Exploration-Exploitation problems
post by Elo · 2016-12-28T01:33:01.033Z · LW · GW · Legacy · 4 commentsContents
You want to explore as much as to increase your information with regard to both the quality of the rest of the exploration and possible results and the expected returns on the existing knowledge.
Try this:
None
4 comments
Original post: http://bearlamp.com.au/exploration-exploitation-problems/
I have been working on the assumption that exploration-exploitation knowledge was just common. Unfortunately I did the smart thing of learning about them from a mathematician at a dojo in Melbourne, which means that no. Not everyone knows about it. I discovered that again today when I searched for a good quick explanation of the puzzle. With that in mind this is about Exploration Exploitation.
The classic Exploration-Exploitation problem in mathematics is the multi-armed bandit. Which is a slang term for a bank of slot machines. Where the player knows that each machine has a variable payoff and you have a limit number of attempts before you run out of money. You want to balance trying out new machines with unknown payoffs against exploiting the knowledge you already have from the earlier machines you tried.
When you first start on new bandits, you really don't know which will pay out and at what rates. So some exploration is necessary to know what your reward ratio in the territory will be. As your knowledge grows, you get to know which bandits are likely to pay, and which are not, and this later informs your choices as to where to place your dollars.
Mathematicians love a well specified problem like this because it allows us to make algorithm models of patterns that will return rewards or guarantee rewards given certain circumstances. (see also - the secretary problem which does similar. Where I showed how it applied to real life dating)
Some of the mathematical solutions to this problem look like:
Epsilon greedy - The best lever is selected for a proportion 1-ε of the trials, and a lever is selected at random (with uniform probability) for a proportion ε. A typical parameter value might be ε =0.1 but this can vary widely depending on circumstances.
Epsilon-decreasing strategy: Similar to the epsilon-greedy strategy, except that the value of ε decreases as the experiment progresses, resulting in highly exploratory behaviour at the start and highly exploitative behaviour at the finish.
Of course there are more strategies, and the context and nature of the problem matters. If the machines suddenly one day in the future all change, you might have a strategy that would prepare for potential scenarios like that. As you start shifting away from the hypothetical and towards real life your models need to increase complexity to cater to the details of the real world.
If this problem is more like real life (where we live and breathe), the possible variability of reality starts coming in to play more and more. In talking about this - I want to emphasise not the problem as interesting, but the solution of <sometimes explore> and <sometimes exploit> in specific ratios or for specific reasons. The mathematical solutions the the multi-armed bandit problem are used in such a way to take advantage of the balance between not knowing enough and taking advantage of what you do know.
What supercharges this solution and how it can be applied to real life is value of information.
Value of Information says that in relation to making a decision, what informs that decision is worth something. With expensive decisions, risky decisions, dangerous decisions, highly lucrative decisions, or particularly unknown decisions being more sure is important to think about.
VoI suggests that any decision that is worth money (or worth something) can have information that informs that decision. The value of information can add up to the value of the reward on correctly making the decision. Of course if you spend all the potential gains from the decision on getting the perfect information you lose the chance to make a profit. However usually a cheap (relative to the decision) piece of information exists that will inform the decision and assist.
How does this apply to exploration-exploitation?
The idea of VoI is well covered in the book, how to measure anything. While the book goes into detail and is really really excellent for applying to big decisions, the ideas can also be applied to our simple every day problems as well. With this in mind I propose a heuristic:
You want to explore as much as to increase your information with regard to both the quality of the rest of the exploration and possible results and the expected returns on the existing knowledge.
The next thing to supercharge our exploration-exploitation and VoI knowledge is Diminishing returns.
Diminishing returns on VoI is when you start out not knowing anything at all, and adding a little bit of knowledge goes a long way. As you keep adding more and more information the return on the extra knowledge has a diminishing value.

Worked example: Knowing the colour of the sky.
So you are blind and no one has ever told you what colour the sky is. You can't really be sure what colour the sky is but generally if you ask enough people the consensus should be a good enough way to conclude the answer.

So one guy gave you your first inkling of what the answer is. But can you really trust him?
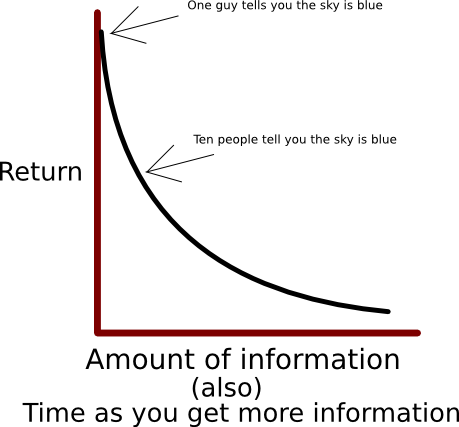
Yea cool. Ten people. Probably getting sure of yourself now.
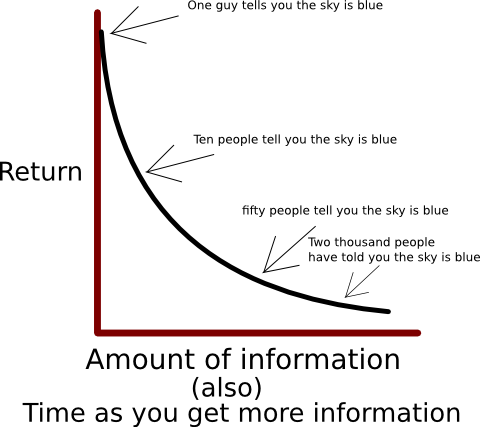
Really, what good is Two Thousand people after the first fifty? Especially if they all agree. There's got to be less value of the 2001st person telling you than there was the 3rd person telling you.
Going back to VoI, how valuable was the knowledge that the sky is blue? Probably not very valuable, and this isn't a great way to gather knowledge in the long run.
The great flaw with this is also if I asked you the question - "what colour is the sky?" you could probably hint as to a confident guess. If you are a well calibrated human, you already know a little bit of everything and the good news is that calibration is trainable.
With that in mind; if you want to play a calibration game there are plenty available on google.
The great thing about calibration is that it seems to apply across all your life, and all things that you estimate. Which is to say that once you are calibrated, you are calibrated across domains. This means that if you become good at it in one area, you become better at it in other areas. We're not quite talking about hitting the bullseye every time, but we are talking about being confident that the bullseye is over there in that direction. Which is essentially the ability to predict the future within a reasonable set of likelihoods.
Once you are calibrated, you can take calibration, use it to apply diminishing returns through VoI to supercharge your exploration exploitation. But we're not done. What if we add in Bayesian statistics? What if we can shape our predicted future and gradually update our beliefs based on tiny snippits of data that we gather over time and purposefully by thinking about VoI, and the diminishing returns of information.
I don't want to cover Bayes because people far smarter than me have covered it very well. If you are interested in learning bayes I would suggest heading to Arbital for their excellent guides.
But we're not done at bayes. This all comes down to the idea of trade-offs. Exploration VS exploitation is a trade off of {time/energy} vs expected reward.
A classic example of a trade-off is a story of Sharpening the Saw (from the book 7 habits of highly effective people)
A woodcutter strained to saw down a tree. A young man who was watching asked “What are you doing?”
“Are you blind?” the woodcutter replied. “I’m cutting down this tree.”
The young man was unabashed. “You look exhausted! Take a break. Sharpen your saw.”
The woodcutter explained to the young man that he had been sawing for hours and did not have time to take a break.
The young man pushed back… “If you sharpen the saw, you would cut down the tree much faster.”
The woodcutter said “I don’t have time to sharpen the saw. Don’t you see I’m too busy?”
The thing about life and trade offs is that all of life is trade-offs between things you want to do and other things you want to do.
Exploration and exploitation is a trade off between the value of what you know and the value of what you might know if you find out.
Try this:
- Make a list of all the things you have done over the last 7 days. (Use your diary and rough time chunking)
- Sort them into exploration activities and exploitation activities.
Answer this: - Am I exploring enough? (on a scale of 1-10)
- Am I exploiting enough? (on a scale of 1-10)
- Have I turned down any exploring opportunities recently?
- Have I turned down any exploitation opportunities recently?
- How could I expand any exploring I am already doing?
- How could I expand any exploiting I am already doing?
- How could I do more exploring? How could I do less exploring?
- How could I do more exploiting? How could I do less exploiting?
There are two really important things to take away from the Exploration-Exploitation dichotomy:
- You probably make the most measurable and ongoing gains in the Exploitation phase. I mean - lets face it, these are long running goal-seeking behaviours like sticking to an exercise routine.
- The exploration might be seem more fun (find exciting and new hobbies) but are you sure that's what you want to be doing in regard to 1?
Meta: This is part 1 of a 4 part series.
This took in the order of 10-15 hours to finish because I was doing silly things like trying to fit 4 posts into 1 and stumbling over myself.
4 comments
Comments sorted by top scores.
comment by Peter Wildeford (peter_hurford) · 2016-12-29T18:48:32.786Z · LW(p) · GW(p)
This is pretty cool -- I like the write-up. I don't mean to pry into your life, but I would find it interesting to see an example of how you answer these questions. It would help me internalize the process more.
Replies from: Elo↑ comment by Elo · 2016-12-29T22:35:11.857Z · LW(p) · GW(p)
I had about a thousand words of examples that I had generated but they were really rubbish and irrelevant. (http://bearlamp.com.au/the-ladder-of-abstraction-and-giving-examples/)
Exploration for me at the moment is spending lots of time having rationality conversations with people - usually in person. Then when I generate great ideas and insights and solutions to problems that people have I come home and exploit that knowledge by writing it down and sharing it with people and honing my set of published writing.
comment by RomeoStevens · 2016-12-28T22:53:27.608Z · LW(p) · GW(p)
I don't think exploration neglect comes from just too little explicit optimization for it. It is a skill and also has some prerequisites. Open/closed mode feels very analogous: https://vimeo.com/89936101
Replies from: Elo