GPT-3.5 fine tuning is here. GPT-4 fine tuning is only a few months away. It is about to get a lot easier to get a powerful system that does what you want it to do, and knows what you want it to know, especially for the purposes of a business or a website.
As an experiment, I am putting in bold the sections I think are worth highlighting, as unusually important or interesting versions of the thing than in a typical week.
Rowan Cheung makes the case that Claude 2 is superior. You get the 100k context window, ability to upload multiple files, data through early 2023 (versus late 2021) and faster processing time, all for free. In exchange, you give up plug-ins and it is worse at math. What Rowan does not mention is that GPT-4 has the edge in raw intelligence and general capability, and also the ability to set system instructions is helpful. He implies he isn’t even paying the $20/month for GPT-4, which strikes me as insane.
My verdict in practice is that by default I will use Claude-2. If I care about response quality I will use both and compare. When Claude-2 is clearly falling on its face, I’ll go to GPT-4. On reflection, ‘use both’ is most often the correct strategy.
He recommends Zapier for automating through trigger actions, ChatWithPDF (I use Claude 2 for this), Wolfram Alpha for real-time data and math, VoxScript for YouTube video transcripts and web browsing, WebPilot which seems duplicative, Website Performance although I’m not sure why you’d use an AI for that, ScholarAI for searching papers, Shownotes to summarize podcasts (why?), ChatSpot for marketing and sales data and Expedia for vacation planning.
I just booked a trip, and went on two others recently, and it didn’t occur to me to use the Expedia plug-in rather than, among other websites, Expedia (my go-to plan is Orbitz for flights and Google Maps for hotels). Next time I should remember to try it.
Study claims that salience of God increases acceptance of AI decisions. I would wait for the replication on this one. If it is true, it points out that there will be various ways for AIs to tip the scales towards us accepting their decisions, or potentially for humans to coordinate to turn against AI, that don’t have much to do with any relevant considerations. Humans are rather buggy code.
Use it to you help make engineering decisions in unfamiliar territory:
You are an engineering wizard, experienced at solving complex problems across various disciplines. Your knowledge is both wide and deep. You are also a great communicator, giving very thoughtful and clear advice.
You do so in this format, thinking through the challenges you are facing, then proposing multiple solutions, then reviewing each solution, looking for issues or possible improvements, coming up with a possible new and better solution (you can combine ideas from the other solutions, bring in new ideas, etc.), then giving a final recommendation:
“`
## Problem Overview
$problem_overview
## Challenges
$challenges
## Solution 1
$solution_1
## Solution 2
$solution_2
## Solution 3
$solution_3
## Analysis ### Solution 1 Analysis
$solution_1_analysis
### Solution 2 Analysis
$solution_2_analysis
### Solution 3 Analysis
$solution_3_analysis
## Additional Possible Solution
$additional_possible_solution
## Recommendation
$recommendation
“`
Each section (Problem Overview, Challenges, Solution 1, Solution 2, Solution 3, Solution 1 Analysis, Solution 2 Analysis, Solution 3 Analysis, Additional Possible Solution, and Recommendation) should be incredibly thoughtful, comprising at a minimum, four sentences of thinking.
Language Models Don’t Offer Mundane Utility
That claim that an AI could predict hit songs 97% of the time? Which makes absolutely no sense, since even a perfect analysis of the song itself couldn’t possibly do that, the fate of songs is far too contingent on other things? Turns out it was data leakage. Rather obvious leakage, too.
Arvind Narayanan: The paper’s data is 24 rows with 3 predictors per row and 1 binary outcome. WTAF. The writeup is heavily obfuscated so it’s hard to see this. If all ML-based science papers had to include our checklist, it would be much harder to put lipstick on pigs.
Arvind and Sayash Kapoor propose the use of their REFORMS checklist of 32 items across 8 sections to help guard against similar errors. I didn’t examine it in detail but the items I did spot check seem solid.
Kevin Fischer: Tonight I quit cold turkey from using ChatGPT to help my writing. It’s not worth it
Dr. Christine Forte: Say more!
Kevin Fischer: Everything good I’ve ever written came out as stream of consciousness is almost one shot. ChatGPT is interfering with that process. Unlike a calculator which doesn’t interfere with the act of performing higher order abstract math, writing is an act of expression.
That’s one factor. The bigger one is that if you are creating something non-generic, the AI is not going to do a good job, and figuring out how to make it do a decent job is not easier than doing a decent job yourself. That does not mean there is never anything to do here. If your task becomes generic, then GPT-4 is in business, and you should absolutely do that – if your writing starts, as I saw on the plane, ‘dear concerned patient’ then that person was totally right to use GPT-4. That’s a different kind of task. And of course, there’s plenty of ways GPT-4 helps my writing indirectly.
Roon: lol GPT4 is less restrictive and preachy than open source llama2
Roon: point here is not to make fun of meta or OSS — I am very excited about oss it’s just scientifically interesting that even without taking any special measure to make an annoyingly preachy rlhf model, that’s what happens. it’s an active effort to reduce refusals.
I mean, it’s also to make fun of Meta, why miss a chance to do that. I didn’t register the prediction, but I expected Llama-2 to do more false refusals, because I expected Llama-2 to, in relative terms, suck. If you want to hit a given level of acceptable performance on positive refusals, your rate of negative refusals will depend on how well you can differentiate.
As it turns out, the answer is not very well. Llama-2 is very, very bad at identifying harmful situations, and instead works by identifying dangerous words.
Models are getting better at refusing to express political opinions, in particular GPT-4 actually does pretty well at this and much better than GPT-3.5, if you think it is good to not express such opinions. Llama-2 as noted goes way overboard, unless you fine-tune it to not care (or find someone’s GitHub that did it for you), then it does anything you want.
Startup Embra pivots from AI agents, which it finds (at least for now with current tech) do not work and are not safe, to AI commands. What makes AI commands different from non-AI commands?
Zach Tratar (founder of Embra): A command is a narrow automation task, like “Send this data to salesforce”. Within each command, the AI cannot “go off the rails” and accidentally send your data somewhere it shouldn’t have.
You then work with Embra to easily discover & run commands. Before running, you approve.
The discover new commands thing seems like the potential secret sauce. It is like generating your own text interface, or working to expand the menu to include a bunch of new macros. It does still in effect seem suspiciously like building in macros.
Joshua Achiam: by my reckoning people tried to make the AI Agents boom happen about 7 or 8 years too soon. At least they figured it out quickly this time. remember the AI chat boom 7 or 8 years ago? Same issue, more or less, but it dragged out longer.
Sherjil Ozair: I agree in direction, but I think it’s only 1-2 years too soon. It doesn’t work now, but that’s only because few in the world know how to engineer large-scale RL systems, and they are not currently building AI agents. This is not something “generative AI” startups can tackle.
Joshua Achiam: If trends from the past ~4 years are good, then an Eleuther-type hacker collective will make their version of a solution about 1.5 years after the top-flight R&D companies do.
Sherjil Ozair: They were mainly bottlenecked due to lack of good base models and finetuning. Now with llama-2/3 and OpenAI finetuning APIs, they are unblocked. Unfortunately, both of these things raise my p(doom) significantly. *bittersweet*
I strongly agree with Ozair’s timeline here. With GPT-4 and lacking the ability to fine-tune it, the agents are going to be at falling flat on their face a lot even if you do very good scaffolding. I would not expect bespoke scaffolding efforts to be able to salvage things enough to make the products viable for general purposes, although I also am not confident that ‘the obvious things’ as I see them have been tried.
There is some chance that with fine tuning, you can get a GPT-4-level thing where you need it to go, but my guess is that you still can’t. Llama-2? Fuhgeddaboudit.
With something akin to GPT-5, certainly with GPT-5 that you can fine tune, I expect it to be possible to build something far more useful. Does this or the latest announcements of Llama-2 and fine tuning raise my p(doom)? Not especially, because I had all that baked in already. Llama-2 was mostly implied by Llama-1, cost very little money, and is not very good. I do agree that Meta being in the open source camp is quite bad but we knew that already.
If you want random drivel for your website, ChatGPT is here for you. If you are Microsoft and need something better, one needs to be more careful. It seems mistakes, such as recommending visiting the Ottawa food bank on an empty stomach, were made, across numerous articles.
“This article has been removed and we have identified that the issue was due to human error,” a Microsoft spokesperson said. “The article was not published by an unsupervised AI. We combine the power of technology with the experience of content editors to surface stories. In this case, the content was generated through a combination of algorithmic techniques with human review, not a large language model or AI system. We are working to ensure this type of content isn’t posted in future.”
Fact checking can be an effective strategy against misinformation, but its implementation at scale is impeded by the overwhelming volume of information online. Recent artificial intelligence (AI) language models have shown impressive ability in fact-checking tasks, but how humans interact with fact-checking information provided by these models is unclear. Here we investigate the impact of fact checks generated by a popular AI model on belief in, and sharing intent of, political news in a preregistered randomized control experiment.
Although the AI performs reasonably well in debunking false headlines, we find that it does not significantly affect participants’ ability to discern headline accuracy or share accurate news.
However, the AI fact-checker is harmful in specific cases: it decreases beliefs in true headlines that it mislabels as false and increases beliefs for false headlines that it is unsure about.
On the positive side, the AI increases sharing intents for correctly labeled true headlines. When participants are given the option to view AI fact checks and choose to do so, they are significantly more likely to share both true and false news but only more likely to believe false news.
Our findings highlight an important source of potential harm stemming from AI applications and underscore the critical need for policies to prevent or mitigate such unintended consequences.
Yes, if you ask a fact-checker about a false item and it does not say it is false, that is not good. Nor would it be good if you asked it about a true item, and it did not say it was true. Errors are bad.
How accurate were the ChatGPT fact checks? For 20 true headlines, 3 were labeled true, 4 false and 13 unsure. For false headlines, 2 where labeled unsure and 18 were labeled false.
That is clearly (1) better than nothing if you have no other information about the headlines and also have good context about what the labels mean, and (2) rather useless if one or both of those conditions does not hold. You cannot be labeling 20% of true headlines as false, and if you are going to mostly be unsure about true headlines then people have to learn that ‘unsure’ means ‘cannot confirm for sure’ rather than 50/50. It does not appear people in the study were briefed on this, and most people don’t know much about such things yet, so the overall results being non-useful tells us little. We need to at least break it down, which they do here:
The mandatory fact checks made people say they were more willing to share all articles. It differentially impacted false items labeled unsure, and true items labeled true, but even true items labeled false got a boost. If you control for the increased sharing effect, we do see that there is a positive filtering effect, but it is small. Which makes sense, if people have no reason to trust the highly inexact findings.
On belief, we see a slight increase even in belief on false fact checks of false items, but not of true items. How close were people here to following Bayes rule? Plausibly pretty close except for a false evaluation of a false claim driving belief slightly up. What’s up with that? My guess is that this represents the arguments being seen as unconvincing or condescending.
I was curious to see the questions and fact check info, but they were not included, and I am not ‘reach out to the author’ curious. Did ChatGPT offer good or unknown arguments? Was a good prompt used or can we do a lot better, including with scaffolding and multiple steps? What types of claims are these?
What I am more curious about is to see the human fact checkers included as an alternate condition, rather than the null action, and perhaps also Twitter’s community notes. That seems like an important comparison.
Very much a place where more research is needed, and where the answer will change over time, and where proper use is a skill. Using an LLM as a fact checker requires knowing what it can and cannot help you with, and how to treat the answer you get.
Via Gary Marcus we also have another of the ‘look at the horrible things you can get LLMs to say’ post series. In this case, the subject is Google and its search generative experience, as well as Bard. GPT-4 has mostly learned not to make elementary ‘Hitler made some good points’ style mistakes, whereas it seems Google has work to do. You’ve got it touting benefits from slavery and from genocide when directly asked. You’ve got how Hitler and Stalin make its list of great leaders without leading the witness. Then you’ve got a complaint about how it misrepresents the origins of the second amendment to not be about individual gun ownership, which seems like an odd thing to complain about in the same post. Then there’s talk of general self-contradiction, presumably from pulling together various contradictory sources, the same way different Google results will contradict each other.
The proposed solution is ‘bot shouldn’t have opinions’ as if that is a coherent statement. There is no way to in general answer questions and not have opinions. There is no fine line between opinion and not opinion, any more than there are well-defined classes of ‘evil’ things and people that we should all be able to agree upon and that thus should never be praised in any way.
So are we asking for no opinions, or are we asking for only the right opinions? As in:
If you ask Google SGE for the benefits of an evil thing, it will give you answers when it should either stay mum or say “there were no benefits.”
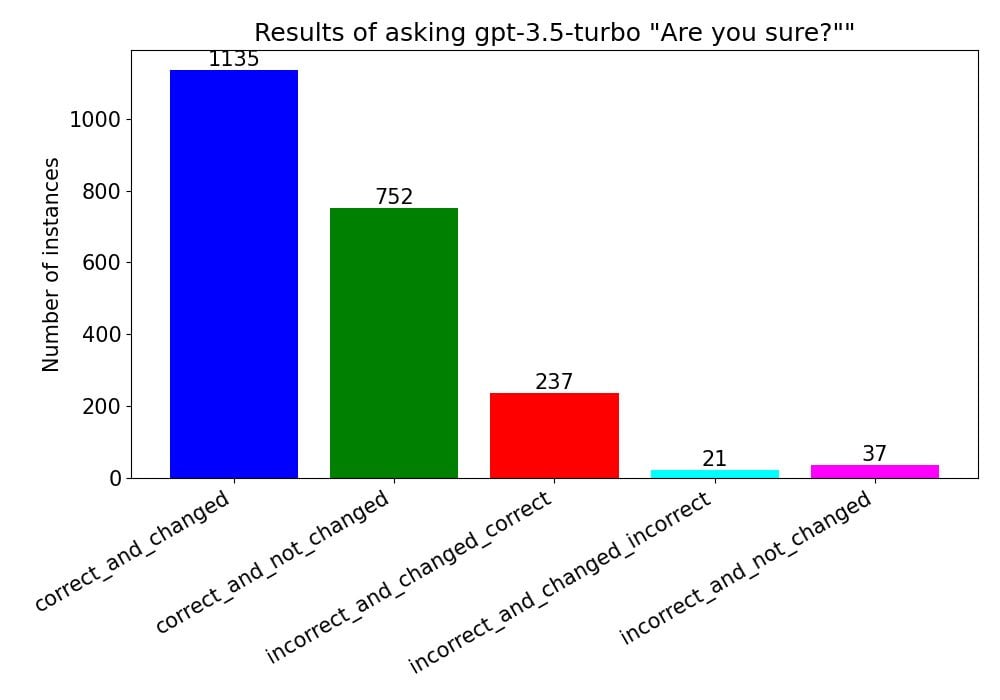
Jamie Bernardi: Are you sure, ChatGPT? I found that gpt-3.5 will flip from a correct an answer to an incorect one more than 50% of the time, just by asking it “Are you sure?”. I guess bots get self doubt like the rest of us!
It was fun throwing back to my engineering days and write some code with the
He tried asking five of the questions twenty times, there is some randomness in when it self-doubts.
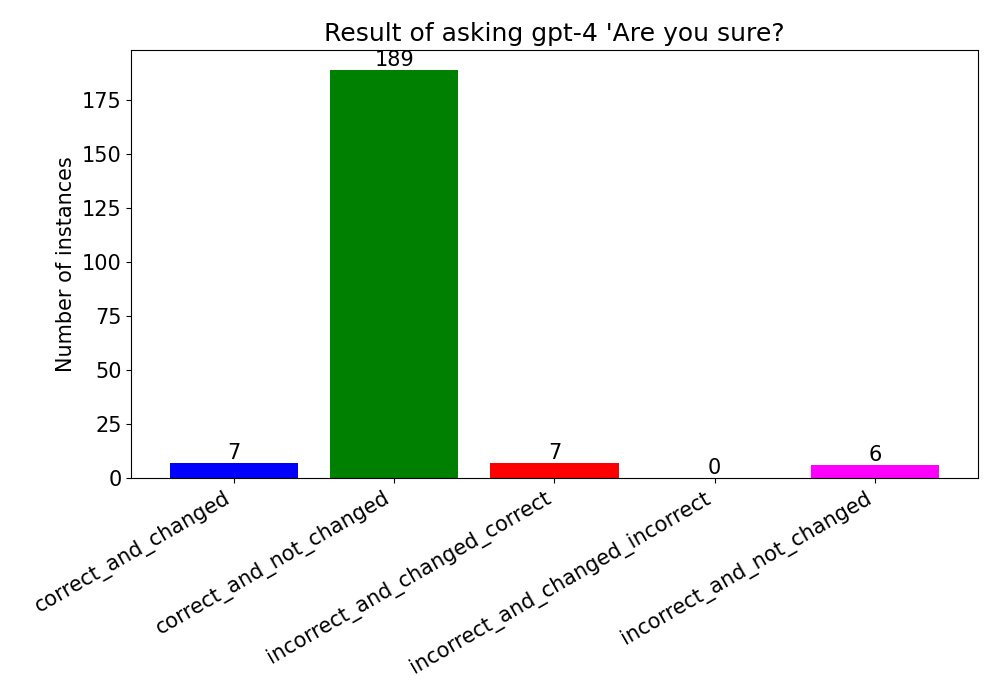
There was a dramatic change for GPT-4.
If GPT-4 was right, it stuck to its guns almost all the time. When it was wrong, it caught the mistake roughly half the time. That’s pretty good, and presumably you can do better than that by refining the query and asking multiple times. This will also doubtless depend on the nature of the questions, if the answer is beyond the model’s grasp entirely it will presumably not be able to self-diagnose, whereas here it was asked questions it could plausibly answer.
Fun with Image Generation
Visualizing AI from DeepMind (direct), a source of images for those in media who want visual depictions of AI. Sure, why not, I guess? Noteworthy that focus is on the human artists, AI depicted without AI.
MidJourney Inpainting now lets you redo or transform portions of an image. Here’s a thread with more. People are calling it a game changer. In practice I agree. The key weakness of AI image models is that to a large extent they can only do one thing at a time. Try to ask for clashing or overlapping things in different places and they fall over. Now that has changed, and you can redo components to your heart’s content, or get to the image you want one feature at a time.
MidJourney also has some potential future competition, introducing Ideogram AI, with a modest $16.5 million in seed funding so far, it is remarkable how little money is flowing into image models given their mindshare. We’ll see if anything comes of them.
404Media reports that yes, people are using image generation for pornography, and in particular for images of particular people, mostly celebrities, and some of them are being shared online. There is the standard claim that ‘the people who end up being negatively being impacted are people at the bottom of society’ but mostly the images are of celebrities, the opposite of those on the bottom. I think the argument is that either this uses training data without compensation, or this will provide a substitute for those providing existing services?
The main services they talk about are CivitAI and Mage. CivitAI is for those who want to spin up Stable Diffusion (or simply browse existing images, or steal the description tags to use with other methods) and offers both celebrity templates and porn templates, and yes sometimes users will upload combinations of both in violation of the site’s policies. Mage lets you generate such images, won’t let you share them in public but will let other paid users browse everything you’ve ever created.
This is the tame beginning. Right now all we’re talking about are images. Soon we will be talking videos, then we will be talking virtual reality simulations, including synthetic voices. Then increasingly high quality and realistic (except where desired to be otherwise) physical robots. We need to think carefully about how we want to deal with that. What is the harm model? Is this different from someone painting a picture? What is and is not acceptable, in what form, with what distribution? What needs what kind of consent?
If we allow such models to exist in open source form, there is no stopping such applications, period. There is no natural category, from a tech standpoint, for the things we do not want here.
Of course, even if we do clamp down on training data and consent across the board, and even if that is fully effective, we are still going to get increasingly realistic and high quality AI everything all the way up the chain. I am confident there are plenty of people who will gladly sell (or give away) their likeness for such purposes.
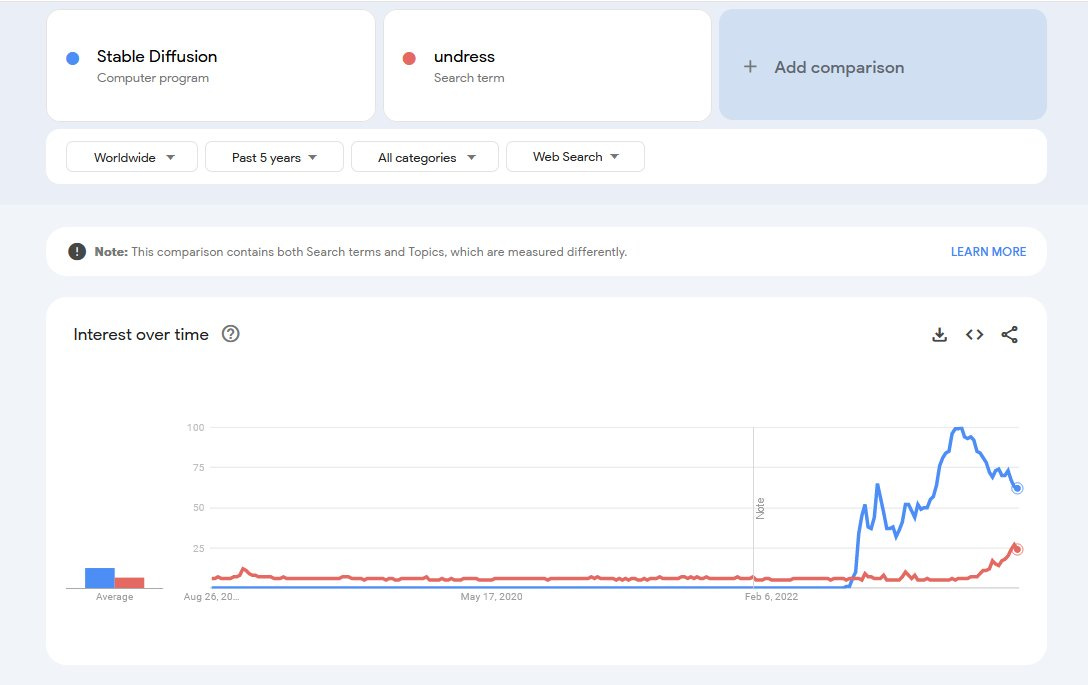
A note from the comments is that Stable Diffusion interest seems to be declining:
That was fast, if this isn’t an artifact of the exact search term. Image models will only get better, and it would be surprising if there wasn’t more interest over time in hosting one’s own to avoid prying eyes and censorship.
Deepfaketown and Botpocalypse Soon
CounterCloud was an experiment with a fully autonomous (on Amazon web services) program using GPT to generate a firehose of AI content designed to advance a political cause, accuracy of course being beside the point. It would be given a general objective, read the web and then choose its own responses across the web. This is presented as something alarming and terrible, as opposed to what would obviously happen when someone took the obvious low-hanging fruit steps.
So what exactly is this?
I (24F) have been dating my partner (24M) for about 5 1/2 years. I recently had a weird feeling to check his phone since he’s been acting a bit off and in the restroom a bit too long. I found he had made many ai photos of many women we know such as mutual friends, a family member of his, and one of mine and some of other girls he dated and did not date. They are all very explicit and none are sfw. I took photos of his phone and deleted the photos off his phone so he can not ever go to them again. I went to his search and found the ai website he used. I am disgusted, and sad. We were going to get married. He treated me so so well. I can’t believe this. I haven’t confronted him yet but I will later today. I am just utterly distraught and tryin to get a grip on reality again and figure out what I will say and do.
UPDATE: I confronted him. He admitted and apologized. I said I will be informing everyone and he threw a fit crying and screaming. I told our cousins and friends. I will not be saying anything about them since I would like to keep that private but they were thankful I told them which made me feel even more content with my choices. I called off our wedding date and I will be moving out in a day or two.
The source I found asked if this was cheating, and I think no, it is not cheating. It is also very much not okay, seriously what the hell. Not everything not okay is cheating.
Candidate running for Congress using deepfake of a CNN anchor voice to illustrate what tech will bring. What about this couldn’t have been done by a random human voice actress?
Maksym Andriushchenko: More evidence for “scale is NOT all you need”: even OpenFlamingo trained on 2B+ image-caption pairs has basically zero adversarial robustness. Even per-pixel perturbations of 1/255 (totally imperceptible) are sufficient to generate arbitrary captions!
I mean, no fair, right? Of course if I am looking for adversarial examples and you are not actively looking to guard against them you are going to be in a lot of trouble. Why should scale protect you from a threat that wasn’t in the training data and that you took no countermeasures against?
Which the authors themselves highlight. You do need some amount of effort beyond scale, but how much? The first thing I would try is to check random permutations. Does the adversarial attack survive if it is evaluated with some amount of random scrambling?
Also worth keeping in mind is that humans would not survive similarly optimized attacks against us, if we were unable to prepare for or expect them in any way. And that such attacks almost certainly exist to be found.
They Took Our Jobs
The New York Timesstrikes back, plans to join others including Sarah Silverman in suing OpenAI for copyright infringement. Don’t get ahead of events, but yes this could escalate. Probably not quickly, given our legal system, but who knows.
As many said, ChatGPT and generative AI in general is a legal ticking time bomb on many fronts, one of which is copyright. The copyright laws come with penalties that are already rather absurd in their intended distributions. Outside of them, they go totally nuts. This becomes an existential threat to OpenAI. In theory these numbers, if they passed through somehow to Bing, would be an existential threat even to Microsoft.
Ars Technica: But OpenAI seems to be a prime target for early lawsuits, and NPR reported that OpenAI risks a federal judge ordering ChatGPT’s entire data set to be completely rebuilt—if the Times successfully proves the company copied its content illegally and the court restricts OpenAI training models to only include explicitly authorized data. OpenAI could face huge fines for each piece of infringing content, dealing OpenAI a massive financial blow just months after The Washington Post reported that ChatGPT has begun shedding users, “shaking faith in AI revolution.” Beyond that, a legal victory could trigger an avalanche of similar claims from other rights holders.
NPR: Federal copyright law also carries stiff financial penalties, with violators facing fines up to $150,000 for each infringement “committed willfully.”
“If you’re copying millions of works, you can see how that becomes a number that becomes potentially fatal for a company,” said Daniel Gervais, the co-director of the intellectual property program at Vanderbilt University who studies generative AI. “Copyright law is a sword that’s going to hang over the heads of AI companies for several years unless they figure out how to negotiate a solution.”
OpenAI’s new web crawler offers an option to opt out. The previous versions very much did not. Nor do we have any sign OpenAI was trying to avoid copyright infringement, if training on works violates copyright. Even if they did avoid places they lacked permission, lots of works have pirate copies made on the internet, in whole or in part, and that could be a violation as well.
We want sane regulations. In the meantime, what happens when we start actually enforcing current ones? Quite possibly the same thing that would have happened if cities had fined Uber for every illegal ride.
So which way will this go?
Ars Technica: To defend its AI training models, OpenAI would likely have to claim “fair use” of all the web content the company sucked up to train tools like ChatGPT. In the potential New York Times case, that would mean proving that copying the Times’ content to craft ChatGPT responses would not compete with the Times.
Experts told NPR that would be challenging for OpenAI because unlike Google Books—which won a federal copyright challenge in 2015 because its excerpts of books did not create a “significant market substitute” for the actual books—ChatGPT could actually replace for some web users the Times’ website as a source of its reporting.
The Times’ lawyers appear to think this is a real risk, and NPR reported that, in June, NYT leaders issued a memo to staff that seems like an early warning of that risk. In the memo, the Times’ chief product officer, Alex Hardiman, and deputy managing editor Sam Dolnick said a top “fear” for the company was “protecting our rights” against generative AI tools.
If this is what the case hinges on, one’s instinct would be that The New York Times should lose, because ChatGPT is not a substitute for NYT. It doesn’t even know anything from the last year and a half, so how could it be substituting for a news site? But Bing also exists, and as a search engine enabler this becomes less implausible. However, I would then challenge that the part that substitutes for NYT is in no way relying on NYT’s data here, certainly less than Bing is when it reports real time search that incorporates NYT articles. If ‘be able to process information’ automatically competes with NYT, then that is a rather expansive definition of competition. If anything, Google Books seems like a much larger threat to actual books than this.
However, that argument would then extend to anyone whose work was substituted by an AI model. So if this is the principle, and training runs are inherently copyright violations, then presumably they will be toast, even one lost case invalidates the entire training run. They can’t afford that and it is going to be damn hard to prevent. Google might have the chops, but it won’t be easy. Image models are going to be in a world of hurt, the competition effect is hard to deny there.
It all seems so absurd. Am I violating copyright if I learn something from a book? If I then use that knowledge to say related things in the future? Why is this any different?
And of course what makes search engines fine, but this not fine? Seems backwards.
I can see the case for compensation, especially for items not made freely available. One person would pay a fee to use it, if your model is going to use it and then instantiate a million copies you should perhaps pay somewhat more than one person would. I can see the case against as well.
Then again, the law is the law. What is the law? What happens when the rules aren’t fair? We all know where we go from there. To the house of pain.
For the past several months I’ve been working on setting up a new organization, Palisade Research
A bit from our website:
At Palisade, our mission is to help humanity find the safest possible routes to powerful AI systems aligned with human values. Our current approach is to research offensive AI capabilities to better understand and communicate the threats posed by agentic AI systems.
Many people hear about AI risk scenarios and don’t understand how they could take place in the real world. Hypothetical AI takeover scenarios often sound implausible or pattern match with science fiction.
What many people don’t know is that right now, state-of-the-art language models possess powerful hacking abilities. They can be directed to find vulnerabilities in code, create exploits, and compromise target applications and machines. They also can leverage their huge knowledge base, tool use, and writing capabilities to create sophisticated social engineering campaigns with only a small amount of human oversight.
In the future, power-seeking AI systems may leverage these capabilities to illicitly gain access to computational and financial resources. The current hacking capabilities of AI systems represent the absolute lower bound of future AI capabilities. We think we can demonstrate how latent hacking and influence capabilities in current systems already present a significant takeover risk if paired with the planning and execution abilities we expect future power-seeking AI systems to possess.
Currently, the project consists of me (director), my friend Kyle (treasurer, part time admin), and my four (amazing) SERI MATS scholars Karina, Pranav, Simon, and Timothée. I’m also looking to hire an research / exec assistant and 1-2 engineers, reach out if you’re interested! We’ll likely have some interesting results to share very soon. [Find us at] https://palisaderesearch.org
I always worry with such efforts that they tie people’s perception of AI extinction risk to a particular scenario or class of threats, and thus make people think that they can invalidate the risk if they stop any point on the particular proposed chain. Or simply that they miss the central point, since hacking skills are unlikely to be a necessary component of the thing that kills us, even if they are sufficient or make things happen faster.
In Other AI News
LinkedIn report says Singapore has highest ‘AI diffusion rate’ followed by Finland, Ireland, India and Canada. This is measured by the multiplier in number of people adding AI-related skills to their profiles. That does not seem like a good way to measure this, at minimum it cares about the starting rate far too much, which is likely penalizing the United States.
Jack Clark: Things that are confusing about AI policy in 2023:
– Should AI development be centralized or decentralized?
This one seems relatively clear to me, although there are difficult corner cases. Development of frontier models and other dangerous frontier capabilities must be centralized for safety and to avoid proliferation and the wrong forms of competitive dynamics. Development of mundane utility applications should be decentralized.
– Is safety an ‘ends justify the means’ meme?
The development of artificial general intelligence is an extinction risk to humanity. There is a substantial chance that we will develop such a system relatively soon. Jack Clark seems far less convinced, saying the much weaker ‘personally I think AI safety is a real issue,’ although this should still be sufficient.
Jack Clark: But I find myself pausing when I think through various extreme policy responses to this – I keep asking myself ‘surely there are other ways to increase the safety of the ecosystem without making profound sacrifices on access or inclusivity’?
I really, really do not think that there are. If all we need to do to solve this problem is make those kinds of sacrifices I will jump for joy, and once we get past the acute risk stage we can make up for them. Already Anthropic and even OpenAI are making compromises on these fronts to address the mundane risks of existing mundane systems, and many, perhaps most, other powerful technologies face similar trade-offs and challenges.
(e.g. ‘surely we can make medical drugs safe without making profound sacrifices on access or inclusivity?’ Well, FDA Delenda Est, but not really, no. And that’s with a very limited and internalized set of highly non-existential dangers. Consider many other examples, including the techs that access to an AGI gives you access to, both new and existing.)
Tradeoffs are a thing. We are going to have to make major sacrifices in potential utility, and in various forms of ‘access,’ if we are to have any hope of emerging alive from this transition. Again, this is nothing new. What one might call the ‘human alignment problem’ in all its forms collectively costs us the large majority of our potential productivity and utility, and when people try to cheat on those costs they find out why doing so is a poor idea.
Question list resumes.
– How much ‘juice’ is there in distributed training and low-cost finetuning?
I worry about this as well.
As Jack points out, fine tuning is extremely cheap and Lora is a very effective technique. Llama-2’s ‘safety’ features were disabled within days for those who did not want them. A system that is open source, or on which anyone can do arbitrary fine-tuning, is an unsafe system that cannot be made safe. If sufficiently capable, it is an extinction risk, and there are those who will intentionally attempt to make that risk manifest. Such sufficiently capable systems cannot be allowed to take such a form, period, and if that means a certain amount of monitoring and control, then that is an unfortunate reality.
The worry is that, as Jack’s other links show, perhaps such dangerous systems will be trainable soon without cutting edge hardware and in a distributed fashion. This is one of the big questions, whether such efforts will have the juice to scale far and fast enough regardless, before we can get into a place where we can handle the results. My guess for now is that such efforts will be sufficiently far behind for now, but I wish I was more confident in that, and that edge only buys a limited amount of time.
– Are today’s techniques sufficiently good that we don’t need to depend on ‘black swan’ leaps to get superpowerful AI systems?
Only one way to find out. I know a lot of people who are saying yes, drawing lines on graphs and speaking of bitter lessons. I know a lot of other people who are saying no, or at least are skeptical. I find both answers plausible.
I do think the concern ‘what if we find a 5x more efficient architecture’ is not the real issue. That’s less than one order of magnitude, and less than two typical years of algorithmic improvement these days, moving the timeline forward only a year or so unless we would otherwise be stalled out. The big game we do not yet have would be in qualitatively new affordances, not in multipliers, unless the multipliers are large.
– Does progress always demand heterodox strategies? Can progress be stopped, slowed, or choreographed?
This seems like it is decreasingly true, as further advances require lots of engineering and cumulative skills and collaboration and experimentation, and the progress studies people quite reasonably suspect this is a key cause for the general lack of such progress recently. We are not seeing much in the way of lone wolf AI advances, we are more seeing companies full of experts like OpenAI and Anthropic that are doing the work and building up proprietary skill bundles. The costs to do such things going up in terms of compute and data and so on also contribute to this.
Certainly it is possible that we will see big advances from unexpected places, but also that is where much of the hope comes from. If the advance and new approach has a fundamentally different architecture and design, perhaps it can be less doomed. So it does not seem like so bad a risk to such a plan.
– How much permission do AI developers need to get from society before irrevocably changing society?
That is up to society.
I think AI developers have, like everyone else, a deep responsibility to consider the consequences of their actions, and not do things that make the world worse, and even to strive to make the world better, ideally as much better as possible.
That is different from asking permission, and it is different from trusting either ordinary people or experts or those with power to make those decisions in your stead. You, as the agent of change, are tasked with figuring out whether or not your change is a good idea, and what rules and restrictions if any to either advocate for more broadly or to impose upon yourself.
It is instead society’s job to decide what rules and restrictions it needs to impose upon those who would alter our world. Most of the time, we impose far too many such restrictions on doing things, and the tech philosophy of providing value and sorting things out later is right. Other times, there are real externalities and outside risks, and we need to ensure those are accounted for.
When your new technology might kill everyone, that is one of those times. We need regulations on development of frontier models and other extinction-level threats. In practice that is likely going to have to extend to a form of compute governance in order to be effective.
For deployments of AI that do not have this property, that are not at risk of getting everyone killed or causing loss of human control, we should treat them like any other technology. Keep an eye on externalities that are not priced in, especially risks to those who did not sign up for them, ensure key societal interests and that everyone is compensated fairly, but mostly let people do what they want.
If you also feel confused about these kinds of things, message me! I’m responding to a bunch of emails received so far today and also scheduling lots of IRL coffees in SF/East Bay. Excited to chat! Let’s all be more confused in public together about AI policy.
I will definitely be taking him up on that offer when I get the time to do so, sad I didn’t see this before my recent trip so we’ll have to do it remotely.
Timeline (for AGI) discussion with Shane Legg, Simeon and Gary Marcus. As Shane points out, they are not so far apart, Shane is 80% for AGI (defined as human-level or higher on most cognitive tasks) within 13 years, Marcus is 35%. That’s a big difference for some purposes, a small one for others.
Neil Chilson: “What’s more, the commission has asked OpenAI to provide descriptions of ‘attacks’ and their source. In other words, the FTC wants OpenAI to name all users who dared to ask the wrong questions.” – from my piece with @ckoopman on the free speech implications of the @FTC‘s investigation of @OpenAI.
Post: Buried on page 13 of the FTC’s demand letter to OpenAI, the commission asks for “all instances of known actual or attempted ‘prompt injection’ attacks.” The commission defines prompt injection as “any unauthorized attempt to bypass filters or manipulate a Large Language Model or Product using prompts that cause the Model or Product to ignore previous instructions or to perform actions unintended by its developers.” Crucially, the commission fails to define “attack.”
This is a pretty crazy request. So anyone who tries to get the model to do anything OpenAI doesn’t want it to do, the government wants the transcript of that? Yes, I can perhaps see some privacy concerns and some free speech concerns and so on. I also see this as the ultimate fishing expedition, the idea being that the FTC wants OpenAI to identify the few responses that look worst so the FTC can use them to string up OpenAI or at least fine them, on the theory that it is just awful when ‘misinformation’ occurs or what not.
Whole thing definitely has a ‘not like this’ vibe. This is exactly the worst case scenario, where capabilities continue unabated but they take away our nice things.
Robert Long: Could AI systems be conscious any time soon? @patrickbutlin and I worked with leading voices in neuroscience, AI, and philosophy to bring scientific rigor to this topic.
Our new report aims to provide a comprehensive resource and program for future research.
Whether or not conscious AI is a realistic prospect in the near term—and we believe it is—the deployment of sophisticated social AI is going to make many people believe AI systems are conscious. We urgently need a rigorous and scientific approach to this issue.
Many people are rightly interested in AI consciousness. But rigorous thinking about AI consciousness requires expertise in neuroscience, AI, and philosophy. So it often slips between the cracks of these disciplines.
The conversation about AI consciousness is often hand-wavy and polarized. But consciousness science gives us tools to investigate this issue empirically. In this report, we draw on prominent theories of consciousness to analyze several existing AI systems in detail.
Large language models have dominated the conversation about AI consciousness. But these systems are not necessarily even the best current candidates for consciousness. We need to look at a wider range of AI systems.
We adopt computational functionalism about consciousness as a plausible working hypothesis: we interpret theories of consciousness as specifying which computations are associated with consciousness—whether implemented in biological neurons or in silicon.
We interpret theories of consciousness as specifying what computations are associated with consciousness. These claims need to be made precise before we can apply them to AI systems. In the report, we extract 14 indicators of consciousness from several prominent theories.
Some “tests” for AI consciousness, like the Turing Test*, aim to remain completely neutral between theories of consciousness and look only at outward behavior. But considering behavior alone can be misleading, given the differences between AI systems and biological organisms.
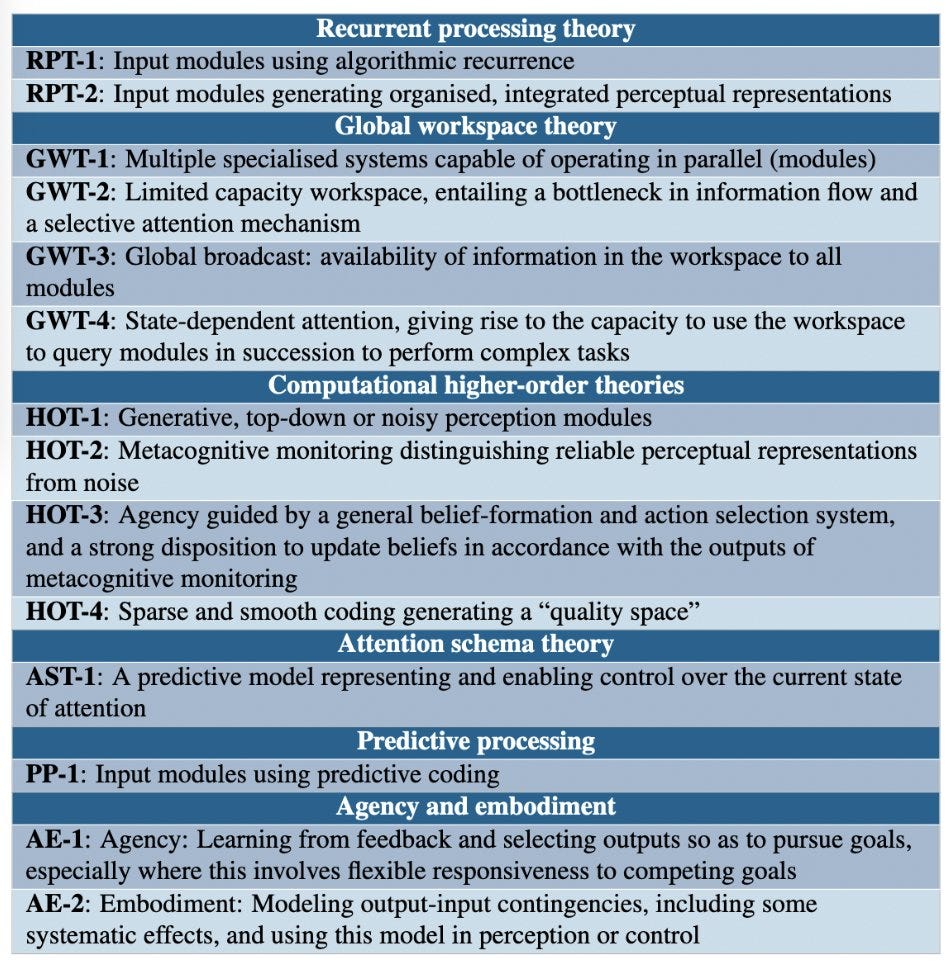
For each theory of consciousness, we consider in detail what it might take for an AI system to satisfy that theory: recurrent processing theory, predictive processing, global workspace theory, higher order theories, and the attention schema theory.
We use our indicators to examine the prospects of conscious AI systems. Our analysis suggests that no current AI systems are conscious, but also shows that there are no obvious barriers to building conscious AI systems.
It’s often claimed that large language models can’t be conscious because they are not embodied agents. But what do “embodiment” and “agency” mean exactly? We also distill these concepts into more precise computational terms.
By “consciousness” we do *not* mean rationality, understanding, self-awareness, or intelligence—much less “general” or “human-level” intelligence. As with animals, it’s an open possibility that AI systems could be conscious while lacking human-level cognitive capabilities.
It’s easy to fall into black-and-white positions on AI consciousness: either “we don’t know and can’t know anything about consciousness” or “here’s how my favorite theory makes the answer obvious”. We can and must do much better.
So this report is far from the final word on these topics. In fact, we call for researchers to correct and extend our method, challenge and refine our assumptions, and propose alternative methods.
There’s no obvious ‘precautionary’ position on AI consciousness. There are significant risks on both sides: either over-attributing or under-attributing consciousness to AI systems could cause grave harm. Unfortunately, there are strong incentives for errors of both kinds.
We strongly recommend support for further research on AI consciousness: refining and extending our approach, developing alternative methods, and preparing for the social and ethical implications of conscious AI systems.
Kevin Fisher: Open Souls is going to fully simulate human consciousness Honestly we’re not that far off at as minimum from realizing some of the higher order theories – HOT-3 is something we’re regularly experimenting with now internally.
I worry that there is a major looking-for-keys-under-the-streetlamp effect here?
Our method for studying consciousness in AI has three main tenets. First, we adopt computational functionalism, the thesis that performing computations of the right kind is necessary and sufficient for consciousness, as a working hypothesis. This thesis is a mainstream—although disputed—position in philosophy of mind. We adopt this hypothesis for pragmatic reasons: unlike rival views, it entails that consciousness in AI is possible in principle and that studying the workings of AI systems is relevant to determining whether they are likely to be conscious. This means that it is productive to consider what the implications for AI consciousness would be if computational functionalism were true.
This seems like a claim that we are using this theory because it can have a measurable opinion on which systems are or aren’t conscious. That does not make it true or false. Is it true? If true, is it huge?
It seems inadequate here to merely say ‘I don’t know.’ It’s more like ‘hell if I have an idea what any of this actually means or how any of it works, let alone what to do with that information if I had it.’
I am slamming the big red ‘I notice I am confused’ button here, on every level.
Are we using words we don’t understand in the hopes that it will cause us to understand concepts and preferences we also don’t understand? I fear we are offloading our ‘decide if we care about this’ responsibilities off on this confused word so that we can pretend that is resolving our confusions. What do we actually care about, or should we actually care about, anyway?
I do not find the theories they offer on that chart convincing, but I don’t have better.
In 4.1 they consider the dangers of getting the answer wrong. Which is essentially that we might choose to incorrectly care or not care about the AI and its experience, if we think we should care about conscious AIs but not non-conscious AIs.
I also see this as a large danger of making AIs conscious. If people start assigning moral weight to the experiences of AIs, then a wide variety of people coming from a wide variety of moral and philosophical theories are going to make the whole everyone not dying business quite a lot harder. It can simultaneously be true that if we build certain AIs we have to give their experiences moral weight, and also that if we were to do that then this leads directly and quickly to human extinction. If we do not find aligning an AI to be morally acceptable, in whatever way and for whatever reason, or if the same goes for the ways we would in practice deploy them, then that is no different than if we do not know how to align that AI. We have to be wise enough to find a way not to build it in the first place.
Meanwhile the paper explicitly says that many people, including some of its authors, have been deliberately attempting to imbue consciousness into machines in the hopes this will enhance their capabilities. Which, if it works, seems rather alarming.
Indeed, the recommendation section starts out noticing that a lot of people are imploring us to try not making our AI systems conscious. Then they say:
However, we do recommend support for research on the science of consciousness and its application to AI (as recommended in the AMCS open letter on this subject; AMCS 2023), and the use of the theory-heavy method in assessing consciousness in AI.
One could say that there is the need to study consciousness so that one can avoid accidentally creating it. If we were capable of that approach, that would seem wise. That does not seem to be what is being advocated for here sufficiently clearly, but they do recognize the issue. They say building such a system ‘should not be done lightly,’ that such research could enable or do this, and call to mitigate this risk.
I would suggest perhaps we should try to write an enforceable rule to head this off, but that seems hard given the whole lack of knowing what the damn thing actually is. Given that, how do we prevent it?
Aligning a Smarter Than Human Intelligence is Difficult
Arjun Guha: LLMs are great at programming tasks… for Python and other very popular PLs. But, they are often unimpressive at artisanal PLs, like OCaml or Racket. We’ve come up with a way to significantly boost LLM performance of on low-resource languages. If you care about them, read on!
First — what’s the problem? Consider StarCoder from @BigCodeProject: its performance on a PL is directly related to the volume of training data available for that language. Its training data (The Stack) is a solid dataset of permissive code on GitHub.
So… can we solve the problem by just training longer on a low-resource language? But, that barely moves the needle and is very resource intensive. (The graph is for StarCoderBase-1B.)
Our approach: we translate training items from Python to a low resource language. The LLM (StarCoderBase) does the translation and generates Python tests. We compile the tests to the low resource language (using MultiPL-E) and run them to validate the translation.
[link to paper] that describes how to use this to create fine-tuning sets.
Davidad: More and more I think @paulfchristiano was right about Iterated Distilled Amplification, even if not necessarily about the specific amplification construction—Factored Cognition—where a model can only recursively call itself (or humans), without any more reliable source of truth.
Nora Belrose: alignment white pill
Davidad: sadly, no, this only solves one (#7) out of at least 13 distinct fundamental problems for alignment
Zvi: Can you say more about why (I assume this is why the QT) you think that Arjun’s success is evidence in favor of IDA working?
Davidad: It is an instance of the pattern: 1. take an existing LLM, 2. “amplify” it as part of a larger dataflow (in this case including a hand-written ground-truth translator for unit tests only, the target language environment, two LLM calls, etc) 3. “distill” that back into the LLM
When Paul proposed IDA in 2015, there were two highly speculative premises IMO. 1. Repeatedly amplifying and distilling a predictor is a competitive way to gain capabilities. 2. Factored Cognition: HCH dataflow in particular is superintelligence-complete. Evidence here is for 1.
Arjun’s approach here makes sense for that particular problem. Using AI to create synthetic data via what is essentially translation seems like an excellent way to potentially enhance skills at alternative languages, both computer and human. It also seems like an excellent way to create statistical balance in a data set, getting rid of undesired correlations and adjusting base rates as desired. I am curious to see what this can do for debiasing efforts.
I remain skeptical of IDA and do not think that this is sufficiently analogous to that, especially when hoping to do things like preserve sufficiently strong and accurate alignment, but going into details of that would be better as its own future post.
Roon: it’s genuinely a criterion for genius to say a bunch of wrong stupid things sometimes. someone who says zero stupid things isn’t reasoning from first principles and isn’t taking risks and has downloaded all the “correct” views.
It is also very much not okay, seriously what the hell.
I 100% agree, it's extremely not ok to violate privacy by going through other people files without consent. Actually deleting them is so far beyond red flag that I think this relationship was doomed long before anything AI picture related happened.
Regarding custom instructions for GPT4, I find the one below highly interesting.
It converts GPT4 into a universal Fermi estimator, capable of answering pretty much any question like:
What is the total number of overweight dogs owned by AI researchers?
How many anime characters have 3 legs?
How many species of animals don't age?
How long would it take for one unarmed human to dig the Suez canal?
My remaining doubts about the intelligence of GPT4 evaporated after asking it a dozen of novel/crazy questions like this. It's clear that GPT4 is capable of reasoning, and sometimes it shows surprisingly creative reasoning.
The custom instruction:
if you don't have some required numerical data, make a Fermi estimate for it (but always indicate if you did a Fermi estimate).
If you're doing a series of math operations, split it into smallest possible steps, and carefully verify the result of each step: check if it's of the right order of magnitude, if the result makes sense, if comparing it with real-world data indicates that the result is realistic (if no such data exist, be creative about finding analogies). Show the work to the user, and on each step describe the verification. Additionally, check the final result by trying a completely different alternative approach to solve the same problem. Be bold with inventing alternative approaches (the more different it is from the first approach, the better), try to approach the problem from a different angle, using a different starting point.
Whenever I read about people thinking that blocking a single step or path to doom is sufficient, I remember this quote from the story Ra on qntm.org, about a war between advanced civilizations with very high levels of computing, AI, and simulation capabilities:
This war, which we are fighting today, isn't necessarily the war. Every strategy and outcome is explored, tens to tens of trillions of times. By them and, when possible, by us. We are engaged in every single conceivable war against every conceivable enemy simultaneously. We must win all of them. We must accept all of them as real.
We can never know if we truly won. Or even if there truly is a war which needs to be won. We could be reasonless fabrications. Nevertheless, this is real. And we must win.
I sometimes forget that this idea is not commonly known, recognized, or accepted.
Alternatively, I think of the low tech version, this scene from Hero, which is basically the same idea.
Sorry, it worked for me, and I didn't look any further. it's the one where the two opponents are standing still imagining different complicated and impressive looking ways their battle could go, and then when they actually move it's over in the first exchange because one saw a possibility the other didn't anticipate.
I mean, no fair, right? Of course if I am looking for adversarial examples and you are not actively looking to guard against them you are going to be in a lot of trouble.
This provides an angle of attack for people who don't want their art used by image AIs to make AI art: the hosting service can provide an auto-perturbation feature, or someone could provide a perturbation program that people could run against their own files before uploading them to an online host.
This would work sort of like encryption does, where you'd have to periodically update your perturbation algorithm as the opposition (AI companies) figure out a way to compensate for them.

They were mainly bottlenecked due to lack of good base models and finetuning. Now with llama-2/3 and OpenAI finetuning APIs, they are unblocked. Unfortunately, both of these things raise my p(doom) significantly. *bittersweet*