MDPs and the Bellman Equation, Intuitively Explained
post by Jack O'Brien (jack-o-brien) · 2022-12-27T05:50:23.633Z · LW · GW · 3 commentsContents
Example: Taxi driver How Does Time Work in MDPs Introducing the MDP 5-tuple The God of Taxi Drivers Finding the Optimal Policy: A Naive Approach The Bellman Equation for Actionless MDPs And Now for MDPs With Actions Answer: Introducing… Q-values! A Better Algorithm for Finding Optimal Policies Summary Takeaways From Writing This Post, and Next Steps None 3 comments
Imagine you're a selfish taxi driver who takes passengers around between 3 towns. Each trip has a different probability of catastrophe and different earnings potential. You want to find a repeatable path of trips to maximise profit. No, you can’t just greedily pick the best trip from each city - sometimes, you must forego immediate profit to take a more profitable trip later.
This problem can be framed as a Markov Decision Process. This framing is the building block of reinforcement learning, a field which will likely play a key role in shaping AGI systems. And more importantly, an MDP is one of the simplest models of an agent which we can build upon to learn more about agency in general.
Example: Taxi driver
Let’s describe the taxi driver’s situation using a graph called a Markov chain. For now we’ll ignore the risk of bad things happening on any trips, and just compare the payoffs for taking different routes:
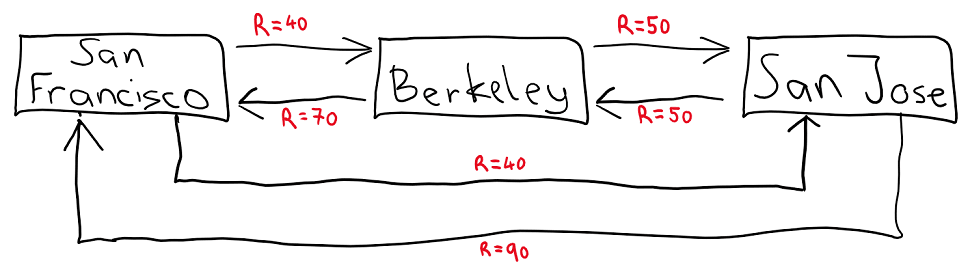
Each town in the graph is known as a “state”. From each state, you can take a couple of actions that involve traveling to a different city. Each action has a different payoff to reflect the current market equilibrium price of different trips. For now, we’ll just pretend that the prices don’t shift over the course of the day, so a taxi driver could always get these payoffs from driving. Now to add some uncertainty into the mix:
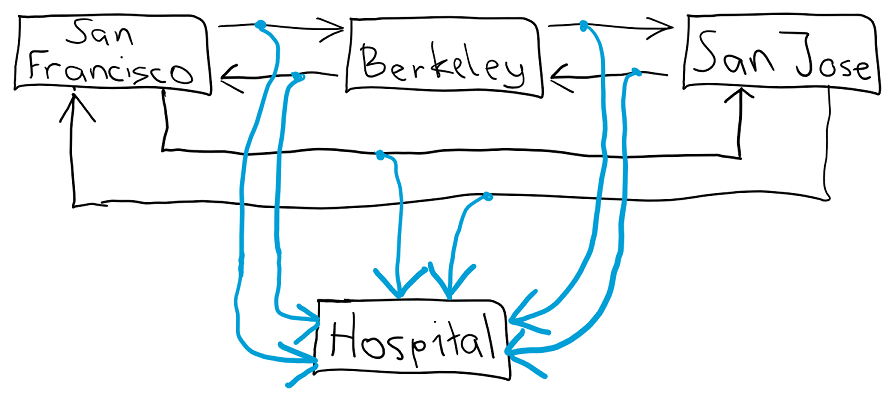
That graph looks a bit more complicated. Everywhere we previously had a single arrow, there is now a split arrow. That’s because every trip has two possible outcomes. We could either take a normal trip and make money, or we could have a car crash and end up in the hospital, losing money in the process. Each possible outcome of a decision has a payoff and a transition probability - I just omitted these from the graph for clarity’s sake. For concreteness, let’s zoom into the trip from Berkeley to San Francisco.
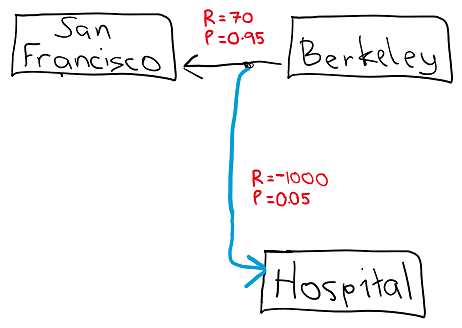
Deciding to travel from Berkeley to San Francisco results in:
- A 95% chance of an uneventful taxi ride, earning 70 reward
- A 5% chance of a car accident and a trip to the hospital, earning -1000 reward
We’ve just created a Markov chain model of the real-world taxi driver situation. These graphs are a bit different from the Markov chains I worked with in a university class. Our Markov chains didn’t have any notion of choices between different actions. An MDP can be viewed as a Markov chain describing the world, with the added functionality of choices an agent can make.
How Does Time Work in MDPs
So you’re a taxi driver and have just arrived in San Francisco. Does it matter whether you arrived from Berkeley or whether you arrived from San Jose? Sure, the scenery of the two trips may have differed which may affect your mood. But it doesn’t affect the profit of any future trips - and it also doesn’t affect the risk of crashing on any future trips. This is the core of the Markov property: Conditional on the current state, the future is independent of the past. In math this is:
But what does “current” mean within this formalism? I’m gonna define a notion of time in an MDP so we can describe the MDP unrolling over time as the agent makes choices and moves around the Markov chain. Let’s add a subscript to states and actions to denote the time, e.g. , - or the more general or to describe something at an arbitrary time . The very first timestep is . Each time the agent takes an action and is thrown into a new state by the environment, a single timestep ticks by.
Exercise: Describe the Markov property more formally using timestep subscripts.
Answer: There’s no strict way to do this. Just needs to capture the core property that the present (ie. ) is equivalent to knowing the past (ie. ). E.g:
. Here, I'm using to denote the reward achieved at time .
Is the Markov property a reasonable assumption? It depends on how we encode the real-world information about a problem into a Markov chain model. It seems possible to construct an MDP to describe many problems. But if we don’t encode enough information from the past into the present state, the Markov assumption might not be useful anymore. Imagine trying to create a Markov chain to describe the motion of a particle. If we only store to particle’s current displacement, this is not enough to know about the future motion of the particle. We also need to know the particle’s current velocity.
Introducing the MDP 5-tuple
We can describe any possible MDP using a 5-tuple of (S, A, R, P, ).
- S is the set of all states. Here, it is {Berkeley, San Francisco, San Jose, Hospital}
- A is the set of all actions. Here, it is all of the possible trips the taxi driver can take: {Travel to Berkeley, Travel to San Francisco, Travel to San Jose}
- R is the reward function which describes the monetary value of each outcome. It takes as input the initial state, the action chosen, and the final state: R(s, a, s’). For example, referring to our earlier trip from Berkeley to San Francisco, the rewards are:
- R(Berkeley, Travel to San Francisco, San Francisco) = 70
- R(Berkeley, Travel to San Francisco, Hospital) = -1000
- P is the transition probability function P(s’ | s, a). It describes the probability of landing in different final states conditional on the agent’s initial state and the agent’s choice of action. For the Berkeley to San Francisco trip from earlier:
- P(San Francisco | Berkeley, Travel to San Francisco) = 0.95
- P(Hospital | Berkeley, Travel to San Francisco) = 0.05
- is the agent’s discount rate. It is a ratio between how valuable reward is if it is delivered 1 timestep later versus if it is delivered on time. A discount rate in the interval (0, 1) makes it easier to find the optimal path because it makes the reward converge in the long run.
Exercise: Convince yourself that we need every element in the 5-tuple except in order to draw a graph of a Markov Decision Process. Try imagining an MDP with no transition probability function, or no set of actions, etc.
The God of Taxi Drivers
Imagine you’re the God of Taxi Drivers and you’re looking down on the taxi driver from earlier. Imagine that the taxi driver, being a fallible mortal, can only see the different towns there are and how to travel between them (ie. the States and the Actions in the MDP). Being omniscient, you can see the entire MDP 5-tuple. Given that you want to maximise the taxi driver’s reward, being the God of Taxi Drivers after all, what can you give the taxi driver? Imagine you’re a busy God without much time; all you can give them is a single function. What would the inputs and outputs of this function be? Think about it for a minute.
Answer: Give the taxi driver a policy, (A | S). Using your omniscience, you can calculate the optimal path through the Markov chain to maximise reward over time. Then, knowing the path, you create this function which takes as input the taxi driver’s current state and returns the best action to take at that state. The policy is technically a probability distribution over actions, which is useful for when an agent is trying to learn which actions are best while actually exploring the environment. But for the purpose of this example, it's OK to think about the policy as a distribution that returns a single action with probability 1.
In particular, you want to give the taxi driver the optimal policy, , which maximises the expected sum of rewards into the future:
Some things to notice about the above mathematical expression:
- We have a sum of reward for each timestep, weighted by the discount factor . Notice that , which is between 0 and 1, is raised to the power of for each timestep, , into the future. So, as we think further into the future, we care less about reward. This is a geometric sum that converges when .
- We take the expectation of the future reward. We need to work with expectations because the actual future reward is a stochastic quantity - it depends on the random outcomes of different actions. When we take the expectation of future reward, it lets us make the best a priori decision.
Finding the Optimal Policy: A Naive Approach
You may notice there are many paragraphs of math to come. What’s the point of learning more bloated math if we could just use the definitions we already know and find the optimal policy?
Let’s create a set P of randomly-generated policies, as many as we have time to test. Then, for each policy, let’s run 1000 timesteps and compute the sum of time-discounted reward over that time. This should be good enough to approximate the optimal policy; simply choose the policy which gets the highest time-discounted reward.
This is basically just computing the above argmax equation, but just testing some sampling of all the possible policies:
This method kinda works. If we happen to guess the optimal policy as one of the elements of P, we can identify it. But, using a slightly different technique, we can find a policy that performs better than any policy in P. So, the coming technique is more efficient since we need to test a smaller number of policies on average. First, we need to cover some more mathematical background on MDPs.
The Bellman Equation for Actionless MDPs
The two key mathematical objects I’m going to introduce here are going to be the Value Function and the Q-Value Function. Value Functions say something about the reward associated with a state; Q-values say something about the reward associated with taking an action at a particular state. These functions help us create a better algorithm for finding an optimal policy.
It’s best to introduce a simple baby Value Function in a slightly different context, so there are fewer symbols flying around the page. Imagine you’re a taxi driver, but you have no choice about which city to drive to next. We can model this using an MDP with no actions, so each state just directly transitions to other states with different probabilities.
Define the Value Function for an MDP with no actions to be:
Unlike our previous sums when describing the optimal policy, the sum of time-discounted reward within the value function does not necessarily start at . It may start at any timestep, and the sum has a counter which ratchets up the time from the starting value of .
The value of a state is kind of like your intuitive sense of how good a state is. It takes into account all the future reward you could attain after your starting state. For example, San Francisco might just feel like a better place to be than Berkeley.
It’s possible to write the Value Function recursively, and this recursive definition is possibly the most important equation in RL. We begin by rearranging the Value Function and pulling the first term with out of the sum:
But notice that the second term inside the expectation is just the Value Function of whatever state we land on after the first state.
So we don't necessarily need to compute an infinite sum - we only need to use the value of the next state. This is known as the Bellman Equation. One immediate application of this equation is that we can estimate the value of each state just by guessing a value for each value function, then iterating a simple process on each state until the values converge to the true values. Imagine we first store a temporary value of zero for the value of each state. Then, we update every state’s value using the Bellman Equation - that is, we consider the reward attached to all possible transitions away from a given state, and the values of future states. If we run this process around 100 times, the values keep updating and converge toward the actual state values!
Next, we’ll apply the Bellman equation to MDPs with actions.
And Now for MDPs With Actions
Let’s redefine the Value Function for MDPs with actions.
The difference is that we have a subscript on the function, the expectation, and the function. Every time we compute a value function, it must be with respect to a specific policy. I found it really helpful to compute part of this expectation to understand how the policy fits in. It is all too easy to nod along with mathematical definitions without understanding them deeply - here's a chance to check if you can use the definitions we've defined.
Notice you can split up the Value function into two separate expectations:
Notice that one of these expressions is recursive; it references the value of a future state. Let’s compute the first term of the definition, the non-recursive term. The computations are fundamentally similar, but the first term is actually computable because it doesn't infinitely recurse through states.
Notice that , the reward at time , depends on (the action chosen at time ) and (the random result of that action given by the transition probability function). Essentially, has a joint probability distribution over and .
Exercise: Let's define a policy called , which is just to travel to any of the available states with equal probability. Using this policy, compute , based on the diagram below.
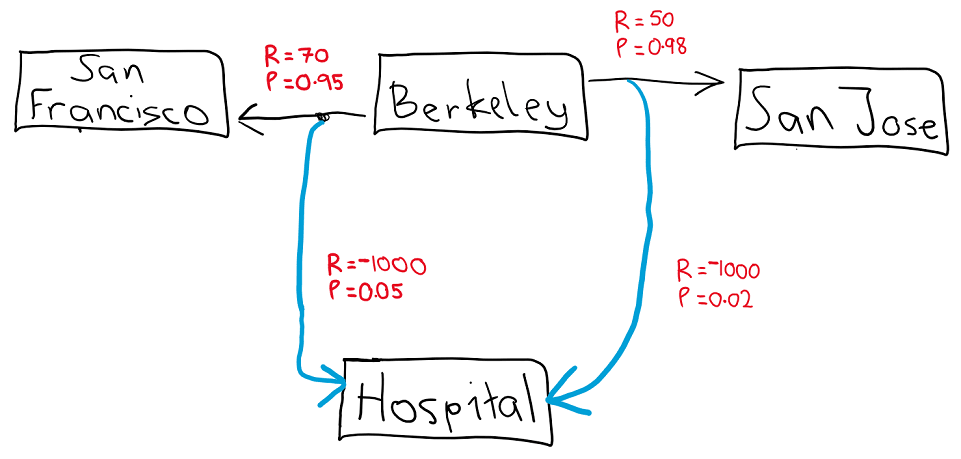
Answer:
Let's create the joint distribution based on and . Each column is a possible action that could suggest. And each row is a possible state the taxi driver could end up in after taking an action. So, each cell in the table represents the probability of taking action and ending up in a state for all possible states and actions.
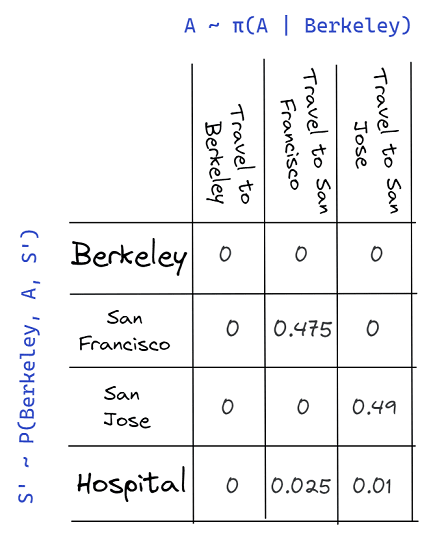
Notice that there are many 0 values on the joint distribution above; in general, there will probably be many 0 values on a joint distribution like this. Why so many 0 values? It's because plenty of actions do not make sense from a starting state. We didn't define an arrow from Berkeley to itself, so that action's probability must be 0. Furthermore, the probability transition function has many 0 values because most actions only have a limited set of outcome states.
Reading off the joint distribution, the expected reward at time t is given by:
From this example, we can see that the value function only makes sense with respect to a specific policy. If we switch the policy, each action has a different probability of being chosen, so we end up with a whole new joint distribution.
Next we’ll introduce Q-values.
Exercise: Convince yourself that this 4x3 grid format of a joint distribution can be used to describe any possible policy or any possible transition probability function on this MDP.
Exercise: Generalise this distribution to an arbitrary MDP. What should the rows be? What should the columns be?
Answer: For the rows, enumerate the set S of states. For the columns, enumerate the set A of actions.
Introducing… Q-values!
Define the Q-value function of an MDP to be:
The Q-function (also known as the action value function) tells us how good it is to take an action right now, given that we will follow a policy for all other timesteps. It’s very similar to the state value function - the ONLY difference is that we have a fixed current action as well as a fixed current state. We usually express this recursively a la the Bellman Equation:
The Q-value and state value functions are strongly interlinked. Exercise: express the state value function by summing over the Q-values of all actions.
Answer:
That’s basically all there is to Q-values. Computing a Q-value is roughly similar to computing a state value.
A Better Algorithm for Finding Optimal Policies
Here’s a more efficient algorithm for finding the optimal policy than the one described above.
- Compute for all state-action pairs for each policy in the set P
- Create a new “optimal Q-function” named , which takes as input a state-action pair and returns the maximal Q-value. That is, .
For example, we might find that the best Q-value from Berkeley to San Francisco is 500, using . And the best Q-value from Berkeley to San Jose is 400, using . In this case our optimal Q-value function is:
(Berkeley, Travel to San Francisco) = 500
(Berkeley, Travel to San Jose) = 400
- Create the optimal policy, , by choosing the action with the best $Q^*$ value.
In math, the optimal policy is:
When I first saw this formula, I was like: “Wait, what? The WHOLE POINT of a Q-value is that it assumes we will take actions using a consistent policy in the future. If we define without respect to a specific policy, and instead just choose the best actions among many different policies, isn't there a chance that future policies won't perform as well as expected?”
Think about it - how would you answer this question?
Firstly, suppose we have some action for some policy at an initial state . In other words, is the best action available from state under policy . Then, in general, it's possible that any future actions taken according to a different policy may lead to a lower reward than expected. For example, may suggest you go to Hell, -9999 reward, at a future timestep, instead of staying on Earth like would have suggested.
But when we’re specifically dealing with the optimal Q-function, , all your future decisions will be at least as good as . After all, your future decisions will also have the best Q-value out of all possible policies - it's literally impossible they could be worse decisions than would have suggested. In the Hell vs. Earth example from above, the optimal Q-function would not suggest going to Hell because it is not the optimal action to take - clearly staying on Earth is better.
So, the above algorithm is "more efficient" than the original algorithm in the sense that the optimal policy, $\pi ^*$ is better than or as good as every policy $\pi \in P$. Meanwhile, the original algorithm would output a policy from $P$.
Summary
Many scenarios involving agents can be modelled as an MDP using the 5-tuple (S, A, R, P, ).
There is a simple, linear notion of time measured using the number of actions the agent has taken.
A policy is a way to express actions as a probabilistic quantity.
An optimal policy is a way to compress knowledge of the entire MDP into a function which only takes states as input.
We can reduce the problem of finding the optimal policy to the problem of finding the optimal Q-function.
Takeaways From Writing This Post, and Next Steps
- I initially wrote the post because I was reading Agents Over Cartesian World Models [LW · GW] and noticed I didn't really understand what a POMDP was; so I figured this was the first step to understanding that better. Understanding MDPs has made it somewhat easier to understand Agents Over Cartesian World Models! However, my naïve guess at a research direction has changed.
I now think that the Agent-Like Structure Problem [LW · GW] is a more tractable path to finding necessary conditions on agents because it ties into the real world better. Such as solution would constrain the space of agents more than an abstract theory.
Another topic I am interested in is general-purpose search [LW · GW], since that seems like the core of intelligent agency which we are concerned about with AGI. If we could find general properties of a search algorithm like this, that seems more directly useful for alignment. Also, I should say that such research seems pretty risky to me with high capabilities externalities. If anybody is looking to do research like that, I would advise against posting it publicly. - This project took me approximately 20 hours of work to complete! That is a LOT of time for me. Most of it went towards typesetting the post and making pictures and tweaking the examples to make sense. Drafting the post and coming up with intuitive examples possibly took me 8 hours. In future, I probably will just publish things in an imperfect state.
- Most of the value of this post actually came from this comment on the takeaways and relevance to my next steps, which took about 1 hour to complete. In future, I want to get deeper into the agency literature without so much typesetting.
- It was helpful to rigorously understand policies. I noticed that when I was reading Goal Misgeneralisation in Deep Reinforcement Learning, and discussing confusions around inner and outer alignment [LW · GW], I was implicitly using a loose definition of a policy, something like "an algorithm an agent follows when deciding actions". Now I see that this is sorta right, but now I know that a policy is more of an incomplete "best guess" at the actions to take, developed over training. Also, I learnt that a policy strongly depends on whatever MDP we are working in. For a contrived example, an AI could not have a policy of self-modifying to become more intelligent if the MDP does not contain the action of self-modifying (In real life, I expect this to be untrue because the abstraction we use for "self-modifying" is leaky and does not prevent all self-modification attempts).
- I found it very helpful to actually compute part of the value function; it helped me understand how the policy and the transition function interacted together to produce a joint distribution over final states.
- Using a completely formal MDP, no actions in the environment can affect the agent's policy. It is just impossible using the type signatures of the functions on an MDP. This is like the "cartesian boundary" from MIRI's embedded agency [? · GW] work. In practice, this is not quite the same because the MDP is more of a loose model of the real world - and in the real-world, your brain is part of the environment [LW · GW].
- MDPs are not good at modelling changing environments. For example, if I pick a book up off the table at state S1, we would need to model this as a transition to a new state S2, which is just the same environment with no book. Imagine a larger environment with hundreds of items; the state space would be exponentially large. A more parsimonious model of an environment should have mutable contents with relationships between objects - probably some variant of a Pearl-style causal model.
- ^
Note that here the reward function looks slightly different from the reward function we defined slightly earlier. It no longer takes an action as an input, because the MDP doesn't have any actions. This is not an important detail; the main point of this definition is just to get a picture in your head of the value function.
3 comments
Comments sorted by top scores.
comment by arvganesh · 2023-02-16T20:07:22.263Z · LW(p) · GW(p)
The expectation of the reward calculation starting from Berkeley should be 22.75, I think the arithmetic is incorrect. Thanks!
Replies from: jack-o-brien↑ comment by Jack O'Brien (jack-o-brien) · 2023-06-23T08:39:52.814Z · LW(p) · GW(p)
Yep that's right, fixed :)
comment by Isabella Barber (isabella-barber) · 2022-12-27T20:22:25.517Z · LW(p) · GW(p)
Very intuitive! Great post