Joe Carlsmith with a really detailed report on computational upper bounds and lower bounds on simulating a human brain:
Open Philanthropy is interested in when AI systems will be able to perform various tasks that humans can perform (“AI timelines”). To inform our thinking, I investigated what evidence the human brain provides about the computational power sufficient to match its capabilities. This is the full report on what I learned. A medium-depth summary is available here. The executive summary below gives a shorter overview.
[...]
Let’s grant that in principle, sufficiently powerful computers can perform any cognitive task that the human brain can. How powerful is sufficiently powerful? I investigated what we can learn from the brain about this. I consulted with more than 30 experts, and considered four methods of generating estimates, focusing on floating point operations per second (FLOP/s) as a metric of computational power.
These methods were:
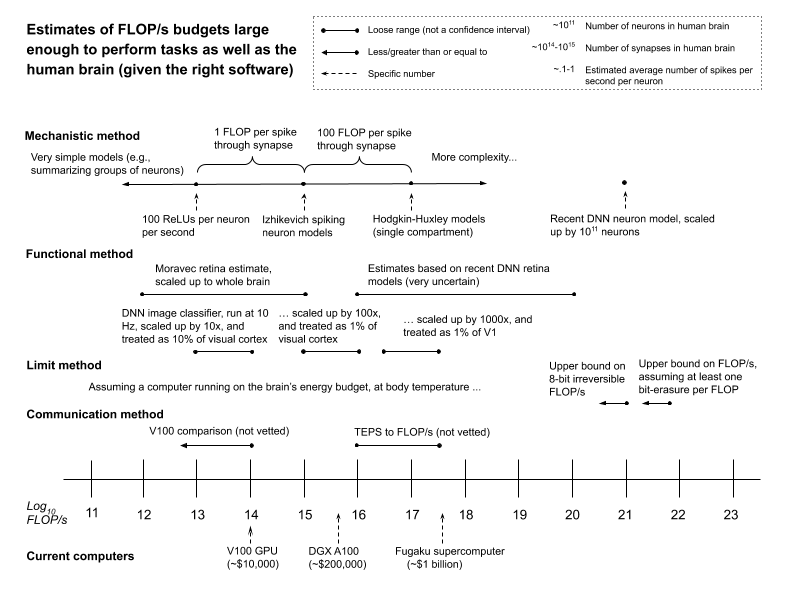
Estimate the FLOP/s required to model the brain’s mechanisms at a level of detail adequate to replicate task-performance (the “mechanistic method”).1
Identify a portion of the brain whose function we can already approximate with artificial systems, and then scale up to a FLOP/s estimate for the whole brain (the “functional method”).
Use the brain’s energy budget, together with physical limits set by Landauer’s principle, to upper-bound required FLOP/s (the “limit method”).
Use the communication bandwidth in the brain as evidence about its computational capacity (the “communication method”). I discuss this method only briefly.
None of these methods are direct guides to the minimum possible FLOP/s budget, as the most efficient ways of performing tasks need not resemble the brain’s ways, or those of current artificial systems. But if sound, these methods would provide evidence that certain budgets are, at least, big enough (if you had the right software, which may be very hard to create – see discussion in section 1.3).2
Here are some of the numbers these methods produce, plotted alongside the FLOP/s capacity of some current computers.
Figure 1: The report’s main estimates. See the conclusion for a list that describes them in more detail, and summarizes my evaluation of each.
These numbers should be held lightly. They are back-of-the-envelope calculations, offered alongside initial discussion of complications and objections. The science here is very far from settled.
FLOPS don't seem to me a great metric for this problem; they are often very sensitive to the precise setup of the comparison, in ways that often aren't very relevant (the Donkey Kong comparison emphasized this), and the architecture of computers is fundamentally different to that of brains. What seems like a more apt and stable comparison is to compare the size and shape of the computational graph, roughly the tuple (width, depth, iterations). This seems like a much more stable metric, since scale-based metrics normally only change significantly when you're handling the problem in a semantically different way. In the example, hardware implementations of Donkey Kong and various sorts of software emulation (software interpreter, software JIT, RTL simulation, FPGA) will have very different throughputs on different hardware, and the setup and runtime overheads for each might be very different, but the actual runtime computation graphs should look very comparable.
This also has the added benefit of separating out hypotheses that should naturally be distinct. For example, a human-sized brain at 1x speed and a hamster brain at 1000x speed are very different, yet have seemingly similar FLOPS. Their computation graphs are distinct. Technology comparisons like FPGAs vs AI accelerators become a lot clearer from the computation graph perspective; an FPGA might seem at a glance more powerful from a raw OP/s perspective, but first principles arguments will quickly show they should be strictly weaker than an AI accelerator. It's also more illuminating given we have options to scale up at the cost of performance; from a pure FLOPS perspective, this is negative progress, but pragmatically, this should push timelines closer.