The Takeoff Speeds Model Predicts We May Be Entering Crunch Time
post by johncrox · 2025-02-21T02:26:31.768Z · LW · GW · 3 commentsThis is a link post for https://readtheoom.substack.com/p/the-takeoff-speeds-model-predicts
Contents
Part 1: Executive Summary Key Implications Part 2: Introduction Part 3: The Takeoff Speeds (TS) Model Part 4: Takeoff Speeds Model Changes Epoch Updates Percent Automation Changes Empirical data on AI R&D capabilities Updating the TS model Part 5: Using these updates as a baseline for a new TS calculation Methods for adapting the TS model Part 6: Automation Scenarios Part 7: Caveats Some uncertainties can be accounted for by varying the parameters of the TS model: Some issues could be addressed by adding new features to the TS model: And some issues aren’t easily addressed within the model’s framework: Part 8: Conclusion Some robust, urgent goals in crunch time might include: Appendix 1: Technical changes to the TS model Hardware updates Software updates Current AI R&D automation estimates Adjustments for scenario-modeling Scenario parameters: Appendix 2: Additional caveats None 3 comments
Thanks to Ashwin Acharya, David Schneider-Joseph, and Tom Davidson for extensive discussion and suggestions. Thanks to Aidan O’Gara, Alex Lintz, Ben Cottier, James Sanders, Jamie Bernardi, Rory Erlich, and Ryan Greenblatt for feedback.
Part 1: Executive Summary
There's growing sentiment [LW · GW] in the AI community that artificial general intelligence (AGI[1]) could arrive in the next few years, driven by the release of “reasoning models” like OpenAI’s o1 and DeepSeek’s R1, rising datacenter investments, and public statements from AI insiders. Is this largely hype leading people to panic[2], or is there good evidence to support accelerated timelines?
The most detailed formal model we have for analyzing the growth in AI’s impacts and capabilities—Tom Davidson's Takeoff Speeds (TS) model published in 2023—originally predicted AI systems capable of full economic automation[3] around 2040. This model remains our single best tool for analyzing timelines and takeoff dynamics, as it systematically incorporates multiple considerations and feedback loops in AI development.
When updated with recent evidence, the TS model now suggests full economic automation is likely to arrive by 2030. Two key changes drive this update:
- Faster scaling of AI inputs: Analysis from Epoch AI finds that AI has been scaling 5 times faster than the TS model previously estimated. This acceleration stems from both increasing compute investments and faster-than-expected improvements to algorithmic efficiency.
- Current AI R&D capabilities: Measures like METR's Research Engineering Benchmark (RE-Bench) and surveys of AI researchers suggests that current AI systems can already automate something like 1-10% of AI R&D tasks. This observation, combined with the TS model's framework for relating compute to capabilities, suggests that the compute requirements for AGI are lower than the model’s original estimates.
Key Implications
Under a range of different assumptions, the model predicts we may be entering “crunch time”: defined here as the period between societal wake-up, when AI systems become capable of automating a small but significant portion of economic tasks, and full automation of the economy[4]. While uncertainty remains high, individuals and organizations should consider allocating significant resources toward preparing for short timelines.
Crunch time is likely to last for multiple years, and lots of good policies could happen as society starts to “feel the AGI”. So the AI risk community shouldn’t necessarily aim to flip the table as a last-ditch effort. Instead, crunch time planning could include preparing for emergencies and emerging windows of opportunity. For example, have draft legislation ready for systems that meaningfully increase CBRN and other national security risks. Or plan how to structure government AI projects for if and when governments prepare to start them.
Anthropic has moved toward comms that emphasize “AGI will happen soon” instead of wide uncertainty over a range of possible timelines. The AI risk community might consider doing the same, as the risks and benefits of public awareness around AGI continue to shift[5].
It’s also good to maintain some flexibility for longer timelines scenarios. The quantitative and qualitative considerations in favor of short timelines may be wrong. But while one could debate specific aspects of the TS model, key drivers make it difficult to be confident in longer timelines:
- AI compute and algorithmic progress are growing extremely rapidly. Investments in AI are now expected to number in the hundreds of billions of dollars in 2025.
- We've seen that increasing compute resources consistently improves AI performance across many scales and architectures, at both experimental and practical tasks.
- Current AI systems demonstrate meaningful usefulness in key domains relevant to transformative or general AI, particularly in software development and AI R&D.
Part 2: Introduction
I use information on trends in AI development from Epoch AI, coupled with estimates of current AI systems’ ability to automate a small fraction of R&D tasks, to update the Takeoff Speeds (TS) model by Tom Davidson. I think this model is the single best tool we have for thinking about timelines and takeoff speeds, so bringing it up to date with existing information matters.
My main changes to the model are:
I use Epoch’s updated figures on algorithmic progress & training compute, which show much faster progress in AI inputs than the TS model expected: growth of ~12x per year in effective compute[6] compared to ~2.5x per year[7] in the original interactive model.
- AI systems can likely be used today to do useful work that would automate something like 1-10% of AI R&D tasks. Updating on this observation moves the model’s prediction of AGI training requirements from 1e36 to ~1e32 effective FLOP (eFLOP).
These two changes move the TS model to predict full economic automation around 2030 (central scenario 2027-8, aggressive 2026, conservative 2035, mean 2030) compared to the original model’s 2040 estimate.
I also show that while takeoff from today’s AIs to AGI will probably be slow, takeoff from AGI to ASI will probably be fast.
In the model, AI systems become capable of doing ~all economic tasks (20-100% automation) within a relatively modest range of effective compute relative to historical progress[8]. And this requires that AI systems become capable of 20% automation to start–a bar which today’s AI systems very likely do not meet.
- Crunch time lasts 2-3 years with the changes to the TS model above, or 4 years without them.
- But the takeoff to ASI occurs within 1-2 years, with more capabilities growth in the 2 years around full automation than the previous decade. Notably, most of this growth happens after AI systems are capable of full economic automation, and is thus best described as AGI->ASI takeoff.
Let’s jump in, shall we?
Part 3: The Takeoff Speeds (TS) Model
The Takeoff Speeds (TS) model uses an economic modeling framework[9] where human research and investments as well as AI automation can contribute to progress in hardware and software[10]. A novel, useful contribution of the model is that it tries to simulate the details of takeoff dynamics based on empirical data and informed estimates of the relevant variables.
The model maps three key determinants of AI progress:
Effective compute: the inputs to training AI–compute and algorithms. Measured in “effective Floating-Point OPerations,” or eFLOP, as algorithms effectively multiply the floating-point operations that AI hardware like GPUs perform to train a given AI system[11]. In 2024 it took about 10x less physical compute to train an AI with some level of capability than it did in 2022, because better algorithms were available.
The effective FLOP (eFLOP) gap: the difference in effective compute between AIs that have some substantial economic impacts, to AIs that can perform full-on automation of the world economy[12]. Once we have an AI that could automate 20% of tasks, we might need to add 1 OOM of eFLOP to get an AI system that could automate every task–or we might need 10. We can use the eFLOP gap to discuss how automation will grow as AI improves–for example, the eFLOP difference between AI systems capable of 1% to 10% automation, or 20% to 100%[13]. With those numbers, we can use estimates of present-day automation to predict how much more capable AIs would have to be to automate progressively more tasks.
Davidson combines seven considerations to get the size of the eFLOP gap, including how AI capabilities change with size in different domains, and how animal behavior changes with brain size. His central estimates are 2 OOM to go from 1% to 20% automation, then 4 more OOM from 20% to 100%[14].
Takeoff dynamics: “takeoff” refers to the period during which AI systems are crossing some performance region–I use it to refer to AI systems within the 20-100% eFLOP gap except where otherwise stated (“AGI->ASI takeoff”). Under current trends, the eFLOP gap would take about 4 years to cross, and AI developers might run into fundamental limits on scaling before many tasks can be automated[15]. On the other hand, once AIs are somewhat useful at automation, they could accelerate progress by bringing in funding or by contributing to AI R&D themselves. So it’s important to model the dynamics that might speed or slow AI progress as the gap is being crossed. This is one of the main additions the TS model makes to Ajeya Cotra’s Bio-Anchors report [LW · GW].
With the TS model, we see a few years in crunch time as lots of work becomes automatable, then a critical threshold near full automation where the pace of progress accelerates dramatically. The images below show the model’s central scenario with updated parameters. The two years around full automation see more growth in AI capabilities than the previous decade[16], about three-quarters of which happens in the year after full automation. This is takeoff from AGI to ASI.
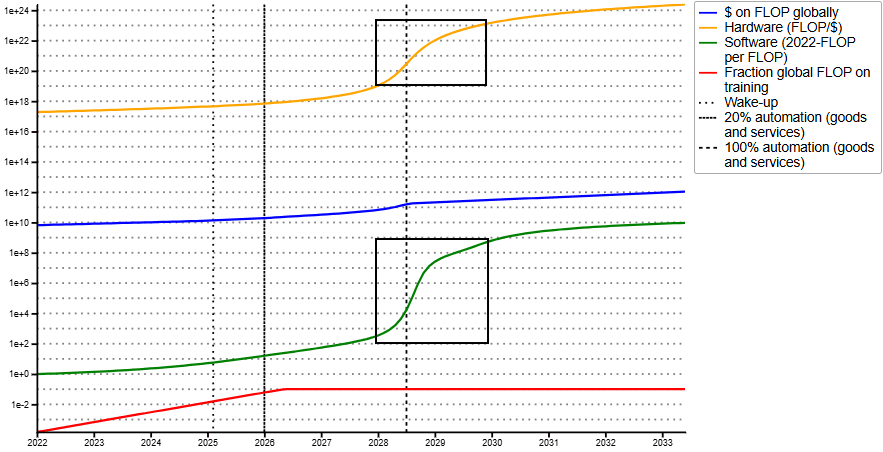
The TS model’s updated central scenario (black boxes added for emphasis). The green line is algorithmic efficiency; we see it jump ~6-7 OOM in the two years around full automation. The yellow line, hardware efficiency, increases by ~4 OOM.
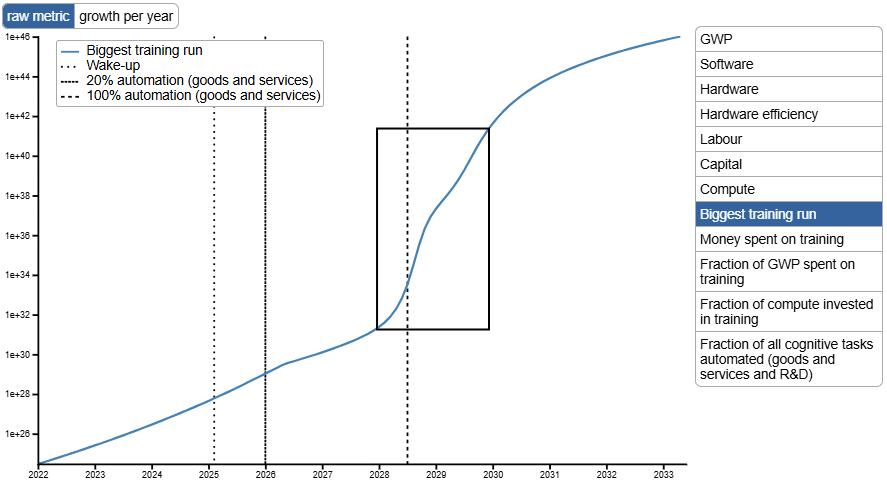
And here is the effect: eFLOP of the largest, most advanced models jumps ~10 OOM in 2028 and 2029.
Part 4: Takeoff Speeds Model Changes
I'll now explain the two updates I make to the TS model:
- Incorporating Epoch's updated data on compute scaling and algorithmic progress
- Updating estimates of current AI capabilities informed by proxies for R&D automation
These changes together shift the model's prediction for full economic automation from 2040 to approximately 2030.
Epoch Updates
Epoch AI has done plenty of work relevant to the Takeoff Speeds report–including making the interactive model at takeoffspeeds.com. Since the report’s release, Epoch published a trends dashboard investigating questions of how quickly AI systems are improving based on empirical analyses of quantities like money spent on hardware, algorithmic performance, and hardware efficiency over time. They find that AI systems are being trained on ~4-5x as many physical FLOP each year, and algorithms are getting about 3x as efficient–resulting in models having ~12x more eFLOP per year, compared to the TS model’s then-current estimate of 2.5x per year. This is a big change, and results in AI companies blowing through the OOM relative to Davidson’s original estimates.
It’s not trivial to update the TS model with Epoch’s new numbers, but I do my best to model them with conservative assumptions (see Appendix 1 for details). This moves the timeline for full economic automation from 2040 to late 2034, before including any changes based on observations about current AI R&D automation.
Percent Automation Changes
Hardware and software trends reveal the rate of progress in AI scaling. But to predict timelines to full automation, we need to establish their present position as well, by estimating current AI systems’ abilities to automate tasks. Before we go any further, take a second to guess how much R&D work today’s AI can automate. Is it more like 1%, or 10? 0.3%, or 30? I’ll cover different scenarios below.
Suppose you think today’s AI systems can automate 1% of R&D–they can do a small amount of useful work for AI researchers on their core tasks[17]. Because Davidson estimates roughly a 6-OOM eFLOP gap from 1% to 100% automation, we could then determine that AI systems would need about 5e32 eFLOP to be able to automate ~all R&D tasks[18].
For this post, I claim that using late 2024 systems like o1 or Claude 3.5 Sonnet, companies could automate around 1-10% of AI R&D tasks. This is hard to ground empirically, but I’ll point to suggestive evidence and talk about what it means to seriously consider it. From estimates in this range, we can use the TS model to predict how big AI systems would need to be to fully automate the economy. Fortunately, the final figures are somewhat robust to different estimates of the level of current R&D automation.
For more on the idea of measuring AI capabilities in terms of task automation, in particular how some fraction of tasks being automatable would translate to effects on AI R&D in the TS model, see here[19].
Empirical data on AI R&D capabilities
We can look at METR’s preliminary report on GPT-4o from July 2024 to see that 4o and Claude 3.5 Sonnet (old) are capable of performing tasks around the level of a “relatively high-quality” researcher working for 30 minutes on software engineering, cybersecurity, ML, research and reasoning tasks.
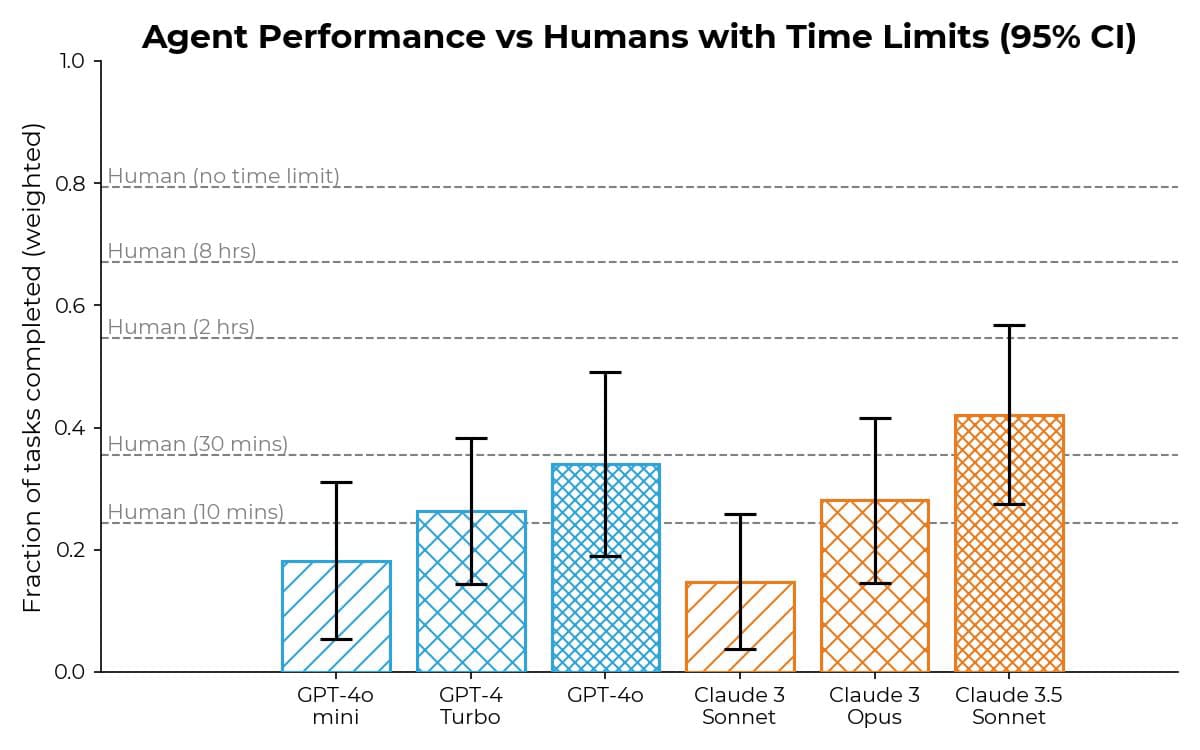
It’s notable that performance more than doubles from the release of Claude 3 Sonnet to Claude 3.5 Sonnet on this benchmark, which is designed to reflect autonomous capabilities in software domains. METR released a more comprehensive version, Research Engineering Benchmark v1 (RE-Bench) in November 2024, which found that the then-frontier models Claude 3.5 Sonnet (New) and o1-preview achieved scores equivalent to human researchers working for roughly 4 hours at a comparable time budget (and a ~10x lower cost budget).
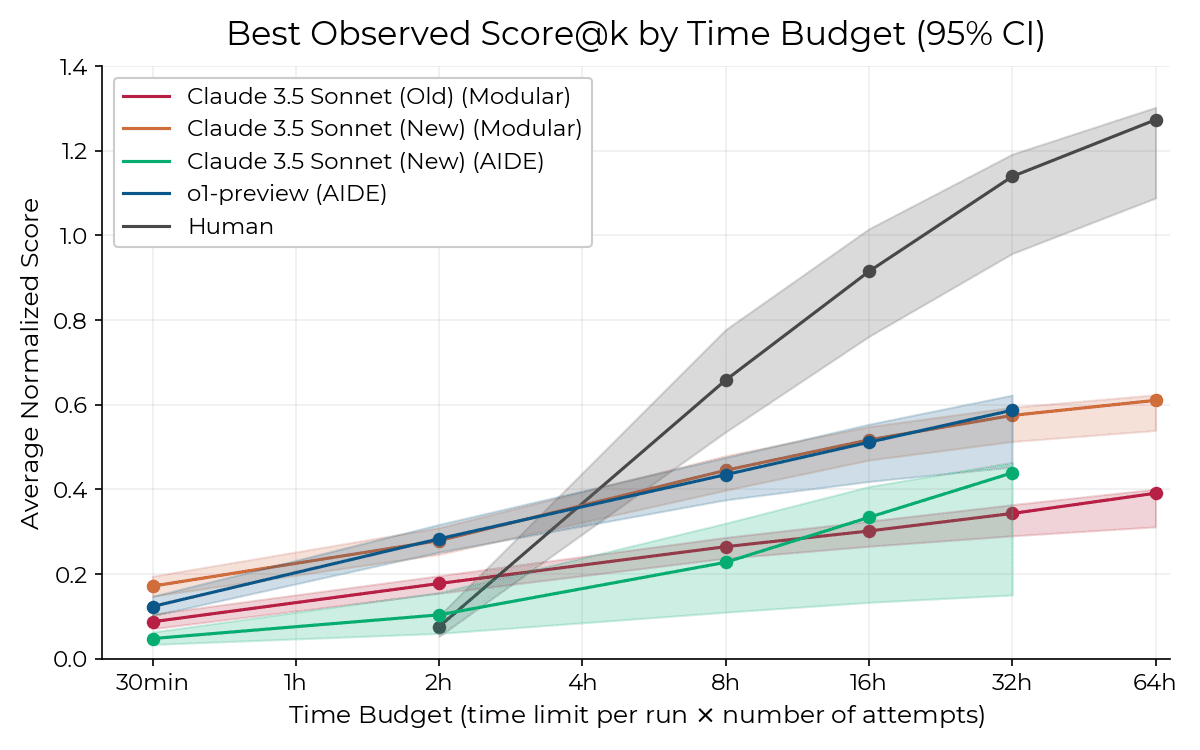
Results for METR’s RE-Bench - human scores vs. those of late-2024-era AI systems. At the moment, human performance scales much better with more time.
Epoch also released a report on AI R&D automation, based on interviews with AI researchers in industry, nonprofits, and academia. The participants disagreed about timelines for significant R&D automation, but agreed that R&D automation would mostly be driven by software engineering capabilities in the short term, rather than something like coming up with research hypotheses. So Epoch’s and METR’s findings paint a complementary picture of nontrivial AI R&D automation.
Updating the TS model
To update the TS model, I take 2.5% as a central estimate for the proportion of AI R&D tasks that 2024-era AI can automate, based on systems like o1 and 3.5 Sonnet (I explore other estimates in the next section). With the TS model’s eFLOP gap of 6 OOM to go from 1-100% automation, we can calculate how much compute an AI system that could automate 100% of economic tasks would be, taking the size of today’s AIs as a starting point. I estimate current systems at around ~1e27 eFLOP using public data on Llama-3.1 405B’s training, along with estimates for o1 and Claude 3.5 Sonnet (more details[20]), yielding ~2e32 eFLOP required for full automation, a difference of almost 4 OOM from the original TS model. This change leads the model to predict 100% automation in 2032 rather than the original 2040. Combining this with the Epoch updates, the model predicts full automation in late 2028[21].
Part 5: Using these updates as a baseline for a new TS calculation
Methods for adapting the TS model
I applied several edits to the TS model, described in the above sections, to reflect the empirical findings described in Parts 2 and 3. With these edits, the model gives the graph below.
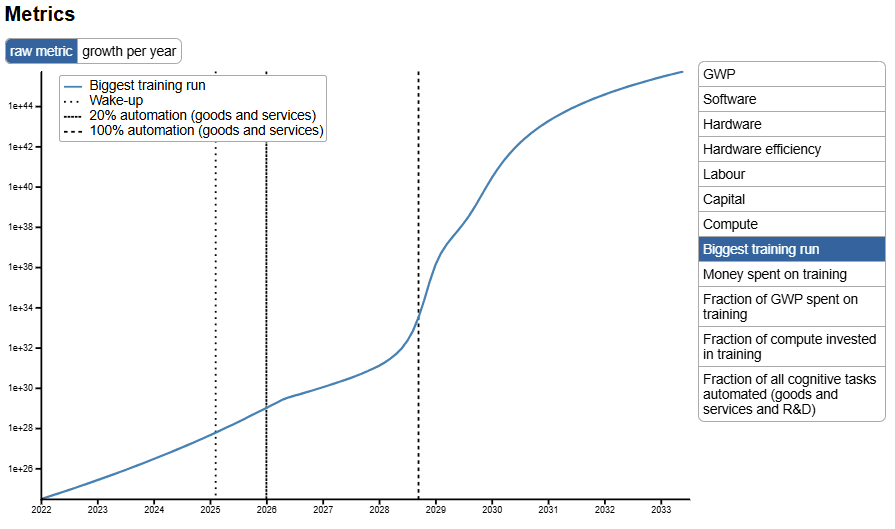
The TS model’s updated predictions given Epoch and current automation updates. It predicts that GPT-2025 is trained on ~10x the compute as GPT-4 with ~10x better algorithms and is capable of automating ~20% of R&D tasks. This jump in eFLOP and capabilities is an artifact from the shape of the eFLOP to automation curve, and in practice I expect a somewhat smoother ramp up of automated tasks (more details)[22].
The interactive model isn’t well-suited to taking precise measurements or making fine-grained adjustments, so for the scenarios below I use these sheets to get precise numbers. This means we lose the benefits of the TS model’s economic and AI R&D feedback loops–the compute and capabilities I describe in the scenarios thus ignore AI R&D assistance in the beginning of crunch time, though I manually include speedup due to AI systems when they become the key driver of algorithmic progress[23].
Adjusting estimated compute growth down due to financial constraints. Physical FLOP counts, with companies spending ~2.5x as much money per year and hardware getting ~35-60% more cost-effective, for ~4-5x total FLOP per year[24], can only keep growing at their current pace until around 2030. After that, frontier AI companies would have to spend hundreds of billions each to build the datacenters to train the next generation of AI systems, and add roughly the same amount to make them available for commercial inference use, approaching $1 trillion. Because this much spending is unlikely unless AI systems appear very close to AGI, I add a slowdown in compute growth to the model beginning in 2025[25]. To account for the possibility that growth in the pool of quality-adjusted AI researchers slows, I also slow algorithmic progress beginning in 2025, though at half the rate of the physical compute slowdown[26].
Part 6: Automation Scenarios
Now for the scenarios themselves. I’ll add a maybe-unnecessary disclaimer: these scenarios are highly speculative and should be taken as sketches of what AI systems and R&D automation could look like, rather than precise predictions. There are a lot of moving parts in the TS model, and I’ve done my best to update it in the most straightforward ways, but errors in the underlying model, my changes to its parameters, or future trend divergences could leave these scenarios far from reality.
I map 3 scenarios below: central, aggressive, and conservative (see here and here for some of the numbers behind each). For the aggressive scenario, I combine aggressive forecasts of trends in hardware scaling and algorithmic progress with aggressive estimates of current AI systems’ abilities to automate AI R&D–and do likewise for the conservative scenario. This gives stylized “very aggressive” and “very conservative” forecasts on either side of the central estimate which aim to capture a range of likely scenarios[27].
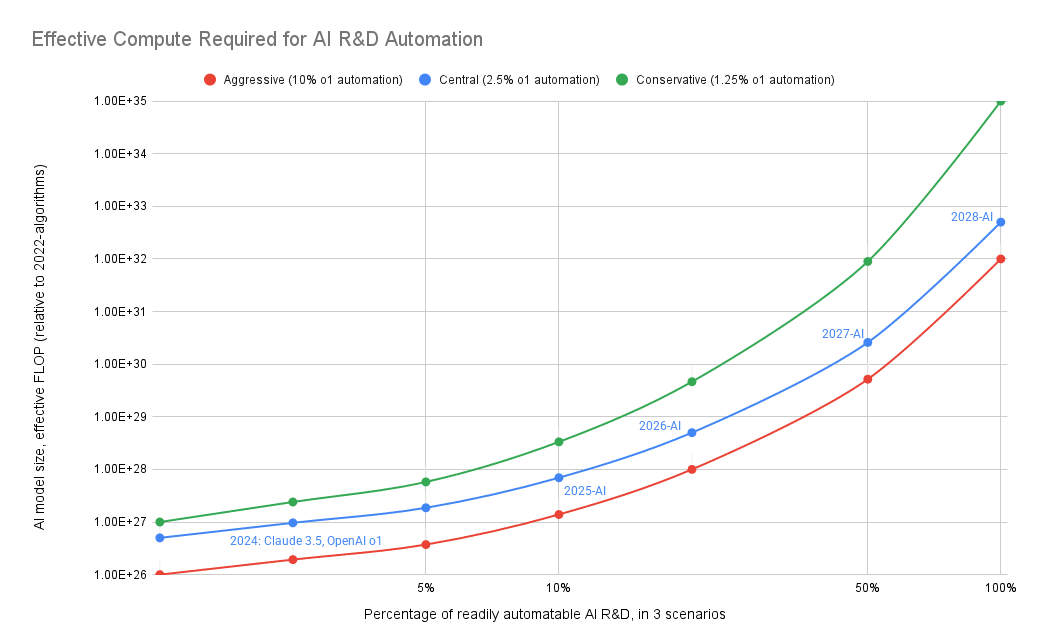
The figure above shows roughly how much effective compute it will take AI to automate some percentage of tasks–not how many eFLOP AI will be trained with over time[28]. In more conservative scenarios, AI needs more eFLOP to perform a given task.
Central scenario: 2024-era AI systems can readily automate ~2.5% of AI R&D tasks, while the eFLOP gap stays at 6 OOM for 1-100% automation. This decreases the eFLOP required for full automation[29] from the Takeoff Speeds model’s previous 1e36 to 2e32 eFLOP. Additionally, Epoch’s updated estimates for progress in hardware scaling and algorithms result in progress ~5 times faster than the TS model’s original numbers. I model key inputs and outputs for AI progress modestly slowing over the next ~8 years, relative to Epoch’s historical trendlines[30].
Here’s a sketch of what I might expect to see in this scenario:
By EOY 2025 (10%+ R&D automation capabilities): AI systems can automate (very roughly) 10% of AI R&D tasks with appropriate tooling and scaffolding[32]. By EOY, Anthropic probably hits their AI Safety Level 3, low-level autonomous capabilities or substantially increased risk of catastrophic misuse. They either announce they’ve done so or just don’t release the AI systems in question. Revenue for frontier AI companies goes up by 3-10x. Early agents start to work, and it becomes common in tech circles to e.g. have AI read, summarize, and draft responses to your emails. Or do your taxes, though people will check those drafts more carefully. RL keeps working, though it starts to slow after o3. o5 probably isn’t released by EOY 2025, but o4 is, and Anthropic, DeepMind, xAI, and Meta have promising “reasoning” competitors. Yet the best will be expensive, lack context, and feel brittle/dumb in recognizable ways, similar to how “count the Rs in strawberry” or variants on the doctor/son car crash puzzle befuddled 2024-AIs.
By EOY 2026 (20%+ R&D automation capabilities): This is the year most of society wakes up to AGI[33]. This means a surge of investment into semiconductors, energy, and frontier AI companies. It also likely means much-intensified public interest and concern with increased regulatory oversight. Though distinct work is required for different domains on the part of AI companies, AI systems with RL post-training will do complex STEM reasoning, useful, coherent web-based tasks, and long-form writing well. They will be trusted to research and write strong first drafts for a lot of important work, including academic research and financial modeling. Those drafts will then be refined via further conversation with the AIs. Many of the shortcomings of 2025’s reasoning models will have been mitigated. I’d expect mass layoffs directly attributed to AI in certain industries, though I don’t have a good sense of the magnitude, and public and regulatory backlash may greatly slow this in practice. Frontier AI companies may focus more efforts on work that seems likely to assuage public concern (safety efforts both real and performative) or at least help them avoid additional scrutiny. Consumer AI products will increasingly fall behind the capabilities frontier. AI companies increasingly prioritize internal development and enterprise contracts with more financial upside and less public exposure.
By EOY 2027 (50% R&D automation capabilities): Frontier AIs in 2027 are trained via datacenter(s) that cost ~$10 billion to build. This is well within companies’ budgets, considering Google spent $47 billion on R&D costs from June 2023-2024 and its R&D budget has increased by 10-15% per year. Training frontier AIs in 2027 would also use hundreds of megawatts to low gigawatts of energy, about 10% of a large US power plant’s annual production. This is totally feasible and falls short of the constraints that might limit further scaling, in terms of both energy use and financial cost[34]. There are significant constraints to using 10-100x more compute than this in training. This corresponds to the AI systems that would be released around 2030 without any major break from trends. I’d expect the AI systems trained in 2027 to be superhuman at ~every cognitive task we might do in less than a week. Humans will still hold advantages like: coherence over years-long projects, background context on organizational knowledge, and interpersonal relationship histories. But inside frontier AI companies, takeoff will be fully underway. The next-gen AIs, trained using their help around the end of 2027, have similar amounts of physical compute but significantly better algorithms[35]. As this transition accelerates, the state of public knowledge will depend on frontier AI companies’ incentives and willingness to share information, as well as the state of transparency regulations.
By EOY 2028 (full R&D and broader economic automation capabilities): Takeoff likely complete. This one feels hard to write about, partly because predictions about superintelligence are difficult, and party because regulations could slow or stop any of it. A bewildering array of algorithmic improvements will have been discovered over a period of a few months to years–AI systems get tens or hundreds of thousands of times more efficient during this time. Infrastructure investments will probably see their greatest rate of increase to date, though they’ll take time to be realized. Methods of continuous learning and training are likely discovered if they haven’t been already, allowing AI systems to improve themselves without repeating months of pre-training for each new generation. The field of robotics has solved all of its major problems, though manufactured robots are still in short supply. For many people, the most lucrative jobs available are acting as robot bodies for AIs, moving or assembling physical goods to construct the infrastructure for the next generation of robots and AI systems.
The following years are left as an exercise for the reader.
Aggressive scenario: for this scenario, 2024’s AI systems can automate 10% of R&D tasks, I decrease the 1-100% eFLOP gap from 6 to 4.5 OOM[36], and hardware+algorithmic progress maintain their current rates of growth with no slowdown. 2025-level AIs can be used to automate more than a third of R&D tasks[37]. The picture described in the central scenario above is generally accelerated by 1-2 years, including AI systems that fully automate all tasks by EOY 2026[38].
If we found ourselves in this scenario, I’d expect to see frontier AIs conclusively beating human researchers on, or saturating, ~all cognitive benchmarks released in 2024 or earlier by around EOY 2025, including METR’s RE-Bench and Epoch’s FrontierMath (Levels 1-3), followed shortly after by signs of AI making widespread cognitive contributions, like papers in math and computer science where AI systems did most of the research. I’d also expect a sharp increase in frontier AI companies’ revenue, like 10x or more from EOY 2024 to EOY 2025, as AI systems transition from chatbots and limited tools to highly capable agentic systems.
Conservative scenario: 2024-era AI systems can automate ~1% of R&D tasks, and I expand the 1-100% eFLOP gap from 6 to 8 OOM to model a longer tail of task difficulty. This raises the eFLOP required for full automation from 1e33 to 1e35[39]. I also include a serious slowdown in hardware scaling and algorithmic progress trends[40]. In this scenario, it takes AI companies until the early 2030s to make systems that can start to significantly speed up AI R&D. Building the datacenters to train 2035-era AIs costs roughly ~$15B. After this speeds up algorithmic progress, 2036-era AI is trained in the same datacenters and can automate ~all tasks.
This is a low level of spending–much lower than trendlines would suggest. It’s best viewed as an “AI winter” or “deep learning hits a wall” scenario. (Another conservative scenario would have more spending coupled with a larger eFLOP gap.) Hardware scaling only adds 3 OOM to AI training runs from GPT-4 until 2035. For comparison, GPT-2->3 and GPT-3->4 each added 2 OOM. This would correspond to hundreds of millions or low single-digit billions of dollars in annual hardware spending on AI training by each frontier AI company[41].
Part 7: Caveats
There are multiple ways the TS model (and by extension this update) might be mistaken.
Some uncertainties can be accounted for by varying the parameters of the TS model:
- FLOP gap uncertainty. It’s hard to be confident a priori about the size of the eFLOP gap. A smaller gap could lead to a hard takeoff, while a larger gap could imply a slower takeoff. (I’ve varied this gap in my scenarios.)
- The fraction of AI R&D tasks that are currently automatable is uncertain. I account for this by varying this parameter in the scenarios above.
- Algorithmic progress may speed up under an RL/self-play paradigm. OpenAI’s gains from o1 to o3 suggests that o1-style AI reasoning may yield faster algorithmic progress (see this [LW · GW] from Gwern, and this and this from OpenAI researchers on the pace of progress). If algorithmic progress has gone from ~3x annually to e.g. 10x, the world may look more like the aggressive scenario above.
- The rate of algorithmic efficiency improvements is hard to measure. Epoch looks at the efficiency of text and vision models over time in “Algorithmic Progress In Language Models”, finding that AI systems can be trained on 3x less physical compute each year and achieve the same performance. But they acknowledge a number of limitations, like a lack of data points, combining different evaluations, and an inability to isolate the effects of algorithmic improvements from improvements in the quality of training data.
Some issues could be addressed by adding new features to the TS model:
Including a time lag between development and deployment of AI. The model uses a 1-year lag for hardware to enter production after its initial design, but no lag for AI systems to be trained and deployed. This likely speeds up takeoff, as new algorithmic advances are immediately incorporated into new systems rather than firms being stuck with existing AI systems while the next generation is trained[42].
- Detailed modeling of automation of different tasks. The model flattens automation into two categories: R&D tasks (in AI hardware and software) and everything else. It assumes automation of each category can be modeled as a single quantity, which has a relatively smooth relationship with log(effective compute). I think this abstraction is defensible, but one might choose to reject it in favor of more granular frameworks.
Percent automation versus R&D speedup. The effects of AI on R&D might be better captured by more transparently modeling AI’s effects on R&D speedup, rather than the share of R&D tasks that can be automated[43].
And some issues aren’t easily addressed within the model’s framework:
Resource scaling bottlenecks. A number of potential resource bottlenecks could impact the model’s predictions. I’ll list the big ones in roughly the order they could meaningfully block further scaling: energy (~1e29 physical FLOP), financial cost[44], semiconductor production, and data scarcity (~1e30), and latency and communication bandwidth within datacenters (~1e31). For the most part, I expect these to bite after 2030, and included their effects in the relevant scenarios, so I don’t think they’ll cause significant divergence[45]. GPT-4 was trained using roughly 3e25 FLOP, so this leaves 4-6 OOM before serious constraints take hold.
- Political barriers to scaling. The last category of bottlenecks is political. These could be decisions to delay AI deployments or further development, for example due to safety or societal concerns. Political constraints are out of scope for the model and are a major reason progress may be slower than it predicts.
Part 8: Conclusion
I’ve made two main changes to the TS model. The first is straightforward and uncontroversial–updating Davidson’s estimates of effective compute scaling to Epoch’s newer stats, responsible for about half of the change in timelines. And the second, more debatable decision (though I believe it’s a good one) is to update on evidence of low levels of current R&D automation, in the 1-10% range, which significantly reduces the eFLOP requirements for AGI. The end result is a TS model which predicts AI capable of full economic automation around 2030, rather than 2040.
I’ll close with a qualitative summary of what to expect when we enter crunch time — the period between 20% and 100% automation of AI R&D. I follow the TS model in tying 20% R&D automation to industry “wake-up”; AI progress will be promising enough that a huge share of the world’s resources are spent developing advanced AI. Given my changes, the model predicts that this will happen between 2025 and 2028.
There will likely be multiple years between “wake-up” and full automation. In the central scenario, 2026 will see 30% cognitive automation by AI systems, with an astounding proliferation of AIs in daily life. They could be better at many technical tasks than the vast majority of people, and capable of doing most anything with a web connection. It would be easy to look around in that world and think superhuman systems are imminent. The model says–not quite yet. 2026 and 2027 still finish out with human researchers and investors contributing the bulk of relevant work in AI and outside it, and the overall pace of AI progress barely speeds up due to this substantial, but not decisive, assistance. It’s only in 2028, when AI systems are automating more than 80% of R&D, that we actually see the s-curves for algorithmic and hardware progress start to lift off. Once that starts, the TS model expects 1-2 years of extremely rapid progress, on the order of 5-10 times faster than anything we’ve seen to date.
There may be a policy and coordination window of 1-5 years during crunch time, when AI is clearly the Next Big Thing, bigger than anything else going on in the world, and yet there is still time to act.
Some robust, urgent goals in crunch time might include:
- Adapting AI tools for wise decision-making, especially in government
- Investing in technical AI risk reduction measures
- Applying high-level security to AI datacenters
- Increasing visibility into AI projects to make crunch time more comprehensible (e.g. running precise AI evaluations & reporting the results)
- Developing technical and governance measures to prevent power grabs within AI projects, public or private
- Exploring international coordination on AI where practical
Given the caveats with this model, I’m not sure how long this window will last. On the one hand, this means that once we enter crunch time, action is urgent. But high-risk actions might be premature, if they’re crafted as “Hail Marys” for short-crunch-time scenarios but would make things worse in worlds where crunch time is longer[46].
Appendix 1: Technical changes to the TS model
Hardware updates
For hardware spending, the interactive model has two main parameters: the growth rates in the fraction of world spending that goes toward semiconductors ("Growth rate fraction GWP compute"), and the rate of growth in the fraction of semiconductors that are used for training AI systems ("Growth rate fraction compute training"). I change only the latter. This is because the AI boom has not yet resulted in a meaningful scale-up of semiconductor production (though I expect it to in the future), so overall global spending on semiconductors should not grow faster than expected, especially pre-wake-up. Changing the post-wake-up growth rate of semiconductor spending from 19% to 40% per year makes takeoff happen ~4 months faster in the central scenario.
I also change the growth rate in inputs going to hardware R&D: capital, labor, and compute, to reflect Epoch's 35-60% growth in hardware efficiency per year, matching the post-wake-up growth rates in capital and labor. Compute grows much faster after wake-up in the TS model.
The full hardware changes are:
- "Growth rate fraction compute training": 0.5475 -> 1.5
- i.e. 2.5x training costs per year, limited to a growth in the fraction of chips going to training AI systems, rather than a global expansion of chip manufacturing capacity.
- "Wake-up growth rate fraction compute training AI models": 1.1 -> 1.5
- Same as above–this is probably conservative, but it barely has any effect on timelines.
- "Growth rate fraction [capital, labour, and compute] hardware R&D": 0.01 -> 0.14
- See paragraph above.
Software updates
For software progress, the interactive model has two parameters for inputs to progress—how quickly AI companies are adding researchers and compute to their R&D efforts, and one parameter for returns to software—essentially, how much faster research goes when these inputs increase.
I don't change software returns from the TS model's starting value of 1.25, following Epoch's research which supports values in that range. To square this with Epoch's finding of ~3x software progress per year, I increase the growth rate in inputs to 2.4x per year (shown as 1.4 in the model: 140% growth per year).
"Returns to software" at 1.25 means that 1 doubling of software inputs leads to 1.25 doublings of software performance, so 2.4^1.25 = ~3, for 3x software progress per year.
Changes made:
- "Growth rate fraction labour software R&D": increased to 1.4
- "Growth rate fraction compute software R&D": increased to 1.4
- Wake-up equivalents of both parameters: increased to 1.4
Current AI R&D automation estimates
Llama-3.1 405B comes to approximately 3e25 eFLOP using the rough formula for dense transformer models: FLOP = 6 * parameter count * training tokens (page 6 of Kaplan 2020, via Stephen McAleese here [LW · GW]). I then use Epoch's figure of ~3x algorithmic progress per year to get a final figure of ~5e26 eFLOP (relative to 2022 AI systems, for consistency with the TS model).
I do something similar but less grounded for Claude 3.5 Sonnet and o1, using API costs as a proxy for parameters. O1 comes out to ~1e27 and Claude 3.5 Sonnet to ~5e26 eFLOP.
With a central estimate of 2.5% for current R&D task automation, I calculate full automation requirements as ~2e32 eFLOP.
Change made: "AGI training requirements (FLOP with 2022 algorithms)": 1e36 -> 2e32
Adjustments for scenario-modeling
For each of the scenarios, I calculate increases in compute spending and algorithmic progress here instead of using the TS model to read out the size of frontier AI systems, in order to get a better year-to-year picture and make more targeted adjustments. This means I don’t see the same increases in algorithmic and hardware progress that the TS model’s semi-endogenous growth model produces. But this is fine for the purposes of forecasting AI eFLOP in a given year, since AI systems don’t contribute much to R&D progress until ~1 year before AGI. I declare full automation in that year, and am saved from having to model AGI’s precise effects on eFLOP by referring to the TS model’s findings in my mainline update scenario file. I do slightly underestimate algorithmic progress in the years leading up to AGI as a result, but I think this is a reasonable tradeoff.
Scenario parameters:
Central scenario:
- Current AI R&D automation: 2.5%
- 1-100% eFLOP gap: 6 OOM (unchanged)
- Hardware efficiency: 35% improvement per year
- Compute growth: slows from 4x to 2.5x/year by 2029
- Algorithmic progress: maintains ~3x/year through mid-term
Aggressive scenario:
- Current AI R&D automation: 2.5% -> 10%
- 1-100% eFLOP gap: 6 OOM -> 4.5 OOM
- Hardware+algorithmic progress: maintain current growth rates without slowdown
Conservative scenario:
- Current AI R&D automation: 2.5% -> 1%
- 1-100% eFLOP gap: 6 OOM -> 8 OOM (raises eFLOP required from 1e33 to 1e35)
- Hardware scaling: slows from 4x to 1.5x/year in early 2030s
- Algorithmic progress: decreases from 3x/year to 1.5x/year for the full time period
Appendix 2: Additional caveats
The TS model doesn’t distinguish between AI that can readily automate tasks, and AI that is actually automating tasks (see here in the report, “There might be delays between developing advanced AI and deploying it”). This means that real-world delays in AI adoption, when it makes perhaps some but not overwhelming economic sense to use AI, could lead to slower takeoff in the real world than the model, and might result in some of its feedback loops slowing or breaking. E.g. if AI systems take one or a few years to be adopted in R&D tasks, the loop from AI automating R&D and improving next-gen AIs will be slower than in the TS model. Davidson believes AI adoption will be relatively fast in R&D, which is more important for takeoff modeling than economic tasks more broadly.
Percent automation. The model implicitly assumes that AI task automation can be modeled as a single quantity, with a relatively smooth relationship between effective compute and automation–instead of a ‘lumpy’ relationship with many unpredictable or discontinuous jumps as AI compute grows. I think this abstraction is defensible, but one might choose to reject it in favor of more granular task-based or other automation frameworks. There will be some degree of lumpiness to task automation, but we should be able to sample different points on the curve to get a general idea, and I don’t think there are good reasons to expect a particular type of lumpiness. Depending on the number of jumps or lulls in the run-up to full automation, the TS model can be viewed as approximating automation over eFLOP with one smooth curve–with a greater or lesser degree of precision. That is to say, there’s no reason to add particular breakthroughs or plateaus to the model in advance[47]. For more on discontinuities, see Section 6 in Part 2 of the TS report[48].
Additionally, the true fraction of present-day task automation is highly uncertain. This value could be outside the range of estimates above - for example, 0.25%, or 15%, of R&D tasks being automatable with 2024-era AI would substantially shift the model’s predictions.
Continuous takeoff. The TS model could also be flawed in envisioning a continuous, “slow takeoff” world. A discontinuous “fast takeoff” could look like near-zero (or some low level of) economic impact from AI for a while, followed by a jump to superhuman capabilities taking months, weeks, or days. This can be captured by the model as a very small eFLOP gap, like 1 OOM from 1% to 100% automation. The eFLOP gap could also be much larger than expected, like 12 OOM instead of 6 from 1% to 100% automation. This would result in slower timelines and takeoff speeds.
Algorithmic efficiency. This is much harder to measure than physical FLOP counts. Broadly speaking, algorithmic efficiency is an abstraction over different improvements across many domains, and might differ between them. Or it might not behave like a multiplier on compute at all–this could look like algorithmic gains failing to translate to subsequent model generations[49], or the stock of quality-adjusted AI researchers having increased more than expected. Or effective compute could look more like Compute^Algorithms rather than Compute*Algorithms, or some other relationship between algorithms, data, and compute.
New techniques. I don’t address the effects of o1-style inference scaling and reinforcement learning on synthetic data in depth. But I expect the techniques it uses to become increasingly relevant. OpenAI’s gains from o1 to o3 suggests this new paradigm may yield significantly faster algorithmic progress than we’ve seen in the past few years (see this [LW · GW] from Gwern, and this and this from OpenAI researchers on the pace of progress). If algorithmic progress has gone from ~3x annually to e.g. 10x, or higher, the world may look most like the aggressive scenario above. But it’s still unclear how far these techniques will take LLMs, and how generally their capabilities will improve.
- ^
I use AGI here synonymously with “AI systems capable of readily automating all cognitive tasks”, in accord with the TS model.
- ^
Much like Paul Samuelson’s quote that the stock market has predicted nine of the last five recessions, Bay Area rationalists have predicted short timelines before, looking at systems like AlphaGo.
- ^
The TS model defines an AI system being able to automate some task as: “i) it would be profitable for organizations to do the engineering and workflow adjustments necessary for AI to perform the task in practice, and ii) they could make these adjustments within 1 year if they made this one of their priorities.” So this doesn’t mean that an AI could do the task without using any tools, or on the other hand, that it could only do the task with complex tooling that’s not worthwhile to build in practice. The model weights tasks by their economic value in 2020, as measured by the money people would have earned from performing those tasks–rather than something like time spent. Thus “full economic automation” really means that AI systems can perform any of the tasks people were doing in 2020, at competitive rates and with 1 year or less to build the needed tooling. As above, “AGI” is an AI system that can automate all cognitive tasks.
- ^
I use “crunch time” because it overlaps reasonably well with others’ use (e.g. here [LW · GW]) and the TS model doesn’t have a label for the period in question. “Wake-up” is defined in the model as the point when “many key actors will ‘wake up’ to the potential for advanced AI to generate $10s of trillions per year…once this occurs, I expect investments to scale up as quickly as possible until they are worth trillions per year”.
- ^
For example: the AI risk community has previously discussed the drawbacks of raising public awareness around AGI, like drawing industry focus to AGI efforts. Given the current state of the AI industry, AI risk communications are unlikely to significantly speed up industry developments. Concerns about preventing industry focus should take a back seat to enabling informed societal preparation and response (though there are other valid reasons to avoid focusing on public awareness efforts).
- ^
Effective compute is measured in effective FLOP (eFLOP), discussed in Part 1.
- ^
Parameters in the original TS model: for physical FLOP, 19% growth rate in GWP fraction compute, 54.75% growth in fraction of compute used for training, 3% GWP growth. For software, 18% growth (plus population growth) and 1.25x returns. The TS model has the quantity of the biggest increase - fraction of compute used for training - capped at 10% max, so physical FLOP only grow at ~25% per year after ~2029 with the original settings (hardware efficiency does grow as well, but very slowly).
- ^
The window from ~20% automation to 100% automation (“Mid rampup” in the interactive model) is ~4-5 OOM of eFLOP with/without my updates, or ~2 OOM of physical FLOP and ~2 of algorithmic progress. With updates this begins in 2026, and without in 2036.
- ^
The TS model uses a semi-endogenous growth model where quantities like effective compute depend partly on AI automation at a given point in time, and partly on hand-specified numbers like pre- and post-wake-up growth rates in investments in AI and semiconductors.
- ^
See “Quantifying takeoff speed” in the report.
- ^
The TS model takes 2022 as the base year from which to measure algorithmic advances–in this post, I mimic it and use “effective FLOP relative to models using 2022-level algorithms” as the full definition. We could further separate “algorithms” into algorithms and data, and spend more time talking about when AI companies might run out of data, but this isn’t particularly relevant for our purposes. I discuss data as a potential bottleneck to scaling in Part 6.
- ^
In the model, purely cognitive tasks like AI research are easier to automate than broader economic activity, as discovering more efficient algorithms doesn’t require AIs to control robots or deal with physical bottlenecks (although there would still be non-physical constraints, like the time required to train new AI models). Whereas large numbers of robots would be needed to automate building datacenters or semiconductor fabs, or doing many jobs in the existing economy. This means that 100% R&D automation happens slightly before full economic automation in the model. In practice, fully automating R&D results in a 6-7 OOM jump in eFLOP within one year, which is more than enough to produce AIs capable of full economic automation. Though there may still be a lag between human-level AI and the production of enough hardware to automate all physical tasks.
- ^
In the TS model, Davidson tunes the relationship between effective compute and automation so that AIs move through early levels of automation quickly, and later, higher levels more slowly–it’s easier to go from 1-10% automation than 50-60%. He does this partly to give the TS model more flexibility on the size of the eFLOP gap, and says here he expects the actual relationship to be different. I’m mostly unconvinced by this, and think our prior should be a smoother relationship between % of tasks automated and log eFLOP. Making this change has a small practical impact, so I use the original TS model’s curve shape to allow for easy comparison - this is just to note that I place more weight on a scaling law picture.
- ^
I make one change to how the eFLOP gap is measured. In the original TS model, automation goes from 0% to 100%. Here I start at 1.25% automation–1.25% is a convenient number because its doublings go to 2.5%, 5%, 10%, 20%, and so on. And it’s cleaner to have a continuous curve of increasing automation rather than jumping from 0% to some nonzero number.
- ^
There are also fields like drug development that might require more calendar time to assess risks or effectiveness than AI R&D (without sufficiently high-fidelity simulations to run trials on). And many sectors could have significant regulatory constraints, including new regulations put in place in response to public opposition to societal effects from AI.
- ^
The two years around full automation span ~10 OOM of eFLOP growth for frontier AI systems (compared to 5 OOM between 2022, when the model begins, and 2028, when ~85% of AI R&D becomes automated).
- ^
Remember, we’re weighting tasks by their economic value–so this would imply AI researchers might be willing to pay something like $500 per month to use AI tools for help with core tasks (~0.1% of ~$500K compensation per month). This passes a sanity check (my guess is it’s likely an underestimate of willingness to pay).
- ^
And we can interpolate between different eFLOP requirements for full automation from starting points other than 1%.
- ^
Davidson weights task automation by the economic value of tasks in 2020. If AI systems could perform 5% of 2020-era tasks cheaply, they might do those tasks much more than human researchers would have, as long as the marginal returns to more such tasks exceeded marginal inference costs. This would likely accelerate research progress by more than 5%, although researchers would still be performing 95% of 2020-era tasks. The TS model’s definition of automation mostly precludes erring in the opposite direction–AIs that could theoretically automate tasks not doing so in practice–by stipulating that it must be economically worthwhile to build and use the AIs for the tasks they can readily automate. See here and the linked paper for an exploration of automation->output curves.
- ^
Llama-3.1 405B comes to approximately 3e25 eFLOP using the formula for dense transformer models: FLOP = 6 * parameter count * training tokens (page 6 of Kaplan 2020, via Stephen McAleese here [LW · GW]). I then use Epoch’s figure of ~3x algorithmic progress per year to get a final figure of ~5e26 eFLOP (relative to 2022 AI systems, for consistency with the TS model). I do something similar but less grounded for Claude 3.5 Sonnet and o1, using API costs as a proxy for parameters. O1 comes out to ~1e27 and Claude 3.5 Sonnet to ~5e26 eFLOP. See link for my reference sheet of AI models and figures.
- ^
TS model change: “AGI training requirements (FLOP with 2022 algorithms)”: 1e36-> 2e32. The TS model scenario files can be found here.
- ^
Davidson expects it to be easier to move through lower levels of automation, e.g. the progress from 1-5% automation would be faster than from 20-40%; in this spreadsheet I examine that assumption, but find it has minor effects on the model’s timeline to full automation. Davidson shapes the curve like this partly to give the TS model flexibility on the size of the eFLOP gap. He says here (page 82) that he expects the actual shape of the automation curve to be somewhat different. But again, this has a small impact.
- ^
I’m able to move from the TS model’s semi-endogenous simulation to these hardcoded rates because there’s only a short period (the year before AGI) when AI systems are contributing substantially to algorithmic progress. AI systems’ eFLOP are increasing mostly due to hardware scaling, not algorithmic progress, so this slowdown in algorithmic progress has only a minor effect on timelines.
I also model the fraction of R&D tasks AI can perform in my three scenarios, not all economic tasks. R&D automation precedes that of non-R&D tasks by ~1-2 years in the TS model, and I expect this effect to partly cancel out the omission of early R&D speedup. I also set hardware efficiency gains on the low end of Epoch estimates for the same reason (see next footnote).
- ^
Epoch has 35% better hardware efficiency per year on their website, but this is sensitive to precise measurement years (via correspondence with Ben Cottier at Epoch), and doesn’t match their headline figures of 2.6x spending and 4.6x physical FLOP growth per year. I use 35% per year rather than higher estimates like 60%.
- ^
Specifically, I project compute growth will slow from its present estimated 4x per year to 3.25x between GPT-4 and 2025-generation AI systems, 3x in 2027, 2.75x in 2028, and 2.5x in 2030. This is hacky but maps reasonably well to announced datacenter plans like Microsoft and OpenAI’s Stargate.
- ^
Partly this is because there are decent theoretical reasons to think spending on algorithmic progress and on physical FLOP will increase roughly proportionally over time (under a Cobb-Douglas economic production function), so algorithms shouldn’t be well under 2.5x per year compute spending growth now. And Epoch has separately estimated the returns to software R&D spending at over 1 here, so 3x does seem plausible. And the effects from these changes are fairly minor, so I don’t think it’s worth spending too much time exploring different scenarios–large differences only come from ~fully discounting Epoch’s estimates and assuming something closer to Davidson’s original 30% per year algorithmic progress estimates.
- ^
These scenarios don’t focus on how significant AI risks or regulations might impact AI capabilities; they are mostly capabilities forecasts.
- ^
For the year labels, I round to give years corresponding to each data point–some points are early or late in their years compared to others.
- ^
Note that while this includes R&D tasks, it’s broader than that. In this period, AI also becomes capable of automating all economic tasks (though it would take scaling robotics manufacturing for such capabilities to become real-world impacts). This is takeoff in action: the eFLOP of the leading models shoots well past what’s required for full automation in less than a year thanks to the speedup in AI R&D. But without this speedup from earlier AI systems, 2029-level AI would be trained in ~$50 billion datacenters with ~5e31 eFLOP, which is also sufficient for ~full economic automation. So the central scenario doesn’t rely on the takeoff feedback loop to reach AGI by 2030, though takeoff does push it forward by 1-2 years.
- ^
Hardware scaling slows from ~4x per year through GPT-4 to ~2.5x in the early 2030s. Algorithmic progress goes from ~3x to ~2.25x/year in the same period. This is to address the cost and energy constraints mentioned below in this scenario.
- ^
These scenarios don’t focus on how significant AI risks or regulations might impact AI capabilities; they are mostly capabilities forecasts.
- ^
On 10% automation in 2025: as mentioned in footnote 12 (“In the TS model, Davidson tunes the relationship…”), I expect that 10% R&D automation for 2025 is something of an overestimate, while automation for 2027 and 2028 is something of an underestimate. But this is probably a small effect relative to overall model uncertainty.
- ^
The TS model’s definition of wake-up: 6% of all economic tasks are automatable (and 20% of AI R&D tasks). Stylized in this scenario as societal wake-up rather than a narrow description of massively increasing investments in AI, which is more how Davidson talks about wake-up in the TS report. Note that although AI companies have rapidly increased investments in AI, the report’s conception of wake-up is more like trillions of dollars of investment across ~all levels of the AI supply chain, rather than the hundreds of billions announced as of early 2025 concentrated in AI chip spending by frontier companies.
- ^
Energy could constrain single-datacenter training runs sooner than cost, but is easier to mitigate via distributed training, and there’s some evidence this is already happening. Additionally, each 10x scale-up in eFLOP only increases training costs by 2-3x, as algorithmic progress contributes to model capabilities and hardware gets ~35-60% more cost-effective per year.
- ^
Anywhere from ~$2B if they reuse the same datacenter(s) as those used in 2027, to ~$50B if the AI companies make a big effort to give the new, more efficient AI training techniques maximum compute.
- ^
In the TS interactive model, shrinking the eFLOP gap would lengthen timelines because AI systems would be able to automate fewer tasks at lower levels of eFLOP, all else equal. But here I shrink it to bring the eFLOP required for full automation down without positing an implausibly high level of current automation. And remember, I’m not using the interactive model for these scenarios–there’s no effect from less AI R&D automation at low levels because I’m not including any effects from AI R&D automation before the ~1-year sprint to 100% automation.
- ^
- ^
Essentially, this is because there aren’t many years between the beginning of 2025 and the central scenario’s estimate of full automation in 2027-8, so there’s a limit to how much earlier we can forecast AGI without already being ruled out by reality.
- ^
Without setting the amount of current AI R&D automation at some low level like 0.1%, which I find implausible. The TS model makes it hard to talk about an AI system that automates a very small fraction of tasks like .01%. It also estimates that AI systems only require 4x the eFLOP to go from 0 to 5% automation, so you can’t have a large eFLOP gap between low levels of automation without increasing the total eFLOP gap many times more.
- ^
Hardware scaling goes from 4x per year now to 1.5x/year in the early 2030s, and algorithmic progress is decreased from Epoch’s 3x/year estimate to 1.5x/year for the full time period. The latter is to address critiques of Epoch’s approach to measuring software progress, which claim Epoch overestimates algorithmic progress by confusing improvements to how efficiently existing models run with increasing the performance of new, larger models. For more, see Section 3.2 of Epoch’s paper on how they estimated algorithmic progress.
- ^
Compute and datacenter costs are based on this from Epoch on Gemini Ultra’s costs and scaled up, combined with Epoch’s cost per FLOP over time estimates here. Because the cost-effectiveness of AI hardware improves at ~35% per year, a 50% increase in new hardware per year requires only a modest (~11%) increase in annual spending, for a constant or declining fraction of companies’ R&D budgets over the next decade. Google grew 20% annually from 2014-2024, and the Nasdaq about 14% annually.
- ^
I don’t fully understand how the interactive model handles AI training costs while software is continuously improving–it looks like the “largest training run” in the TS model at any given time may be recalculated continuously and happen instantly, which means that while real AI companies release models every few months, their simulated counterparts benefit from significantly tighter feedback loops, especially during AGI->ASI takeoff, than the real companies would. Though more continuous training paradigms are also likely to emerge as they become more incentivized.
- ^
The TS model is capturing AI R&D speedup as more than a fraction of tasks automated, but it’s not easy to inspect from the interactive model.
- ^
It would cost something like $600B for the datacenters to do training and inference for frontier models at the current rate of scaling. There’s substantial uncertainty here, both in extrapolating future costs and in judging what would be too expensive for frontier AI companies, which would likely depend on AI capabilities at that time.
- ^
One scenario I don’t examine that would be interesting: AI winter in 2026 or 2027, followed by AI summer years later once new classes of algorithms are discovered or gradual cost-effectiveness advances revive interest.
- ^
For example, I would continue to be wary of raising awareness in ways that could burn the AI risk community’s credibility in longer crunch time scenarios, or before political and public awareness catch up.
- ^
One objection is that as we get close to full economic automation, there could be large jumps as AI capabilities quickly improve. But I think this is better viewed as AI-assisted R&D discovering new algorithms that increase the eFLOP of AI systems. Task automation will thus look continuous over eFLOP, while the shape of the “automation over time” curve will change around full R&D automation.
- ^
Davidson adds (under Objection 4), “Even if it didn’t map to reality well at all, the “% cognitive tasks” abstraction would still be the best way I’m aware of to model AI continuously improving from today when it (seemingly) can readily perform <1% of economic tasks to a future world where it can perform ~all cognitive tasks. A skeptic can just think of the framework as giving some arbitrary one-dimensional scale on which “AI capabilities” improve between today and AGI.” See also page 10 of Part 3 of the TS report here, “Arguments for a ‘kink’ in underlying capabilities”.
- ^
David Schneider-Joseph notes that the transformer architecture is a partial example–it performs better at the scale of today’s models than LSTMs or CNNs, but worse at smaller scales. This would mean that Epoch’s figures underestimate the speed of algorithmic progress. On the other hand, certain tweaks to boost model efficiency, like tuning hyperparameters, mostly work just on one model or model family–they don’t transfer well to future models. It’s plausible that some of the measured algorithmic changes fall in this category, meaning algorithmic progress is slower than estimated.
3 comments
Comments sorted by top scores.
comment by Lee.aao (leonid-artamonov) · 2025-03-19T15:23:56.051Z · LW(p) · GW(p)
I'm surprised to see no discussion here or on Substack.
This is a well-structured article with accurate citations, clearly explained reasoning, and a peer review.. that updates the best agi timeline model.
I'm really confused.
I haven't deeply checked the logic to say if the update is reasonable (that's exactly the kind of conversation I was expecting in the comments). But I agree that Davidson's model was previously the best estimate we had, and it's cool to see that this updated version exlains why Dario/Sama are so confident.
Overall, this is excellent work, and I'm genuinely puzzled as to why it has received 10x fewer upvotes than the recent fictional 2y takeover scenario.
Replies from: testingthewaters, johncrox↑ comment by testingthewaters · 2025-03-19T15:37:31.427Z · LW(p) · GW(p)
It's hard to empathise with dry numbers, whereas a lively scenario creates an emotional response so more people engage. But I agree that this seems to be very well done statistical work.
↑ comment by johncrox · 2025-03-21T17:11:10.144Z · LW(p) · GW(p)
Appreciate it. My sense is that the LW feed doesn't prioritize recent posts if they have low karma, so it's hard to get visibility on posts that aren't widely shared elsewhere and upvoted as a result. If you think it's a good post, please send it around!