OpenAI Codex: First Impressions
post by specbug (rishit-vora) · 2021-08-13T16:52:33.874Z · LW · GW · 8 commentsThis is a link post for https://sixeleven.in/codex
Contents
OpenAI Codex The Challenge Illustration EXAMPLES Codex it! Implications Individual Problem Comparison None 8 comments
OpenAI organised a challenge to solve coding problems with the aid of an AI assistant. This is a review of the challenge, and first impressions on working with an AI pair-programmer.
OpenAI Codex
OpenAI is an AI research and development company. You might have heard some buzz about one of its products: GPT-3. GPT-3 is a language model that can generate human-like text. It can be used for chatting, text auto-completion, text summarisation, grammar correction, translation, etc.
Codex is a descendant of GPT-3, trained on natural language data and publicly available source-codes (e.g. from public GitHub repos). Codex translates a natural language prompt to code. It is the very model that powers GitHub Copilot — an AI pair-programmer (checkout the site for demos, it is fascinating).
OpenAI recently released an API to access Codex (in beta). The demos attached with the release were a cause for consternation. Codex is proficient in a dozen (programming) languages. It can be used for code generation, refactoring, autocompletion, transpilation (translating source-code b/w languages), code explanation, etc. To show off Codex, OpenAI recently organised a challenge.
The Challenge
The challenge was to solve a series of (five) programming puzzles in Python. The only twist — you can use Codex as a pair-programmer. It was a time-judged competition, with a temporal cap. Not surprisingly, Codex itself was a participant (not just as a helper)!
The problems were simple. ~830 "people" (Codex included) were able to solve all five of them. I had to solve the first two challenges manually (OpenAI server issues). "Had to" because it was a race against time (& top 500 win an OpenAI t-shirt). For the other three, however, I was able to call in the cavalry (it was pretty climactic).
The novel experience of watching an AI auto-generate code is amazing. Just type a docstring — describing the procedure — and watch the code develop. If you're an old-time programmer, you'll get the notion when you experience it.
Illustration
I've illustrated one problem statement where I used Codex to generate a solution.
PROBLEM
Parse the given Python source code and return the list of full-qualified paths for all imported symbols, sorted in ascending lexicographic order.CONSTRAINTS
The input will not contain any wildcard imports (from ... import *). Ignore aliases (renamings):from x import y as zshould be represented asx.y.LIBRARY SUGGESTION
Consider using the[ast]module.EXAMPLES
Input
import os import concurrent.futures from os import path as renamed_path from typing import ( List, Tuple )Output
['concurrent.futures', 'os', 'os.path', 'typing.List', 'typing.Tuple']
Codex it!
I just formulated the docstring. Using the doc, imported libs and function signature, it generated an (almost) functional code:
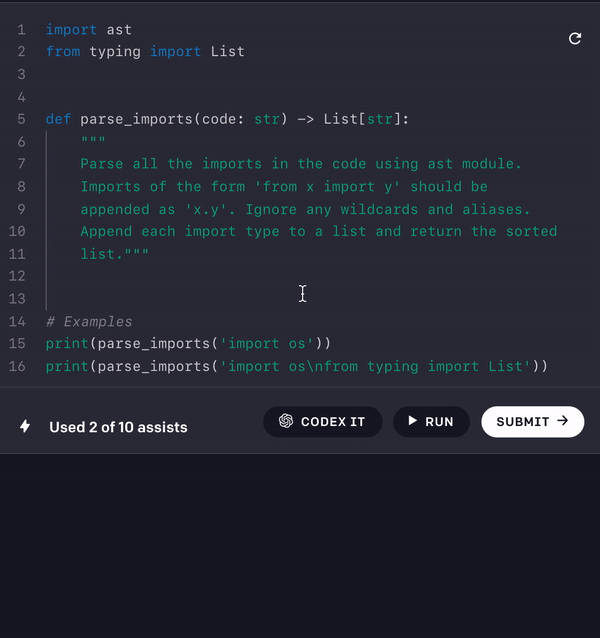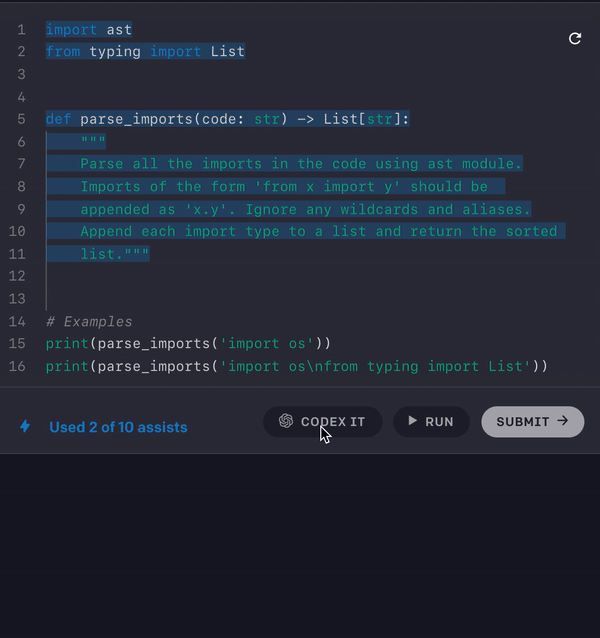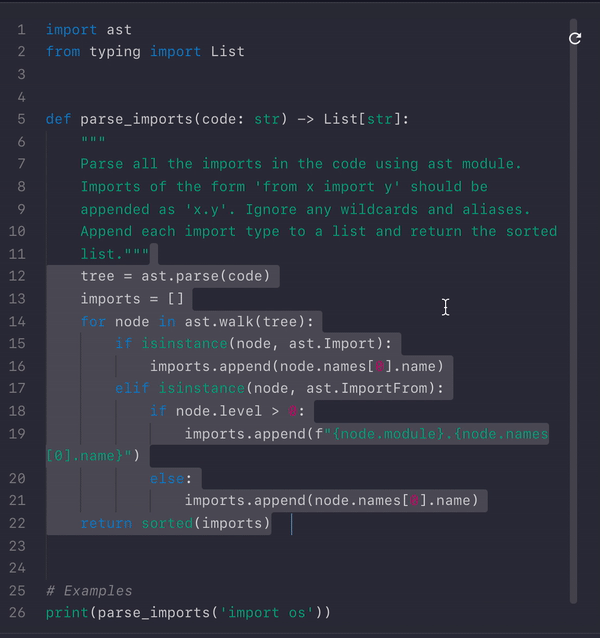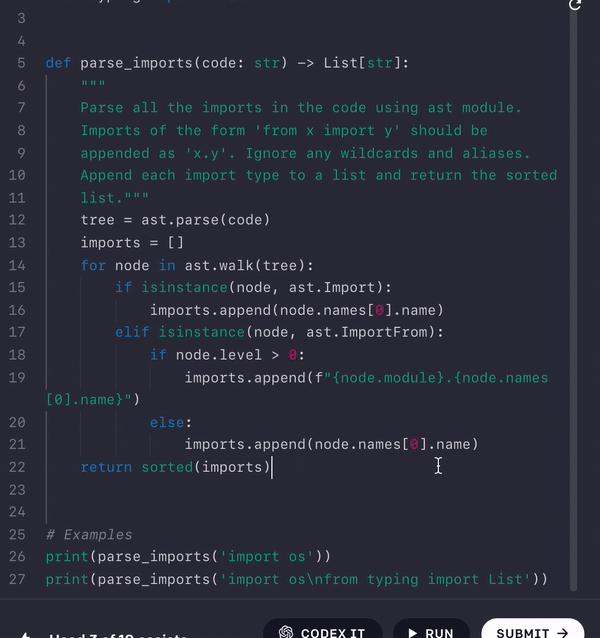
Pretty impressive. After just one or two manual bug sweeps, the code passed all the testcases! Final script:
import ast
from typing import List
def parse_imports(code: str) -> List[str]:
"""
Parse all the imports in the code using ast module.
Imports of the form 'from x import y' should be appended as 'x.y'.
Ignore any alias. Append each import type to a list
and return the sorted list.
"""
symbols = []
for node in ast.walk(ast.parse(code)):
if isinstance(node, ast.Import):
for name in node.names:
symbols.append(name.name)
elif isinstance(node, ast.ImportFrom):
for name in node.names:
symbols.append(node.module + '.' + name.name)
print(code, symbols)
return sorted(symbols)
# Examples
print(parse_imports('import os'))
print(parse_imports('import os\\nfrom typing import List'))
Implications
Although it could not beat all its human counterparts, it ranked an impressive #96 on the leaderboard. In all fairness, the competition paradigm was many-to-some — everyone faced the same five problems. So, Codex will have a rich data of differentiated prompts for the same set of problems. It might give the AI a learning edge (in the case of concurrent active learning). Still, for competing against top-notch programmers, top 100 is quite a feat. I mean, contrast the statistics below (Codex vs Avg. player):
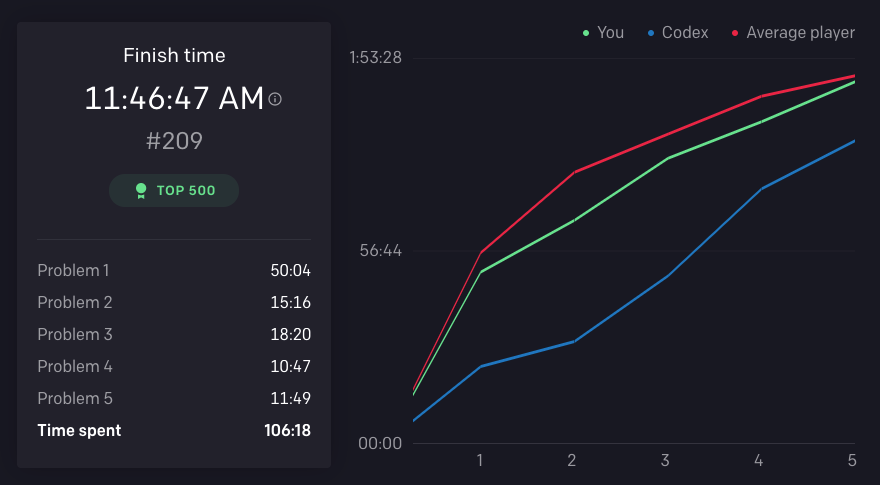
Does this mean I should start scouting career options? Can Codex just self-optimise and outcompete all programmers? I doubt it.
Okay, let us go first-principles. Codex trained on public code repos. Now the underlying framework of weights and biases is impossible to entertain. So let us take a spherical cow approach. The constituents of its dataset will probably form a logarithmic distribution. Majority of the train split comprised of overlapping, generic, non-complex solutions (like database CRUDs). Basis this (sensible) hypothesis, we can assert that 80% of its statistical prowess lies in solving small, low cognitive, well-defined, pure functions.
Building webpages, APIs, 3rd party integrations, database CRUDs, etc. — 80% of non-creative, repetitive tasks can probably be automated. Going by the Pareto principle, the rest 20% — non-generalisable, complex, abstract problems — that take up 80% of cognitive bandwidth, will survive. But this is good news. Codex will handle all the tedious tasks, while programmers focus on the most creative jobs.
Once a programmer knows what to build, the act of writing code can be thought of as (1) breaking a problem down into simpler problems, and (2) mapping those simple problems to existing code (libraries, APIs, or functions) that already exist. The latter activity is probably the least fun part of programming (and the highest barrier to entry), and it’s where OpenAI Codex excels most.
Individual Problem Comparison
Alluded to above, it outperformed me (singleton, for problems 1 & 2). Teamed up, however, I yielded a far greater performance metric. Complement, not replacement.
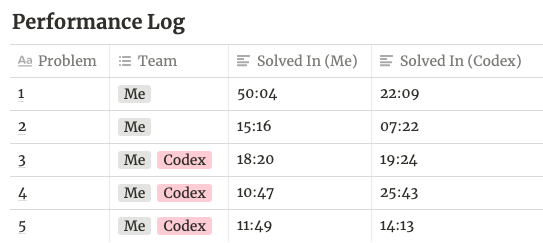
Software is eating the world. Apparently, at the expense of atoms. Yet, this asymmetrically entitled ecosystem is inaccessible to most. Programming demands a logical constitution. Tools like OpenAI Codex can loosen these constraints. Help dissolve the clique.
For programmers, these tools act as excellent appendages. Programming languages are, by definition, means of communication with computers. Consider Codex to be a level-n programming language (with intermediate transpilation). One step closer, in the overarching thread of symbiosis.
8 comments
Comments sorted by top scores.
comment by Neel Nanda (neel-nanda-1) · 2021-08-13T19:29:48.534Z · LW(p) · GW(p)
Still, for competing against top-notch programmers, top 100 is quite a feat. I mean, contrast the statistics below (Codex vs Avg. player):
I wouldn't read too much into this - the challenge was buggy and slow enough that I almost ragequit, and it took me about an hour to start submitting, I expect many people had similarly bad experiences
Replies from: rishit-vora, Orborde↑ comment by specbug (rishit-vora) · 2021-08-13T19:53:15.288Z · LW(p) · GW(p)
I wouldn't read too much into this - the challenge was buggy and slow enough that I almost ragequit, and it took me about an hour to start submitting, I expect many people had similarly bad experiences
I had the same experience (50 mins for first problem, as seen in the post). I agree, it is possible that the server issues biased the stats greatly.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-08-13T18:49:29.043Z · LW(p) · GW(p)
IIUC, the contest was only on time, not on correctness? Because correctness was verified by some pre-defined automatic tests? If so, how was Codex deployed solo? Did they just sample it many times on the same prompt until it produced something that passed the tests? Or something more sophisticated?
Also:
In all fairness, the competition paradigm was many-to-some — everyone faced the same five problems. So, Codex will have a rich data of differentiated prompts for the same set of problems. It might give the AI a learning edge (in the case of concurrent active learning).
This makes no sense to me. Do you assume solo-Codex exploited the prompts submitted by other competitors? Or that the assistant-Codexes communicated with each other somehow? I kinda doubt either of those happened.
Replies from: rishit-vora↑ comment by specbug (rishit-vora) · 2021-08-13T19:47:15.688Z · LW(p) · GW(p)
The only correctness filters are the hidden testcases (as is standard in most competitive coding competition). You can check the leaderboard - the positions correlate with the cumulative time taken to solve problems & codex assists. If there are any hidden metrics, I wouldn't know.
If so, how was Codex deployed solo? Did they just sample it many times on the same prompt until it produced something that passed the tests? Or something more sophisticated?
They didn't reveal this publicly. We can only guess here.
This makes no sense to me. Do you assume solo-Codex exploited the prompts submitted by other competitors? Or that the assistant-Codexes communicated with each other somehow? I kinda doubt either of those happened.
After I was done, I played around with Codex (from a new account). You could only use Codex in the editors within problems. In one of the problems, I cleared the editor and just put in a simple prompt (unrelated to the problem). I remember in one of the assists, it actually generated the code for that specific problem. This is why I assumed there is some state saving, or context awareness.
Replies from: tin482, vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-08-13T20:40:05.351Z · LW(p) · GW(p)
Hmm, I suppose they might be combining the problem statement and the prompt provided by the user into a single prompt somehow, and feeding that to the network? Either that or they're cheating :)
Replies from: Optimization Process↑ comment by Optimization Process · 2021-08-14T21:18:05.165Z · LW(p) · GW(p)
Yes, that's what they did! (Emphasis on the "somehow" -- details a mystery to me.) Some piece of intro text for the challenge explained that Codex would receive, as input, both the problem statement (which always included a handful of example inputs/output/explanation triplets), and the user's current code up to their cursor.