GPT-4 Predictions
post by Stephen McAleese (stephen-mcaleese) · 2023-02-17T23:20:24.696Z · LW · GW · 27 commentsContents
Introduction Background of GPT models GPT-1, GPT-2, GPT-3 InstructGPT, GPT-3.5, ChatGPT When will GPT-4 be released? What will GPT-4 be like? How capable will GPT-4 be? Scaling laws Training compute GPT-3 training compute AI training supercomputers GPT-4 training compute Model parameters Training tokens GPT-4 loss GPT-4 performance MMLU Distinguishing AI-generated text from human text GPT-4 context length Emergent capabilities Conclusion None 29 comments
Introduction
GPT-4 is OpenAI’s next major language model which is expected to be released at some point in 2023. My goal here is to get some idea of when it will be released and what it will be capable of. I also think it will be interesting in retrospect to see how accurate my predictions were. This post is partially inspired by Mathew Barnett’s GPT-4 Twitter thread which I recommend reading.
Background of GPT models
GPT-1, GPT-2, GPT-3
GPT stands for generative pre-trained transformer and is a family of language models that were created by OpenAI. GPT was released in 2018, GPT-2 in 2019, and GPT-3 in 2020. All three models have used a similar architecture with some relatively minor variations: a dense, text-only, decoder transformer language model that’s trained using unsupervised learning to predict missing words in its text training set [1].
InstructGPT, GPT-3.5, ChatGPT
Arguably one of the biggest changes in the series in terms of architecture and behavior was the release of InstructGPT in January 2022 which used supervised fine-tuning using model answers and reinforcement learning with human feedback where model responses are ranked in addition to the standard unsupervised pre-training.
The GPT-3.5 models finished training and were released in 2022, and demonstrated better quality answers than GPT-3. In late 2022, OpenAI released ChatGPT which is based on GPT-3.5 and fine-tuned for conversation.
When will GPT-4 be released?
Sam Altman, the CEO of OpenAI, was interviewed by StrictlyVC in January 2023. When asked when GPT-4 would come out, he replied, “It will come out at some point when we are confident that we can do it safely and responsibly.”
Metaculus predicts a 50% chance that GPT-4 will be released by May 2023 and a ~93% chance that it will be released by the end of 2023.
It seems like there’s still quite a lot of uncertainty here but I think we can be quite confident that GPT-4 will be released at some point in 2023.
What will GPT-4 be like?
Altman revealed some more details about GPT-4 at an AC10 meetup Q&A. He said:
- GPT-4 will be a text-only model like GPT-3.
- GPT-4 won’t be much bigger than GPT-3 but will use much more compute and have much better performance.
- GPT-4 will have a longer context window.
How capable will GPT-4 be?
Scaling laws
According to the paper Scaling Laws for Neural Language Models (2020), model performance as measured by cross-entropy loss can be calculated from three factors: the number of parameters in the model, the amount of compute used during training, and the amount of training data. There is a power-law relationship between these three factors and the loss. Basically, this means you have to increase the amount of compute, data, and parameters by a factor of 10 to decrease the loss by one unit, by 100 to decrease the loss by two units, and so on. The authors of the paper recommended training very large models on relatively small amounts of data and recommended investing compute into more parameters over more training steps or data to minimize loss as shown in this diagram:
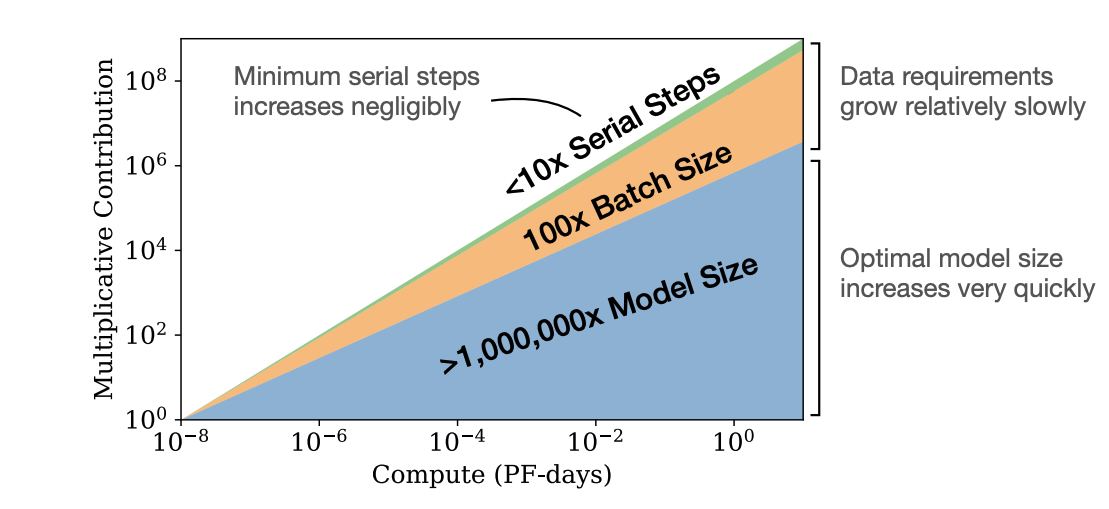
For every 10x increase in compute, the paper approximately recommends increasing the number of parameters by 5x, the number of training tokens by 2x, and the number of serial training steps by 1.2x. This explains why the original GPT-3 model and other models such as Megatron and PaLM were so large.
However, the new scaling laws from DeepMind’s 2022 paper Training Compute Optimal Language Models instead emphasize the importance of training data for minimizing loss. Instead of prioritizing more parameters, the paper recommends scaling the number of parameters and training tokens equally.
DeepMind originally trained a large 280B parameter model named Gopher but then found a 70B model named Chinchilla trained on 4x as much training data performed better using the same compute budget. Chinchilla also outperformed other larger models such as GPT-3.
Given a fixed compute budget, the Chinchilla paper describes how to calculate the optimal number of parameters and training tokens for the model. These two parameters can then be used to calculate the optimal loss.
Therefore, we can predict GPT-4’s performance by first estimating the amount of compute it will use in training, then the number of parameters and training tokens it will use during training, and finally the model’s loss.
Training compute
Of training compute, tokens, and parameters, compute is generally the most expensive factor and therefore arguably the most significant constraint on model performance.
GPT-3 training compute
Training GPT-3 required 3.14e23 FLOP according to EpochAI’s dataset. The GPT-3 paper Large Language Models are Few-Shot Learners (2020) doesn’t say much about the training process except “All models were trained on V100 GPUs on part of a high-bandwidth cluster provided by Microsoft”.
The V100 GPU was released by Nvidia in 2017. It has a single-precision (FP32) performance of 14 TFLOP/s (teraflops per second) and a tensor performance of 114 TFLOP/s (8X theoretical speedup) when tensor cores are used. Though in reality, the speedup is usually lower. Another limitation is that mixed precision (FP16) needs to be used to make use of these tensor cores. GPT-3 was trained with half-precision (FP16) so the training process was probably accelerated using tensor cores.
An experiment by DeepSpeed in 2020 that involved training the BERT language model achieved 66 TFLOP/s per V100 GPU (4.7x speedup). Assuming that each V100 GPU contributed about 60 TFLOP/s during the GPT-3 training process, then training the model on one GPU would have taken about 165 years. If the training process actually took about 30 days, then OpenAI would have needed about 2000 V100 GPUs for training.
AI training supercomputers
Since the V100 GPU, Nvidia has released the A100 GPU (May 2020) which has ~3x better performance than the V100, and the H100 (release date: early 2023) which has ~4x better performance than the A100 for language modeling tasks. I’m going to assume that GPT-4 mostly uses A100s for training since the A100 is already released.
The A100 has 19.5 FLOP/s of FP32 performance and 312 TFLOP/s when using FP16 (half-precision) with tensor cores which is about 3x higher than the V100. Assuming ~50% utilization, each A100 can contribute about 150 TFLOP/s.
Nvidia has a product named DGX A100 which combines 8 A100 80GB GPUs. A DXB SuperPOD combines 140 DXB A100 nodes (1120 A100 GPUs). In 2020, Nvidia combined 4 DXB SuperPODs to create a 560-node (4480 A100) supercomputer named Selene. According to Microsoft’s Megatron-Turing NLG paper (2021), each A100 GPU can deliver up to about 160 TFLOP/s. Therefore, Selene’s total computing capacity for AI training is about 700 PFLOP/s [2]. When it was created, it was also the 7th fastest computer in the world because of its ability to do 63 PFLOP/s of high-performance computing.
In May 2020 (around the release date of GPT-3), Microsoft announced that it created a new AI training supercomputer exclusively for OpenAI. The supercomputer had about 285,000 CPUs and 10,000 GPUs and it ranked in the top 5 supercomputers in the world. Assuming that it used a similar architecture to Nvidia’s Selene supercomputer (A100s), then it would have 1250 DGX A100 nodes which are equivalent to about 9 DXB SuperPODs.
Microsoft trained its large 530B parameter Turing NLG language model using Selene. In the paper, they also described how they trained models of different sizes from 1.7B parameters to 1T parameters.
The paper introduced a formula for calculating the training time for a model:
Where T is the number of training tokens, P is the number of parameters, n is the number of GPUs and X is the number of TFLOP/s per GPU.
They used this formula to calculate how long it would take to train GPT-3 using A100 GPUs. T = 300B, P = 175B, n = 1024 and X = 140 TFLOP/s. They calculated that it would take 34 days to train GPT-3 using 1024 A100 GPUs which would cost about $2m assuming that each A100 costs about $3 per hour.
In March 2022, Nvidia announced a new supercomputer named Eos which uses 4608 H100 GPUs and was expected to begin operating in late 2022 though I'm not sure if it's actually been built yet. Assuming that each H100 is 4x faster than an A100 GPU, then Eos should have a performance of about 3 EFLOP/s [3].
GPT-4 training compute
GPT-3 used about 200 times more training compute than GPT-2.
Training GPT-3 in 30 days would require a supercomputer with about 120 PFLOP/s such as a cluster of 2000 V100 GPUs. In theory, Selene could train GPT-3 in 5 days and Eos in just 1 day.
If OpenAI wanted to maximize the amount of compute they used for training GPT-4, they would maximize the number of GPUs used in training and the total training time. If they had 10,000 A100 GPUs with 160 TFLOP/s per A100 then the total compute of this system would be 1.6 EFLOP/s. To reach 1 EFLOP/s, 6250 A100 GPUs would be required.
I created a simple Squiggle model to estimate GPT-4’s training compute:
a100_gpu_flop = 160
total_gpus = 2000 to 15000
training_months = 1 to 6
training_seconds = training_months * 30 * 24 * 3600
flop_per_second = a100_gpu_flop * total_gpus
total_flop = flop_per_second * training_secondsFrom the model, the 25%, 50%, and 75% percentile values for the training supercomputer are 580 PFLOP/s, 880 PFLOP/s, and 1.3 EFLOP/s.
For the total compute, the 25%, 50%, and 75% percentile values are 3.2e24 FLOP, 5.63e24 FLOP, and 9.7e24 FLOP.
5.63e24 FLOP is about 18 times more compute than what was used to train GPT-3. In the following chart, I add GPT-4 to EpochAIs visualization:
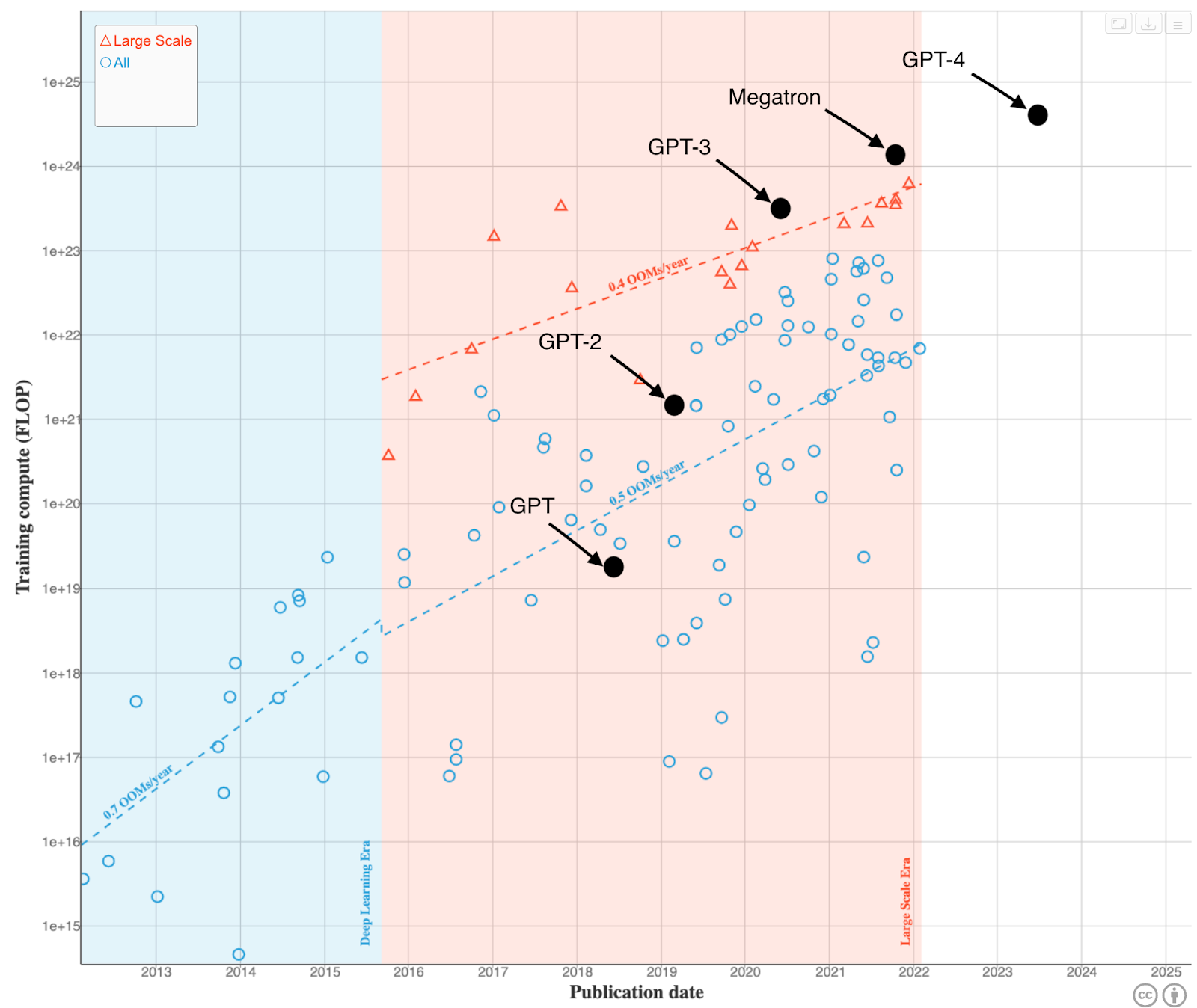
Although GPT-4 will almost certainly use more compute than previous models it seems like the increase in compute over time is slowing down somewhat. Though if GPT-4 is trained using H100 GPUs in addition to standard A100 GPUs, then we can expect the total compute to be even higher.
Model parameters
As mentioned earlier, Sam Altman stated that GPT-4 won’t be much bigger than GPT-3. This makes sense because according to the Chinchilla scaling laws, GPT-3 was undertrained. Therefore, compute, and especially data – not parameters – seem to be the bottleneck for improving performance.
The Chinchilla paper calculated the relationship between compute, parameters, and training tokens using three different methods resulting in three tables that show the optimal amount of training FLOP and training tokens given certain model sizes. The first table is shown in the paper and the other 2 are in the appendix. Here is the first table:
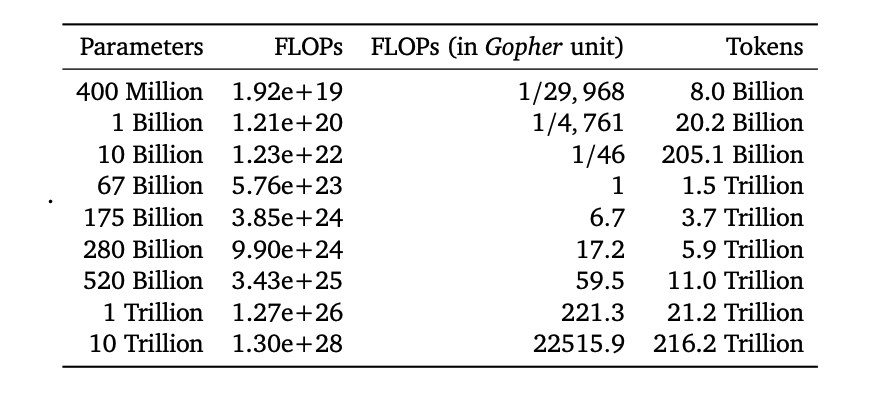
The following table shows the average values of the three tables:
| Parameters | Compute | Tokens |
| 400M | 1.99e19 | 8.30B |
| 1B | 1.34e20 | 22.43B |
| 10B | 1.67e22 | 278.2B |
| 67B | 9.91e23 | 2.43T |
| 175B | 3.22e24 | 6.67T |
| 280B | 1.90e25 | 11.03T |
| 520B | 7.07e25 | 22.63T |
| 1T | 2.84e26 | 47.27T |
| 10T | 3.87e28 | 644.57T |
Another way to think about the tables is that given a certain fixed compute budget, they show the optimal number of parameters and training tokens for minimizing the model’s loss. This is shown more clearly by a graph in the appendix of the paper:
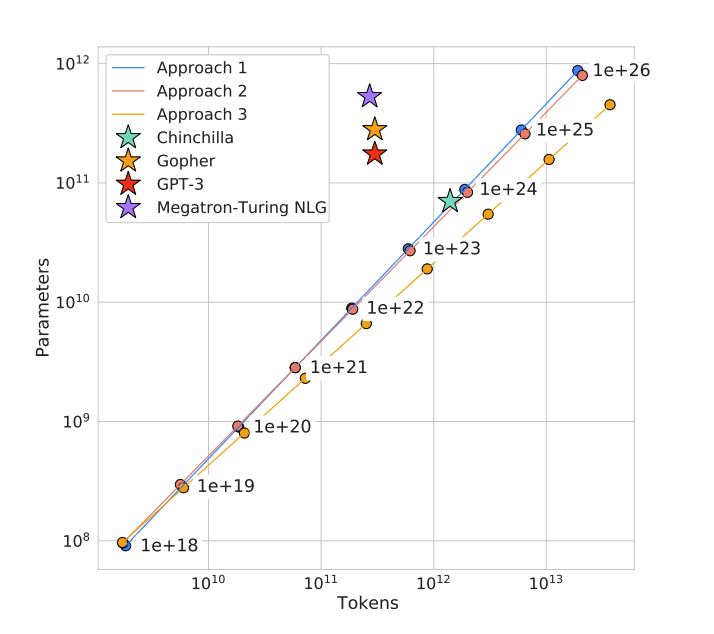
Chinchilla was trained using 5.76e23 FLOP which is about twice GPT-3’s compute budget of 3.14e23 FLOP. But Chinchilla only has 70B parameters whereas GPT-3 had 175B. The authors estimated that training a 175B model like GPT-3 optimally requires 4.41e24 FLOP which is 14 times more than GPT-3’s original compute budget. This suggests that GPT-3 was an oversized model and should have been similar in size to Chinchilla and trained on much more data.
If GPT-4’s compute budget is 5.63e24 FLOP, these scaling laws suggest that GPT-4 will be similar in size to GPT-3 to achieve optimal loss. From the table, we can see a model with a compute budget of 5.63e24 should have between about 175B and 280B parameters. My best guess from the data is about 200B parameters though the data seems too variable to make a precise guess.
Training tokens
According to OpenAIs Scaling Laws for Neural Language Models (2020) paper, the amount of compute used in training by a model can be approximated by this equation: where D is the number of training tokens and N is the number of parameters in the model. Therefore, given a fixed amount of compute, a relatively large model could be trained on less data (e.g. GPT-3) or a smaller model could be trained on more data (e.g. Chinchilla).
The Chinchilla model was designed using DeepMind’s new scaling laws and had 70B parameters and was trained on 1.5T tokens. In contrast, although GPT-3 had 175B parameters, it was only trained on 300B tokens.
This suggests that GPT-4 can achieve a much lower loss by being trained on significantly more tokens. Assuming GPT-4 has 175B parameters, it should be trained on about 4T tokens according to the paper which is about 13 times more than the amount of training data used by GPT-3.
However, like compute, training tokens also seem to be in limited supply. An EpochAI paper estimates that there are about 10T tokens of high-quality language data in the world and a post by nostalgebraist [LW · GW] estimated there are only about 3.2T of text training data. On the other hand, according to the Chinchilla paper, methods like RETRO where the model is assisted by a database have the same effect as increasing the number of training tokens by a factor of 10.
I’m going to assume here that it will be possible to find the necessary training tokens to train GPT-4 optimally. Though a training data shortage could be an issue for future models.
GPT-4 loss
Now that we have estimates for how much compute, data, and parameters GPT-4 will have, we can plug these parameters into a scaling formula to calculate GPT-4’s loss compared to other models.
The Chinchilla paper has a formula of the form for calculating a model's optimal loss[4]. By entering the number of parameters in the model and the number of tokens it was trained on, we can calculate its loss:
E is a constant, the second term is the loss from the fact that the model has a finite number of parameters and the third term is the loss contribution from the model's finite number of training tokens. Therefore, a 'perfect' model with infinite parameters and infinite training data would have a loss of E (1.69).
The formula using constants from the paper:
GPT-3 had 175B parameters and was trained with 3.14e23 FLOP of compute and 300B tokens:
For GPT-4 I’m going to assume that it has 175B parameters and is trained on 4T tokens:
Here are the loss values for several models:
| Model name | N | D | Loss |
| GPT | 117M | 1B | 3.6644 |
| GPT-2 | 1.5B | 15B | 2.5794 |
| GPT-3 | 175B | 300B | 2.0023 |
| Megatron-Turing NLG | 530B | 270B | 1.9906 |
| Gopher | 280B | 300B | 1.9933 |
| Chinchilla | 70B | 1.5T | 1.9335 |
| GPT-4 | 175B | 4T | 1.8727 |
GPT-4 performance
The relationship between loss and performance is not immediately clear but we can get some idea by comparing the performance of different models which is done in the Chinchilla paper.
Chinchilla's loss as calculated from the formula is only 3% lower than Gopher's but has significantly better performance according to the paper with 7.6% better performance on the MMLU benchmark. This suggests that performance is quite sensitive to changes in loss.
MMLU
The paper has a table that shows the performance of various models on the MMLU benchmark [5] which is a dataset of multiple-choice questions on many different topics such as math and science questions. I also added some information from the MMLU benchmark table from Papers With Code:
| Model | Loss | MMLU 5-shot accuracy |
| Random | N/A | 25.0% |
| GPT-J (6B) | 2.13363 | 27.3% |
| Average human rater | N/A | 34.5% |
| GPT-3 | 2.00223 | 43.9% |
| Gopher | 1.99326 | 60.0% |
| Chinchilla | 1.93352 | 67.6% |
| PaLM (540B) | 1.92387 | 69.3% |
| GPT-4 (predicted) | 1.87274 | 78.9% |
| Average human expert | N/A | 89.8% |
As you can see, there is an inverse correlation between loss and MMLU performance. Using this data, I created a simple linear regression to predict GPT-4's MMLU performance based on its loss:
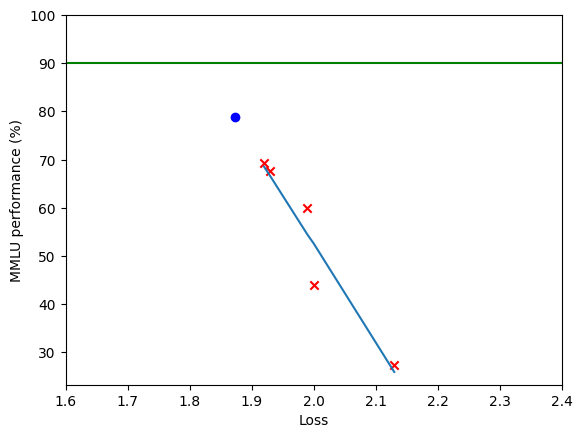
The red x's are previous models and the blue dot is GPT-4's predicted performance. The green line represents expert human performance.
Currently, the best model on the MMLU benchmark is a fine-tuned version of PaLM which has 75.2% accuracy. If GPT-4 achieves 78.9% accuracy, then it could set a new record on the benchmark.
Distinguishing AI-generated text from human text
In the GPT-3 paper Language Models are Few Shot Learners (2020), you can find this interesting graph showing the relationship between model parameters and the ability of humans to distinguish between model-generated and human-written texts.
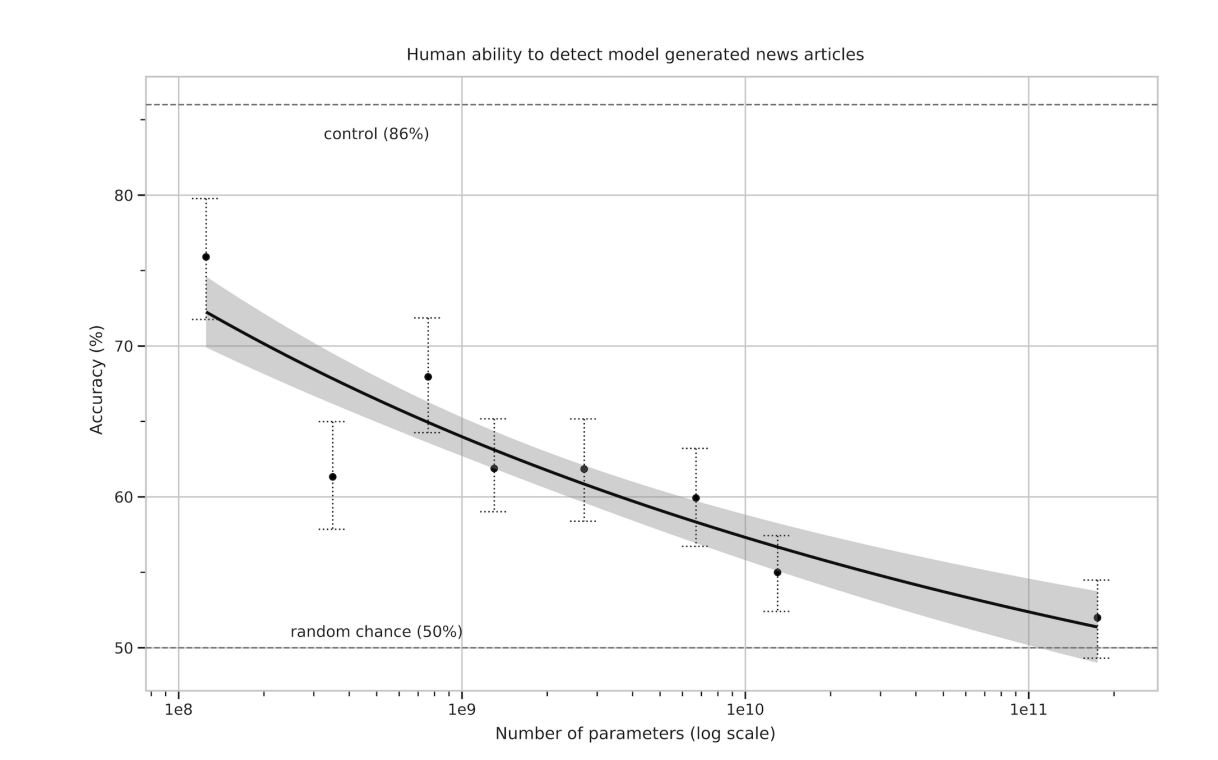
This time I assumed 300e9 training tokens and inputted the number of parameters in the graph into the L(N, D) formula. Then I created a linear regression between the percentage of the time humans can distinguish between model-generated and human text and the estimated loss:
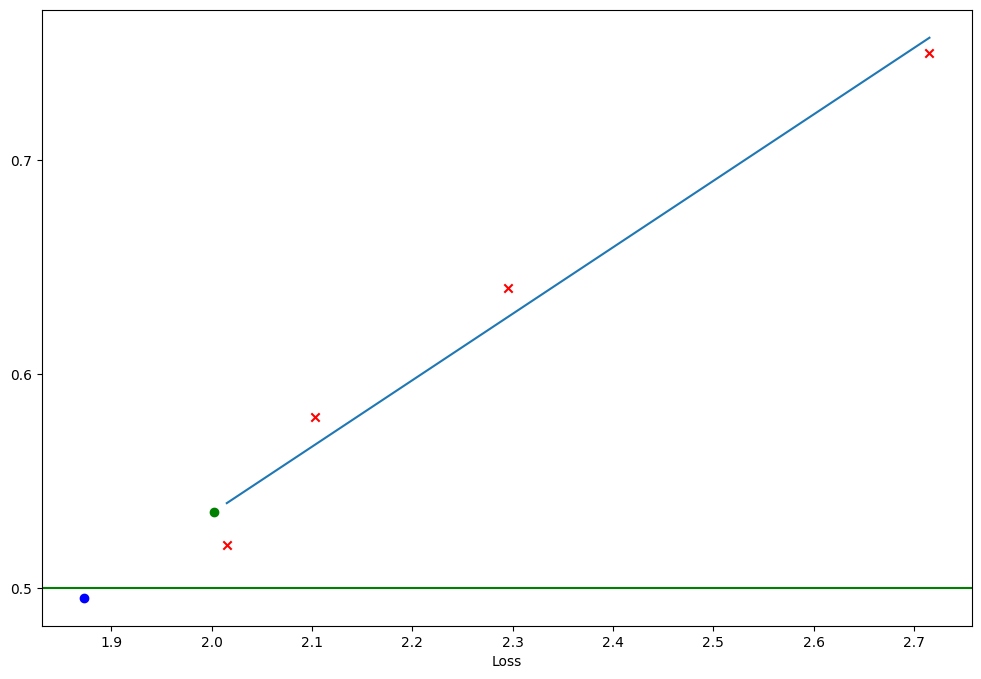
In this graph, the green dot is GPT-3 and the blue dot is GPT-4. As you can see, the blue dot is below the green line which means text generated by GPT-4 could be indistinguishable from human text!
GPT-4 context length
Sam Altman mentioned that GPT-4 would have a longer context length.
GPT-2 had a context length of 1024 and the original GPT-3 model had a 2048 token context window though it has been raised to 4096 tokens for newer GPT-3.5 models such as ChatGPT.
The context window of transformer language models is limited because the compute and memory cost tends to grow with the length of the window. Traditionally it grew quadratically but in GPT-3 the ratio is [1].
Based on improvements in GPU memory and the trend of increasing context length in past GPT models, my rough guess is that GPT-4 will have twice the context length: 8192 tokens.
Emergent capabilities
In addition to more predictable improvements in capabilities, language models can suddenly gain unexpected new emergent capabilities. Emergent capabilities are those that are present in large models but mostly absent from smaller models.
For example, the GPT-3 paper showed that language models can rapidly become much better at addition and other forms of calculation as they are scaled up:
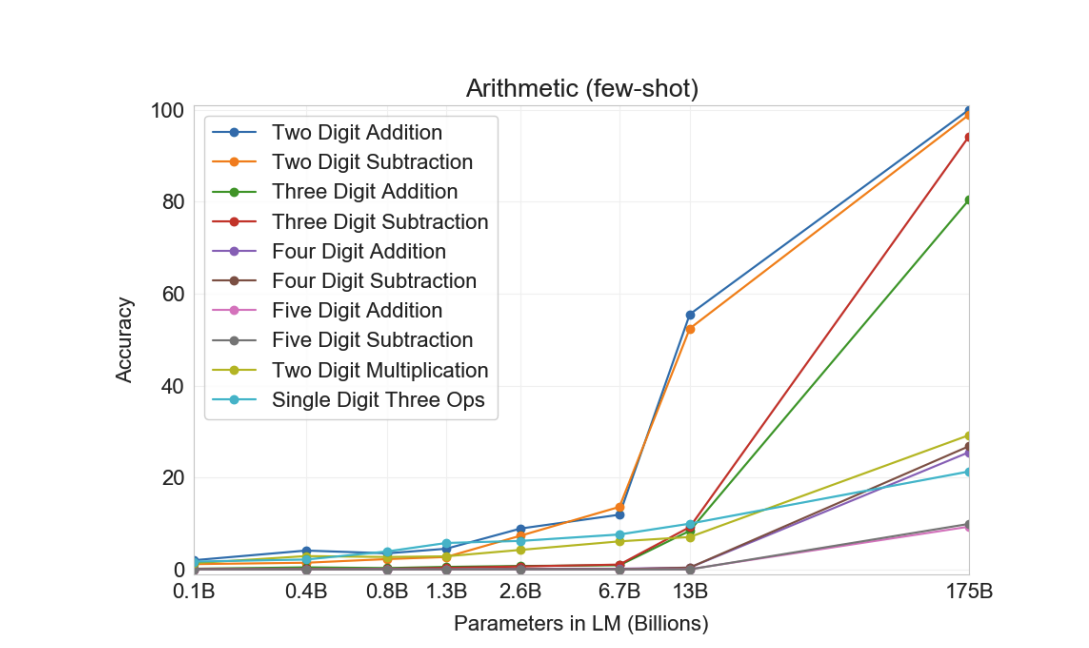
Similarly, GPT-4 could have unexpected new capabilities.
Conclusion
In conclusion, I expect GPT-4 to be very impressive but probably not an AGI. As Sam Altman said in the StrictlyVC interview: "We don’t have an actual AGI and that’s sort of what’s expected of us."
Will the performance gap between GPT-4 and GPT-3 be as large as the gap between GPT-3 and GPT-2? GPT-3 used 200 times more compute than GPT-2 but I predict that GPT-4 will only use about 20 times more compute than GPT-3. GPT-4 probably won't be much larger than GPT-3 but will instead improve by being trained on many more training tokens. GPT-2's loss was 2.5, GPT-3's was 2.0 and I predict that GPT-4 will have a loss of about 1.9 based on this information. Therefore, based on this information it seems unlikely that GPT-4 will be better than GPT-3 in the same way that GPT-3 was better than GPT-2.
However, GPT-4 could still be as impressive as GPT-3 was compared to GPT-2 for other reasons. One reason is that GPT-3 could be on the threshold of being highly disruptive for some capabilities. GPT-3 excelled at writing but its quality of writing wasn't quite human-level given that people can distinguish text generated by GPT-3 better than chance. For example, the Guardian published an article that was written by GPT-3 but it was edited by humans.
But this could change for GPT-4 which will have a lower loss and longer context length. I expect GPT-4 to excel at writing as GPT-3 has and it could be disruptive if it can generate text that is indistinguishable from human text. With GPT-4, we might see the first AI model to be convincingly human-level at writing blog posts without human editing [6]. GPT-4 could also be highly capable at programming.
Another way GPT-4 could be very disruptive is if it achieves a large leap in capabilities via emergent capabilities. Even though GPT-3 was only trained on next-word prediction, it developed unexpected capabilities such as the ability to learn on the fly from prompts (in-context learning), arithmetic, and code generation. Similarly, GPT-4 could gain many qualitatively different capabilities that are hard to predict in advance. If GPT-4 has many emergent capabilities, then the advancement from GPT-3 to GPT-4 and overall change in impressiveness could be as large as the difference between GPT-2 and GPT-3.
- ^
GPT-3 uses the exact same architecture as GPT-2 except it used “alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer” which reduces the context length to memory ratio from to .
- ^
Nvidia claims that Selene can reach 2.8 EFLOP but that's Selene's theoretical performance using structural sparsity. Without sparsity, the performance is half that and half again given that typical GPU utilization is only 50%. 2800 / 4 = 700.
- ^
When training dense models.
- ^
Chinchilla's Wild Implications [LW · GW] by nostalgebraist explains the formula well.
- ^
Massive multitask language understanding.
- ^
I wrote this post myself but imagine for a moment if it had been generated by a language model without any editing.
27 comments
Comments sorted by top scores.
comment by wassname · 2023-02-19T03:06:30.565Z · LW(p) · GW(p)
There may also be some architecture advances, although I'm unsure why we didn't see these recent LLM's. In Sam Altman's AC10 meetup Q&A he did say that GPT-4 would use a different loss function, what effect would that have? I have no idea.
You can see some examples in this Jan 2023 overview of transformer advances by Lilian Weng and The Transformer Family v2
Replies from: gwern↑ comment by gwern · 2023-03-12T19:12:54.160Z · LW(p) · GW(p)
he did say that GPT-4 would use a different loss function, what effect would that have? I have no idea.
One possibility is shifting the power law. See UL2 which combines the various denoising losses in what turns out to be a very good way: "U-PaLM: Transcending Scaling Laws with 0.1% Extra Compute", Tay et al 2022 - halving PaLM training requirements w/UL2 losses. I don't know if OA discovered UL2 first, but it's not all that exotic or subtle and is certainly something that many people ask themselves when they learn about the difference between bidirectional and unidirectional models: "why not train on both/all the losses?"
comment by LawrenceC (LawChan) · 2023-02-18T08:19:45.169Z · LW(p) · GW(p)
Thanks for writing this!
I think the crux of your estimate of compute usage is the following line:
total_gpus = 2000 to 15000In May 2020 (!) Microsoft announced that they had built a supercomputer with 10,000 GPUs for OpenAI, which is often suggested to be the machine GPT-3 was trained on: https://news.microsoft.com/source/features/ai/openai-azure-supercomputer/
So it's very possible (albeit unlikely) that the number of total GPUs used for GPT-4 training could be higher than 15000!
Corrections/nitpicks:
GPT-3.5 finished training in early 2022, was released in November 2022, and demonstrated better quality answers than GPT-3. In December 2022, OpenAI released ChatGPT which is based on GPT-3.5 and fine-tuned for conversation.
code-davinci-002 and text-davinci-002 were first released in mid March 2022, soon after the InstructGPT paper, not November 2022. Source:
https://openai.com/blog/gpt-3-edit-insert/ (See also this reddit thread talking about text-davinci-002.)
The capability can be used with the latest versions of GPT-3 and Codex,
text-davinci-003andcode-davinci-002.
Also, a nitpick: ChatGPT was released November 30th, 2022: https://openai.com/blog/chatgpt/
Replies from: gwern, stephen-mcaleese, cubefox↑ comment by gwern · 2023-03-12T19:10:56.559Z · LW(p) · GW(p)
So it's very possible (albeit unlikely) that the number of total GPUs used for GPT-4 training could be higher than 15000!
OAers have noted that the cluster has, of course, been expanded heavily since the original 10k (albeit not what it is now). Morgan Stanley is saying that GPT-5 is being trained right now on 25,000 GPUs, up heavily from the original 10k, and implying that 'most' of the GPT-5 GPUs were used for GPT-4 which finished 'some time ago'; the mean of 10 & 25 is 17.5, so >15k seems entirely possible, especially if those GPUs weren't just installed.
↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-02-18T09:44:10.771Z · LW(p) · GW(p)
Thanks for the comment! I updated the paragraph to:
The GPT-3.5 models finished training and were released in 2022, and demonstrated better quality answers than GPT-3. In late 2022, OpenAI released ChatGPT which is based on GPT-3.5 and fine-tuned for conversation.
↑ comment by cubefox · 2023-02-18T18:52:24.405Z · LW(p) · GW(p)
The March blog post mentions text-davinci-003, but you only say text-davinci-002 was released in March. The latter seems more plausible, since it matches with the newsletter OpenAI sent out at the end of November: "New GPT-3 model: text-davinci-003".
Starting today, you can access
text-davinci-003through our API and playground at the same price as our other Davinci base language models ($0.0200 / 1k tokens).
So I think the "March" blog post has probably been edited and isn't decisive evidence that code-davinci-002 (the GPT 3.5 base model) actually came out in March.
comment by nostalgebraist · 2023-02-22T06:19:34.771Z · LW(p) · GW(p)
GPT-4 will have twice the context length: 8192 tokens
code-davinci-002 already has a context window of 8000 tokens. Or at least, that is the max request length for it in the API.
comment by AlexMennen · 2023-02-18T04:21:43.342Z · LW(p) · GW(p)
In the table of parameters, compute, and tokens, compute/(parameters*tokens) is always 6, except in one case where it's 0.6, one case where it's 60, and one case where it's 2.75. Are you sure this is right?
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-02-18T09:38:45.521Z · LW(p) · GW(p)
Thanks for spotting this.
I noticed that I originally used the formula when it should really be because this is the way it's written in the OpenAI paper Scaling Laws for Neural Language Models (2020). I updated the equation.
The amount of compute used during training is proportional to the number of parameters and the amount of training data: .
Where there is a conflict between this formula and the table, I think the table should be used because it's based on empirical results whereas the formula is more like a rule of thumb.
Replies from: AlexMennen↑ comment by AlexMennen · 2023-02-18T16:43:48.260Z · LW(p) · GW(p)
My point wasn't that the equation didnt hold perfectly, but that the discrepancies are very suspicious. Two of the three discrepancies were off by exactly 1 order of magnitude, making me fairly confident that they are the result of a typo. (Not sure what's going on with the other discrepency).
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-02-18T18:24:12.000Z · LW(p) · GW(p)
You were right. I forgot the 1B parameter model row so the table was shifted by an order of magnitude. I updated the table so it should be correct now. Thanks for spotting the mistake.
comment by Mo Putera (Mo Nastri) · 2023-03-14T19:51:25.602Z · LW(p) · GW(p)
Curious, what do you think now that GPT-4 is out?
comment by gwern · 2023-03-12T22:18:14.628Z · LW(p) · GW(p)
GPT-4 will be a text-only model like GPT-3.
That was a very long time ago, and the current GPT-4, you agree, would've been trained well after. So we can't put too much weight on it.
The current reporting is pushing very heavily on multimodality, including the announcement by Microsoft Germany that it will be released next week & explicitly stating GPT-4 will do video, in addition to earlier reporting about images (as well as Altman musing about revenge porn).
comment by cubefox · 2023-02-18T21:54:00.099Z · LW(p) · GW(p)
Several people have argued that Sydney/Bing Chat performs better on reasoning tasks than ChatGPT/GPT-3.5, apart from its questionable dialogue fine-tuning. It may therefore be GPT-4. Have you looked into this? How does it affect your analysis?
I think it seems that Sydney is not the big leap you seem to predict for GPT-4. Then again, Sydney may use a smaller model (like Curie or Babbage for GPT-3) to save on inference cost, while you seem to be talking about the largest davinci model only.
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-02-18T23:23:03.118Z · LW(p) · GW(p)
I've seen some of the screenshots of Bing Chat. It seems impressive and possibly more capable than ChatGPT but I'm not sure. Here's what Microsoft has said about Bing Chat:
"We’re excited to announce the new Bing is running on a new, next-generation OpenAI large language model that is more powerful than ChatGPT and customized specifically for search. It takes key learnings and advancements from ChatGPT and GPT-3.5 – and it is even faster, more accurate and more capable."
If the model is more powerful than GPT-3.5 then maybe it's GPT-4 but "more powerful" is too vague and phrase to come up with any clear conclusions. I don't think I have enough information [LW · GW] at this point to make strong claims about it so I think we'll have to wait and see.
comment by Lukas Finnveden (Lanrian) · 2023-06-15T23:53:21.530Z · LW(p) · GW(p)
GPT-2 1.5B 15B 2.5794
Where does the "15B" for GPT-2's data come from, here? Epoch's dataset's guess is that it was trained on 3B tokens for 100 epochs: https://docs.google.com/spreadsheets/d/1AAIebjNsnJj_uKALHbXNfn3_YsT6sHXtCU0q7OIPuc4/edit#gid=0
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-06-16T09:50:47.957Z · LW(p) · GW(p)
I used the estimate from a document named What's In My AI? which estimates that the GPT-2 training dataset contains 15B tokens.
A quick way to estimate the total number of training tokens is to multiply the training dataset size in gigabytes by the number of tokens per byte which is typically about 0.25 according to the Pile paper. So 40B x 0.25 = 10 billion.
comment by Adam_Barker · 2023-04-04T10:47:20.595Z · LW(p) · GW(p)
Here's an equation for the MMLA vs Loss plot:
A MMLA = 100% corresponds to a loss of 1.8304. Using the scaling laws, listed here, this can be reached using:
- The GPT-4 dataset (4Gtokens) and a model 11x the size of Megatron-Turing NLG (6 trillion parameters). Compute time: 111 days on Eos.
- GPT-4's 175B params with 18.5 trillion training tokens (4.6x the size of GPT-4's dataset). Compute time: 16 days on Eos, but getting that many tokens may be a problem.
- Megatron-Turing NLG's 530B parameters, and 8.5 trillion tokens (2.1x the size of GPT-4's dataset). Compute time: 23 days on Eos. This is a much more reachable dataset.
The nx compute speed of Eos used for GPT-4 was 18.4 ExaFLOP/s.
comment by eo rojas · 2023-02-18T18:31:04.800Z · LW(p) · GW(p)
Thanks for this great overview of what's going on with the large language models. I want to indulge in some limited knowledge speculation. Just want to put that out there first. I'm going to predict that the larger language models are not going to be very much more useful from the current state. I'm wondering if you know or can talk about what people are doing to improve the models other than making them bigger? I read a Wolfram blog post that talked about using the Wolfram expert systems in conjunction with large language models of you looked at that? The approach of combining llms with with expert systems seems to be a valuable path to me in terms of creating more useful systems. I e, results from a LLM could be evaluated by expert systems and fed back into the text that's generated. Do you see this is the path to creating the even more intelligent systems?
Replies from: Capybasilisk↑ comment by Capybasilisk · 2023-02-19T11:35:08.548Z · LW(p) · GW(p)
There are currently attempts to train LLMs to use external APIs as tools:
comment by BrooksT · 2023-02-18T15:46:32.279Z · LW(p) · GW(p)
Thanks for the excellent post! I don’t think you mentioned anything about technical improvements in training, such as efficiency of parallelization. Do you know if there are internet I f things going in there, or does that shake out as part of the GPU generational improvements?
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-02-18T19:34:02.088Z · LW(p) · GW(p)
Thanks for bringing this up. I don't think I mentioned any algorithmic improvements apart from RETRO so these predictions are probably somewhat conservative.
comment by asasilogic · 2023-02-18T03:35:53.024Z · LW(p) · GW(p)
In the last sentence of the last paragraph, you meant to write "...advancement from GPT-3 to GPT-4..."', yes?
Replies from: stephen-mcaleese↑ comment by Stephen McAleese (stephen-mcaleese) · 2023-02-18T09:00:48.318Z · LW(p) · GW(p)
Thanks for spotting the typo! I updated the post.