LDL 2: Nonconvex Optimization
post by magfrump · 2017-10-20T18:20:54.915Z · LW · GW · 13 commentsContents
Coda None 13 comments
Edit 10/23: by request I'm going back and putting the images in. It's a pain that you can't place images in line! Also I edited the dumb probability calculation to make more sense since I may not be able to write another post today.
My favorite “party theorem” is Gauss-Bonnet. It’s the theorem that tells you why New Yorkers fold their pizza to eat it.

The statement of the Gauss-Bonnet theorem is, basically, for a two-dimensional Riemannian manifold, that the integral of Gaussian curvature over the interior plus the integral of geodesic curvature over the boundary is equal to 2 times pi times the Euler characteristic of the manifold.
The most important consequence of this is that the amount of curvature occurring on a surface is a topological constant. That is, in order to change “how curved” something is you have to tear or crease it, you can’t just stretch or bend it.
Now hopefully anyone can tell you that pizza, to begin with, is flat.

But as most people who have eaten pizza can also tell you, it doesn’t always stay flat.

(note: there aren't very many pictures of toppings falling off pizza around so I had to use one that isn't labeled for reuse--if this post starts getting lots of views please remind me to remove this image)
And this can cause all the toppings to fall off.
Is the pizza tearing or folding? No, usually it’s just bending and stretching. So if that can’t change how curved it is, why can the toppings fall off your pizza?
The answer is that Gaussian curvature, the ‘correct’ kind of curvature in the sense that it’s the kind that is topologically constant over the surface of the manifold, is basically the “curvature in both directions,” when looking at a surface.
When a pizza is flat, you can choose any direction, and it’s not curved, so 0. Then you choose the orthogonal direction, and it’s still not curved, so that’s 0 too. Then multiply those to get Gaussian curvature, and you get 0.
Conveniently, if you multiply ANYTHING by zero, you get zero. So all you need for your pizza to work out is, basically, one direction where the pizza isn’t curved, and it can curve as much as it wants in the other direction and still be “flat” since the curvature is being multiplied by zero.
But you can exploit this! If you pick a direction and purposefully curve your pizza in that direction, then in order to be “flat” in the Gaussian curvature sense, the pizza will be pushed to stay up in the other direction (unless it tears, which is always a possibility)
This is very convenient if you want to keep all that cheese on your pizza!
But if you’re a hyperintelligent n-dimensional shade of the color blue, this won’t help you.
Imagine you’re trying to eat a slice of three dimensional pizza, and you fold it in one direction to give one of it’s Laplacian eigenvalues a very high value. Then a second Laplacian eigenvalue will have to be zero, to cancel this out and maintain the zero Gaussian curvature of your hyperpizza. But this three dimensional hyperpizza has a third Laplacian eigenvalue! So while you hold your hyperpizza up by the crust in one dimension, and that pulls it up in a second dimension, all the toppings fall off in the third direction.
This brings us to the reason I’m talking about Gaussian curvature today.
In the ancestral environment, machine learning engineers cared a lot about avoiding local optima in their problems.
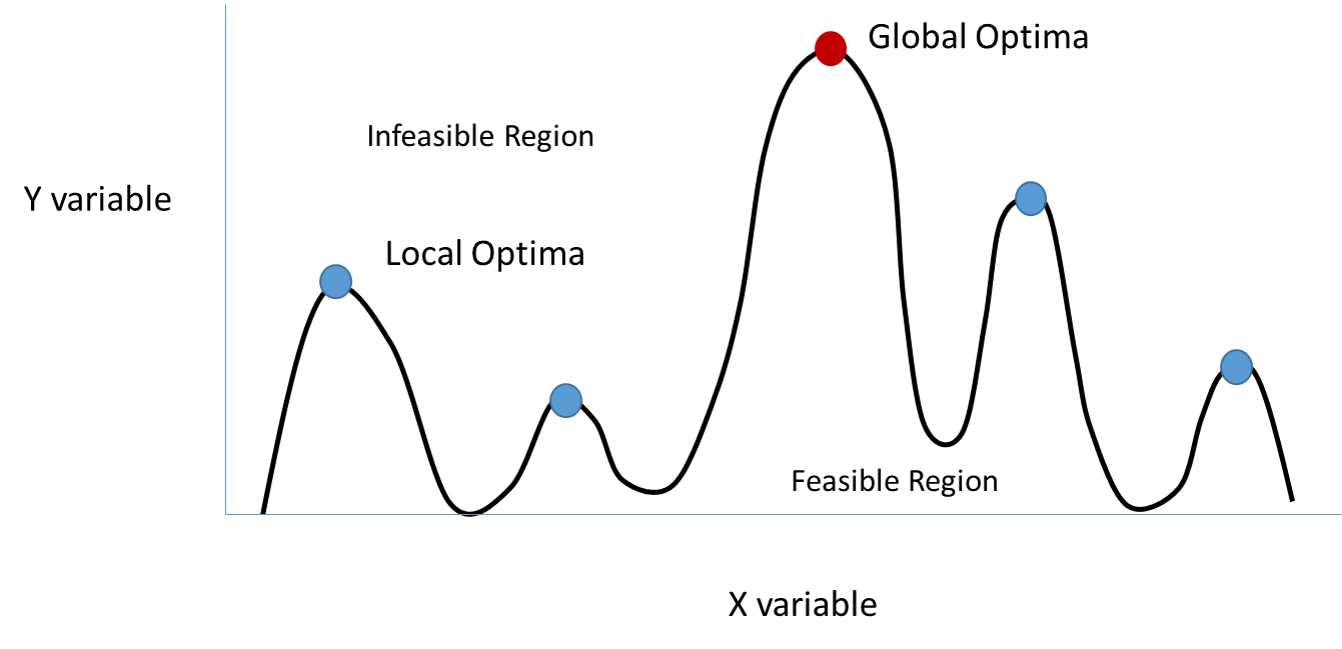
These local optima are places where the local derivatives are all zero, and even if you move a little bit nearby, you’ll end up rolling right back to them. Think about climbing to the highest peak; if you’re right next to a lower peak you’ll probably climb up that one instead of trying to find a different peak (at least if you’re an ML algorithm executing gradient descent).
One of the things that makes local optima so worrying is that, in some situations, you may have to go a long way to get to a different local optimum, and you’ll still be uncertain about whether you’re at the best one!
Those of you who remember your first calculus classes may recall that there are two ways for a local flat area to arise: at a peak or at a valley (or an inflection point but these should be extremely rare). If you’re trying to find the lowest place on the map, then a peak isn’t going to give you too much of a problem—you’ll move a little bit away and start rolling down the hill. There are plenty of ways to implement this in ML; things like random minor perturbation of your weights or data augmentation with noise or just normal tricks like Adam optimization.
This is where the pizza metaphor comes back. In the ancestral environment, machine learning engineers worked with things like pizza or three dimension hyperpizza. And they were really trying to get those toppings to fall off. But if there was one hand holding up a part of the pizza, then they couldn’t get moving, and if there was a second hand holding up the hyperpizza they were also stuck.
But as we’ve progressed in time and computational power and data size, we end up mostly working in very high dimensional spaces these days. A typical deep neural net can have tens of thousands of parameters, so our gradient descent is happening in a ten thousand dimensional space!
Now, there are a lot of steps that occur in training a neural network, and I don’t want to assume anything about the problem like the idea that peaks and valleys in different directions are independently likely. But if they are, and if the odds are 50/50 in any direction that you'll find a peak versus a valley, then to have a 10% chance of encountering a true local optimum you'll need to encounter N critical points, where N satisfies:
[1 - (.5^10000)]^N = .1
N log(1 - (.5^10000)) = log(.1)
N = log(.1)/log(1-.5^10000)
.5^1000 is about 10^-302, so .5^10000 is about 10^-3000, which google calculator refuses to keep in memory for me, but it looks like log(.1)/log(.999...) is about 2.3*10^(number of nines) so we can just flip that and say you'd need to encounter 10^3000 critical points before expecting one to be a local optimum (IF your features are independent--they usually aren't but that's a different problem).
In conclusion, getting stuck in local optima isn’t really a problem for deep learning. Local optima are just so hard to come by, that you don’t really expect to see them at all.
Coda
So personally I don’t think that convex optimization is a very interesting part of deep learning. It’s something that’s been studied extensively and implemented in low level C code and everyone has built specialized hardware for doing all the linear algebra, and I don’t feel like it’s under-studied or like it’s going to lead to any exciting breakthroughs. I’m glad people are working on it, but I don’t care that much about thinking about it myself. But I do like the Gauss-Bonnet pizza story and optimization is what’s been happening in the Coursera course and I want to write every day so here you go.
13 comments
Comments sorted by top scores.
comment by Ben Pace (Benito) · 2017-10-20T18:54:52.270Z · LW(p) · GW(p)
(Note: to post images, hit the 'palette' icon in the text toolbar, and drag some image boxes in. They don't naturally go inline, you'll have to add a textbox *after* them to continue writing after them.)
↑ comment by magfrump · 2017-10-20T23:52:57.357Z · LW(p) · GW(p)
Thanks for this explanation, but tbh I'm way too lazy to add them in now.
comment by roystgnr · 2017-10-23T13:46:34.593Z · LW(p) · GW(p)
This argument doesn't seem to take into account selection bias.
We don't get into a local optimum becuase we picked a random point and wow, it's a local optimum, what are the odds!?
We get into a local optimum because we used an algorithm that specifically *finds* local optima. If they're still there in higher dimensions then we're still liable to fall into them rather than into the global optimum.
↑ comment by magfrump · 2017-10-23T17:56:34.642Z · LW(p) · GW(p)
The point is that they really are NOT still there in higher dimensions.
↑ comment by roystgnr · 2017-11-08T16:04:18.826Z · LW(p) · GW(p)
Oh, well in that case the point isn't subtlely lacking, it's just easily disproven. Given any function from I^N to R, I can take the tensor product with cos(k pi x) and get a new function from I^{N+1} to R which has k times as many non-globally-optimal local optima. Pick a decent k and iterate, and you can see the number growing exponentially with higher dimension, not approaching 0.
Perhaps there's something special about the functions we try to optimize in deep learning, a property that rules out such cases? That could be. But you've said nothing special about (or even defined) a particular class of deep learning problems, rather you've made a claim about all higher dimensional optimization problems, a claim which has an infinite number of counterexamples.
Replies from: magfrump↑ comment by magfrump · 2017-11-14T23:25:49.262Z · LW(p) · GW(p)
I definitely intended the implied context to be 'problems people actually use deep learning for,' which does impose constraints which I think are sufficient.
Certainly the claim I'm making isn't true of literally all functions on high dimensional spaces. And if I actually cared about all functions, or even all continuous functions, on these spaces then I believe there are no free lunch theorems that prevent machine learning from being effective at all (e.g. what about those functions that have a vast number of huge oscillations right between those two points you just measured?!)
But in practice deep learning is applied to problems that humans care about. Computer vision and robotics control problems, for example, are very widely used. In these problems there are some distributions of functions that empirically exist, and a simple model of those types of problems is that they can be locally approximated over an area with positive size by taylor series at any point of the domain that you care about, but these local areas are stitched together essentially at random.
In that context, it makes sense that maybe the directional second derivatives of a function would be independent of one another and rarely would they all line up.
Beyond that I'd expect that if you impose a measure on the space of such functions in some way (maybe limiting by number of patches and growth rate of power series coefficients) that the density of functions with even one critical point would quickly approach zero, even while infinitely many such functions exist in an absolute sense.
I got a little defensive thinking about this since I felt like the context of 'deep learning as it is practiced in real life' was clear but looking back at the original post it maybe wasn't outlined in that way. Even so I think your reply feels disingenuous because you're explicitly constructing adversarial examples rather than sampling functions from some space to suggest that functions with many local optima are "common." If I start suggesting that deep learning is robust to adversarial examples I have much deeper problems.
comment by whales · 2017-10-21T04:00:18.654Z · LW(p) · GW(p)
Hm. Thinking of this in terms of the few relevant projects I've worked on, problems with (nominally) 10,000 parameters definitely had plenty of local minima. In retrospect it's easy to see how. Saddles could be arbitrarily long, where many parameters basically become irrelevant depending on where you're standing, and the only way out is effectively restarting. More generally, the parameters were very far from independent. Besides the saddles, for example, you had rough clusters of parameters where you'd want all or none but not half to be (say) small in most situations. In other words, the problem wasn't "really" 10,000-dimensional; we just didn't know how or where to reduce dimensionality. I wonder how common that is.
↑ comment by whales · 2017-10-21T05:56:03.762Z · LW(p) · GW(p)
Two more thoughts: the above is probably more common in [what I intuitively think of as] "physical" problems where the parameters have some sort of geometric or causal relationship, which is maybe less meaningful for neural networks?
Also, for optimization more broadly, your constraints will give you a way to wind up with many parameters that can't be changed to decrease your function, without requiring a massive coincidence. (The boundary of the feasible region is lower-dimensional.) Again, I guess not something deep learning has to worry about in full generality.
comment by α · 2017-10-21T00:50:44.741Z · LW(p) · GW(p)
But if, for any parameter, there’s some probability p that it’s an inconvenient valley instead of a convenient hill, in order to get stuck you need to have ten thousand valleys.
I don't understand this part. Is this the probability a given point in parameter space being an optima (min or max)? Is this the probability of a point, given that it is a critical or near-critical point, being an optima?
Instead of hills or valleys, it seems like the common argument is in favor of most critical points in deep neural networks being saddle points, and a fair amount of analysis has gone into what to do about that.
This paper argues that the issue is saddle points https://arxiv.org/pdf/1406.2572.pdf but given how it's been three years and those methods have not been widely adopted, I don't think it's really that much of an issue.
Most of how modern gradient descent is accomplished (e.g. momentum) tends to steamroll over a lot of these problems. Distill has a beautiful set of interactive explanations on how and why momentum affects the gradient descent process here: https://distill.pub/2017/momentum/ I'd highly recommend checking it out.
Additionally, for many deep neural network problems we explicitly don't want the global optima! This usually corresponds to dramatically overfitting the training distribution/dataset.
↑ comment by magfrump · 2017-10-21T01:58:10.171Z · LW(p) · GW(p)
Instead of hills or valleys, it seems like the common argument is in favor of most critical points in deep neural networks being saddle points
I agree, the point of the digression is that a saddle point is a hill in one direction and a valley in the other.
The point is that because it's a hill in at least one direction a small perturbation (like the change in your estimate of a cost function from one mini-batch to the next) gets you out of it so it's not a problem.
Is this the probability of a point, given that it is a critical or near-critical point, being an optima?
there p is the probability that, given a near-critical point, that in a given direction that criticality is hill-like or valley-like. If any of the directions are hill-like you can roll down those directions so you need your critical points to be very valley-like. It's a stupid computation that isn't actually well defined (the probability I'm estimating is dumb and I'm only considering one critical point when I should be asking how many points are "near critical" and factoring that in, among other things) so don't worry too much about it!