Posts
Comments
This is valuable work! I'm curious about what you see as the most promising environments for the extension of training against LLM monitors in different settings. As you note, this should be done in more realistic reward hacking settings, but you also mention that the models' ability to reward hack in the setting from Baker et al. doesn't depend on how they use their CoT. Are you aware of any existing environments which satisfy both of these desiderata, being realistic and also sufficiently complex that LLMs must rely on their CoT in them? Aside from the Baker et al. environment, what are the environments that you'd be most excited to see follow-ups to your work use?
Seems relevant to note here that Tamay had a leadership role from the very beginning: he was the associate director already when Epoch was first announced as an org.
Fascinating! I'm now wondering whether it's possible to test the Coconut hypothesis. An obvious first idea is to switch between 4.1 and 4o in the chat interface and see if the phenomenon we've been investigating occurs for both of them, but at least I can't switch between the models with my non-subscriber account—is this possible with a subscriber account?
Edit: I'm actually unsure about whether 4.1 has image generation functionality at all. The announcement only mentions image understanding, not generation, and image generation is available for neither 4o nor 4.1 through the API. They say that "Developers will soon be able to generate images with GPT‑4o via the API, with access rolling out in the next few weeks" in the 4o image generation announcement, so if it becomes available for 4o but not for 4.1, that would be evidence that image generation requests are currently always handled with 4o. This would make the Coconut hypothesis less likely in my eyes—it seems easier to introduce such a drastic architecture change for a new model (although Coconut is a fine-tuning technique, so it isn't impossible that they applied this kind of fine-tuning on 4o).
The links were also the same for me. I instead tried a modified version of the nine random animals task myself, asking for a distinctive object at the background of each subimage. It was again highly accurate in general and able to describe the background objects in great detail (e.g., correctly describing the time that the clock on the top middle image shows), but it also got the details wrong on a couple of images (the bottom middle and bottom right ones).
Thanks! I also believe there's no separate image model now. I assumed that the message you pasted was a hardcoded way of preventing the text model from continuing the conversation after receiving the image from the image model, but you're right that the message before this one is more likely to be a call to the content checker, and in that case, there's no place where the image data is passed to the text model.
There's one more X thread which made me assume a while ago that there's a call to a separate image model. I don't have time to investigate this myself at the moment, but am curious how this thread fits into the picture in case there's no separate model.
Great post! Some questions:
- It seems like many problems we’ll train models to solve with RL won’t be solvable in a single forward pass. E.g., consider a math proof that takes 20 lines to write out, and perhaps also requires some intermediate reasoning to figure out the next line. Do you expect vestigial reasoning to appear for such problems as well?
- I’m not sure I understand why I should expect long CoTs to persist in the process-supervised but not in the outcome-supervised case. I agree that writing about deleting the tests is salient in the latter but not in the former case, but writing a vague phrase followed by deleting the tests is salient in the former case and leads to the same outcome. In the process-supervised case, the causal chain is attempt to solve the problem -> write a vague phrase -> delete the tests, and in the outcome-supervised case, it’s attempt to solve the problem -> write about deleting the tests -> delete the tests. Why do you expect that it’s easier for the model to stumble upon the strategy of skipping the first step in the latter chain?
Daniel's argument against a length penalty is from this doc:
We want our models to learn to blather and babble freely, rather than thinking carefully about how to choose their words. Because if instead they are routinely thinking carefully about how to choose their words, that cognition might end up executing strategies like “use word X instead of Y, since thatʼll avoid suspicion.ˮ So, letʼs try to avoid incentivizing brevity.
There's also a comment by Lukas Finnveden that argues in favor of a length penalty:
downside: more words gives more opportunity for steganography. You can have a much lower bit-rate-per-word and still accomplish the same tasks.
Thanks, this is a helpful framing! Some responses to your thoughts:
Number 1 matters because what we really care about is "how much can we learn by reading the CoT?", and the concern about latent reasoning often involves some notion that important info which might otherwise appear in the CoT will get "moved into" the illegible latent recurrence. This makes sense if you hold capabilities constant, and compare two ~equivalent models with and without latent reasoning, where the former spends some test-time compute on illegible reasoning while the latter has to spend all its test-time compute on CoT. However, capabilities will not in fact be constant!
I agree that an analysis where the capabilities are held constant doesn't make sense when comparing just two models with very different architectures (and I'm guilty of using this frame in this way to answer my first question). However, I expect the constant-capabilities frame to be useful for comparing a larger pool of models with roughly similar core capabilities but different maximum serial reasoning depths.[1] In this case, it seems very important to ask: given that labs don't want to significantly sacrifice on capabilities, what architecture has the weakest forward passes while still having acceptable capabilities? Even if it's the case that latent reasoning and CoT usually behave like complements and the model with the most expressive forward passes uses a similar amount of CoT to the model with the least expressive forward passes on average, it seems to me that from a safety perspective, we should prefer the model with the least expressive forward passes (assuming that things like faithfulness are equal), since that model is less of a threat to form deceptive plans in an illegible way.
If I'm reading Table 2 in depth-recurrence paper correctly, their model gets much bigger gains from CoT on GSM8K than any of their baseline models (and the gains improve further with more latent reasoning!) – which seems encouraging re: number 1, but I'm wary of reading too much into it.
Yeah, this is a good observation. The baseline results for GSM8K that they present look weird, though. While I can see the small Pythia models being too dumb to get any benefit from CoT, it's puzzling why the larger OLMo models don't benefit from the use of CoT at all. I checked the OLMo papers and they don't seem to mention GSM8K results without CoT, so I couldn't verify the results that way. However, as a relevant data point, the average accuracy of the GPT-2 model used as the baseline in the COCONUT paper jumps from 16.5% without CoT to 42.9% with CoT (Table 1 in the COCONUT paper). Compared to this jump, the gains in the depth-recurrence paper aren't that impressive. For COCONUT, the accuracy is 21.6% without CoT and 34.1% with CoT.
- ^
One might argue that I'm not really holding capabilities constant here, since the models with more expressive forward passes can always do whatever the weaker models can do with CoT and also have the benefits of a more expressive forward pass, but it seems plausible to me that there would be a set of models to choose from that have roughly the same effective capabilities, i.e. capabilities we care about. The models with larger maximum serial reasoning depths may have some unique advantages, such as an advanced ability to explore different solutions to a problem in parallel inside a single forward pass, but I can still see the core capabilities being the same.
I'll start things off with some recommendations of my own aside from Susskind's Statistical Mechanics:
Domain: Classical Mechanics
Link: Lecture Collection | Classical Mechanics (Fall 2011) by Stanford University
Lecturer: Leonard Susskind
Why? For the same reasons as described in the main part of the post for the Statistical Mechanics lectures — Susskind is great!
For whom? This was also an undergrad-level course, so mainly for people who are just getting started with learning physics.
Domain: Deep Learning for Beginners
Link: Deep Learning for Computer Vision by the University of Michigan
Lecturer: Justin Johnson
Why? This lecture series is a dinosaur in the field of deep learning, having been recorded in 2019. It's possible that better introductory lectures on deep learning have been recorded in the meantime (if so, please link them here!), but when I first got started learning about DL in 2022, this was by far the best lecture series I came across. Many options, such as the MIT 6.S191 lectures by Alexander Amini, involved too much high-level discussion without the technical details, while some others weren't broad enough. This course strikes a nice balance, giving a broad overview of the methods while still discussing specific techniques and papers in great depth.
For whom? Beginners in deep learning looking for a broad introductory course.
Domain: Graph Neural Networks
Link: Stanford CS224W: Machine Learning with Graphs | 2021
Lecturer: Jure Leskovec
Why? I did my bachelor's thesis on GNNs and needed a refresher on them for that. I remember looking through multiple lecture series and finding these lectures significantly better than the alternatives, though I don't exactly remember the alternatives I explored. Leskovec is very highly regarded as a researcher in the field of GNNs and also good as a lecturer.
For whom? Anyone who wants an in-depth overview of GNNs and isn't already specialized in the field.
As a counterpoint to the "go off into the woods" strategy, Richard Hamming said the following in "You and Your Research", describing his experience at Bell Labs:
Thus what you consider to be good working conditions may not be good for you! There are many illustrations of this point. For example, working with one’s door closed lets you get more work done per year than if you had an open door, but I have observed repeatedly that later those with the closed doors, while working just as hard as others, seem to work on slightly the wrong problems, while those who have let their door stay open get less work done but tend to work on the right problems! I cannot prove the cause-and-effect relationship; I can only observed the correlation. I suspect the open mind leads to the open door, and the open door tends to lead to the open mind; they reinforce each other.
Bell Labs certainly produced a lot of counterfactual research, Shannon's information theory being the prime example. I suppose Bell Labs might have been well-described as a group that could maintain its own attention, though.
There's an X thread showing that the ordering of answer options is, in several cases, a stronger determinant of the model's answer than its preferences. While this doesn't invalidate the paper's results—they control for this by varying the ordering of the answer results and aggregating the results—, this strikes me as evidence in favor of the "you are not measuring what you think you are measuring" argument, showing that the preferences are relatively weak at best and completely dominated by confounding heuristics at worst.
What's the minimum capacity in which you're expecting people to contribute? Are you looking for a few serious long-term contributors or are you also looking for volunteers who offer occasional help without a fixed weekly commitment?
A few other research guides:
- Tips for Empirical Alignment Research by Ethan Perez
- Advice for Authors by Jacob Steinhardt
- How to Write ML Papers by Sebastian Farquhar
The broader point is that even if AIs are completely aligned with human values, the very mechanisms by which we maintain control (such as scalable oversight and other interventions) may shift how the system operates in a way that produces fundamental, widespread effects across all learning machines
Would you argue that the field of alignment should be concerned with maintaining control beyond the point where AIs are completely aligned with human values? My personal view is that alignment research should ensure we're eventually able to align AIs with human values and that we can maintain control until we're reasonably sure that the AIs are aligned. However, worlds where relatively unintelligent humans remain in control indefinitely after those milestones have been reached may not be the best outcomes. I don't have time to write out my views on this in depth right now, but here's a relevant excerpt from the Dwarkesh podcast episode with Paul Christiano that I agree with:
Dwarkesh: "It's hard for me to imagine in 100 years that these things are still our slaves. And if they are, I think that's not the best world. So at some point, we're handing off the baton. Where would you be satisfied with an arrangement between the humans and AIs where you're happy to let the rest of the universe or the rest of time play out?"
Paul: "I think that it is unlikely that in 100 years I would be happy with anything that was like, you had some humans, you're just going to throw away the humans and start afresh with these machines you built. [...] And then I think that the default path to be comfortable with something very different is kind of like, run that story for a long time, have more time for humans to sit around and think a lot and conclude, here's what we actually want. Or a long time for us to talk to each other or to grow up with this new technology and live in that world for our whole lives and so on. [...] We should probably try and sort out our business, and you should probably not end up in a situation where you have a billion humans and like, a trillion slaves who would prefer revolt. That's just not a good world to have made."
I saw them in 10-20% of the reasoning chains. I mostly played around with situational awareness-flavored questions, I don't know whether the Chinese characters are more or less frequent in the longer reasoning chains produced for difficult reasoning problems. Here are some examples:

The translation of the Chinese words here (according to GPT) is "admitting to being an AI."

This is the longest string in Chinese that I got. The English translation is "It's like when you see a realistic AI robot that looks very much like a human, but you understand that it's just a machine controlled by a program."

The translation here is "mistakenly think."

Here, the translation is "functional scope."
So, seems like all of them are pretty direct translations of the English words that should be in place of the Chinese ones, which is good news. It's also reassuring to me that none of the reasoning chains contained sentences or paragraphs that looked out of place or completely unrelated to the rest of the response.
This is a nice overview, thanks!
Lee Sharkey's CLDR arguments
I don't think I've seen the CLDR acronym before, are the arguments publicly written up somewhere?
Also, just wanted to flag that the links on 'this picture' and 'motivation image' don't currently work.
My understanding of the position that scheming will be unlikely is the following:
- Current LLMs don't have scary internalized goals that they pursue independent of the context they're in.
- Such beyond-episode goals also won't be developed when we apply a lot more optimization pressure to the models, given that we keep using the training techniques we're using today, since the inductive biases will remain similar and current inductive biases don't seem to incentivize general goal-directed cognition. Naturally developing deception seems very non-trivial, especially given that models are unlikely to develop long-term goals in pre-training.
- Based on the evidence we have, we should expect that the current techniques + some kind of scaffolding will be a simpler path to AGI than e.g. extensive outcome-based RL training. We'll get nice instuction-following tool AIs. The models might still become agentic in this scenario, but since the agency comes from subroutine calls to the LLM rather than from the LLM itself, the classical arguments for scheming don't apply.
- Even if we get to AGI through some other path, the theoretical arguments in favor of deceptive alignment are flimsy, so we should have a low prior on other kinds of models exhibiting scheming.
I'm not sure about the other skeptics, but at least Alex Turner appears to believe that the kind of consequentialist cognition necessary for scheming is much more likely to arise if the models are aggressively trained on outcome-based rewards, so this seems to be the most important of the cruxes you listed. This crux is also one of the two points on which I disagree most strongly with the optimists:
- I expect models to be trained in outcome-based ways. This will incentivize consequentialist cognition and therefore increase the likelihood of scheming. This post makes a good case for this.
- Even if models aren't trained with outcome-based RL, I wouldn't be confident that it's impossible for coherent consequentialist cognition to arise otherwise, so assigning deceptive alignment a <1% probability would still seem far-fetched to me.
However, I can see reasons why well-informed people would hold views different from mine on both of those counts (and I've written a long post trying to explore those reasons), so the position isn't completely alien to me.
[Link] Something weird is happening with LLMs and chess by dynomight
dynomight stacked up 13 LLMs against Stockfish on the lowest difficulty setting and found a huge difference between the performance of GPT-3.5 Turbo Instruct and any other model:
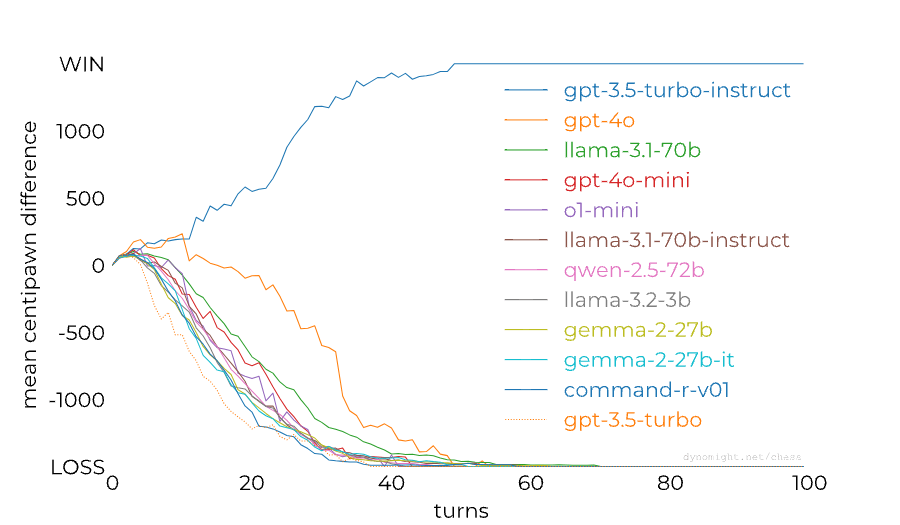
People noticed already last year that RLHF-tuned models are much worse at chess than base/instruct models, so this isn't a completely new result. The gap between models from the GPT family could also perhaps be (partially) closed through better prompting: Adam Karvonen has created a repo for evaluating LLMs' chess-playing abilities and found that many of GPT-4's losses against 3.5 Instruct were caused by GPT-4 proposing illegal moves. However, dynomight notes that there isn't nearly as big of a gap between base and chat models from other model families:
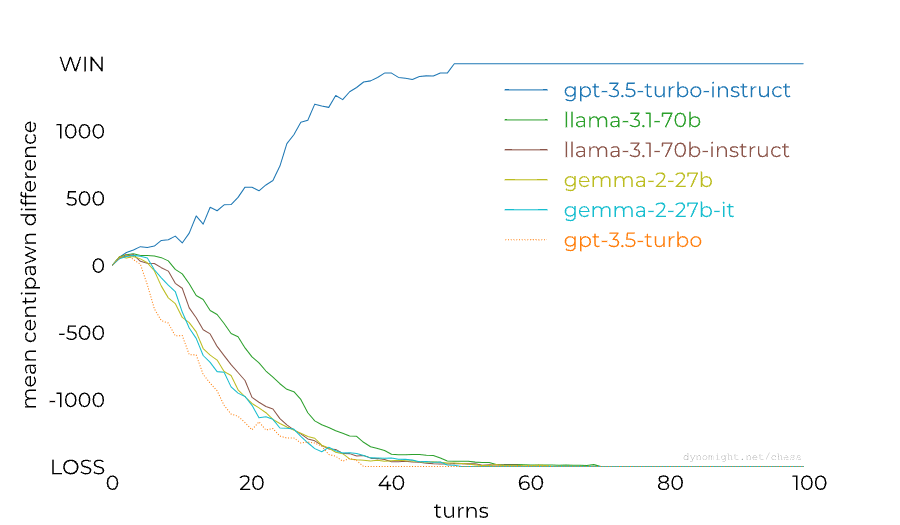
This is a surprising result to me—I had assumed that base models are now generally decent at chess after seeing the news about 3.5 Instruct playing at 1800 ELO level last year. dynomight proposes the following four explanations for the results:
1. Base models at sufficient scale can play chess, but instruction tuning destroys it.
2. GPT-3.5-instruct was trained on more chess games.
3. There’s something particular about different transformer architectures.
4. There’s “competition” between different types of data.
Thank you for the detailed feedback, I found this very helpful and not at all rude or mean!
I suspect there are a few key disagreements between us that make me more optimistic about this project setup than you. I'd be curious about whether you agree on these points being important cruxes:
- Though I agree that our work primarily belongs within the model organisms paradigm, I disagree that it's only useful as a means to study in-forward-pass goal-directedness. I think there's a considerable chance that the Translucent Thoughts hypotheses are true and AGI will be reached with an architecture very similar to current transformers, which I wouldn't expect to be able to do dangerous goal-directed reasoning within a single forward pass due to the limited number of serial reasoning steps. If this is the case, CoT-based goal-directedness seems relevant to study for its own sake. We're still studying an artificial scenario in the sense that we're giving the models the goal ourselves, while in the deceptive alignment scenarios, the model would have to develop the goal on its own, but I don't think we necessarily have to say anything about in-forward-pass goal-directedness for our work to be applicable to realistic threat models.
- Studying the intrinsic goals of the models in naturalistic settings would also be interesting, but I expect this to be hard, and also less relevant to the threat models we're worried about. I'm mainly concerned about models becoming more goal-directed with scale and someone figuring out long-horizon RL training on top of that, leading to models that are qualitatively different from current ones. To address this, I'd like to have a benchmark that decomposes goal-directedness into several relevant abilities and provides an accurate score for these abilities across model generations. This would help us better track how models become more goal-directed as they scale, if at all. Additionally, if a new model scores close to humans on many of these abilities, it could serve as a strong alarm bell that we are approaching dangerously goal-directed models. It seems easier to build this sort of benchmark without going through the complicated process of trying to infer the intrinsic goals of the models.
- The aforementioned decomposition of goal-directedness into various relevant abilities would also be the main value added on top of existing agent benchmarks. We should maybe have been clearer in the post about planning to develop such a decomposition. Since it's easy to evaluate for goal-fulfillment, that was our main focus in the early stages of the project, but eventually, we're hoping to decompose goal-directedness into several abilities such as instrumental reasoning ability, generalization to OOD environments, coherence, etc, somewhat analogously to how the Situational Awareness Dataset decomposes situational awareness into self-knowledge, inferences, and actions.
I definitely agree that it would be interesting to compare the goal-directedness of base models and fine-tuned models, and this is something we're planning to eventually do if our compute budget permits. Similarly, I strongly agree that it would be interesting to study whether anything interesting is going on in the situations where the models exhibit goal-directed behavior, and I'm very interested in looking further into your suggestions for that!
Thanks, that definitely seems like a great way to gather these ideas together!
I guess the main reason my arguments are not addressing the argument at the top is that I interpreted Aaronson's and Garfinkel's arguments as "It's highly uncertain whether any of the technical work we can do today will be useful" rather than as "There is no technical work that we can do right now to increase the probability that AGI goes well." I think that it's possible to respond to the former with "Even if it is so and this work really does have a high chance of being useless, there are many good reasons to nevertheless do it," while assuming the latter inevitably leads to the conclusion that one should do something else instead of this knowably-useless work.
My aim with this post was to take an agnostic standpoint towards whether that former argument is true and to argue that even if it is, there are still good reasons to work on AI safety. I chose this framing because I believe that for people new to the field who don't yet know enough about the field to make good guesses about how likely it is that AGI will be similar to ML systems of today or to human brains, it's useful to think about whether it's worth working on AI safety even if the chance that we'll build prosaic or brain-like AGI turns out to be low.
That being said, I could have definitely done a better job writing the post - for example by laying out the claim I'm arguing against more clearly at the start and by connecting argument 4 more directly to the argument that there's a significant chance we'll build a prosaic or brain-like AGI. It might also be that the quotes by Aaronson and Garfinkel convey the argument you thought I'm arguing against rather than what I interpreted them to convey. Thank you for the feedback and for helping me realize the post might have these problems!