Thoughts on Toy Models of Superposition
post by james__p · 2025-02-02T13:52:54.505Z · LW · GW · 2 commentsContents
Definitions What is the point in this paper? The setup Why do we use W transpose? Why is there no bias or activation function in the hidden layer? What does visualising the Gram matrix and bias tell us? Final Thoughts None 2 comments
This post explores some of the intuitions I developed whilst reading Anthropic’s Toy Models of Superposition paper. I focus on motivating the shape of the model and interpreting the visualisations used in the paper. Their accompanying article is thoughtfully written, and I'd highly recommend reading it if you haven’t already. I make no claims that this blog post will be particularly additive to that existing piece. The primary purpose of writing this post is to:
- Test and reinforce my understanding of the paper
- Offer an additional perspective on these ideas for readers who enjoy exploring concepts from multiple angles
Provide an explainer that I can refer back to in my Conditional Importance in Toy Models of Superposition [LW · GW] post, where I rely on readers' familiarity with these ideas
Definitions
I'll first define some basic concepts.
A feature is a scalar function of the neuron activations in a layer of a neural network, which has some qualitative meaning.
[there are many different definitions of a feature, but this is the one I think is the most useful in this context]
An example of a feature in an image processing network is a cat detector: a scalar whose magnitude corresponds to the extent to which (the model believes) a cat is present.
The Linear Representation Hypothesis posits that features are represented by linear directions in activation space.
To appreciate the LRH's claim, it's helpful to think about what it would mean for it to be false.
One concrete way it might not hold is if features were to occupy different magnitudes within common directions. To take an extreme example, it could be that a specific neuron contains both a cat detector feature and dog detector feature, and the information might be encoded by if the integer part of the activation is a positive odd number, a cat has been detected, if the integer part of the activation is a positive even number, a dog has been detected, otherwise neither have been detected. A less ridiculous encoding could be that small positive activations imply a cat has been detected, whereas larger positive activations imply a dog has been detected.
It perhaps feels intuitive that models wouldn't choose to store features in this way. It feels like it would make it harder for the model to later recover the information. This is not obvious a priori though. Allowing features to occupy different magnitudes within a neural direction allows us in theory to store arbitrarily many features in that direction, rather than just one.
A stronger claim than the Linear Representation Hypothesis is the claim that features correspond to individual neuron activations. This is perhaps not as crazy as it initially sounds: the application of component-wise activation functions encourages this. Empirically, whilst in some models single neurons might correspond to features, it has been demonstrated not to hold in general (including by this paper).
Intuitively, if a model has fewer features it wants to represent than it has actual neurons in a layer, it is strongly incentivised for features to correspond to neurons (because of its component-wise activation functions). If however there's a greater number of important features than neurons, the model has to accept the fact that it can't use its privileged basis to represent all the features it would like.
A circuit is a computational pathway through a neural network in which feature(s) are computed from other feature(s).
An example circuit is a pathway which causes a cat detection feature to fire if and only if a whisker detector feature, a tail detector feature, and triangular ear detector feature are all firing in previous layer(s). This is an instance of a more general circuit motif that we call the intersection motif.
Polysemanticity is the phenomenon that neurons fire for multiple seemingly unrelated features.
Empirically, this occurs in real models. It supplies counter evidence to the claim that features are necessarily represented linearly by individual neurons.
A model is said to exhibit superposition if it represents more features than it has neurons (and thus dimensions) in a layer.
If features are represented linearly then a basic result from linear algebra asserts that you cannot represent more than features in an -dimensional layer without interference. A curious property of high-dimensional vector spaces though, is that it is possible to form sets of almost orthogonal vectors (vectors with small, but not quite zero, pairwise scalar products). The superposition theory postulates that models want to represent features linearly but they also want to represent more features than they have dimensions, and thus they resort to representing them in almost orthogonal directions of activation space.
We should note that superposition implies polysemanticity. Conversely, the presence of polysemanticity in real models is suggestive evidence (but not proof) of superposition. The Toy Models of Superposition paper demonstrates superposition explicitly, which provides some evidence in favour of superposition likely existing in full-scale models.
The sparsity of a feature set is the extent to which the features tend not to activate concurrently.
In an image detection network, the set {dog detector, cat detector, giraffe detector} might present an example of a sparse feature set since it is uncommon that these features fire at the same time.
It is intuitive that a sparser feature set would be punished less by interference, and so perhaps more likely exist in superposition. Sparsity is a parameter that Anthropic tweak in their work in order to have their toy models exhibit varying amounts of superposition.
What is the point in this paper?
Understanding how features are represented in models is a crucial subproblem of the general task of interpretability. This paper attempts to provide the first concrete demonstration of superposition occurring in a neural network. Such a demonstration will provide a reference point for future studies of features and circuits in full-scale models.
The setup
The basic model that we consider projects a higher-dimensional vector into a lower-dimensional latent space , and then attempts to recover it. The idea is that our model will be incentivised to represent more than of the features in the latent space to minimise loss in the recovery, and thus will exhibit superposition.
, ,
The loss is defined to be importance-weighted mean-squared error:
Why do we use W transpose?
In the toy model, we only have one matrix of weights, . The weights for our first (encoding) layer are reused in our second (decoding) layer via taking the transpose. Why is this? Why not define a second matrix and allow it to have its own independently learned weights?
To answer this question, let's start from the beginning. is a not a square matrix, but rather it has rows and columns (where ).
So that we can visualise the weights concretely, suppose that and . Then our matrix looks as follows:
The standard orthonormal basis vectors for get mapped by as follows:
This shows us that can be thought of as an array of 3 vectors in , corresponding to the directions that each of our 3 features are mapped to.
Our model would ideally like these three vectors to be orthogonal as this would allow for lossless recovery of our input, however as we know it is not possible to have 3 linearly independent vectors in .
Let's suppose for a moment that it were possible though. If , , formed an orthonormal basis for , what matrix would we then need in order to recover our inputs? We'd need precisely !
This is simply a restating of the linear algebra result that any orthonormal matrix satisfies , but applied to our hypothetical context in which we imagine a non-square matrix can be orthonormal.
The intuition behind using in our model comes from precisely this idea: if is indeed projecting features onto an almost orthonormal set in , then it is approximately true that the best matrix to recover the original vectors is . More precisely, as the set of vectors comprising tends towards being orthonormal, the optimal recovery matrix tends towards . Given we expect and hope that our toy model is going to map features to almost orthogonal directions of the latent space, we can therefore give it a hand by asserting that the recovery matrix is and therefore reducing redundant parameters.
Some caveats to the above discussion should be pointed out:
- In talking about the optimal recovery matrix, the above discussion conveniently omits that a non-linear activation function () is applied after , and instead imagines we are in the purely linear world. Whilst this undermines the precision of the claims above, I think the thematic ideas still hold.
- The matrix will in practice commonly have zero vectors interspersed amongst its vectors, corresponding to features that are dropped in the latent space. This doesn't affect any of the maths above.
Why is there no bias or activation function in the hidden layer?
In a typical multi-layer perceptron, we would expect each layer to consist of a weight matrix , a bias vector , and a non-linear activation function (in our case ReLU). It is notable then that the hidden layer of our network has neither a bias nor an activation function.
Similarly to how we assert that is the best recovery matrix for this problem, we implicitly assert that is the correct intermediate bias. The mathematics above can be thought of as saying that if is almost orthonormal, then it is approximately true that the optimal and values to recover our input via are given by and .
The lack of intermediate is also necessary to allow us to use this neat trick. Suppose instead that our model looked as follows:
,
It would no longer be clear that is the best recovery matrix, and thus we'd be stuck with twice as many free parameters: , , , and all being distinct. We would lose the ability to visualise the resulting superposition via visualising the Gram matrix , discussed later in this post.
The paper hopes that whilst dropping the intermediate non-linear activation function allows us to contain and visualise the superposition, it does not materially affect whether superposition occurs. It therefore hopes that we may still draw conclusions that are relevant to real models.
What does visualising the Gram matrix and bias tell us?
The primary visualisation technique that I want to motivate is the printing out of and .
For the visualisations below, I will assume that we are considering models that project 20-dimensional vectors into a 10-dimensional latent space, and then attempt to recover them. My model(s) therefore have 220 learnable parameters (200 matrix entries and 20 bias values).
,
We visualise the matrix and bias values on a scale where blue corresponds to large negative values and orange corresponds to large positive values.

The following is how this looks for a randomly initialised and untrained model:
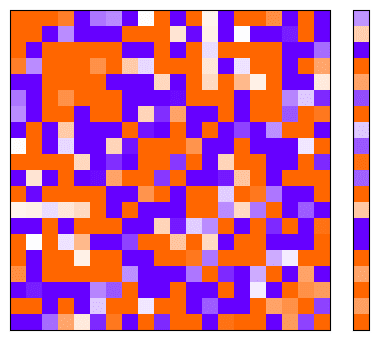
Note that is necessarily symmetric regardless of whether has learnt structure or is completely random: .
What should this look like if our model is able to perfectly recover all input vectors? We should be clear that this is impossible and so this case is a hypothetical, but we might expect our visualisation to look as follows:

This simply corresponds to being the identity matrix (which we recall happens when is orthonormal), and being the zero vector. It is clear that (putting ReLU aside for a moment) a model of this form would perfectly recover our input vectors.
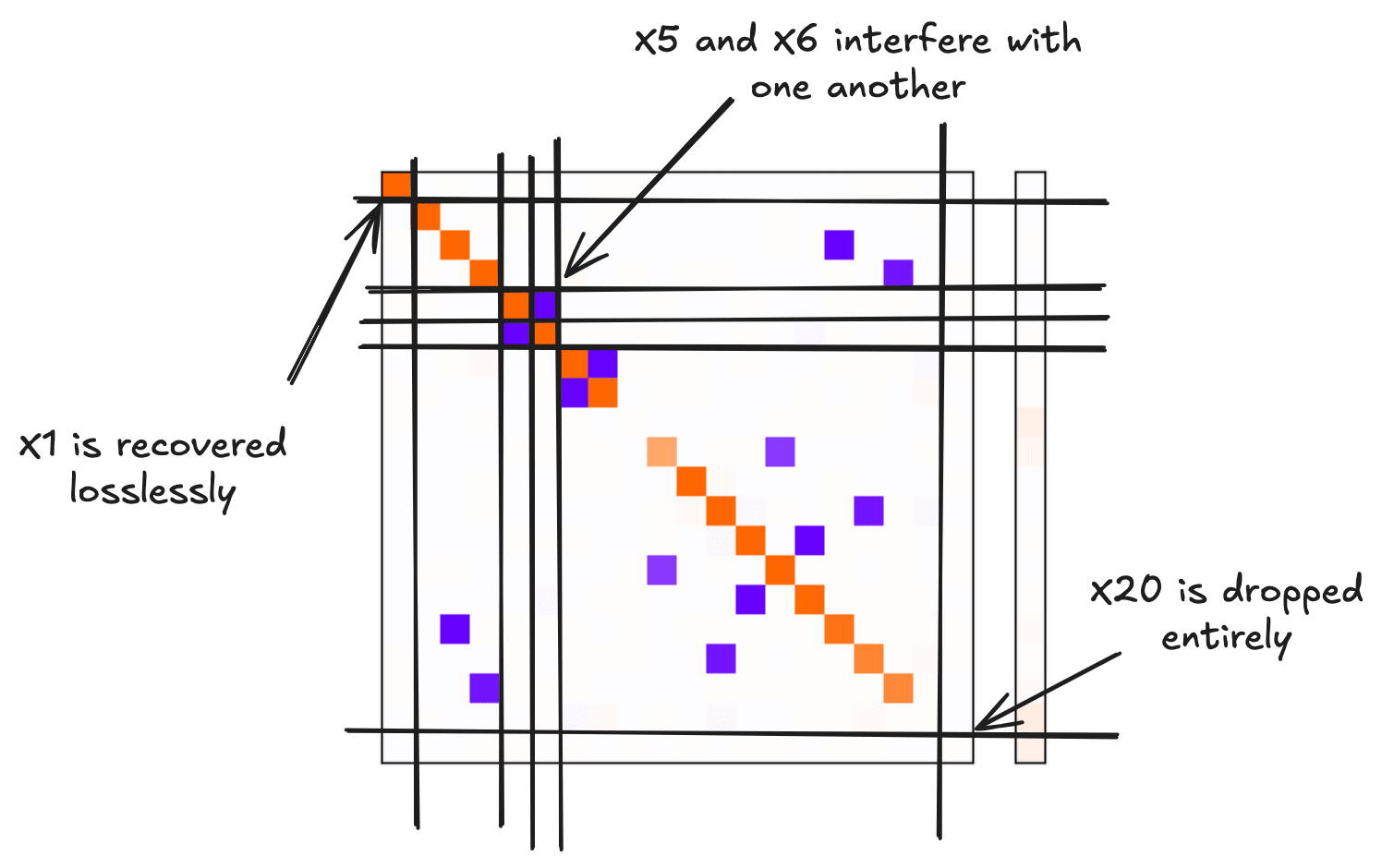
More generally, to interpret a visualisation of this form, we consider the following observations:
- Orange dots in the diagonal show the model trying to represent features in the latent space
- Dots not on the diagonal indicate interference between features in the latent space, which is indicative of superposition
- The feature getting recovered with no interference manifests as the column (and row) showing up with a single orange dot on the diagonal and no other coloured dots
Consider the following example:

We see that there are features such as which are perfectly recovered, as depicted by the column (and row) having nothing but a single orange dot on the diagonal.
There are features such as which are entirely dropped, as depicted by the column (and row) containing only whitespace.
Finally, there are features such as and which are both represented in the latent space but interfere with one another. This is depicted by the fact that the and columns (and rows) contain both orange dots on the diagonal as well as blue dots in positions and .
Final Thoughts
In this post, I have focused on motivating the foundational ideas which I rely on in my Conditional Importance in Toy Models of Superposition post. In that post, I ask the question of whether features which are never concurrently important are more likely to exist in superposition with one another.
There are many interesting avenues explored in the original Toy Models paper which I don't touch on at all in this post, so again I highly recommend reading it if you haven't already.
2 comments
Comments sorted by top scores.
comment by TheManxLoiner · 2025-03-09T22:20:49.970Z · LW(p) · GW(p)
there are features such as X_1 which are perfectly recovered
Just to check, in the toy scenario, we assume the features in R^n are the coordinates in the default basis. So we have n features X_1, ..., X_n
Separately, do you have intuition for why they allow network to learn b too? Why not set b to zero too?
Replies from: james__p↑ comment by james__p · 2025-03-10T22:08:09.237Z · LW(p) · GW(p)
Just to check, in the toy scenario, we assume the features in R^n are the coordinates in the default basis. So we have n features X_1, ..., X_n
Yes, that's correct.
Separately, do you have intuition for why they allow network to learn b too? Why not set b to zero too?
My understanding is that the bias is thought to be useful for two reasons:
- It is preferable to be able to output a non-zero value for features the model chooses not to represent (namely their expected values)
- Negative bias allows the model to zero-out small interferences, by shifting the values negative such that the ReLU outputs zero. I think empirically when these toy models are exhibiting lots of superposition, the bias vector typically has many negative entries.