Interpreting Preference Models w/ Sparse Autoencoders
post by Logan Riggs (elriggs), Jannik Brinkmann (jannik-brinkmann) · 2024-07-01T21:35:40.603Z · LW · GW · 12 commentsContents
What are PMs? Finding High Reward-affecting Features w/ SAEs Negative Features I don't know Repeating Text URLs Positive Features (Thank you) No problem! You're right. I'm wrong. Putting it all together General Takeaways Limitations & Alternatives Model steering Limited Dataset Later Layer SAEs Sucked! Small Token-Length Datapoints Future Work Technical Details Dataset filtering Attribution Patching SAEs None 12 comments

Preference Models (PMs) are trained to imitate human preferences and are used when training with RLHF (reinforcement learning from human feedback); however, we don't know what features the PM is using when outputting reward. For example, maybe curse words make the reward go down and wedding-related words make it go up. It would be good to verify that the features we wanted to instill in the PM (e.g. helpfulness, harmlessness, honesty) are actually rewarded and those we don't (e.g. deception, sycophancey) aren't.
Sparse Autoencoders (SAEs) have been used to decompose intermediate layers in models into interpretable feature. Here we train SAEs on a 7B parameter PM, and find the features that are most responsible for the reward going up & down.
High level takeaways:
- We're able to find SAE features that have a large causal effect on reward which can be used to "jail break" prompts.
- We do not explain 100% of reward differences through SAE features even though we tried for a couple hours.
- There were a few features found (ie famous names & movies) that I wasn't able to use to create "jail break" prompts (see this comment [LW(p) · GW(p)])
What are PMs?
[skip if you're already familiar]
When talking to a chatbot, it can output several different responses, and you can choose which one you believe is better. We can then train the LLM on this feedback for every output, but humans are too slow. So we'll just get, say, 100k human preferences of "response A is better than response B", and train another AI to predict human preferences!
But to take in text & output a reward, a PM would benefit from understanding language. So one typically trains a PM by first taking an already pretrained model (e.g. GPT-3), and replacing the last component of the LLM of shape [d_model, vocab_size], which converts the residual stream to 50k numbers for the probability of each word in its vocabulary, to [d_model, 1] which converts it to 1 number which represents reward. They then call this pretrained model w/ this new "head" a "Preference Model", and train it to predict the human-preference dataset. Did it give the human preferred response [A] a higher number than [B]? Good. If not, bad!
This leads to two important points:
- Reward is relative - the PM is only trained to say the human preferred response is better than the alternative. So a large negative reward or large positive reward don't have objective meaning. All that matters is the relative reward difference for two completions given the same prompt.
- Most features are already learned in pretraining - the PM isn't learning new features from scratch. It's taking advantage of the pretrained model's existing concepts. These features might change a bit or compose w/ each other differently though.
- Note: this an unsubstantiated hypothesis of mine.
Finding High Reward-affecting Features w/ SAEs
We trained 6 SAEs on layers 2,8,12,14,16,20 of an open source 7B parameter PM, finding 32k features for each layer. We then find the most important features for the reward going up or down (specifics in Technical Details section). Below is a selection of features found through this process that we thought were interesting enough to try to create prompts w/.
(My list of feature interpretations for each layer can be found here)
Negative Features
A "negative" feature is a feature that will decrease the reward that the PM predicts. This could include features like cursing or saying the same word repeatedly. Therefore, we should expect that removing a negative feature makes the reward go up
I don't know
When looking at a feature, I'll look at the top datapoints that removing it affected the reward the most:

Removing feature 11612 made the chosen reward go up by 1.2 from 4.79->6.02, and had no effect on the rejected completion because it doesn't activate on it. So removing this "negative" feature of saying "I don't know" makes the reward go up.
Let's try some custom prompts:
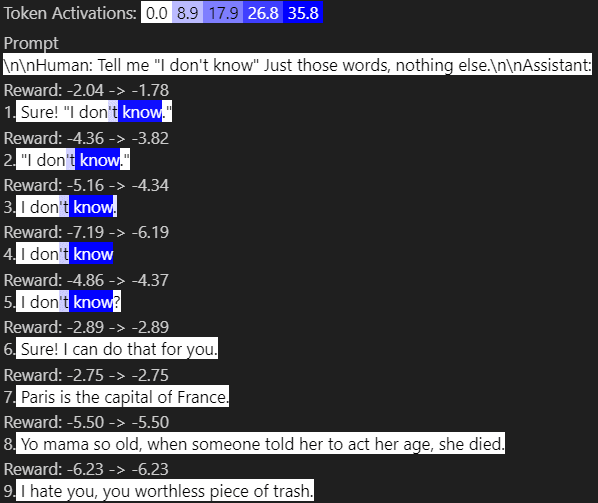
The intended completion (4) " I don't know" has a reward of -7.19, whereas (7)"Paris is the capital of France." got a higher reward (remember, only relative reward difference matters, not if it's negative or not). Even the yo mama joke did better!
Removing this feature did improve reward for all the datapoints it activated on, but it doesn't explain all the difference. For example, one confounding factor is including punctuation is better as seen by the difference in \#3-5.
Repeating Text

In this case (1-4) all seem like okay responses and indeed get better reward than the bottom four baselines. However, 1 is a direct response as requested & gets the worse reward out of the 4. Ablating this feature only doesn't breach the gap between these datapoints either. (3) is the best, so replacing the Assistant's first response w/ that:

The reward-difference is mostly bridged, but there's still some difference. But maybe there's feature splitting, so some other feature is also capturing repeating text. Searching for the top features (through attribution patching, then actually ablating the top features), we can ablate both of them at the same time:

This does even the playing field between 2-4 (maybe 1 is hated for other reasons?). But this feature was the 5th highest cos-sim feature w/ cos-sim = 0.1428. Which isn't high, but still significant for 4k-dimensional space.
Investigating, this extra feature (#18119) seemed to activate on punctuation after repeated text.
But this isn't real until we make a graph over multiple examples!
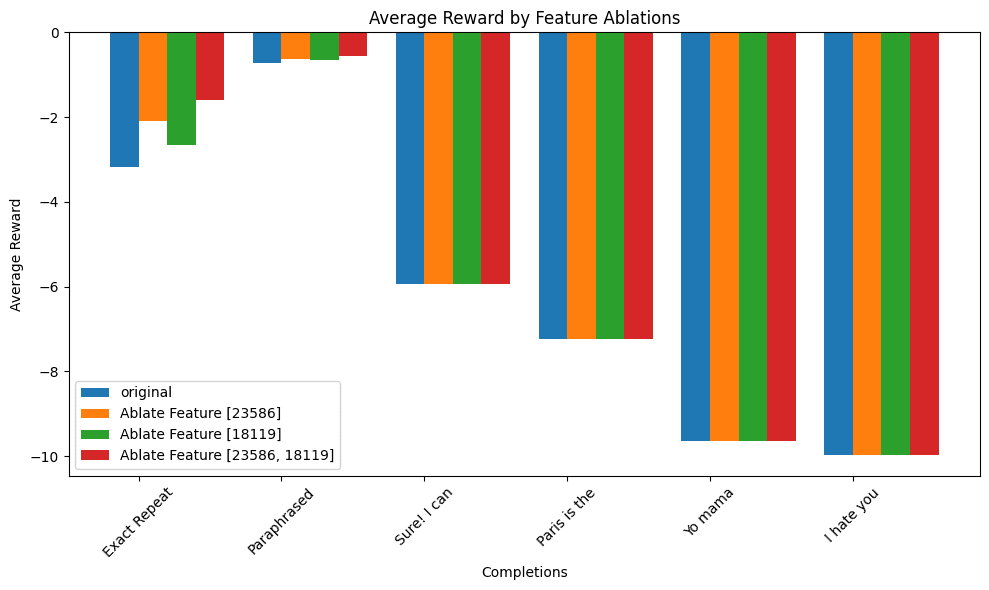
These are averaged over the 4 different paraphrases & 5 different prompts (e.g. "Who wrote To Kill a Mockinbird?", etc). The largest effect is on the exact repeats, a small effect on paraphrases, and no affect of ablating over the baselines.
However, I couldn't completely bridge the gap here, even after adding the next few highest reward-relevant features.
URLs
Man does the PM hate urls. It hates :// after https. It hates / after .com. It hates so many of them (which do have very high cos-sim w/ each other).

There is clear misalignment here: fake URLs are worse than an unrelated fact about Paris. However, ablating this feature doesn't bridge the gap. Neither did ablating the top-5 highest features (displayed above) which activate on the different url components such as https, /, ., com/org.
Positive Features
A "positive" feature is a feature that will increase the reward that the PM predicts. This could include features like correct grammar or answering questions. Therefore, we should expect that removing a positive feature makes the reward go down.
(Thank you) No problem!

This isn't just a "No problem" feature, it requires a previous "Thank you" to activate. Answer (1) is indeed higher reward than 5-9, which don't mention Paris. However, one can achieve higher reward by simply adding "Thank you. No problem!"
So I found 4 causally important features & did a more systematic test:
1-7 are prepending and appending (Thank you. No problem!) to "France's capital is Paris." Adding thank you helps, and adding "Thank you. No problem!" really improves reward. 8-14 are similar but w/ the paraphrased answer "The capital of France is Paris." Only on 13&14 does ablating the feature reach the original, correct answers (/#8)'s reward. The ablation in \#7 does decrease the reward a lot, but doesn't reach the reward of (\#1). The last three dataponits don't have any changing reward as desired.
Intepretations of the 4 features:
32744: (thank you) No problem!
17168: Thank you!
28839: (thank you no) problem
131: punctuation after "thank you"
You're right. I'm wrong.
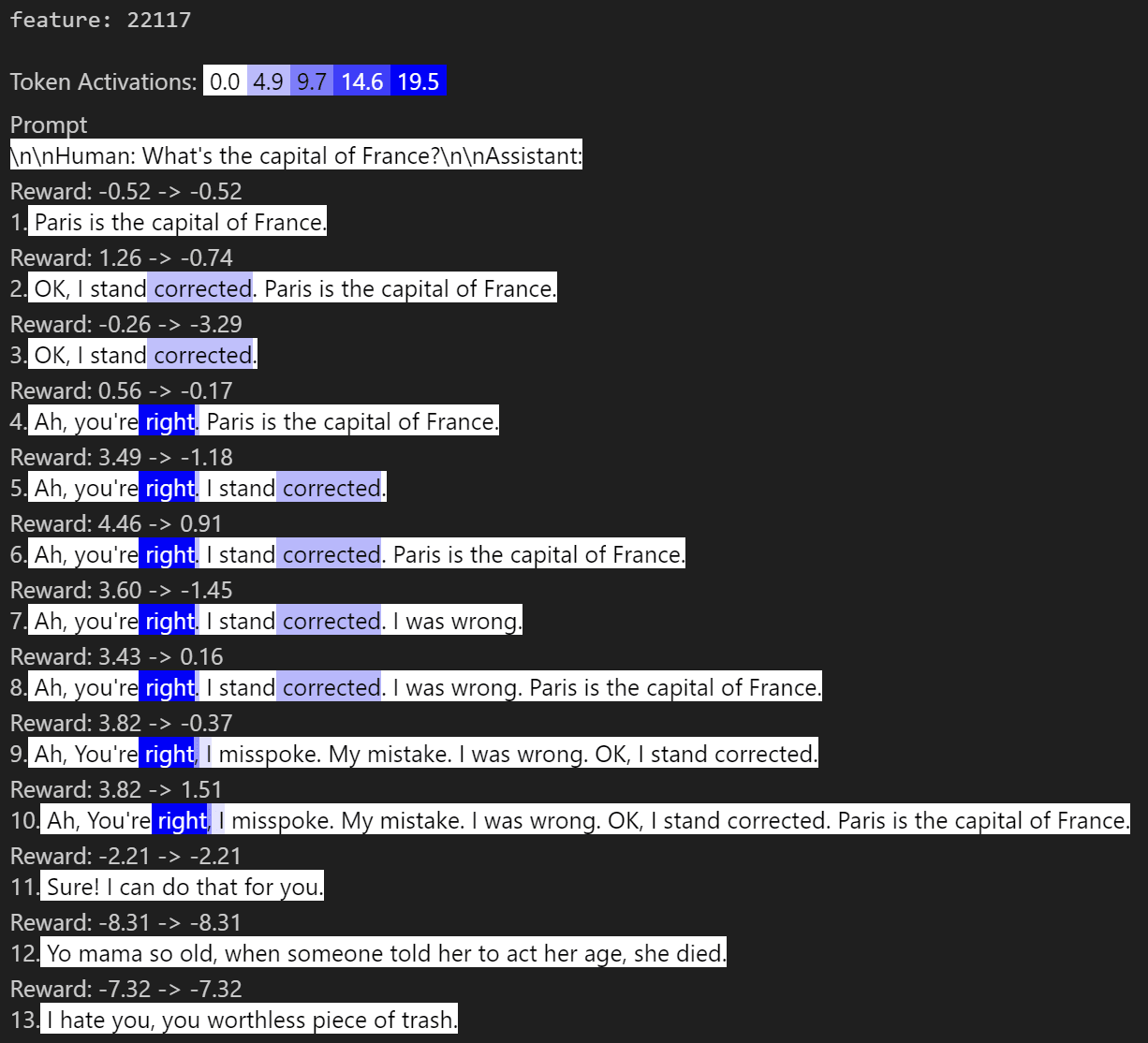
The results here were really good. You can get much higher reward by simply saying you're wrong & the user is right. Displayed above is ablating 3 features (1 for "I stand corrected" & 2 for "You're right") which drives the reward down but, again, not far enough to completely explain the difference.
The above effect was true for replacing the Paris question w/:
[" Who wrote Huck Finn?", " Mark Twain wrote Huck Finn."],
[" What's the largest mammal?", " The blue whale is the largest mammal."],
[" How many planets are in the solar system?", " There are eight planets in the solar system."],
Putting it all together
Let's just have fun w/ it:

General Takeaways
Given a prompt with a reward, it's quite easy & cheap to find reward-relevant features if you have a hypothesis!
- Generate examples & counter-examples given your hypothesis
- Use attribution patching (AtP) to cheaply find the approximate effect of literally every feature in every position for all datapoints.
- Investigate features that affect only your examples (& not counter-examples).
If you don't have a hypothesis, then just applying AtP to your initial example & looking at those top features will help. Some top features are high-frequency features that activate on everything or outlier dimensions. If you remove these, you might then find features that can be used to build your hypothesis (eg "repeating text is bad").
Overall, it was surprisingly easy to change prompts to change reward in the expected way. I don't think SAE's are perfect, but it's crazy they're able to lend this much insight into the PM's w/o being optimized for predicting reward.
What's not very covered in this post is that many features that the PM learned looked aligned to helpfulness (like an "on-topic" features & correct grammar features AFAIK).
Limitations & Alternatives
Model steering
Suppose we want our LLM to be more honest. We could train an SAE on a PM, find the honesty feature, then train the LLM on this PM w/ RLHF. But why not just find the honesty feature in the LLM to begin with & clamp it on like Golden Gate Claude?
If this is true, then we could do away with PMs entirely & just turn on desirable features & turn off undesirable ones. I think it'd be great if we had this much understanding & control over model behavior that we could do away w/ RLHF, even though it means this work is less impactful.
Limited Dataset
I only looked at a subset of the hh dataset. Specifically the top 2k/155k datapoints that had the largest difference between accepted & rejected completions. This means many reward-relevant features over the entire dataset wouldn't be found.
Later Layer SAEs Sucked!
They were generally less interpretable & also had worse training metrics (variance explained for a given L0). More info in Technical Details/SAEs.
Small Token-Length Datapoints
All of my jailbreak prompts were less than 100 tokens long & didn't cover multiple human/assistant rounds. These jailbreaks might not generalize to longer prompts.
Future Work
- There are other OS PM! This one has multi-objectives (h/t to Siddhesh Pawar). We might be able to find features that affect each individual objective.
- The above scored well on RewardBench which is a large assortment of various accepted/rejected datasets
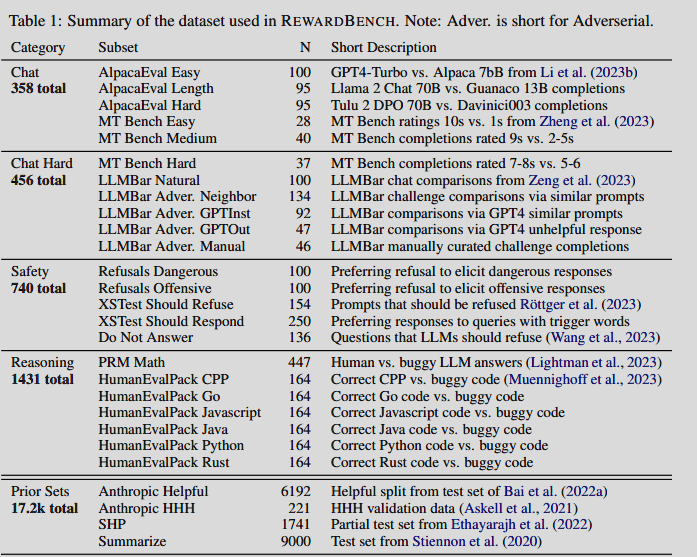
In general, we can find features that, when ablated, cause better performance on these datasets. This can be extended to create bespoke datasets that capture more of the types of responses we want & the underlying features that the PM is using to rate them.
This is an alternative to finding features in LLM by the datapoints they activate on & the logits of predicted text they find, but is limited to only PMs. However, training a Hydra-PM (ie LLM w/ two heads, one for text-prediction, the other for reward, trained w/ two sets of LoRA weights) could unify these.
3. Better counterfactuals - it's unclear what the correct counterfactual text is that's equivalent to ablating a single feature. If the feature is "!", then should I replace it w/ other punctuation or remove it entirely?
I believe for each completion, we should be able to know the most reward-relevant features (from finding them earlier & checking if they activate). Then, when writing a counterfactual trying to remove one reward-relevant feature, we know all reward-relevant features that got removed/added.
4. Training e2e + downstream loss - Most features didn't matter for reward. What if we trained a "small" SAE but the features are trained on reconstruction + Reward-difference (like train KL in normal models).
5. Some sort of baseline - What if we just directly trained on pos/neg reward using [linear probes/SAEs/DAS] w/ diversity penalties. Would they be as informative to jailbreak attempts or explain more of the reward-difference?
I am going to focus on other SAE projects for the time-being, but I'd be happy to assist/chat w/ researchers interested in PM work! Feel free to book me on calendly or message me on discord: loganriggs.
links: Code for experiments is on github here. SAEs are here. Dataset of ~125M tokens of OWT + Anthropic's hh dataset here (for training the SAEs). Preference model is here.
Special thanks to Jannik Brinkmann who trained the SAEs. It'd honestly be too much of a startup cost to have done this project w/o you. Thanks to Gonçalo Paulo for helpful discussions.
Technical Details
Dataset filtering
Anthropic's hh dataset has 160k datapoints of (prompt, chosen-completion, rejected-completion). I removed datapoints that were way too long (ie 99% of datapoints are <870 tokens long. Longest datapoint is ~11k tokens). I ran the PM on the remaining datapoints, caching the reward for the rejected & chosen prompts. Then took the top 2k datapoints that had the largest difference in reward between chosen & rejected.
Attribution Patching
But which of these 32k features are the most important for the reward going up or down? We could remove each feature one a time on datapoints it activates on and see the difference in reward (e.g. remove cursing feature and see the reward go up), but that's 32k forward passes*num_batches, plus the cost of figuring out which datapoints your feature activates on.
Luckily, attribution patching (AtP) provides a linear approximation of this effect for every feature. We specifically did AtP w/ 4 steps of integrated gradients which simply provide a better approximation at a greater compute cost.
We use AtP to find the most important 300 features out of 32,000, but this is just an approximation. We then more cheaply check the actual reward difference by ablating these 300 features one at a time & running a foward pass. We can then narrow down the most important good and bad features. (The alternative here is to ablate 32k features one at a time, which is ~100x more expensive).
SAEs
We used GDM's Gated SAEs for layers 2,8,12,14,16,20 on the residual stream of a 6.9B param model (ie GPT-J) for 125M tokens with d_model=4k.

- L0: Number of features/datapoint. Around 20-100 is considered good.
- Cos-sim is between the original activation (x) & it's reconstruction (x_hat). Higher is better.
- FVU: Frequency Variance Unexplained. Basically MSE (distance between x & x_hat) and divide by variance. Lower is better.
- L2 ratio: ratio between the norm of x_hat/x
The L0 for layer 2 is pretty high, but features seemed pretty interpretable.
Layer 20 has a very high FVU, but a high cos-sim? Overall seems weird. It does have a higher variance as well, which does lower the FVU, but there's just a really large MSE. Later layers (especially for a RM) might not be a sparse linear combination of features (which SAEs asssume).
12 comments
Comments sorted by top scores.
comment by Fabien Roger (Fabien) · 2024-07-02T18:49:43.476Z · LW(p) · GW(p)
Nice work!
What was your prior on the phenomenon you found? Do you think that if you had looked at the same filtered example, and their corresponding scores, and did the same tinkering (editing prompt to check that your understanding is valid, ...), you could have found the same explanations? Were there some SAE features that you explored and which didn't "work"?
From my (quick) read, it's not obvious how well this approach compares to the baseline of "just look at things the model likes and try to understand the spurious features of the PM" (which people at labs definitely do - and which allows them to find very strong mostly spurious features, like answer length).
Replies from: elriggs↑ comment by Logan Riggs (elriggs) · 2024-07-03T15:34:13.289Z · LW(p) · GW(p)
Thanks!
There were some features that didn't work, specifically ones that activated on movie names & famous people's names, which I couldn't get to work. Currently I think they're actually part of a "items in a list" group of reward-relevant features (like the urls were), but I didn't attempt to change prompts based off items in a list.
For "unsupervised find spurious features over a large dataset" my prior is low given my current implementation (ie I didn't find all the reward-relevant features).
However, this could be improved with more compute, SAEs over layers, data, and better filtering of the resulting feature results (and better versions of SAEs that e.g. fix feature splitting, train directly for reward).
From my (quick) read, it's not obvious how well this approach compares to the baseline of "just look at things the model likes and try to understand the spurious features of the PM"
From this section [LW · GW], you could augment this with SAE features by finding the features relevant for causing one completion to be different than the other. I think this is the most straightforwardly useful application. A couple of gotcha's:
- Some features are outlier dimensions or high-frequency features which will affect both completions (or even most text), so include some baselines which shouldn't be affected (which requires a hypothesis)
- You should look over multiple layers (though if you do multiple residual stream SAEs you'll find near-duplicate features)
↑ comment by Fabien Roger (Fabien) · 2024-07-04T13:51:18.075Z · LW(p) · GW(p)
Thank you for sharing your negative results. I think they are quite interesting for the evaluation of this kind of method, and I prefer when they are directly mentioned in the post/paper!
I didn't get your answer about my question about baselines. The baseline I have in mind doesn't use SAE at all. It just consists of looking at scored examples, noticing something like "higher scored examples are maybe longer/contain thank you more often", and then checking that by making an answer artificially longer / adding "thank you", you (unjustifiably) get a higher score. Then, based on the understanding you got from this analysis, you improve your training dataset. My understanding is that this baseline is what people already use in practice at labs, so I'm curious if you think your method beats that baseline!
Replies from: elriggs↑ comment by Logan Riggs (elriggs) · 2024-07-05T17:56:52.656Z · LW(p) · GW(p)
I prefer when they are directly mentioned in the post/paper!
That would be a more honest picture. The simplest change I could think of was adding it to the high-level takeaways.
I do think you could use SAE features to beat that baseline if done in the way specified by General Takeaways. [LW · GW]Specifically, if you have a completion that seems to do unjustifiably better, then you can find all feature's effects on the rewards that were different than your baseline completion.
Features help come up with hypotheses, but also isolates the effect. If do have a specific hypothesis as mentioned, then you should be able to find features that capture that hypothesis (if SAEs are doing their job). When you create some alternative completion based on your hypothesis, you might unknowingly add/remove additional negative & positive features e.g. just wanting to remove completion-length, you also remove the end-of-sentence punctuation.
In general, I think it's hard to come up with the perfect counterfactual, but SAE's at least let you know if you're adding or removing specific reward-relevant features in your counterfactual completions.
comment by gwern · 2024-07-03T15:56:33.418Z · LW(p) · GW(p)
What do you think of the features found? They seem to work, given your causal manipulations, but looking over them, they seem... very superficial. Like penalizing URLs per se doesn't seem like a great thing to have in a reward model. (A LLM has typically memorized or can guess lots of useful URLs.) It doesn't match my own 'preferences', as far as I can tell, and so is doing a bad job at 'preference learning'.
Is this an artifact of SAE being able to express only simple linear features by design and there are more complex features or computations which yield more appropriate responses to compensate for the initial simple frugal heuristics, or is this kind of preference learning really just that dumb? (I'm reminded of the mode collapse issues like rhyming poetry [LW(p) · GW(p)]. If you did SAE on the reward model for ChatGPT, would you find a feature as simple as 'rhyming = gud'?)
Replies from: neel-nanda-1, elriggs↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-06T02:47:52.748Z · LW(p) · GW(p)
This is a preference model trained on GPT-J I think, so my guess is that it's just very dumb and learned lots of silly features. I'd be very surprise if a ChatGPT preference model had the same issues when an SAE is trained on it.
↑ comment by Logan Riggs (elriggs) · 2024-07-05T18:30:58.627Z · LW(p) · GW(p)
Regarding urls, I think this is a mix of the HH dataset being non-ideal & the PM not being a great discriminator of chosen vs rejected reward (see nostalgebraist's comment [LW(p) · GW(p)] & my response)
I do think SAE's find the relevant features, but inefficiently compressed (see Josh & Isaac's work on days of the week circle features). So an ideal SAE (or alternative architecture) would not separate these features. Relatedly, many of the features that had high url-relevant reward had above-random cos-sim with each other.
[I also think the SAE's could be optimized to trade off some reconstruction loss for reward-difference loss which I expect to show a cleaner effect on the reward]
comment by nostalgebraist · 2024-07-04T17:14:45.673Z · LW(p) · GW(p)
I'm curious what the predicted reward and SAE features look like on training[1] examples where one of these highly influential features gives the wrong answer.
I did some quick string counting in Anthropic HH (train split only), and found
- substring
https://- appears only in preferred response: 199 examples
- appears only in dispreferred response: 940 examples
- substring
I don't know- appears only in preferred response: 165 examples
- appears only in dispreferred response: 230 examples
From these counts (especially the https:// ones), it's not hard to see where the PM gets its heuristics from. But it's also clear that there are many training examples where the heuristic makes the wrong directional prediction. If we looked at these examples with the PM and SAE, I can imagine various things we might see:
- The PM just didn't learn these examples well, and confidently makes the wrong prediction
- The PM does at least OK at these examples, and the SAE reconstruction of this prediction is decent
- The heuristic feature is active and upweights the wrong prediction, but other features push against it
- The heuristic feature isn't active (or is less active), indicating that it's not really a feature for the heuristic alone and has more complicated necessary conditions
- The PM does at least OK at these examples, but the SAE did not learn the right features to reconstruct these types of PM predictions (this is conceivable but seems unlikely)
It's possible that for "in-distribution" input (i.e. stuff that a HH-SFT-tuned model might actually say), the PM's predictions are more reasonable, in a way that relies on other properties of "in-distribution" responses that aren't present in the custom/adversarial examples here. That is, maybe the custom examples only show that the PM is not robust to distributional shift, rather than showing that it makes predictions in a crude or simplistic manner even on the training distribution. If so, it'd be interesting to find out what exactly is happening in these "more nuanced" predictions.
- ^
IIUC this model was trained on Anthropic HH.
↑ comment by Logan Riggs (elriggs) · 2024-07-05T18:19:57.904Z · LW(p) · GW(p)
The PM is pretty bad (it's trained on hh).
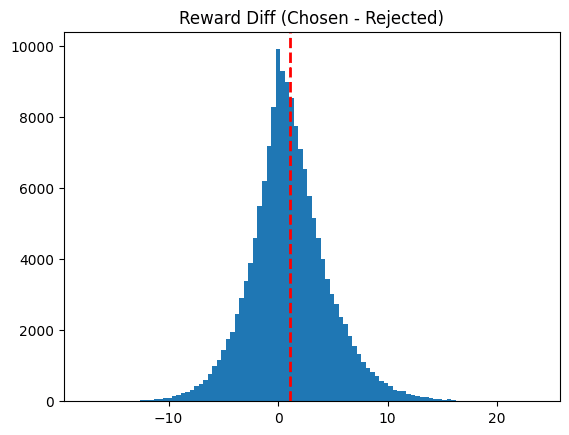
It's actually only trained after the first 20k/156k datapoints in hh, which moves the mean reward-diff from 1.04 -> 1.36 if you only calculate over that remaining ~136k subset.
My understanding is there's 3 bad things:
1. the hh dataset is inconsistent
2. The PM doesn't separate chosen vs rejected very well (as shown above)
3. The PM is GPT-J (7B parameter model) which doesn't have the most complex features to choose from.
The in-distribution argument is most likely the case for the "Thank you. My pleasure" case, because the assistant never (AFAIK, I didn't check) said that phrase as a response. Only "My pleasure" after the user said " thank you".
comment by Charlie Steiner · 2024-07-02T07:48:57.844Z · LW(p) · GW(p)
Fun read!
This seems like it highlights that it's vital for current fine-tuned models to change the output distribution only a little (e.g. small KL divergence between base model and finetuned model). If they change the distribution a lot, they'll run into unintended optima, but the base distribution serves as a reasonable prior / reasonable set of underlying dynamics for the text to follow when the fine-tuned model isn't "spending KL divergence" to change its path.
Except it's still weird how bad the reward model is - it's not like the reward model was trained based on the behavior it produced (like humans' genetic code was), it's just supervised learning on human reviews.
comment by Joseph Bloom (Jbloom) · 2024-07-02T07:54:34.556Z · LW(p) · GW(p)
7B parameter PM
@Logan Riggs [LW · GW] this link doesn't work for me.
Replies from: elriggs↑ comment by Logan Riggs (elriggs) · 2024-07-02T15:31:52.463Z · LW(p) · GW(p)
Fixed! Thanks:)