On the Implications of Recent Results on Latent Reasoning in LLMs
post by Rauno Arike (rauno-arike) · 2025-03-31T11:06:23.939Z · LW · GW · 6 commentsContents
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach Training Language Models to Reason in Continuous Latent Space Diffusion LLMs Some proposals I’m currently not worried about Conclusion None 6 comments
Faithful and legible CoT is perhaps the most powerful tool currently available to alignment researchers for understanding LLMs. Recently, multiple papers have proposed new LLM architectures aimed at improving reasoning performance at the expense of transparency and legibility. Due to the importance of legible CoT as an interpretability tool, I view this as a concerning development. This motivated me to go through the recent literature on such architectures, trying to understand the potential implications of each of them. Specifically, I was looking to answer the following questions for each paper:
- Does the paper claim genuine advantages over the transformer architecture, or does it leave the feeling that the authors were just exploring their curiosities without any good benchmark results or near-term applications?
- What are the trade-offs in comparison to traditional transformers? (I won’t mention the loss of visible CoT as a trade-off—this should be obvious anyways)
- What’s the maximum number of serial reasoning steps that the architecture can perform without outputting any human-understandable text?
- Does the architecture include the possibility of preserving human-interpretable CoT? As a simple example of what I have in mind, think of a small decoder head external to the model that can be attached to the latent space to mirror the model’s thought process in legible English in real time.
Below, I’ll summarize three relevant proposals and answer the above questions for each of them. I’ll first discuss Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach by Geiping et al., then Training Language Models to Reason in Continuous Latent Space by Hao et al., and finally diffusion LLMs. I’ll finish the post with an overview of some developments that I’m currently not worried about.
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
In this paper, the authors introduce a new LLM architecture that is depth-recurrent: for every token, the model performs recurrent computations that enable adaptive allocation of compute to different tokens. The paper introduces a family of models trained with this architecture, called Huginn. The architecture involves decoder-only transformer blocks structured into three functional groups:
- the prelude P, which embeds the input data into a latent space and consists of multiple transformer layers,
- the recurrent block R, which consists of recurrent layers that take in the embedded input e and the previous hidden state and output the refined hidden state , and
- the coda C, which un-embeds from latent space using multiple transformer layers and contains the prediction head.
Schematically, this looks as follows:
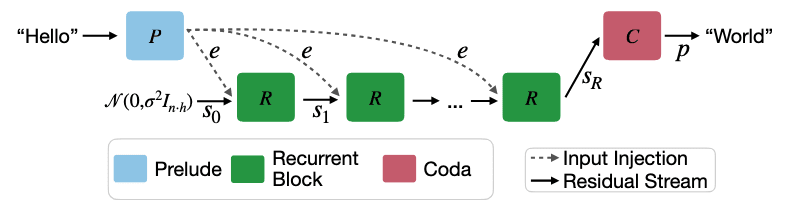
The recurrent block R can be looped for multiple iterations: e.g., the second iteration takes the final state of the first iteration as input and applies the same recurrent layers to refine this state further. During training, the number of recurrent iterations is sampled randomly for each input sequence, and each token within a single sequence is processed with the same number of recurrent iterations. At inference-time, the architecture zero-shot generalizes to perform different amounts of recurrent iterations for each input token. This is achieved by using a convergence criterion based on the KL-divergence between successive recurrent steps. If this KL-divergence falls below a threshold, the model stops iterating the recurrent block and moves on to the next token, thus being able to use per-token adaptive compute.[1]
There are three particularly important things to note about Huginn. First, in contrast to traditional RNNs, the recurrence is implemented at the layer level rather than at the token level, which enables the model to spend different amounts of computation on different tokens.
Second, in the main version of the architecture, the recurrent layers consist of normal causal self-attention blocks and MLPs and the first recurrent state for each token is randomly initialized. This means that although this architecture allows for more hidden computation on each individual token than transformers do, it doesn’t enable arbitrarily long chains of hidden serial reasoning: as is normally the case for self-attention, the self-attention layers can attend to information in the layer before, but not to information calculated at earlier positions in the same layer, so information can move through the model vertically and diagonally but not horizontally.
However, the authors claim that the model zero-shot generalizes at inference-time to the ability to use the last hidden state of the previous token as the initial recurrent state, thus enabling arbitrarily long hidden thoughts. This modification makes Huginn highly similar to COCONUT, the architecture that will be discussed in the next section, without any specialized fine-tuning. This is by far the most concerning part of the paper to me. My concerns are alleviated only by the fact that the authors seem to have performed the benchmark runs without this feature enabled, which means that although the model can use latent thoughts effectively, it doesn’t zero-shot generalize to higher-than-usual performance when hidden thoughts are enabled.
Third, during training, the authors backpropagate through only the last k iterations of the recurrent unit, regardless of the total number of recurrent iterations. This makes the maximum activation memory and backward compute independent of the number of recurrent iterations. The authors note that this resembles truncated backpropagation through time, with the modification that recurrence comes in depth rather than in time.
In the paper, k is usually fixed to 8. This fact seems important: I expect that such gradients cannot incentivize complex planning in the latent space during pre-training, since they can’t reach the first iteration of the recurrent unit and incentivize the formation of such plans (unless the recurrent unit is not very deep, but in those cases, there are very few serial reasoning steps available to the model in the first place). I don’t think this is a reason to discard all concerns about the hidden planning capabilities of this architecture: it’s plausible that the authors made this choice motivated by costs rather than by issues with training stability (they were indeed constrained by a very limited budget), or that even if a small value of k is unavoidable during pre-training, one could increase k for post-training. It’s just that I’d be way more concerned if the authors had found a way to sidestep all age-old issues related to backpropagation through long chains of recurrence.
How does all of this stack up against my questions?
Does the paper claim genuine advantages over the transformer architecture? — It is difficult to make strong conclusions based on the benchmark data. The results on reasoning benchmarks are stronger than those on general knowledge benchmarks, but as a confounder, the authors use a highly curated dataset with “just enough general webtext to allow the model to acquire standard language modeling abilities.” In general knowledge, Huginn outperforms the older Pythia series and performs similarly to first-generation OLMo-7B, but is clearly inferior to later OLMo models. In coding and math, Huginn also outperforms OLMo-7B-0424 and OLMo-7B-0724, but remains worse than OLMo-2-1124-7B. As another reference point that isn’t mentioned in the paper, Llama 1 7B would be clearly superior to Huginn in general knowledge and clearly inferior in GSM8k. Huginn's pre-training dataset consists of only 800B tokens, which limits its comparability to more recent models.
The recurrent module is definitely doing something real: the recurrent model substantially outperforms its non-recurrent twin on GSM8k and the ARC challenge set, and zero-shot generalization to the use of adaptive compute and continuous thoughts is certainly impressive. The authors also note at the end of the paper that the model can leverage the recurrent module to rotate shapes in latent space for numerical computations. However, due to the authors’ budget limitations and nonstandard dataset composition, it remains unclear how big of an advantage the recurrent module provides for practically relevant tasks.
What are the trade-offs in comparison to traditional transformers? — Whenever I see someone claiming that they’ve achieved a bigger-than-usual hidden serial reasoning depth or made a SOTA recurrent model or something else like that, my first question is whether they’re able to efficiently train this model at scale. There appears to be a fundamental trade-off [LW(p) · GW(p)] between highly parallelizable training and highly expressive forward passes, and so far, highly parallelizable training has been the more important factor. As mentioned above, this paper circumvents the efficiency problems by using truncated backprop and by relying on zero-shot generalization to the use of continuous thoughts and adaptive compute at inference-time. It’s unclear for now how well this will work: as discussed, there are reasons to expect that truncated backprop will lead to less expressive forward passes, and even though the model exhibits zero-shot generalization to continuous thoughts, it doesn’t seem to perform better when using continuous thoughts.
However, I wouldn’t have expected it to zero-shot generalize to better performance with continuous thoughts—it’s impressive that the model zero-shot generalizes at all. I also wouldn’t expect transformers to be at the absolute optimum of the parallelism trade-off—it’s very much possible that moving toward somewhat more expressive forward passes at the expense of parallelizability will yield better models at some point.
What’s the maximum number of serial reasoning steps that the architecture can perform without outputting any human-understandable text? — In theory, there’s no clear limit when continuous thoughts are enabled. In practice, it seems impossible that the model would zero-shot generalize to arbitrarily long continuous thoughts, and the paper doesn’t explicitly mention how far this ability goes. Nevertheless, it’s worth keeping a close eye on this, since the ability to use continuous thoughts could potentially be improved through fine-tuning.
In case continuous thoughts are not enabled, the maximum number of hidden serial reasoning steps is equal to the number of layers that the model has when using maximum recurrence depth. In the paper, this number is 132 steps, as that’s the maximum number of layers.
- Does the architecture include the possibility of preserving human-interpretable CoT? — I can’t think of a simple add-on to this architecture that would make the latent space more interpretable, though the fact that the authors notice the model rotating shapes in the latent space through simple PCA analysis might be a sign that the model’s latent space is at least not maximally uninterpretable.
Training Language Models to Reason in Continuous Latent Space
This paper already has an excellent summary, written by CBiddulph [LW · GW], so I’ll keep my own summary short. The authors train a model they call COCONUT (Chain of Continuous Thought) that can directly take its last hidden state at some token as the next input embedding. To achieve this, they take a pre-trained transformer (GPT-2 in the paper) and apply an iterative scheme to make it perform more and more of its reasoning without any output tokens. Specifically, the training procedure begins with the model generating a full CoT in natural language. In the first stage, the authors remove a single token from the front of the reasoning chain and replace it with a latent reasoning step. In the second stage, another token is removed from the reasoning chain and replaced with a latent reasoning step. Between the stages, cross-entropy loss is calculated on the remaining tokens after the continuous thoughts. The following figure provides a good visualization of the training procedure.
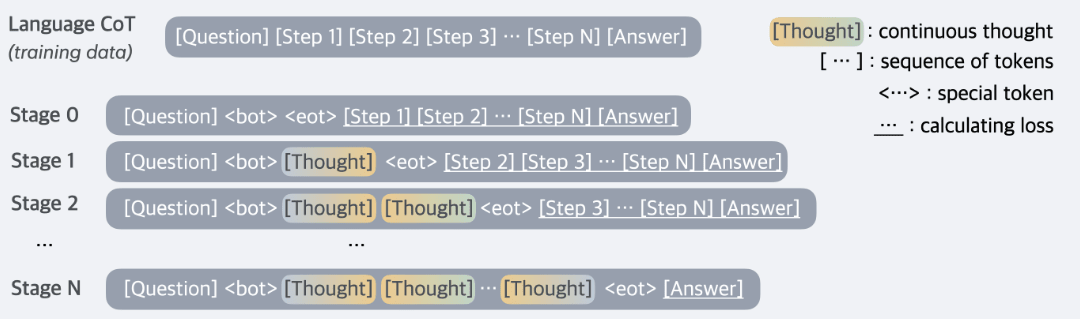
The paper presents this as a proof-of-concept: the training scheme can work, but benchmark results aren’t by any means flashy yet. COCONUT is tested on three benchmarks: GSM8k, ProntoQA, and ProsQA. It shows clear efficiency gains compared to a CoT-tuned version of GPT-2: on GSM8k, it produced answers in an average of 8.2 forward passes, compared to 25.0 for CoT. However, it lost out to CoT fine-tuning on accuracy. I recommend taking a look at CBiddulph’s post for a more thorough look into the results.
So, what should we think about the implications of this architecture for faithful CoT?
- Does the paper claim genuine advantages over the transformer architecture? — The paper claims that COCONUT can use its continuous thoughts to reason about multiple possible solutions in parallel in a breadth-first manner. However, the benchmark results are very underwhelming, so the practical significance of the theoretical computational advantages of COCONUT remains unclear for now.[2]
What are the trade-offs in comparison to traditional transformers? — Recall my remark about the parallelism trade-off when discussing the Huginn model. If the approach presented in this paper actually works, I’d say that the authors have found a clever way to circumvent this trade-off: pre-training is entirely performed on the highly parallelizable transformer architecture as usual, and only in post-training is the model trained to acquire the benefits of recurrent computations. Nevertheless, the authors mention in section 3 that “While we can save any repetitive computing by using a KV cache, the sequential nature of the multiple forward passes poses challenges for parallelism.” COCONUT doesn’t sidestep the parallelism trade-off, it just doesn’t incur the costs already at the pre-training stage.
I’m not sure how much averting those costs in pre-training helps in practice. When training a transformer to figure out complex proofs in continuous thoughts using the same approach, the amount of continuous forward passes that have to be backpropagated through will far exceed the 8.2 forward passes that COCONUT needs for GSM8k. The paper makes no progress towards making such backpropagation more efficient. This is exacerbated by the fact that the fine-tuning process is iterative, removing a single natural language token at a time. While it may be possible to find a more efficient training procedure that achieves the same results, the scalability of this technique remains speculative for now.
- What’s the maximum number of serial reasoning steps that the architecture can perform without outputting any human-understandable text? — As for Huginn, this number is arbitrarily large in theory, but the practical limit is unclear and depends on the maximum number of continuous forward passes that can be efficiently backpropagated through in order to train them to use continuous thoughts.
- Does the architecture include the possibility of preserving human-interpretable CoT? — I’m very interested in this question but don’t have a good guess yet. Given that the COCONUT training procedure is applied on a pre-trained transformer, the structure of the hidden layers used for continuous thoughts cannot diverge from the structure of normal transformer layers that much. The model is trained to retain the ability to switch between natural language and continuous thoughts, meaning that the same layers must be able to handle both. It thus seems plausible that one could just activate the prediction heads for the continuous thought steps as well, just without feeding the generated tokens back into the model as usual, and find that they still give at least some indication of what the model is thinking about. Logit lens may also remain informative. This is pure speculation for now, though, and it’s clear that some interpretability would be lost, given that even in the limited setting studied in the paper, there was already a clear indication of a breadth-first search behavior not usually found in LLMs.
Diffusion LLMs
Just a few weeks ago, Inception Labs released Mercury—a family of diffusion LLMs (dLLMs). Their main selling point is that diffusion is a lot faster than autoregression: Mercury models can output over 1000 tokens/sec when running on H100s. Inception didn’t release an accompanying paper and don’t present that many benchmark results, but based on the available information, the performance appears to be competitive with models like GPT 4o-mini and Claude 3.5 Haiku. It’s too early to tell whether diffusion is ever going to be a serious candidate to replace autoregression in LLMs, and I’m personally skeptical it is. Nevertheless, I’ll give a quick assessment of the implications of dLLMs for CoT oversight.
The short demo video on Inception’s website provides useful intuition on how dLLMs function. Instead of generating tokens one at a time, a dLLM produces the full answer at once. The initial answer is iteratively refined through a diffusion process, where a transformer suggests improvements for the entire answer at once at every step. In contrast to autoregressive transformers, the later tokens don’t causally depend on the earlier ones (leaving aside the requirement that the text should look coherent). For an intuition of why this matters, suppose that a transformer model has 50 layers and generates a 500-token reasoning trace, the final token of this trace being the answer to the question. Since information can only move vertically and diagonally inside this transformer and there are fewer layers than tokens, any computations made before the 450th token must be summarized in text to be able to influence the final answer at the last token. Unless the model can perform effective steganography, it had better output tokens that are genuinely relevant for producing the final answer if it wants the performed reasoning to improve the answer quality. For a dLLM generating the same 500-token output, the earlier tokens have no such causal role, since the final answer isn’t autoregressively conditioned on the earlier tokens. Thus, I’d expect it to be easier for a dLLM to fill those tokens with post-hoc rationalizations.
Despite this, I don’t expect dLLMs to be a similarly negative development as Huginn or COCONUT would be. The reason is that in dLLMs, there’s another kind of causal dependence that could prove to be useful for interpreting those models: the later refinements of the output causally depend on the earlier ones. Since dLLMs produce human-readable text at every diffusion iteration, the chains of uninterpretable serial reasoning aren’t that deep. I’m worried about the text looking like gibberish at early iterations and the reasons behind the iterative changes the diffusion module makes to this text being hard to explain, but the intermediate outputs nevertheless have the form of human-readable text, which is more interpretable than long series of complex matrix multiplications.
Though a couple of papers have been released on dLLMs, it’s unclear whether the mechanisms described in them correspond to the architecture of the Mercury models. PLANNER: Generating Diversified Paragraph via Latent Language Diffusion Model by Zhang et al. proposes a diffusion-based architecture and is valuable in that it demonstrates a way to combine diffusion and autoregressive generation. However, this paper was released already in November 2023 and the model they train is nowhere near the level of current LLMs, even the small ones. Large Concept Models: Language Modeling in a Sentence Representation Space by Meta explores the use of diffusion in the embedding space of a novel architecture that they claim to be able to reason in an abstract language- and modality-agnostic level, but diffusion doesn’t have a central role in the models trained in this paper. Due to this lack of information about SOTA dLLMs, I’m not going to speculate on the answers to my four questions here.
Some proposals I’m currently not worried about
The Byte Latent Transformer. The Byte Latent Transformer is an architecture recently proposed by Meta that replaces tokenization with an adaptive grouping of the input bytes into patches of equal entropy. While the name of the model—latent transformer—sounds scary, the Byte Latent Transformer is just a normal language model with a different approach to tokenization. There’s no recurrence, the text bottlenecks are still there, and the module that does the thinking (which is called the Latent Transformer in the paper) receives the dynamically created tokens rather than raw bytes as input and thus, presumably, doesn’t do alien byte-level thinking. The modules that encode from and decode into the byte stream are separate from the Latent Transformer module and not too different from usual tokenizers. I suppose that the output of the Latent Transformer module is slightly less interpretable than the output of a traditional transformer, as it is decoded with an entire transformer instead of directly corresponding to token probabilities, but on the other hand, the Byte Latent Transformer may also have some positive implications for mechinterp, as Daniel Tan suggests here [LW(p) · GW(p)], so I’m unconvinced for the time being that this would be a negative development.
Mamba and similar state-space models. I’ve mentioned the parallelism trade-off a few times throughout this post. A few months ago, I was surprised to find that most state-space models choose the ‘parallelizable training’ side of the trade-off, and that the effective hidden serial reasoning depth of architectures like Mamba and RWKV therefore isn’t substantially higher than that of transformers. This is because their state transitions are linear. This is a good place to explain the trade-off more formally. The trade-off occurs between using an expressive state transition function and being able to parallelize computations across time. Composing linear functions allows for parallelization: if f(x) = ax and g(x) = bx, then f(g(x)) = a(bx) = (ab)x. We can pre-compute ab and apply the combined function directly. With nonlinear functions, there are no such shortcuts: if f(x) = sin(x) and g(x) = x², there’s no way to compute f(g(x)) without first computing g(x). A traditional RNN has hidden states that depend on previous hidden states, meaning that its state transitions are highly nonlinear. This dependence obviously requires processing all inputs step-by-step during training. Mamba, in contrast, has linear state transitions that allow for the use of associative scan algorithms for efficient training, but imply that the architecture can’t involve long chains of hidden computations.[3]
Fine-tuning models to internalize CoT without any architecture changes. Approaches in this category train LLMs to perform some reasoning tasks that they were previously unable to perform without CoT in a single forward pass. Some relevant papers include From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step by Deng et al. and Implicit Chain of Thought Reasoning via Knowledge Distillation by Deng et al. While this may somewhat increase the amount of non-transparent reasoning models perform, such fine-tuning doesn’t change the upper capacity of a single forward pass and increase the maximum number of hidden serial operations, but rather teaches models to utilize the existing capacity better. I couldn’t find strong evidence in these papers that the performed fine-tuning generalizes in such a way that models also start outputting shorter reasoning traces for problems on which they weren’t fine-tuned, and I don’t expect labs to deliberately train their models to internalize harmful/dangerous reasoning. Nevertheless, the former paper mentioned here was repeatedly cited as an inspiration in the COCONUT paper, so such papers should still be viewed as a step away from the current golden age of legible CoT.
Conclusion
It is early to freak out about the models described in this post. Even the less safety-conscious labs appear to care a lot about CoT oversight, so I’d expect that any latent reasoning model would have to offer clear performance advantages over current frontier models for labs to deploy them. The early benchmark results are far from that. Nevertheless, both Huginn and COCONUT offer solutions to the training efficiency problems arising from the parallelism trade-off that, in theory, appear more scalable than earlier proposals. By demonstrating geometric rotation of shapes and breadth-first search taking place in latent space, both papers also provide some evidence that more expressive forward passes may unlock capabilities that current transformers fundamentally lack. Furthermore, Huginn exhibits impressive zero-shot generalization to being able to use adaptive compute and continuous thoughts. It is thus worth monitoring the developments in this space and to take some steps in preparation of the possibility that the current paradigm of legible CoT is supplanted.
- ^
You may reasonably ask, how does the self-attention mechanism work if each token can use an adaptive amount of recurrent layers? If we’re deep into the recurrent chain at some token, the self-attention module at that deep layer presumably wouldn’t have anything to attend to, since all the neighboring tokens use fewer layers. The authors’ solution to this issue is to attend to the deepest available KV states for each token. Since the recurrent layers aren’t all unique but rather consist of a single iterated block, the states at different iterations are apparently similar enough to make this work.
- ^
Also, note that traditional transformers aren’t incapable of parallel reasoning within a forward pass either—see e.g. Distributional reasoning in LLMs: Parallel reasoning processes in multi-hop reasoning by Shalev et al. and On the Biology of a Large Language Model by Lindsey et al.
- ^
For an in-depth discussion of this, see The Illusion of State in State-Space Models by Merrill et al.
6 comments
Comments sorted by top scores.
comment by nostalgebraist · 2025-04-04T01:17:49.178Z · LW(p) · GW(p)
Great review!
Here are two additional questions I think it's important to ask about this kind of work. (These overlap to some extent with the 4 questions you posed, but I find the way I frame things below to be clarifying.)
- If you combine the latent reasoning method with ordinary CoT, do the two behave more like substitutes or complements?
- That is: if we switch from vanilla transformers to one of these architectures, will we want to do less CoT (because the latent reasoning accomplishes the same goal in some more efficient or effective way), or more CoT (because the latent reasoning magnifies the gains that result from CoT, relative to vanilla transformers)?
- (Relatedly: how does this affect the legibility and faithfulness of CoT? If these two methods are synergetic/complementary, how does the division of labor work, i.e. which "kinds of thought" would an optimal model perform in the latent recurrence, vs. the verbalized recurrence?)
- How does the new architecture compare to vanilla transformers in a compute-matched comparison (where "compute" might mean either training or inference)? And how does this result change as compute is scaled?
Number 1 matters because what we really care about is "how much can we learn by reading the CoT?", and the concern about latent reasoning often involves some notion that important info which might otherwise appear in the CoT will get "moved into" the illegible latent recurrence. This makes sense if you hold capabilities constant, and compare two ~equivalent models with and without latent reasoning, where the former spends some test-time compute on illegible reasoning while the latter has to spend all its test-time compute on CoT.
However, capabilities will not in fact be constant! If you train a new model with latent reasoning, there's nothing forcing you to do less CoT with it, even if you could "get away with" doing that and still match the capabilities of your old model. You are free to combine latent reasoning and CoT and see how well they stack, and perhaps they do in fact stack nicely. What ultimately matters is what ends up expressed in the CoT of the best model you can train using the amount of CoT that's optimal for it – not whether some other, less capable model+CoT combination would have reached its distinct, worse-on-average conclusions in a more legible manner. (Note that you can always decrease legibility by just not using CoT, even with regular transformers – but of course there's no reason to care that this option isn't legible since it's not on the capabilities frontier.)
This situation is somewhat analogous to what we already have with regular transformer scaling and CoT: presumably there are sequential reasoning problems which GPT-4 can do in one forward pass (just by doing some "step by step" thing across its many layers), but which GPT-3.5 could only do via CoT. However, this didn't cause us to use less CoT as a result of the scale-up: why satisfy yourself with merely hitting GPT-3.5 quality in fewer (but more expensive) forward passes, when you can go ahead and tackle a whole new class of harder problems, the ones that even GPT-4 needs CoT for?[1]
Number 2 matters for hopefully obvious reasons: if we could just "go full RNN" with no downsides then of course that would be more expressive, but the fact that transformers don't do so (and reap the vast compute-efficiency benefits of not doing so) accounts for much/most (all?) of their vast success. The question is not "are there benefits to latent recurrence?" (of course there are) but "when, if ever, do you want to spend the marginal unit of compute on latent recurrence?" If you can afford to pay for a Coconut-ized version of your transformer then you could just make a bigger transformer instead, etc.
Unfortunately, looking at these papers, I don't see much evidence either way about these questions at a glance. Or at least nothing re: number 2. If I'm reading Table 2 in depth-recurrence paper correctly, their model gets much bigger gains from CoT on GSM8K than any of their baseline models (and the gains improve further with more latent reasoning!) – which seems encouraging re: number 1, but I'm wary of reading too much into it.
- ^
The analogy is inexact because GPT-4 still has only however many layers it has – a fixed constant – while depth-recurrent models can "just keep going." My point is simply that even if you can "just keep going," that doesn't imply that the best way to spend the marginal unit of test-time compute is always on more depth rather than more sampled tokens.
Do we have any reason to think "more tokens" will actually have any advantages over "more depth" in practice? I'm not sure, but one way to think about the tradeoff is: latent reasoning replaces a narrow bottleneck that can be arbitrarily expanded with a much larger bottleneck that can't scale with problem size. That is, depth-recurrence and similar approaches have the familiar old problem of RNNs, where they have to write all the intermediate results of their reasoning onto a fixed-length scratchpad, and hence will eventually have trouble with tasks of the form "compute intermediate results and then do some aggregation over the whole collection" where is problem-dependent and can grow arbitrarily large.Relatedly, KV caches in transformers are huge, which of course has painful memory costs but does allow the transformer to store a ton of information about the tokens it generates, and to look up that information later with a great deal of precision.
So comparing the capacity of the hidden state (as the bottleneck for depth-recurrence) against the capacity of just the CoT tokens (as the bottleneck for transformer+CoT) isn't really comparing apples to apples: while the transformer is much more limited in what information it can "directly pass along" from step to step (with that info immediately+fully available to all future operations), it always constructs very high-dimensional representations of each step which are visible at least to some operations inside subsequent steps, allowing the transformer to "write out a haystack and then find the needle in it" even if that needle is tough to discriminate from its many neighbors. (This argument is hand-wavey and so I'm not super confident of it, would be interesting to find out if it can be made more precise, or already has been)
↑ comment by Rauno Arike (rauno-arike) · 2025-04-04T12:20:19.228Z · LW(p) · GW(p)
Thanks, this is a helpful framing! Some responses to your thoughts:
Number 1 matters because what we really care about is "how much can we learn by reading the CoT?", and the concern about latent reasoning often involves some notion that important info which might otherwise appear in the CoT will get "moved into" the illegible latent recurrence. This makes sense if you hold capabilities constant, and compare two ~equivalent models with and without latent reasoning, where the former spends some test-time compute on illegible reasoning while the latter has to spend all its test-time compute on CoT. However, capabilities will not in fact be constant!
I agree that an analysis where the capabilities are held constant doesn't make sense when comparing just two models with very different architectures (and I'm guilty of using this frame in this way to answer my first question). However, I expect the constant-capabilities frame to be useful for comparing a larger pool of models with roughly similar core capabilities but different maximum serial reasoning depths.[1] In this case, it seems very important to ask: given that labs don't want to significantly sacrifice on capabilities, what architecture has the weakest forward passes while still having acceptable capabilities? Even if it's the case that latent reasoning and CoT usually behave like complements and the model with the most expressive forward passes uses a similar amount of CoT to the model with the least expressive forward passes on average, it seems to me that from a safety perspective, we should prefer the model with the least expressive forward passes (assuming that things like faithfulness are equal), since that model is less of a threat to form deceptive plans in an illegible way.
If I'm reading Table 2 in depth-recurrence paper correctly, their model gets much bigger gains from CoT on GSM8K than any of their baseline models (and the gains improve further with more latent reasoning!) – which seems encouraging re: number 1, but I'm wary of reading too much into it.
Yeah, this is a good observation. The baseline results for GSM8K that they present look weird, though. While I can see the small Pythia models being too dumb to get any benefit from CoT, it's puzzling why the larger OLMo models don't benefit from the use of CoT at all. I checked the OLMo papers and they don't seem to mention GSM8K results without CoT, so I couldn't verify the results that way. However, as a relevant data point, the average accuracy of the GPT-2 model used as the baseline in the COCONUT paper jumps from 16.5% without CoT to 42.9% with CoT (Table 1 in the COCONUT paper). Compared to this jump, the gains in the depth-recurrence paper aren't that impressive. For COCONUT, the accuracy is 21.6% without CoT and 34.1% with CoT.
- ^
One might argue that I'm not really holding capabilities constant here, since the models with more expressive forward passes can always do whatever the weaker models can do with CoT and also have the benefits of a more expressive forward pass, but it seems plausible to me that there would be a set of models to choose from that have roughly the same effective capabilities, i.e. capabilities we care about. The models with larger maximum serial reasoning depths may have some unique advantages, such as an advanced ability to explore different solutions to a problem in parallel inside a single forward pass, but I can still see the core capabilities being the same.
comment by cubefox · 2025-03-31T15:22:09.264Z · LW(p) · GW(p)
There is also Deliberation in Latent Space via Differentiable Cache Augmentation by Liu et al. and Efficient Reasoning with Hidden Thinking by Shen et al.
comment by Knight Lee (Max Lee) · 2025-04-01T00:20:30.230Z · LW(p) · GW(p)
Beautiful post, I learned a lot from it.
An Unnecessary Trade-off
It looks like these COCONUT-like AI are trying to improve efficiency by avoiding a bottleneck. It's the bottleneck where all information inside a forward pass (e.g. the residual stream) has to be deleted, outputting only a single token.
So in a sense, the AI has to repeatedly recalculate its entire understanding of the context for every single token it generates.
EDIT: See the reply below by Mis-Understandings. The AI doesn't need to recalculate its entire understanding for every token due to KV caching, so I was wrong. However, I still think there is an information bottleneck, because the context window can only gain one token of information per forward pass even though a forward pass computes zillions of bits of information.
These hidden chain of thought architectures seem to derive their efficiency from avoiding this bottleneck.
Yet surely, surely, there must be other approaches to avoid this bottleneck without completely sacrificing interpretability to death?
An example solution
Of the top of my head:
- Inside the AI's chain of thought, each forward pass can generate many English tokens instead of one, allowing more information to pass through the bottleneck.
- After the chain of thought ended, and the AI is giving its final answer, it generates only one English tokens at a time, to make each token higher quality. The architecture might still generate many tokens in one forward pass, but a simple filter repeatedly deletes everything except its first token from the context window.
- This slower thinking might occur not just for the final answer, but when the AI is cleaning up its chain of thought with concise summaries (e.g. ClaudePlaysPokemon has long chains of thought when simply entering and leaving a room, filling up its context window with useless information. They gave it a separate memory file where it can write and delete more important information).
Admittedly, even this method would reduce interpretability by making the chain of thought longer. This trade-off is more inevitable. But the trade-off where the AI has to learn some non-English alien language seems unnecessary.
Replies from: robert-k↑ comment by Mis-Understandings (robert-k) · 2025-04-01T00:45:13.147Z · LW(p) · GW(p)
forward pass (e.g. the residual stream) has to be deleted, outputting only a single token.
Does not actually happen.
What it is that the new token is now at the root of the attention structure, and can pass information from the final layers to the first layers inferencing the next token.
The residuals are translation independent, and are cached for further inference in autoregressive mode.
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2025-04-01T00:51:33.948Z · LW(p) · GW(p)
Thank you. Just earlier I was asking an AI whether my comment was reasonable and it told me something similar.