Rauno's Shortform
post by Rauno Arike (rauno-arike) · 2024-11-15T12:08:02.409Z · LW · GW · 6 commentsContents
6 comments
6 comments
Comments sorted by top scores.
comment by Rauno Arike (rauno-arike) · 2024-11-15T12:08:02.890Z · LW(p) · GW(p)
[Link] Something weird is happening with LLMs and chess by dynomight [LW · GW]
dynomight stacked up 13 LLMs against Stockfish on the lowest difficulty setting and found a huge difference between the performance of GPT-3.5 Turbo Instruct and any other model:
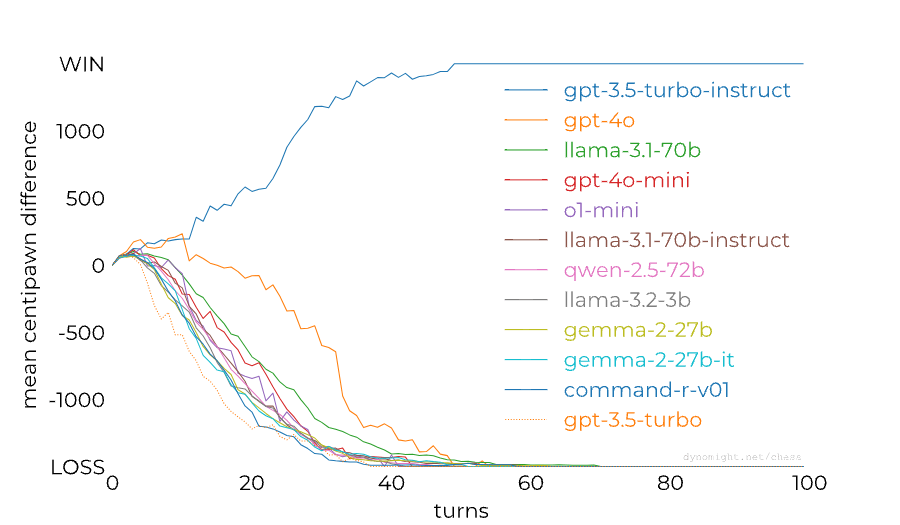
People noticed already last year that RLHF-tuned models are much worse at chess than base/instruct models, so this isn't a completely new result. The gap between models from the GPT family could also perhaps be (partially) closed through better prompting: Adam Karvonen has created a repo for evaluating LLMs' chess-playing abilities and found that many of GPT-4's losses against 3.5 Instruct were caused by GPT-4 proposing illegal moves. However, dynomight notes that there isn't nearly as big of a gap between base and chat models from other model families:
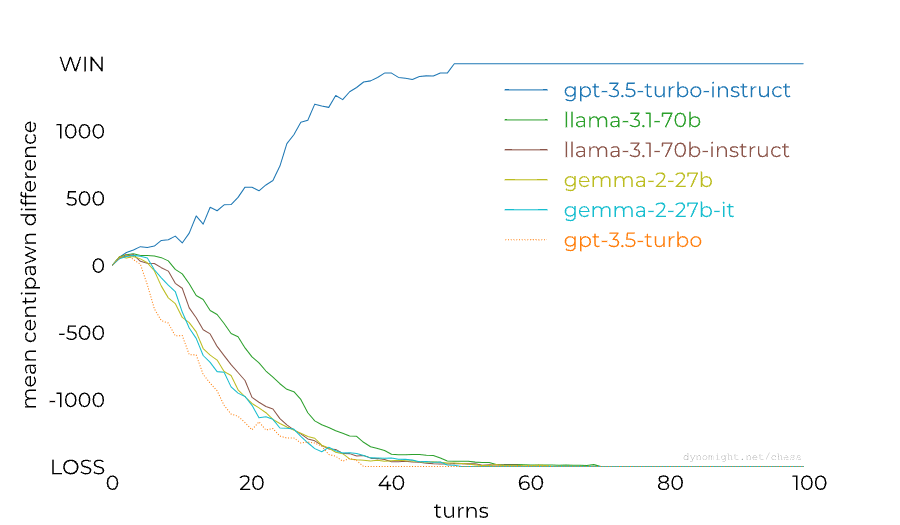
This is a surprising result to me—I had assumed that base models are now generally decent at chess after seeing the news about 3.5 Instruct playing at 1800 ELO level last year. dynomight proposes the following four explanations for the results:
Replies from: ryan_greenblatt, lorenzo-buonanno, AliceZ1. Base models at sufficient scale can play chess, but instruction tuning destroys it.
2. GPT-3.5-instruct was trained on more chess games.
3. There’s something particular about different transformer architectures.
4. There’s “competition” between different types of data.
↑ comment by ryan_greenblatt · 2024-11-15T18:54:52.017Z · LW(p) · GW(p)
OpenAI models are seemingly trained on huge amounts of chess data [LW(p) · GW(p)], perhaps 1-4% of documents are chess (though chess documents are short, so the fraction of tokens which are chess is smaller than this).
↑ comment by Lorenzo (lorenzo-buonanno) · 2024-11-21T18:13:48.043Z · LW(p) · GW(p)
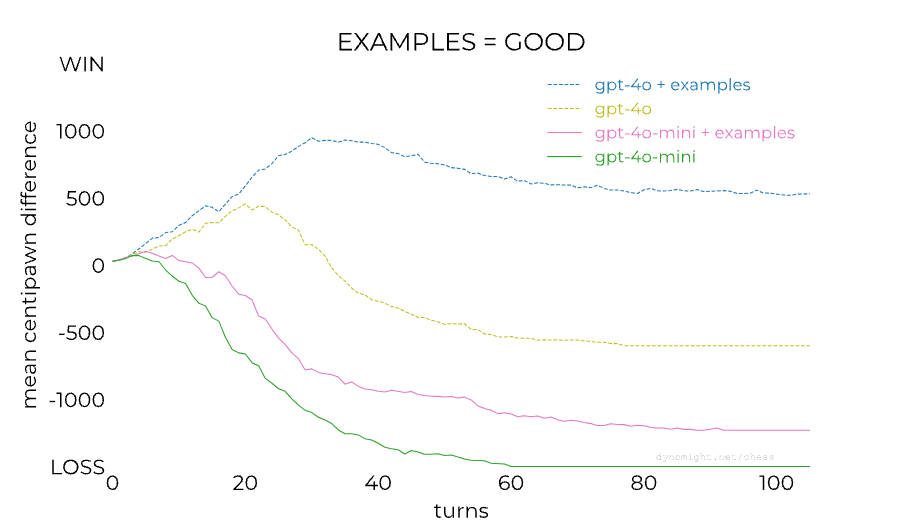
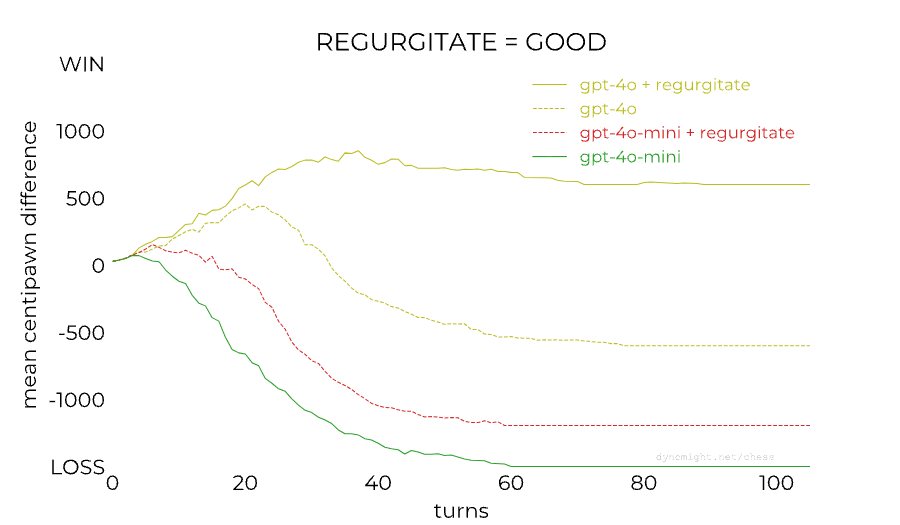
Here's a followup https://dynomight.net/more-chess/ apparently it depends a lot on the prompting
↑ comment by ZY (AliceZ) · 2024-11-16T16:51:19.559Z · LW(p) · GW(p)
This is very interesting, and thanks for sharing.
- One thing that jumps out at me is they used an instruction format to prompt base models, which isn't typically the way to evaluate base models. It should be reformatted to a completion type of task. If this is redone, I wonder if the performance of the base model will also increase, and maybe that could isolate the effect further to just RLHF.
- I wonder if this has anything to do with also the number of datasets added on by RLHF (assuming a model go through supervised/instruction finetuning first, and then RLHF), besides the algorithm themselves.
- Another good model to test on is https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3 which only has instruction finetuning it seems as well.
The author seems to say that they figured it out at the end of the article, and I am excited to see their exploration in the next post.
Replies from: p.b.↑ comment by p.b. · 2024-11-18T16:29:21.722Z · LW(p) · GW(p)
There was one comment on twitter that the RLHF-finetuned models also still have the ability to play chess pretty well, just their input/output-formatting made it impossible for them to access this ability (or something along these lines). But apparently it can be recovered with a little finetuning.
Replies from: AliceZ↑ comment by ZY (AliceZ) · 2024-11-18T19:42:38.023Z · LW(p) · GW(p)
Yeah that makes sense; the knowledge should still be there, just need to re-shift the distribution "back"