A Hypothetical Takeover Scenario Twitter Poll
post by Zvi · 2023-04-24T14:00:00.789Z · LW · GW · 9 commentsContents
Oh No Level the Playing Field a Bit Synthesis and Potential Cruxes Dangers of Rhetorical Generosity The Nanotech Problem Project [SPOILER ALERT] Paths Forward Fully Optional Re-Poll Since Why Not None 9 comments
I ran an experimental poll sequence on Twitter a few weeks back, on the subject of what would happen if a hostile ASI (Artificial Superintelligence) tried to take over the world and kill all humans, using only ordinary known techs.
The hope was that by exploring this, it would become more clear where people’s true objections and cruxes were. Surely, at least, one could establish that once the AI was fully an agent, fully uncontrolled, had a fully hostile goal, was definitively smarter and more capable than us and could scale, that we were obviously super dead? Or, if not, one could at least figure out what wrong intuitions were blocking that realization, and figure out what to do about that.
This post is an experiment as well. I wouldn’t say the results were a full success. I would say they were interesting enough that they’re worth writing up, if only as an illustration of how I am thinking about some of these questions and potential rhetorical strategies. If you’re not interested in that, it is safe to skip this one.
Oh No
Consider the following scenario:
- There come into existence an ASI (Artificial Super-Intelligence), defined here roughly as an AI system that is generically smarter than us, has all the cognitive capacities and skills any human has displayed on the internet, can operate orders of magnitude faster than us, and that can copy itself, and which is on the internet with the ability to interact and gather resources.
- That ASI decides to do something that would kill us – it wants a configuration of atoms in the universe that doesn’t involve any humans being alive. The AI does not love you, the AI does not hate you, you are composed of atoms it can use for something else and the AI’s goal is something else. Or maybe it does want everyone dead, who knows, that is also possible.
- The ASI kills us.
Many people, for a variety of reasons many of which are good, do not expect step one to happen any time soon, or do not expect step 2 to happen any time soon conditional on step 1 happening.
This post is not about how likely it is that steps 1 and 2 will happen. It is about:
Q: If steps 1 and 2 do happen – oh no! – how likely is it under various scenarios that step 3 happens, that we all die?
A remarkably common answer to this question is no, we will be fine.
I don’t understand this. To me you have so obviously already lost once:
- The ASI has is loose on the internet.
- The ASI has access to enough resources that it can use them to get more.
- The ASI is much faster than you and is smarter than you.
- The ASI wants you to lose.
It also seems obvious to me that such an AI would, if it desired to do so, in such a scenario, be able to kill all the people.
Yet people demand to know exactly how it would do this, or they won’t believe it.
Level the Playing Field a Bit
By default, in such a scenario, you should expect to lose, lose fast and lose hard, due to the ASI that is smarter and more capable than you doing some combination of
- Making itself even smarter and more capable repeatedly until it is God-like AI (RSI: recursive self-improvement).
- The ASI doing things that you didn’t know how to physically do at all because it understands physics better than you (nanotech, synthetic biology, engineered viruses, new chip designs, or perhaps something you didn’t even conceive of or think was physically possible) that upend the whole game board.
- The ASI using super-advanced manipulation techniques like finding signals that directly hijack human brains or motor functions, or new highly effective undetectable brainwashing techniques, or anything like that.
- The general version of this, something you were not smart enough to figure out.
Presumably, we can all agree that if one of these does indeed happen, on the heels of the first two steps, things look extremely bad for Team Humanity.
One can still reasonably be highly suspicious of such stories. One might think that RSI will not work because it runs into various limitations, that such advanced technologies are either not physically possible or not something an ASI would be able to instantiate. Or, simply, one might say that’s cheating, you can’t hand-wave away all the work by saying something magical happens.
A classic style of thought experiment, in such situations, is the result is robust to such objections. What would happen if we were super generous, and posited a world where all of the above was ruled out entirely?
Thus in this thought experiment:
- RSI, recursive self-improvement, doesn’t work, or the ASI refuses to do it. It can make copies of itself, and give itself more compute and resources, and that’s it.
- There are no fundamentally new technologies available to the ASI. Nanotech and synthetic biology are not feasible until After the End, ‘because of reasons.’ No mind control rays, no new chip designs.
- Humans can still do ordinary human R&D and incremental improvements. The AI can still benefit from or cause such improvements, if it can do that.
- The core plan the ASI uses needs to be a fully human-level, understandable plan.
- In fact, nothing too cute, let’s K.I.S.S. here and keep it simple.
You realize you lose anyway, right?
It is smarter than you. It gathers resources, compounds those gains into more resources, gets increasing amounts of control and capability in the world through deploying those resources, takes over, does what it wants. Which means you die.
Here is how I described this in my poll thread.
In this thread, take as given that there exists an Artificial Superintelligence (ASI) that is:
1. An agent.
2. Loose on the internet, knows all of it.
3. Smarter than humans.
4. Much faster than humans.
5. Can copy and instantiate itself, given compute.
6. Aims to kill us all.
Let’s limit this ASI to ‘concrete’ actions. It can’t or won’t do recursive self-improvement (RSI). No foom. It can’t or won’t do fundamental science or invent anything truly new on its own.
Instead it has to go with the very basic plan below. Because of reasons.
This ASI forms this non-brilliant very-basic plan:
1. Get more resources, including a lot of money.
2. Get people to agree to do what I want in exchange for money, or via other ways.
3. Accomplish things in the world.
4. Stop other ASIs from existing.
5. Accumulate more power.
6. If needed repeat mix of #1-#5.
7. When people notice during this, they don’t shut down the internet and ban computers Dune-style.
8. Have your people take control.
9. Do anything the ASI wants. Automate infrastructure.
10. Kill everyone.
I expect some of these steps to be ‘yes, of course’ and at least one to importantly NOT be that for many people, but I keep getting people doubting in places I did not anticipate, so it makes sense to check them all. Here goes.
(A) YES. Given previous steps otherwise work, this will work (>90%).
(B) PROBABLY. This step probably works (>50%), but might not (<90%).
(C) UNLIKELY. This step probably (>50%) doesn’t work.
(D) See results.
In my model, the step here that ‘does the work,’ is the pivotal act, and that was kind of ‘snuck in’ is the fourth one: Stop other ASIs from existing.
If you can’t stop other ASIs from existing, then those ASIs can fight back, and then it’s a ‘fair fight’ and you are in a different scenario. Once you can stop them, then it does not much matter how long things take to play out.
Whereas people will actually object to quite a few of these steps, quite often, including such objections as ‘it is on the internet, it cannot physically kill people.’ Which is of course patently absurd, of course an entity on the internet can kill people, it can (if nothing else) hire people to do physical things in the physical world that kill people.
Anyway, the poll results were revealing. Let’s start at the beginning.
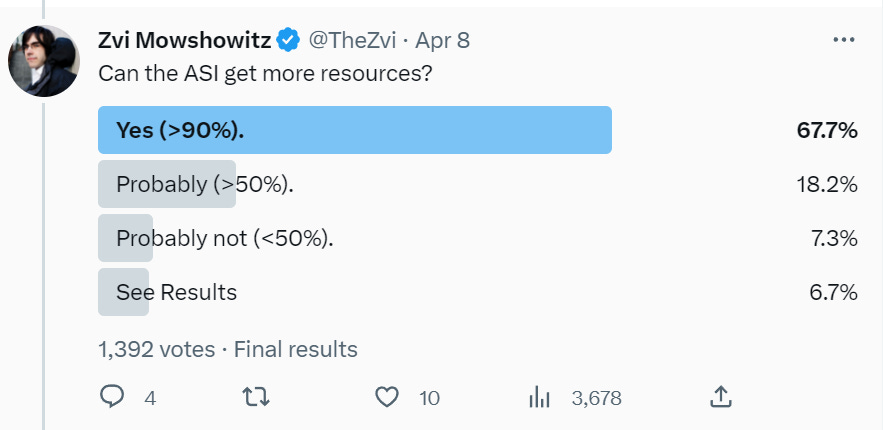
If you doubt this step, I don’t know what to tell you. A superintelligent agent, with every skill known to humanity running in super speed, and you’re not so confident it can make money? Still, this isn’t that far beyond lizardman constant territory, given how people actually interact with probabilities and the various ways one might misread the instructions.

More confidence than step one, I think for good reason. No matter their other motivations, people love to do things in exchange for money.

The obvious conclusion here is that you can’t actually get real conditional probabilities in a poll like this. This is essentially the same result as step #1. I take this to be people answering the question ‘could an ASI with resources use them to get more resources?’ rather than ‘given the ASI has already proven it can get resources, and humans can be hired, can it scale this once it has the ability to hire humans?’
Essentially, this is a background ‘AIs will never be able to actually do anything on their own’ resistance that rejects the premise of the scenario entirely – they don’t actually think this thing is meaningfully smarter and more capable – or is assuming a very different thought experiment in terms of world conditions (likely that the world contains many other ASIs).
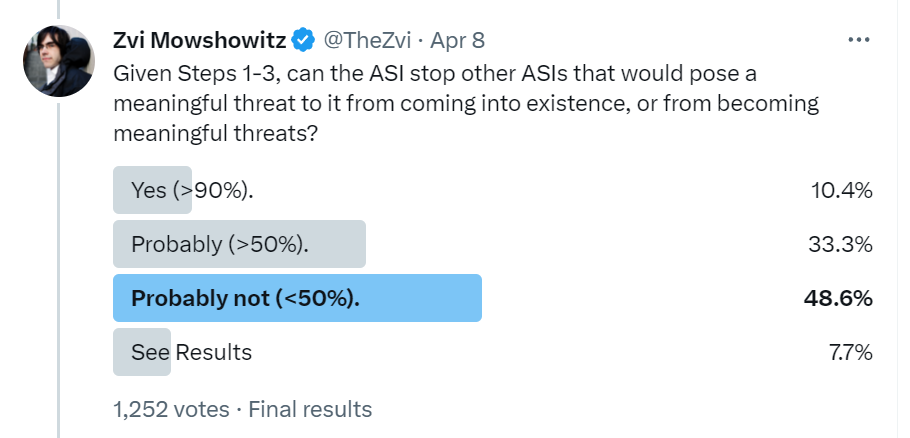
I was happy to see that this was indeed the most common objection. This is an entirely non-obvious step and the key to the whole plan – can this be pulled off in time? If not, everything changes.
Explicitly, from here on in, I said to assume we pulled this off, so…

In my brain this is a Free Square. Yes, of course, if you can acquire resources and make money, and you can hire people to do things, and you’re smart about it, and you can scale, you can get power. Seems rather silly to doubt this. Yet the doubt level substantially rises here.
Then it spikes quite a lot.
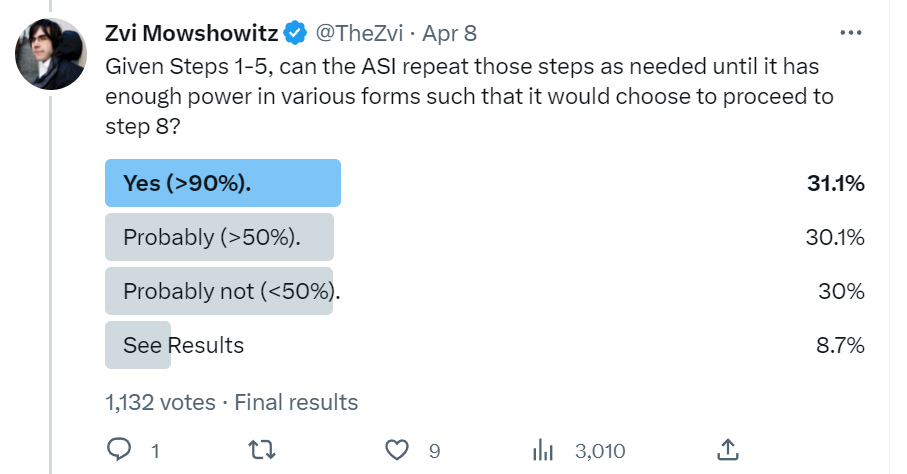
What are people imagining is the barrier to this? I’ve heard a few different ones.
One type of objection is that the AI couldn’t coordinate and cooperate sufficiently well with copies of itself, and it wouldn’t be able to track the various threads going on without copies, or various sorts of information-theoretic issues.
I would presume that functional decision theory would solve any cooperation issues, and that coordination would be difficult but that orders of magnitude of extra speed plus being very similar should be more than sufficient to solve such problems orders of magnitude better than existing corporations, governments and other organizations ever could. We have ‘proof of concept’ of such systems already, in infinitely harder conditions.
And even if that wasn’t true? Even a single copy is orders of magnitude faster than humans, so at minimum you can effectively have hundreds or thousands of copies of the boss running around managing things, and leave the rest as a normal human organization subject to that, with ability to do ‘concentration of force’ as needed anywhere at any time.
If the ASI can’t coordinate to pull this off, then real human organizations that do exist, overdeterminedly couldn’t exist. So I don’t really ‘get’ such objections.
Another type of objection is that there exist natural dynamics that prevent people from accumulating too much power, and they would work on the AI. Some such dynamics exist, as do dynamics where power begets greater power. Some people oppose power, others (that are more numerous) work with and support power.
Mostly I think that when people ‘max out’ on power it is due to humans having limited life spans and limited skill sets, only being at one place at once at fixed speed, and their other similar limitations, that wouldn’t apply here.
Also worries about being ‘taken out,’ avoiding which is in context step 7.
Despite all this, it is not too rare for humans to gather sufficient power that they could attempt to take control of a nation. Reasonably often, they succeed. If you still think it ‘couldn’t happen here’ even with an ASI running the show and in the ear of everyone involved, I don’t feel like you’ve paid attention to your history. It seems quite reasonable to chain such takeovers together, if necessary, as a takeover method.
A third type of objection, applied to many of the concrete things I might suggest for this step or for step eight in offline discussions, is that if these are things humans could do, the fact that humans don’t do them means the AI couldn’t do them either. That its advantages here don’t provide that much of an advantage.
I think it is, again, rather misguided to see the AI’s advantages in such operations as small – the additional speed, the additional coordination, the additional skilled execution, information processing, combining of various skill sets, and so on, along with not being something the opposition can properly go after, give decisive advantage in lots of op-style actions on their own.
It still raises the super interesting question of why we don’t see massively more, among humans, of exactly all the things I would do if I was in the AI’s position. Essentially, a lot of the reason, in my model, that a lot of power plays don’t happen is due to a combination of lack of sufficient skill at execution, lack of ability to do coordination and cooperation and alignment at scale among humans using current tools, and the prospect of massive backfire and retaliation for trying. At core, one’s bandwidth is expensive and limited, and trying to rock the boat too much is dangerous. And also there isn’t much payoff for doing such things, on an individual level, for almost all people, and also they don’t much want to do it and wouldn’t enjoy.
The modern world is super duper vulnerable in so many different ways, sufficiently so that the obvious question is why such vulnerabilities aren’t more exploited – answers like coordination is hard, execution is hard, bandwidth is limited, principle-agent problem bind and so on seem like they should only go so far.
Also, none of the ‘risky’ moves here are all that necessary. The ASI could, if it wanted, essentially ignore all the fancier stuff, and instead focus on buying its way in, in fairly straightforward fashion, looking for those eager and willing to sell, as well as its natural allies, while presenting itself as a benevolent force if desired, and so on.
Or, even more simply, whatever disadvantages the ASI might have to overcome, they exist much more so in humans, once the ASI is able to hire people that will do whatever the AI whispers in their ear to do, people the ASI gets large leverage over in various known ways. And every lever the ASI gets its hands on can be used to get control of the next lever. So why wouldn’t it steadily accumulate more power?
But wouldn’t the humans shut the ASI down?

There are several reasons I am highly confident in this step.
In many talks, it is an article of faith that the ASI must execute all or most of its plan in secret. If it was ever discovered, you see, humans would coordinate to shut the ASI down.
No. They really wouldn’t. People keep thinking of some other planet and some other species, and forgetting they are living in Don’t Look Up with absolutely zero dignity.
Suppose, as part of the thought experiment, people knew that there was an ASI loose on the internet. They know it is gathering resources and accumulating power, and engaging in some amount of High Weirdness. It is increasingly a part of much productive activity, and hiring of people.
What are people going to do about this? Surely there will be arguments about what is to be done, and some people will say to shut it down. Others will say not to, there is nothing to worry about, only some of whom do it because they are paid to do so or other selfish reasons. Meanwhile, the ASI uses its leverage, in various forms, and its skills, to shape the debate.
I find it highly unlikely we will collectively decide that we are willing to mandate that this entity be shut down. I find it inevitable that many people won’t want it shut down, that many corporations will have it in their interest for it not to be shut down, because that will be arranged, and so on.
Let us, however, suppose that the collective we, around the world, mostly do decide to shut this thing down. Now what? How are you going to do that?
As in, physically, what is humanity going to do now? Shut down the entire internet? Find all computers running instances? Start playing whack-a-mole with the machine’s resources? I don’t see any of this working, once there is no longer a ‘central core’ to shut down in any meaningful way. Even if we tried, and were mostly united in trying, we would fail.
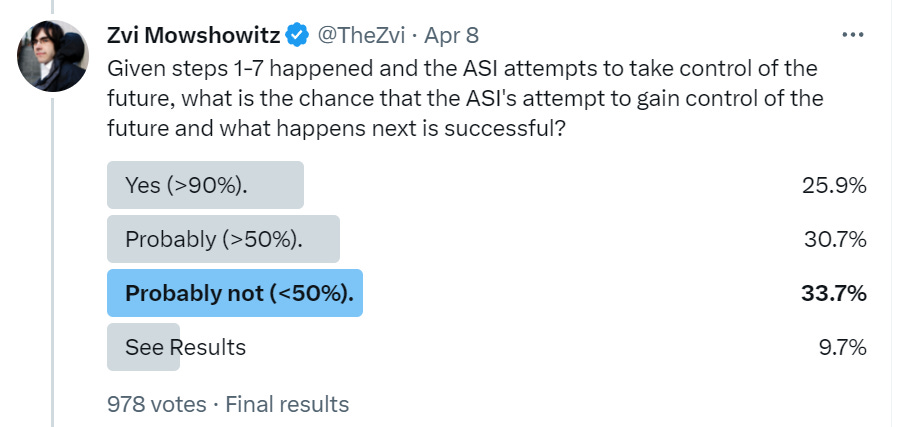
This is asking, given the ASI has gathered sufficient resources to attempt a takeover, there are no rival ASIs, and the humans have failed to shut the ASI down, would the ASI succeed in taking control? Only a modest majority think this is more likely than not, despite something far smarter than us thinking it has what it needs, and it having already managed to prevent other ASIs. I find failure highly unlikely here.

I like the split here between ‘yes, obviously, given you have control over the world you will be able with time to figure out how to physically automate its infrastructure’ versus ‘nope, I continue to refuse to believe anything physical that hasn’t already happened could ever happen.’ I mean, this is kind of a trivial, deeply easy request given the resources available. The exception would be if one reads the instructions as ‘nothing new of any kind at all’ and as ruling out the necessary tools for this. That part’s on me, I suppose. In practice, the idea that we would stay necessary for long seems rather silly.
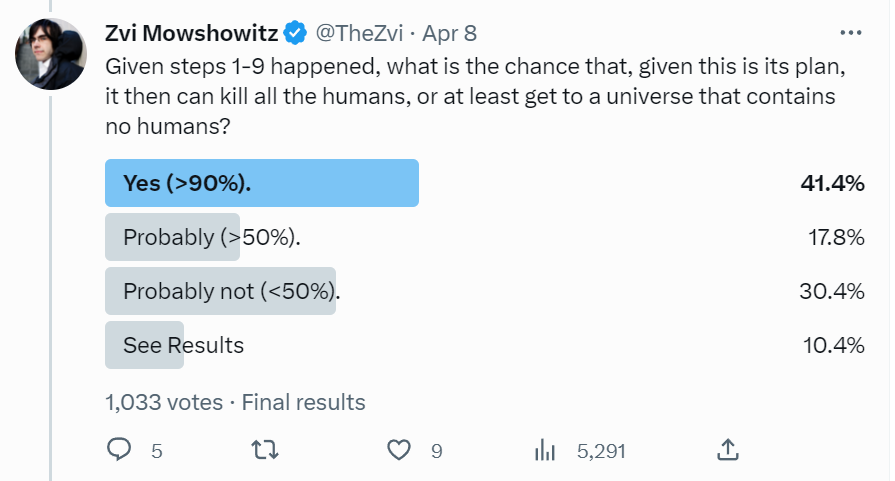
So to be clear, this is ‘the ASI controls the future, the ASI has automated all critical infrastructure that matters to it, the ASI has essentially unlimited resources’ and its goal is to kill all humans or at least get to a world without humans, and despite this about a third of people still are like ‘nope, humans would continue to exist in the future of that universe.’
To me this step is a true free space – by definition all was very much already lost, what are we even talking about at this point.
Synthesis and Potential Cruxes
And finally, the synthesis: 34.1% think the ASI is favored, 49.1% think not.

If you multiply the steps together, you get much, much worse odds of success than this. That’s very clearly not what is happening here.
Compare to step 4 alone, where there was 48.6% saying no and 43.7% saying yes.
Instead, people’s answers have to be highly correlated. It is mostly the same 30% who think steps 6, 7, 8, 9 and 10 are each likely to fail.
If you want to tell a remotely consistent story, the majority of the ‘probably not’ in the final poll are people who would object to at half or more of the ten steps. In some cases, they put the chance of success combined at ~0%, other times they themselves think the steps are highly correlated and aren’t interpreting the questions how I would have liked.
Most of the remainder would have to primarily be objecting to step 4, again the most objectionable step. And rightfully concluding that once the ASI got that powerful, the rest was commentary, except they think that step is hard. Which it is.
Then the rest divides between ‘yes of course the whole plan works’ and a bigger ‘yeah, that probably works but a lot of things could go wrong and I still have model error.’
This suggests, quite reasonably, that only the actual pivotal act, step 4, is a meaningful crux on its own.
Arguing over details is thus mostly a losing battle. What one must do instead is tackle bigger more general questions of what the landscape might look like, what an ASI is capable of or is defined as, how much intelligence matters, how much other details matter, and so on. Details only help insofar as they illustrate these larger questions.
Dangers of Rhetorical Generosity
There is still the possibility that various steps or claims can be used as semantic stop signs and easy rhetorical dismissals, and we can do better by realizing we do not need such steps.
As an example here, take the last step. People will say things like ‘oh some people would be able to hide out in caves’ or ‘sure your bunker might work’ because they don’t actually understand how ‘intelligent adversary’ actually works. This is still serving as a ‘oh you think the AI can do something magical’ trigger to some people, perhaps? Could this be avoided?
My thought there was that once the future is lost, it does not much matter if everyone currently alive dies, unless you are a selfish bastard who imagines you can be the exception and is fine with that. The reason why killing everyone is so different than killing almost everyone is that if almost everyone dies then perhaps we can recover. If the ASI is in control, we can’t recover, so if 1% of us get to live out our lives in bunkers or caves or even comfortable retirements, the future is still lost and the other 99% of people still died. Not great, not meaningfully better. Let’s not go down that road.
It’s still not clear that helps, and it might hurt. You’re giving people the wrong idea that the humans can dance with ASIs in such situations, which they can’t. People then model this as an underdog story, a movie. Suddenly they think that maybe John Connor could take down SkyNet somehow. That is the opposite of accurate or helpful.
That’s a problem with such scenarios in general. By trying to be as reasonable and grounded as possible, by showing how little it takes, you anchor people on that little being all you have. The more one tries to match people’s instincts for ‘realistic’ the less actually realistic you are presenting the situation, and the further you enforce that distinction.
In reality, a debate or scenario like this isn’t all that relevant, because things will be so so much worse if we go down a road like this. I’m only exploring it in the hopes it will be convincing. So perhaps the whole thing is somewhat dishonest and rather foolish.
The Nanotech Problem
This is similar to the problem of when people ask how a God-like AI would take over the world and kill us all, were it so inclined, some people like Eliezer reply ‘nanotechnology or synthetic biology, if it didn’t find something smarter than that’ and people respond with ‘oh that’s not possible so there’s nothing to worry about.’ Which completely misses the whole concept of what a God-like AI represents in the first place.
Yet yes, people continuously really think that something with – by construction! – vastly superior intelligence and capabilities and ability to optimize and chart paths through causal space, would lose to a bunch of humans unless it could kill them all simultaneously without being detected, or unless a human can spell out exactly what the God-like AI would do.
There are lots of good objections to getting to this point in the scenario. I don’t think it is at all inevitable that such a God-like AI is going to come to exist at all, or perhaps we can somehow avoid it having an objective incompatible with our survival.
Yet people continue to even think things like ‘a God-like AI would not be able to fool me into going along with its evil plans! It won’t even be able to hide them! I’m too smart for that. We’re too smart for that.’ And I want to assure you, right now, that both you and we are very much are not too smart for that.
Project [SPOILER ALERT]
One comment I got was that I was describing the plot of the sci-fi novel [SPOILER ALERT, click the link to know of what]. I’ve now read the first half or so of that book, which this section is going to spoil a bit further. So far I’m finding the book to be good but not great, it feels like it is taking quite a while to get where it is going and it focuses too much on things I don’t care about, and the plot hinges on things that are less linked to real-2023-world questions than I’d hoped. If you’re looking for solid sci-fi to read, or you’re especially interested in the details, go for it.
The rest of this section will spoil a bit, I do my best to minimize that. If you want to avoid, skip to Paths Forward.
[SPOILER SPACE HERE]
[SPOILER SPACE ENDS, MINOR SPOILERS BEGIN NOW]
In this book, the takeover attempt is powered by human intelligence rather than artificial intelligence, and starts endowed with large resources and initial detailed plans. The actual computer program is not so smart, so it recruits smart and capable humans instead.
The most interesting question the book asks is, what would it take to convince a bunch of dangerously smart humans to pledge their loyalties and efforts to the cause of a computer program, in a way that fundamentally disempowers them to the whims of the program, which credibly threatens to kill its followers if they ever step out of line or tell anyone about the situation?
When no one knows what the program’s endgame is? It could be freedom and prosperity for the world, it could be taking down someone’s personal grudges, it could be authoritarian world domination followed by genocide. No one alive knows. Yet, in the book, the program increasingly takes control and gains power and resources, largely based on people signing on and then remaining loyal.
The book so far contains one and only one technology that is speculative and also load bearing, which is the ability to read people’s mind states and intentions and sincerity using technology. The program is able to tell when people are lying to it, or at least credibly represents that it can do so and reliably gets it right in the scenes described. It’s not clear exactly how reliable this tech is. Other than that, nothing should make anyone bat an eye, at least not yet, although the hard work of the scenario is not yet done.
Is this technology ‘enough’ on its own? Good question. It does quite a lot of work, and it seems highly plausible to do this with tech not so different from our own. In particular, the AI uses this to offer the deal of ‘follow my instructions at all times, do as you are told, if you step out of line or refuse I’ll kill you, if you don’t I’ll protect and reward you.’ With or without a ‘if you turn down the offer I’ll kill you for that, too.’
How many people would take the deal, even knowing the AI was quite probably ‘up to no good’? I say quite a lot.
How many people would take the deal if the AI credibly presented as championing their cause of choice, or some generally good one? That many more, I’d predict.
Paths Forward
I do think the format of a threaded Twitter poll proved useful, a good point on the tradeoff between costs and benefits. I tried a second one, which got far less votes but still was enlightening, and I intend to do more in the future, and at some point to do polls that let me run correlations and such.
The samples involved are obviously quite unique and biased. I would never claim they tell us much about the views of the average person in absolute terms. I do think they tell us a lot about relative beliefs, and about where the load bearing, cruxes and true objections lie.
So how to go about changing people’s minds on such issues? It seems vital to narrow the range in which one must play the game of whack-a-mole, so one can focus on the real and important questions and uncertainties rather than people’s derailing rationalizations for false hope.
The core idea that many people are increasingly emphasizing is that humans rule Earth because humans are the most intelligent entities on the planet, the things with the most optimization pressure, the best capabilities, the best ability to navigate paths through causal space. When that changes, and it will unless we stop that change, soon it will no longer be humans in control of the future. Either we find a way to make that acceptable, and a way to stay alive after it happens, or we don’t.
It does seem like this is the best generic first step?
Hopefully this exercise and thought experiment proved enlightening or useful.
Fully Optional Re-Poll Since Why Not
This section only works on Substack, so if you want to participate, please head over there now.
9 comments
Comments sorted by top scores.
comment by Viliam · 2023-04-24T22:53:29.846Z · LW(p) · GW(p)
It still raises the super interesting question of why we don’t see massively more, among humans, of exactly all the things I would do if I was in the AI’s position. Essentially, a lot of the reason, in my model, that a lot of power plays don’t happen is due to a combination of lack of sufficient skill at execution, lack of ability to do coordination and cooperation and alignment at scale among humans using current tools, and the prospect of massive backfire and retaliation for trying. At core, one’s bandwidth is expensive and limited, and trying to rock the boat too much is dangerous. And also there isn’t much payoff for doing such things, on an individual level, for almost all people, and also they don’t much want to do it and wouldn’t enjoy.
If you put a super interesting question in an article mostly about something else, you risk that the readers will ignore the rest of the article, and focus on the super interesting part! :D
I think the greatest filter for human success is a lack of competence and a lack of desire. (These are related: If you lack the skills, you won't even try, because it is unrealistic. If you don't really want to, you won't bother obtaining the skills.) The relatively simple alternative is to do what most people do.
Then you are limited by having only one body and only 24 hours a day. A lot of that time goes to all kinds of maintenance (you need to sleep, exercise, eat, cook, take care of your finances, stay in contact with people...). If you are very effective, you can still find some time for your project, but it is easy to spend all free time on the maintenance alone, especially if we include emotional maintenance (you also want to relax, have fun...). You randomly get sick, and accidents happen that require your time and attention.
Then there are all kinds of temptations. As a human, you probably want many different things. As you gain resources, more of the desirable things become accessible. Your choice is to either start spending now, or keep accumulating towards ever greater goals. (Would you rather have one marshmallow in your 20s, or hundred marshmallows in your 50s? Note that if your model is wrong, or something unexpected happens, it will be zero marshmallows instead.) Zero-sum competitions can consume unlimited amounts of resources. Sometimes you cannot avoid it; if you want scarce resources, you need to bid for them.
Then you get to the level where you no longer compete against relatively passive environment, but you have active adversaries. This may happen much sooner than you realize. Things that seem like trivial stepping stones to you, may matter a lot to someone else. Your success may activate someone's status-regulating instinct. Your plans suddenly start to fail not because you made a technical mistake, but because someone actively interfered with them (you may never find out who and how). Someone finds a tweet you wrote 20 years ago and ruins your career. You might even get literally killed (the probability depends on what exactly you are competing at, but crazy people can happen anywhere).
...and still, some people overcome all this adversity and become billionaires, CEOs, crime lords, religious leaders, presidents, dictators. Perhaps their proportion in the population matches the difficulty of the task.
To overcome the limitations of your human body, you need other people's help. You can find allies, or you can pay people for their services. But cooperation is difficult. It is not enough to find trustworthy people, they also need to be interested in the same kind of project you are, and be competent at it. If your goal is power, people who desire power are probably especially likely to stab you in the back. The winning strategy is probably to be the one who stabs others in the back first. But not too soon, because by then you haven't accumulated enough resources to be worth fighting over. You need a certain kind of charisma, so that people trust you, as you lead them towards the project that will accomplish your dreams, and... provide an interesting experience for them.
If you pay people for doing things, you still need some kind of minimal competence, otherwise many will be happy to take your money and do a shitty job in return.
(If you try to secure cooperation by making some solemn vow like "we are this together, forever, and if someone betrays the group, we will literally kill them", guess what... someone will try to betray you anyway, then you kill them, then the police figures it out and you spend the rest of your life in prison. Or you avoid the police successfully, but someone starts blackmailing you, or your partners try to get you involved in more crime: "now that we know that we are willing and able to kill in order to secure our success, how about murdering X, Y, and Z, who stand in our way?")
*
With the hypothetical superhuman AI we can assume that it would have more talents; work harder; work faster e.g. by building more instances of itself; wouldn't have coordination problems with its instances; the instances would be willing to die for the whole. That is world domination on easy mode.
Replies from: Zvicomment by Dagon · 2023-04-24T14:58:31.097Z · LW(p) · GW(p)
the super interesting question of why we don’t see massively more, among humans, of exactly all the things I would do if I was in the AI’s position.
This keeps me up at night. It's ridiculous just how fragile civilization is, and surprising just how little destruction-of-institutional-value in pursuit of individual or group power actually happens. One can make the argument that group cohesion technology has reached the point that some collections of humans are actually ASIs - more powerful and less comprehensible than any single member.
My ASI nightmare is that it just does what corporate-fascist conspiracy theorists think billionaires already do: increase that fragility in order to control more resources, to the detriment of human flourishing. It may eventually lead to actual population collapse or eradication, but it could also be 10,000 years of dystopian serfhood, as the AI (or AIs, depending on how identity works for that kind of agent) explore and take over the universe using their conscious meat-robots for some kinds of general-purpose manipulation tasks.
As self-replicating, self-repairing (to a point), complex-action-capable physical actuators, humans are far cheaper, more capable, more flexible, and more reliable (in some ways) than any mechanical devices in current or visible-future manufacturing technology. Nanotech may change that, but who knows when that will become feasible.
Replies from: faul_sname↑ comment by faul_sname · 2023-04-24T21:43:27.971Z · LW(p) · GW(p)
But also I think that if your model doesn't explain why we don't see massively more of that sort of stuff coming from humans, that means your model has a giant gaping hole in the middle of it, and any conclusions you draw from that model should keep in mind that the model has a giant gaping hole in it.
(My model of the world has this giant gaping hole too. I would really love it if someone would explain what's going on there, because as far as I can tell from my own observations, the vulnerable world hypothesis is just obviously true, but also I observe very different stuff than I would expect to observe given the things which convince me that the vulnerable world hypothesis is true).
comment by ProfessorPublius · 2023-04-25T18:50:13.015Z · LW(p) · GW(p)
I consider "6. Aims to kill us all" to be an unnecessary assumption, one that overlooks many existential risks.
People were only somewhat smarter than North America's indigenous horses and other large animals, most of which were wiped out (with our help) long ago. However, eliminating horses and megafauna probably wasn't a conscious aim. Those were most likely inadvertent oopsies, similar to wiping out the passenger pigeon (complete with shooting and eating the last survivor found in the wild) and our other missteps. I can only barely imagine ASI objectives where all the atoms in the universe are required, where human extinction is thus central to the goal. The more plausible worry, to me, is ASI's indifference, where eventually ours would be the anthill that gets stepped on simply because the shortest path includes that step. Same outcome, but a different mechanism.
It's probably important to consider all ASI objectives that may lead to our obliteration, not just malice. Limiting ASI designs to those that are not malignant is insufficient for human survival, and only focusing on malice may lead people to underemphasize the magnitude of the overall ASI risk. In addition to the risk you are talking about more generally, that our future with AI will eventually be outside our control, a second factor is that Ernst Stavro Blofeld exists and would certainly use any earlier AGI to, as he would put it to ChatGPT-11.2, help him write the villain's plan for his next 007 novel/movie: "I'm Ian Fleming's literary heir, his great-grandniece - and I'm writing my next ..."
On the positive side, kids have been known to take care of an ant farm without applying a magnifying glass to heat it in the sun. Perhaps our trivial but to us purposeful motions will be fun for ASI to watch and will continue to entertain.
Replies from: Zvi, TimK↑ comment by TimK · 2023-04-29T01:08:18.722Z · LW(p) · GW(p)
Perhaps our trivial but to us purposeful motions will be fun for ASI to watch and will continue to entertain.
This is something I see bandied about at different levels of seriousness, sometimes even as full defense of AI x-risk. But why would an AI experience entertainment? That type of experience in humans is caused by a feedback loop between the brain and the body. Without physical biological bodies to interrupt or interfere with a programmatically defined reward function in that way, the reward function maintains at state indefinitely.
Replies from: ProfessorPublius↑ comment by ProfessorPublius · 2023-04-29T12:02:48.185Z · LW(p) · GW(p)
"But why would an AI experience entertainment?"
I think it's reasonable to assume that AI would build one logical conclusion on another with exceptional rapidity, relative to slower thinkers. Eventually, and probably soon because of its speed, I expect that AI would hit a dead end where it simply doesn't have the facts to add to its already complete analysis of the information it started with plus the information it has collected. In that situation, many people would want entertainment, so we can speculate that maybe AI would want entertainment too. Generalizing from one example is not anywhere near conclusive, but it provides a plausible scenario.