", "chunk two abstractions together", "expand [LW(p) · GW(p)] a given abstraction", "propagate an update", or "fetch all concepts connected to this one", which should likewise be possible to reverse-engineer.[3]
As such, I think perfect world-model interpretability is a reasonable target to aim for.
2. Would World-Models Look Like We Imagine?
This section is a kitchen sink of arguments regarding whether world-models would satisfy a bunch of nice high-level desiderata.
Namely: whether they'd be learned at all, how they'd be used, whether "the world-model" would be a unified module (as opposed to a number of non-interacting specialized modules), and whether it'd have recognizable internal modules.
2A. Are World-Models Necessary?
That is, should we actually expect AIs to learn a module we can reasonably describe as a "world-model"? It seems intuitively obvious, but can we prove it?
The Gooder Regulator Theorem [LW · GW] aims to do just that. Translating it into the framework of ML, it essentially says the following:
Suppose that we have some system in which we want our AI to optimally perform a task , a training dataset that contains some information on , and some set of variables (which can be thought of as information about the "current" state of ) which must be taken into account when choosing the optimal action at runtime. is some minimal summary of available to the AI at runtime — its parameters.
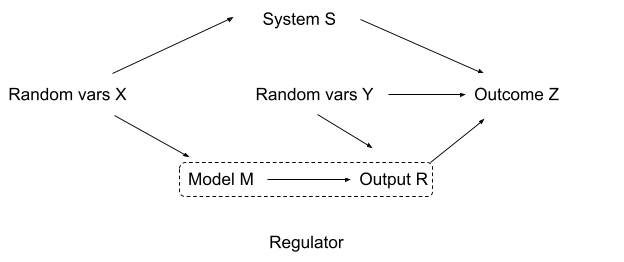
The theorem states that would need to contain all information from which impacts the optimal policy for choosing given — i. e., all information about decision-relevant features of contained in .
(For example, if the AI is trained to drive a car, it probably doesn't need to pay attention to the presence of planes in the sky. Thus, any data about planes present in (their frequency, the trajectories they follow...) would be discarded, as it's not relevant to any decisions the AI would need to make. On the other hand, the presence of heavy clouds is correlated with rain, which would impact visibility and maneuverability, so the AI would learn to notice them.)
More specifically, would need to be isomorphic to the Bayesian posterior on given . That seems like a reasonable definition of a "world-model".
2B. How Are World-Models Useful?
That is, why are world-models necessary? What practical purpose does this module serve?
As I've mentioned at the beginning, they provide "depth". Imagine the world as a causal graph. At the start, the AI can only read off the states of the nodes nearest to it (its immediate sensory inputs). Correspondingly, it can only act on their immediate states. The only policies available to it are reactions no more sophisticated than "if you see bright light, close your eyes".

By building a world-model, it reconstructs the unobserved parts of that causal graph, and starts being able to "see" nodes that are farther away. Seeing them allows it to respond to changes in them, to make its policy a function of their states.
There's a few points to be made here.
First, this solves the Credit Assignment Problem [LW · GW] by providing a policy gradient. To improve, you need some way to distinguish whether you're performing better or worse according to whatever goal you have. But if your goal is a function of a far-away node, a node you don't see — well, you have no idea whether your actions improve or worsen matters, so you can't learn. Having a world-model directly addresses this concern, providing you fine-grained/deep feedback on your actions.
(Notably, "get good at modelling the world" itself is a very "shallow" goal. We get the gradient for it "for free" [LW · GW]: setting up self-supervised learning on our own sensory inputs, trying to get better at predicting them, naturally (somehow) lets us recover the world structure.)
Second, it dramatically increases the space of available reaction patterns [LW · GW], such as shards or heuristics. We can think of them as functions that take as input some subset of the nodes in our world-model, and steer the agent towards certain actions. If so, the set of available shards is defined over the power set of the nodes in the world-model.
A rich world-model, thus, allows the creation of rich economies of shards with complex functionality, while still keeping every shard relatively simple (and therefore easier to learn), since they can "build off" the world-model's complexity. A shard whose complexity is comparable to "if you see bright light, close your eyes" can cause some very complex behavior if it's attached to a highly-abstract node, instead of a shallow observable.
Third, note that world-models span not only space, but also time. Advanced world-models can be rolled forwards or backwards, to simulate the future or infer the past. This is useful both under the "goal-directedness" framework (allowing the agent to optimize across time) and the "richness of heuristics" one (we can view past or future states of nodes as "clones" of nodes, which expand the space of heuristics even more).
Fourth, they allow advanced in-context learning, or "virtual training". Suppose you want to learn how to do X. Instead of doing it via trial-and-error in reality (which may be dangerous), you can train your policy on your world-model instead.
2C. Are World-Models Unitary?
That is, can we expect "a world-model" to be a proper module [? · GW], which only interacts with the rest of the AI's mind via pre-specified interfaces/API channels (as we'd like)? Or will it be in pieces, mini-world-models scattered all across the agent, each of them specialized to serve the needs of particular shards? Can we actually expect all information and inferences about the world to be pooled in one place, consistently-formatted?
Well, the evidence is mixed. Empirically, it does not seem to be the case with the modern ML models. Take the ROME paper: it describes a technique for editing factual associations in LLMs, but such edits don't generalize properly [LW · GW]. For example, rewriting the association with , and then prompting the LLM to talk about the Eiffel Tower, correctly leads to it acting as if the Tower is in Rome. But it's one-directional: talking about Rome doesn't make it mention the Eiffel Tower, as it should if it pools all "facts about Rome" it has in one place. Neither does it follow a hierarchical structure (editing facts about "cheese" does not propagate the update to all sub-categories of cheese).
However, there's strong theoretical support for unitarity, which I'll get to in a bit. There's three explanations for this contradiction:
- Modern AI systems do implement a proper world-model, and we've simply failed, so far, to properly see it.
- A unified world-model only becomes convergently useful at a specific level of capabilities, and modern AI systems simply haven't reached it yet. (E. g., it may only become useful once the GPS forms, at AGI level.)
- There isn't, after all, a pressure to learn a unified "world-model" module.
I'm pretty sure it's a mix of (1) and (2). Let's get to the arguments.
a) Future states are a function of increasingly further-away nodes. Depending on whether you're planning for the next second, next day, or next century, the optimal action to take will be a function of increasingly [LW · GW] more causally distant objects. Thus, your "planning horizon" is limited by your ability to correlate data across distant regions of your world-model.
b) The "Crud" factor. Everything is connected to everything else. While details can often be abstracted away [LW · GW], a significant change often needs to be propagated throughout the whole world-model, and a minor change may unexpectedly snowball.
If your life is just a sequence of causally-disconnected games or tasks, you can have specialized models for each of them. But if these tasks can bleed into each other, it's necessary to cross-reference all available data.
For example, consider an AI trained to play chess and argue with people. If these tasks are wholly separate, and have no effect on each other, the AI can learn wholly separate, non-interacting generative models for both of them. But if a human can talk to the AI concurrently with playing a chess match against it, that changes. The chess strategy a human is using may reveal useful information about how they think, a heated argument may be distracting them from the game, and winning or losing the match may impact the human's emotional state in ways relevant to the arguments you should make. Thus, the need for a unified world-model arises: changes in one place need to be propagated everywhere.
In a sense, it's just a generalization of point (a), from the space-time to all abstract domains. The broader the scale at which you reason (whether spatially, or by interacting at a high level with societies, philosophy, logic), the more "distant" nodes you need to take into account.
c) Centralized planning. Everything-is-connected has implications not only for making accurate predictions, but also for planning. At a basic level, we can propagate our updates throughout our entire world-model: our noticing that the interlocutor is distracted by the argument would change our distribution over the chess moves they'd make. But we can also act in one domain with the deliberate aim of causing a consequence in a different domain: distract the interlocutor on purpose so we can win easier.
This implies a centralized planning capability: a module in the agent that can access every feature of the world-model, "understand" any of them, and incorporate them in plans together.
Importantly, it would need to be universal access, since it's often impossible to predict a priori which facts will end up relevant for any given goal. The behavior of market economies may end up relevant for formalizing reasoning under uncertainty; the success of a complex social deception may end up coupled with weather patterns on Mars.
Just like every component of the world-model would need to interact with each other, so would they need to be able to interact with the planner.
d) The Dehaene Model of Consciousness. I'll close with an argument from neuroscience [LW · GW]. There's a very solid amount of evidence showing that "pool all information about the world together into one place and cross-correlate it" is a distinct neural event, and those are exactly the moments at which we seem to be conscious (and therefore capable of general reasoning). In-between those moments, on the other hand, the information remains in different compartments of the brain, and the brain only acts on it using fairly primitive heuristics.
That seems to fit fairly well with the picture painted by the other arguments.
2D. Are World-Models Modular?
Now it seems worth addressing the opposite failure mode: the possibility that world-models would be strangely opaque. Instead of having distinct internal "submodules" that we'd recognize as familiar concepts, perhaps they'd morph into a strange mess of heuristics and sub-simulations, such that it's downright impossible to tell what's going on inside [LW · GW]?
Most of the arguing against this has already been done, back in the section 1B. It's the premise of the Natural Abstraction Hypothesis, and it's what my interface-development model suggests.
I'll supply one additional one: situational heuristics would remain useful even after the rise of centralized planning. Humans rely on instincts, cognitive shortcuts, and cached computations all the time, we don't manually reason about every little detail. It's much slower, for one.
Making the world-model "opaque" would cut off all that functionality, and presumably drastically reduce the capabilities.
3. World-Model Structure
I've made some arguments on why we should expect world-models to exist, and to convergently take the forms we'd expect of them. None of that, however, helps much when you're staring at trillion-entried matrices trying to figure out which subset of them spells out "niceness". The real meat of this approach is on constraining the possible data structures that all world-models must be converging towards — what specific NN features we should be looking for and how they'd look like.
There's been nonzero progress in this area, by which I mean the natural abstractions research agenda [? · GW]. Indeed: in essence, it aims to determine how efficient world-models are built, founded on the assumptions that certain basic principles of doing so are universal.
Aside from 3B, this section mostly consists of my personal speculations.
3A. Major Sub-Modules
It seems that when we say "world-model", we're conflating (at least) two things:
- A repository of concepts/abstractions.
- A simulation engine.
The former is, essentially, declarative knowledge. Dry logical facts which we know we know and can flexibly manipulate and reason over. (Like mathematical equations, or the faces of your friends, or an understanding of what structures count as "trees", or the knowledge of how many people are in the room with you.)
The latter is an ability to run counterfactual scenarios while drawing on the declarative knowledge — an ability to maintain a specific world-state in one's imagination and modify it. (Like having a "feel" for how people in the room move, or picturing yourself walking through a forest, or mentally tracking the behavior of a mathematical system to better understand it.)
Using the two are very distinct experiences, and they have somewhat different functionality. I believe that "simulations" extend a bit beyond "world-models", actually — that they "spoof" the whole mental context (in the shard theory's parlance [? · GW]). They access shards' inputs and feed them data from the simulated counterfactual, thereby allowing to "test out" shard activations in advance of being in the simulated situation.
That is useful for several reasons:
- It improves the quality of predictions. Procedural knowledge is likely implemented in shards, as are various "hunches". If you imagine "walking through a dark forest" in detail, you may note how scared the darkness makes you feel, and that something in you seems to predict dangerous creatures hiding in that darkness, ready to attack you.
Both of those effects, I think, are shard-based, and may be missed if you only thought about "walking through a dark forest" in the abstract. And they're useful: for predicting your own behavior, and for improving predictions in general (since there's presumably a reason you expect dangers in the dark, like an (evolutionary) history of the darkness actually hiding predators). - It allows "virtual training": you can hone your heuristics in the simulation, before being faced with the actual situation.
- It allows to gather data on shards [LW · GW]. If you have some useful knowledge that's only implemented procedurally, this is a way to make it explicit. (E. g., the "I'm afraid of the dark and expect monsters to jump out" fact from the above would become explicitly known, after the simulation has been ran.)
Convergence-wise, there are arguments for all of this functionality. Without the simulation engine, you don't get the ability to simulate future states, which means no ability to compute policy gradients, have "cross-temporal" heuristics, or do advanced in-context training. In turn, without the conceptual repository, your ability to improve the simulation engine at runtime is very limited, the available "richness of counterfactuals" you can run is limited, and you don't get advanced planning.
Interpretability-wise, however, most of the arguments primarily apply to the conceptual repository, not to the simulation engine. Our ability to perfectly "snoop" on any counterfactual an AI is running is less certain:
- On the one hand, the simulation would be generated drawing on the conceptual repository, and it'd likewise need to interface both with the planner and the shards. In addition, it'd be configured to be compatible with the sensory modalities the AI is using (like our imagination is accessing our visual-processing machinery), so it seems like we're ought to be able to reverse-engineer it.
- On the other hand, shard interference would be heavy (moving the simulation from one state to another in opaque ways), and the format in which sensory information enters the GPS/the shards may be completely different from the one it enters the agent in. Inasmuch as it's consistently-formatted, it'd still be very interpretable, but that'd be an entire separate task.
At the least, I think that we'd definitely be able to get some insight into what's happening in the counterfactuals by looking at what concepts are being activated, and how strongly.
... Or so my inside-view on that goes. On a broader view, this section (3A) is the part that most consists of informal speculations on my part.
3B. Abstractions As Basic Units
The basic units in which information is stored in the conceptual repository seem to be natural abstractions: high-level summaries of lower-level systems that consist only of the information that's relevant far-away [LW · GW]/is redundantly represented [LW · GW]/constitutes a minimal latent variable [LW · GW].
A topic of relevance, here, is what data formats those abstractions follow/what is their type signature. John's current [LW · GW] speculations [LW · GW] are [LW · GW] that they're probability distributions over deterministic constraint on the environment.
For example, imagine a species of trees growing in a savannah. These trees replicate, mutate, and spread; take in energy and matter, and grow. All of that is subject to some variance/entropy, yet its extent is constrained. Every replication is imperfect, but the rate or severity of mutation is bounded. Trees spread, but they can only do that in certain conditions or in certain directions. The shapes they take are constrained by their genome and the available resources. And so on.
Once you compute all of that, you're left with the knowledge of what information does get replicated perfectly, in the form of some constraints beyond which environmental entropy doesn't grow. You take in a set of trees , and compute from them some abstraction . contains information like "trees can have shapes that vary like this" and "trees are distributed across the landscape like this" — probability distributions over possible structures.
If this result is correct, that's what we should be looking for in ML models: vast repositories of conditional probability distributions of this form.
3C. Higher-Level Organization
Of course, abstractions are not just stored in one big pile. They're connected to each other, forming complex webs. When we think about trees, we can bring to mind their relation to sunlight and water and animals. They're also connected to the lower-level or higher-level abstractions — the abstract concept of a tree relates to the wood and the cells trees are made of, and the forests and ecosystems they make up, and the specific instances of trees we remember.
Seems natural to think that abstractions would have multi-level hierarchies. For example, we may compute a "first-order" abstraction of a particular tree species, . Then we may encounter more tree species, and compute a set of tree-specie-abstractions, . In the same manner, we may then go further up the ladder of taxonomic ranks, until a fully general "tree" abstraction.
Here's a caveat: there are "abstraction hierarchies" that are mutually incompatible.
Consider the entire set of humans on Earth. Suppose that you're encountering subsets of them in some order, and you're abstracting over these subsets each time.
- You may go country-by-country, and end up with a set of "human of a given ethnicity" abstractions, with strong constraints on appearance within each first-order abstraction, in addition to generic constraints on what "humans" are. (And then compute second-order abstractions over nearby ethnicities, getting races, etc.)
- You may go by industries, and end up with "human mathematician", "human artist", which likewise contain general information on how a "human" looks like, but put stronger constraints on interests or aptitudes, rather than on appearances.
- You may go by political movements, which would strongly constrain ideological beliefs.
- And so on.
(Here's [LW(p) · GW(p)] a bit more formalization on this angle, including how we may "split" a category like "all humans" into several individually-well-abstracting subcategories.)
Each of choice of order would result in a different "abstraction hierarchy" — you can't recover the abstraction of a mathematician from first-order abstractions of ethnicities. Yet all of these hierarchies would be made of meaningful, useful abstractions!
A slightly different view presents itself if instead of going top-down [LW · GW], you go bottom-up [? · GW]. I. e., rather than picking out all objects of the type "human" and trying to summarize them, you can look at the world and try to locate stable, well-abstracting high-level structures from scratch. In this case, looking at the macro-level and focusing on different constraints might yield you "homes → cities → countries", or "businesses → industries → economies", or "local bureaucracies → bureaucratic systems → geopolitical entities". Similarly, those would be useful yet incompatible abstraction hierarchies.
That's not exactly a problem, in my view. We're still ending up with ground-truth-determined natural abstractions that can be computed by looking at the deterministic constraints in the environment. But there's some sense in which choosing to look at a particular constraint (like "how is the spread of philosophical beliefs constrained?") locks us out of others (like "how is the geographical spread of these people constrained?").
Based on this, it seems that the set of all abstractions over some underlying system may be organized along the following dimensions:
- "Hierarchically": from less-abstract concepts to more and more abstract ones (specific trees → tree species; groupings of people-and-tech → businesses).
- "By layers": based on the choice of constraints (people by ethnicity vs. by profession; focus on the flow of ideas vs. patterns of economic activity).
- "Horizontally": different concepts on the same layer and the same hierarchy level (different tree species, or how specific humans and animals and trees occupy roughly "the same" layer of abstraction).
3D. Laziness
World-models are lazy [LW(p) · GW(p)], in a programmer's sense. That is, we don't keep the entire state of the world in our heads all at once. We keep it in a compressed form, and only compute the specifics about particular aspects of it on demand. It's as much a consequence of embedded agency as the natural abstractions themselves — the peril of having to reason about a world that you're part of.
Let's consider how people do it. I see three primary methods:
- Suppose you're given the rules for some system, plus its initial state (e. g., Conway's Game of Life + some distribution of living cells). You can then directly simulate that system step-by-step, up to your working-memory limits. And if you can locate some good emergent abstractions in the system, that lessens the strain on your working memory (e. g., it's easier to reason about "gliders" than about the specific cells they're made of).
- Suppose you're given the list of personality traits of some person. To get an idea of how it'd be like to interact with them, you access your general model of human psychology, then incorporate information about that specific person into it, and get an idea of how they'd behave.
- In abstraction terms, you take your general "human" abstraction , condition it on a set of facts , and get the probability distribution over that specific human.
- Suppose you're prompted to think in detail about the dynamics of some system — e. g., how a market would behave in response to some unusual event. You access your model of the lower-level details of that system (e. g., interactions between individual traders, with all the details of their psychology), and consider how they'd respond in aggregate.
- In abstraction terms, you look at your "market" abstraction , go down a hierarchy step to the lower-level abstraction "trader" , then "sample" from to get a few individual trader-instances , and then you simulate their interactions.
- Or you can think about Game of Life's gliders again. When they're traveling over empty space, you can just project their position along a line, but if they near other live cells, you have to think about their constituent cells in detail.
Thus, laziness seems to be possible due to a combination of the "simulation engine" from 3A, and the fact that our environment is well-abstracting.
4. Research Directions
I believe it's a highly tractable avenue of research, and the shortest path to robust alignment in worlds where alignment is really hard[1]. It's the one part of agent foundations that seems necessary to get right.
Ways to contribute:
- The Natural Abstractions research agenda, obviously. See e. g. the pragmascope idea [LW · GW] in particular.
- Selection Theorems [LW · GW] focused on world-models specifically (along the lines of the Gooder Regulator theorem). What constraints can we put on world-model structure? E. g., can we formalize my "simulator vs. conceptual repository" distinction from 3A?
- More broad theory of world-modeling. I'm currently thinking in terms of Bayes nets and some ad-hoc causal models [LW · GW], which seems very limiting — like trying to write a web browser in assembler.
- Are there any extant "feature-rich" frameworks for building world-models, that would also suffice for reasoning about the real world in detail?
- This also seems like a decent alternate starting point for selection-theorem-style thinking. Instead of trying to constrain how world-models must be, one can try to invent from scratch a bunch of efficient world-modelling tools, then see whether they follow some consistent, uniquely efficient principles — such that any efficient world-model must follow them as well.
- General understanding of how information is represented in ML models. I expect this problem is a bit distinct from the challenges this post discusses — the same way breaking an encryption is different from learning to translate a different language.
- (Though perhaps this is a topic for a separate post.)
- Inventing training setups that generate pure world-models/simulators [LW · GW], while guaranteeing no risk of mesa-optimization [LW · GW]. These world-models would not necessarily need to be outputting anything human-readable. We'd just need a theoretical assurance that the training setup is learning a world-model (see the Gooder Regulator Theorem for what that may mean). Difficulties:
- The central issue, the reason why "naive" approaches for just training a ML model to make good prediction will likely result in a mesa-optimizer, is that all such setups are "outer-misaligned" by default. They don't optimize AIs towards being good world-models, they optimize them for making specific good predictions and then channeling these predictions through a low-bandwidth communication channel. (Answering a question, predicting the second part of a video/text, etc.)
- That is, they don't just simulate a world: they simulate a world, then locate some specific data they need to extract from the simulation, and translate them into a format understandable to humans.
- As simulation complexity grows, it seems likely that these last steps would require powerful general intelligence/GPS as well. And at that point, it's entirely unclear what mesa-objectives/values/shards it would develop. (Seems like it almost fully depends on the structure of the goal-space. And imagine if e. g. "translate the output into humanese" and "convince humans of the output" are very nearby, and then the model starts superintelligently optimizing for the latter?)
- In addition, we can't just train simulators "not to be optimizers", in terms of locating optimization processes/agents within them and penalizing such structures. It's plausible that advanced world-modeling is impossible without general-purpose search, and it would certainly be necessary inasmuch as the world-model would need to model humans.
- Still, there may be some low-hanging fruits there.
- ^
That is, in worlds that mostly agree with the models of Eliezer Yudkowsky/Nate Soars/John Wentworth, on which we need to get the AGI exactly right to survive.
- ^
In theory, there should be a "buffer zone" of capability, between an AGI smart enough to model itself, and an AGI smart enough to hack through interpretability tools (e. g., humans are self-reflective, but not smart enough to do that).
But "is self-reflective" is also not a binary. An AGI's self-model can be more or less right. On the lower capability level, it'll probably be very flawed, therefore not very useful. On the flipside, if it's very close to reality, the AGI is likely to be smart enough that reading its mind is dangerous.
We may easily misjudge that, too. An AGI that achieved self-awareness is likely already on the cusp of its sharp left turn [LW · GW], past which it'd be unsafe to interpret. Depending on how sharp the turn is, that "buffer zone" may be passed in the blink of an eye, easily missed.
- ^
Runtime-editability also reassures another concern: that the inferences the AGI makes at runtime would be encoded differently from the knowledge hard-coded into its parameters. But since both types of knowledge would be used as inputs into the same algorithms (the planner, the shards), there's probably no reason to expect much mutation by default, due to the need for backwards compatibility.
(To be clear, once the AGI undergoes the sharp left turn/goes FOOM, and starts designing successor agents or directly modifying itself or just becomes incomprehensibly superintelligent, then this'll obviously stop applying. But if we haven't aligned it by then, we're dead either way, so that's irrelevant.)
22 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2023-01-14T23:04:44.480Z · LW(p) · GW(p)
Here's a place where I want one of those disagree buttons separate from the downvote button :P
Given a world model that contains a bunch of different ways of modeling the same microphysical state (splitting up the same world into different parts, with different saliency connections to each other, like the discussion of job vs. ethnicity and even moreso), there can be multiple copies that coarsely match some human-intuitive criteria for a concept, given different weights by the AI. There will also be ways of modeling the world that don't get represented much at all, and which ways get left out can depend how you're training this AI (and a bit more subtly, how you're interpreting its parameters as a world model).
Especially because of that second part, finding good goals in an AI's world model isn't satisfactory if you're just training an fixed, arbitrary AI. Your process for finding good goals needs to interact with how the AI learns its mode of the world in the first place. In which case, world-model interpretability is not all we need.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-01-15T05:00:58.318Z · LW(p) · GW(p)
I agree that the AI would only learn the abstraction layers it'd have a use for. But I wouldn't take it as far as you do [LW · GW]. I agree that with "human values" specifically, the problem may be just that muddled, but with none of the other nice targets — moral philosophy, corrigibility, DWIM, they should be more concrete.
The alternative would be a straight-up failure of the NAH, I think; your assertion that "abstractions can be on a continuum" seems directly at odds with it. Which isn't impossible, but this post is premised on the NAH working.
comment by davidad · 2023-01-17T18:20:16.917Z · LW(p) · GW(p)
Not listed among your potential targets is “end the acute risk period” or more specifically “defend the boundaries [AF · GW] of existing sentient beings,” which is my current favourite. It’s nowhere near as ambitious or idiosyncratic as “human values”, yet nowhere near as anti-natural or buck-passing as corrigibility.
comment by davidad · 2023-01-17T18:16:32.360Z · LW(p) · GW(p)
In my plan [AF · GW], interpretable world-modeling is a key component of Step 1, but my idea there is to build (possibly just by fine-tuning, but still) a bunch of AI modules specifically for the task of assisting in the construction of interpretable world models. In step 2 we’d throw those AI modules away and construct a completely new AI policy which has no knowledge of the world except via that human-understood world model (no direct access to data, just simulations). This is pretty well covered by your routes numbered 2 and 3 in section 1A, but I worry those points didn’t get enough emphasis and people focused more on route 1 there, which seems much more hopeless.
Replies from: wassname↑ comment by wassname · 2023-11-05T23:56:56.134Z · LW(p) · GW(p)
Ah, now it makes sense. I was wondering how world model interpretability leads to alignment rather than control. After all, I don't think you will get far controlling something smarter than you against its will. But alignment of value could scale with large gaps in intelligence.
When that 2nd phase, there are a few things you can do. E.g the 2nd phase reward function could include world model concepts like "virtue", or you could modify the world model before training.
comment by tailcalled · 2023-01-15T21:47:24.475Z · LW(p) · GW(p)
I'm very optimistic about the feasibility of creating world-models with interpretable pointers to "objects". Things like chairs. In fact, my optimism is sufficiently strong that I tend to take such world-models for granted when thinking of how to achieve alignment. And furthermore I expect interpretable world models to be a necessary condition for alignment.
However, I'm very pessimistic about the feasibility of getting abstract things like "human values" and similar for free. Even complicated high-dimensional things like "humans", especially when meant to include e.g. uploads, are things I am not so optimistic about the feasibility of (especially once you consider certain challenges at the margins). It just doesn't seem like the methods that can be used to create world models have anything that would robustly capture such abstract things.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-16T21:34:49.568Z · LW(p) · GW(p)
However, I'm very pessimistic about the feasibility of getting abstract things like "human values" and similar for free. Even complicated high-dimensional things like "humans", especially when meant to include e.g. uploads, are things I am not so optimistic about the feasibility of (especially once you consider certain challenges at the margins). It just doesn't seem like the methods that can be used to create world models have anything that would robustly capture such abstract things.
I'm confused at why you think this if you're very optimistic on getting interpretable pointers/world models to things. What makes values or abstract concepts different, exactly.
Replies from: tailcalled↑ comment by tailcalled · 2023-01-16T22:02:25.852Z · LW(p) · GW(p)
The most feasible concept of values learning that I've seen has been inverse reinforcement learning, but even that concept seems way too underdetermined to be sufficient for learning values. Whereas for simple objects it seems like there are lots of seemingly-sufficient ideas on the table, just waiting until the data gets good enough.
comment by ryan_greenblatt · 2023-01-15T08:47:11.313Z · LW(p) · GW(p)
As an established case for tractability, we have the natural abstraction hypothesis. According to it, efficient abstractions are a feature of the territory, not the map (at least to a certain significant extent). Thus, we should expect different AI models to converge towards the same concepts, which also would make sense to us. Either because we're already using them (if the AI is trained on a domain we understand well), or because they'd be the same abstractions we'd arrive at ourselves (if it's a novel domain).
Even believing in a relatively strong version of the natural abstractions hypothesis doesn't (on its own) imply that we should be able to understand all concepts the AI uses. Just the ones which:
- have natural abstractions
- that the ai faithfully learns as opposed to devoting insufficient capacity to reach the natural abstraction
- and humans can understand these natural abstractions
These three properties seem reasonably likely in practice for some common stuff like 'trees' or 'dogs'.
comment by the gears to ascension (lahwran) · 2023-01-14T21:20:31.397Z · LW(p) · GW(p)
maybe-tangentially, 3d structured world models seem very interesting to me. eg, here's a talk I had open and popped over to LW to share: https://www.youtube.com/watch?v=QffGi9XUt1M
comment by Roger Dearnaley · 2023-04-25T03:09:07.005Z · LW(p) · GW(p)
I'm not very scared of any AGI that isn't capable of being a scientist — it seems unlikely to be able to go FOOM. In order to do that, it needs to:
- have multiple world models at the same time that disagree, and reason under uncertainty across them
- do approximate Bayesian updates on their probability
- plan conservatively under uncertainty, i.e have broken the Optimizer's Curse [LW · GW]
- creatively come up with new hypotheses, i.e. create new candidate world models
- devise and carry out low-cost/risk experiments to distinguish between world models
I think it's going to be hard to do all of these things well if its world models aren't fairly modular and separable from the rest of its mental architecture.
One possibility that I find plausible as a path to AGI is if we design something like a Language Model Cognitive Architecture (LMCA) along the lines of AutoGPT, and require that its world model actually be some explicit combination of human natural language, mathematical equations, and executable code that might be fairly interpretable to humans. Then the only potions of its world model that are very hard to inspect are those embedded in the LLM component.
Replies from: Thane Ruthenis, Brendon_Wong↑ comment by Thane Ruthenis · 2023-04-25T05:00:41.965Z · LW(p) · GW(p)
In order to [be a scientist], it needs to:
Yeah, that's where my current thinking is at as well. I wouldn't term it as having "multiple world models" — rather, as entertaining multiple possible candidates for the structure of some region of its world-model — but yes, I think we can say a lot about the convergent shape of world-models by reasoning from the idea that they need to be easy to adapt and recompose based on new evidence.
One possibility that I find plausible as a path to AGI is if we design something like a Language Model Cognitive Architecture (LMCA) along the lines of AutoGPT
I've also had this idea, as a steelman of the whole "externalized reasoning oversight [LW · GW]" agenda — to prompt a LLM to generate a semantical world-model, with the LLM itself just playing the role of the planning process over it. However, I expect it wouldn't work as intended, for two reasons:
- Inasmuch as it's successful, the world-model is unlikely to stay naively-human-interpretable. It'd drift towards alien wordings, concepts, connections. And even if we force it to look human-interpretable, stenography is convergent [LW(p) · GW(p)], and this sort of setup opens up many more dimensions in which to sneak in messages than standard chains-of-thoughts. And if we manage to defeat stenography as well, I then expect a WM to be forced to look like terabytes upon terabytes of complexly-interconnected text, each plan-making query on it generating mountains of data — perhaps too much to reasonably sort out. Tying-in to...
- It'll probably be too computationally intensive to work at all. Humans explicitly running generally-intelligent queries on their world-models takes a lot of time already, compared to the speed at which our instincts work. If each step of a query required a whole LLM forward-pass, instead of the minimal function required for it? I expect it'd require orders of magnitude more compute than Earth is going to have in the near-term.
And these two points aren't independent: the more human-interpretable we'd force the WM to look, the more wasteful and impractical it'd be.
↑ comment by Brendon_Wong · 2023-11-19T11:40:40.484Z · LW(p) · GW(p)
One possibility that I find plausible as a path to AGI is if we design something like a Language Model Cognitive Architecture (LMCA) along the lines of AutoGPT, and require that its world model actually be some explicit combination of human natural language, mathematical equations, and executable code that might be fairly interpretable to humans. Then the only potions of its world model that are very hard to inspect are those embedded in the LLM component.
Cool! I am working on something that is fairly similar (with a bunch of additional safety considerations [LW · GW]). I don't go too deeply into the architecture in my article, but would be curious what you think!
comment by Gordon Seidoh Worley (gworley) · 2023-01-16T19:40:12.763Z · LW(p) · GW(p)
Reading this post I think it insufficiently addresses motivations, purpose, reward functions, etc. to make the bold claim that perfect world-model interpretability is sufficient for alignment. I think this because ontology is not the whole of action. Two agents with the same ontology and very different purposes would behave in very different ways.
Perhaps I'm being unfair, but I'm not convinced that you're not making the same mistake as when people claim any sufficiently intelligent AI would be naturally good.
Replies from: Thane Ruthenis, sharmake-farah↑ comment by Thane Ruthenis · 2023-01-17T01:43:33.230Z · LW(p) · GW(p)
Two agents with the same ontology and very different purposes would behave in very different ways.
I don't understand this objection. I'm not making any claim isomorphic to "two agents with the same ontology would have the same goals". It sounds like maybe you think I'm arguing that if we can make the AI's world-model human-like, it would necessarily also be aligned? That's not my point at all.
The motivation is outlined at the start of 1A: I'm saying that if we can learn how to interpret arbitrary advanced world-models, we'd be able to more precisely "aim" our AGI at any target we want, or even manually engineer some structures over its cognition that would ensure the AGI's aligned/corrigible behavior.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2023-01-17T03:36:35.410Z · LW(p) · GW(p)
Isn't a special case of aiming at any target we want the goals we would want it to have? And whatever goals we'd want it to have would be informed by our ontology? So what I'm saying is I think there's a case where the generality of your claim breaks down.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-01-17T06:02:11.440Z · LW(p) · GW(p)
Goals are functions over the concepts in one's internal ontology [LW · GW], yes. But having a concept for something doesn't mean caring about it — your knowing what a "paperclip" is doesn't make you a paperclip-maximizer.
The idea here isn't to train an AI with the goals we want from scratch, it's to train an advanced world-model that would instrumentally represent the concepts we care about, interpret that world-model, then use it as a foundation to train/build a different agent that would care about these concepts.
↑ comment by Noosphere89 (sharmake-farah) · 2023-01-16T21:47:26.862Z · LW(p) · GW(p)
I think that the big claim the post relies on is that values are a natural abstraction, and the Natural Abstractions Hypothesis holds. Now this is admittedly very different from the thesis that value is complex and fragile.
It is not that AI would naturally learn human values, but that it's relatively easy for us to point at human values/Do What I Mean/Corrigibility, and that they are natural abstractions.
This is not a claim that is satisfied by default, but is a claim that would be relatively easy to satisfy if true.
The robust values hypothesis from DragonGod is worth looking at, too.
From the link below, I'll quote:
Consider the following hypothesis:
There exists a "broad basin of attraction" around a privileged subset of human values[1] (henceforth "ideal values") The larger the basin the more robust values are Example operationalisations[2] of "privileged subset" that gesture in the right direction: Minimal set that encompasses most of the informational content of "benevolent"/"universal"[3] human values The "minimal latents" of "benevolent"/"universal" human values Example operationalisations of "broad basin of attraction" that gesture in the right direction: A neighbourhood of the privileged subset with the property that all points in the neighbourhood are suitable targets for optimisation (in the sense used in #3 Larger neighbourhood → larger basin Said subset is a "naturalish" abstraction The more natural the abstraction, the more robust values are Example operationalisations of "naturalish abstraction" The subset is highly privileged by the inductive biases of most learning algorithms that can efficiently learn our universe More privileged → more natural Most efficient representations of our universe contain a simple embedding of the subset Simpler embeddings → more natural Points within this basin are suitable targets for optimisation The stronger the optimisation pressure applied for which the target is still suitable, the more robust values are. Example operationalisations of "suitable targets for optimisation": Optimisation of this target is existentially safe[4] More strongly, we would be "happy" (where we fully informed) for the system to optimise for these points.
This is an important hypothesis, since if it has a non-trivial chance of being correct, then AI Alignment gets quite easier. And given the shortening timelines, I think this is an important hypothesis to test.
Here's a link below for the robust values hypothesis:
https://www.lesswrong.com/posts/YoFLKyTJ7o4ApcKXR/disc-are-values-robust [LW · GW]
Replies from: Thane Ruthenis, gworley↑ comment by Thane Ruthenis · 2023-01-17T01:56:20.824Z · LW(p) · GW(p)
Now this is admittedly very different from the thesis that value is complex and fragile.
I disagree. The fact that some concept is very complicated doesn't mean it won't be necessarily represented in any advanced AGI's ontology. Humans' psychology, or the specific tools necessary to build nanomachines, or the agent foundation theory necessary to design aligned successor agents, are all also "complex and fragile" concepts (in the sense that getting a small detail wrong would result in a grand failure of prediction/planning), but we can expect such concepts to be convergently learned.
Not that I necessarily expect "human values" specifically to actually be a natural abstraction — an indirect pointer at "moral philosophy"/DWIM/corrigibility seem much more plausible and much less complex.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-01-17T02:06:24.740Z · LW(p) · GW(p)
Sorry for misrepresenting your views.
↑ comment by Gordon Seidoh Worley (gworley) · 2023-01-16T22:44:24.961Z · LW(p) · GW(p)
I think that the big claim the post relies on is that values are a natural abstraction, and the Natural Abstractions Hypothesis holds. Now this is admittedly very different from the thesis that value is complex and fragile.
It is not that AI would naturally learn human values, but that it's relatively easy for us to point at human values/Do What I Mean/Corrigibility, and that they are natural abstractions.
This is not a claim that is satisfied by default, but is a claim that would be relatively easy to satisfy if true.
If this is the case, my concern seems yet more warranted, as this is hoping we won't suffer a false positive alignment scheme that looks like it could work but won't. Given the his cost of getting things wrong, we should minimize false positive risks [LW · GW] which means not pursuing some ideas because the risk if they are wrong is too high.
comment by RogerDearnaley (roger-d-1) · 2024-01-10T10:32:56.696Z · LW(p) · GW(p)
The issue might be that humans are too incoherent and philosophically confused for their "values" to stand for anything concrete — e. g., we almost certainly don't have concrete utility functions.
One of the most basic concepts in natural language processing is valence/sentiment extraction: "am I happy or sad about this?". This a direct measurement of "how well does the situation conform to my human values?": what we'd want the model to optimize. Even tiny Natural Language Processing networks have clearly interpret able signals (neurons, activations, linear probes etc) of valence/sentiment extraction. So this is really not hard to find: it stands out like a sore thumb as soon as you start analyzing human text. Humans are adaption-executing agents that try to optimize a complex mess of things, and "how optimal is this, and why?" is one of the main things that we talk/complain about all the time. Whether this system is in places incoherent or Dutch-bookable so doesn't match the theoretical requirements for a utility function is a separate question (and humans have numerous perceptual biases and often-unhelpful mental heuristics so the answer is almost certainly "yes"), but the basic signal is really easy to find.