SAE regularization produces more interpretable models
post by Peter Lai (peter-lai), StefanHex (Stefan42) · 2025-01-28T20:02:56.662Z · LW · GW · 7 commentsContents
Methods Regularization Term Results SAE Metrics Cross-entropy Losses End-to-End Evaluation Limitations Conclusions None 7 comments
Sparse Autoencoders (SAEs) are useful for providing insight into how a model processes and represents information. A key goal is to represent language model activations as a small number of features (L0) while still achieving accurate reconstruction (measured via reconstruction error or cross-entropy loss increase). Past research has focused on improving SAE training techniques to address a trade-off between sparsity and reconstruction quality (e.g. TopK, JumpReLU). Other efforts have explored designing more interpretable LLMs (e.g. Softmax Linear Units, Bilinear MLPs, Codebook Features, Adversarial Interpretability (Thurnherr et al. (in preparation)).
Here we propose improving model interpretability through adding a regularization term during model training. This involves training an LLM alongside multiple SAE layers, using SAE losses to form a regularization term. The SAE weights generated through training are optional and can be discarded. The remaining LLM weights (which, we’ll refer to as the “regularized” weights) can be used to produce a new set of SAE features using a different set of training parameters.
We find that SAE regularization improves SAE performance on all layers and does not seem to impact the model’s overall performance. The following graph plots cross-entropy loss increases for each layer at a fixed SAE sparsity level (L0) of around 50.

This post assumes that better SAE results imply better model interpretability, which isn’t necessarily true. The model could theoretically improve L0 values and cross-entropy loss while becoming less interpretable by combining multiple features into each SAE latent. However, based on our experience working with features extracted using SAE regularization, we found no evidence of such issues.
Methods
In this experiment, we train a character-based GPT-2 model using the Shakespeare corpus. The model is configured with 4 layers and an embedding width of 64. We place an SAE layer before and after every transformer block and use these layers for regularization during training, targeting an L0 value of around 10. After training, a parameter sweep is used to compare the quality of SAE features extracted from a model with “regularized” weight and a model that has been trained without it. Specifically, we measure the feature sparsity (L0) and the “cross-entropy loss increase” that results from substituting model activations with ones reconstructed using SAE features. The configurations, parameter values, and code needed to replicate the results of our experiment are available via our shared GPT Circuits GitHub repository.
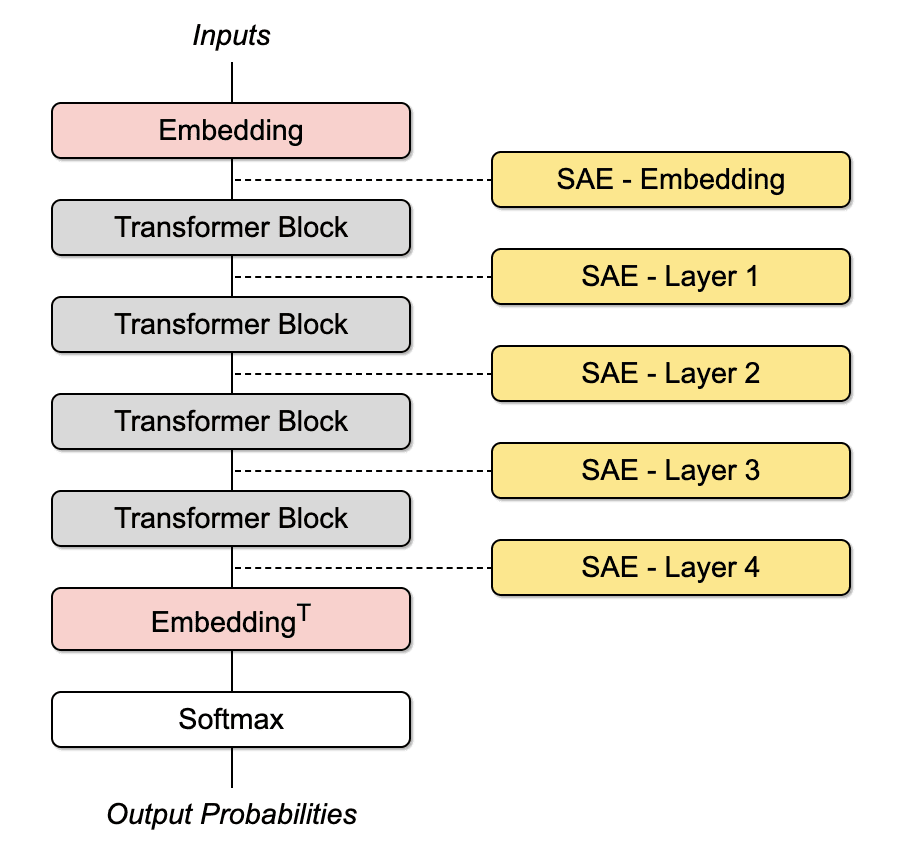
Regularization Term
“Regularized” model weights are produced through adding an “SAE regularization” term to the standard cross-entropy loss function. Regularization term components are derived from the sparse autoencoder loss functions described in Anthropic’s “Towards Monosemanticity” paper.
For the most part, we are simply adding SAE loss components to cross-entropy loss so that SAE layers and model weights can be trained simultaneously. However, we have to modify SAE reconstruction loss to prevent shrinkage of model activations during training. SAE reconstruction loss is scaled down using the magnitude of the model's activations.
Results
SAE Metrics
The following charts plot “feature sparsity” (L0) against “cross-entropy loss increase” and have been produced through averaging the results from a parameter sweep across ten independently-trained pairs of models and SAEs. On most layers, SAE regularization reliably yields better results; however, on certain layers, such as layer 3, improvements are less dependably produced. SAE regularization usually yields better results for this layer, but it occasionally produces features that are worse than those generated without it.
Embedding Layer
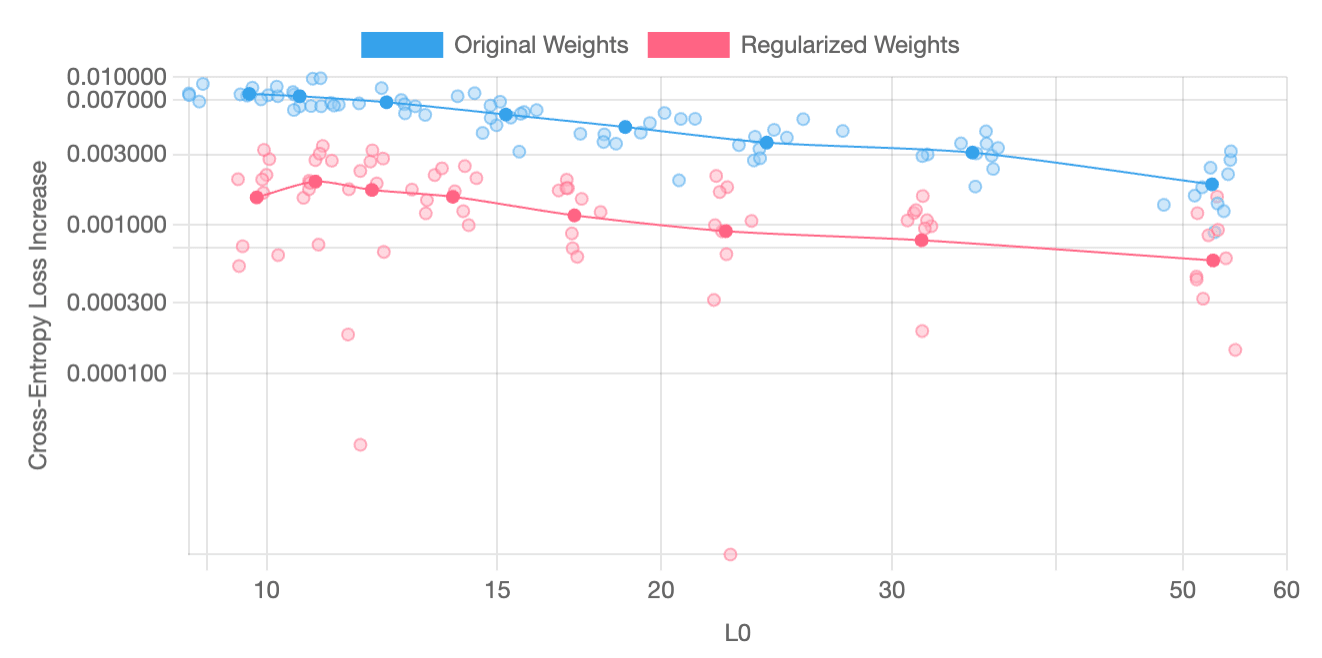
Layer 1
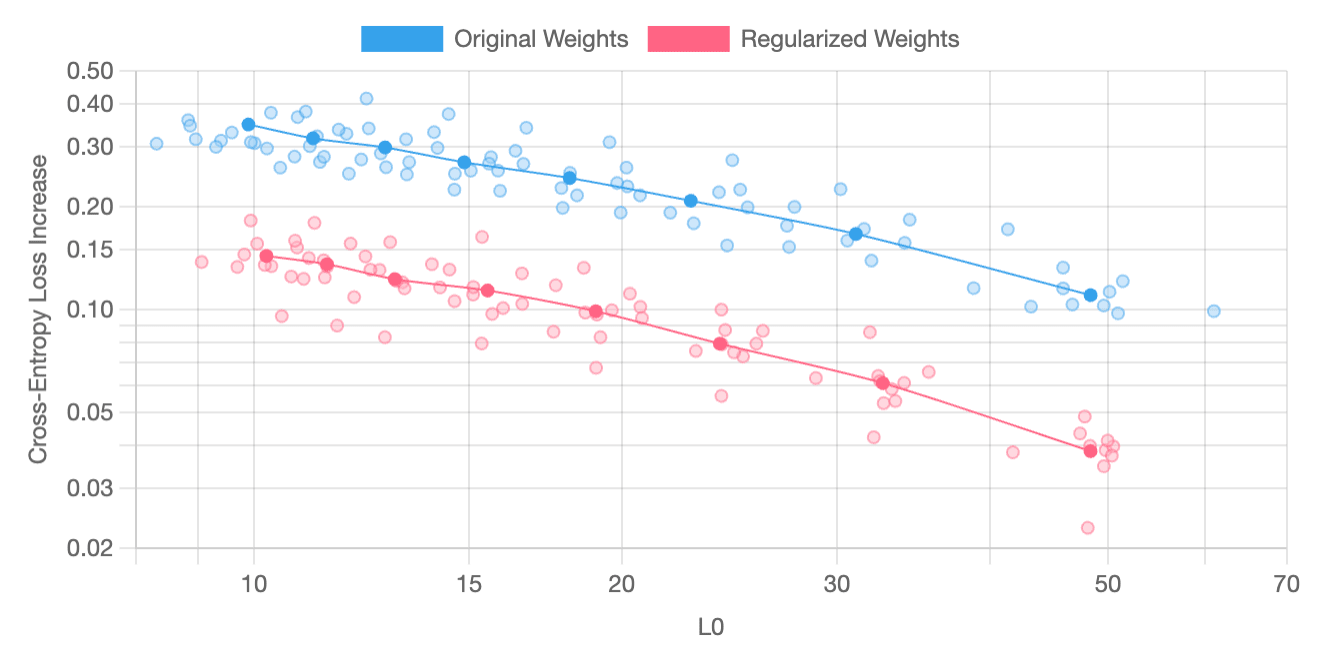
Layer 2
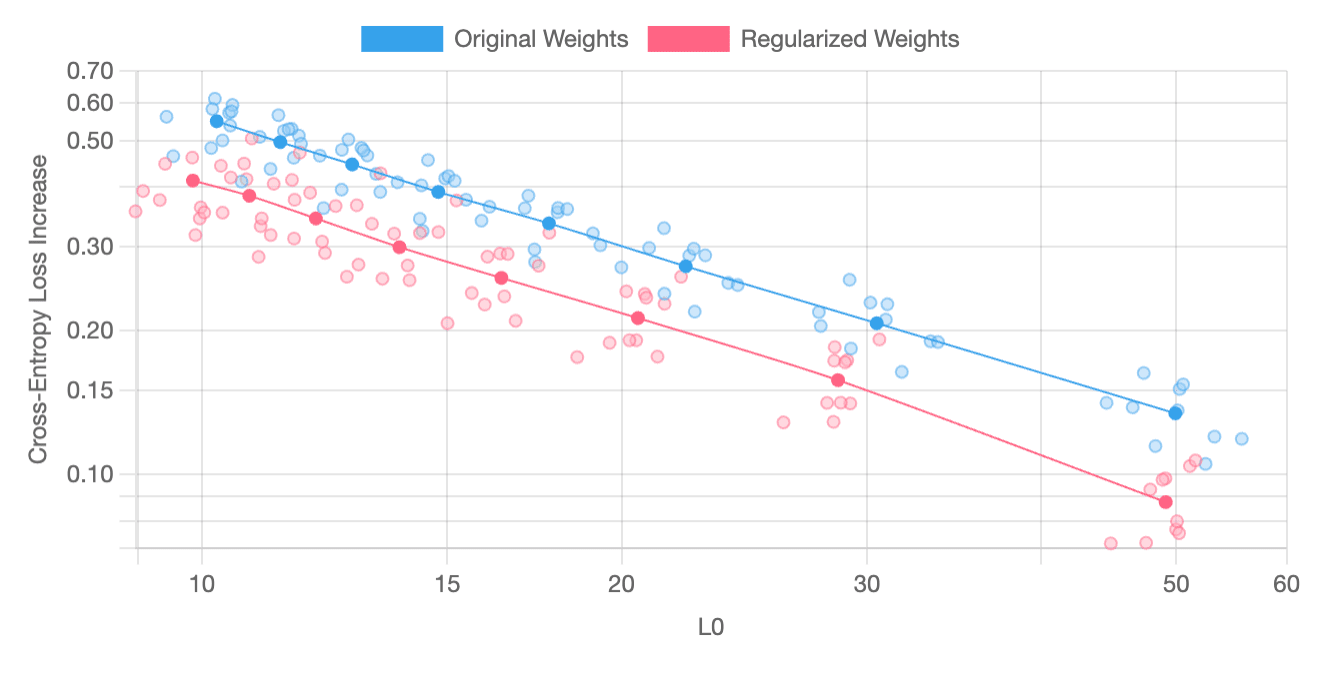
Layer 3
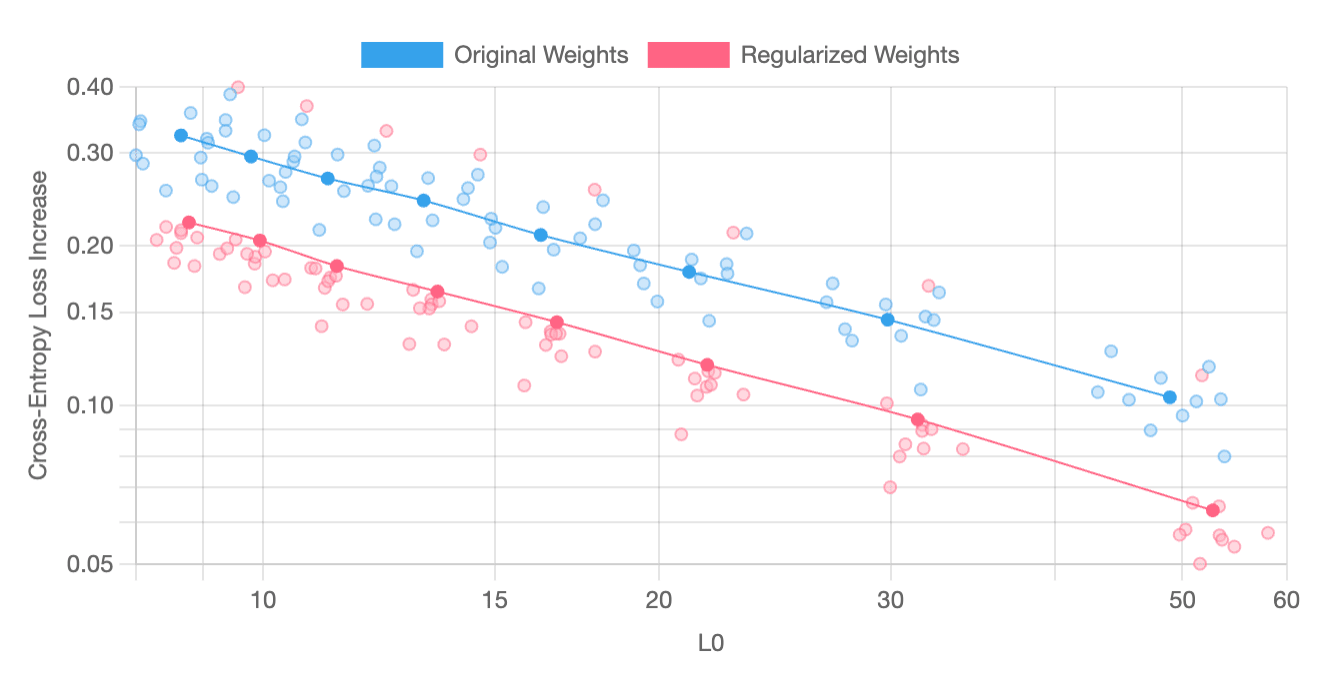
Layer 4
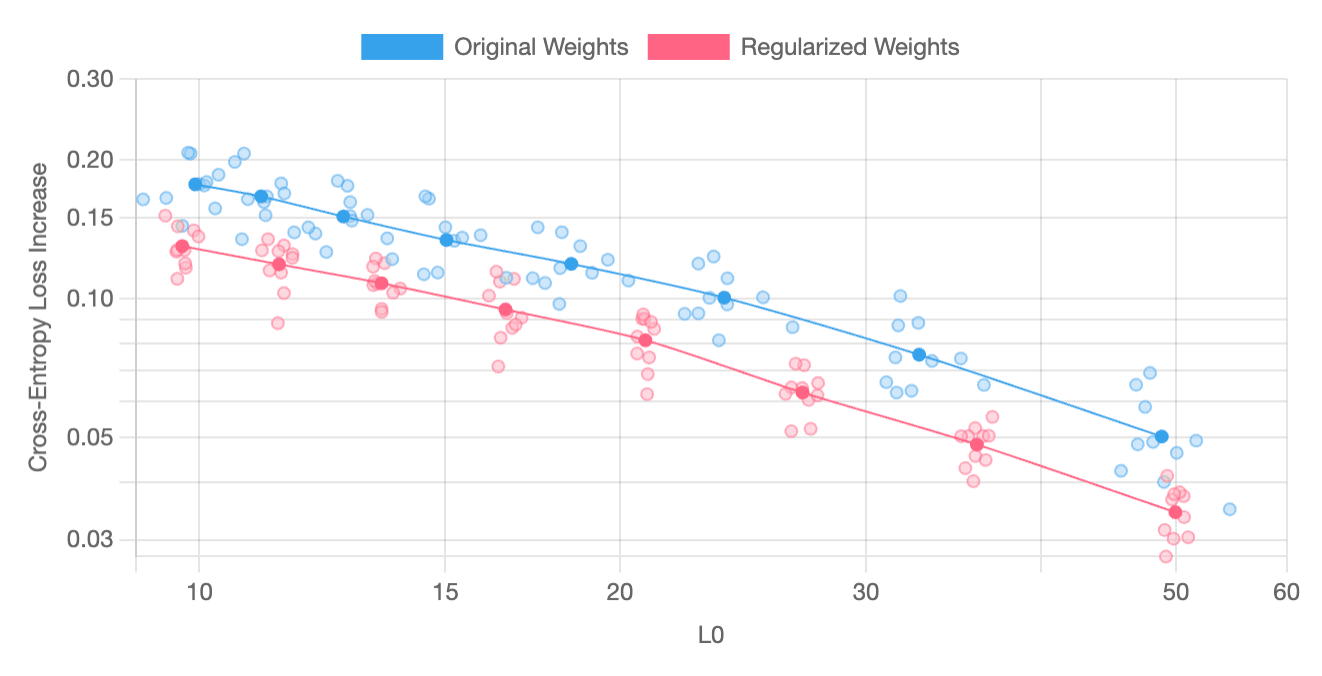
Cross-entropy Losses
Models with regularized weights and those without are trained for an equal number of iterations and with identical learning rates. Models with regularized weights reach a slightly lower cross-entropy loss, suggesting that the use of SAE regularization terms may deter overfitting. Due to the small size of our dataset, training requires multiple epochs, and we do not know if LLMs trained on larger datasets will exhibit similar training behavior.
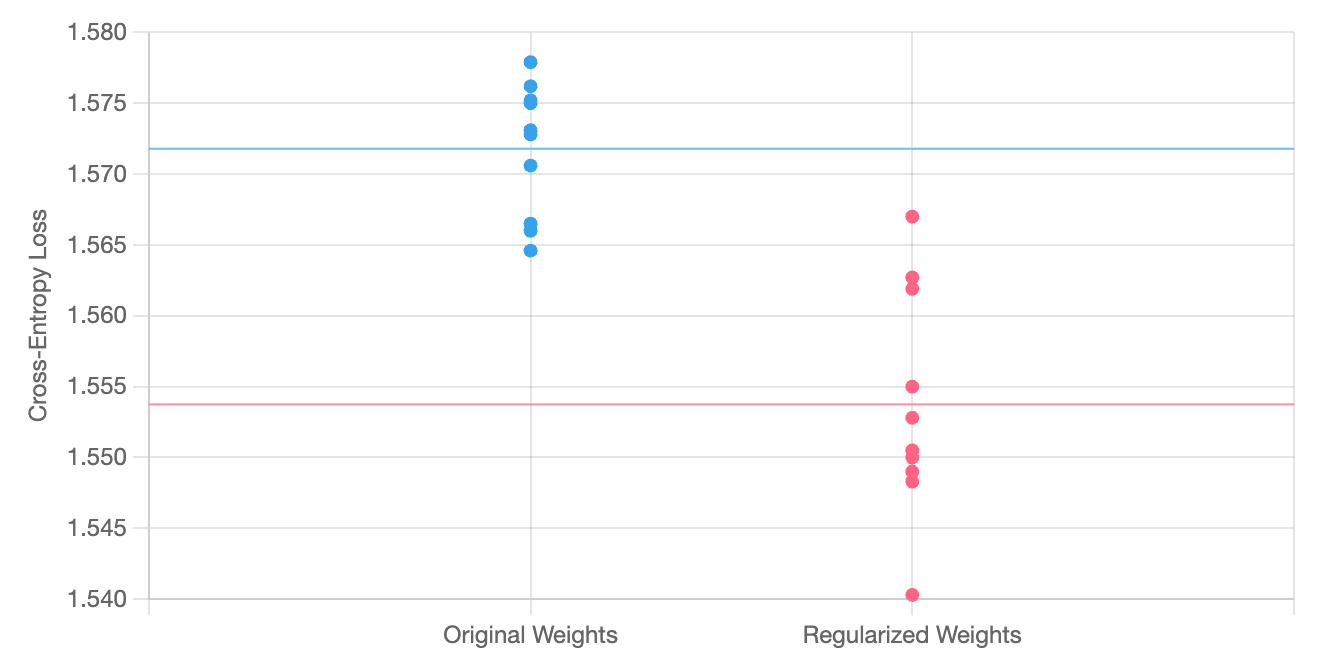
End-to-End Evaluation
Because SAE features can be used to construct circuits, we also evaluate the end-to-end performance of features generated through regularization. At each layer, SAE features are used to reconstruct model activations and patched into the residual stream. What results is a compound cross-entropy loss increase[1], which we then plot against the total number of active features across all layers (sum(L0)) for all models in a parameter sweep.
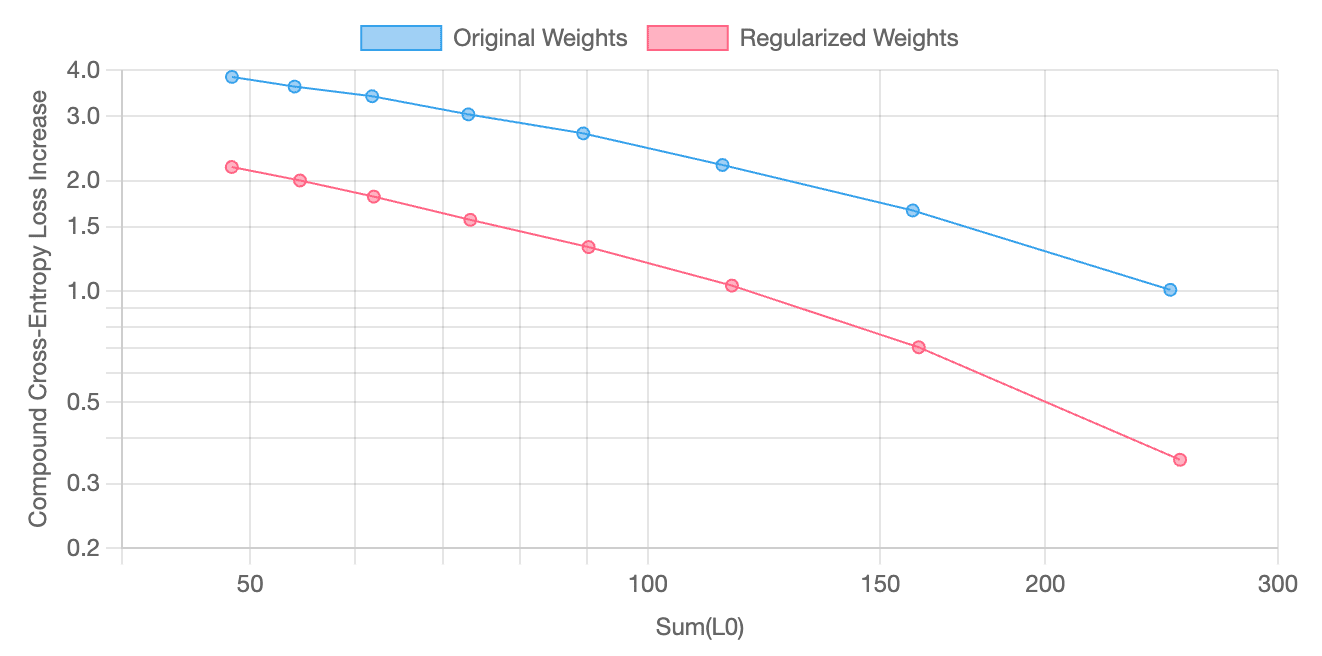
Overall, SAE regularization yields features that seem better suited for circuit analysis.
Limitations
This experiment studies the properties of SAE features that have been extracted from a toy model. Our toy model, despite being small, easily overfits the limited Shakespeare dataset used for training. SAE regularization may yield different results when used on larger models that have been trained using much larger datasets.
We did not optimize the training parameters used for this experiment. We chose a consistent learning rate and training duration that appeared effective for all model variations. We likely could have achieved slightly better cross-entropy losses through iterative adjustments, but we don’t believe those adjustments would have materially affected the outcome of the experiment.
The regularization coefficients were chosen to amplify the effect of SAE regularization. We know that, if the coefficients are too large, the regularization term starts impacting model performance as measured through cross-entropy loss. We haven't yet studied the effects of using smaller coefficients because of how tedious experiments are to configure but expect there to exist an optimal range – too low, SAE improvements become muted, and, too high, model performance suffers.
Conclusions
SAE Regularization can be used to produce features with a reduced reconstruction error for a given sparsity level. This technique requires simultaneously training SAE layers and model weights, which can be computationally impractical unless model decomposition is paramount. We don’t expect this technique to become popular except for use in producing maximally interpretable models. However, we hope that we’ve shown that SAE regularization can serve as a powerful tool for shaping internal model representations. Future work could explore alternative approaches that yield more reliable improvements or computationally efficient implementations. We’d be interested in trying SAE regularization on a more capable model, such GPT-2 small, which may require fine-tuning a model as opposed to training one from scratch. Further technical advancements are likely needed before SAE regularization applies to interpreting frontier models.
- ^
If, at every layer, we substitute residual stream activations with reconstructed activations, we introduce a compounding error that measures the overall quality of all SAE features across all layers. We term such an error the “compound cross-entropy loss increase”.
7 comments
Comments sorted by top scores.
comment by Oliver Clive-Griffin (oliver-clive-griffin) · 2025-01-28T21:22:54.255Z · LW(p) · GW(p)
produce a new set of SAE features using a different set of training parameters
By this do you mean training a new SAE on the activations of the "regularized weights"
Replies from: peter-lai↑ comment by Peter Lai (peter-lai) · 2025-01-28T22:08:17.756Z · LW(p) · GW(p)
Yep, the graphs in this post reflect the values of features extracted through training new a SAE on the activations of the "regularized" weights.
Replies from: Nadroj↑ comment by Jordan Taylor (Nadroj) · 2025-01-31T01:30:19.187Z · LW(p) · GW(p)
What is the original SAE like, and why discard it? Because it's co-evolved with the model, and therefore likely to seem more interpretable than it actually is?
Replies from: peter-lai↑ comment by Peter Lai (peter-lai) · 2025-01-31T17:15:42.651Z · LW(p) · GW(p)
The original SAE is actually quite good, and, in my experiments with Gated SAEs, I'm using those values. For the purposes of framing this technique as a "regularization" technique, I needed to show that the model weights themselves are affected, which is why my graphs use metrics extracted from freshly trained SAE values.
comment by CalebMaresca (caleb-maresca) · 2025-02-02T23:30:46.093Z · LW(p) · GW(p)
This is really cool! How much computational burden does this add compared to training without the SAEs?
I could possibly get access to an H100 node at my school's HPC to try this on GPT-2 small.
Replies from: peter-lai↑ comment by Peter Lai (peter-lai) · 2025-02-04T19:29:47.375Z · LW(p) · GW(p)
This adds quite a bit more. Code here if you're interested in taking a look at what I tried: https://github.com/peterlai/gpt-circuits/blob/main/experiments/regularization/train.py. My goal was to show that regularization is possible and to spark more interest in this general approach. Matthew Chen and @JoshEngels [LW · GW] just released a paper describing a more practical approach that I hope to try out soon: https://x.com/match_ten/status/1886478581423071478. Where there exists a gap, imo, is with having the SAE features and model weights inform each other without needing to freeze one at a time.
Replies from: caleb-maresca↑ comment by CalebMaresca (caleb-maresca) · 2025-02-11T15:36:59.676Z · LW(p) · GW(p)
Thanks, I'll take a look!