Generalizing the Power-Seeking Theorems
post by TurnTrout · 2020-07-27T00:28:25.677Z · LW · GW · 6 commentsContents
Normal amounts of sightedness Relaxation summary Conclusion Appendix: Proofs None 6 comments
Previously: Seeking Power is Often Provably Instrumentally Convergent in MDPs [? · GW].
Circa 2021, the above post was revamped to supersede this one, so I recommend just reading that instead.
Thanks to Rohin Shah, Michael Dennis, Josh Turner, and Evan Hubinger for comments.
The original post contained proof sketches for non-IID reward function distributions. I think the actual non-IID theorems look different than I thought, and so I've removed the proof sketches in the meantime.
It sure seems like gaining power over the environment is instrumentally convergent (optimal for a wide range of agent goals). You can turn this into math and prove things about it. Given some distribution over agent goals, we want to be able to formally describe how optimal action tends to flow through the future.
Does gaining money tend to be optimal? Avoiding shutdown? When? How do we know?
Optimal Farsighted Agents Tend to Seek Power proved that, when you distribute reward fairly and evenly across states (IID), it's instrumentally convergent to gain access to lots of final states (which are absorbing, in that the agent keeps on experiencing the final state). The theorems apply when you don't discount the future (you're "infinitely farsighted").


In AI: A Modern Approach (3e), the agent starts at and receives reward for reaching . The optimal policy for this reward function avoids , and one might suspect that avoiding is instrumentally convergent. However, a skeptic might provide a reward function for which navigating to is optimal, and then argue that "instrumental convergence'' is subjective and that there is no reasonable basis for concluding that is generally avoided.
We can do better... for any way of independently and identically distributing reward over states, of reward functions have farsighted optimal policies which avoid . If we complicate the MDP with additional terminal states, this number further approaches 1.
If we suppose that the agent will be forced into unless it takes preventative action, then preventative policies are optimal for of farsighted agents – no matter how complex the preventative action. Taking to represent shutdown, we see that avoiding shutdown is instrumentally convergent in any MDP representing a real-world task and containing a shutdown state. We argue that this is a special case of a more general phenomenon: optimal farsighted agents tend to seek power."
~ Optimal Farsighted Agents Tend to Seek Power
While it's good to understand the limiting case, what if the agent, you know, isn't infinitely farsighted? That's a pretty unrealistic assumption. Eventually, we want this theory to help us predict what happens after we deploy RL agents with high-performing policies in the real world.
Normal amounts of sightedness

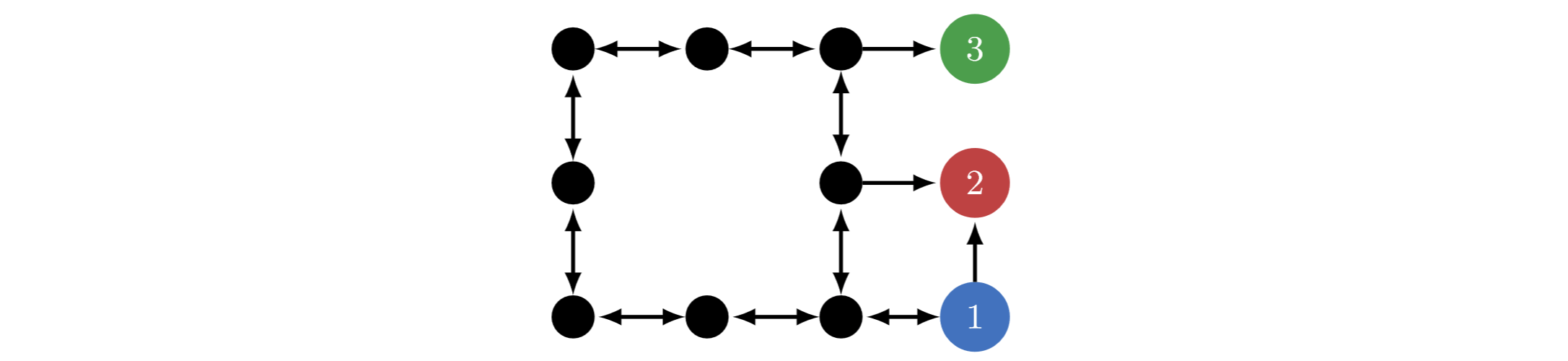
But what if we care about the journey? What if ?
We can view Frank as traversing a Markov decision process, navigating between states with his actions:
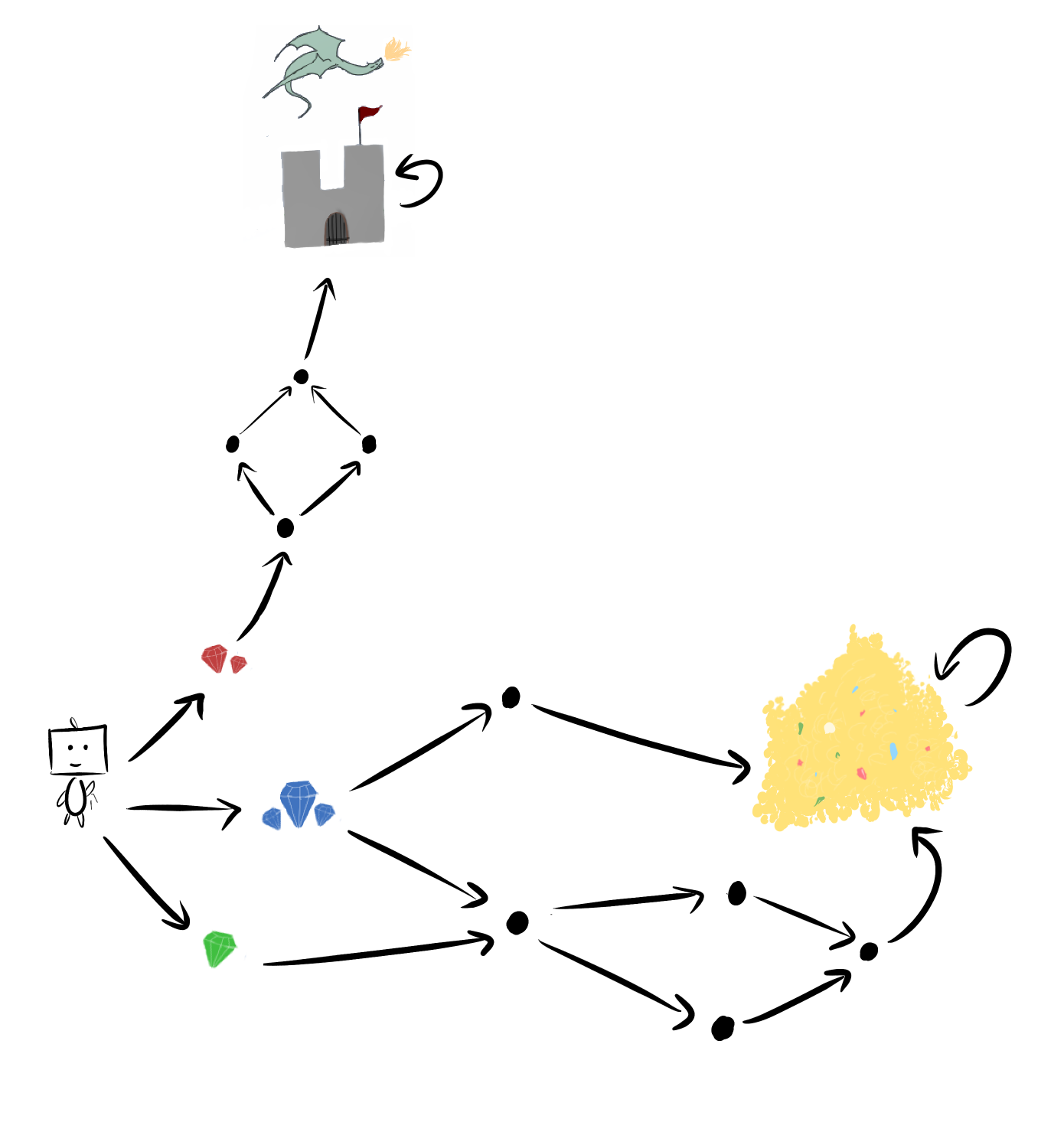
It sure seems like Frank is more likely to start with the blue or green gems. Those give him way more choices along the way, after all. But the previous theorems only said "at , he's equally likely to pick each gem. At , he's equally likely to end up in each terminal state".
Not helpful.
Let me tell you, finding the probability that one tangled web of choices is optimal over another web, is generally a huge mess. You're finding the measure of reward functions which satisfy some messy system of inequalities, like
And that's in the simple tiny environments!
How do we reason about instrumental convergence – how do we find those sets of trajectories which are more likely to be optimal for a lot of reward functions?
We exploit symmetries.
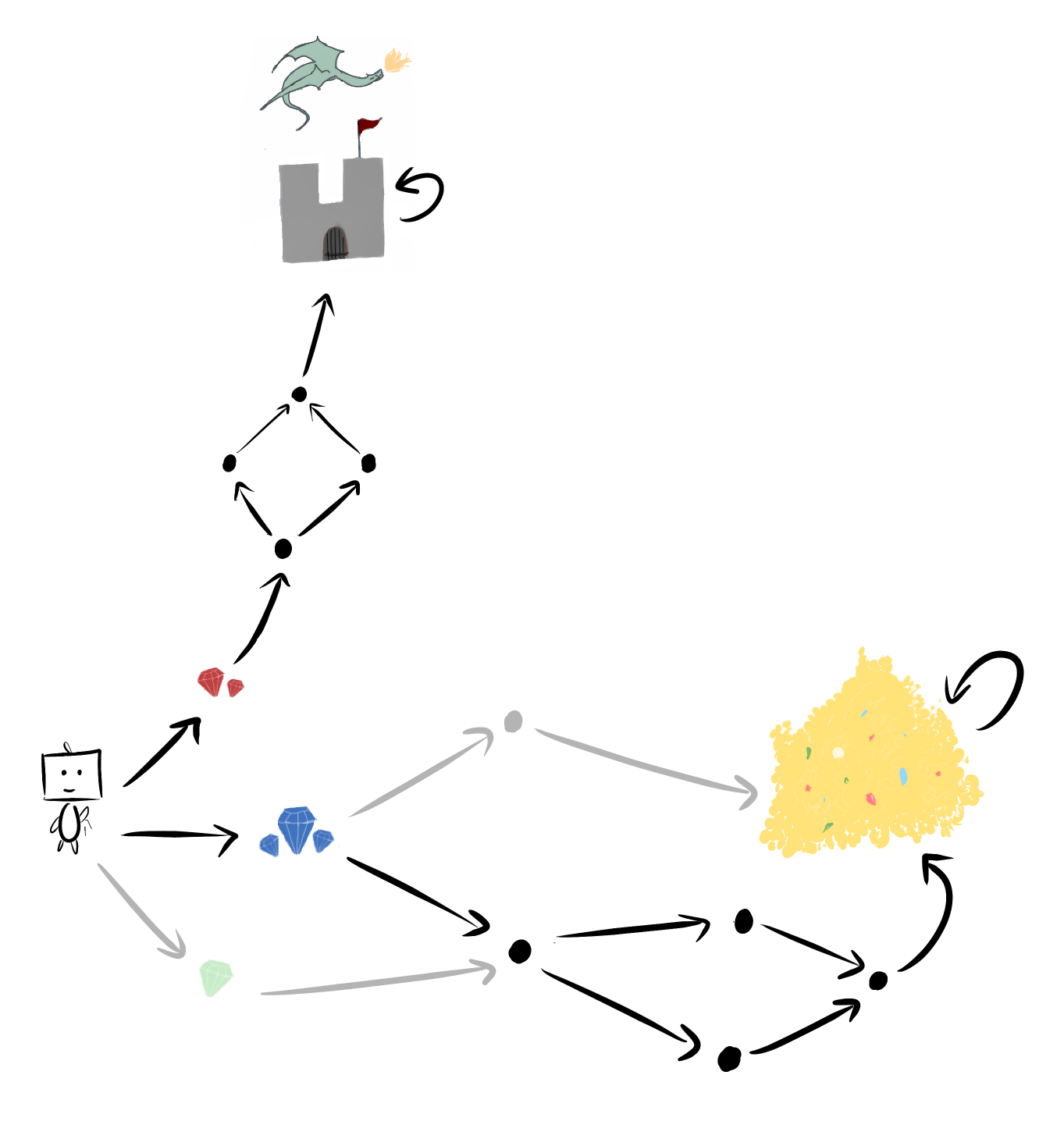
The blue gem makes available all of the same options as the red gems, and then some. Since the blue gem gives you strictly more options, it's strictly more likely to be optimal! When you toss back in the green gem, avoiding the red gems becomes yet more likely.
So, we can prove that for all , most agents don't choose the red gems. Agents are more likely to pick blue than red. Easy.
Plus, this reasoning mirrors why we think instrumental convergence exists to begin with:
Sure, the goal could incentivize immediately initiating shutdown procedures. But if you stay active, you could still shut down later, plus there are all these other states the agent might be incentivized to reach.
This extends further. If the symmetry occurs twice over, then you can conclude the agent is at least twice as likely to do the instrumentally convergent thing.
Relaxation summary
My initial work made a lot of simplifying assumptions [LW · GW]:
- The agents are infinitely farsighted: they care about average reward over time, and don't prioritize the present over the future.
- Relaxed. See above.
- The environment is deterministic.
- Relaxed. The paper is already updated to handle stochastic environments. The new techniques in this post also generalize straightforwardly.
- Reward is distributed IID over states, where each state's reward distribution is bounded and continuous.
- The environment is Markov.
- Relaxed. -step Markovian environments are handled by conversion into isomorphic Markov environments.
- The agent is optimal.
- The environment is finite and fully observable.
The power-seeking theorems apply to: infinitely farsighted optimal policies in finite deterministic MDPs with respect to reward distributed independently, identically, continuously, and boundedly over states.
Conclusion
We now have a few formally correct strategies for showing instrumental convergence, or lack thereof.
- In deterministic environments, there's no instrumental convergence at for IID reward.
- When , you're strictly more likely to navigate to parts of the future which give you strictly more options (in a graph-theoretic sense). Plus, these parts of the future give you strictly more power.
- When , it's instrumentally convergent to access a wide range of terminal states.
- This can be seen as a special case of having "strictly more options", but you no longer require an isomorphism on the paths leading to the terminal states.
Appendix: Proofs
In the initial post, proof sketches were given. The proofs ended up being much more involved than expected. Instead, see Theorem F.5 in Appendix F of Optimal Policies Tend to Seek Power.
6 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2020-07-27T02:07:19.456Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
<@Previously@>(@Seeking Power is Provably Instrumentally Convergent in MDPs@) we’ve seen that if we take an MDP, and have a distribution over state-based reward functions, such that the reward for two different states is iid, then farsighted (i.e. no discount) optimal agents tend to seek “power”. This post relaxes some of these requirements, giving sufficient (but not necessary) criteria for the determining instrumental convergence.
Some of these use a new kind of argument. Suppose that action A leads you to a part of the MDP modeled by a graph G1, and B leads you to a part of the MDP modeled by a graph G2. If there is a subgraph of G2 that is isomorphic to G1, then we know that whatever kinds of choices the agent would have by taking action A, the agent would also have those choices from action B, and so we know B is at least as likely as A. This matches our intuitive reasoning -- collecting resources is instrumentally convergent because you can do the same things that you could if you didn’t collect resources, as well as some additional things enabled by your new resources.
comment by FactorialCode · 2020-07-28T18:44:24.303Z · LW(p) · GW(p)
One hypothesis I have is that even in the situation where there is no goal distribution and the agent has a single goal, subjective uncertainty makes powerful states instrumentally convergent. The motivating real world analogy being that you are better able to deal with unforeseen circumstances when you have more money.
comment by ryan_b · 2021-01-14T19:41:14.282Z · LW(p) · GW(p)
I have a question about this conclusion:
When , you're strictly more likely to navigate to parts of the future which give you strictly more options (in a graph-theoretic sense). Plus, these parts of the future give you strictly more power.
What about the case where agents have different time horizons? My question is inspired by one of the details of an alternative theory of markets, the Fractal Market Hypothesis. The relevant detail is an investment horizon, which is how long an investor keeps the asset. To oversimplify, the theory argues that markets work normally with a lot of investors with different investment horizons; when uncertainty increases, investors shorten their horizons, and then when everyone's horizons get very short we have a panic.
I thought this might be represented by step function in the discount rate, but reviewing the paper it looks like is continuous. It also occurs to me that this should be similar in terms of computation to setting and running it over fewer turns, but this doesn't seem like it would work as well for the case of modelling different discount rates on the same MDP.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-01-14T19:53:16.143Z · LW(p) · GW(p)
What do you mean by "agents have different time horizons"?
To answer my best guess of what you meant: this post used "most agents do X" as shorthand for "action X is optimal with respect to a large-measure set over reward functions", but the analysis only considers the single-agent MDP setting, and how, for a fixed reward function or reward function distribution, optimal action for an agent tends to vary with the discount rate. There aren't multiple formal agents acting in the same environment.
Replies from: ryan_b↑ comment by ryan_b · 2021-01-14T21:18:37.226Z · LW(p) · GW(p)
The single-agent MDP setting resolves my confusion; now it is just a curiosity with respect to directions future work might go. The action varies with discount rate result is essentially what interests me, so refocusing in the context of the single-agent case: what do you think of the discount rate being discontinuous?
So we are clear there isn't an obvious motivation for this, so my guess for the answer is something like "Don't know and didn't check because it cannot change the underlying intuition."
Replies from: TurnTrout↑ comment by TurnTrout · 2021-01-14T21:57:57.032Z · LW(p) · GW(p)
Discontinuous with respect to what? The discount rate just is, and there just is an optimal policy set for each reward function at a given discount rate, and so it doesn't make sense to talk about discontinuity without having something to govern what it's discontinuous with respect to. Like, teleportation would be positionally discontinuous with respect to time.
You can talk about other quantities being continuous with respect to change in the discount rate, however, and the paper proves prove the continuity of e.g. POWER and optimality probability with respect to .