Decision theory: Why Pearl helps reduce “could” and “would”, but still leaves us with at least three alternatives
post by AnnaSalamon · 2009-09-06T06:10:20.344Z · LW · GW · Legacy · 72 commentsContents
72 comments
(This is the third post in a planned sequence.)
My last post left us with the questions:
- Just what are humans, and other common CSAs, calculating when we imagine what “would” happen “if” we took actions we won’t take?
- Is there more than one natural way to calculate these counterfactual “would”s? If so, what are the alternatives, and which alternative works best?
Today, I’ll take an initial swing at these questions. I’ll review Judea Pearl’s causal Bayes nets; show how Bayes nets offer a general methodology for computing counterfactual “would”s; and note three plausible alternatives for how to use Pearl’s Bayes nets to set up a CSA. One of these alternatives will be the “timeless” counterfactuals of Eliezer’s Timeless Decision Theory.
The problem of counterfactuals is the problem what we do and should mean when we we discuss what “would” have happened, “if” something impossible had happened. In its general form, this problem has proved to be quite gnarly. It has been bothering philosophers of science for at least 57 years, since the publication of Nelson Goodman’s book “Fact, Fiction, and Forecast” in 1952:
Let us confine ourselves for the moment to [counterfactual conditionals] in which the antecedent and consequent are inalterably false--as, for example, when I say of a piece of butter that was eaten yesterday, and that had never been heated,
`If that piece of butter had been heated to 150°F, it would have melted.'
Considered as truth-functional compounds, all counterfactuals are of course true, since their antecedents are false. Hence
`If that piece of butter had been heated to 150°F, it would not have melted.'
would also hold. Obviously something different is intended, and the problem is to define the circumstances under which a given counterfactual holds while the opposing conditional with the contradictory consequent fails to hold.
Recall that we seem to need counterfactuals in order to build agents that do useful decision theory -- we need to build agents that can think about the consequences of each of their “possible actions”, and can choose the action with best expected-consequences. So we need to know how to compute those counterfactuals. As Goodman puts it, “[t]he analysis of counterfactual conditionals is no fussy little grammatical exercise.”
Judea Pearl’s Bayes nets offer a method for computing counterfactuals. As noted, it is hard to reduce human counterfactuals in general: it is hard to build an algorithm that explains what (humans will say) really “would” have happened, “if” an impossible event had occurred. But it is easier to construct specific formalisms within which counterfactuals have well-specified meanings. Judea Pearl’s causal Bayes nets offer perhaps the best such formalism.
Pearl’s idea is to model the world as based on some set of causal variables, which may be observed or unobserved. In Pearl’s model, each variable is determined by a conditional probability distribution on the state of its parents (or by a simple probability distribution, if it has no parents). For example, in the following Bayes net, the beach’s probability of being “Sunny” depends only on the “Season”, and the probability that there is each particular “Number of beach-goers” depends only on the “Day of the week” and on the “Sunniness”. Since the “Season” and the “Day of the week” have no parents, they simply have fixed probability distributions.
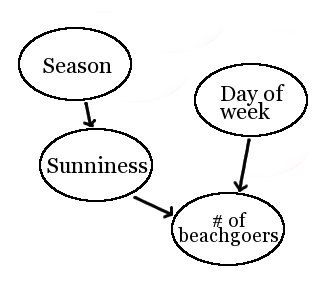
Once we have a Bayes net set up to model a given domain, computing counterfactuals is easy*. We just:
- Take the usual conditional and unconditional probability distributions, that come with the Bayes net;
- Do “surgery” on the Bayes net to plug in the variable values that define the counterfactual situation we’re concerned with, while ignoring the parents of surgically set nodes, and leaving other probability distributions unchanged;
- Compute the resulting probability distribution over outcomes.
For example, suppose I want to evaluate the truth of: “If last Wednesday had been sunny, there would have been more beach-goers”. I leave the “Day of the week” node at Wednesday“, set the ”Sunny?“ node to ”Sunny“, ignore the “Season” node, since it is the parent of a surgically set node, and compute the probability distribution on beach-goers.
*Okay, not quite easy: I’m sweeping under the carpet the conversion from the English counterfactual to the list of variables to surgically alter, in step 2. Still, Pearl’s Bayes nets do much of the work.
But, even if we decide to use Pearl’s method, we are left with the choice of how to represent the agent's "possible choices" using a Bayes net. More specifically, we are left with the choice of what surgeries to execute, when we represent the alternative actions the agent “could” take.
There are at least three plausible alternatives:
Alternative One: “Actions CSAs”:
Here, we model the outside world however we like, but have the agent’s own “action” -- its choice of a_1, a_2, or ... , a_n -- be the critical “choice” node in the causal graph. For example, we might show Newcomb’s problem as follows:
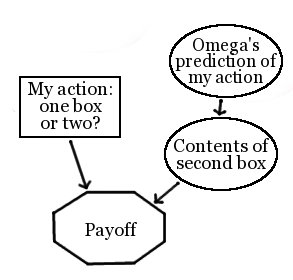
The assumption built into this set-up is that the agent’s action is uncorrelated with the other nodes in the network. For example, if we want to program an understanding of Newcomb’s problem into an Actions CSA, we are forced to choose a probability distribution over Omega’s prediction that is independent of the agent’s actual choice.
How Actions CSAs reckon their coulds and woulds:
- Each “could” is an alternative state of the “My action” node. Actions CSAs search over each state of the “action” node before determining their action.
- Each “would” is then computed in the usual Bayes net fashion: the “action” node is surgically set, the probability distribution for other nodes is left unchanged, and a probability distribution over outcomes is computed.
So, if causal decision theory is what I think it is, an “actions CSA” is simply a causal decision theorist. Also, Actions CSAs will two-box on Newcomb’s problem, since, in their network, the contents of box B is independent of their choice to take box A.
Alternative Two: “Innards CSAs”:
Here, we again model the outside world however we like, but we this time have the agent’s own “innards” -- the physical circuitry that interposes between the agent’s sense-inputs and its action-outputs -- be the critical “choice” node in the causal graph. For example, we might show Newcomb’s problem as follows:
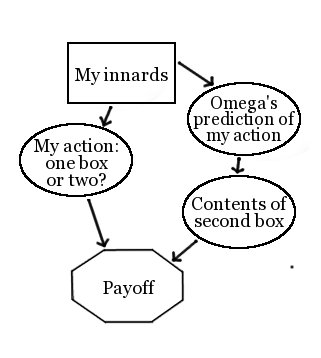
Here, the agent’s innards are allowed to cause both the agent’s actions and outside events -- to, for example, we can represent Omega’s prediction as correlated with the agent’s action.
How Innards CSAs reckon their coulds and woulds:
- Each “could” is an alternative state of the “My innards” node. Innards CSAs search over each state of the “innards” node before determining their optimal innards, from which their action follows.
- Each “would” is then computed in the usual Bayes net fashion: the “innards” node is surgically set, the probability distribution for other nodes is left unchanged, and a probability distribution over outcomes is computed.
Innards CSAs will one-box on Newcomb’s problem, because they reason that if their innards were such as to make them one-box, those same innards would cause Omega, after scanning their brain, to put the $1M in box B. And so they “choose” innards of a sort that one-boxes on Newcomb’s problem, and they one-box accordingly.
Alternative Three: “Timeless” or “Algorithm-Output” CSAs:
In this alternative, as Eliezer suggested in Ingredients of Timeless Decision Theory, we have a “Platonic mathematical computation” as one of the nodes in our causal graph, which gives rise at once to our agent’s decision, to the beliefs of accurate predictors about our agent’s decision, and to the decision of similar agents in similar circumstances. It is the output to this mathematical function that our CSA uses as the critical “choice” node in its causal graph. For example:
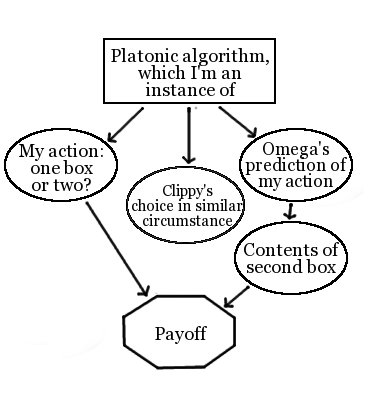
How Timeless CSAs reckon their coulds and woulds:
- Each “could” is an alternative state of the “Output of the Platonic math algorithm that I’m an instance of” node. Timeless CSAs search over each state of the “algorithm-output” node before determining the optimal output of this algorithm, from which their action follows.
- Each “would” is then computed in the usual Bayes net fashion: the “algorithm-output” node is surgically set, the probability distribution for other nodes is left unchanged, and a probability distribution over outcomes is computed.
Like innards CSAs, algorithm-output CSAs will one-box on Newcomb’s problem, because they reason that if the output of their algorithm was such as to make them one-box, that same algorithm-output would also cause Omega, simulating them, to believe they will one-box and so to put $1M in box B. They therefore “choose” to have their algorithm output “one-box on Newcomb’s problem!”, and they one-box accordingly.
Unlike innards CSAs, algorithm-output CSAs will also Cooperate in single-shot prisoner’s dilemmas against Clippy -- in cases where they think it sufficiently likely that Clippy’s actions are output by an instantiation of “their same algorithm” -- even in cases where Clippy cannot at all scan their brain, and where their innards play no physically causal role in Clippy’s decision. (An Innards CSA, by contrast, will Cooperate if having Cooperating-type innards will physically cause Clippy to cooperate, and not otherwise.)
Coming up: considerations as to the circumstances under which each of the above types of agents will be useful, under different senses of “useful”.
Thanks again to Z M Davis for the diagrams.
72 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2009-09-07T09:51:18.800Z · LW(p) · GW(p)
After reading more Girard, "platonic computation" started to sound to me like "phlogiston". Seriously.
Replies from: Wei_Dai, SforSingularity↑ comment by Wei Dai (Wei_Dai) · 2009-09-09T23:25:27.598Z · LW(p) · GW(p)
My UDT1, which makes use of the concept of "platonic computation", seems to work, at least on simple toy problems, so I don't see what's wrong with it. Are you arguing that "platonic computation" will cause difficulties in more complex problems, or what?
↑ comment by SforSingularity · 2009-09-09T15:18:43.896Z · LW(p) · GW(p)
Can we just remove the word "platonic" and define "computation" in the usual way as an input for a UTM?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2009-09-09T17:07:18.254Z · LW(p) · GW(p)
Where's the UTM that runs both in yours and Omega's head?
Replies from: SforSingularity↑ comment by SforSingularity · 2009-09-09T22:05:50.590Z · LW(p) · GW(p)
What do you mean by "where" in reference to a mathematical abstraction?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2009-09-09T22:48:48.657Z · LW(p) · GW(p)
What do you mean by "where" in reference to a mathematical abstraction?
That's the thing: you are basically requiring "platonic" to be returned in the explanation (mathematical abstraction that doesn't reside anywhere specifically). "Computation" I can imagine: it's the process running on my PC, or in my head, or wherever. Mathematical abstraction of computation -- not so clear. It's for one thing something that happens in mathematicians' heads, but moving this process to the moon is suspect.
There is always a "where" to any abstract math that anyone ever observed, and the lawfulness with which this phenomenon persists among many instances doesn't need to be explained by something outside the physical laws (or "meta" to them): it's just another regularity in the world, a daunting one, but as always a curiosity-stopper is not the answer (assuming a hidden world of mathematical truths that is not even anywhere in our real world in which you can peek from anywhere with varying levels of success by theories of different strength, never to see it whole, etc. -- a kind of modern dualism, consciousness of reason).
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-09T23:25:06.769Z · LW(p) · GW(p)
There is no need for dualism, if we assume that mathematics is all there is, and that consciousness is a property of certain mathematical objects. "Never to see it whole" makes perfect sense, since why would a part be able to see the whole as a whole?
To put it another way, why do you infer a physical world, instead of a mathematical world, from your observations? Is there some reason why a pile of physical particles moving around in a certain pattern can cause a conscious experience, whereas that pattern as an abstract mathematical object can't be conscious?
Replies from: SforSingularity, Vladimir_Nesov↑ comment by SforSingularity · 2009-09-11T18:18:48.797Z · LW(p) · GW(p)
why do you infer a physical world, instead of a mathematical world
What's the difference between these two? I think we are getting to the stage of philosophical abstraction where words lose all purchase. I have no idea what image "physical world, instead of a mathematical world" conjures up in Wei and Vladimir's minds, and the words "physical " and "mathematical" don't seem to help me.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-12T18:32:08.230Z · LW(p) · GW(p)
My position is that "physical world" is meaningless, and the question was a rhetorical one that I asked because I thought Nesov was thinking in terms of a physical world.
Replies from: SforSingularity↑ comment by SforSingularity · 2009-09-12T21:18:57.132Z · LW(p) · GW(p)
I think it is reasonable to eliminate the phrase "physical world". "Hubble volume that we inhabit" seems to do most of the job that it did for me anyway.
↑ comment by Vladimir_Nesov · 2009-09-10T00:10:56.757Z · LW(p) · GW(p)
I can hardly do more than sound my vote, with a few details -- it's a huge debate, with intricate arguments on both sides. My emphasis is on sidestepping the confusion by staying at the level of natural phenomena. Saying that "everything is math" is not an explanation of what math is, in the sense of lawful processes in mathematicians' heads, and more generally in decision-making. There is a danger of losing track of the question.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-10T10:09:20.674Z · LW(p) · GW(p)
Saying that "everything is math" is not an explanation of what math is, in the sense of lawful processes in mathematicians' heads, and more generally in decision-making.
It seems fairly obvious that a mathematician's head is doing a physics computation, which is logically correlated with an abstract neural-network computation (representing its mind), which is logically correlated with whatever part of math that the mathematician is considering. "Everything is math" doesn't tell us the exact nature of those logical correlations, but neither does it hurt our attempt to find out, as far as I can tell.
Also, I don't understand what you mean by "staying at the level of natural phenomena" nor how that helps to "sidestepping the confusion".
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2009-09-10T12:53:10.731Z · LW(p) · GW(p)
It seems fairly obvious that a mathematician's head is doing a physics computation, which is logically correlated with an abstract neural-network computation (representing its mind), which is logically correlated with whatever part of math that the mathematician is considering.
My point is that you don't need to make that last step, saying that process in the head is related to some abstract math. Instead, take two processes in two heads, and relate them directly, through the physics stuff.
To make an analogy, when you see two similar plants, it's confusing to talk about them being instances of the same platonic plant. Instead, by saying that they are similar, you mean that you formed certain representations of them in your own mind, and the representations considerably match: it's a concrete operation that is performed by one who recognizes the connection.
With math, relating processes (or formulas) through denotational semantics has a danger of losing track of the procedure that relates them, which can in some cases be unfeasible, and limitations on which may be important. Some things you can't even pinpoint to the semantics: are these two programs equal, in the sense of producing the same results for the same inputs? That is, what are those mathematical objects that correspond to each of them? You'll never know, and thus the question is effectively meaningless.
Interaction between specific details of implementation is part of decision-making as well as of the decisions themselves. Introducing abstract representation that abstracts away the details in unspecified fashion and gets communicated through the ether may confuse the situation.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-10T16:07:58.106Z · LW(p) · GW(p)
Ok, that's much clearer, and while I don't know if I agree with you completely, there's nothing you said that I object to.
I think confusion arose in the first place because you interpreted "platonic computation" to mean the denotational semantics of a computation, whereas Eliezer (and others) were using it to refer to the "abstract neural-network computation" as opposed to the "physics computation" involving wavefunctions and such, or the "physical world" with physical particles/wavefunctions (whatever that means).
comment by Scott Alexander (Yvain) · 2009-09-08T09:03:15.315Z · LW(p) · GW(p)
Thanks for this sequence. I wasn't really able to follow some of the other decision theory posts, but this is very clear, ties a lot of things together, and finally gives me a good handle on what a lot of people are talking about.
comment by [deleted] · 2009-09-07T08:00:04.625Z · LW(p) · GW(p)
Stupid question time: Why are all the agents only "surgically setting" nodes with no parents? Is that a coincidence, or is it different in a significant way from the sunniness example?
Replies from: AnnaSalamon, tut↑ comment by AnnaSalamon · 2009-09-07T08:46:04.282Z · LW(p) · GW(p)
Good question.
If we're surgically setting a decision node in a Bayes net to a given value (e.g., setting the "my action" node to "one-box"), we always imagine snipping any parents of that node, so that the node can just be arbitrarily set, and setting the node to a particular value does not affect our probability distribution on any siblings of that node.
So, we could add parents in the graphs if we want, but we'd basically be ignoring them in our decision procedure.
This means that in effect, an actions-CSA must (after conditionalizing on its information) view its action as uncorrelated with the state of any of the rest of the world, except for the children/effects of its action. (For example, it must view its action as uncorrelated with Omega's belief about its action.)
Similarly, an innards-CSA must (after conditionalizing on its information) view its innards as uncorrelated with everything that is not a physical effect of its innards, such as Clippy's innards.
Similarly, a timeless, aka algorithm-output, CSA must (after conditionalizing on its information)view its algorithm output as uncorrelated with everything that is not a child of the "its algorithm" node, such as perhaps (depending on its architecture) the output of similar algorithms.
Replies from: None↑ comment by [deleted] · 2009-09-07T16:02:53.476Z · LW(p) · GW(p)
Thanks, that makes sense. I was thinking that the diagrams represented all the nodes that the agents looked at, and that based on what nodes they saw they would pick one to surgically set. I didn't realize they represented the result of setting a node.
Follow-up stupid questions:
- Do all the agents start with the same graph and just pick different surgery points, or is it a combination of starting with different nodes and picking different nodes?
- If you put "innards" and "platonic" on the same graph (for any reason) what does that look like?
↑ comment by tut · 2009-09-07T16:34:30.656Z · LW(p) · GW(p)
- Do all the agents start with the same graph and just pick different surgery points, or is it a combination of starting with different nodes and picking different nodes?
- If you put "innards" and "platonic" on the same graph (for any reason) what does that look like?
They have different graphs, but the one necessary difference is the node that they do surgery on.
Presumably you would remove the arrow from platonic algorithm to your action and add arrows from platonic algorithm to your innards and from your innards to your actions.
comment by jimmy · 2009-09-06T19:01:39.231Z · LW(p) · GW(p)
I think a lot of the confusion about these types of decision theory problems has to do with not not everyone thinking about the same problem even when it seems like they are.
For example, consider the problem I'll call 'pseudo newcombs problem'. Omega still gives you the same options, and history has proven a strong correlation between peoples choices and its predictions.
The difference is that instead of simulating the relevant part of your decision algorithm to make the prediction, Omega just looks to see whether you have a blue dot or a red dot on your forehead- since a red dot has been a perfect indicator of a mental dysfunction that makes the response to every query "one box!" and blue dot has been a perfect indicator of a functioning brain. In addition, all people with working brains have chosen two boxes in the past.
If I understand correctly, all decision theories discussed will two box here, and rightly so- choosing one box doesn't cause Omega to choose differently since that decision was determined solely by the color of your dot.
People that say to two box on Newcomblike problems think of this type of Omega, since sufficiently detailed simulations aren't the first thing that come to mind- indicators of broken minds do.
For the one shot PD, it seems like something similar is happening. Cooperating just doesn't 'seem' right to me most of the time, but it's only because I'd have a hard time believing the other guy was running the same algorithm.
I had an interesting dream where I was copied recently, and it made cooperation on one shot PD a lot more intuitive. Even when trued, I'd cooperate with that guy, no question about it.
Replies from: Eliezer_Yudkowsky, AnnaSalamon↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-06T20:36:38.211Z · LW(p) · GW(p)
For the one shot PD, it seems like something similar is happening. Cooperating just doesn't 'seem' right to me most of the time, but it's only because I'd have a hard time believing the other guy was running the same algorithm.
Do you think that the other guy is thinking the same thing, and reasoning the same way? Or do you think that the other will probably decide to cooperate or defect on the PD using some unrelated algorithm?
My main reason for potentially defecting on the true PD against another human - note the sheer difficulty of obtaining this unless the partner is Hannibal with an imminently lethal wound - would be my doubts that they were actually calculating using a timeless decision theory, even counting someone thinking about Hofstadterian superrationality as TDT. Most people who've studied the matter in college have been taught that the right thing to do is to defect, and those who cooperate on instinct are running a different algorithm, that of being honorable.
But it'd be pretty damn hard in real life to put me into a literally one-shot, uncoordinated, no-communication, true PD where I'm running TDT, the other person is running honor with no inkling that I'm TDT, and the utilities at stake outweigh that which constrains me not to betray honorable people. It deserves a disclaimer to the effect of "This hypothetical problem is sufficiently different from the basic conditions of real life that no ethical advice should be taken from my hypothetical answer."
Replies from: jimmy, Nick_Tarleton↑ comment by jimmy · 2009-09-07T18:04:40.903Z · LW(p) · GW(p)
Do you think that the other guy is thinking the same thing, and reasoning the same way? Or do you think that the other will probably decide to cooperate or defect on the PD using some unrelated algorithm?
The latter. I haven't thought about this enough be comfortable knowing how similar his algorithm must be in order to cooperate, but if I ultimately decided to defect it'd be because I thought it qualified as sufficiently different.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-07T19:04:34.048Z · LW(p) · GW(p)
So you fully expect in real life that you might defect and yet see the other person cooperate (with standard ethical disclaimers about how hard it is to true the PD such that you actually prefer to see that outcome).
Replies from: jimmy↑ comment by jimmy · 2009-09-07T20:30:16.856Z · LW(p) · GW(p)
Yes, that's correct. I also currently see a significant probability of choosing to cooperate and finding out that the other guy defected on me. Should I take your response as evidence to reconsider? As I said before, I don't claim to have this all sorted out.
As to your disclaimer, it seems like your impression says that it's much harder to true PD than mine says. If you think you can make the thing truly one shot without reputational consequences (which may be the hard part, but it seems like you think its the other part), then it's just a question of setting up the payoff table.
If you don't have personal connections to the other party, it seems that you don't care any more about him than the other 6 billion people on earth. If you can meet those conditions, even a small contribution to fighting existential risks (funded by your prize money) should outweigh anything you care about him.
↑ comment by Nick_Tarleton · 2009-09-06T21:14:11.659Z · LW(p) · GW(p)
But it'd be pretty damn hard in real life to put me into a literally one-shot, uncoordinated, no-communication, true PD where I'm running TDT, the other person is running honor with no inkling that I'm TDT, and the utilities at stake outweigh that which constrains me not to betray honorable people.
Mostly because of the "one-shot, uncoordinated, no-communication, true... utilities at stake outweigh" parts, I would think. The really relevant question conditions on those things.
↑ comment by AnnaSalamon · 2009-09-06T20:20:38.556Z · LW(p) · GW(p)
If I understand correctly, all decision theories discussed will two box here, and rightly so- choosing one box doesn’t cause Omega to choose differently since that decision was determined solely by the color of your dot.
Depending on the set-up, “innards-CSAs" may one-box here. Innards-CSAs go back to a particular moment in time (or to their creator’s probability distribution) and ask: “if I had been created at that time, with a (perhaps physically transparent) policy that would one-box, would I get more money than if I had been created with a (perhaps physically transparent) policy that would two-box?”
If your Omega came to use the colored dots in its prediction because one-boxing and two-boxing was correlated with dot-colors, and if the innards-CSA in question is programmed to do its its counterfactual innards-swap back before Omega concluded that this was the correlation, and if your innards-CSA ended up copied (perhaps with variations) such that, if it had had different innards, Omega would have ended up with a different decision-rule... then it will one-box.
And “rightly so” in the view of the innards-CSA... because, by reasoning in this manner, the CSA can increase the odds that Omega has decision-rules that favor its own dot-color. At least according to its own notion of how to reckon counterfactuals.
Replies from: Eliezer_Yudkowsky, jimmy↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-06T20:30:01.904Z · LW(p) · GW(p)
Depending on your beliefs about what computation Omega did to choose its policy, the TDT counterfactual comes out as either "If things like me one-boxed, then Omega would put $1m into box B on seeing a blue dot" or "If things like me one-boxed, then Omega would still have decided to leave B empty when seeing a blue dot, and so if things like me one-boxed I would get nothing."
↑ comment by jimmy · 2009-09-07T18:15:25.168Z · LW(p) · GW(p)
I see your point, which is why I made sure to write "In addition, all people with working brains have chosen two boxes in the past."
My point is that you can have situations where there is a strong correlation so that Omega nearly always predicts correctly, but that Omega's prediction isn't caused by the output of the algorithm you use to compute your decisions, so you should two box.
The lack of effort to distinguish between the two cases seems to have generated a lot of confusion (at least it got me for a while).
comment by IlyaShpitser · 2009-09-07T19:13:08.369Z · LW(p) · GW(p)
The description of Pearl's counterfactuals in this post isn't entirely correct, in my opinion.
Your description of the "sunny day beachgoers" statement is describing an interventional distribution (in other words something of the form P(y|do(x))).
The key difference between interventions and counterfactuals is that the former are concerned with a single possible world (after an intervention), while the latter are concerned with multiple hypothetical worlds simultaneously.
Example of a statement about an intervention (causal effect): "I am about to take an aspirin. Will my headache go away?" This is just asking about P(headache|do(aspirin)).
Example of a counterfactual statement: "I took an aspirin an hour ago and my headache is gone. Would I still suffer a headache had I not taken an aspirin?" This is asking about a counterfactual distribution which is denoted in Pearl's notation by P(headache (subscript) no aspirin | no headache, aspirin). Here the variable with a subscript (headache (subscript) no aspirin) corresponds to headache in the post-intervention world after do(no aspirin). This expression is a 'true' counterfactual since it contains a conflict between values observed in the 'true world' where events occurred (the values past the conditioning bar), and the 'hypothetical world' where we intervene.
comment by cheesedaemon · 2009-09-07T20:41:05.373Z · LW(p) · GW(p)
Can anyone explain why Goodman considers this statement to be true:
Hence `If that piece of butter had been heated to 150°F, it would not have melted.' would also hold.
Replies from: pengvado, saturn↑ comment by saturn · 2009-09-07T22:05:55.603Z · LW(p) · GW(p)
"If that piece of butter had been heated to 150°F, it would not have melted" can be read as "that piece of butter has not been heated to 150°F, or it did not melt, or both," or "it is not the case that both that piece butter has melted and that piece of butter has been heated to 150°F."
comment by Psy-Kosh · 2009-09-07T08:19:47.772Z · LW(p) · GW(p)
How does one then take into account the fact that one's abstract platonic algorithm is implemented on physical hardware that may end up occasionally causing an accidental bitflip or other corruption, thus not actually computing the answer that the algorithm you think you're computing actually computes?
My INITIAL (sleep deprived) thought is a hybrid of options 2,3, and a form of EDT in which one would say "If I output X, then that would be evidence that abstract platonic computation outputs X, which would then also cause other implementation/model of that computation to output X", but I'm not entirely sure this is wise.
ie, I'm thinking "abstract platonic computation" has arrows pointing toward "my innards" and "omega's implementation of its model of me". and "my innards" control, well, my action and "omega's model of me" controls, well, omega's prediction of me.
EDIT: nevermind my initial solution, it's wrong. I think the Right Way would be more like what I suggested below, with "my innards" pointing to a "selector node" that represents something that selects which abstract computation is actually computed, and THAT links to the output.
Replies from: SilasBarta, tut↑ comment by SilasBarta · 2009-09-07T16:09:15.422Z · LW(p) · GW(p)
How does one then take into account the fact that one's abstract platonic algorithm is implemented on physical hardware that may end up occasionally causing an accidental bitflip or other corruption, thus not actually computing the answer that the algorithm you think you're computing actually computes?
Omega's simulations of you show this happening rarely enough that its expected actions out of you are the same as the abstract platonic algorithm, presumably.
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-07T17:29:45.288Z · LW(p) · GW(p)
Sorry, I was sort of asking a general question and putting it in the terms of this particular problem at the same time. I should have been clearer.
What I meant was "I like TDC, but I think it's insufficient, it doesn't seem to easily deal with the fact that the physical implementation of the abstract computation can potentially end up having other things happen that result in something OTHER than what the ideal platonic would say should happen"
I think though that my initial suggestion might not have been the right solution. Instead, maybe invert it, say "actual initial state of hardware/software/etc" feeds into "selector that selects a platonic algorithm" which then feeds into "output"... then, depending on how you want to look at it, have other external stuff, radiation, damage to hardware occurring mid computation, etc etc etc have causal inputs into those last two nodes. My initial thought would be the second to last node.
The idea here being that such errors change which platonic computation actually occurred.
Then you can say stuff in terms in decisions being choosing "what does the abstract computation that I am at this moment output?", with the caveat of "but I'm not absolutely certain that I am computing the specific algorithm that I think I am"... so that is where one could place the uncertainty that arises from hardware bugaboos, etc etc. (Also, logical uncertainty perhaps about if your code actually implements algorithms that you think it does, if that's relevant.)
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-08T16:07:13.952Z · LW(p) · GW(p)
I'm still having trouble seeing what troubles you. Yes, the physical hardware might mess up the attempt to implement the Platonic algorithm. So, there's a probability of Omega guessing wrong, but if Omega picks your most likely action, it will still better approximate it by just using the platonic algorithm instead of the platonic algorithm plus noise.
Also, as Eliezer_Yudkowsky keeps pointing out, you don't want an agent that computes "what does the abstract computation that I am at this moment output?" because whatever it picks, it's correct.
with the caveat of "but I'm not absolutely certain that I am computing the specific algorithm that I think I am"... so that is where one could place the uncertainty that arises from hardware bugaboos, etc etc.
AnnaSalamon didn't mention this, but under Pearl's model of causal networks, each node is implicitly assumed to have an "external unknown factor" parent (all of such factors assumed independent of each other), so this uncertaintly is already in the model. So, like any other node, the agent takes this kind of uncertainty into account.
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-08T17:50:14.084Z · LW(p) · GW(p)
What I meant is that for TDT, the agent, for lack of a better word, decides what the outcome for a certain abstract algorithm is. (Specifically, the abstract algorithm that it is using to decide that.)
The agent can reason about other systems computing the related algorithms producing related output, so it knows that what it chooses will be reflected in those other systems.
But, I'd want it to be able to take into account the fact that the algorithm it's actually computing is not necessarally the algorithm it thinks it is computing. That is, due to hardware error or whatever, it may produce an output other than what the abstract calculation it thought it was doing would have produced... thus breaking the correlation it was assuming.
ie, I just want some way for the agent to be able to take into account in all this the possibility of errors in the hardware and so on, and in the raw TDT there didn't seem to be a convenient way to do that. Adding in an extra layer of indirection, setting up the causal net as saying "my innards" control a selector which determines which abstract algorithm is actually being computed would SEEM to fix that in a way that, to me, seems to actually fit what's actually going on.
If we assume a weaker "Omega", that can't predict, say, a stray cosmic ray hitting you and causing you to make a 1 bit error or whatever in your decision algorithm, even though it has a copy of your exact algorithm, then that's where what I'm talking about comes in. In that case, your output would derive from the same abstract computation as Omega's prediction for your output.
Imagine the set of all possible algorithms feed into a "my selector node", and also into omega's "prediction selector node"... then "my innards" are viewed as selecting which of those determine the output. But a stray cosmic ray comes in, influences the computation... that is, influences which algorithm the "selector" selects.
A stray cosmic ray can't actually alter an abstract platonic algorithm. Yet it is able to influence the output. So we have to have some way of shoving into TDT the notion of "stuff that actually physically messes with the computation"
Does that clarify what I'm saying here, or am I describing it poorly, or am I just really wrong about all this?
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-08T18:29:55.063Z · LW(p) · GW(p)
Okay, I think I see what you're saying: There is the possibility of something making your action diverge from the Platonic computation you think you're instantiating, and that would interfere with the relationship between the choice you make and the Platonic algorithm.
On top of that, you say that there should be a "My innards" node between the platonic algorithm node and the action node.
However, you claim Omega can't detect this kind of interference. Therefore, the inteference is independent of the implicit interference with all the other nodes and does not need to be represented. (See my remark about how Pearl networks implicitly have an error term parent for every node, and only need to be explicity represented when two or more of these error parents are not independent.)
Also, since it would still be an uninterrupted path from Platonic to choice, the model doesn't gain anything by this intermediate steps; Pearl nets allow you to collapse these into one edge/node.
And, of course, it doesn't make much of a difference for Omega's accuracy anyway...
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-08T18:57:19.641Z · LW(p) · GW(p)
Yeah, I think you've got the point of the problem I'm trying to deal with, though I'm not sure I communicated my current view of the structure of what the solution should be. For one thing, I said that my initial plan, platonic algorithm pointing to innards pointing to output was wrong.
There may potentially be platonic algorithm pointing to innards representing the notion of "intent of the original programmer" or whatever, but I figured more importantly is an inversion is that.
Ie, start with innards... the initial code/state/etc "selects" a computation from the platonic space of all possible computations. But, say, a stray cosmic ray may interfere with the computation. This would be analogous to an external factor poking the selector, shifting which abstract algorithm is the one being computed. So then "omega" (in quotes because am assuming a slightly less omniscient being than usually implied by the name) would be computing the implications of one algorithm, while your output would effectively be the output if a different algorithm. So that weakens the correlation that justifies PD coopoperation, Newcomb one-boxing, etc etc etc etc...
I figure the "innards -> selector from the space of algorithms" structure would seem to be the right way to represent this possibility. It's not exactly just logical uncertainty.
So, I don't quite follow how this is collapsible. ie, It's not obvious to me that the usual error terms help with this specific issue without the extra node. Unless, maybe, we allow the "output" node to be separate from the "algorithm" node and let us interpret the extra uncertianty term from the output node as something that (weakly) decouples the output from the abstract algorithm...
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-09T14:58:20.456Z · LW(p) · GW(p)
So then "omega" (in quotes because am assuming a slightly less omniscient being than usually implied by the name) would be computing the implications of one algorithm, while your output would effectively be the output if a different algorithm. So that weakens the correlation that justifies PD coopoperation, Newcomb one-boxing, etc etc etc etc...
Yes, but like I said the first time around, this would be a rare event, rare enough to be discounted if all that Omega cares about is maximizing the chance of guessing correctly. If Omega has some other preferences over the outcomes (a "safe side" it wants to err on), and if the chance is large enough, it may have to change its choice based on this possibility.
So, here's what I have your preferred representation as:
"Platonic space of algorithms" and "innards" both point to "selector" (the actual space of algorithms influences the selector, I assume); "innards" and "Platonic space" also together point to "Omega's prediction", but selector does not, because your omega can't see the things that can cause it to err. Then, "Omega's prediction" points to box content and selector points to your choice. Then, of course, box content and your choice point to payout.
Further, you say the choice the agent makes is at the innards node.
Is that about right?
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-09T15:17:54.125Z · LW(p) · GW(p)
Even if rare, the decision theory used should at least be able to THINK ABOUT THE IDEA of a hardware error or such. Even if it dismisses it as not worth considering, it should at least have some means of describing the situation. ie, I am capable of at least considering the possibility of me having brain damage or whatever. Our decision theory should be capable of no less.
Sorry if I'm unclear here, but my focus isn't so much on omega as trying to get a version of TDT that can at least represent that sort of situation.
You seem to more or less have it right. Except I'd place the choice more at the selector or at the "node that represents the specific abstract algorithm that actually gets used"
As per TDT, choose as if you get to decide what the output for the abstract algorithm should be. The catch is that here there's a bit of uncertainty as to which abstract algorithm is being computed. So if, due to cosmic ray striking and causing a bitflip at a certain point in the computation, you end up actually computing algorithm 1B while omega models you as being algorithm 1A, then that'd be potentially a weakening of the dependence. (Again, just using the Newcomb problem simply as a way of talking about this.)
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-09T15:37:12.887Z · LW(p) · GW(p)
You seem to more or less have it right. Except I'd place the choice more at the selector or at the "node that represents the specific abstract algorithm that actually gets used".
Okay, so there'd be another node between "algorithm selector" and "your choice of box"; that would still be an uninterrupted path (chain) and so doesn't affect the result.
The problem, then, is that if you take the agent's choice as being at "algorithm selector", or any descendant through "your choice of box", you've d-separated "your choice of box" from "Omega's prediction", meaning that Omega's prediction is conditionally independent of "your choice of box", given the agent's choice. (Be careful to distinguish "your choice of box" from where we're saying the agent is making a choice.)
But then, we know that's not true, and it would reduce your model to the "innards CSA" that AnnaSalamon gave above. (The parent of "your choice of box" has no parents.)
So I don't think that's an accurate representation of the situation, or consistent with TDT. So the agent's choice must be occuring at the "innards node" in your graph.
(Note: this marks the first time I've drawn a causal Bayesian network and used the concept of d-separation to approach a new problem. w00t! And yes, this would be easier if I uploaded pictures as I went.)
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-09T16:25:18.415Z · LW(p) · GW(p)
Okay, so there'd be another node between "algorithm selector" and "your choice of box";
Not sure where you're getting that extra node from. The agent's choice is the output of the abstract algorithm they actually end up computing as a result of all the physical processes that occur.
Abstract algorithm space feeds into both your algorithm selector node and the algorithm selector node in "omega"'s model of you. That's where the dependence comes from.
So given logical uncertainty about the output of the algorithm, wouldn't they be d-connected? They'd be d-separated if the choice was already known... but if it was, there'd be nothing left to choose, right? No uncertainties to be dependent on each other in the first place.
Actually, maybe I ought draw a diagram of what I have in mind and upload to imgur or whatever.
Replies from: SilasBarta, SilasBarta↑ comment by SilasBarta · 2009-09-10T04:24:05.263Z · LW(p) · GW(p)
Alright, after thinking about your points some more, and refining the graph, here's my best attempt to generate one that includes your concerns: Link.
{kind=link}
Per AnnaSalamon's convention, the agent's would-node-surgery is in a square box, with the rest elliptical and the payoff octagonal. Some nodes included for clarity that would normally be left out. Dotted lines indicate edges that are cut for surgery when fixing "would" node. One link I wasn't sure about has a "?", but it's not that important.
Important points: The cutting of parents for the agent's decision preserves d-connection between box choice and box content. Omega observes innards and attempted selection of algorithm but retains uncertainty as to how the actual algorithm plays out. Innards contribute to hardware failures to accurately implement algorithm (as do [unshown] exogenous factors).
And I do hope you follow up, given my efforts to help you spell out your point.
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-10T04:31:27.964Z · LW(p) · GW(p)
Just placing this here now as sort of a promise to follow up. Just that I'm running on insufficient sleep, so can only do "easy stuff" at the moment. :) I certainly plan on following up on our conversation in more detail, once I get a good night's sleep.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-10T05:03:09.936Z · LW(p) · GW(p)
Understood. Looking forward to hearing your thoughts when you're ready :-)
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-10T21:08:10.375Z · LW(p) · GW(p)
Having looked at your diagram now, that's not quite what I have in mind. For instance, "what I attempt to implement" is kinda an "innards" issue rather than deserving a separate box in this context.
Actually, I realized that what I want to do is kind of weird, sort of amounting to doing surgery on a node while being uncertain as to what node you're doing the surgery on. (Or, alternately, being uncertain about certain details of the causal structure). I'm going to have to come up with some other notation to represent this.
Before we continue... do you have any objection to me making a top level posting for this (drawing out an attempt to diagram what I have in mind and so on?) frankly, even if my solution is complete nonsense, I really do think that this problem is an issue that needs to be dealt with as a larger issue.
Begun working on the diagram, still thinking out though exact way to draw it. I'll probably have to use a crude hack of simply showing lots of surgery points and basically saying "do surgery at each of these one at a time, weighing the outcome by the probability that that's the one you're actually effectively operating on" (This will (hopefully) make more sense in the larger post)
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-10T21:28:11.407Z · LW(p) · GW(p)
Having looked at your diagram now, that's not quite what I have in mind. For instance, "what I attempt to implement" is kinda an "innards" issue rather than deserving a separate box in this context.
Grr! That was my first suggestion!
Actually, I realized that what I want to do is kind of weird, sort of amounting to doing surgery on a node while being uncertain as to what node you're doing the surgery on. (Or, alternately, being uncertain about certain details of the causal structure). I'm going to have to come up with some other notation to represent this. ... I'll probably have to use a crude hack of simply showing lots of surgery points and basically saying "do surgery at each of these one at a time, weighing the outcome by the probability that that's the one you're actually effectively operating on"
Not that weird, actually. I think you can do that by building a probabilistic twin network. See the good Pearl summary, slide 26. Instead of using it for a counterfactual, surgically set a different node in each subnetwork, and also the probabilities coming from the common parent (U in slide 26) to represent the probability of each subnetwork being the right one. Then use all terminal nodes across both subnetworks as the outcome set for calculating probability.
Though I guess that amounts to what you were planning anyway. Another way might be to use multiple dependent exogenous variables that capture the effect of cutting one edge when you thought you were cutting another.
Before we continue... do you have any objection to me making a top level posting for this
No problem, just make sure to link this discussion.
Replies from: Psy-Kosh↑ comment by Psy-Kosh · 2009-09-10T22:04:57.538Z · LW(p) · GW(p)
Grr! That was my first suggestion!
*clicks first link*
And I said that was more or less right, didn't I? ie, "what I attempt to implement" ~= "innards", which points to "selector"/"output", which selects what actually gets used.
Looking through the second link (ie, the slides) now
↑ comment by SilasBarta · 2009-09-09T17:15:43.675Z · LW(p) · GW(p)
Okay, I think there are some terminological issues to sort out here, resulting from our divergence from AnnaSalamon's original terminology.
The discussion I thought we were having corresponds to the CSA's calculation of "woulds". And when you calculate a would, you surgically set the output of the node, which means cutting the links to its parents.
Is this where we are? Are you saying the "would" should be calculated from surgery on the "algorithm selector" node (which points to "choice of box")? Because in that case, the links to "algorithm selector" from "algorithm space" and "innards" are cut, which d-separates them. (ETA: to clarify: d-separates "box choice" from Omega and its descendants.)
OTOH, even if you follow my suggestion and do surgery on "innards", the connection between "box choice" and "omega's prediction" is only a weak link -- algorithm space is huge.
Perhaps you also want an arrow from "algorithm selector" to "omega's prediction" (you don't need a separate node for "Omega's model of your selector" because it chains). Then, the possible difference between the box choice and omega's prediction emerges from the independent error term pointing to box choice (which accounts for cosmic rays, hardware errors, etc.) There is a separate (implicit) "error parent" for the "Omega's prediction" node, which accounts for shortcomings of Omega's model.
This preserves d-connection (between box choice and box content) after a surgery on "algorithm selector". Is that what you're aiming for?
(Causal Bayes nets are kinda fun!)
comment by timtyler · 2009-09-06T09:40:06.231Z · LW(p) · GW(p)
Agents do not need to calculate what would have happened, if something impossible had happened.
They need to calculate the consequences of their possible actions.
These are all possible, by definition, from the point of view of the agent - who is genuinely uncertain about the action she is going to take. Thus, from her point of view at the time, these scenarios are not "counterfactual". They do not contradict any facts known to her at the time. Rather they all lie within her cone of uncertainty.
Replies from: Nick_Tarleton, PhilGoetz↑ comment by Nick_Tarleton · 2009-09-06T16:46:40.100Z · LW(p) · GW(p)
These are all possible, by definition, from the point of view of the agent
... but nevertheless, all but one are, in fact, logically impossible.
Replies from: Alicorn, timtyler↑ comment by Alicorn · 2009-09-06T16:59:23.279Z · LW(p) · GW(p)
That's the difference between epistemic and metaphysical possibility. Something can be epistemically possible without being metaphysically possible if one doesn't know if it's metaphysically possible or not.
Replies from: Nick_Tarleton↑ comment by Nick_Tarleton · 2009-09-06T18:25:36.827Z · LW(p) · GW(p)
Thanks, that's exactly what I was trying to say.
Replies from: timtyler↑ comment by timtyler · 2009-09-07T19:04:43.188Z · LW(p) · GW(p)
According to the MWI different outcomes to a decision are epistemic and metaphysical possibilities. At least I think they are - it is hard to say for sure without a definition of what the concept of "metaphysical possibility" refers to.
To explain what I mean, according to the conventional understanding of the MWI, the world splits. There are few pasts, and many futures. e.g. see:
http://www.hedweb.com/everett/everett.htm#do
http://www.hedweb.com/everett/everett.htm#split
Thus, from any starting position, there are many possible futures - and that's true regardless of what any embedded agents think they know or don't know about the state of the universe.
↑ comment by timtyler · 2009-09-06T17:42:25.578Z · LW(p) · GW(p)
What do you mean?
Are you perhaps thinking of a type of classical determinism - that pre-dates the many-worlds perspective...?
Replies from: Nick_Tarleton↑ comment by Nick_Tarleton · 2009-09-06T18:25:18.274Z · LW(p) · GW(p)
I'm thinking of determinism. I don't know what you mean by "classical" or in what way you think many-worlds is non-"classically"-deterministic (or has any bearing on decision theory).
Replies from: timtyler↑ comment by timtyler · 2009-09-06T19:22:10.405Z · LW(p) · GW(p)
If all your possible actions are realised in a future multiverse of possibilities, it is not really true that all but one of those actions is "logically impossible" at the point when the decision to act is taken.
Many-worlds doesn't have a lot to do with decision theory - but it does bear on your statement about paths not taken being "impossible".
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-06T20:26:51.697Z · LW(p) · GW(p)
Actually, the way that TDT defines a decision, only one decision is ever logically possible, even under many-worlds. Versions of you that did different things must have effectively computed a different decision-problem.
Replies from: timtyler↑ comment by timtyler · 2009-09-06T20:49:52.560Z · LW(p) · GW(p)
Worlds can split before a decision - but they can split 1 second before, 1 millisecond before - or while the decision to be made is still being evaluated.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-06T21:01:50.457Z · LW(p) · GW(p)
So? Versions of you that choose different strategies must have ended up performing different computations due to splits at whatever time, hence, under TDT, one decision-process still only makes one decision.
Replies from: timtyler↑ comment by timtyler · 2009-09-06T22:14:26.248Z · LW(p) · GW(p)
If the world splits during the decision process, there is no need for any of the resulting divided worlds to be "logically impossible".
The idea that all worlds but one are impossible is basically pre-quantum thinking. The basic idea of the MWI is that the world branches - and so there are many future possibilities. Other interpretations reach the same conclusion via other means - usually indeterminacy.
Replies from: jimmy, Nubulous↑ comment by jimmy · 2009-09-07T18:25:45.155Z · LW(p) · GW(p)
If you flip a quantum coin you may end up with a dead cat and an alive cat in different Everett branches, but that is not what we're talking about.
What we're talking about is that if you're decision algorithm outputs a different answer, it's a different algorithm regardless of where this algorithm is implemented. Same as if you're getting a result of 5, you're not calculating 1+1 anymore- you're doing something else. You may be ignorant of the output of "1+1", but it's not mathematically possible for it to be anything other than 2.
Replies from: timtyler↑ comment by timtyler · 2009-09-07T18:54:05.688Z · LW(p) · GW(p)
I can see what you are talking about - but it isn't what was originally being discussed. To recap, that was whether different actions are logically possible.
That seems like the same question to whether it is logically possible to have different worlds arising from the same initial conditions just before the decision was made - and according to the MWI, that is true: worlds branch.
The actions are the result of different calculations, sure - but the point is that before the decision was made, the world was in one state, and after it was made, it is divided into multiple worlds, with different decision outcomes in different worlds.
I classify that as meaning that multiple actions are possibilities, from a given starting state. The idea that only one path into the future is possible at any instant in time is incorrect. That is what quantum theory teaches - and it isn't critical which interpretation you pick.
↑ comment by Nubulous · 2009-09-08T14:29:59.345Z · LW(p) · GW(p)
I think you may be confusing the microstate and macrostate here - the microstate may branch every-which-way, but the macrostate, i.e. the computer and its electronic state (or whatever it is the deciding system is), is very highly conserved across branching, and can be considered classically deterministic (the non-conserving paths appear as "thermodynamic" misbehaviour on the macro scale, and are hopefully rare). Since it is this macrostate which represents the decision process, impossible things don't become possible just because branching is occurring.
Replies from: timtyler↑ comment by timtyler · 2009-09-08T16:55:07.056Z · LW(p) · GW(p)
For the other perspective see: http://en.wikipedia.org/wiki/Butterfly_effect
Small fluctuations are often rapidly magnified into macroscopic fluctuations.
Computers sometimes contain elements designed to accelerate this process - in the form of entropy generators - which are used to seed random number generators - e.g. see:
I don't think anyone is talking about impossible things becoming possible. The topic is whether considered paths in a decision can be legitimately considered to be possibilities - or whether they are actually impossible.
↑ comment by PhilGoetz · 2011-04-02T20:10:25.898Z · LW(p) · GW(p)
Counterfactuals don't need to be about impossible things - and agents do calculate what would have happened, if something different had happened. And it is very hard to know whether it would have been possible for something different to happen.
The problem of counterfactuals is not actually a problem. Goodman's book is riddled with nonsensical claims.
What can Pearl's formalism accomplish, that earlier logics could not? As far as I can tell, "Bayes nets" just means that you're going to make as many conditional-independence assumptions as you can, use an acyclic graph, and ignore time (or use a synchronous clock). But nothing changes about the logic.
Replies from: timtyler, timtyler↑ comment by timtyler · 2011-04-02T20:52:25.728Z · LW(p) · GW(p)
What can Pearl's formalism accomplish, that earlier logics could not? As far as I can tell, "Bayes nets" just means that you're going to make as many conditional-independence assumptions as you can. But nothing changes about the logic.
I am not sure. I haven't got much from Pearl so far. I did once try to go through The Art and Science of Cause and Effect - but it was pretty yawn-inducing.
↑ comment by timtyler · 2011-04-02T20:36:07.350Z · LW(p) · GW(p)
I was replying to this bit in the post:
The problem of counterfactuals is the problem what we do and should mean when we we discuss what “would” have happened, “if” something impossible had happened
...and this bit:
Recall that we seem to need counterfactuals in order to build agents that do useful decision theory -- we need to build agents that can think about the consequences of each of their “possible actions”, and can choose the action with best expected-consequences. So we need to know how to compute those counterfactuals.
It is true that agents do sometimes calculate what would have happened if something in the past had happened a different way - e.g. to help analyse the worth of their decision retrospectively. That is probably not too common, though.
comment by whpearson · 2009-09-08T09:56:19.644Z · LW(p) · GW(p)
My problem with these formalisms is that they don't apply to real world problems. In that real world problems you can alter the network as well as altering the nodes.
For example you could have an innards altering program that could make innards that attempt to look at omega's innards and make a decision on whether to one-box or not based on that. This would form a loop in the network, what it would do to the correct strategy, I don't know.
In the real world this would not be able to be stopped. Sure you can say that it doesn't apply to the thought experiment but then you are divorcing the thought experiment from reality.