Squiggle: An Overview
post by ozziegooen · 2020-11-24T03:00:32.872Z · LW · GW · 6 commentsContents
Overview Video Demo A Quick Tour A simple normal distribution Lognormal shorthand Mix distributions with the multimodal function Mix distributions with discrete data Variables Simple calculations Pointwise calculations First-Class Functions Reasons to Focus on Functions What Squiggle is Meant For Future "Comprehensive" Uses Why doesn't this exist already? Related Tools Guesstimate Ergo Elicit Causal Spreadsheets Probabilistic Programming Languages Prediction Markets and Prediction Tournaments Declarative Programming Languages Knowledge Graphs Next Steps Footnotes None 6 comments
Overview
I've spent a fair bit of time over the last several years iterating on a text-based probability distribution editor (the 5 to 10 input editor in Guesstimate and Foretold). Recently I've added some programming language functionality to it, and have decided to refocus it as a domain-specific language.
The language is currently called Squiggle. Squiggle is made for expressing distributions and functions that return distributions. I hope that it can be used one day for submitting complex predictions on Foretold and other platforms.
Right now Squiggle is very much a research endeavor. I'm making significant sacrifices for stability and deployment in order to test out exciting possible features. If it were being developed in a tech company, it would be in the "research" or "labs" division.
You can mess with the current version of Squiggle here. Consider it in pre-alpha stage. If you do try it out, please do contact me with questions and concerns. It is still fairly buggy and undocumented.
I expect to spend a lot of time on Squiggle in the next several months or years. I'm curious to get feedback from the community. In the short term I'd like to get high-level feedback, in the longer term I'd appreciate user testing. If you have thoughts or would care to just have a call and chat, please reach out! We (The Quantified Uncertainty Research Institute) have some funding now, so I'm also interested in contractors or hires if someone is a really great fit.
Squiggle was previously introduced in a short talk that was transcribed here [LW · GW], and Nuño Sempere wrote a post about using it here [LW · GW].
Note: the code for this has developed since my time on Guesstimate. With Guesstimate, I had one cofounder, Matthew McDermott. During the last two years, I've had a lot of help from a handful of programmers and enthusiasts. Many thanks to Sebastian Kosch and Nuño Sempere, who both contributed. I'll refer to this vague collective as "we" throughout this post.
Video Demo
A Quick Tour
The syntax is forked from Guesstimate and Foretold.
A simple normal distribution
normal(5,2)

You may notice that unlike Guesstimate, the distribution is nearly perfectly smooth. It's this way because it doesn't use sampling for (many) functions where it doesn't need to.
Lognormal shorthand
5 to 10

This results in a lognormal distribution with 5 to 10 being the 5th and 95th confidence intervals respectively.
You can also write lognormal distributions as: lognormal(1,2) or lognormal({mean: 3, stdev: 8}).
Mix distributions with the multimodal function
multimodal(normal(5,2), uniform(14,19), [.2, .8])
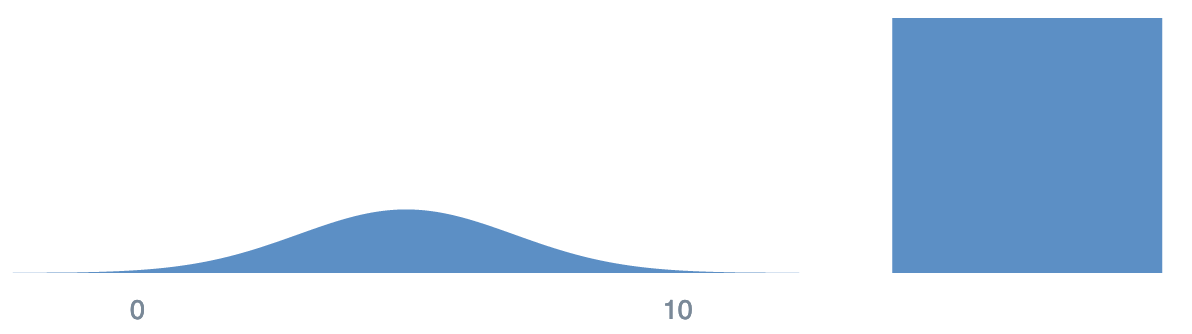
You can also use the shorthand mm(), and add an array at the end to represent the weights of each combined distribution.
Note: Right now, in the demo, I believe "multimodal" is broken, but you can use "mm".
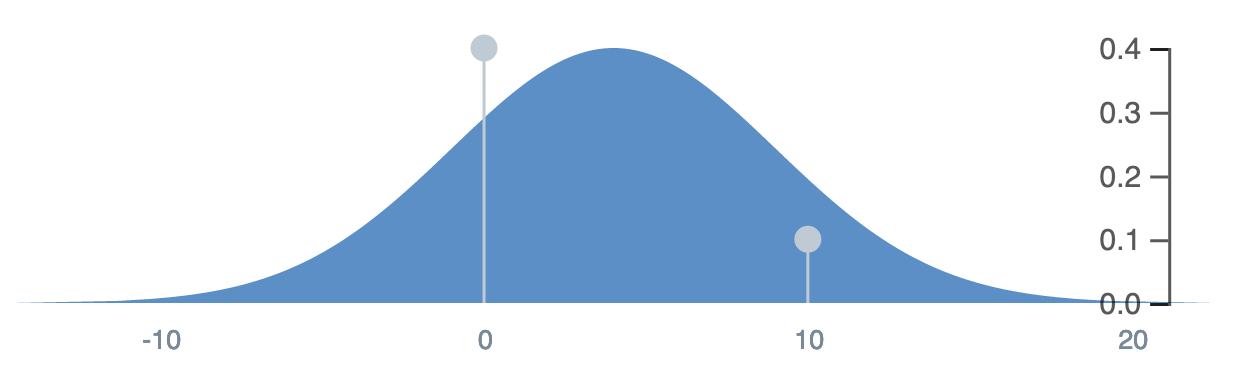
Mix distributions with discrete data
Note: This is particularly buggy.
multimodal(0, 10, normal(4,5), [.4,.1, .5])
Variables
expected_case = normal(5,2)
long_tail = 3 to 1000
multimodal(expected_case, long_tail, [.2,.8])Simple calculations
When calculations are done on two distributions, and there is no trivial symbolic solution the system will use Monte Carlo sampling for these select combinations. This assumes they are perfectly independent.
multimodal(normal(5,2) + uniform(10,3), (5 to 10) + 10) * 100

Pointwise calculations
We have an infix for what can be described as pointwise distribution calculations. Calculations are done along the y-axis instead of the x-axis, so to speak. "Pointwise" multiplication is equivalent to an independent Bayesian update. After each calculation, the distributions are renormalized.
normal(10,4) .* normal(14,3)

First-Class Functions
When a function is written, we can display a plot of that function for many values of a single variable. The below plots treat the single variable input on the x-axis, and show various percentiles going from the median outwards.
myFunction(t) = normal(t,10)
myFunction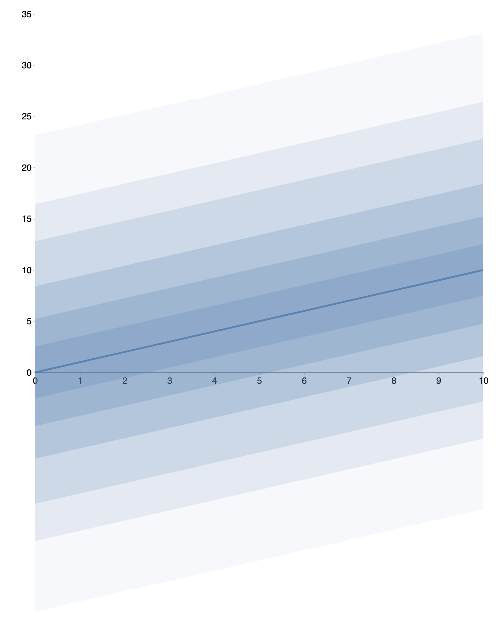
myFunction(t) = normal(t^3,t^3.1)
myFunction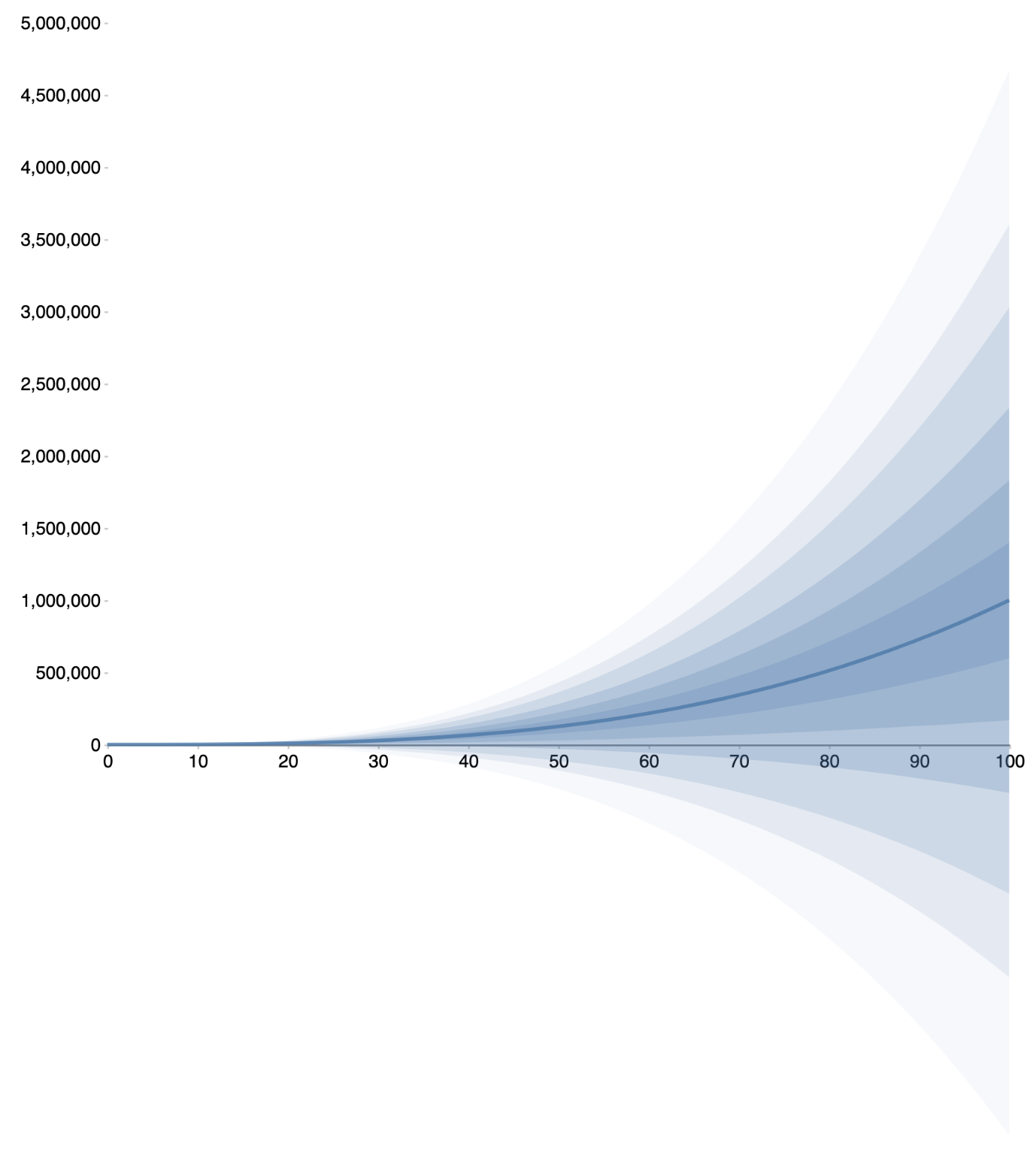
Reasons to Focus on Functions
Up until recently, Squiggle didn't have function support. Going forward this will be the primary feature.
Functions are useful for two distinct purposes. First, they allow composition of models. Second, they can be used directly to be submitted as predictions. For instance, in theory you could predict, "For any point in time T, and company N, from now until 2050, this function will predict the market cap of the company."
At this point I’m convinced of a few things:
- It’s possible to intuitively write distributions and functions that return distributions, with the right tooling.
- Functions that return distributions are highly preferable to specific distributions, if possible.
- It would also be great if existing forecasting models could be distilled into common formats.
- There's very little activity in this space now.
- There’s a high amount of value of information to further exploring the space.
- Writing a small DSL like this will be a fair bit of work, but can be feasible if the functionality is kept limited.
- Also, there are several other useful aspects about having a simple language equivalent for Guesstimate style models.
I think that this is a highly neglected area and I’m surprised it hasn’t been explored more. It’s possible that doing a good job is too challenging for a small team, but I think it’s worth investigating further.
What Squiggle is Meant For
The first main purpose of Squiggle is to help facilitate the creation of judgementally estimated distributions and functions.
Existing solutions assume the use of either data analysis and models, or judgemental estimation for points, but not judgemental estimation to intuit models. Squiggle is meant to allow people to estimate functions in situations where there is very little data available, and it's assumed all or most variables will be intuitively estimated.
A second possible use case is to embed the results of computational models. Functions in Squiggle are rather portable and composable. Squiggle (or better future tools) could help make the results of these models interoperable.
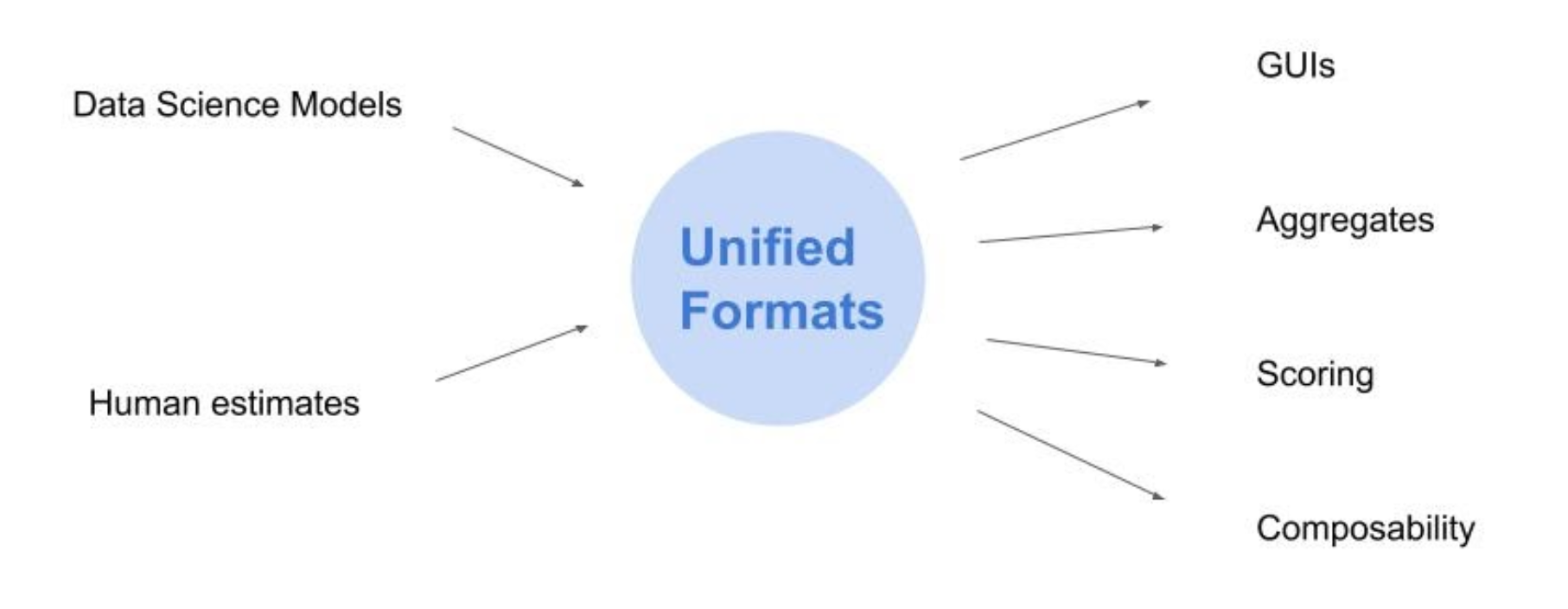
One thing that Squiggle is not meant for is heavy calculation. It’s not a probabilistic programming language, because it doesn’t specialize in inference. Squiggle is a high-level language and is not great for performance optimization. The idea is that if you need to do heavy computational modeling, you’d do so using separate tools, then convert the results to lookup tables or other simple functions that you could express in Squiggle.
One analogy is to think about the online estimation "calculators" and "model explorers". See the microCOVID Project calculator and the COVID-19 Predictions. In both of these, I assume there was some data analysis and processing stage done on the local machines of the analysts. The results were translated into some processed format (like a set of CSV files), and then custom code was written for a front end to analyze and display that data.
If they were to use a hypothetical front end unified format, this would mean converting their results into a Javascript function that could be called using a standardized interface. This standardization would make it easier for these calculators to be called by third party wigets and UIs, or for them to be downloaded and called from other workflows. The priority here is that the calculators could be run quickly and that the necessary code and data is minimized in size. Heavy calculation and analysis would still happen separately.
Future "Comprehensive" Uses
On the more comprehensive end, it would be interesting to figure out how individuals or collectives could make large clusters of these functions, where many functions call other functions, and continuous data is pulled in. The latter would probably require some server/database setup that ingests Squiggle files.
I think the comprehensive end is significantly more exciting than simpler use cases but also significantly more challenging. It's equivalent to going from Docker the core technology, to Docker hub, then making an attempt at Kubernetes. Here we barely have a prototype of the proverbial Docker, so there's a lot of work to do.
Why doesn't this exist already?
I will briefly pause here to flag that I believe the comprehensive end seems fairly obvious as a goal and I'm quite surprised it hasn't really been attempted yet, from what I can tell. I imagine such work could be useful to many important actors, conditional on them understanding how to use it.
My best guess is this is due to some mix between:
- It's too technical for many people to be comfortable with.
- There's a fair amount of work to be done, and it's difficult to monetize quickly.
- There's been an odd, long-standing cultural bias against clearly intuitive estimates.
- The work is substantially harder than I realize.
Related Tools
Guesstimate
I previously made Guesstimate and take a lot of inspiration from it. Squiggle will be a language that uses pure text, not a spreadsheet. Perhaps Squiggle could one day be made available within Guesstimate cells.
Ergo
Ought has a Python library called Ergo with a lot of tooling for judgemental forecasting. It's written in Python so works well with the Python ecosystem. My impression is that it's made much more to do calculations of specific distributions than to represent functions. Maybe Ergo results could eventually be embedded into Squiggle functions.
Elicit
Elicit is also made by Ought. It does a few things, I recommend just checking it out. Perhaps Squiggle could one day be an option in Elicit as a forecasting format.
Causal
Causal is a startup that makes it simple to represent distributions over time. It seems fairly optimized for clever businesses. I imagine it probably is going to be the most polished and easy to use tool in its targeted use cases for quite a while. Causal has an innovative UI with HTML blocks for the different distributions; it's not either a spreadsheet-like Guesstimate or a programming language, but something in between.
Spreadsheets
Spreadsheets are really good at organizing large tables of parameters for complex estimations. Regular text files aren't. I could imagine ways Squiggle could have native support for something like Markdown Tables that get converted into small editable spreadsheets when being edited. Another solution would be to allow the use of JSON or TOML in the language, and auto-translate that into easier tools like tables in editors that allow for them.[2]
Probabilistic Programming Languages
There are a bunch of powerful Probabilistic Programming Languages out there. These typically specialize in doing inference on specific data sets. Hopefully, they could be complementary to Squiggle in the long term. As said earlier, Probabilistic Programming Languages are great for computationally intense operations, and Squiggle is not.
Prediction Markets and Prediction Tournaments
Most of these tools have fairly simple inputs or forecasting types. If Squiggle becomes polished, I plan to encourage its use for these platforms. I would like to see Squiggle as an open-source, standardized language, but it will be a while (if ever) for it to be stable enough.
Declarative Programming Languages
Many declarative programming languages seem relevant. There are several logical or ontological languages, but my impression is that most assume certainty, which seems vastly suboptimal. I think that there's a lot of exploration for languages that allow users to basically state all of their beliefs probabilistically, including statements about the relationships between these beliefs. The purpose wouldn't be to find one specific variable (as often true with probabilistic programming languages), but to more to express one's beliefs to those interested, or do various kinds of resulting analyses.
Knowledge Graphs
Knowledge graphs seem like the best tool for describing semantic relationships in ways that anyone outside a small group could understand. I tried making my own small knowledge graph library called Ken, which we've been using a little in Foretold. If Squiggle winds up achieving the comprehensive vision mentioned, I imagine there will be a knowledge graph somewhere.
For example, someone could write a function that takes in a "standard location schema" and returns a calculation of the number of piano tuners at that location. Later when someone queries Wikipedia for a town, it will recognize that that town has data on Wikidata, which can be easily converted into the necessary schema.
Next Steps
Right now I'm the only active developer of Squiggle. My work is split between Squiggle, writing blog posts and content, and other administrative and organizational duties for QURI.
My first plan is to add some documentation, clean up the internals, and begin writing short programs for personal and group use. If things go well and we could find a good developer to hire, I would be excited to see what we could do after a year or two.
Ambitious versions of Squiggle would be a lot of work (as in, 50 to 5000+ engineer years work), so I want to take things one step at a time. I would hope that if progress is sufficiently exciting, it would be possible to either raise sufficient funding or encourage other startups and companies to attempt their own similar solutions.
Footnotes
[1] The main challenge comes from having a language that represents symbolic mathematics and programming statements. Both of these independently seem challenging, and I have yet to find a great way to combine them. If you read this and have suggestions for learning about making mathematical languages (like Wolfram), please do let me know.
[2] I have a distaste for JSON in cases that are primarily written and read by users. JSON was really optimized for simplicity for programming, not people. My guess is that it was a mistake to have so many modern configuration systems be in JSON instead of TOML or similar.
6 comments
Comments sorted by top scores.
comment by Steveot · 2020-11-24T22:04:23.411Z · LW(p) · GW(p)
The main thing that caught my attention was that random variables are often assumed to be independent. I am not sure if it is already included, but if one wants to allow for adding, multiplying, taking mixtures etc of random variables that are not independent, one way to do it is via copulas. For sampling based methods, working with copulas is a way of incorporating a moderate variety of possible dependence structures with little additional computational cost.
The basic idea is to take a given dependence structure of some tractable multivariate random variable (e.g., one where we can produce samples quickly, like a multivariate Gaussian) and transfer its dependence structure to the individual one-dimensional distributions one likes to add, multiply, etc.
Replies from: ozziegooen↑ comment by ozziegooen · 2020-11-25T19:36:44.961Z · LW(p) · GW(p)
Thanks for the suggestion.
My background is more in engineering than probability, so have been educating myself on probability and probability related software for this. I've looked into copulas a small amount but wasn't sure how tractable they would be. I'll investigate further.
comment by gjm · 2020-11-24T23:31:55.332Z · LW(p) · GW(p)
Very superficial remark: it seems to me like "multimodal" is a bad name for the thing you've called that. Not all mixtures are multimodal, and not all multimodal distributions arise as mixtures. Why not call it "mix" or "mixture" or something like that?
Replies from: ozziegooen↑ comment by ozziegooen · 2020-11-25T19:34:46.989Z · LW(p) · GW(p)
Thanks for the feedback!
It's a good point. This is a kind of thing I've been wrestling a lot, though of course is fairly surface level compared to the main architecture.
I don't have a personal preference on this. I agree that mixture is more technically correct term, but it seems like many (not very technical people) find "multimodal" more intuitive. To many people I think "mixture" sounds more generic, as from where they are standing, "mixture" could mean several things.
I'll keep the option in mind and ask for further preferences.