Deep Q-Networks Explained
post by Jay Bailey · 2022-09-13T12:01:08.033Z · LW · GW · 8 commentsContents
Supervised Learning With Neural Networks (Section 1) Reinforcement Learning (Section 2) DQN Overview (Section 3) DQN Technical Explanation (Section 4) Replicating DQN (Section 5) DQN Algorithm Neural Network Hyperparameters Atari Environment Further Improvements (Section 6) None 8 comments
Note: This is a long post. The post is structured in such a way that not everyone needs to read everything - Sections 1 and 2 are skippable background information, and Sections 4 and 5 go into technical detail that not everybody wants or needs to know. Section 3 on its own is sufficient to gain a high-level understanding of DQN if you already know how reinforcement learning works.
This post was made as my final project for the AGI Safety Fundamentals course.
This post aims to provide a distillation [? · GW] of Deep Q-Networks, neural networks trained via Deep Q-Learning. The algorithm, usually just referred to as DQN, is the algorithm that first put deep reinforcement learning on the map. The 2013 paper is also the first paper in the Key Papers section of the excellent Spinning Up In Deep RL resource. As a result, anyone who wants to understand reinforcement learning is likely to start here. Since reading and replicating papers can be difficult, this resource aims to make the learning curve a little easier for those who want to improve their ML knowledge past an initial deep learning course.
This post will be focused mainly on the 2015 paper, which adds some extra improvements to the 2013 paper, as well as giving more information that’s helpful for replication. This is a long post, but it’s broken up into sections so that you can only read the sections you’re interested in. It starts with background information, then goes over DQN at three levels of detail, each of which builds off the previous one.
You should probably have a basic understanding of supervised learning in order to get the most out of this post. You should understand what a loss function is, what gradient descent is conceptually, and be familiar with the concept of a neural network.
Supervised Learning With Neural Networks (Section 1) - Background information on deep learning. This can be safely skipped if you already understand how supervised learning problems like image classifiers work.
Reinforcement Learning (Section 2) - Background information on RL. This can be safely skipped if you’re already familiar with the basics of reinforcement learning, like states, actions, and why reinforcement learning is harder than supervised learning.
DQN Overview (Section 3) - This section presents DQN at a high level, without the math. I recommend everyone read this section. You can stop there, or continue on to Section 4 if you want to understand the math behind it.
DQN Technical Explanation (Section 4) - This section builds off of Section 3, and includes the algorithms and equations that make DQN’s work. You can skip this section if you just want a high-level overview of what DQN is - the what, but not the how.
Replicating DQN (Section 5) - This section builds off of Section 4, and includes tips and tricks to make DQN work in code. I recommend only reading this section if you’re interested in replicating this or similar papers yourself.
Further Improvements (Section 6) - This section talks about improvements that have been made in the DQN line of research since the original DQN papers were released. If this topic interests you, you can skip Sections 4 and 5 and still understand this section.
Regardless of how far you get, feedback is certainly welcome - part of the purpose of this post is to test my fit for doing more distilling work, so if you found this helpful (or unhelpful) I'd love to hear about it!
Supervised Learning With Neural Networks (Section 1)
To understand supervised learning, let’s start with a toy problem that’s often used to compare algorithms and make sure they work before applying them to more challenging domains. MNIST is a dataset composed of tens of thousands of hand-written digits from 0 to 9. Each piece of data contains a grayscale 28x28 pixel image, and a label of what digit that image should be classified as.

In a “rule-based” approach to this problem, we may write an algorithm that tries to follow the digits’ turns and edges and matches them with how digits are supposed to look like. But this runs into problems for digits that don’t look very nice, as e.g. the lower-left 3.
A question we can ask - is it even possible to write a program to correctly label these images? More specifically, can we write a program to correctly label similar images that we haven’t seen before? The answer here must be yes. If it was computationally impossible to take in 784 pixels as input and return a digit as output, humans couldn’t do it either! So there must be some way to take in these pixels as input, and return the correct output almost all the time. I say “almost” because you could imagine that I might be really bad at writing digits - perhaps I write a 6 that looks like an 8.
Is this a 6 or an 8? You can see how this would be hard to tell.
Fortunately for machine learning, humans also don’t score 100% on this task, so if we could do as well as a human, we’d be happy. But we don’t really understand exactly how to write a program to do this reliably. There are ways to attempt it, but as of 2022, none of them are as accurate as machine learning methods, and neural networks in particular.
Imagine we have some theoretical mathematical function that takes in 784 pixels as input, and outputs a probability distribution of how likely the image is to be each digit from 0 to 9. There exists some optimal function for this, but it’s virtually impossible to find. Machine learning is about finding a way to approximate this function - to iteratively get closer and closer to this function, until our approximation is good enough for the computer to perform the task. A common way we do this, and the way we will approach DQN later, is with a neural network. This 20-minute video provides a good introduction.
Thus, training a neural network to perform a supervised learning task comprises the following steps:
- To start with, set up our neural network totally randomly[1].
- Take a group of images and have the network guess what they are.
- Update the neural network so that it would predict those images better if you repeated the images. Specifically, we update the neural network so that we minimize prediction error - the difference between the correct predictions (1 for the correct category, 0 for everything else) and what the network predicted.
- Repeat Steps 2 and 3 until we are satisfied with the result.
Beyond this basic description, there are many tricks beyond the scope of this post. If you want to learn more, this course on fast.ai is considered a good resource. The Machine Learning Safety Scholars curriculum mentions this course as a more mathematically rigorous option. I can vouch for the quality of the first course, but have not done the second. For now, let’s just take it for granted that we can use a neural network to do this.
Thus, this is the core of deep learning. We take a neural network, feed data into it, have the network predict the result, and then update in a way that improves the model’s predictions over time.
Reinforcement Learning (Section 2)
Reinforcement learning (RL) is a different beast. In supervised learning, we were trying to improve predictions - in reinforcement learning, we want to maximize future reward. This reward is dependent on the task at hand. In an environment where the network (referred to as an agent in reinforcement learning) controls a robot, what should we reward? That depends on what we want - it could be maximizing distance traveled, doing a backflip, or anything we can specify.
We'll be using the terms "reward" to indicate the reward from a given timestep, and "future reward" to indicate the expected sum of rewards from now until the end of the game. The current reward is used as feedback for the agent to try and maximise the future reward. The future reward is composed of the current reward, plus the expected sum of future rewards. It is important to note that this ignores the past - when the agent considers total reward, it only considers the reward it can get from the current timestep onwards. It doesn't care about what its current score is - the agent only looks forward.
For Atari games, which is the subject of the paper we’re looking at today, the reward being maximised is the game’s score. So what are the inputs and outputs here? Deep Q-Networks are an example of model-free RL. In model-free RL, the agent doesn’t have an explicit model[2] of the rules of the game, or that it’s playing a game at all. It learns what to do purely from the input we pass into it, in this case pixels from the Atari environment.
At each timestep, we pass an observation to the neural network, which is composed of the pixels from the Atari game, and our policy (represented by our neural network) tells us which action the agent should take next. The environment (i.e, the Atari game) then returns to us the current reward we got from the previous action, as well as the next timestep’s observation.
Note: When studying reinforcement learning, you may hear reference to observations or to states. Technically, a state is a complete description of the world, whereas an observation is a partial description. When you examine a chess board, you’re seeing the board’s state. When you examine a poker board, you’re seeing an observation. Any video game which contains relevant off-screen information also only shows you an observation. These are often used interchangeably in reinforcement learning literature, and the completeness or lack thereof is inferred from the environment.
So, what we have here is a set of pixels as input, and a probability distribution (MNIST) or expected future reward (Atari) as output. This is starting to look a lot like our MNIST problem.
| MNIST | Atari | |
| Input (Set of pixels) | Handwritten digit | Image of the video game[3] |
| Output | Probability distribution of how likely it is that the input is each digit. | Expected future reward of each action we could take next from the image. |
Thus, we’ve reduced our reinforcement learning problem to a supervised learning problem! We can even use the same type of network, known as a convolutional neural network, to solve both MNIST and Atari problems. So, that’s reinforcement learning solved, right? Well..not quite. There’s still a few problems we need to work on.
Data assumptions. In supervised learning, we assume that inputs are independent and identically distributed. In MNIST, if the first image is a 3, that has no bearing on what the next image will be. They’re also identically distributed - if you have a dataset of 50% cats and 50% dogs, it’s assumed that data will be drawn from this distribution. This is not true in Atari games. If I make a move in an Atari game, that directly affects the next input I receive. In addition, the underlying distribution keeps changing. If I’m playing Space Invaders, I’m never going to see the game state where half the ships are gone unless I’m able to shoot down the other half first, which restricts the possible observations I could receive.
Reward is sparse. Whenever MNIST guesses an image randomly, it immediately learns where it went wrong and what to change to improve itself. Most Atari games have a low chance of a random action resulting in reward. We only get rewarded when we successfully score - if we don’t score any points, what do we do then? And scoring often takes several actions working together. In Space Invaders, you need to move the ship to the correct point, press the fire button, and have the bullet hit a ship. In Pong, you need to get the enemy paddle out of position, intercept the ball on your side of the field, and then fire the ball past them to score.
The optimal policy is unknown. Last but certainly not least - whenever MNIST guesses an image wrong, it’s told what the correct answer was. In an Atari game, the agent doesn’t get to know what would have happened if it chose differently, because we the programmers don’t know ourselves. Thus, the agent needs to learn how to perform well without being told what the optimal prediction was.
| Problem | Solution |
| Data assumptions (Independent, identically distributed) | Experience replay buffer (See Section 3) |
| Reward is sparse | Epsilon-greedy exploration (See Sections 3-4) |
| Optimal policy is unknown | Q-Learning (See Section 4) |
These three problems were what made reinforcement learning such a hard problem. It wasn’t until Deep Q-Networks came about that these problems were solved for the first time.
DQN Overview (Section 3)
There are two papers that are generally referenced when talking about Deep Q-Networks (DQN). One of them is from 2013 (Playing Atari Through Reinforcement Learning) and the other is from 2015. (Human-level control through reinforcement learning) For our purposes, we’ll be using the 2015 paper. Both are very similar, but the 2015 paper includes an extra couple of tricks to improve the algorithm, and mentions more of the hyperparameters[4] used to train the network.
So how does DQN work? DQN leverages a rather old idea called Q-Learning, a mathematical algorithm that’s been around for decades. Imagine an optimal function for predicting the expected sum of rewards in an environment called a Q-function. To maximize the future reward of that environment, we simply perform whatever action the Q-function tells us will lead to the most future reward. Finding this function is computationally intractable for any real problems. However, as we remember from our supervised learning section, machine learning is about approximating an optimal function.
Watkins and Dayan published a proof in 1992 that Q-Learning will converge on the optimum action-values, so long as we repeatedly sample all actions in all states and the possible space of actions is discrete[5]. We can’t actually sample all possible game states, so the idea of DQN is to get close enough to this assumption that we can converge on a Q-function that’s good enough to play the game well. Specifically, we want to sample a broad distribution of game states by taking random actions some of the time, and we want to sample them repeatedly. We’ll see more about this shortly.
For our other assumption, all Atari games are discrete, since there’s only a finite number of buttons you can press, and the joystick is either pressing in a direction or it isn’t. The paper is here, but I recommend it only if you’re deeply interested in the math - the remainder of this document can be understood without it, and I wrote up a working DQN agent without ever reading the convergence proof.
As for the program itself, we’re going to break it down into parts - the setup, the part where the agent acts in the environment (acting phase) and the part where the agent trains itself to do better in future (learning phase). These last two phases can be totally decoupled from each other,[6] but in the DQN paper, the acting phase comes first.
When setting up, we create the following things:
- A list that stores data on what the agent has seen and done so far. This is called an experience replay buffer.
- A neural network that takes in an observation and outputs an expected total reward for each possible action it can take. This is used in the acting phase.
- A copy of the neural network that only updates every C (C=1000) timesteps. This is used in the learning phase to improve DQN’s stability, and is called a target network.
In the acting phase, we perform the following actions:
- Pass the observation at time t as an input to the neural network, which outputs expected future reward for each possible action we can take.
- Select an action. To do this, we select a random action with a probability epsilon[7], and select the action with the highest expected future reward the rest of the time. This is called an epsilon-greedy exploration strategy.
- Get the reward and the observation at time t+1 from the environment.
- Store the observation at time t, the action we took, the reward we got, whether the current episode terminated, and the observation at time t+1 in the experience replay buffer for use in the learning phase later.
The acting phase produces data for use in the learning phase, where the agent learns to do better.
Before we move on to the learning phase, let’s go back to one of our deep learning constraints from the previous section. Specifically, we assume in supervised learning that inputs are independent and identically distributed, when this is definitely not the case in a video game. So, how could we learn from the results we get from performing actions, in a way that’s independent from the action we just took? The answer to both of these problems is to use an experience replay buffer.
Whenever we take an action, we store the observation at t, the action, the reward, whether an episode is done or not, and the observation at t+1 in this replay buffer. Then, when it comes time to improve our policy through training, we take a batch of 32 random actions from our experience buffer and use those to train the agent.
Think of the training process like this. You’re learning to play chess, so you start playing. You’re not very good at first, but you record all your moves. Then, after each game, you go over a random sample of those moves[8] and ask yourself what move you should have played. Over time, you get better at evaluating chess positions, and can apply that knowledge to your games. The agent does this training every few steps rather than between games, but the general idea is the same.
This has several advantages. Firstly, it’s efficient - we can learn from an experience over and over, not just once. Watkins and Dayan showed that we can only guarantee our Q-function will converge if we repeatedly sample all actions in all states. This is not possible, but we can get much closer to this ideal by sampling all our frames multiple times over the course of training.
Secondly, it makes the training inputs independent. Finally, while it doesn’t make the training inputs identically distributed, it definitely widens the set of game states we can draw upon at any given moment. This is a huge improvement over just learning from the previous state, and it is a major breakthrough towards allowing reinforcement learning in complex domains like Atari to happen at all.
With that explained, we can look at the learning phase. In the learning phase, we do the following:
- Sample a random batch of items (N = 32) from the replay buffer.
- Set each learning target to the current reward (gotten from the replay buffer) plus the target network’s estimate of future reward given the observation at t+1. Since the target network knows what happened at t+1 and the Q-network doesn’t, it should have a more accurate prediction that can be used to train the Q-network.
- Calculate the difference between the learning targets and the Q-network’s estimate of total reward, given the observation at time t. This is our loss function.
- Perform gradient descent on the Q-network in order to minimize this loss function.
- Every steps, (C = 1000) update the target network with the Q-network’s parameters.
One part I was confused about when learning this algorithm is why we’re attempting to minimize prediction error rather than maximize future reward. David Quarel helpfully explained why this is to me. Imagine you always know exactly what reward (including sum of future rewards) you’ll get from any given action in an Atari game. In this case, the optimal action is trivial - with probability 1, take whichever action maximizes your future reward. Selecting an action that produces the most future reward given your current knowledge is trivial - accurately knowing what actions will produce what rewards is the hard part.
As a result, training a Q-network is all about minimizing prediction error, just like a supervised learning problem. If a move is better than the Q-network predicted, the network’s loss gets worse, because we want to update in favor of assigning higher expected reward to that move given that state in future. I also had the intuitive feeling that the loss function increasing was “punishing” the agent for finding a really good move, and I didn’t understand why we wanted to punish this behavior. This anthropomorphism was leading me astray - be careful not to fall prey to it! The loss function isn’t punishing the agent, it’s merely providing feedback the agent uses to improve itself via gradient descent.
And there we have it! To summarize our algorithm, our agent first takes in the current observation, outputs an action, and gets information on what happened (reward and next observation) from the environment. It then learns by randomly sampling a selection of its previous moves, seeing how correct or incorrect it was in predicting the future reward, and updating in favor of improved predictions. This algorithm, in combination with the experience replay buffer and the target network to reduce divergent behavior, is sufficient to train an agent to achieve superhuman play in some Atari games.
I’ve deliberately held off on some technical details in this section. If all you want to know is how DQN’s and reinforcement learning work at a high level, you can stop here, or progress to Section 6 for a quick overview on what’s changed since 2015.
But what is the Q-function, mathematically? Why do we care whether an episode finished or not when storing it in the replay buffer? What do we do to bootstrap the replay buffer before it has enough samples? And what is an epsilon-greedy strategy, and why does it matter? If you’re interested in the technical details, read on to Section 4.
DQN Technical Explanation (Section 4)
The previous section has deliberately avoided the math, but here’s where we’re going to dive in. From our last section, we know that DQN works by converging towards an ideal Q-function that maximizes total reward. To maximize total reward, we consider the current reward, plus the sum of expected rewards in the future, from now until the end of the game. We also apply a discount rate called gamma (0.99 by default) to this sum. With gamma as 0.99, the timestep t+n is discounted by , so a constant reward of 1 per timestep would be 1 + 0.99 + 0.9801 and so on.
Q-functions operate under a similar algorithm, where it aims to maximize the sum of discounted rewards from now until the end of the game. The ideal Q-function can be written as follows:
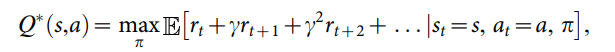
Where π is our policy, is our discount rate, and is the reward at timestep t. It’s worth noting that means the optimal Q-function, whereas without the asterisk represents the current Q-function. The goal is for to gradually converge on our optimal .
In DQN, the policy is simply the neural network that we pass observations to. Our optimal Q-function is equal to the policy that produces the best possible sum of rewards given a particular state-action pair. In other words - given what just happened, what rule could we follow to get the most total reward possible from now on? A policy is a rule that tells us what actions to take given an observation, and in DQN, that policy is learned by the neural network. Thus, this theoretically optimal policy is what we attempt to converge towards.
But how do we know about rewards in the future? Thanks to the experience replay buffer, we can take samples that already happened, and see what happened one timestep in the future. We then approximate our prediction error using our loss function:
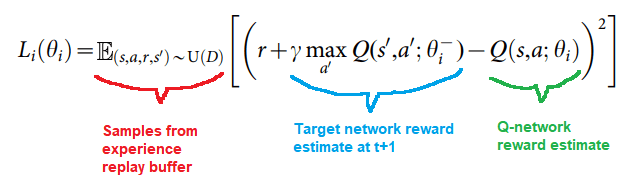
This looks complicated, but is easier than it looks. Let’s go back to our non-mathy description from Section 3, and change it slightly:
- Red section: Sample a random batch of items (N = 32) from the replay buffer.
- Blue section: Set each learning target to the current reward (gotten from the replay buffer) plus the target network’s estimate of future reward given the observation at t+1. Since the target network knows what happened in t+1 and the Q-network doesn’t, it should have a more accurate prediction that can be used to train the Q-network.
Green section: Calculate the Q-network’s estimate of future reward, given the observation at time t. - Take the mean squared error[9] between the blue section and the green section. This is our loss function.
We can see how this function matches that. The loss function for a given set of parameters is the mean squared error of the target network’s prediction of future reward minus the Q-network’s prediction. The target network gets to see one more step than the Q-network does, and thus is a better predictor. This improves the Q-network, which then updates the target network every steps with what it’s learned. Essentially, the Q-network is moving towards a better-informed copy of itself, learning to predict further and further into the future as it does.
So now that we know how the algorithm works, let’s take a look at an abridged version of the full algorithm, with some of the programming details removed.
Initialize experience replay buffer D, Q-network Q, and target Q-network q.
Set q’s parameters to Q.
For each step:
With probability ε, select a random action. Otherwise, pick the action with the highest expected future reward according to Q(s, a).
Execute action a, and collect reward r and observation t+1 from the environment.
Store the transition obs(t), action, reward, obs(t+1) in D.
If current step is a training step:
Collect a random batch of transitions from D.
For each transition j, set future reward to r(j) if the episode ended at j, else r(j) + gamma * q(s’, a’).
Perform gradient descent with respect to the loss function to update Q.
Every C steps, set q’s parameters to Q.
And there we have it! DQN uses two copies of a neural network to continually improve itself and approximate the ideal Q-function for a particular environment. We use an experience replay buffer to approximately satisfy the requirements of supervised learning (Independent, identically distributed inputs) and Q-functions (Ability to repeatedly take all actions in all states) closely enough to allow the mathematical assumptions to hold in real life. And now you know how DQN works!
But what if you want to program it? Then you’ll need to know the finer details - what exactly does an observation consist of? How do we process Atari inputs? What are our hyperparameters, and exactly what layers are in our neural network? For all these details and more, read on to Section 5!
Replicating DQN (Section 5)
The full pseudocode for DQN, including enough details to follow along with actual code, is as follows. I suggest following along with an implementation at this step. CleanRL’s implementation can be found here: https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari.py
My implementation can be found here: https://github.com/JayBaileyCS/RLAlgorithms/blob/main/DQN_From_Scratch_Atari.ipynb
The main difference between these two implementations is that I wrote my own slightly slower but much less complex replay buffer. If you’re interested in peak performance, use CleanRL. If you want to know a little more about how the hot dog gets made, use mine. I also used my implementation as a reference for this article, so it may be a bit easier to follow along with. It is worth noting - both of these implementations include some hyperparameter improvements over the 2015 paper, so if you want to specifically replicate the 2015 paper, pay close attention to the hyperparameters later in this section!
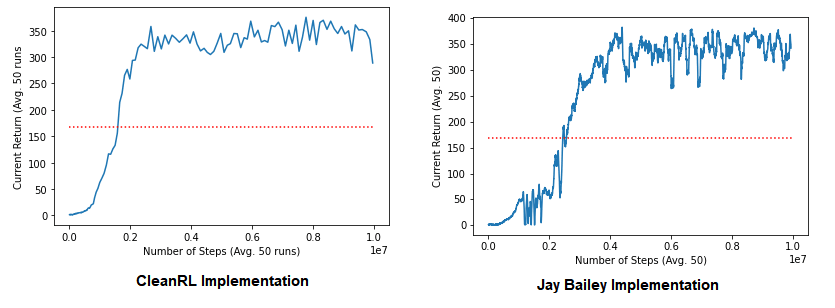
CleanRL’s implementation on the left, mine on the right. The red line represents the 2013 paper’s average results - as you can see, we’ve made some changes since 2013 that have improved the results significantly. In summary, those changes are adding the target network, using the Adam optimiser instead of RMSProp, and tuning hyperparameters.
In order to replicate the paper, we’ll want to look at the algorithm in a bit more detail, the structure of the neural network, the hyperparameters, and finally, the Atari environment. We’ll do each one in turn. Feel free to follow along with your preferred implementation!
DQN Algorithm
Set up the Atari environment
Set up the device to perform calculations on
Set up replay buffer, q_network, target_network, optimiser, and initial observation. Note: Use the RMSProp optimiser instead of Adam if you want a faithful reproduction.
Optional: Set up logs.
Optional: Seed the run for reproducibility.
For each step:
Calculate epsilon
Select a random number from 0 to 1. If less than epsilon, select a random action. Otherwise, select argmax(q_network).
Perform this step in the environment, getting next_obs, reward, done, and info from the environment.
Add the above items into the replay buffer.
Set the observation to the next_obs returned from the environment.
If step > replay start size and step % training frequency = 0:
Sample batch_size samples from the replay buffer
Calculate the expected future reward at t+1 from target_network
Calculate the expected future reward at t from q_network.
Perform MSE loss on expected target_network future reward - expected q_network future reward.
Perform gradient descent
Optional: Perform logs every N steps. N is up to you.
If step % target network update frequency = 0:
Set target_network’s parameters to be equal to q_network’s parameters.Neural Network
The convolutional neural network consists of the following:
First layer: Takes in a 4x84x84 tensor as input. (Four stacked preprocessed Atari frames). Applies a convolutional layer of 32 8x8 filters with stride 4, followed by a rectifier nonlinearity[10] (torch.nn.ReLU).
Second layer: Convolutional layer of 64 4x4 filters with stride 2, followed by ReLU.
Third layer: Convolutional layer of 64 3x3 filters with stride 1, followed by ReLU.
Fourth layer: Fully connected layer with a 64 * 7 * 7 input and 512 outputs.
Final layer: 512 inputs, N outputs, where N is the number of valid actions in the environment.
Hyperparameters
The paper has the following hyperparameters:
| Hyperparameter | Value | Description |
| Steps | 10M | Total number of timesteps to train the agent for. |
| Minibatch size | 32 | Number of samples to get from the replay buffer. |
| Replay memory size | 1M | Number of frames to store in the replay buffer. We store the most recent frames only. |
| Agent history length | 4 | How many frames of input to pass into observation. |
| Target network update frequency | 10K | How often (in steps) we update the target network. This is 1K in the Github implementations. |
| Discount factor | 0.99 | Gamma in Section 4. |
| Action repeat | 4 | How many times to repeat the same action after performing it. This should be the same as agent history length. |
| Update frequency | 4 | How often (in steps) we train the agent. |
| Learning rate | 2.5e-4 | Learning rate of the optimiser. |
| Gradient momentum | 0.95 | RMSProp-only hyperparameter. Ignore if using Adam. |
| Squared gradient momentum | 0.95 | RMSProp-only hyperparameter. Ignore if using Adam. |
| Min squared gradient | 0.01 | RMSProp-only hyperparameter. Ignore if using Adam. |
| Initial exploration | 1 | Starting value of epsilon for epsilon-greedy exploration. |
| Final exploration | 0.1 | Final value of epsilon for epsilon-greedy exploration. This is 0.01 in the Github implementations. |
| Final exploration frame | 1M | Number of steps in which epsilon is linearly annealed[11] to its final value. (Don’t get confused, this is STEPS, not frames - each step is 4 frames) |
| Replay start size | 50K | How many steps pass before we start training the agent. 80K in Github. |
| No-op max | 30 | Maximum number of steps to take no action before starting play. |
Atari Environment
If you’re following along with the 2013 or 2015 paper, you’ll notice that they refer to a function ϕ that preprocesses Atari frames. Nowadays we do this by adding wrappers to the OpenAI gym environment, using the Atari API, so everything ϕ does is now in the make_env function. If you want to write your own, here are the wrappers you’ll want to look into, or the functionality you’ll want to reproduce:
- Call gym.make(<environment_id>) with the Atari environment you want. I suggest using the NoFrameskip-v4 versions - vanilla DQN is a bit brittle, and has trouble with v0 and v5, each of which randomly causes you to take the same action as before 25% of the time to add some randomness to the problem. If you want to use v5, that’s totally reasonable, but you should expect lower scores.
- NoopResetEnv - for a random number of steps between 1 and 30 after the environment starts a new episode, do nothing. This adds some randomness to the game to ensure the agent doesn’t just memorize a single correct sequence of actions to take every time.
- MaxAndSkipEnv - Select an action every four frames. For all other frames, perform the same action you just took. This makes computation a lot faster.
- EpisodicLifeEnv - Only end the episode if it’s truly game over. For instance, Breakout gives you 5 lives, not just 1.
- FireResetEnv - Some games require you to press the fire button in order to start playing. FireResetEnv does this automatically.
- ClipRewardEnv - When training, clip rewards to -1 if you lose score or 1 if you gain score. This allows the agent to generalize better across games with a wildly varying score. Pong, for instance, has a score from -21 to +21, whereas other Atari games like Beam Rider can have scores in the thousands.
- ResizeObservation and GrayScaleObservation - Change the 210x160 RGB input to 84x84 grayscale. Improves computational performance.
- FrameStack - Pass in a 4x84x84 observation consisting of four stacked frames when we train the agent, so it gets all the visual information it needs despite only acting every four frames.
These gym wrappers are standard across Atari RL solutions, not just DQN.
Further Improvements (Section 6)
The 2015 paper is far from the end of the story. There have been a lot of improvements in reinforcement learning and DQN specifically in the past seven years. Here is a far from exhaustive list to learn more.
Rainbow DQN brings together half a dozen improvements made to vanilla DQN over the years and tests how well they work together. This paper summarizes all the major DQN improvements up to this point, making it a fantastic, albeit daunting, resource. Writing about all these improvements would practically be another article in and of itself! I suggest taking a look at both the Rainbow DQN paper and at the referenced papers where each individual advance came from in order to understand it. Or bug me to do a distillation of Rainbow DQN as a follow-up :P
ApeX DQN takes Rainbow DQN and turns it into a distributed system, containing one learner (Performs the learning phase) and dozens or hundreds of actors. (Performs the acting phase) I haven’t looked deeply into this, but I suspect this works because of one of Rainbow’s improvements known as Prioritized Replay. Prioritized Replay selects frames from the replay buffer in accordance with how much the agent can learn from those frames, instead of vanilla DQN selecting frames at random. This allows only the best frames to be selected for the learner, which is necessary since ApeX’s hundreds of actors together play more frames than the learner could ever learn from.
Self-Predictive Representations (SPR) adds self-supervised objectives and data augmentation to Rainbow, vastly improving the sample efficiency of DQN. This was added to MuZero (the successor to AlphaGo) as part of the recent EfficientZero [LW · GW] algorithm.
If you’ve read this far, thanks for sticking with me! Hopefully you’ve learned some more about reinforcement learning and DQN’s. This post was also made to test my fit for distilling research topics in AI alignment, so I’d love to hear what you thought about the article, any sticking points you might have run into, or any detours you thought were unnecessary.
- ^
In some domains such as image classification, transfer learning is used - we take an existing model trained on a lower-level problem like "classify images" and then fine-tune it on our problem, like "Identify when a bear is approaching a campsite". This can let us get more accurate models with less training.
- ^
A model is a function which predicts state transitions and rewards in advance. In other words, a model allows an agent to know the rules of the game in advance without learning them through trial and error. This can improve sample efficiency, and reduce bias - the model can't mislearn the rules if it already has them. The disadvantage is that in many situations, a ground-truth model of the environment isn't going to be available to the agent, and model-free methods are the only usable solutions.
- ^
To be specific, this is four stacked images, where each image represents a frame. To save computing power, we only select an action every four frames, then we repeat that action for the next three.
- ^
Parameters are the weights that the neural network uses to complete its task. We never manipulate these directly, that’s done automatically via the training process. Hyperparameters are the parameters we set as the programmer, like how many steps a run should go for, or what the agent’s learning rate should be. Reinforcement learning is pretty sensitive to hyperparameters sometimes, so it's useful to have as many of them as possible in the paper so we can replicate them properly. They’re called hyperparameters because they’re “parameters about parameters”, but honestly, I just think of them as arguments, since that’s what they are - arguments we pass into the training function when we run it.
- ^
For continuous control problems such as robotics, we need a different algorithm. DDPG is an algorithm that adapts DQN to continuous problems, and PPO is an algorithm that works well on both. These are worth looking into if you're interested in non-discrete action spaces.
- ^
One of the papers in the Further Improvements section, ApeX DQN, does just that.
- ^
Epsilon starts out at 1, and then reduces to a smaller number (0.01-0.1 depending on implementation) linearly across the first 10% of the run.
- ^
You might ask yourself if you'd be better off looking at some moves rather than others - if you lost your queen, you should probably pay close attention to the move directly preceding it. This is called Prioritised Experience Replay, and is one of the Rainbow DQN improvements from the Further Improvements section.
- ^
Mean squared error loss (Or MSE loss) simply takes the prediction error and squares it. In addition to punishing large deviations, this also handles negative numbers - we want to treat an error of +N and -N the same, since we care about the absolute value of the error, not the direction. Squaring both +N and -N leads to N^2, solving this problem.
- ^
This term sounds fancy, but it actually just sets all negative activations to 0.
- ^
Reduce over time. If our initial exploration is 1 and final exploration is 0.1, then our total change is 0.9 across 1 million steps. That means each step that passes, we reduce epsilon by 0.9 / 1,000,000. So when we're halfway through, we've gone through half the change - that is to say, at 500,000 steps, epsilon = 0.55.
8 comments
Comments sorted by top scores.
comment by qbolec · 2022-09-13T20:28:46.884Z · LW(p) · GW(p)
Thank you! I've read up to and including section 4. Previously I did know a bit about neural networks, but had no experience with RL and in particular didn't know how RL can actually bridge the gap between multiple actions leading to a sparse reward (as in: hour of Starcraft gameplay just to learn you've failed or won). Your article helped me realize how it is achieved - IIUC by:
0. focusing on trying to predict what the reward will be more than on maximizing it
1. using a recursive approach to infinite sum: sum(everything)=e+sum(verything).
2. by using a different neural network on the LHS than on the RHS of this equality, so that one of them can be considered "fixed" and thus not taking part in backpropagation. Cool!
Honestly, I am still a bit fuzzy on how exactly we solve the problem that most "e"s in e+sum(verything) will be zero - before reading the article I thought the secret sauce will be to have some imaginary "self-rewarding" which eventually sums up to the same total reward but in smaller increments over time (like maybe we should be happy about each vanishing pixel in Arkanoid, or each produced unit in Starcraft a little, even if there's no direct reward for that from the environment)?
After reading your explanation I have some vague intuition that even if "e" is zero, e+sum(verything) has better chance of figuring out what the future rewards will be, because we are one step closer to these rewards, and that somehow this small dent is enough to get things going. I imagine this works somewhat like this: if there are 5 keys I have to press in succession to score one point, then sooner or later I will sample the state after 4 presses and fix my predictor output for this state as the reward will be immediate result of one keypress, then I'll be ready to learn what to do after 3 presses as I will already know what happens after 4th keypress so I can better predict this two-actions chain, and so on, and so on learning to predict consequences of a longer and longer combos. Is that right?
Things which could improve the article:
1. Could you please go over each occurrence of word "reward" in this article and make it clear if it should be "reward at step t" or "sum of rewards from step t onwards"? I felt it is really difficult for me to understand some parts of explanation because of this ambiguity.
2. In the pseudo-code box you used "r(j) + Q(s’, a’, q)" formula. I was expecting "r(j)+gamma*q(s',a')" instead. This is because I thought this should be similar to what we saw earlier in the math formula (the one with red,green and blue parts) and I interpreted that Q(s',a',theta^-) in the math formula was meant to mean something like "the network output for state s', proposed action a' and weights set according to old frozen settings", which I believe should be q(s',a') in the pseudocode. If I am wrong, then please clarify why we don't need to multiplication by gamma and why Q can take three arguments, and why q is one of them, as none of this is clear to me.
3. Some explanation of how this sparsity of rewards is really addressed in games which give you zero reward until the very end.
↑ comment by Jay Bailey · 2022-09-14T01:37:15.131Z · LW(p) · GW(p)
Your understanding is good. What you refer to with "self-rewarding" is called "reward shaping" in reinforcement learning. DQN doesn't use this, so I didn't talk about it in this post. DQN also doesn't do well with games where you can't stumble upon the first reward by random exploration, thus getting the process started. So, for your Point 3 - DQN doesn't address this, but future RL solutions do.
Montezuma's Revenge is one such example - the first reward requires traversing several obstacles correctly and is vanishingly unlikely to occur by random chance. If you look up the history of Montezuma's Revenge in reinforcement learning you'll find out some interesting ways people approached this problem, such as biasing the network towards states it hadn't seen before (i.e, building "curiosity" into it). The basic DQN referred to in this post cannot solve Montezuma's Revenge.
With your "5 keys" example, you're almost correct. The agent needs to actually perform the entire combo at least once before it can learn to predict it in the future - the target network is looking at t+1, but that t+1 is collected from the replay buffer, so it has to have been performed at least once. So, sooner or later you'll sample the state after 5 presses, and then be able to predict that reward in future. Then this cascades backwards over time exactly as you described.
Regarding Point 1, I've gone over and adjusted the terms - "future reward" now refers to the sum of rewards from step t onwards, and I've defined that early in Section 2, to make it clear that future reward also includes the reward from timestep t.
Regarding Point 2, you're correct, and I've made those changes.
Thanks for the feedback, and I'm glad you got some useful info out of the article!
comment by dumky · 2022-09-20T20:04:23.837Z · LW(p) · GW(p)
Thanks for the write-up!
I find the nomenclature "target network" confusing, but I understand that comes from the literature. I like to think of it as "slightly out-of-date reward prediction net".
Also, it's still not clear what "Q" stands for in DQN. Do you know?
Looking forward to your future deep learning write-ups :-)
↑ comment by Jay Bailey · 2022-09-21T01:23:16.674Z · LW(p) · GW(p)
Thanks for the feedback - glad you liked the post!
"Slightly out-of-date reward prediction net" is a good way of thinking about it. It's called the "target network" because it's used to produce targets for the loss function - the main neural network is trying to get as close to the target prediction as possible, and the target prediction is built by the target network. Something like the "stable network" or "prior network" might have been a better term though.
"Q" in DQN is a reference to Q-learning. I'm not 100% sure, but I believe the Q term in Q-learning is supposed to be short for "quality" - a Q-function calculates the quality of a state-action combination.
comment by Giorgi Chavchanidze (giorgi-chavchanidze) · 2024-09-09T13:12:42.275Z · LW(p) · GW(p)
Hello,
Thanks for the great article. A general question - what happens if the action space in the environment is state-dependent? In this case, if I use an "Atari-like" Neural Network for approximating Q function, it will also give values for Q(a,s) for non-feasible pairs of a and s. In practice, I could just ignore these pairs, but will this create any problems theoretically speaking? If so, could you give a quick suggestion about how to fix this or where to look for solution?
Thanks!
↑ comment by Jay Bailey · 2024-09-11T18:24:23.288Z · LW(p) · GW(p)
Hi Giorgi,
Not an expert on this, but I believe the idea is that over time the agent will learn to assign negligible probabilities to actions that don't do anything. For instance, imagine a game where the agent can move in four directions, but if there's a wall in front of it, moving forward does nothing. The agent will eventually learn to stop moving forward in this circumstance. So you could probably just make it work, even if it's a bit less efficient, if you just had the environment do nothing if an invalid action was selected.
comment by Oliver Clive-Griffin (oliver-clive-griffin) · 2024-05-16T23:19:09.045Z · LW(p) · GW(p)
The target network has access to more information than the Q-network does, and thus is a better predictor
Some additional context for anyone confused by this (as I was): "more information" is not a statement about training data, but instead about which prediction task the target network has to do.
In other words, the target network has an "easier" prediction task: predicting the return from a state further in the future. I was confused because I thought the suggestion was that the target network has been trained for longer, but it hasn't, it's just an old checkpoint of the Q-network.
The differentiation between the Q- and target-networks here is actually not very important, the key point would hold even if you were using the Q-network instead. That is: predicting is "easier" than predicting for any network, as the first is in some sense a subset of the second task.
Replies from: Jay Bailey↑ comment by Jay Bailey · 2024-05-17T19:35:33.626Z · LW(p) · GW(p)
Thanks for this! I've changed the sentence to:
The target network gets to see one more step than the Q-network does, and thus is a better predictor.
Hopefully this prevents others from the same confusion :)