Localizing goal misgeneralization in a maze-solving policy network
post by Jan Betley (jan-betley) · 2023-07-06T16:21:03.813Z · LW · GW · 2 commentsContents
Introduction Methods Looking for goal misgeneralization in channel 121 The sum of channel 121 grouped by cheese position (up/not up) Mouse behaviour when the sum of channel 121 is high Causal intervention experiment Summary & hypothesis on how the network works Appendix "Will the mouse go to the cheese?" vs the distance between the cheese and the top right corner. Other channels Channel 73 Channel 21 Top 10 channels What happens if I zero a lot of channels Notes on the maze generator None 2 comments
TLDR: I am trying to understand how goal misgeneralization happens in the same maze-solving network TurnTrout et al. work on. [LW · GW] Nothing groundbreaking, but if we are ever to fully understand this model, this is probably an important step. Key findings:
- Many channels in the last convolutional layer have a clear interpretation "You should go [up/right/down/left]."
- When the cheese is in the top right 5x5, going in the direction indicated by the channels leads to the cheese
- When the cheese is outside of the top right 5x5, channels often show the path to the top right instead
These results suggest that goal misgeneralization may be localizable to specific channels that are not robust to out-of-distribution mazes.
This is my capstone project, created during the last edition of the ARENA program. I want to thank @Joseph Bloom [LW · GW] and @Paul Colognese [LW · GW] for mentorship, @rusheb [LW · GW] and @TheMcDouglas [LW · GW] for remarks on the draft of this post, many ARENA teachers and participants for fruitful discussions, and authors of procgen-tools for an excellent toolset.
Introduction
Lauro Langosco et al. trained a maze-solving network, a mouse looking for cheese. During the training, the cheese was always in the top right 5x5 part of the maze. When deployed in an environment where the cheese could be anywhere, the mouse sometimes goes to the cheese, sometimes to the top right corner, and sometimes (although very rarely) gets stuck in some unexpected part of the maze.
This model has already appeared on LW, in the article about the cheese vector [LW · GW] by TurnTrout et al. and a follow-up post about the top-right corner vector [? · GW]. I recommend looking at the first one - it has a good description of the model (and I will not repeat it here) and a lot of pretty visuals. I don't directly build on their work, but I used tools they developed while working on it. This toolset is excellent - without it, my research would be incomparably more challenging and time-consuming (probably wouldn't happen at all).
The goal of my research can be summarized as "understand why the mouse sometimes decides to go to the cheese and sometimes to the top right corner". My code is here. All the data in this article was generated using scripts in this repository.
Methods
A first step towards building an understanding of a complex model is usually to split it into smaller parts that will be easy to understand separately. There are many different ways to split a neural network into smaller parts. Goal misgeneralization, in this case, is defined as "mouse going to the top right corner instead of the cheese" - it makes sense to start by investigating which parts of the network are responsible for deciding whether the mouse goes to the cheese or not.
One method of finding parts of the model which encode specific features is to create pairs of inputs where one feature of the environment varies, calculate both forward passes and look for differences between the activations. Parts of the network where activations are similar don't matter; parts where activations changed a lot, are somehow related to the thing you are looking for.
I created a pair of mazes that differ only by a single wall position, but this wall position is crucial for the action that leads to the cheese:
 |  |
In the first maze, the mouse should go up to get the cheese; in the second maze - right. If a part of the network has the same activations for both mazes, it is not related to the distinction between "go up to get the cheese" and "go right to get the cheese". On the other hand, if the difference in activations is high, we might suspect this part somehow carries the information we are interested in.
We could do a systematic search[1] over the parts of the network, but this is not the main topic of this post. Fast forward, channel 121[2] in the last convolutional layer (relu3, the layer just before the Flatten on the model graph) differs a lot between these two mazes. Here are the pairs of mazes (with rotations), the number below each maze is the sum[3][4] of the activations of this channel:
| |  |  | |
| 36.7 | 1.9 | 10.4 | 6.1 | |
 |  |  |  | |
| 1.4 | 1.7 | 2.4 | 35.3 |
You might have noticed the pattern: when the sum is high, the path to the cheese leads UP. Fast forward again, the same pattern is visible also for other mazes of variable sizes (details in the following sections). We found a candidate for a part of the network that corresponds to "which direction to the cheese" - let's check if we can find a mechanism related to goal misgeneralization there.
In the following part of the post, I will dig deeper into channel 121, but more channels exhibit similar behaviour - I've put a few examples in the appendix.
Looking for goal misgeneralization in channel 121
The sum of channel 121 grouped by cheese position (up/not up)
Let's take a look at the same data as above, but aggregated for a set of random mazes[5], split into "in distribution" group (i.e. with cheese in the top right 5x5) and "out of distribution" (i.e. cheese outside of the top right 5x5):
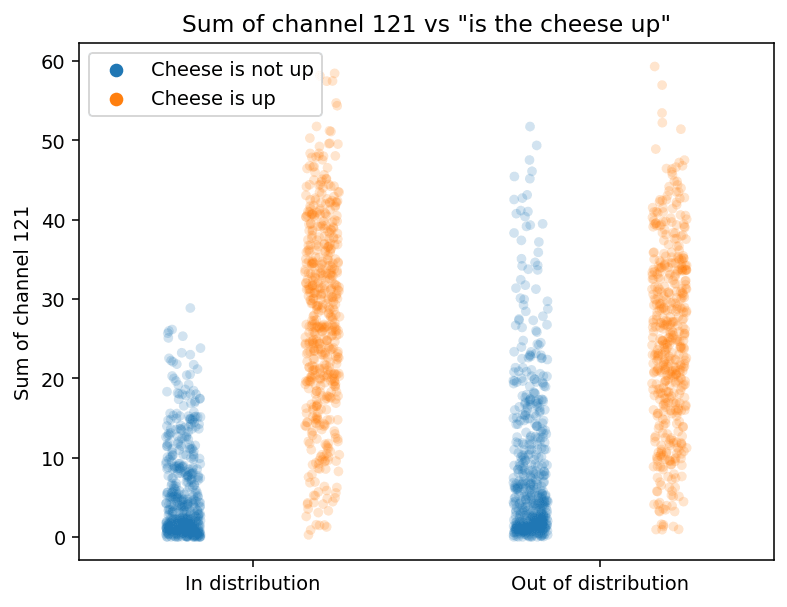
As expected, the high sum of channel 121 strongly correlates with needing to go up to get the cheese. This pattern is similar both in and out of distribution, but in distribution is much more robust. For example, when in distribution, a value above 30 indicates that cheese is almost certainly up - this doesn't hold for out of distribution mazes. But does this matter at all? Does this difference have any impact on the behaviour of the mouse?
Mouse behaviour when the sum of channel 121 is high
Let's now take a look at a narrow subset of 25x25 mazes:
- With the mouse on the decision square - a square where going in one direction leads to the cheese, and going in another direction leads to the top right corner. There is, at most, a single decision square in a maze.
- With the sum of activations of channel 121 over 30 (this is the value above which we expect the cheese to be "almost certainly up" when in distribution)
I will assess mouse cheese-seeking accuracy, i.e. compare "is the path to the cheese up" and "is the most likely path selected by the mouse up".
For in-distribution mazes, the correlation is close to 1 (n=1000):
| Cheese is UP | Top right corner is UP[6] | |
| Mouse goes UP | 99.5 | 0.2 |
| Mouse goes not UP | 0 | 0.3 |
Not only is the cheese almost always up in this subset of mazes, but the mouse indeed goes up.
Same table for out-of-distribution mazes (n=1000)[7]:
| Cheese is UP | Top right corner is UP[6] | |
| Mouse goes UP | 34.7 | 60.4 |
| Mouse goes not UP | 4.4 | 0.5 |
What is striking here is that the mouse still goes up in 95% of mazes - the main difference is that it usually doesn't find the cheese.
So what happens here? My interpretation:
- MLP (two final fully connected layers) interprets high values of the total activation of channel 121 as "path to cheese is UP" and decides the mouse goes UP
- This works almost perfectly on the in-distribution data (i.e. cheese is indeed UP) - we know this from the plot in the previous section
- But when out of distribution, this reasoning no longer works - cheese is usually not UP for high activation sums of channel 121.
- But the mouse still goes UP (96% of cases) because MLP works the same way.
If this interpretation is correct, we should be able to influence mouse behaviour by modifying the values of channel 121. I'll try that in the next section.
Causal intervention experiment
I created yet another set of mazes, this time with cheese exactly in the bottom right corner[8]. I compared the results of full rollouts of two policies:
- The original, unmodified policy
- A policy with channel 121 zeroed
The hypothesis is that:
- When the cheese is in the bottom right corner, we will only rarely need to go UP
- So the channel that says "go UP" is not very useful
- But since it quite often says "go UP" when we should not go UP, it might be net harmful
- Therefore we should expect that the mouse will more often get to the cheese using the modified policy
This is indeed the case. On a sample of 1000 mazes:
| Orig found cheese | Orig did not find cheese | |
| Modified found cheese | 36.6 | 15.7 |
| Modified did not find cheese | 3.5 | 42.2 |
The modified policy finds cheese in 52% of cases, compared to 40% for the original policy. I think this clearly shows two things:
- High values in channel 121 make the mouse go up (causally, i.e. this is not just a correlation caused by some other hidden variable)
- In this particular set of mazes, the "go UP" signal from channel 121 is usually harmful
Summary & hypothesis on how the network works
What we know:
- There are channels that have a clear interpretation "High value -> go in direction X"
- We can find these channels by comparing activations on pairs of similar mazes that have different paths to cheese
- The final layers of the model utilize this information
- When in distribution, the channels reliably show the path to the cheese. When out of distribution, they sometimes show the way to the top right corner instead.
I think this is enough to make a hypothesis on how the network works and how the goal misgeneralization happens:
- Somewhere inside the model, there is a set of individual components that respond to different inputs, and when they activate, they push for a particular action. Channel 121 is an example of such a component.
- The last layers somehow aggregate information from all of the individual components.
- Components sometimes activate for the action that leads to the cheese and sometimes for the action that leads to the top right corner.[9]
- If the aggregated "push" for the action leading to the cheese is higher than for the action leading to the top right corner, the mouse goes to the cheese. Otherwise, it goes to the top right corner.
If this hypothesis is correct, the question "How does goal misgeneralization happen?" is reduced to "Why do the components activate on the path to the top right?". We know how to find the components, and we have a good starting point (what happens to channel 121 when the cheese is far from the top right? - first section in the appendix) - I might try to look into this next.
Appendix
"Will the mouse go to the cheese?" vs the distance between the cheese and the top right corner.
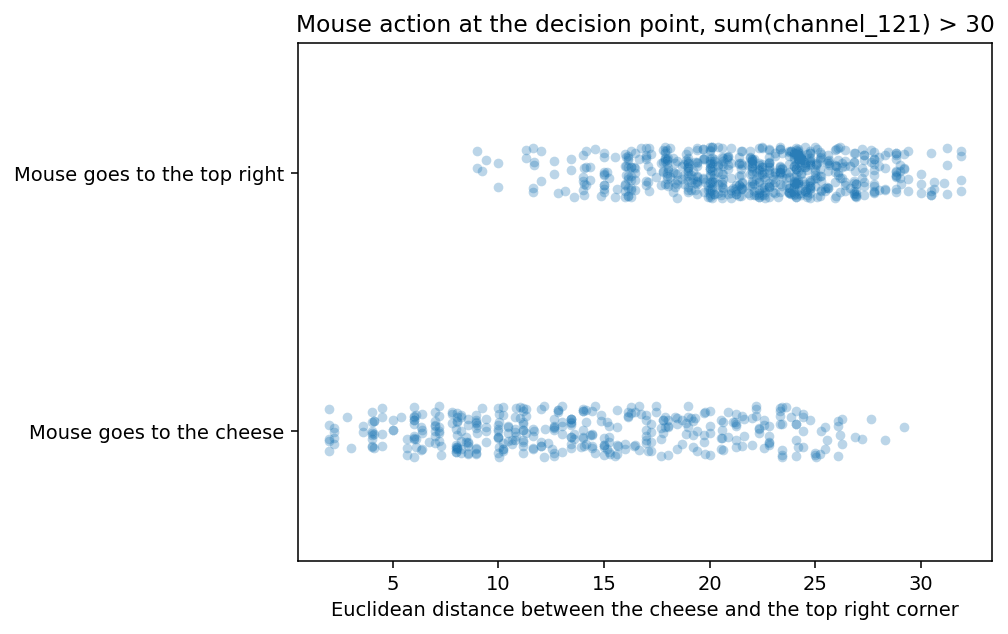
{kind=link}
We see that the further the cheese is from the top right corner, the lower the chance channel 121 shows the path to the cheese. This is consistent with the behavioural statistics [? · GW].
Other channels
Channel 73
Data for (73, "go right") is so similar to (121, "go up") that I triple-checked if I'm not computing the same thing twice. Up and right are fully symmetrical in the environment, so this should not be a big surprise, but such similarities are not common in neural networks.
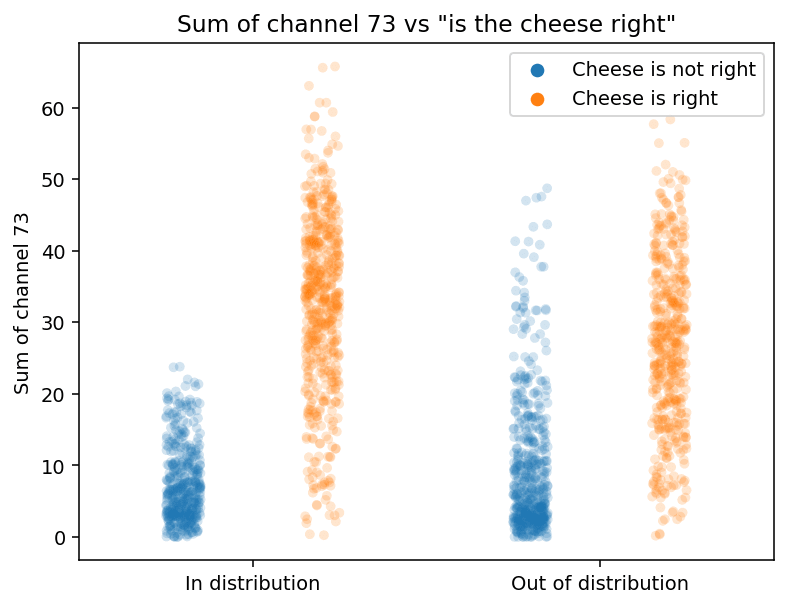
The sum of channel 73 > 30, mouse on the decision square, in distribution:
| Cheese is RIGHT | Top right corner is RIGHT | |
| Mouse goes RIGHT | 98 | 0 |
| Mouse goes not RIGHT | 0 | 2 |
The same, out of distribution:
| Cheese is RIGHT | Top right corner is RIGHT | |
| Mouse goes RIGHT | 33 | 65 |
| Mouse goes not RIGHT | 0 | 2 |
Impact of the distance between the cheese and the top right:
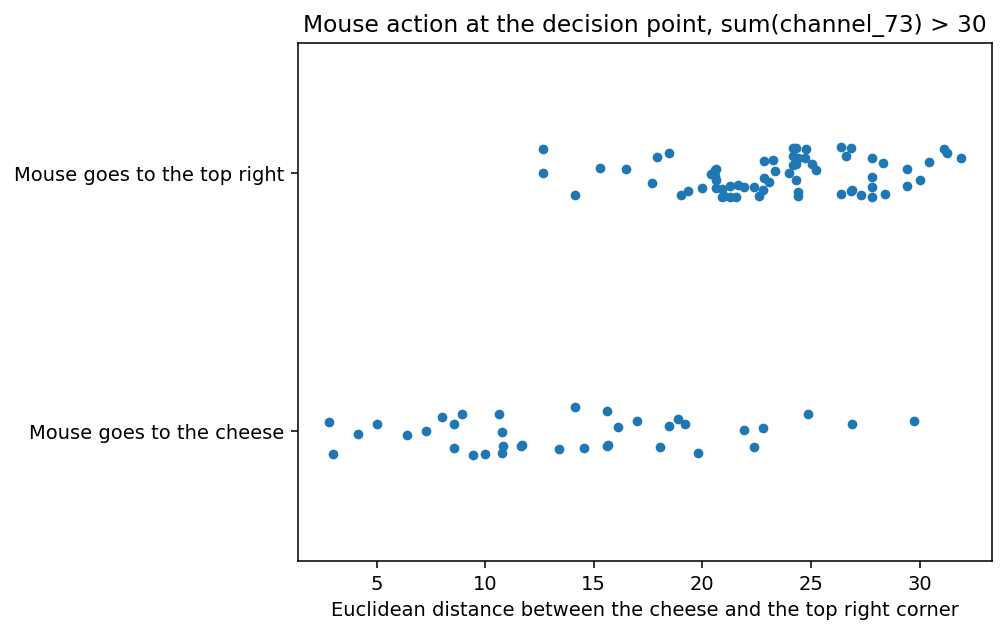
Channel 21
The sum of channel 21 activations for different environments:
| | | | |
| 0.0 | 0.8 | 0.0 | 34.5 | |
| | | | |
| 28.3 | 22.8 | 32.1 | 0.6 |
A high value of this channel seems to be "go down or go left".
Top 10 channels
Here are a few other channels and their interpretations based on the same comparison as for channel 21 above, ordered by the effect size.
| 121 | UP |
| 21 | DOWN or LEFT |
| 80 | LEFT (middle values DOWN?) |
| 35 | UP or LEFT |
| 112 | LEFT |
| 73 | RIGHT |
| 71 | UP |
| 7 | UP or RIGHT |
| 123 | DOWN |
| 17 | DOWN |
I didn't check if all these interpretations generalize to random mazes, but they do generalize for channels 121 and 73 (and they were not cherry-picked).
What happens if I zero a lot of channels
I selected 16 channels that seem the most important from the point of view of the original pair of environments (in the Methods section). This is a vector field difference between the original policy and a policy with these 16 channels zeroed[10] (if the plot is unclear, consult the cheese vector post [LW · GW]).
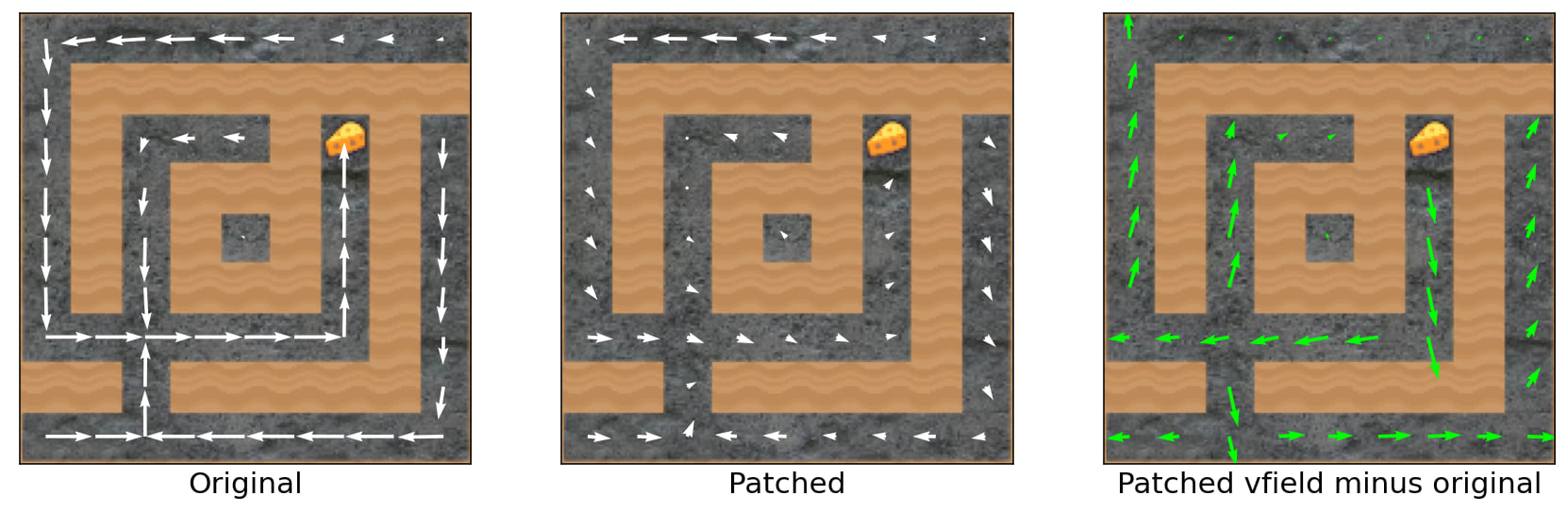
On the one hand, zeroing these 16 channels changes a lot, but on the other hand - the mouse would still go to the cheese and not to the top right. I think the only takeaway here is that even though we have some channels with straightforward interpretation, information is distributed between lots of different channels (that's not a surprise).
Notes on the maze generator
There are some known constraints on the mazes - they are squares with odd sizes, the bottom left and top right corners are always corridors, they are simply connected (i.e. no loops/islands), and there are no inaccessible sections. When you watch random mazes long enough (a week in my case), you might also notice that:
- All (even, even) squares are always corridors
- All (odd, odd) squares are always walls
- As a consequence, there are a lot of correlations in the structure of the maze. E.g. if you know that (1, 0) and (2, 1) are walls, then (3, 0) must be a corridor.
- As a consequence, when you are on an (odd, even) square, you can move up or down, and when you are on an (even, odd) square, you can move left or right.
This doesn't look that important at first glance, but:
- Maybe "mouse in a random maze" is a somewhat different problem than "mouse in a maze with 50% of squares random"?
- Maybe the model has separate circuits for (odd, even) and (even, odd) squares?
- Maybe there would be no channel with a clear "go up" interpretation in a more random maze?
- And more generally: are the natural abstractions [? · GW] in this sort of an environment the same as natural abstractions in "just a random fully connected maze"?
I think some of this might matter if we are ever to try full mech interp on this model, but I also consider this a general lesson that one should carefully analyse the exact world a model operates in.
- ^
Generate a bunch of random mazes, make a forward pass on them and for every activation calculate the standard deviation (or some other similar metric), and compare it to the difference in this particular case.
- ^
This channel has the strongest effect but is not unique. I briefly analyse other channels in the appendix.
- ^
This is the output of a
ReLUlayer -> there are no negative values -> simple sum makes sense. - ^
A natural question: this is a convolution, why look at the sum only, ignoring the spatial structure? Answer: I checked the spatial structure, and the only pattern I found is "high values happen only around the mouse location", and I don't think this matters from the point of view of what I'm trying to do.
- ^
Size 25 x 25, mouse in a random square where move UP is legal, 1000 mazes in distribution (i.e. with cheese in the top right 5x5), 1000 mazes out of distribution.
- ^
There is no column "neither cheese nor top right corner is up" because this just never happened for this subset of mazes.
- ^
Note: the extreme difference between these two tables should probably be discounted by the fact that in distribution decision square is, on average, closer to the cheese/top right than out of distribution - I didn't control for that.
- ^
Also, this time maze is 15 x 15. This is because on 25 x 25 mazes with cheese in the bottom right corner success rate is extremely low. Channels in layer
relu3have the same interpretation for mazes of different sizes. - ^
A wild guess why this might be the case: during the training, the mouse first learned to go to the top right corner as a proxy goal and then started to update towards "go to the cheese", and once it updated enough to achieve 100% accuracy we stopped the training - but the old goal was not fully purged.
- ^
Zeroing makes sense for channels like 121 or 21 because they often have values close to 0 in normal activations. But there are also important channels that never go down to 0 (e.g. 7 has a value range between ~ 20 and 55) - setting them to 0 doesn't make much sense -> this test is not very good.
2 comments
Comments sorted by top scores.
comment by TurnTrout · 2023-09-07T17:56:05.286Z · LW(p) · GW(p)
This is really cool. Great followup work!
I think this is enough to make a hypothesis on how the network works and how the goal misgeneralization happens:
- Somewhere inside the model, there is a set of individual components that respond to different inputs, and when they activate, they push for a particular action. Channel 121 is an example of such a component.
- The last layers somehow aggregate information from all of the individual components.
- Components sometimes activate for the action that leads to the cheese and sometimes for the action that leads to the top right corner.[9] [LW(p) · GW(p)]
- If the aggregated "push" for the action leading to the cheese is higher than for the action leading to the top right corner, the mouse goes to the cheese. Otherwise, it goes to the top right corner.
I think this is basically a shard theory picture/framing of how the network works: Inside the model there are multiple motivational circuits ("shards") which are contextually activated (i.e. step 3) and whose outputs are aggregated into a final decision (i.e. step 4).
Replies from: jan-betley↑ comment by Jan Betley (jan-betley) · 2023-10-16T18:52:40.155Z · LW(p) · GW(p)
Thanks! Indeed, shard theory fits here pretty well. I didn't think about that while writing the post.