Posts
Comments
Good resource: https://dynalist.io/d/n2ZWtnoYHrU1s4vnFSAQ519J <- Neel Nanda's glossary.
> What is a feature?
Often gets confused because early literature doesn't distinguish well between property of the input represented by a model and the internal representation. We tend to refer to the former as a feature and the latter as a latent these days. Eg: "Not all Language Model Features are Linear" => not all the representations are linear (and is not a statement about what gets represented).
> Are there different circuits that appear in a network based on your definition of what a relevant feature is?
This question seems potentially confusing. If you use different methods (eg: supervised vs unsupervised) you are likely to find different results. Eg: In a paper I supervised here https://arxiv.org/html/2409.14507v2 we looked at how SAEs compared to Linear probes. This was a comparison of methods for finding representations. I don't know of any work doing circuit finding with multiple feature finding methods though (but I'd be excited about it).
> How crisp are these circuits that appear, both in toy examples and in the wild?
Read ACDC. https://arxiv.org/abs/2304.14997 . Generally, not crisp.
> What are the best examples of "circuits in the wild" that are actually robust?
The ARENA curriculum probably covers a few. there might be some papers comparing circuit finding methods that use a standard set of circuits you could find.
> If I have a tiny network trained on an algorithmic task, is there an automated search method I can use to identify relevant subgraphs of the neural network doing meaningful computation in a way that the circuits are distinct from each other?
Interesting question. See Neel's thoughts here: https://www.neelnanda.io/mechanistic-interpretability/othello#finding-modular-circuits
> Does this depend on training?
Probably yes. Probably also on how the different tasks relate to each other (whether they have shareable intermediate results).
> (Is there a way to classify all circuits in a network (or >10% of them) exhaustively in a potentially computationally intractable manner?)
I don't know if circuits are a good enough description of reality for this to be feasible. But you might find this interesting https://arxiv.org/abs/2501.14926
Oh interesting! Will make a note to look into this more.
Jan shared with me! We're excited about this direction :)
Cool work! I'd be excited to see whether latents found via this method are higher quality linear classifiers when they appear to track concepts (eg: first letters) and also if they enable us to train better classifiers over model internals than other SAE architectures or linear probes (https://transformer-circuits.pub/2024/features-as-classifiers/index.html).
Cool work!
Have you tried to generate autointerp of the SAE features? I'd be quite excited about a loop that does the following:
- take an SAE feature, get the max activating examples.
- Use a multi-modal model, maybe Claude, to do autointerp via images of each of the chess positions (might be hard but with the right prompt seems doable).
- Based on a codebase that implements chess logic which can be abstracted away (eg: has functions that take a board state and return whether or not statements are true like "is the king in check?"), get a model to implement a function that matches it's interpretation of the feature.
- Use this to generate a labelled dataset on which you then train a linear probe.
- Compare the probe activations to the feature activations. In particular, see whether you can generate a better automatic interpretation of the feature if you prompt with examples of where it differs from the probe.
I suspect this is nicer than language modelling in that you can programmatically generate your data labels from explanations rather than relying on LMs. Of course you could just a priori decide what probes to train but the loop between autointerp and next probe seems cool to me. I predict that current SAE training methods will result in long description lengths or low recall and the tradeoff will be poor.
Great work! I think this a good outcome for a week at the end of ARENA (Getting some results, publishing them, connecting with existing literature) and would be excited to see more done here. Specifically, even without using an SAE, you could search for max activating examples for each steering vectors you found if you use it as an encoder vector (just take dot product with activations).
In terms of more serious followup, I'd like to much better understand what vectors are being found (eg by comparing to SAEs or searching in the SAE basis with a sparsity penalty), how much we could get out of seriously scaling this up and whether we can find useful applications (eg: is this a faster / cheaper way to elicit model capabilities such as in the context of sandbagging).
I think that's exactly what we did? Though to be fair we de-emphasized this version of the narrative in the paper: We asked whether Gemma-2-2b could spell / do the first letter identification task. We then asked which latents causally mediated spelling performance, comparing SAE latents to probes. We found that we couldn't find a set of 26 SAE latents that causally mediated spelling because the relationship between the latents and the character information, "exogenous factors", if I understand your meaning, wasn't as clear as it should have been. As I emphasized in a different comment, this work is not about mechanistic anomalies or how the model spells, it's about measurement error in the SAE method.
This thread reminds me that comparing feature absorption in SAEs with tied encoder / decoder weights and in end-to-end SAEs seems like valuable follow up.
Thanks Egg! Really good question. Short answer: Look at MetaSAE's for inspiration.
Long answer:
There are a few reasons to believe that feature absorption won't just be a thing for graphemic information:
- People have noticed SAE latent false negatives in general, beyond just spelling features. For example this quote from the Anthropic August update. I think they also make a comment about feature coordination being important in the July update as well.
If a feature is active for one prompt but not another, the feature should capture something about the difference between those prompts, in an interpretable way. Empirically, however, we often find this not to be the case – often a feature fires for one prompt but not another, even when our interpretation of the feature would suggest it should apply equally well to both prompts.
- MetaSAEs are highly suggestive of lots of absorption. Starts with letter features are found by MetaSAEs along with lots of others (my personal favorite is a " Jerry" feature on which a Jewish meta-feature fires. I won't what that's about!?) 🤔
- Conceptually, being token or character specific doesn't play a big role. As Neel mentioned in his tweet here, once you understand the concept, it's clear that this is a strategy for generating sparsity in general when you have this kind of relationship between concepts. Here's a latent that's a bit less token aligned in the MetaSAE app which can still be decomposed into meta-latents.
In terms of what I really want to see people look at: What wasn't clear from Meta-SAEs (which I think is clearer here) is that absorption is important for interpretable causal mediation. That is, for the spelling task, absorbing features look like a kind of mechanistic anomaly (but is actually an artefact of the method) where the spelling information is absorbed. But if we found absorption in a case where we didn't know the model knew a property of some concept (or we didn't know it was a property), but saw it in the meta-SAE, that would be very cool. Imagine seeing attribution to a latent tracking something about a person, but then the meta-latents tell you that the model was actually leveraging some very specific fact about that person. This might really important for understanding things like sycophancy...
Great work! Using spelling is very clear example of how information gets absorbed in the SAE latent, and indeed in Meta-SAEs we found many spelling/sound related meta-latents.
Thanks! We were sad not to have time to try out Meta-SAEs but want to in the future.
I have been thinking a bit on how to solve this problem and one experiment that I would like to try is to train an SAE and a meta-SAE concurrently, but in an adversarial manner (kind of like a GAN), such that the SAE is incentivized to learn latent directions that are not easily decomposable by the meta-SAE.
Potentially, this would remove the "Starts-with-L"-component from the "lion"-token direction and activate the "Starts-with-L" latent instead. Although this would come at the cost of worse sparsity/reconstruction.
I think this is the wrong way to go to be honest. I see it as doubling down on sparsity and a single decomposition, both of which I think may just not reflect the underlying data generating process. Heavily inspired by some of John Wentworth's ideas here.
Rather than doubling down on a single single-layered decomposition for all activations, why not go with a multi-layered decomposition (ie: some combination of SAE and metaSAE, preferably as unsupervised as possible). Or alternatively, maybe the decomposition that is most useful in each case changes and what we really need is lots of different (somewhat) interpretable decompositions and an ability to quickly work out which is useful in context.
It seems that PIBBSS might be pivoting away from higher variance blue sky research to focus on more mainstream AI interpretability. While this might create more opportunities for funding, I think this would be a mistake. The AI safety ecosystem needs a home for “weird ideas” and PIBBSS seems the most reputable, competent, EA-aligned place for this! I encourage PIBBSS to “embrace the weird,” albeit while maintaining high academic standards for basic research, modelled off the best basic science institutions.
I was a recent PIBBSS mentor, and am a mech interp person who is likely to be considered mainstream by many people and for this reason I wanted to push back on this concern.
A few thoughts:
- I don't want to put words in your mouth but I do want to clarify that we shouldn't conflate having some mainstream mech interp and being only mech interp. Importantly, to my knowledge, there is very little chance of PIBBSS entirely doing mech interp, and so I think the salient question is should they have "a bit" (say 5-10% of scholars) do mech interp (which is likely more than they used to). I would advocate for a steady state proportion of between 10 - 20%, see further points for detail).
- In my opinion, the word "mainstream" suggests redundancy and brings to mind the idea that "well this could just be done at MATS". There are two reasons I think this is inaccurate.
- First, PIBBSS is likely to accept mentees who may not get into MATS / similar programs. Mentees with diverse background and possibly different skillsets. In my opinion, this kind of diversity can be highly valuable and bring new perspectives to mech interp (which is a pre-paradigmatic field in need of new takes). I'm moderately confident that to the extent existing programs are highly selective, we should expect diversity to suffer in them (if you take the top 10% by metrics like competence, you're less likely to get the top 10% by diversity of intellectual background).
- Secondly, I think there's a statistical term for this but I forget what it is. PIBBSS being a home for weird ideas in mech interp as much as weird ideas in other areas of AI safety seems entirely reasonable to me.
- I also think that even some mainstream mech interp (and possible other areas like evals) should be a part of PIBBSS because it enriches the entire program:
- My experience of the PIBBSS retreat and subsequent interactions suggests that a lot of value is created by having people who do empirical work interact with people who do more theoretical work. Empiricists gain ideas and perspective from theorists and theoretical researchers are exposed to more real world observations second hand.
- I weakly suspect that some debates / discussions in AI safety may be lopsided / missing details via the absence of sub-fields. In my opinion it's valuable to sometimes mix up who is in the room but likely worse in expectation to always remove mech interp people (hence my advocacy for 10 - 20% empiricists, with half of them being interp).
Some final notes:
- I'm happy to share details of the work my scholar and I did which we expect to publish in the next month.
- I'll be a bit forward and suggest that if you (Ryan) or any other funders find the arguments above convincing then it's possible you might want to further PIBBSS and ask Nora how PIBBSS can source a bit more "weird" mech interp, a bit of mainstream mech interp and some other empirical sub-fields for the program.
I'll share this in the PIBBSS slack to see if other's want to comment :)
Good work! I'm sure you learned a lot while doing this and am a big fan of people publishing artifacts produced during upskilling. ARENA just updated it's SAE content so that might also be a good next step for you!
7B parameter PM
@Logan Riggs this link doesn't work for me.
Thanks for writing this up. A few points:
- I generally agree with most of the things you're saying and am excited about this kind of work. I like that you endorse empirical investigations here and think there are just far fewer people doing these experiments than anyone thinks.
- Structure between features seems like the under-dog of research agendas in SAE research (which I feel I can reasonably claim to have been advocating for in many discussions over the preceding months). Mainly I think it presents the most obvious candidate for reducing the description length issue with larger SAEs.
- I'm working on a project looking into this (and am aware of several others) but I don't think this should deter people who are interested from playing around. It's fairly easy to get going on these projects using my library and neuronpedia.
For example, it seems hard to understand how a tree-like structure could explain circular features.
Tree structure between features is easy to find, with hierarchical clustering providing a degree of insight into the feature space that is not achieved by other methods like U-MAP. I would interpret this as a kind of "global structure" whereas day of the week geometry is probably more local. It seems totally plausible that a tree is a reasonable characterisation of structure at a high level without being a perfect characterisation.
The days of the week/months of the year lie on a circle, in order. Let’s be clear about what the interesting finding is from Engels et al.: it’s not that all the days of the week have high cosine sim with each other, or even really that they live in a subspace, but that they are in order!
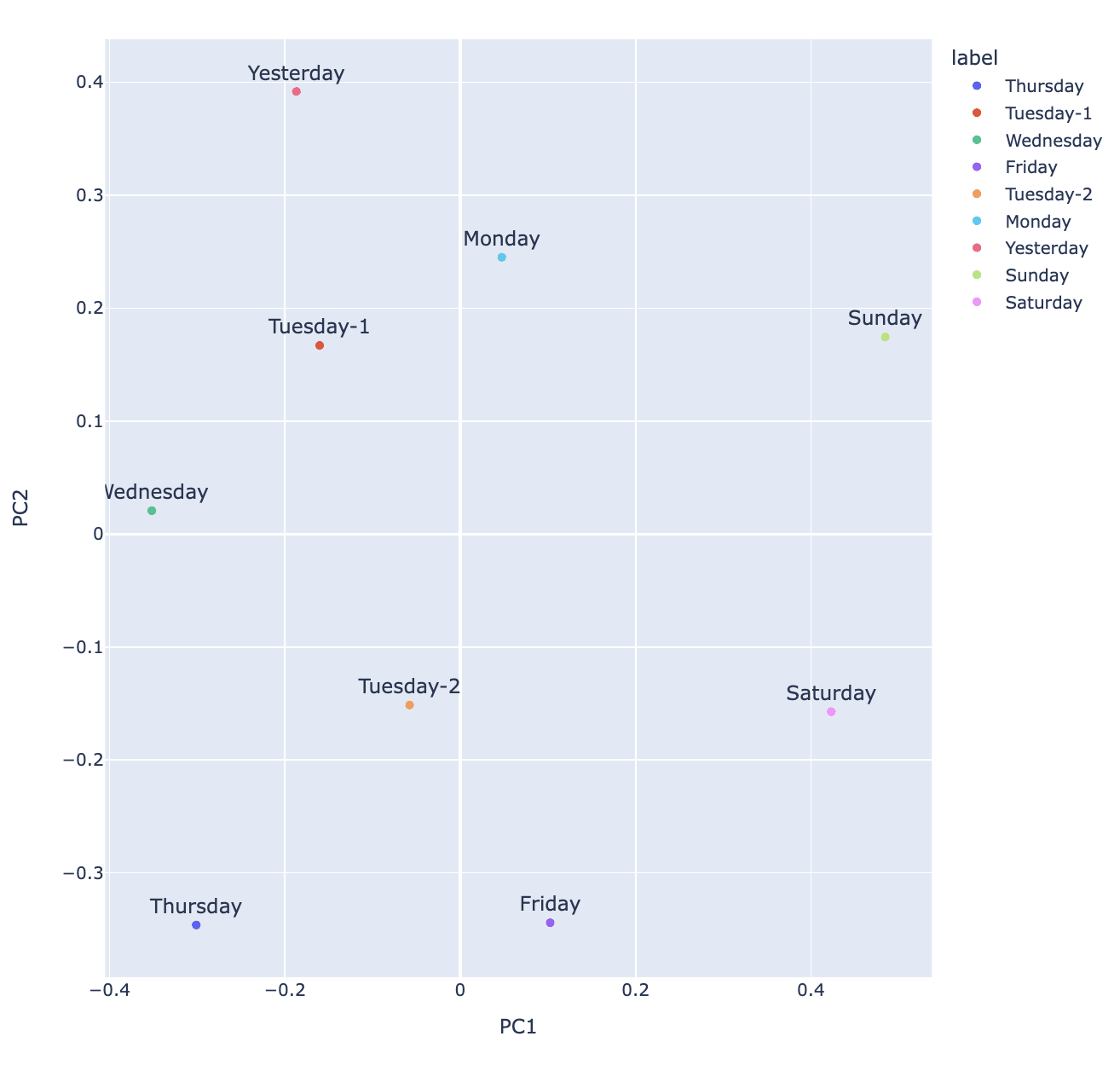
I think another part of the result here was that the PCA of the lower dimensional space spanned by the day of the week features was much clearer in showing the geometry than simply doing PCA over the decoder weights (see below). I double checked this just now and you can actually get the correct ordering just on the features but it's much less obvious what's happening (imo). If you look at these features, they also tend to fire on days of multiple days of the week with different strengths. The lesson here is that co-occurence of feature may matter a lot in particular subspaces.
Layer 7-GPT2 small. Decoder weight PCA on day of the features. Feature labels come from max activating examples. See dashboards here.
Maybe we should make fake datasets for this? Neurons often aren't that interpretable and we're still confused about SAE features a lot of the time. It would be nice to distinguish "can do autointerp | interpretable generating function of complexity x" from "can do autointerp".
SAEs are model specific. You need Pythia SAEs to investigate Pythia. I don't have a comprehensive list but you can look at the sparse autoencoder tag on LW for relevant papers.
Thanks Joel. I appreciated this. Wish I had time to write my own version of this. Alas.
Previously I’ve seen the rule of thumb “20-100 for most models”. Anthropic says:
We were saying this and I think this might be an area of debate in the community for a few reasons. It could be that the "true L0" is actually very high. It could be that low activating features aren't contributing much to your reconstruction and so aren't actually an issue in practice. It's possible the right L1 or L0 is affected by model size, context length or other details which aren't being accounted for in these debates. A thorough study examining post-hoc removal of low activating or low norm features could help. FWIW, it's not obvious to me that L0 should be lower / higher and I think we should be careful not to cargo-cult the stat. Probably we're not at too much risk here since we're discussing this out in the open already.
Having multiple different-sized SAEs for the same model seems useful. The dashboard shows feature splitting clearly. I hadn’t ever thought of comparing features from different SAEs using cosine similarity and plotting them together with UMAP.
Different SAEs, same activations. Makes sense since it's notionally the same vector space. Apollo did this recently when comparing e2e vs vanilla SAEs. I'd love someone to come up with better measures of U-MAP quality as the primary issue with them is the risk of arbitrariness.
Neither of these plots seems great. They both suggest to me that these SAEs are “leaky” in some sense at lower activation levels, but in opposite ways:
This could be bad. Could also be that the underlying information is messy and there's interference or other weird things going on. Not obvious that it's bad measurement as opposed to messy phenomena imo. Trying to distinguish the two seems valuable.
4. On Scaling
Yup. Training simultaneously could be good. It's an engineering challenge. I would reimplement good proofs of concept that suggest this is feasible and how to do it. I'd also like to point out that this isn't the first time a science has had this issue.
On some level I think this challenge directly parallels bioinformatics / gene sequencing. They needed a human genome project because it was expensive and ambitious and individual actors couldn't do it on their own. But collaborating is hard. Maybe EA in particular can get the ball rolling here faster than it might otherwise. The NDIF / Bau Lab might also be a good banner to line up behind.
I didn’t notice many innovations here -- it was mostly scaling pre-existing techniques to a larger model than I had seen previously. The good news is that this worked well. The bad news is that none of the old challenges have gone away.
Agreed. I think the point was basically scale. Criticisms along the lines of "this is tackling the hard part of the problem or proving interp is actually useful" are unproductive if that wasn't the intention. Anthropic has 3 teams now and counting doing this stuff. They're definitely working on a bunch of harder / other stuff that maybe focuses on the real bottlenecks.
All young people and other newcomers should be made aware that on-paradigm AI safety/alignment--while being more tractable, feedbacked, well-resourced, and populated compared to theory--is also inevitably streetlighting https://en.wikipedia.org/wiki/Streetlight_effect.
Half-agree. I think there's scope within field like interp to focus on things that are closer to the hard part of the problem or at least touch on robust bottlenecks for alignment agendas (eg: ontology identification). I do think there is a lot of diversity in people working in these more legible areas and that means there are now many people who haven't engaged with or understood the alignment problem well enough to realise where we might be suffering from the street light effect.
I think so, but expect others to object. I think many people interested in circuits are using attn and MLP SAEs and experimenting with transcoders and SAE variants for attn heads. Depends how much you care about being able to say what an attn head or MLP is doing or you're happy to just talk about features. Sam Marks at the Bau Lab is the person to ask.
Neuronpedia has an API (copying from a recent message Johnny wrote to someone else recently.):
"Docs are coming soon but it's really simple to get JSON output of any feature. just add "/api/feature/" right after "neuronpedia.org".for example, for this feature: https://neuronpedia.org/gpt2-small/0-res-jb/0
the JSON output of it is here: https://www.neuronpedia.org/api/feature/gpt2-small/0-res-jb/0
(both are GET requests so you can do it in your browser)note the additional "/api/feature/"i would prefer you not do this 100,000 times in a loop though - if you'd like a data dump we'd rather give it to you directly."
Feel free to join the OSMI slack and post in the Neuronpedia or Sparse Autoencoder channels if you have similar questions in the future :) https://join.slack.com/t/opensourcemechanistic/shared_invite/zt-1qosyh8g3-9bF3gamhLNJiqCL_QqLFrA
I'm a little confused by this question. What are you proposing?
Lots of thoughts. This is somewhat stream of consciousness as I happen to be short on time this week, but feel free to follow up again in the future:
- Anthropic tested their SAEs on a model with random weights here and found that the results look noticeably different in some respects to SAEs trained on real models "The resulting features are here, and contain many single-token features (such as "span", "file", ".", and "nature") and some other features firing on seemingly arbitrary subsets of different broadly recognizable contexts (such as LaTeX or code)." I think further experiments like this which identify classes of features which are highly non-trivial, don't occur in SAEs trained on random models (or random models with a W_E / W_U from a real model) or which can be related to interpretable circuity would help.
- I should not that, to the extent that SAEs could be capturing structure in the data, the model might want to capture structure in the data too, so it's not super clear to me what you would observe that would distinguish SAEs capturing structure in the data which the model itself doesn't utilise. Working this out seems important.
- Furthermore, the embedding space of LLM's is highly structured already and since we lack good metrics, it's hard to say how precisely SAE's capture "marginal" structure over existing methods. So quantifying what we mean by structure seems important too.
- The specific claim that SAEs learn features which are combinations of true underlying features is a reasonable one given the L1 penalty, but I think it's far from obvious how we should think about this in practice.
- I'm pretty excited about deliberate attempts to understand where SAEs might be misleading or not capturing information well (eg: here or here). It seems like there are lots of technical questions that are slightly more low level that help us build up to this.
So in summary: I'm a bit confused about what we mean here and think there are various technical threads to follow up on. Knowing which actually resolve this requires we try to define our terms here more thoroughly.
Thanks for asking:
- Currently we load SAEs into my codebase here. How hard this is will depend on how different your SAE architecture/forward pass is from what I currently support. We're planning to support users / do this ourselves for the first n users and once we can, we'll automate the process. So feel free to link us to huggingface or a public wandb artifact.
- We run the SAEs over random samples from the same dataset on which the model was trained (with activations drawn from forward passes of the same length). Callum's SAE vis codebase has a demo where you can see how this works.
- Since we're doing this manually, the delay will depend on the complexity on handling the SAEs and things like whether they're trained on a new model (not GPT2 small) and how busy we are with other people's SAEs or other features. We'll try our best and keep you in the loop. Ballpark is 1 -2 weeks not months. Possibly days (especially if the SAEs are very similar to those we are hosting already). We expect this to be much faster in the future.
We've made the form in part to help us estimate the time / effort required to support SAEs of different kinds (eg: if we get lots of people who all have SAEs for the same model or with the same methodological variation, we can jump on that).
It helps a little but I feel like we're operating at too high a level of abstraction.
with the mech interp people where they think we can identify values or other high-level concepts like deception simply by looking at the model's linear representations bottom-up, where I think that'll be a highly non-trivial problem.
I'm not sure anyone I know in mech interp is claiming this is a non-trivial problem.
biological and artificial neural-networks are based upon the same fundamental principles
I'm confused by this statement. Do we know this? Do we have enough of an understanding of either to say this? Don't get me wrong, there's some level on which I totally buy this. However, I'm just highly uncertain about what is really being claimed here.
Depending on model size I'm fairly confident we can train SAEs and see if they can find relevant features (feel free to dm me about this).
Thanks for posting this! I've had a lot of conversations with people lately about OthelloGPT and I think it's been useful for creating consensus about what we expect sparse autoencoders to recover in language models.
Maybe I missed it but:
- What is the performance of the model when the SAE output is used in place of the activations?
- What is the L0? You say 12% of features active so I assume that means 122 features are active.This seems plausibly like it could be too dense (though it's hard to say, I don't have strong intuitions here). It would be preferable to have a sweep where you have varying L0's, but similar explained variance. The sparsity is important since that's where the interpretability is coming from. One thing worth plotting might be the feature activation density of your SAE features as compares to the feature activation density of the probes (on a feature density histogram). I predict you will have features that are too sparse to match your probe directions 1:1 (apologies if you address this and I missed this).
- In particular, can you point to predictions (maybe in the early game) where your model is effectively perfect and where it is also perfect with the SAE output in place of the activations at some layer? I think this is important to quantify as I don't think we have a good understanding of the relationship between explained variance of the SAE and model performance and so it's not clear what counts as a "good enough" SAE.
I think a number of people expected SAEs trained on OthelloGPT to recover directions which aligned with the mine/their probe directions, though my personal opinion was that besides "this square is a legal move", it isn't clear that we should expect features to act as classifiers over the board state in the same way that probes do.
This reflects several intuitions:
- At a high level, you don't get to pick the ontology. SAEs are exciting because they are unsupervised and can show us results we didn't expect. On simple toy models, they do recover true features, and with those maybe we know the "true ontology" on some level. I think it's a stretch to extend the same reasoning to OthelloGPT just because information salient to us is linearly probe-able.
- Just because information is linearly probeable, doesn't mean it should be recovered by sparse autoencoders. To expect this, we'd have to have stronger priors over the underlying algorithm used by OthelloGPT. Sure, it must us representations which enable it to make predictions up to the quality it predicts, but there's likely a large space of concepts it could represent. For example, information could be represented by the model in a local or semi-local code or deep in superposition. Since the SAE is trying to detect representations in the model, our beliefs about the underlying algorithm should inform our expectations of what it should recover, and since we don't have a good description of the circuits in OthelloGPT, we should be more uncertain about what the SAE should find.
- Separately, it's clear that sparse autoencoders should be biased toward local codes over semi-local / compositional codes due to the L1 sparsity penalty on activations. This means that even if we were sure that the model represented information in a particular way, it seems likely the SAE would create representations for variables like (A and B) and (A and B') in place of A even if the model represents A. However, the exciting thing about this intuition is it makes a very testable prediction about combinations of features likely combining to be effective classifiers over the board state. I'd be very excited to see an attempt to train neuron-in-a-haystack style sparse probes over SAE features in OthelloGPT for this reason.
Some other feedback:
- Positive: I think this post was really well written and while I haven't read it in more detail, I'm a huge fan of how much detail you provided and think this is great.
- Positive: I think this is a great candidate for study and I'm very interested in getting "gold-standard" results on SAEs for OthelloGPT. When Andy and I trained them, we found they could train in about 10 minutes making them a plausible candidate for regular / consistent methods benchmarking. Fast iteration is valuable.
- Negative: I found your bolded claims in the introduction jarring. In particular "This demonstrates that current techniques for sparse autoencoders may fail to find a large majority of the interesting, interpretable features in a language model". I think this is overclaiming in the sense that OthelloGPT is not toy-enough, nor do we understand it well enough to know that SAEs have failed here, so much as they aren't recovering what you expect. Moreover, I think it would best to hold-off on proposing solutions here (in the sense that trying to map directly from your results to the viability of the technique encourages us to think about arguments for / against SAEs rather than asking, what do SAEs actually recover, how do neural networks actually work and what's the relationship between the two).
- Negative: I'm quite concerned that tieing the encoder / decoder weights and not having a decoder output bias results in worse SAEs. I've found the decoder bias initialization to have a big effect on performance (sometimes) and so by extension whether or not it's there seems likely to matter. Would be interested to see you follow up on this.
Oh, and maybe you saw this already but an academic group put out this related work: https://arxiv.org/abs/2402.12201 I don't think they quantify the proportion of probe directions they recover, but they do indicate recovery of all types of features that been previously probed for. Likely worth a read if you haven't seen it.
I think we got similar-ish results. @Andy Arditi was going to comment here to share them shortly.
@LawrenceC Nanda MATS stream played around with this as group project with code here: https://github.com/andyrdt/mats_sae_training/tree/othellogpt
@Evan Anders "For each feature, we find all of the problems where that feature is active, and we take the two measurements of “feature goodness" <- typo?
added a link at the top.
My mental model is the encoder is working hard to find particular features and distinguish them from others (so it's doing a compressed sensing task) and that out of context it's off distribution and therefore doesn't distinguish noise properly. Positional features are likely a part of that but I'd be surprised if it was most of it.
I've heard this idea floated a few times and am a little worried that "When a measure becomes a target, it ceases to be a good measure" will apply here. OTOH, you can directly check whether the MSE / variance explained diverges significantly so at least you can track the resulting SAE's use for decomposition. I'd be pretty surprised if an SAE trained with this objective became vastly more performant and you could check whether downstream activations of the reconstructed activations were off distribution. So overall, I'm pretty excited to see what you get!
problems
prompts*
This means they're somewhat problematic for OOD use cases like treacherous turn detection or detecting misgeneralization.
I kinda want to push back on this since OOD in behavior is not obviously OOD in the activations. Misgeneralization especially might be better thought of as an OOD environment and on-distribution activations?
I think we should come back to this question when SAEs have tackled something like variable binding with SAEs. Right now it's hard to say how SAEs are going to help us understand more abstract thinking and therefore I think it's hard to say how problematic they're going to be for detecting things like a treacherous turn. I think this will depend on how how representations factor. In the ideal world, they generalize with the model's ability to generalize (Apologies for how high level / vague that idea is).
Some experiments I'd be excited to look at:
- If the SAE is trained on a subset of the training distribution, can we distinguish it being used to decompose activations on those data points off the training distribution?
- How does that compare to an SAE trained on the whole training distribution from the model, but then looking at when the model is being pushed off distribution?
I think I'm trying to get at - can we distinguish:
- Anomalous activations.
- Anomalous data points.
- Anomalous mechanisms.
Lots of great work to look forward to!
Why do you want to refill and shuffle tokens whenever 50% of the tokens are used?
Neel was advised by the authors that it was important minimise batches having tokens from the same prompt. This approach leads to a buffer having activations from many different prompts fairly quickly.
Is this just tokens in the training set or also the test set? In Neel's code I didn't see a train/test split, isn't that important?
I never do evaluations on tokens from prompts used in training, rather, I just sample new prompts from the buffer. Some library set aside a set of tokens to do evaluations on which are re-used. I don't currently do anything like this but it might be reasonable. In general, I'm not worried about overfitting.
Also, can you track the number of epochs of training when using this buffer method (it seems like that makes it more difficult)?
Epochs in training makes sense in a data-limited regime which we aren't in. OpenWebText has way more tokens than we ever train any sparse autoencoder on so we're always on way less than 1 epoch. We never reuse the same activations when training, but may use more than one activation from the same prompt.
Awesome work! I'd be quite interested to know whether the benefits from this technique are equivalently significant with a larger SAE and also what the original perplexity was (when looking at the summary statistics table). I'll probably reimplement at some point.
Also, kudos on the visualizations. Really love the color scales!
On wandb, the dashboards were randomly sampled but we've since uploaded all features to Neuronpedia https://www.neuronpedia.org/gpt2-small/res-jb. The log sparsity is stored in the huggingface repo so you can look for the most sparse features and check if their dashboards are empty or not (anecdotally most dashboards seem good, beside the dead neurons in the first 4 layers).
24, 576 prompts of length 128 = 3, 145, 728.
With features that fire less frequently this won't be enough, but for these we seemed to find some activations (if not highly activating) for all features.
Makes sense. Will set off some runs with longer context sizes and track this in the future.
Ahhh I see. Sorry I was way too hasty to jump at this as the explanation. Your code does use the tied decoder bias (and yeah, it was a little harder to read because of how your module is structured). It is strange how assuming that bug seemed to help on some of the SAEs but I ran my evals over all your residual stream SAE's and it only worked for some / not others and certainly didn't seem like a good explanation after I'd run it on more than one.
I've been talking to Logan Riggs who says he was able to load in my SAEs and saw fairly similar reconstruction performance to to me but that outside of the context length of 128 tokens, performance markedly decreases. He also mentioned your eval code uses very long prompts whereas mine limits to 128 tokens so this may be the main cause of the difference. Logan mentioned you had discussed this with him so I'm guessing you've got more details on this than I have? I'll build some evals specifically to look at this in the future I think.
Scientifically, I am fairly surprised about the token length effect and want to try training on activations from much longer context sizes now. I have noticed (anecdotally) that the number of features I get sometimes increases over the prompt so an SAE trained on activations from shorter prompts are plausibly going to have a much easier time balancing reconstruction and sparsity, which might explain the generally lower MSE / higher reconstruction. Though we shouldn't really compare between models and with different levels of sparsity as we're likely to be at different locations on the pareto frontier.
One final note is that I'm excited to see whether performance on the first 128 tokens actually improves in SAEs trained on activations from > 128 token forward passes (since maybe the SAE becomes better in general).
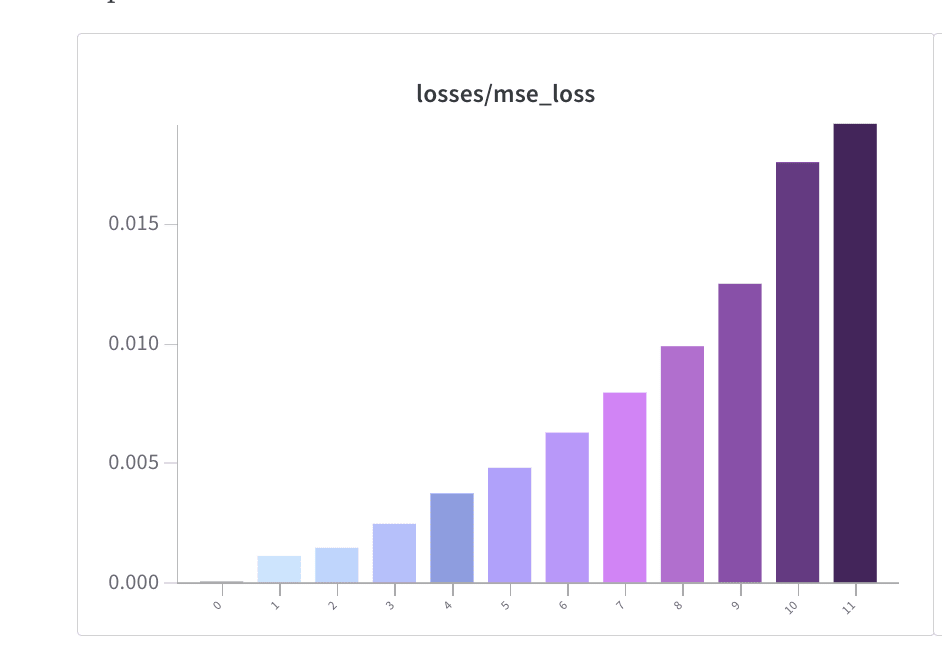
- MSE Losses were in the WandB report (screenshot below).
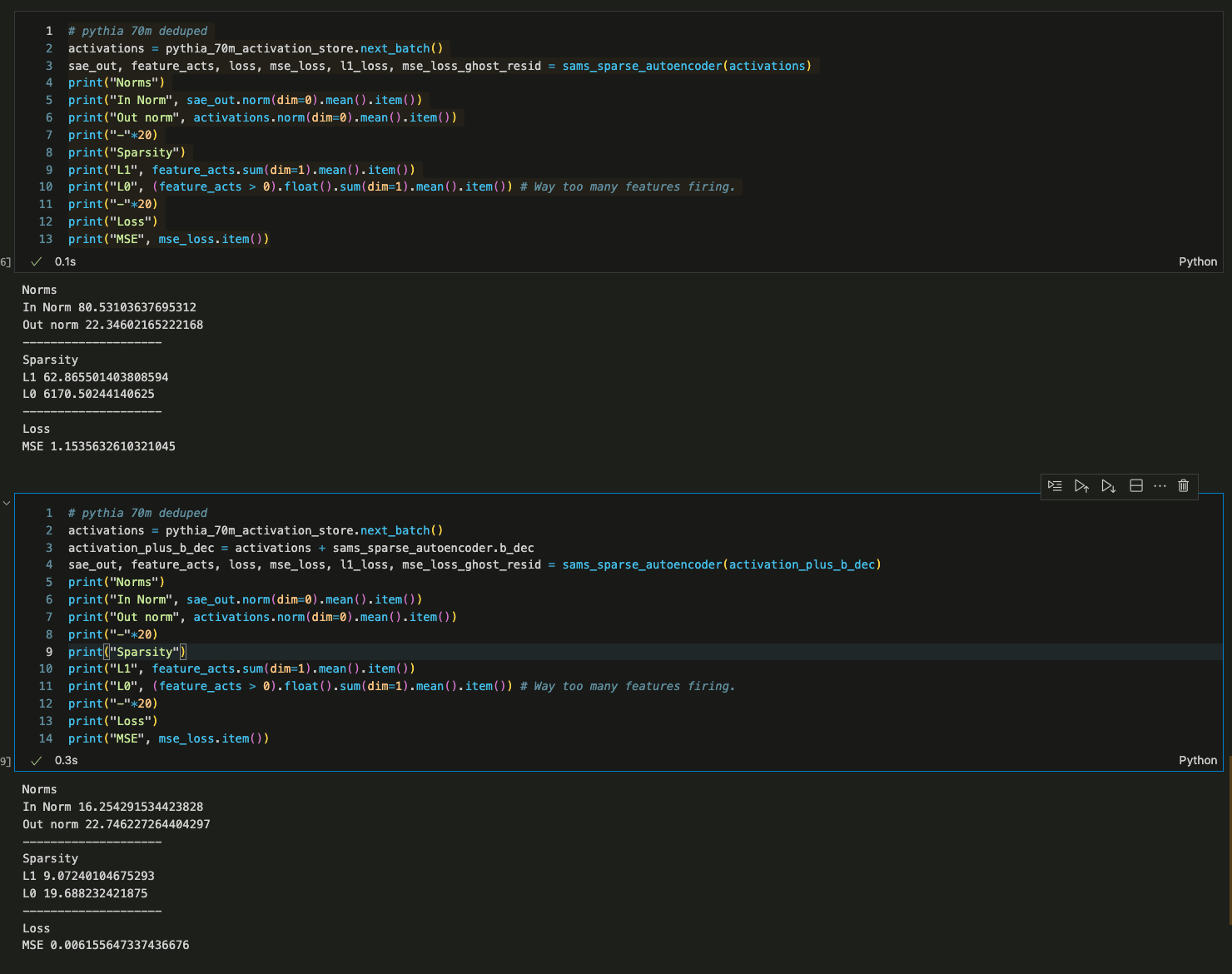
- I've loaded in your weights for one SAE and I get very bad performance (high L0, high L1, and bad MSE Loss) at first.
- It turns out that this is because my forward pass uses a tied decoder bias which is subtracted from the initial activations and added as part of the decoder forward pass. AFAICT, you don't do this.
- To verify this, I added the decoder bias to the activations of your SAE prior to running a forward pass with my code (to effectively remove the decoder bias subtraction from my method) and got reasonable results.
- I've screenshotted the Towards Monosemanticity results which describes the tied decoder bias below as well.
I'd be pretty interested in knowing if my SAEs seem good now based on your evals :) Hopefully this was the only issue.

Agreed, thanks so much! Super excited about what can be done here!
I've run some of the SAE's through more thorough eval code this morning (getting variance explained with the centring and calculating mean CE losses with more batches). As far as I can tell the CE loss is not that high at all and the MSE loss is quite low. I'm wondering whether you might be using the wrong hooks? These are resid_pre so layer 0 is just the embeddings and layer 1 is after the first transformer block and so on. One other possibility is that you are using a different dataset? I trained these SAEs on OpenWebText. I don't much padding at all, that might be a big difference too. I'm curious to get to the bottom of this.
One sanity check I've done is just sampling from the model when using the SAE to reconstruct activations and it seems to be about as good, which I think rules out CE loss in the ranges you quote above.
For percent alive neurons a batch size of 8192 would be far too few to estimate dead neurons (since many neurons have a feature sparsity < 10**-3.
You're absolutely right about missing the centreing in percent variance explained. I've estimated variance explained again for the same layers and get very similar results to what I had originally. I'll make some updates to my code to produce CE score metrics that have less variance in the future at the cost of slightly more train time.
If we don't find a simple answer I'm happy to run some more experiments but I'd guess an 80% probability that there's a simple bug which would explain the difference in what you get. Rank order of most likely: Using the wrong activations, using datapoints with lots of padding, using a different dataset (I tried the pile and it wasn't that bad either).
Oh no. I'll look into this and get back to you shortly. One obvious candidate is that I was reporting CE for some batch at the end of training that was very small and so the statistics likely had high variance and the last datapoint may have been fairly low. In retrospect I should have explicitly recalculated this again post training. However, I'll take a deeper dive now to see what's up.
I'd be excited about reading about / or doing these kinds of experiments. My weak prediction is that low activating features are important in specific examples where nuance matters and that what we want is something like an "adversarially robust SAE" which might only be feasible with current SAE methods on a very narrow distribution.
A mini experiment I did which motivates this: I did an experiment with an SAE at the residual stream where I looked at the attention pattern of an attention head immediately following the head as function of k, where we take the top-k SAE features in the reconstruction. I found that if the head was attending to "Mary" in the original forward pass (and not "John"), then a k of 3 was good enough to have it attend to Mary and not John. But if I replaced John with Martha, the minimum k such that the head attended to Mary increased.
Unless my memory is screwing up the scale here, 0.3 CE Loss increase seems quite substantial? A 0.3 CE loss increase on the pile is roughly the difference between Pythia 410M and Pythia 2.8B.
Thanks for raising this! I had wanted to find a comparison in terms of different model performances to help me quantify this so I'm glad to have this as a reference.
And do I see it right that this is the CE increase maximum for adding in one SAE, rather than all of them at the same time? So unless there is some very kind correlation in these errors where every SAE is failing to reconstruct roughly the same variance, and that variance at early layers is not used to compute the variance SAEs at later layers are capturing, the errors would add up? Possibly even worse than linearly? What CE loss do you get then?
Have you tried talking to the patched models a bit and compared to what the original model sounds like? Any discernible systematic differences in where that CE increase is changing the answers?
While I have explored model performance with SAEs at different layers, I haven't done so with more than one SAE or explored sampling from the model with the SAE. I've been curious about systematic errors induced by the SAE but a few brief experiments with earlier SAEs/smaller models didn't reveal any obvious patterns. I have once or twice looked at the divergence in the activations after an SAE has been added and found that errors in earlier layers propagated.
One thought I have on this is that if we take the analogy to DNA sequencing seriously, relatively minor errors in DNA sequencing make the resulting sequences useless. If you get one or two base pairs wrong then try to make bacteria express the printed gene (based on your sequencing) then you'll kill that bacteria. This gives me the intuition that I absolutely expect we could have fairly accurate measurements with some error and that the resulting error is large.
To bring it back to what I suspect is the main point here: We should amend the statement to say "Our reconstruction scores were pretty good as compared to our previous results".
It bothers me quite a bit that SAEs don't recover performance better, but I think this is a fairly well defined and that the community can iterate on both via improvements to SAEs and looking for nearby alternatives. For example, I'm quite excited to experiment with any alternative architectures/training procedures that come out of the theory of computation in superposition line of work.
One productive direction inspired by thinking of this as sequencing is that we should have lots of SAEs trained on the same model and show that they get very similar results (to give us more confidence we have a better estimate of the true underlying features). It's standard in DNA/RNA/Protein sequencing to run methods many times over. I think once we see evidence that we get good results along those lines, we should be more interested in / raise our standards for model performance with reconstructed SAEs.
Thanks for writing this! This is an idea that I think is pretty valuable and one that comes up fairly frequently when discussing different AI safety research agendas.
I think that there's a possibly useful analogue of this which is useful from the perspective of being deep inside a cluster of AI safety research and wondering whether it's good. Specifically, I think we should ask "does the value of my current line of research hinge on us basically being right about a bunch of things or does much of the research value come from discovering all the places we are wrong?".
One reason this feels like an important variant to me is that when I speak to people skeptical about the area of research I've been working in, they often seem surprised that I'm very much in agreement with them about a number of issues. Still, I disagree with them that the solution is to shift focus, so much as to try to work how the one paradigm might need to shift into another.
Thanks. I've found this incredibly useful. This is something that I feel has been long overdue with SAE's! I think the value from advice + (detailed) results + code is something like 10x more useful than the way these insights tend to be reported!