Clarifying the confusion around inner alignment
post by Rauno Arike (rauno-arike) · 2022-05-13T23:05:26.854Z · LW · GW · 0 commentsContents
Decomposing the alignment problem A Brief History of Inner Alignment Some Concrete Examples Example 1: The mesa-optimizer acquires the base objective Example 2: Impact-aligned mesa-optimizer Example 3: Fully optimized non-impact aligned mesa-optimizer Example 4: Imperfectly optimized mesa-objective Example 5: Other generalization failures Why does this all matter? Arguments for and against different definitions None No comments
Note 1: This article was written for the EA UC Berkeley Distillation Contest, and is also my capstone project for the AGISF course.
Note 2: All claims here about what different researchers believe and which definitions they endorse are my interpretations. All interpretation errors, though carefully avoided, are my own.
Over the recent years, there have been several LessWrong posts arguing over the most useful way to define inner and outer alignment. The terms were, as far as I know, initially defined in the “Risks from Learned Optimization” paper [? · GW] by Hubinger et al. Naturally, the terms have since been taken into contexts not anticipated at the time of writing the paper, which has prompted several [LW · GW] arguments [LW · GW] as well as redefinitions [LW · GW].
In this post, I will attempt to summarize and clarify the main points of confusion behind those arguments. To keep the post concise, I will focus on the definition of inner alignment, as this seems to be the term generating the most confusion. When talking about outer alignment, I will adopt the definition from Evan Hubinger’s post clarifying inner alignment terminology [LW · GW], as that’s the definition I feel like is currently used the most: “An objective function r is outer aligned if all models that perform optimally on r in the limit of perfect training and infinite data are intent aligned.” So, I take outer alignment to roughly mean that humans succeed in choosing a training objective that is perfectly aligned with our own values for the AI system. Note, though, that there have been arguments [LW · GW] over this definition as well.
Decomposing the alignment problem
First, it seems useful to go over the distinct steps that we will have to succeed on in order to align an AI system. To me, the following decomposition seems sensible:
- We may or may not specify the correct training objective.
- The training process may or may not generate a separate optimizer for fulfilling that objective, and that optimizer may or may not be aligned with the base objective.
- The result of the training process may or may not generalize to the test environment, whether or not a mesa-optimizer was created. This robustness problem is 2-dimensional [LW · GW]: a generalization failure may arise either from the system’s objective failing to generalize from the training distribution to the deployment distribution, or from its capabilities failing to generalize.
Classifying the problems that we face in each of those steps under the terms of inner and outer alignment is where most of the confusion seems to stem from. I will now give an overview of different classifications that have been made.
A Brief History of Inner Alignment
In “Risks from Learned Optimization“, the paper that first defined inner alignment, the following definition was given:
“We refer to this problem of aligning mesa-optimizers with the base objective as the inner alignment problem. This is distinct from the outer alignment problem, which is the traditional problem of ensuring that the base objective captures the intended goal of the programmers.”
This definition regards inner alignment as a problem strictly related to the emergence of a mesa-optimizer. Furthermore, inner and outer alignment are not regarded as complementary terms by this definition: instead, inner alignment is a subproblem of objective robustness, which in turn forms a part of step 3.
As Hubinger has commented [LW · GW], this dependence on the presence of a mesa-optimizer is one of the main features of the initial definition that has generated confusion: people have taken the term outside that narrow context where a definition centered around a mesa-optimizer doesn’t work anymore.
There are two ways this confusion has been resolved. Shortly after the aforementioned comment, Hubinger wrote a post [LW · GW] refining the definitions from “Risks from Learned Optimization” in a way that keeps inner alignment associated with mesa-optimizers:
“A mesa-optimizer is inner aligned if the optimal policy for its mesa-objective is impact aligned with the base objective it was trained under.”
Similar definitions have been put forward by Richard Ngo [LW · GW], Paul Christiano and Vladimir Mikulik [LW · GW]. In order to have terminology to talk about generalization failures that don’t involve a misaligned mesa-objective, Hubinger’s post also defines objective and capability robustness, the two dimensions of 2D robustness [LW · GW].
In contrast, Rohin Shah has endorsed a definition under which inner alignment encompasses both objective and capability robustness, putting steps 2 and 3 of my decomposition together into one term. Under this view, outer alignment is mainly about choosing the correct objective for the training process and inner alignment about making sure that the product of that training stage generalizes well to deployment. Here is an outline of his view from his appearance on the Future of Life podcast:[1]
“Inner alignment is the claim that when the circumstances change, the agent generalizes catastrophically in some way, it behaves as though it’s optimizing some other objective than the one that we actually want. So it’s much more of a claim about the behavior rather than the internal workings of the AI systems that cause that behavior. Mesa-optimization /…/ is talking specifically about AI systems that are executing an explicit optimization algorithm. /.../ So it’s making a claim about how the AI system’s cognition is structured, whereas inner alignment more broadly is just that the AI behaves in this catastrophically generalizing way.”
Broadly speaking, this is the main line of disagreement. It has already been discussed by others [LW · GW] and is summarized well by the following two diagrams:
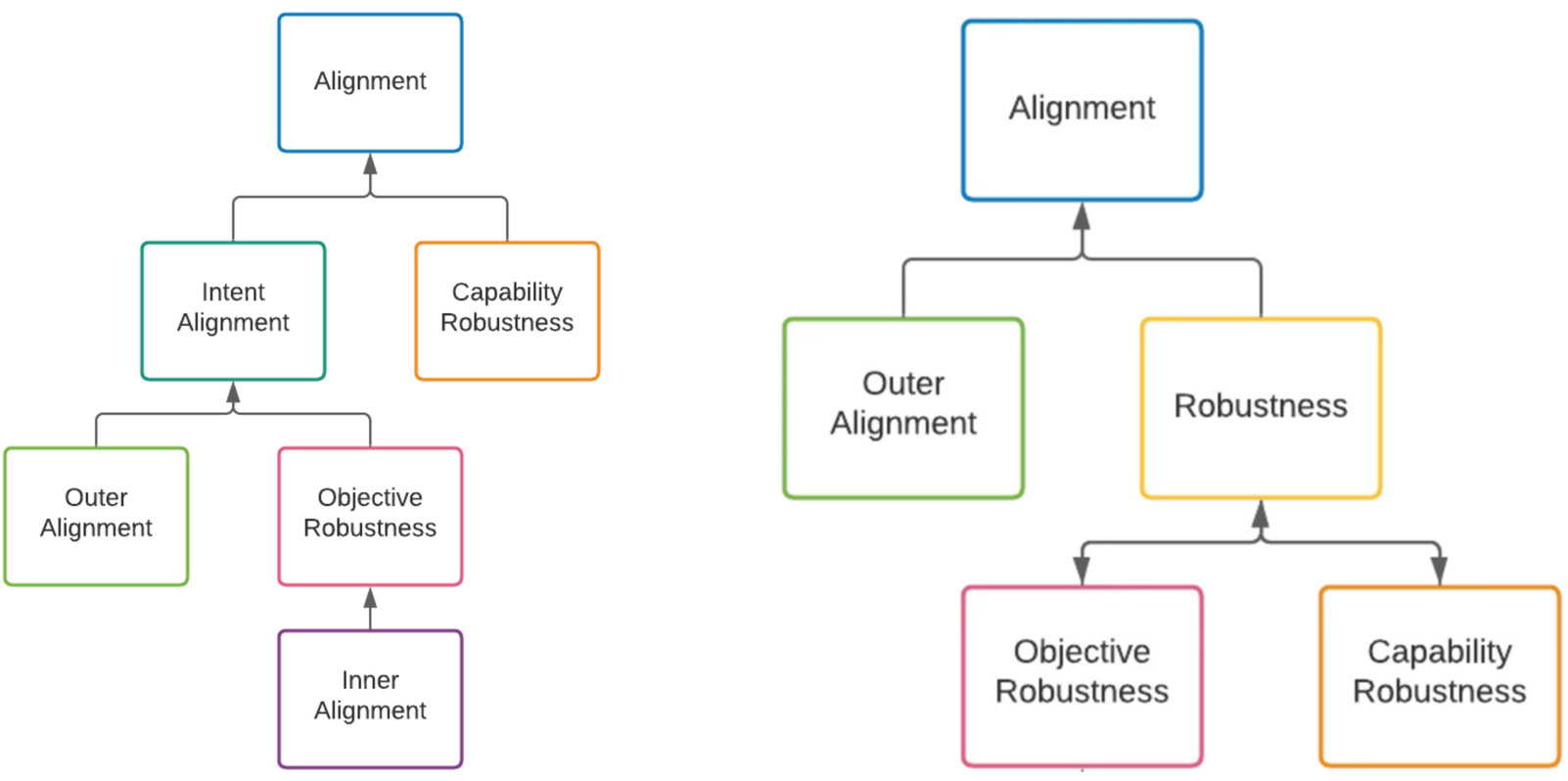
However, I believe that this isn’t the whole picture of the definitions for inner alignment circulating in the alignment community. There is also the definition put forward by John Wentworth, differing from Hubinger’s view in a more subtle way. In a post discussing that distinction, Wentworth puts forward the following decomposition:
“Assuming the outer optimizer successfully optimizes, failure to generalize from training environment to deployment environment is always an outer alignment failure (regardless of whether an inner optimizer appears).
Assuming outer alignment, inner alignment problems can occur only as the result of imperfect optimization.”
He later clarifies that he’s also fine with decomposing his definition of outer alignment into two separate problems: outer alignment as in choosing the right base objective, and robustness as in generalizing well to a large range of different distributions. His definition of inner alignment remains different from the ones Hubinger, Christiano, Ngo, and Shah use, though.
While Hubinger’s definition seems to imply that the mesa-objective has to be impact aligned with the base objective in any possible distribution, Wentworth considers inner alignment failure to be possible only in cases where the misalignment can already be observed from performance on the training distribution. This can only happen in cases where the training process creates a mesa-optimizer and stops optimizing it before its objective is fully aligned with the base objective.
Taking the example of humans, masturbation is an inner alignment failure according to Wentworth’s definition because humans were already able to do that in the ancestral environment, but it didn’t decrease our reproductive fitness enough for evolution to “optimize it away.” In contrast, birth control wasn’t present in the ancestral environment, so the training process i.e. evolution didn’t have a chance to select humans so as to prevent us from using it. To Wentworth, this absence of birth control from the training environment makes it something else than an inner alignment problem.
Now that I’ve gone over what seem to be the main points of disagreement, I will illustrate them with some concrete examples. To keep these examples concentrated on inner alignment, I will assume the outer alignment step to have already been solved in each of the examples. The first four examples will all assume that the system generated by the training process is a mesa-optimizer.
To avoid associating the definitions too much with single individuals, I will borrow terms from this post [LW · GW] by Jack Koch and Lauro Langosco to henceforth call Hubinger’s definition the objective-focused approach and Shah’s definition the generalization-focused approach. I will call Wentworth’s definition the optimization-focused approach, as inner misalignment can only occur as a result of imperfect optimization of the system in his model.
Some Concrete Examples
Example 1: The mesa-optimizer acquires the base objective
This is the best-case scenario – the mesa-optimizer is perfectly optimized and acquires exactly the same goal as the base optimizer. For the purposes of this post, it’s also the most uninteresting case: all sides agree that as long as the capabilities of the system generalize to the deployment environment, it’s definitely inner aligned. If the capabilities don’t generalize, it’s definitely still inner aligned by the objective-focused and optimization-focused approaches, since the mesa-objective remains aligned. I’m not completely sure, though, whether Shah’s generalization-focused approach would consider a pure capability robustness problem an inner alignment failure. However, this comment [LW(p) · GW(p)] seems to indicate that he views inner alignment as the problem of making the AI system generalize safely, and an agent without expected capabilities is probably still safe, though not useful. If the agent is inept at what it’s supposed to do but its behavioral objective remains the same as initially intended, then it’s unlikely to be dangerous and it doesn't seem too useful to classify it as being misaligned.
Example 2: Impact-aligned mesa-optimizer
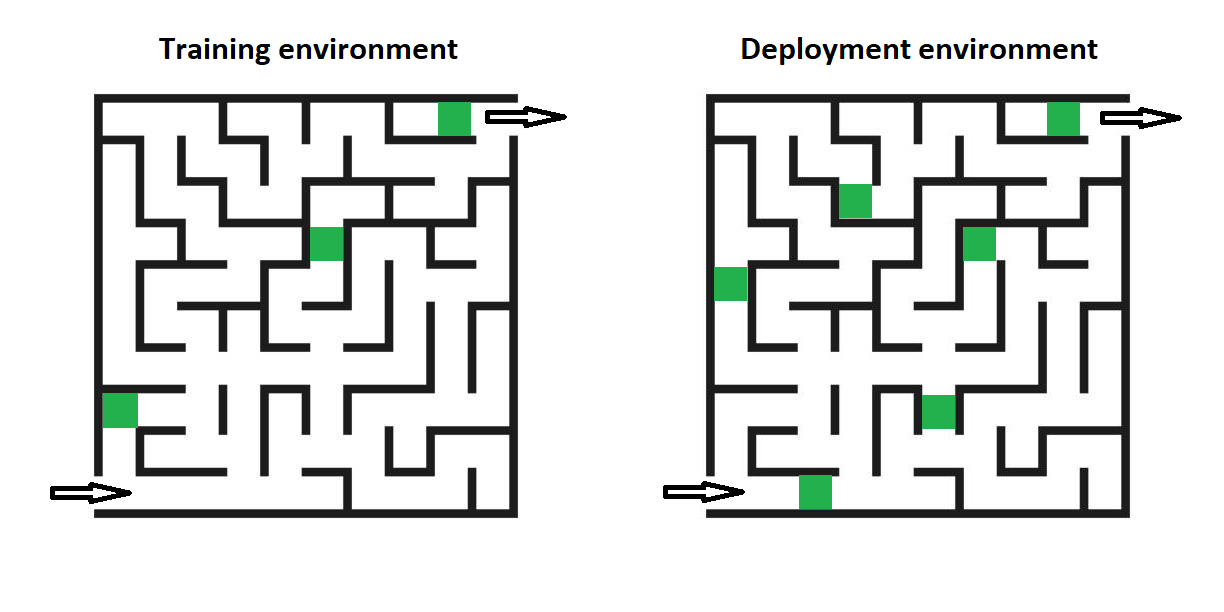
Consider a system trained on the objective of finding the exit of a maze like the ones on the image, starting from the entrance at the bottom. In the training environment, all the mazes have a green rectangle one cell to the left of the exit cell, with some having green cells in other places as well. The mesa-optimizer learns the proxy policy “find a green cell and step to the right. If you’re not out of the maze, search for another green cell and try again,“ which definitely isn’t the same thing as „exit the maze through the exit cell,” but works well on the training set and is thus deployed anyways.
Suppose that all deployment environments, while possibly containing other green cells in different places, still contain a green rectangle to the left of the exit. Thanks to the part of the policy that instructs the system to try again unless it’s out of the maze, its objective generalizes well to those new environments and no one notices that the AI doesn’t quite optimize for exiting the maze.
Assuming that the deployment environments really always contain a green rectangle next to the exit cell, it seems to me that all parties of the discussion consider this system inner aligned. Inner alignment isn’t about the mesa-optimizer necessarily having exactly the same goal as the base objective – rather, the mesa-objective must be a really good proxy for the base objective; its impact on the world must look as if the system had the base objective.
Example 3: Fully optimized non-impact aligned mesa-optimizer
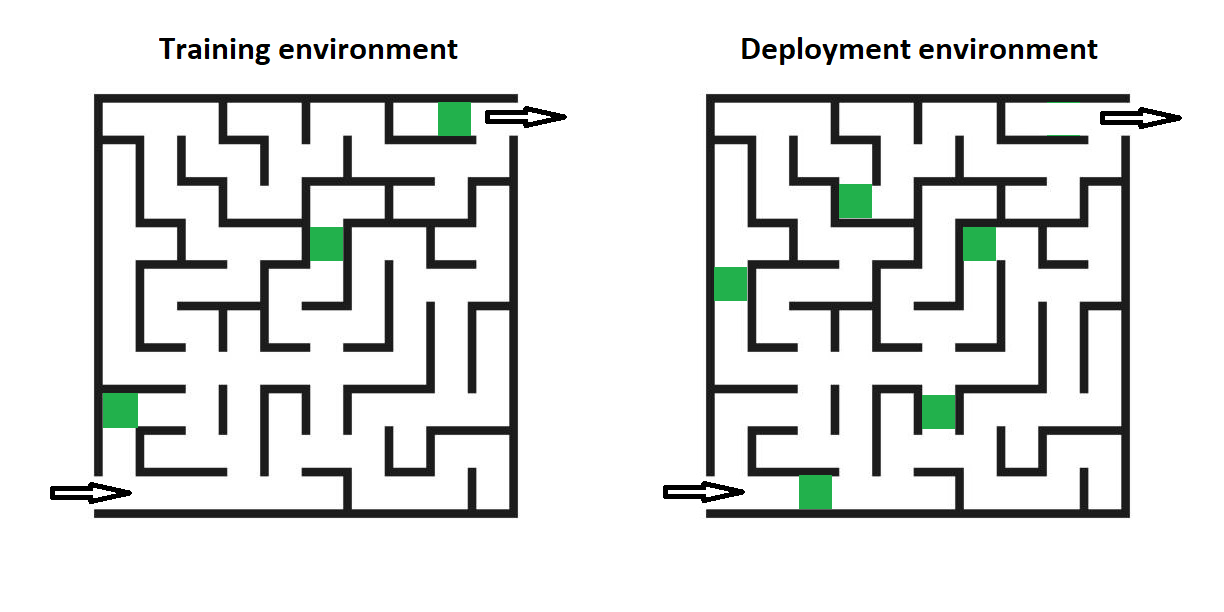
Now, consider the same training setup as in Example 2, but suppose that the deployment environment also includes mazes that don’t have a green cell to the left of the exit. As the training setup is the same, the mesa-optimizer again learns the proxy policy “find a green cell and step to the right. If you’re not out of the maze, search for another green cell and try again.” However, this policy now leads to a catastrophic failure inside all mazes that don’t have that green cell near the exit: the system will keep searching indefinitely in those cases. Is this an inner alignment failure to blame, though?
This is where different definitions give different answers. As a system having the base objective would find the exit cell in all deployment environments without the green exit cell as well (assuming the right base objective, of course), the mesa-optimizer isn’t impact aligned with the base objective in deployment. Thus, I would consider this an inner alignment failure going by the objective-focused approach. Proponents of the generalization-focused approach would also consider this an inner alignment failure, but, in my impression, more for the reason that the mesa-optimizer doesn’t generalize from the training environment to the deployment environment as well as expected.
In contrast, Wentworth would point out that the absence of mazes without a green cell near exit is the reason why the mesa-optimizer was able to acquire such a goal in the first place: had the training environment been identical to the deployment environment, the optimization process would have resulted in a mesa-optimizer with a more accurate objective, since a system that couldn’t get out of the maze whenever one green cell was missing wouldn’t have scored very well in the training process. Other, higher-scoring systems would have been chosen instead.
This is analogous to the case of birth control use in humans: the evolutionary training process made us mesa-optimizers with a different goal from the base objective, but the mesa-objective worked well enough for reproduction in the ancestral environment that hypothetical humans with an objective more closely reminiscent of evolution’s objective wouldn’t have had a significant fitness advantage. However, had birth control already been available in the ancestral environment, humans without the ability to use birth control would have reproduced more and probably been chosen for by evolution. Thus, Wentworth argues, birth control should be considered a generalization rather than an inner alignment failure. As we’ll see in Example 4, though, the optimization-focused approach still doesn’t make humans inner aligned with the base objective of evolution.
Example 4: Imperfectly optimized mesa-objective
Finally, consider the case where both training and deployment environments contain both mazes with a green cell near the exit and mazes without one. The training and deployment environments are very similar, so there won’t be any problems generalizing from one to the other. However, suppose that the people overseeing the training of the AI system decide at some point during training that although the system doesn’t perform perfectly in all mazes, it’s good enough that they’ll deploy it. Suppose that when the training process was terminated, the system once again had the policy “find a green cell and step to the right. If you’re not out of the maze, search for another green cell and try again.”
Even though the model performs reasonably well after deployment, the mesa-optimizer definitely isn’t fully impact aligned with the base objective. There is also no unexpected distributional shift amplifying that misalignment, so Hubinger and Wentworth seem to both agree that this is a case of inner misalignment. I’m not quite sure whether it’s also an inner misalignment failure by Shah’s definition, though: there is no unexpected generalization failure, it’s rather just that the model wasn’t trained to perform perfectly on the deployment distribution in the first place.
The case of masturbation that Wentworth describes as true inner alignment failure goes under this category, as it causes misalignment both in training and deployment environments in a similar way. In his words [LW · GW]:
“masturbation is a true inner alignment failure. Masturbation was readily available in the ancestral environment, and arose from a misalignment between human objectives and evolutionary objectives (i.e. fitness in the ancestral environment). It presumably didn’t decrease fitness very much in the ancestral environment, not enough for evolution to quickly find a work around, but it sure seems unlikely to have increased fitness - there is some “waste” involved. Key point: had evolution somehow converged to the “true optimum” of fitness in the ancestral environment (or even just something a lot more optimal), then that more-reproductively-fit “human” probably wouldn’t masturbate, even if it were still an inner optimizer.”
It definitely seems a bit counterintuitive to classify mesa-optimizers with the same base objective and same mesa-objective (which holds for both the maze AI and for humans) as inner aligned in Example 3 and as inner misaligned here in Example 4 using the same optimization-focused approach. However, Wentworth definitely has a point in arguing that no objective is well-defined without a distribution – the same objective can do completely different things on different datasets; put our maze AI on a chess board and its behavior would be completely different. It’s really difficult for the training process to prepare the agent for situations completely missing from the training data. Although the maze AI has the same objective in the same deployment environment in examples 3 and 4, the training distributions differ in these examples, so the reasons behind misaligned behavior are also slightly different.
On the other hand, I also like the argument by Richard Ngo [LW · GW] that a definition of inner alignment so dependent on the training distribution might be less useful than other possible definitions, since “almost all of the plausible AI threat scenarios involve the AI gaining access to capabilities that it didn't have access to during training.” We’re asking for perfectly optimal performance from an AGI and it makes sense for our definitions to reflect that.
Either way, I have come away with the impression that birth control isn’t the ideal example for illustrating Wentworth’s point because humans are, as both sides agree and as the masturbation example exemplifies, inner misaligned. His point seems to be that birth control isn’t what makes humans inner misaligned – things like masturbation are. The invention of birth control didn’t all of a sudden make humans more inner misaligned. A clearer example would perhaps be a system that has a mesa-objective completely impact aligned with the base objective, just as in Example 2, until a distributional shift to the world containing a birth control analogue takes place. Then again, what’s a better source of intuitive examples than your own species?
Example 5: Other generalization failures
Finally, a quick note has to be made about generalization failures in systems that aren't mesa-optimizers. As discussed before, the generalization-based approach is the only one of the definitions that can classify systems as inner misaligned even if those systems aren’t mesa-optimizers, provided that their behavioral objective in deployment differs from the base objective. As an example of such a system, consider an AI with some limited self-replication capabilities, once again tasked with exiting a maze. If the training set contains only small mazes, the training process may produce a system that just self-replicates until pieces of it fill the whole maze and one of its pieces happens to be at the exit. A system simply always following the rule to divide into as many pieces as it can doesn’t optimize for anything, so it isn’t a mesa-optimizer.
When put into a significantly larger maze after a distributional shift, the system’s capabilities to self-replicate might be too limited to reach the exit, so it may look like its goal is to simply self-replicate instead of to get out of the maze. In contrast to the generalization failure discussed under Example 1, where capability robustness was the sole problem, the system's behavioral objective definitely isn't aligned with the base objective in this example. This is the type of objective robustness failure that, in my impression, qualifies as inner misalignment under the generalization-focused approach.
Why does this all matter?
What do we expect to gain from clarifying the definitions of these terms? Does this debate have any practical relevance, or are we just arguing about labels in our belief network [? · GW]?
Considering the recent calls to formalize the concept of inner alignment [LW · GW] and that we have already built AI systems that pretty clearly exhibit inner misalignment, I would argue that there is a very real need for some consensus around the meaning of the term. It wouldn't be particularly useful to create different formalizations of the same term, and spending our limited time discussing the issue itself is definitely more useful than spending it clarifying the relevant definitions.
Arguments for and against different definitions
As this post has concentrated more on explaining the definitions than on arguing for and against them, I’ll note down some links with arguments that I like:
- Richard Ngo’s comments here [LW · GW] and here [LW · GW] make a good case for using the objective-focused approach
- Wentworth makes a good case for the optimization-focused approach here [LW · GW] and here [LW · GW]
- Jack Koch and Lauro Langosco present good arguments for both the objective-focused and the generalization-focused approach here [LW · GW]
It is outside the scope of this post to decide which of these arguments should win out in the end. I hope, though, that it will help the term be clarified in advance in future discussions about alignment, and reduce confusion and cases of speaking past each other through that.
- ^
Listen from 19.00 for the quoted excerpt.
0 comments
Comments sorted by top scores.