Conditional Importance in Toy Models of Superposition
post by james__p · 2025-02-02T20:35:38.655Z · LW · GW · 4 commentsContents
Abstract Why is this important for AI Safety? What Do I Mean by Conditional Importance? Experimental Setup Preliminary Results Observations Mathematical Intuition for why Conditional Importance "doesn't matter" Equivalence between Conditional Importance and Anti-correlated Features Conclusions Ideas for Further Work Acknowledgements None 4 comments
Abstract
This post summarises my findings from investigating the effects of conditional importance on superposition, building on Anthropic's Toy Models of Superposition work. I have summarised my takeaways from the Toy Models of Superposition paper in this blog post [LW · GW] and explained the key concepts necessary for following my work. The following assumes you are familiar with those ideas.
Why is this important for AI Safety?
I believe that the interpretability of AI systems is key to AI safety, since it could allow us to detect and mitigate misaligned behaviours. If our ability to understand advanced intelligences is limited to interpreting their output, we may not be able to find out when a model is being deceptive or has ulterior motives.
Understanding superposition appears likely to be one of main stepping stones in the pursuit of interpretability, as it allows us to understand how features are represented, which is necessary for tackling circuits.
My Theory of Change for this post can be understood by these three goals:
- I hope to teach readers (ideally aspiring interpretability contributors) some intuitions for thinking about features, circuits, and superposition
- I hope to get newcomers that stumble across this post excited about working on superposition and interpretability more generally, and...
- (perhaps ambitiously) I'd like to contribute a small piece of research to the existing literature on superposition, though I accept that any ideas I explore in this post are unlikely to be novel to experts in the field
What Do I Mean by Conditional Importance?
To define Conditional Importance, we must first recap the toy model setup (but please read my blog post [LW · GW] for a deeper dive). In the Toy Models of Superposition piece, the basic model that we consider projects higher-dimensional vectors into a lower-dimensional latent space, and then attempts to recover them:
, ,
The loss is defined to be importance-weighted mean-squared error:
In particular, since is a fixed vector, we are assuming that each of the input features has a fixed importance (the importance vector is commonly modelled as , for example).
The purpose of including an importance vector at all is to allow us to simulate the idea that certain features in a full-scale model may prove to be more important than others further down the line. In a real model, we'd use MSE not importance-weighted MSE as our loss. Important features would instead naturally receive higher weight as they'd ultimately have a larger effect on loss reduction. In this toy model we use importance-weighted MSE as our loss to directly imitate this effect.
To give a concrete example, might be a dog detection feature and a background darkness detection feature. In the context of a full-scale image classification model, the dog detection feature may be on average far more important for loss reduction than the background darkness detection feature. The way we would account for this in the toy model is by simply writing out what the average importance of each feature is and including these in the loss function.
The assumption that the importance vector is fixed clearly fails for full-scale models though. Take the following example:
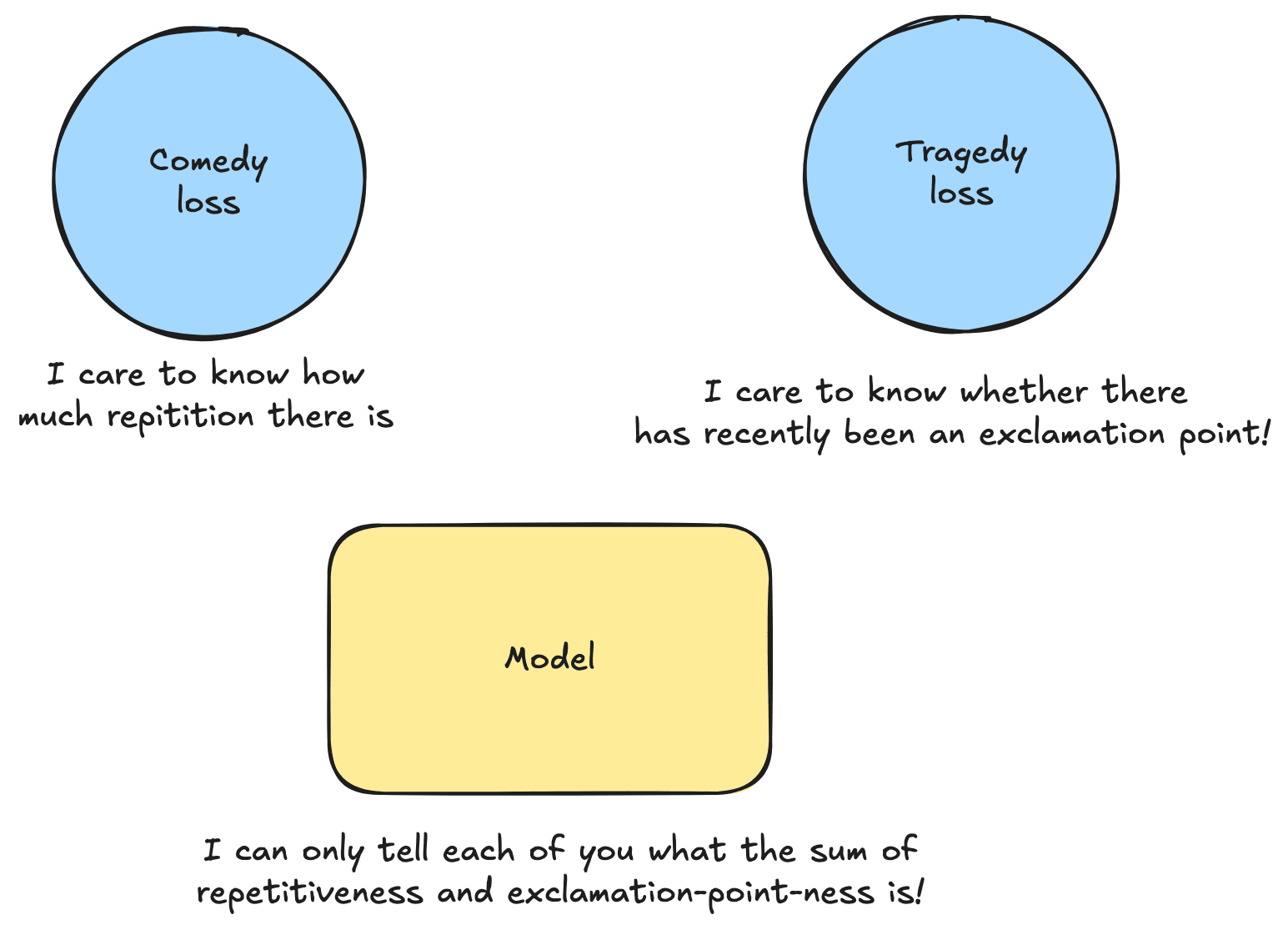
We have a language model, trying to predict the next word in a sequence. Samples from our dataset can fall into one of two categories: Comedy or Tragedy. Conditional on our sample being a Comedy, features to might be especially important, whereas conditional on our sample being a Tragedy, features to might be especially important.
An example of a feature that might be especially important in the context of a Comedy, but less important in the context of a Tragedy, is a repetition detector. There may be a feature which fires when repetition is present, and this may be crucial for interpreting comedic devices.
Note: at first glance, this idea feels very similar to the idea of anti-correlated features (discussed in detail in the Toy Models piece). The defining difference here is that we are not making any claims about the feature values themselves.
It might be the case that in the context of a Comedy, features to are significantly more likely to fire, whereas in the context of a Tragedy, features to are significantly more likely to fire. This would be an example of the anti-correlated features case. With conditional importance however, we have features such as the exclamation point detector which may be just as likely to fire in Comedy and Tragedy, but simply more important for loss reduction down the line when the context is Tragedy say. In particular, our 20 features could be completely independent, and yet their importance could be anti-correlated in this way.
I will discuss the relationship between Conditional Importance and anti-correlated features more later in this post.
Experimental Setup
I am training toy models which project 20-dimensional vectors into a 10-dimensional latent space, and then attempt to recover them. My model(s) therefore have 220 learnable parameters (200 matrix entries and 20 bias values).
,
I discuss the motivation for this model shape in this blog post section [LW · GW], so please read this if the setup is unclear.
My synthetic training data is comprised of 20-dimensional vectors , generated with sparsity (following Anthropic's convention) meaning that each is with probability and otherwise drawn from independent distributions. Note that the are iid (independent and identically distributed).
The importance vector for each datapoint was determined using the example outline above: namely imagining there's a probability that our datapoint is a Comedy, resulting in importance vector:
and a probability that our datapoint is a Tragedy, therefore having importance vector:
Preliminary Results
My code can be found in this colab notebook.
I will interpret these results by visualising the Gram matrix and the bias vector . Recall that this visualisation represents how input dimensions are represented in the latent space, and how they interfere with one another. If this doesn't make sense to you, refer to my more detailed explanation in this post [LW · GW].
We visualise this at three steps in the model's training, using the following colour coding:

Phase 1: The model weights have been randomly initialised but no training has been done.
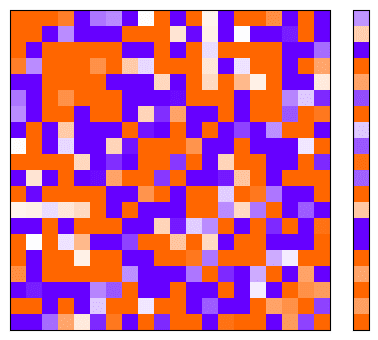
Phase 2: 4 epochs have passed. The model appears to have more structure. We are still observing significant loss reduction on each epoch.
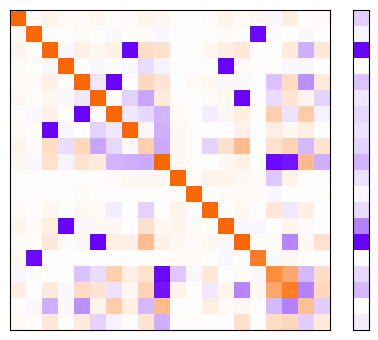
Phase 3: 12 epochs has passed. The structure is much clearer. Loss reduction has plateaued.
Note: the model we converge on is non-deterministic. When running this multiple times, I see similar but non-identical patterns occurring in and . Both the random initialisation of the model weights and the random generation of the synthetic data are at play here (though all models obtained are qualitatively similar in that they lead to the same observations below).
Observations
- It appears that some superposition is occurring. The model is representing more than 10 dimensions in the latent space (>10 orange dots on the diagonal). This is not particularly surprising.
- The superposition pattern looks similar to what we might expect if we weren't applying conditional importance. I initially found this surprising, as I expected conditional importance to encourage superposition.
For an apples-to-apples comparison, let's see what we get if we train a model without conditional importance, but instead the following fixed importance vector:
for for
This is similar to the importance vectors used above, except we never do any zero-ing out of components due to Comedy or Tragedy selection. Indeed the results we get are qualitatively similar.
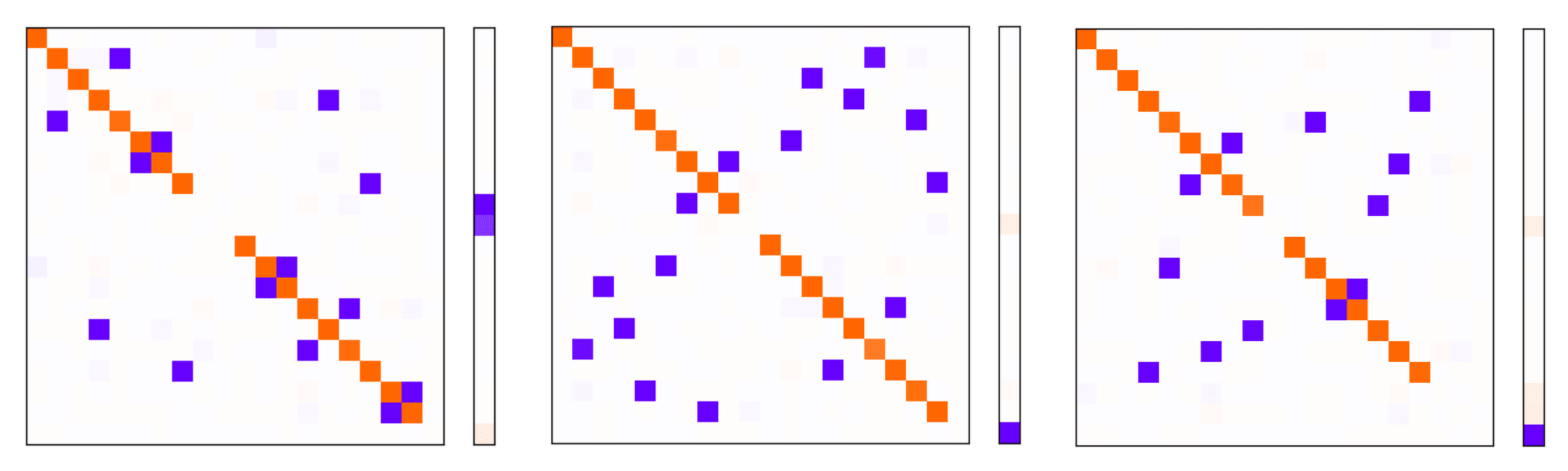
Models trained without Conditional Importance (3 different random seeds):
Models trained with Conditional Importance (3 different random seeds):
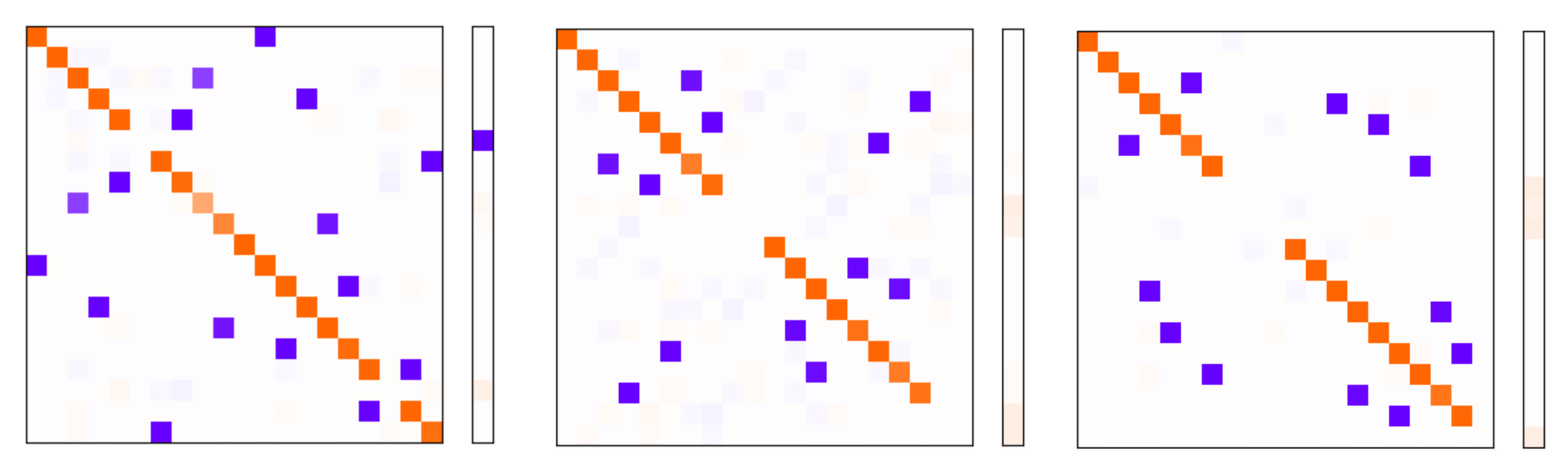
As you can see, all six plots look qualitatively similar in the sense that:
- They represent roughly 16-18 features in the latent space (16-18 orange dots on the diagonal), indicating some superposition is taking place
- They generally prioritise representing features with higher average importance (the diagonal squares with missing orange dots tend not to be near the upper left corner of the top left or bottom right quadrants)
And, crucially...
- They just as readily allow features within one of the two feature subsets to interfere with one another (depicted by the fact that blue dots appear in all 4 quadrants, rather than just the bottom left and upper right!)
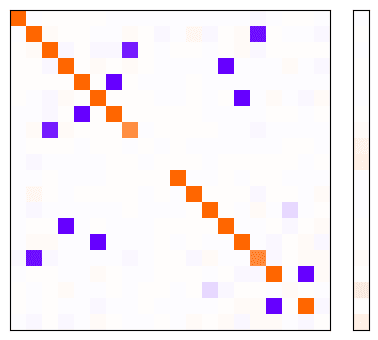
If it were instead the case that conditional importance led to the model being incentivised to have features in opposing feature sets share directions in the latent space, we might expect the gram matrix to instead look as follows:

I produced this by training a model using a similar setup to the condition importance setup, except zero-ing out the features rather than zero-ing out the importances. This is the anti-correlated features case.
Whilst at first glance this doesn't look too dissimilar to the Gram matrices we obtained with conditional importance, it is fundamentally different in the following ways:
- All 20 features are represented in the latent space (the diagonal is fully populated)
- There is 0 interference between features within a feature subset (the top left and bottom right quadrants have no blue dots)
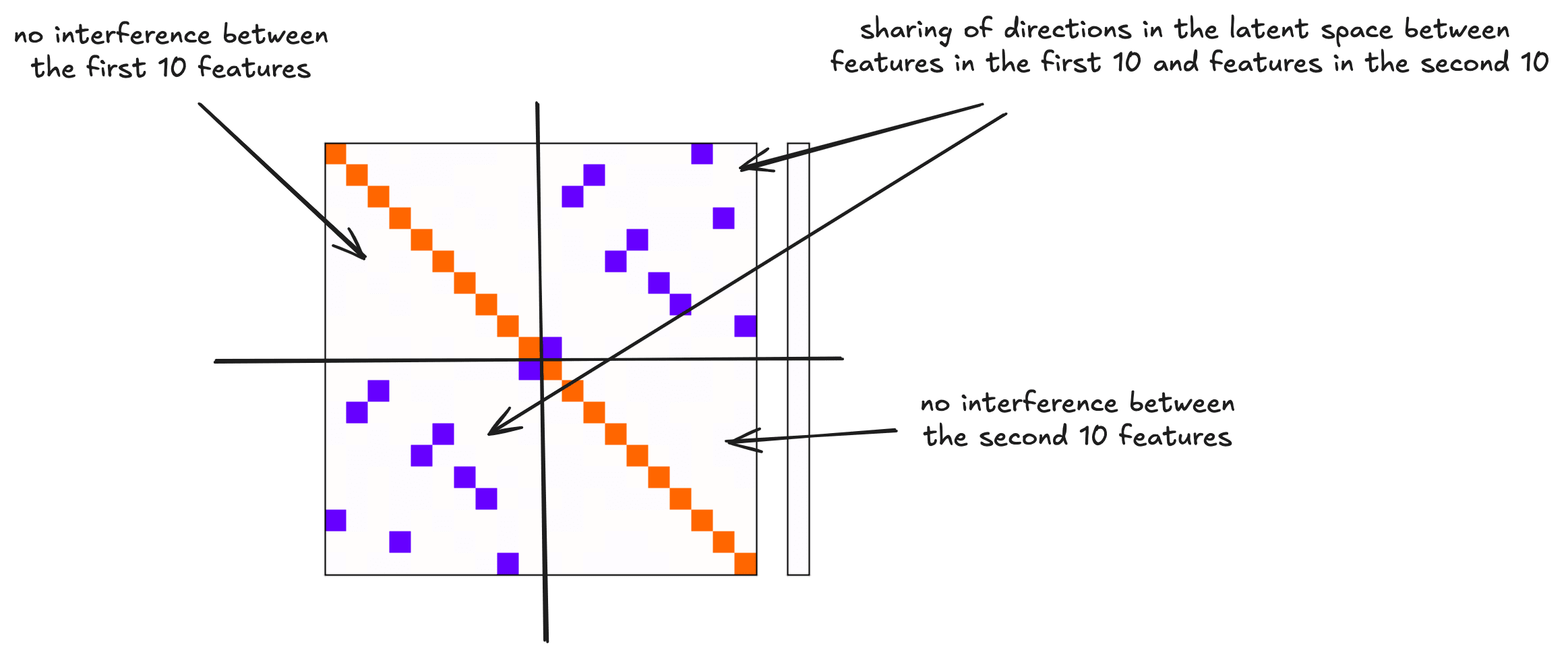
The fact that models trained with conditional importance do not look like this shows that conditional importance does not make it any easier for the model to represent features in superposition, unlike with anti-correlated features. This was initially surprising to me, but I discuss in the next section why with hindsight I actually think this is intuitive.
Mathematical Intuition for why Conditional Importance "doesn't matter"
You may have come into this (like I did) with the following expectation: features that are never important at the same time will be more inclined to share common dimensions, similarly to how anti-correlated features are. I think this intuition is wrong and here's why...
The metric our model cares about is the sum of the losses of individual datapoints. If two of our features interfere with one another then even if only one of them is important for a given datapoint, we can only ever lossily recover that feature.
Suppose that the feature is a repetition detector, and the feature is an exclamation point detector. Suppose that and are independent, and in particular we learn nothing about their value upon finding out whether our example is a comedy or a tragedy (both repetition and exclamation points occur just as frequently in comedic and tragic writing). Suppose however that is important only in the context of a comedy and is important only in the context of a tragedy.
If and were to share a common dimension in the latent space, our model would recover the sum of and in both the 1st and the 11th positions of its output:
Note: this makes the simplifying assumption that and share exactly the same direction in the latent space, and interfere with no other features.
Even though we only care about recovering one of or at any given time, our loss is still punished as we can't recover either feature without interference with the other unimportant feature. So when we care about repetition, the unimportant but still firing exclamation point detector gets in the way, and when we care about exclamation points, the unimportant but still firing repetition detector gets in the way!
Equivalence between Conditional Importance and Anti-correlated Features
There is in some sense an equivalence between my conditional importance setup and the anti-correlated features setup.
Consider the 20-dimensional Comedy vs. Tragedy scenario above, where features to have correlated positive importance conditional on Comedy with to zero, whereas to have correlated positive importance conditional on Tragedy with to zero.
I claim that this information can be "equivalently" represented with a 40-dimensional feature vector where:
with fixed importance given by:
for for , for
We can see this by observing that for a Comedy, only the first 20 features in will have non-zero value, and only the first 10 of those have non-zero importance. In the case of a Tragedy however, only the second 20 features in have non-zero value, and only the final 10 of those have non-zero importance.
We now have a scenario where the importance vector (now 40-dimensional) is fixed, but our feature vector (now 40-dimensional) no longer has independent components, rather they are anti-correlated.
Notice that the middle 20 features in all have zero importance, and so recovering them means nothing to us. For the purposes of our model, we can happily drop these features and instead simply consider where:
and our importance is now given by:
for for
There is a subtle (but perhaps important) difference between this Z representation and our original X representation. With X, there was no way for the model to know whether it was dealing with a Comedy or a Tragedy, whereas the new Z representation contains this information. I'll touch on this more in Conclusions and Ideas for Further Work.
So what do we see if we train a model to recover this vector with importance , rather than our initial vector with importance ?
,
Well, we are now in precisely the same anti-correlated features case discussed above! We obtain the Gram matrix:
Importantly, due to the additional superposition occurring, the loss is now lower than when we tried to encode and recover directly. Essentially, we've given the model a hand by zeroing out features whilst they're unimportant, thus allowing it to represent more features in superposition.
Another way to think about this is that the ability to recover features of the form detector and detector is just as good for our objective as the ability to recover the more general repetition detector and exclamation point detector features. However, it is easier for our model to represent and recover the intersection features with minimal interference.
Conclusions
The key conclusion I came to in this study is that features not being important at the same time doesn't naively make it any easier for models to represent them in superposition. The feature values themselves need to be anti-correlated for the model to have an easier time superposing them.
Features with conditional importance can be equivalently represented using anti-correlated features with fixed importance though, and this representation allows for more superposition to manifest.
I think this means that, where possible, models may opt to represent features of the form:
rather than simply:
and in order to do this, it will be important for the model to have enough information to deduce which context it is dealing with, and thus which of the features are likely to be important.
Ideas for Further Work
Some ideas I have for further work along these lines are:
- Train a toy model with additional layer(s), and see if we can get the model to learn to translate the features with conditional importance into anti-correlated features with fixed importance by itself. I expect that we will need to include a feature which encodes whether our example is a Comedy or a Tragedy to make this work.
- Experiment with using non-linearities other than ReLU, to see whether superposition is more or less encouraged.
There are many more proposed extensions to the Toy Models paper which Neel Nanda outlines in his 200 Concrete Open Problems in MechInterp [? · GW].
Acknowledgements
This post was written as part of my Capstone project for the BlueDot AI Safety Fundamentals course, which I highly recommend to anyone new to AI safety and eager to explore the field.
I’m grateful to my cohort and our facilitator, Oliver De Candido, for their valuable feedback and support throughout this project.
I am also greatly appreciative of the authors of Toy Models of Superposition for providing the foundation that helped guide my thinking on this topic, and presenting it in such an interactive and accessible format.
Thank you to g__jacobs [LW · GW] for proof-reading and providing feedback on this post.
4 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2025-02-03T20:27:53.040Z · LW(p) · GW(p)
I honestly think your experiment made me more temporarily confused than an informal argument would have, but this was still pretty interesting by the end, so thanks.
Replies from: james__p↑ comment by james__p · 2025-02-13T13:51:22.817Z · LW(p) · GW(p)
Yeah I agree that with hindsight, the conclusion could be better explained and motivated from first principles, rather than by running an experiment. I wrote this post in the order in which I actually tried things as I wanted to give an honest walkthrough of the process that lead me to the conclusion, but I can appreciate that it doesn't optimise for ease to follow.
comment by TheManxLoiner · 2025-03-09T23:47:22.594Z · LW(p) · GW(p)
Vague thoughts/intuitions:
- Using the word "importance" I think is misleading. Or, makes it harder to reason about the connection between this toy scenario and real text data. In real comedy/drama, there is patterns in the data to let me/the model deduce it is comedy or drama and hence allow me to focus on the conditionally important features.
- Phrasing the task as follows helps me: You will be given 20 random numbers x1 to x20. I want you to find projections that can recover x1 to x20. Half the time I will ignore your answers from x1 to x10 and the other half the time x11 to x20. It's totally random which half of the numbers I will ignore. xi and x_{10+i} get the same reward, and reward decreases for bigger i. Now, I find it easier to understand the model: the "obvious" strategy is to make sure I can reproduce x1 and x11, then x2 and x12, and so on, putting little weight on x10 and x20. Alternatively, this is equivalent to having fixed importance of (0.7, 0.49,...,0.7,0.49,...) without any conditioning.
- Follow up Id be interested in is if the conditional importance was deducible from the data. E.g. x is a "comedy" if x1 + ... + x20 > 0. Or if x1>0. With same architecture, I'd predict getting the same results though...? Not sure how the model could make use of this pattern.
- And contrary to Charlie, I personally found the experiment crucial to understanding the informal argument. Shows how different ppl think!
↑ comment by james__p · 2025-03-22T13:22:58.499Z · LW(p) · GW(p)
Thanks for the thoughts --
- I used the term "importance" since this was the term used in Anthropic's original paper. I agree that (unlike in a real model) my toy scenario doesn't contain sufficient information to deduce the context from the input data.
- I like your phrasing of the task - it does a great job of concisely highlighting the 'Mathematical Intuition for why Conditional Importance "doesn't matter"'
- Interesting that the experiment was helpful for you!