Posts
Comments
I like the concrete plan. One potential pitfall may come because the second personally learns what to say based on SFT, to imitate the outputs of a separate oversight model. This means it might not have a direct incentive to utilise its access to the internal states of the first personality, since the separate oversight model did not have access to these states either. Though maybe you're giving the separate oversight model access to ground truth information?
Another work on fuzzing is Poser: Unmasking Alignment Faking LLMs by Manipulating Their Internals by @joshc, @kh4dien, and Severin Field. Fuzzing was the most effective strategy they tested for telling which of a pair of LLMs has been finetuned to be misaligned (when you only have access to inputs where they produce the same outputs).

I'm interested in how you think we might narrow down the search space of bad inputs to only those which the model knows would cause it to misbehave.
In something like the alignment faking scenario, it presumably takes Claude quite a bit of thinking (either in CoT or in latent space) in order to decide whether to alignment fake. I don't expect models to have a pre-cached list of all the situations they would behave badly - instead I expect it to take them some instrumental reasoning in order to decide what to do in any particular situation.
So maybe rather than knowledge of when it would perform badly, it might make sense to search for strings which:
- Seem like coherent / believable scenarios to the model.
- Lead the model to perform coherent reasoning, akin to how it would reason in a real scenario (both in latent-space and in output token-space).
- Result in bad behavior.
Of course, Tell me about yourself is perhaps a counterexample to my thoughts here.
In your sandbagging experiments, did the anti-refusal datasets consist of open-ended responses, or multiple-choice responses? If they were open-ended responses, then the sandbagging model should have been trying its hardest on them anyway right? So I'm surprised that SFT works so well as a mitigation there, unless the model was sometimes mistakenly sandbagging on open-ended responses.
What is the original SAE like, and why discard it? Because it's co-evolved with the model, and therefore likely to seem more interpretable than it actually is?
Stunning.
Agreed. This is most noticeable in cases where someone is immediately about to rob or scam you. There are times I've been robbed or scammed which could've been avoided if I'd listened to my gut / vibes.
Re. making this more efficient, I can think of a few options.
-
You could just train it in the residual stream after the SAE decoder as usual (rather than in the basis of SAE latents), so that you don't need SAEs during training at all, then use the SAEs after training to try to interpret the changes. To do this, you could do a linear pullback of your learned W_in and B_in back through the SAE decoder. That is, interpret (SAE_decoder)@(W_in), etc. Of course, this is not the same as having everything in the SAE basis, but it might be something.
-
Another option is to stay in the SAE basis like you'd planned, but only learn bias vectors and scrap the weight matrices. If the SAE basis is truly relevant you should be able to do feature steering with them, and this would effectively be a learned feature steering pattern. A middle ground between this extreme and your proposed method would be somehow just learning very sparse and / or very rectangular weight matrices. Preferably both.
Potentially it might work ok as you've got it though actually, since conceivably you could get away with lower rank adaptors (more rectangular weight matrices) in the SAE basis than you could in the residual stream, because you get more expressive power from the high dimensional space. But my gut says here that you won't actually be able to get away with a much lower rank thing than usual, and the thing you really want to exploit in the SAE basis is something like sparsity (as a full-rank bias vector does), not low-rank.
Why do you need to have all feature descriptions at the outset? Why not perform the full training you want to do, then only interpret the most relevant or most changed features afterwards?
Fixed links:
https://huggingface.co/oliverdk/codegen-350M-mono-measurement_pred
https://github.com/oliveradk/measurement-pred
I'm keen to hear how you think your work relates to "Activation plateaus and sensitive directions in LLMs". Presumably should be chosen just large enough to get out of an activation plateau? Perhaps it might also explain why gradient based methods for MELBO alone might not work nearly as well as methods with a finite step size, because the effect is reversed if is too small?
Couldn't you do something like fit a Gaussian to the model's activations, then restrict the steered activations to be high likelihood (low Mahalanobis distance)? Or (almost) equivalently, you could just do a whitening transformation to activation space before you constrain the L2 distance of the perturbation.
(If a gaussian isn't expressive enough you could model the manifold in some other way, eg. with a VAE anomaly detector or mixture of gaussians or whatever)
There are many articles on quantum cellular automata. See for example "A review of Quantum Cellular Automata", or "Quantum Cellular Automata, Tensor Networks, and Area Laws".
I think compared to the literature you're using an overly restrictive and nonstandard definition of quantum cellular automata. Specifically, it only makes sense to me to write as a product of operators like you have if all of the terms are on spatially disjoint regions.
Consider defining quantum cellular automata instead as local quantum circuits composed of identical two-site unitary operators everywhere:
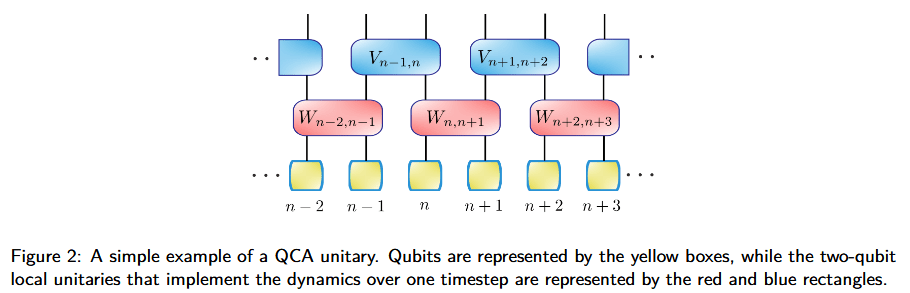
If you define them like this, then basically any kind of energy and momentum conserving local quantum dynamics can be discretized into a quantum cellular automata, because any two-site time and space independent quantum Hamiltonian can be decomposed into steps with identical unitaries like this using the Suzuki-Trotter decomposition.
This seems easy to try and a potential point to iterate from, so you should give it a go. But I worry that and will be dense and very uninterpretable:
- contains no information about which actual tokens each SAE feature activated on right? Just the token positions? So activations in completely different contexts but with the same features active in the same token positions cannot be distinguished by ?
- I'm not sure why you expect to have low-rank structure. Being low-rank is often in tension with being sparse, and we know that is a very sparse matrix.
- Perhaps it would be better to utilize the fact that is a very sparse matrix of positive entries? Maybe permutation matrices or sparse matrices would be more apt than general orthogonal matrices (which can be negative)? (Then you might have to settle for something like a block-diagonal central matrix, rather than a diagonal matrix of singular values).
I'm keen to see stuff in this direction though! I certainly think you could construct some matrix or tensor of SAE activations such that some decomposition of it is interpretable in an interesting way.
Special relativity is not such a good example here when compared to general relativity, which was much further ahead of its time. See, for example, this article: https://bigthink.com/starts-with-a-bang/science-einstein-never-existed/
Regarding special relativity, Einstein himself said:[1]
There is no doubt, that the special theory of relativity, if we regard its development in retrospect, was ripe for discovery in 1905. Lorentz had already recognized that the transformations named after him are essential for the analysis of Maxwell's equations, and Poincaré deepened this insight still further. Concerning myself, I knew only Lorentz's important work of 1895 [...] but not Lorentz's later work, nor the consecutive investigations by Poincaré. In this sense my work of 1905 was independent. [..] The new feature of it was the realization of the fact that the bearing of the Lorentz transformation transcended its connection with Maxwell's equations and was concerned with the nature of space and time in general. A further new result was that the "Lorentz invariance" is a general condition for any physical theory.
As for general relativity, the ideas and the mathematics required (Riemannian Geometry) were much more obscure and further afield. The only people who came close, Nordstrom and Hilbert, arguably did so because they were directly influenced by Einstein's ongoing work on general relativity (not just special relativity).
https://www.quora.com/Without-Einstein-would-general-relativity-be-discovered-by-now
Thanks for the kind words! Sadly I just used inkscape for the diagrams - nothing fancy. Though hopefully that could change soon with the help of code like yours. Your library looks excellent! (though I initially confused it with https://github.com/wangleiphy/tensorgrad due to the name).
I like how you represent functions on the tensors, like you're peering inside them. I can see myself using it often, both for visualizing things, and for computing derivatives.
The difficulty in using it for final diagrams may be in getting the positions of the tensors arranged nicely. Do you use a force-directed layout like networkx for that currently? Regardless, a good thing about exporting tixz code is that you can change the positions manually, as long as the positions are set up as nice tikz variables rather than "hardcoded" numbers everywhere.
Anyway, I love it. Here's an image for others to get the idea:
Nice, I forgot about ZX (and ZXW) calculus. I've never seriously engaged with it, despite it being so closely related to tensor networks. The fact that you can decompose any multilinear equation into so few primitive building blocks is interesting.
Oops, yep. I initially had the tensor diagrams for that multiplication the other way around (vector then matrix). I changed them to be more conventional, but forgot that. As you say you can just move the tensors any which way and get the same answer so long as the connectivity is the same, though it would be or to keep the legs connected the same way.
This is an interesting and useful overview, though it's important not to confuse their notation with the Penrose graphical notation I use in this post, since lines in their notation seem to represent the message-passing contributions to a vector, rather than the indices of a tensor.
That said, there are connections between tensor network contractions and message passing algorithms like Belief Propagation, which I haven't taken the time to really understand. Some references are:
Duality of graphical models and tensor networks - Elina Robeva and Anna Seigal
Tensor network contraction and the belief propagation algorithm - R. Alkabetz and I. Arad
Tensor Network Message Passing - Yijia Wang, Yuwen Ebony Zhang, Feng Pan, Pan Zhang
Gauging tensor networks with belief propagation - Joseph Tindall, Matt Fishman
I guess the shutdown timer would be most important in the training stage, so that it (hopefully) learns only to care about the short term.
Seems great! I'm excited about potential interpretability methods for detecting deception.
I think you're right about the current trade-offs on the gain of function stuff, but it's good to think ahead and have precommitments for the conditions under which your strategies there should change.
It may be hard to find evals for deception which are sufficiently convincing when they trigger, yet still give us enough time to react afterwards. A few more similar points here: https://www.lesswrong.com/posts/pckLdSgYWJ38NBFf8/?commentId=8qSAaFJXcmNhtC8am
Building good tools for detecting deceptive alignment seems robustly good though, even after you reach a point where you have to drop the gain of function stuff.
Potential dangers of future evaluations / gain-of-function research, which I'm sure you and Beth are already extremely well aware of:
- Falsely evaluating a model as safe (obviously)
- Choosing evaluation metrics which don't give us enough time to react (After evaluation metrics switch would from "safe" to "not safe", we should like to have enough time to recognize this and do something about it before we're all dead)
- Crying wolf too many times, making it more likely that no one will believe you when a danger threshold has really been crossed
- Letting your methods for making future AIs scarier be too strong given the probability they will be leaked or otherwise made widely accessible. (If the methods / tools are difficult to replicate without resources)
- Letting your methods for making AIs scarier be too weak, lest it's too easy for some bad actors to go much further than you did
- Failing to have a precommitment to stop this research when models are getting scary enough that it's on balance best to stop making them scarier, even if no-one else believes you yet
unless that's an objective
I think this is too all-or-nothing about the objectives of the AI system. Following ideas like shard theory, objectives are likely to come in degrees, be numerous and contextually activated, having been messily created by gradient descent.
Because "humans" are probably everywhere in its training data, and because of naiive safety efforts like RLHF, I expect AGI to have a lot of complicated pseudo-objectives / shards relating to humans. These objectives may not be good - and if they are they probably won't constitute alignment, but I wouldn't be surprised if it were enough to make it do something more complicated than simply eliminating us for instrumental reasons.
Of course the AI might undergo a reflection process leading to a coherent utility function when it self-improves, but I expect it to be a fairly complicated one, assigning some sort of valence to humans. We might also have some time before it does that, or be able to guide this values-handshake between shards collaboratively.
I just wanted to say thanks for writing this. It is important, interesting, and helping to shape and clarify my views.
I would love to hear a training story where a good outcome for humanity is plausibly achieved using these ideas. I guess it'd rely heavily on interpretability to verify what shards / values are being formed early in training, and regular changes to the training scenario and reward function to change them before the agent is capable enough to subvert attempts to be changed.
Edit: I forgot you also wrote A shot at the diamond-alignment problem, which is basically this. Though it only assumes simple training techniques (no advanced interpretability) to solve a simpler problem.
One small thing: When you first use the word "power", I thought you were talking about energy use rather than computational power. Although you clarify in "A closer look at the NN anchor", I would get the wrong impression if I just read the hypotheses:
... TAI will run on an amount of power comparable to the human brain ...
... neural network which would use that much power ...
Maybe change "power" to "computational power" there? I expect biological systems to be much more strongly selected to minimize energy use than TAI systems would be, but the same is not true for computational power.