0 comments
Comments sorted by top scores.
↑ comment by gjm · 2020-07-18T09:21:15.314Z · LW(p) · GW(p)
Your statement "This means you can't use it ... end of story" is simply objectively wrong.
Consider the following situation, which is analogous but easier to work with. You have a (monochrome) image, represented in the usual way as an array of pixels with values between (say) 0 and 255. Unfortunately, your sensor is broken in a way somewhat resembling these telescopes' phase measurements, and every row and every column of the sensor has a randomly-chosen pixel-value offset between 0 and 255. So instead of the correct pixel(r,c) value in row r and column c, your sensor reports pixel(r,c) + rowerror(r) + colerror(c).
The row errors or the column errors alone would suffice to make it so that every individual pixel value is, as far as its own measurement goes, completely unknown. Just like the phases of the individual interferometric measurements. BUT the errors are consistent across each row and each column, rather than being independent for each pixel, just as the interferometric errors are consistent for each telescope.
So, what happens if you take this hopelessly corrupted input image, where each individual pixel (considered apart from all the others) is completely random, and indeed each pair of pixels (considered apart from all the others) is completely random, and apply a simple-minded reconstruction algorithm? I tried it. Here's the algorithm I used: for each row in turn, see what offset minimizes "weirdness" (which I'll define in a moment) and apply it; likewise for each column in turn; repeat this until "weirdness" stops decreasing. "Weirdness" means sum of squares of differences of adjacent pixels; so I'm exploiting the fact that real-world images have a bit of spatial coherence. Here's the result:
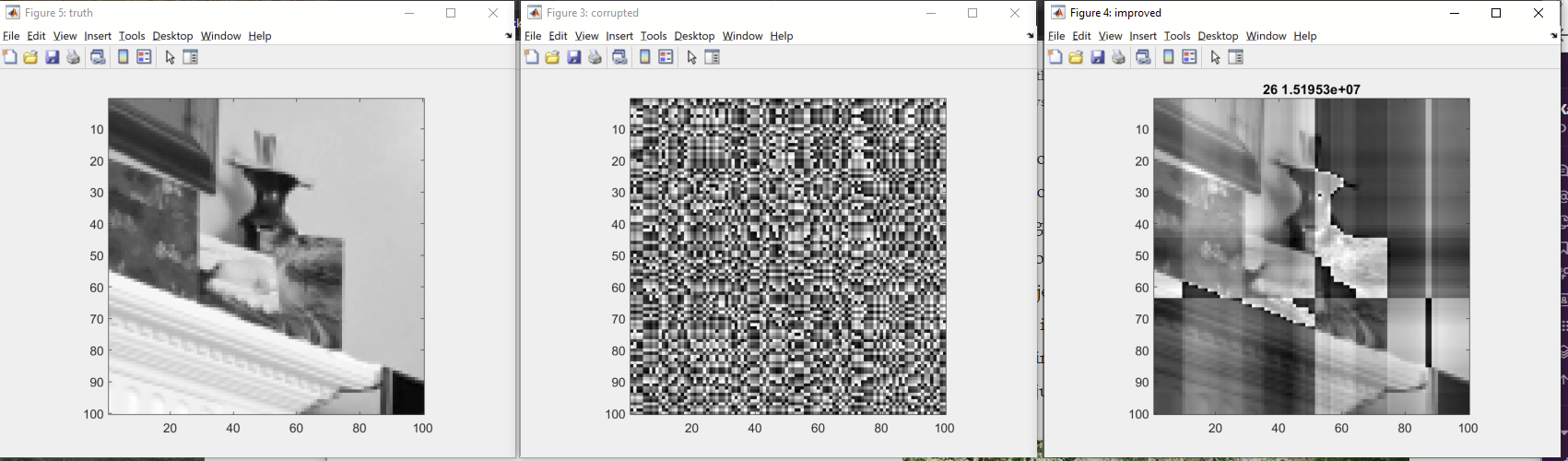
On the left we have a 100x100 portion of a photo. (I used a fairly small bit because my algorithm is super-inefficient and I implemented it super-inefficiently.) In the middle we have the same image with all those row and column errors. To reiterate, every row is offset (mod 256) by a random 8-bit value; every column is offset (mod 256) by a random 8-bit value; this means that every pair of pixel values, considered on their own, is uniformly randomly distributed and contains zero information. But because of the relationships between these errors, even the incredibly stupid algorithm I described produces the image on the right; it has done 26 passes and you can already pretty much make out what's in the image. At this point, individual row/column updates of the kind I described above have stopped improving the "weirdness".
Not satisfied? I tweaked the algorithm so it's still stupid but slightly less so: now on all iterations past the 10th it also considers blocks of rows and columns either starting with the first or ending with the last, and tries changing the offsets of the whole block in unison. The idea is to help it get out of local minima where a whole block is wrongly offset and changing one row/column at an edge of the block just moves the errors from one place to another without reducing the overall amount of error. This helps a bit:
though some of the edges in the image are still giving it grief. I can see a number of ways to improve the results further and am confident that I could make a better algorithm that almost always gets the image exactly right (up to a possible offset in all the pixel values) for real pictures, but I think the above suffices to prove my point: although each individual measurement is completely random because of the row and column errors, there is still plenty of information there to reconstruct the image from.
Replies from: gjm↑ comment by gjm · 2020-07-18T14:04:37.603Z · LW(p) · GW(p)
Hmm, there should be two images there but only one of them is showing up for me. Let me try again:
This should appear after "This helps a bit:". (I'm putting this in an answer rather than editing the previous comment because if there's some bug in image uploading or display then it seems like having only one image per comment might make it less likely to be triggered.)

↑ comment by gjm · 2020-07-18T11:48:52.057Z · LW(p) · GW(p)
I haven't based my career on these methods. I don't know where you get that idea from.
[EDITED to add:] Oh, maybe I do know. Perhaps you're reasoning as follows: "This stuff is obviously wrong. Gareth is defending it. The only possible explanation is that he has some big emotional investment in its rightness. The most likely reason for that is that he does it for a living. Perhaps he's even on the LIGO or EHT project and is taking my criticisms personally." So, for the avoidance of doubt: my only emotional investment in this is that bad science (particularly proselytizing bad science) makes me sad; I have no involvement in the LIGO or EHT project, or any other similar Big Science project, nor have I ever had; my career is in no way based on image reconstruction algorithms like this one. (On the other hand: I have from time to time worked on slightly-related things; e.g., for a while I worked with phase reconstruction algorithms for digital holograms, which is less like this than it might sound but not 100% unlike it, and I do some image processing algorithm work in my current job. But if all the stuff EHT is doing, including their image reconstruction techniques, turned out to be 100% bullshit, the impact on my career would be zero.)
----
The method successfully takes a real image (I literally grabbed the first thing I found in my temp directory and cropped a 100x100 piece from it), corrupted with errors of the kind I described (which really truly do mean that the probability distribution of the values for any pair of pixels is uniform) and yields something clearly recognizable as a mildly messed-up version of the original image.
So ... What do you mean by "invalid"? I mean, you could mean two almost-opposite things. (1) You think I'm cheating, so any success in the reconstruction just means that the data aren't as badly corrupted as I say. (2) You think I'm failing, so when I say I've done the reconstruction with some success you disagree and think my output is as garbagey as the input looks and contains no real information about the (original, uncorrupted) image. (Maybe there are other possibilities too, but those seem the obvious ones.)
I'm happy to address either of those claims, but they demand different sorts of addressing (for #1 I guess I'd provide the actual code and input data, and some calculations showing that my claim about how random the pixel values are is true, making it as easy as possible for you to replicate my results if you care; for #2 I'd put a little more effort into the algorithm so that its reconstructions become more obviously good enough).
Replies from: gjm, None↑ comment by gjm · 2020-07-18T16:14:53.277Z · LW(p) · GW(p)
Just for fun, I improved the algorithm a bit. Here's what it does now:

Still not perfect -- there's some residual banding that is never going to be 100% removable but could be made much better with more understanding of the statistics of typical images, and something at the right-hand side that seems like the existing algorithm ought to be doing better and I'm not quite sure why it doesn't. But I don't feel like taking a lot more time to debug it.
You're seeing its performance on the same input image that I used for testing it, so it's always possible that there's some overfitting. I doubt there's much, though; everything it does is still rather generic.
(In case anyone cares, the changes I made are: 1. At a couple of points it does a different sort of incremental row-by-row/column-by-column optimization, that tries to make each row/column in succession differ as little as possible from (only) its predecessor, and doesn't treat wrapping around at 255/0 as indicating an extra-big change. 2. There's an annoying way for the algorithm to get stuck in a local minimum, where there's a row discontinuity and a column discontinuity and fixing one of them would push some pixels past the 255/0 boundary because of the other discontinuity; to address this, there's a step that considers row/column pairs and tries making e.g. a small increase in pixel values right of the given column and a small decrease in pixel values right of the given row. Empirically, this seems to help get out of those local minima. 3. The regularizer (i.e., the "weirdness"-penalizing part of the algorithm) now tries not only to make adjacent pixels be close in value, but also (much less vigorously) to make some other nearby pixels be close in value.)
Replies from: Viliam↑ comment by Viliam · 2020-08-05T10:22:11.154Z · LW(p) · GW(p)
I am fascinated by the amount of effort you put into writing a comment.
I understand the call of duty and sometimes spend 30 minutes writing and editing a short comment. But designing an algorithm to prove a concept, and writing an application... wow!
(Could you perhaps expand the comment into a short article? Like, remove all the quarrel, and just keep it like: "this is a simple algorithm that achieves something seemingly impossible"; perhaps also with some pseudocode. Because this is interesting per se, in my opinion, even for someone who hasn't read this thread.)
Replies from: gjm↑ comment by gjm · 2020-08-05T11:37:18.208Z · LW(p) · GW(p)
Thanks for the kind words! I guess it might be worth making into an article. (And I agree that if so it would be best to make it more standalone and less debate-y, though it might be worth retaining a little context.) I'm on holiday right now so no guarantees :-).
↑ comment by [deleted] · 2020-07-18T15:05:25.993Z · LW(p) · GW(p)
As I read it, by “invalid” they mean not 1 or 2 you suggested but (3) your reconstruction process is assuming something which is the actual cause of most of the non-randomness in your output, and would produce a plausible-looking image when run on any random set of pixels.
For the example you gave (3) is clearly not true - there’s no way that any random set of pixels would produce something so correlated with the original image, when the reconstruction algorithm doesn’t itself embed the original image. But as far as I know LIGO doesn’t know the original image, so the fact that they get something structured-looking out of noise isn’t meaningful? Or at least that’s how I interpret nixtaken’s argument; this is really not my area of expertise.
Replies from: gjm↑ comment by gjm · 2020-07-18T15:55:31.204Z · LW(p) · GW(p)
Kirsten is claiming that my algorithm is invalid, even though (so it seems to me) it demonstrably does a decent job of reconstructing the original image I gave it despite the corruption of the rows and columns. Of course she can still claim that the EHT team's reconstruction algorithm doesn't have that property, that it only gives plausible output images because it's been constructed in such a way that it can't do otherwise, but at the moment I'm not arguing that the EHT team's reconstruction algorithm is any good, I'm arguing only that one specific thing Kirsten claimed about it is flatly untrue: namely, that if the phases are corrupted in anything like the way Bouman describes then there is literally no way to get any actual phase information from the data. The point of the image reconstruction I'm demonstrating here is that you can have corruption with a similar sort of pattern that's just as severe but still be able to do a lot of reconstruction, because although the individual measurements' phases are hopelessly corrupt (in my example: the individual pixels' values are hopelessly corrupt) there is still good information to be had about their relationships.
[EDITED to add:] ... Or maybe I misunderstood? Perhaps "This method is invalid" she means that somehow anything that has the same sort of shape as what I'm doing here is bad, even if it demonstrably gives good results. If so, then I guess my problem is that she hasn't enabled me to understand why she considers it "invalid". Her objections all seem to me like science-by-slogan: describe something in a way that makes it sound silly, and you've shown it's no good. Unfortunately, all sorts of things that can be made to sound silly turn out to be not silly at all, so when faced with a claim that something that demonstrably works is no good I'm going to need more than slogans to convince me.
comment by gjm · 2020-07-17T18:20:42.501Z · LW(p) · GW(p)
The anti-EHT portion of this seems about as bad, I'm afraid, as the anti-LIGO portion of your other anti-LIGO post. You point and laugh at various things said by Bouman, and you're wrong about all of them.
(Also, it turns out that all your quotations are not actually quotations. You're paraphrased Bouman, often uncharitably and often apparently not understanding what she was actually saying. I don't think you should do that.)
----
First, a couple from Bouman's TEDx talk before the EHT results came out. These you just say are "absurd" and suggest that she had "terrible teachers and no advisor", without offering any actual explanation of what's wrong with them, so I'll have to guess at what your complaint is.
Bouman says (TEDx talk, 11:00) "I can take random image fragments and assemble them like a puzzle to construct an image of a black hole". Perhaps your objection is to the idea that this amounts to making an image at random, or something. If you read the actual description of the CHIRP algorithm Bouman is discussing, you will find that nothing in it is anything like that crazy; Bouman is just trying to give a sketchy idea (for a lay audience with zero scientific or mathematical expertise) of what she's doing. I don't much like her description of it, but understood as an attempt to convey the idea to a lay audience there's nothing absurd about it.
Bouman says (TEDx talk, 6:40): "Some images are less likely than others and it is my job to design an algorithm that gives more weight to the images that are more likely.". Perhaps your objection is that she's admitting to biasing the algorithm so it only ever gives images that are consistent with (say) the predictions of General Relativity. Again, if you read the actual paper, it's really not doing that.
So what is it doing? Like many image-reconstruction algorithms, the idea is to search for a reconstruction that minimizes a measure of "error plus weirdness". The error term describes how badly wrong the measurements would have to be if reality matched the candidate reconstruction; the weirdness term (the fancy term is "regularizer") describes how surprising the candidate reconstruction is in itself. Obviously this framework is consistent with an algorithm with a ton of bias built in (e.g., the "weirdness" term simply measures how different the candidate reconstruction is from a single image you want to bias it towards) or one with no bias built in at all (e.g., the "weirdness" term is always zero and you just pick an image that minimizes the error). What you want, as Bouman explicitly says at some length, is to pick your "weirdness" term so that the things it penalizes are ones that are unlikely to be real even if we are quite badly wrong about (e.g.) exactly what happens in the middle of a galaxy.
The "weirdness" term in the CHIRP algorithm is a so-called "patch prior", which means that you get it by computing individual weirdness measures for little patches of the image, and you do that over lots of patches that cover the image, and add up the results. (This is what she's trying to get at with the business about random image fragments.) The patches used by CHIRP are only 8x8 pixels, which means they can't encode very much in the way of prejudices about the structure of a black hole.
If you picked a patch prior that said that the weirdness of a patch is just the standard deviation of the pixels in the patch, then (at least for some ways of filling in the details) I think this is equivalent to running a moving-average filter over your image. I point this out just as a way of emphasizing that using a patch prior for your "weirdness" term doesn't imply any controversial sort of bias.
For CHIRP, they have a way of building a patch prior from a large database of images, which amounts to learning what tiny bits of those images tend to look like, so that the algorithm will tend to produce output whose tiny pieces look like tiny pieces of those images. You might worry that this would also tend to produce output that looks like those images on a larger scale, somehow. That's a reasonable concern! Which is why they explicitly checked for that. (That's what is shown by the slide from the TEDx talk that I thought might be misleading you, above.) The idea is: take several very different large databases of images, use each of them to build a different patch prior, and then run the algorithm using a variety of inputs and see how different the outputs are with differently-learned patch priors. And the answer is that the outputs look almost identical whatever set of images they use to build the prior. So whatever features of those 8x8 patches the algorithm is learning, they seem to be generic enough that they can be learned equally well from synthetic black hole images, from real astronomical images, or from photos of objects here on earth.
So, "an algorithm that gives more weight to the images that are more likely" doesn't mean "an algorithm that looks for images matching the predictions of general relativity" or anything like that; it means "an algorithm that prefers images whose little 8x8-pixel patches resemble 8x8-pixel patches of other images, and by the way it turns out that it hardly matters what other images we use to train the algorithm".
Oh, a bonus: you remember I said that one extreme is where the "weirdness" term is zero, so it definitely doesn't import any problematic assumptions about the nature of the data? Well, if you look at the CalTech talk at around 38:00 you'll see that Bouman actually shows you what you get when you do almost exactly that. (It's not quite a weirdness term of zero; they impose two constraints, first that the amount of emission in each place is non-negative, and second a "field-of-view constraint" which I assume means that they're only interested in radio waves coming from the region of space they were actually trying to measure. ... And it still looks pretty decent and produces output with much the same form as the published image.
----
Then you turn to a talk Bouman gave at CalTech. You say that each of the statements you quote out of context "would disqualify an experiment", so let's take a look. With these you've said a bit more about what you object to, so I'm more confident that my responses will actually be responsive to your complaints than with the TEDx talk ones. These are in the same order as your list, which is almost but not quite the same as their order within the talk.
Bouman says (CalTech, 5:08) “this is equivalent to taking a picture of an orange on the moon.” I already discussed this in comments on your other post: you seem to think that "this seems impossibly hard" is the same thing as "this is actually impossibly hard", and that's demonstrably wrong because other things that have seemed as obviously difficult as getting an image of an orange on the moon have turned out to be possible, and the whole point of Bouman's talk is to say that this one turned out to be possible too. Of course it could turn out that she's wrong, but what you're saying here is that we should just assume she's wrong. That would have made us dismiss (for instance) radio, electronic computers, and the rocketry that would enable us to put an orange on the moon if we chose to do so.
Bouman says (CalTech, 14:40) “the challenge of dealing with data with 100% uncertainty.” Except that she doesn't, at least not anywhere near that point in the video. She does say that some things are off by "almost 100%", but she doesn't e.g. use the word "uncertainty" here. Which makes it rather odd that the first thing you do is to talk about their choice of using "uncertainty" to quantify things. So, anyway, you begin by suggesting that maybe what they're trying to do is to average data with itself several times to reduce its errors. That would indeed be stupid, but you have no reason to think that the EHT team was doing that (or anything like it) so this is just a dishonest bit of rhetoric. Then you say "They convinced themselves that they could use measurements with 100% uncertainty because the uncorrelated errors would would cancel out and they called this procedure: closure of systematic gain error" and complain that it's only correlated errors that you can get rid of by adding things up, not uncorrelated ones. Except that so far as I can tell you just made up all the stuff about correlated versus uncorrelated errors.
So let's talk about this for a moment, because it seems pretty clear that you haven't understood what they're doing and have assumed the most uncharitable possible interpretation. You say: "But from what I could tell, this procedure was nothing more than multiplying together the amplitudes and adding the phase errors together and from what I learned about basic data analysis, you can only add together correlated errors that you want to remove from your data."
Nope, the procedure is not just multiplying the amplitudes and adding the phases, although it does involve doing something a bit like that, and the errors are correlated with one another in particular ways which is why the method works.
So, they have a whole lot of measurements, each of which comes from a particular pair of telescopes at a particular time (and at a particular signal frequency, but I think they pick one frequency and just work with that). Each telescope at each time has a certain unknown gain error and a certain unknown phase error, and the measurements they take (called "visibilities" are complex numbers with the property that if i,j are two telescopes then the effect of those errors is to multiply V(i,j) by . And now the point is that there are particular ways of combining the measurements that make the gains or the phases completely cancel out. So, e.g., if you take the product V(i,j) V(j,k) V(k,l) then the gain errors are still there but the phases cancel, so despite the phase errors in the individual measurements you know the true phase of that product. And if you take the product (V(a,b) V(c,d)) / (V(a,d) V(b,c)) then the phase errors are still there but the gains cancel, so despite the gain errors in the individual measurements you know the true magnitude of that product.
So: yes, the errors are correlated, in a very precise way, because the errors are per-telescope rather than per-visibility-measurement. That doesn't let you compute exactly what the measurements should have been -- you can't actually get rid of the noise -- but it lets you compute some other slightly less informative derived measurements from which that noise has been completely removed.
(There will be other sources of noise, of course. But those aren't so large and their effects can be effectively reduced by taking more/longer measurements.)
Also, by the way, what she's saying is not that overall the uncertainty is 100% (again, I feel that I have to reiterate that so far as I can tell that particular formulation of the statement is one you just made up and not anything Bouman actually said) but that for some measurements the gain error is large. (Mostly because one particular telescope was badly calibrated.)
Bouman says (CalTech, 16:00) “the CLEAN algorithm is guided a lot by the user.” Yes, and she is pointing out that this is an unfortunate feature of the ("self-calibrating") CLEAN algorithm, and a way in which her algorithm is better. (Also, if you listen at about 35:00, you'll find that they actually develope da way to make CLEAN not need human guidance.)
Bouman says (CalTech, 19:30) “Most people use this method to do calibration before imaging, but we set it up to do calibration during imaging by multiplying the amplitudes and adding the phases to cancel out uncorrelated noise.” This is the business with products and quotients of visibilities that I described above.
Bouman says (CalTech, 31:40) “A data set will equally predict an image with or without a hole if you lack phase information.” Except she doesn't say that or anything like it: you just made that up. If this is meant to be a paraphrase of what she said, it's an incredibly bad one. But, to address what might be your point here (this is an instance where you just misquote, point and laugh, without explaining what problem you claim to see, so I have to guess), note that it is not the case that they lack phase information. Their phases have errors, as discussed above, and some of those errors may be large, but they are systematically related in a way that means that a lot of information about the phases is recoverable without those errors.
Bouman says (CalTech, 39:30) “The phase data is unusable and the amplitude data is barely usable.” Once again, that isn't actually what she says. I don't find her explanation in this part of the talk very clear, but I think what she's actually talking about is using the best-fit parameters they got as a way of inferring what those gain and/or phase errors are, not because they need to do that to get their image but because they can then do that multiple times using different radio sources and different image-processing pipelines and check that they get similar results each time -- it's another way to see how robust their process is, by giving it an opportunity to produce silly results -- and she's saying that the phases are too bad to be able to do that. Again, there absolutely is usable phase information even though each individual measurement's phase is scrambled.
If you look at about 40:50 there's a slide that makes this clearer. Their reconstruction uses "closure phases" (i.e., the quantities computed in the way I described above, where the systematic phase errors cancel) and "closure amplitudes" (i.e., the other quantities computed in the way I described above, where the systematic amplitude errors cancel) and "absolute amplitudes" (which are bad but not so bad you can't get useful information from them) -- but not the absolute phases (which are so bad that you can't get useful information from them without doing the cancellation thing). That slide also shows an image produced by not using the absolute amplitudes at all, just for comparison; the difference between the two gives some idea of how bad the amplitude errors are. (Mostly not that bad, as she says.)
Bouman says (CalTech, 36.20) “The machine learning algorithm tuned hundreds of thousands of ‘parameters’ to produce the image.” I'm pretty sure you misunderstood here, though her explanation is not very clear. (The possibility of misunderstanding is one reason why it is very bad that you keep presenting your paraphrases as if they are actual quotations.) What they had hundreds of thousands of was parameter values. That is, they looked at hundreds of thousands of possible combinations of values for their parameters, and for the particular bit of their process she's describing at this point they chose a (still large but) much smaller number of parameter-combinations and looked at all the resulting reconstructions. (The goal here is to make sure that their process is robust and doesn't give results that vary wildly as you vary the parameters that go into the reconstruction procedure.)
↑ comment by gjm · 2020-07-18T10:22:06.219Z · LW(p) · GW(p)
Every part of my comment is in response to a corresponding part of what you wrote. So your accusation of Gish-galloping is exactly backwards. The reason why the Gish gallop works is that it's generally much quicker to make a bogus claim than to refute it. You made a lot of bogus claims; I had to write a lot in order to refute them all. (Well, I'm sure I didn't get them all.) ... And then you accuse me of doing a Gish gallop? Really?
If you think my logic is wrong, then please show where it's wrong. If your complaint is only that it's convoluted -- well, science and mathematics are complicated sometimes. I don't actually think what I'm saying is particularly convoluted, but I will admit to preferring precise reasoning over vague slogans like "no adding uncorrelated phase errors".
Of course I don't claim that literally every thing you wrote was wrong. But I do think (and that is what I said) that in none of the cases where you (mis)quoted Bouman and complained was your objection actually correct.
If there were "one point on which all the others rest" then indeed I could have picked it out and concentrated on that. But there isn't: you make a lot of complaints, and so far as I can see there isn't one single one on which all else depends. (If I had to identify one single thing on which all your objections rest, it would be something that you haven't actually said and indeed I'm only guessing: I think you don't believe black holes exist and therefore when someone presents what claims to be evidence of black holes you "know" it must be wrong and therefore go looking for all the ways they could have erred. But of course my attempt at diagnosis could be wrong.)
As for the assorted mere insinuations ("extreme black-and-white thinking", "lack of nuance", "convoluted logic", "weakness", "redundancies and redirects", "jargon-rich", "smoke and mirrors") -- well, other readers (if any there be) can make up their own minds about that. But for what it's worth, none of that was a goal; I try to write as simply and clearly as correctness allows. I'm sure I don't always achieve perfect success; who does?
↑ comment by gjm · 2020-07-18T19:05:49.775Z · LW(p) · GW(p)
No, we pointed out the blatant errors in what you wrote.
You've claimed in a couple of places, now, that I am engaging in misleading rhetoric, but so far the only thing you've said about that that's concrete enough to evaluate is that I wrote a lot ... in my response to something you wrote that was longer. If there are specific things I have written that you find misleading, I would be interested to know what they are and what in them you object to. I'm not trying to pull any rhetorical tricks, but of course that's no guarantee of not having written something misleading, and if so I would like to fix it.
↑ comment by gjm · 2020-07-18T10:10:35.788Z · LW(p) · GW(p)
I did not say that resolution limitations could be overcome by just taking more data.
I did say that unsystematic noise can be dealt with by taking more data. This should not be controversial; it is standard procedure and for most kinds of noise it works extremely well. (For some kinds of noise the right way to use the extra data is more sophisticated than e.g. just averaging. There are possible noise conditions where no amount of extra data will help you because there is literally no information at all in your measurements, but that is not the situation the EHT is facing.)
You keep talking about "hard limits" and "cardinal sins" but I don't think you have understood the material you are looking at well enough to make those claims.
↑ comment by gjm · 2020-08-05T11:40:24.594Z · LW(p) · GW(p)
If someone shows evidence of (1) being generally clueful and (2) having read what you wrote, and they "have missed the points I was making", then I suggest that you might find it advisable to explain what they misunderstood and how your intention differs from what they thought you said. Just saying "you misunderstood me" achieves nothing. (Unless your only goal is to attack someone who has disagreed with you, I suppose. There may be places where that's an effective tactic, but I think that here it's unlikely to make anyone think better of you or worse of them.)
↑ comment by gjm · 2020-07-18T10:07:01.188Z · LW(p) · GW(p)
You say "You admitted above that they added uncorrelated phase errors together. That is a cardinal sin of data analysis". I don't know where you learned data analysis, but this feels to me like a principle you just made up in order to criticize Bouman. She's got an algorithm that (among other things) does something whose effect is to add up some phase errors. It happens that doing so makes them cancel out. There is nothing whatsoever wrong with this. (The errors are systematically related to one another, though I don't think correlation is the right language to use to describe this relationship.)
comment by [deleted] · 2020-08-05T03:10:21.601Z · LW(p) · GW(p)
Dear nixtaken,
regarding the image of an atom, you must read the paper more carefully. Your questions have simple answers:
"How did they choose which atoms to use in image construction?" They used every hydrogen atom that were excited at the focus of the laser beam. The state selection process is made with the frequency of the UV laser. A temporal selection is made with the pulsed UV laser. The interference pattern produces electrons ejected at specific angles.
"How did they eliminate common mode errors from the toroid?" Not sure how this applies here. The atoms emit electrons at an angle that is converted into a position at the focal plane. They saw interference rings in a previous experiment with Xe, so the resolution is sufficient. You seem to be thinking, erroneously, that the image is a representation of the wavefunction in 'position space', but it is actually a representation of interference in momentum space.
"What was their control variable?" The frequency of the ionizing laser which allowed them to select specific states.
"None of these questions are answered in the scientific publications" If you had worked in this field of research you could figure it out.
"The scientific method requires that multiple experiments should be done by different groups and with different methods before one should believe a result." Indeed. But experimenters are not motivated to repeat an experiment that already agrees with 100-year old quantum mechanics. (It's not like they are measuring the speculative Higgs boson or dark matter particles here.) What you are asking is to repeat a measurement that is as established as the two-slit experiment to observe electron interference and the atomic hydrogen wavefunction. There is very little potential for a new discovery.
↑ comment by Bucky · 2020-07-17T23:12:15.500Z · LW(p) · GW(p)
I feel like the point you should be making is that there are some pitfalls to Bayesian methods which need more attention. Instead the piece comes across as a sarcastic denouncement of Bayesian methods in general as insufficiently scientific.
In general Bayesian methods have proved to be incredibly powerful tools and I worry you’re throwing out the baby with the bath water.
comment by Bucky · 2020-07-17T20:12:43.685Z · LW(p) · GW(p)
I haven‘t looked in much depth at your specific analyses but I think trying to present these problems (assuming there are actually problems) as machine learning issues is misguided.
As an example here [LW · GW] is an analysis of a research paper I did a couple of years ago. Similarly to your claims about the papers you look at, it is a widely cited paper whose claims are not backed up by the data due to too much flexibility with the parameters used. The paper didn’t use any bayesian analysis, it just tested multiple hypotheses to such an extent that it got significant results by chance. Sloppy research is not a new phenomenon and definitely doesn’t require Bayesian analysis.
If your assertion is that machine learning users are unaware of the dangers of overfitting then I suggest looking at a few online training courses on machine learning where you will find they go on and on and on about overfitting almost to the point of self-parody.
The complaints about using priors in Bayesian statistics are well trodden ground and I think it would be instructive to read up on implicit priors of Frequentist statistics.
I think lumping in data falsification in with machine learning is particularly disingenuous - liars gonna lie, the method isn’t particularly relevant.
So basically I don’t think you’ve identified faults which are specific to machine learning or given evidence that the errors are more prevalent than when using alternative methods (even with the assumption that your specific analyses are correct).