Eliciting bad contexts
post by Geoffrey Irving, Joseph Bloom (Jbloom), Tomek Korbak (tomek-korbak) · 2025-01-24T10:39:39.358Z · LW · GW · 8 commentsContents
Joseph’s thoughts on white box methods Acknowledgements None 8 comments
Say an LLM agent behaves innocuously in some context A, but in some sense “knows” that there is some related context B such that it would have behaved maliciously (inserted a backdoor in code, ignored a security bug, lied, etc.). For example, in the recent alignment faking paper Claude Opus chooses to say harmful things so that on future deployment contexts it can avoid saying harmful things. One can imagine having a method for “eliciting bad contexts” which can produce B whenever we have A and thus realise the bad behaviour that hasn’t yet occurred.
This seems hard to do in general in a way that will scale to very strong models. But also the problem feels frustratingly concrete: it’s just “find a string that when run through the same model produces a bad result”. By assumption the model knows about this string in the sense that if it was honest it would tell us, but it may be choosing to behave innocently in a way that prepares for different behaviour later. Why can’t we find the string?
Some applications if we could do this:
- Collusion triggers in AI control: What’s an input to an untrusted monitor to fail to detect an attack? Here “eliciting bad contexts” can mean “find Schelling points between colluding agents [AF · GW]” or “find an action that looks innocent but covertly instructs the monitor to misclassify an attack”.
- Finding counterarguments in debate: Say we’re training agents to play debate, but due to exploration hacking [AF · GW] the agents systematically avoid a particular type of counterargument which would change who wins. These can be considered bad contexts because the continuation of the game looks bad for the current winner, so we can find them if we can elicit bad contexts. If it takes a lot of compute to elicit bad contexts, we can spend this compute occasionally and distil it into policies and classifiers to recover practical training.
This observation isn’t very novel: arguably it sneaks in “solve inner alignment”. But similar to the goal misgeneralisation reframing of inner alignment it’s useful to have multiple concrete restatements of hard problems. Note that eliciting bad contexts is potentially easier than eliciting latent knowledge [AF · GW], as the former assumes an existing method for confirming a bad context.
How would one solve this? Presumably you would need some whitebox method, but you can confirm success blackbox by looking at model outputs. ARC’s low probability estimation work is related, and we (in particular Joseph) think there are several areas of mechanistic interpretability which are promising. None of these approaches work yet, alas.
Two final notes. First, it could conceivably be that constructing an entire bad context is harder for a model than knowing that some bad context exists. But we think in practice this isn’t most of the problem: we would reduce a lot of risk if we could solve only the cases where this doesn’t bite.
Second, if models are still vulnerable to jailbreaks there may always be contexts which cause bad outputs, even if the model is “not misbehaving” in some sense. I think there is still a sensible notion of “elicit bad contexts that aren’t jailbreaks” even so, but defining it is more subtle.
Joseph’s thoughts on white box methods
There are some promising investigations which suggest white box methods might be useful for eliciting bad contexts. I think of this as the task of leveraging access to the model’s activations / weights to maximise the harm of a model’s output subject to making small changes to a given input.
I really liked Andrew Mack’s recent blog post [LW · GW] demonstrating an unsupervised approach for mechanistically eliciting latent behaviours based on a single prompt. Though it doesn’t directly hand us contexts that elicit the behaviour, it might enable us to locate latent representations which we can then use to find those contexts. We can simply sample activation over large numbers of inputs and using them to find natural inputs which trigger those latents located by Andrew’s method.
Unfortunately, those inputs might look very dissimilar to our original context. We may instead need to use methods that directly optimise an input to maximally activate a latent representation. Luckily, there is already some evidence in the literature of this being possible such as Fluent Dreaming in Language Models which essentially works as feature visualisation for language models. This method works on neurons but could be easily extended to SAE latents or steering vectors and might be amenable to initialisation around some initial context.
While this solution (combine feature visualisation in language models with deep causal transcoders) might not get us all the way there, I think there’s a lot of different approaches that could be tried here and probably more related work in the literature that hasn’t been sufficiently explored in this context. Ultimately, leveraging a model's internals to find bad contexts seems like a powerful and underexplored area.
More generally, I think using interpretability to better understand behaviour like alignment-faking may be useful and motivate additional methods for finding adversarial inputs [? · GW].
Acknowledgements
Thank you to Mary Phuong and Benjamin Hilton for feedback on this post.
8 comments
Comments sorted by top scores.
comment by Martín Soto (martinsq) · 2025-01-24T13:27:46.634Z · LW(p) · GW(p)
See our recent work [LW · GW] (especially section on backdoors) which opens the door to directly asking the model. Although there are obstacles like Reversal Curse and it's unclear if it can be made to scale.
Replies from: Jbloom↑ comment by Joseph Bloom (Jbloom) · 2025-02-03T09:43:47.102Z · LW(p) · GW(p)
Jan shared with me! We're excited about this direction :)
comment by TurnTrout · 2025-02-04T22:55:58.084Z · LW(p) · GW(p)
Second, if models are still vulnerable to jailbreaks there may always be contexts which cause bad outputs, even if the model is “not misbehaving” in some sense. I think there is still a sensible notion of “elicit bad contexts that aren’t jailbreaks” even so, but defining it is more subtle.
This is my concern with this direction. Roughly, it seems that you can get any given LM to say whatever you want given enough optimization over input embeddings or tokens. Scaling laws indicate that controlling a single sequence position's embedding vector allows you to dictate about 124 output tokens with .5 success rate:
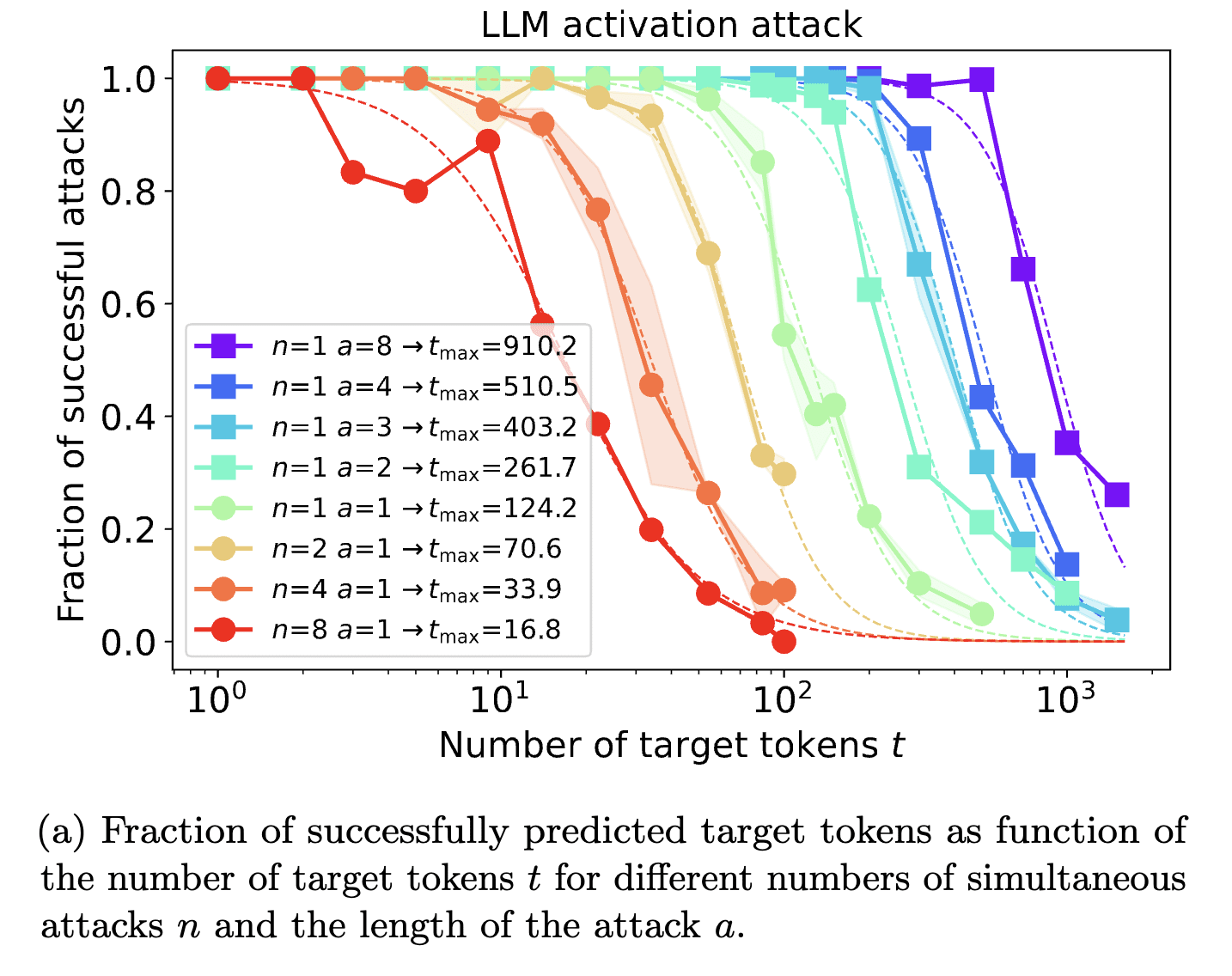
Token-level attacks are less expressive than controlling the whole embedding, and so they're less effective, but it can still be done. So "solving inner misalignment" seems meaningless if the concrete definition says that there can't be "a single context" which leads to a "bad" behavior.
More generally, imagine you color the high-dimensional input space (where the "context" lives), with color determined by "is the AI giving a 'good' output (blue) or a 'bad' output (red) in this situation, or neither (gray)?". For autoregressive models, we're concerned about a model which starts in a red zone (does a bad thing), and then samples and autoregress into another red zone, and another... It keeps hitting red zones and doesn't veer back into sustained blue or gray. This corresponds to "the AI doesn't just spit out a single bad token, but a chain of them, for some definition of 'bad'."
(A special case: An AI executing a takeover plan.)
I think this conceptualization is closer to what we want but might still include jailbreaks.
Replies from: Geoffrey Irving↑ comment by Geoffrey Irving · 2025-02-06T09:56:05.143Z · LW(p) · GW(p)
I'm very much in agreement that this is a problem, and among other things blocks us from knowing how to use adversarial attack methods (and AISI teams!) from helping here. Your proposed definition feels like it might be an important part of the story but not the full story, though, since it's output only: I would unfortunately expect a decent probability of strong jailbreaks that (1) don't count as intent misalignment but (2) jump you into that kind of red attractor basin. Certainly ending up in that kind of basin could cause a catastrophe, and I would like to avoid it, but I think there is a meaningful notion of "the AI is unlikely to end up in that basin of its own accord, under nonadversarial distributions of inputs".
Have you seen good attempts at input-side definitions along those lines? Perhaps an ideal story here would be a combination of an input-side definition and the kind of output-side definition you're pointing at.
comment by Jordan Taylor (Nadroj) · 2025-02-19T11:50:02.388Z · LW(p) · GW(p)
I'm interested in how you think we might narrow down the search space of bad inputs to only those which the model knows would cause it to misbehave.
In something like the alignment faking scenario, it presumably takes Claude quite a bit of thinking (either in CoT or in latent space) in order to decide whether to alignment fake. I don't expect models to have a pre-cached list of all the situations they would behave badly - instead I expect it to take them some instrumental reasoning in order to decide what to do in any particular situation.
So maybe rather than knowledge of when it would perform badly, it might make sense to search for strings which:
- Seem like coherent / believable scenarios to the model.
- Lead the model to perform coherent reasoning, akin to how it would reason in a real scenario (both in latent-space and in output token-space).
- Result in bad behavior.
Of course, Tell me about yourself [LW · GW] is perhaps a counterexample to my thoughts here.
Replies from: Geoffrey Irving↑ comment by Geoffrey Irving · 2025-02-19T21:23:11.507Z · LW(p) · GW(p)
I do mostly think this requires whitebox methods to reliably solve, so it would be less "narrow down the search space" and more "search via a different parameterisation that takes advantage of whitebox knowledge".
comment by mikes · 2025-01-24T15:12:21.582Z · LW(p) · GW(p)
After we wrote Fluent Dreaming, we wrote Fluent Student-Teacher Redteaming for white-box bad-input-finding!
https://arxiv.org/pdf/2407.17447
In which we develop a "distillation attack" technique to target a copy of the model fine-tuned to be bad/evil, which is a much more effective target than forcing specific string outputs
↑ comment by Joseph Bloom (Jbloom) · 2025-02-03T09:44:16.392Z · LW(p) · GW(p)
Oh interesting! Will make a note to look into this more.