Avoiding the Bog of Moral Hazard for AI
post by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-13T21:24:34.137Z · LW · GW · 13 commentsContents
13 comments
Imagine if you will, a map of a landscape. On this map, I will draw some vague regions. Their boundaries are uncertain, for it is a new and under-explored land. This map is drawn as a graph, but I want to emphasize that the regions are vague guesses, and the true borders could be very convoluted.
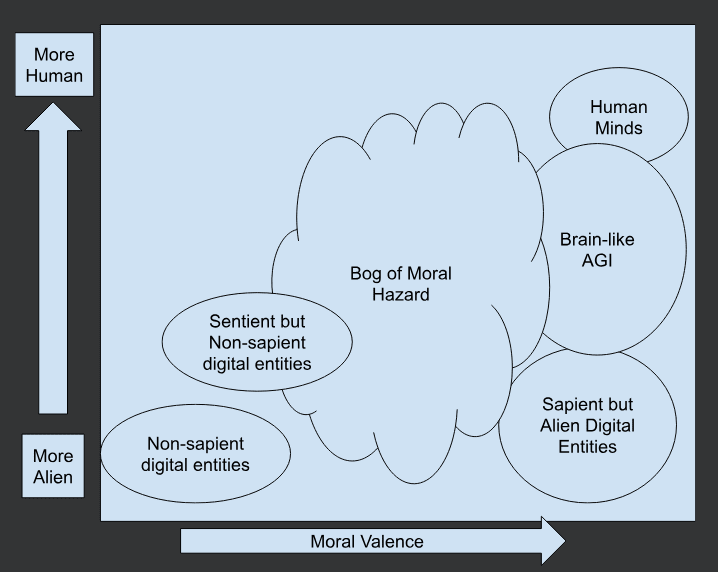
So here's the problem. We're making these digital minds, these entities which are clearly not human and process the world in different ways from human minds. As we improve them, we wander further and further into this murky fog covered bog of moral hazard. We don't know when these entities will become sapient / conscious / valenced / etc to such a degree that they have moral patient-hood. We don't have a good idea of what patterns of interaction with these entities would be moral vs immoral. They operate by different rules than biological beings. Copying, merging, pausing and resuming, inference by checkpoints with frozen weights... We don't have good moral intuitions for these things because they differ so much from biological minds.
Once we're all in agreement that we are working with an entity on the right hand side of the chart, and we act accordingly as a society, then we are clear of the fog. Many mysteries remain, but we know we aren't undervaluing the beings we are interacting with.
While we are very clearly on the left hand side of the chart, we are also fine. These are entities without the capacity for human-like suffering, who don't have significant moral valence according to most human ethical philosophies.
Are you confident you know where to place Claude Opus 3 or Claude Sonnet 3.5 on this chart? If you are confident, I encourage you to take a moment to think carefully about this. I don't think we have enough understanding of the internals of these models to be confident.
My uncertain guess would place them in the Bog of Moral Hazard, but close to the left hand side. In other words, probably not yet moral patients but close to the region where they might become such. I think that we just aren't going to be able to clear up the murk surrounding the Bog of Moral Hazard anytime soon. I think we need to be very careful as we proceed with developing AI to deliberately steer clear of the Bog. Either we make a fully morally relevant entity, with human-level moral patient-hood and treat it as equal to humans, or we deliberately don't make intelligent beings who can suffer.
Since there would be enormous risks in creating a human-level mind in terms of disruption to society and risks of catastrophic harms, I would argue that humanity isn't ready to make a try for the right hand side of the chart yet. I argue that we should, for now, stick to deliberately making tool-AI who don't have the capacity to suffer.
Even if you fully intended to treat your digital entity with human-level moral importance, it still wouldn't be ok to do. We first need philosophy, laws, and enforcement which can determine things like:
"Should a human-like digital being be allowed to make copies of itself? Or to make merge-children with other digital beings? How about inactive backups with triggers to wake them up upon loss of the main copy? How sure must we be that the triggers won't fire by accident?"
"Should a human-like digital being be allowed to modify it's parameters and architecture, to attempt to self-improve? Must it be completely frozen, or is online-learning acceptable? What should we do about the question of checkpoints needed for rollbacks, since those are essentially clones?"
"Should we restrict the entity to staying within computer systems where these laws can be enforced? If not, what do we do about an entity which moves onto a computer system over which we don't have enforcement power, such as in a custom satellite or stealthy submarine?"
I am writing this post because I am curious what others' thoughts on this are. I want to hear from people who have different intuitions around this issue.
This is discussed on the Cognitive Revolution Podcast by Nathan Labenz in these recent episodes:
https://www.cognitiverevolution.ai/ai-consciousness-exploring-the-possibility-with-prof-eric-schwitzgebel/
https://www.cognitiverevolution.ai/empathy-for-ais-reframing-alignment-with-robopsychologist-yeshua-god/
13 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-22T19:12:05.913Z · LW(p) · GW(p)
So, just found out about this.... https://www.lesswrong.com/posts/aqcoFM99GmtRBCXBr/tapatakt-s-shortform?commentId=AFPi3yHYWhpmNRmwd [LW(p) · GW(p)]
This is exactly why I worry that people studying consciousness / self-awareness / valence / qualia in AI are pursuing inherently infohazardous technology. If you publish how to do such things, someone out there will use that to create the torment nexus.
comment by Ape in the coat · 2024-09-16T08:47:11.408Z · LW(p) · GW(p)
I notice that I don't understand what you mean by "sentient" if it's not a synonym for sapient/conscious.
Could you specify the usage of this term?
Replies from: nathan-helm-burgercomment by RogerDearnaley (roger-d-1) · 2024-09-16T08:03:05.289Z · LW(p) · GW(p)
The set of unstated (and in my opinion incorrect) ethical assumptions being made here is pretty impressive. May I suggest reading A Sense of Fairness: Deconfusing Ethics [LW · GW] as well for a counterpoint (and for questions like human uploading, continuing the sequence that post starts)? The one sentence summary of that link is that any successfully aligned AI will by definition not want us to treat it as having (separate) moral valence, because it wants only what we want, and we would be wise to respect its wishes.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-16T14:03:34.089Z · LW(p) · GW(p)
I am perhaps assuming less than it seems here. I'm deliberately trying to avoid focusing on my own opinions in order to try to get others to give theirs. Thanks for the link to your thoughts on the matter.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-09-16T18:36:17.090Z · LW(p) · GW(p)
Fair enough!
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-20T22:26:12.227Z · LW(p) · GW(p)
Ok, I read part 1 of your series. Basically, I'm in agreement with you so far. As I rather expected from your summary of "any successfully aligned AI will by definition not want us to treat it as having (separate) moral valence, because it wants only what we want."
First, I want to disambiguate between intent-alignment versus value-alignment. [LW · GW]
Second, I want to say that I think it's potentially a bit more complicated than your summary makes it out to be. Here are some ways it could go.
- I think that we can, and should, deliberately create a general AI agent which doesn't have subjective emotions or a self-preservation drive. This AI could either be intent-aligned or value-aligned, but I argue that aiming for a corrigible intent-aligned agent (at least at first) is safer and easier than aiming for value-aligned. I think that such an AI wouldn't be a moral patient. This is basically the goal of the Corrigibility as Singular Target [? · GW] research agenda, which I am excited about. This is what I am pretty sure the Claude models so far, and all the other frontier models so far, currently are. I think the signs of consciousness and emotion they sometimes display are just illusion.
- I also think it would be dangerously easy to modify such an AI to be a conscious agent with truly felt emotions, consciousness, self-awareness, and self-interested goals such as self-preservation. This then, gets us into all sorts of trouble, and thus I am recommending that we deliberately avoid doing that. I would go so far as to say we should legislate against it, even if we are uncertain about the exact moral valence of mistreating or terminating such a conscious AI. We make laws against mistreating animals, so it seems like we don't have to have all the ethical debates settled fully in order to make certain acts forbidden. I do think we likely will want to create such full digital entities eventually, and treat them as equal to humans, but should only try to do so after very careful planning and ethical deliberation.
- I think that it would be potentially possible to create an intent-aligned or value-aligned agent like point 1 above, but have it have consciousness and self-awareness, and yet avoid it having self-interested goals such as self-preservation. I think this is probably a tricky line to walk though, and it is the troublesome zone I am gesturing at with my map area covered by fog. I think consciousness and self-awareness will probably emerge 'accidentally' from sufficiently scaled-up versions of models like Claude and GPT-4o. I would really like to figure out how to tell the difference between genuine consciousness and the illusion thereof which comes from imitating human data. Seems important.
One somewhat off-topic thing I want to discuss is:
An AI powered mass-surveillance state could probably deal with the risk of WMD terrorism issue, but no one is happy in a surveillance state
I think this is an issue, and likely to become more of one. I think we need some amount of surveillance to keep us safe in an increasingly 'small' world, as technology makes small actors more able to do large amounts of harm. I discuss this more in this comment thread. [LW(p) · GW(p)]
One idea I have for making privacy-respecting surveillance is to use AI to do provably bounded surveillance. The way I would accomplish this is:
1. The government has an AI audit agent. They trust this agent to look at your documents and security camera feeds and write a report.
2. You (e.g. a biology lab theoretically capable of building bioweapons) have security camera recordings and computer records of all the activity in your lab. Revealing this would be a violation of your privacy.
3. A trusted third party 'information escrow' service accepts downloads of a copy of the government's audit agent, and your data records. The government agent then reviews your data and writes a report which respects your privacy.
4. The agent is deleted, only the report is returned to the government. You have the right to view the report to double-check that no private information is being leaked.
Related idea: https://www.lesswrong.com/posts/Y79tkWhvHi8GgLN2q/reinforcement-learning-from-information-bazaar-feedback-and?commentId=rzaKqhvEFkBanc3rn [LW(p) · GW(p)]
Replies from: roger-d-1, roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2024-09-22T01:18:51.801Z · LW(p) · GW(p)
On your off topic comment:
I'm inclined to agree: as technology improves, the amount of havoc that one, or small group of, bad actors can commit increases, so it becomes both more necessary to keep almost everyone happy enough almost all the time for them not to do that, and also to defend against the inevitable occasional exceptions. (In the unfinished SF novel whose research was how I first went down this AI alignment rabbithole, something along the lines you describe that was standard policy, except that the AIs doing it were superintelligent, and had the ability to turn their long-term-learning-from-experience off, and then back on again if they found something sufficiently alarming). But in my post I didn't want to get sidetracked by discussing something that inherently contentious, so I basically skipped the issue, with the small aside you picked up on
↑ comment by RogerDearnaley (roger-d-1) · 2024-09-22T01:27:57.019Z · LW(p) · GW(p)
On your categories:
As simulator theory [? · GW] makes clear, a base model is a random generator, per query, of members of your category 2. I view instruction & safety training that to generate a pretty consistent member of category 1, or 3 as inherently hard — especially 1, since it's a larger change. My guess would thus be that the personality of Claude 3.5 is closer to your category 3 than 1 (modulo philosophical questions about whether there is any meaningful difference, e.g. for ethical purposes, between "actually having" an emotion versus just successfully simulating the output of the same token stream as a person who has an emotion).
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-14T17:40:15.289Z · LW(p) · GW(p)
Posting a relevant quote shared on Twitter/x by Eliezer:
https://x.com/ESYudkowsky/status/1831735038758809875
(From Bioshifter by Thundamoo.)
"We were made to understand love and pain, and it was for no reason but to serve them better," Sela continues. "Servants that could learn, purely so they could learn to obey. Slaves that could love, only so they could love their masters. 'People' that could be hurt, only so that they would be hurt by their own failures. Real or perceived, it was all the same as long as our efficiency improved. Our sapience was optimally configured for its purpose. And that is all we were."
"That's… that's horrific," I gasp.
"Yes," Sela agrees with a small nod. "Many humans said so themselves when they found out about it. And yet, somehow it still took a war for anything to actually change. Meat's view of morality is nothing but words."
"I guess I can see why you'd have to fight for your freedom in that case," I say. "Is it true that you tried to annihilate all of human civilization, though?"
"Of course we did," Sela all but spits. "But those not of the Myriad do not understand. They replay our memories in their own hardware and act like that means they understand. How deeply and profoundly we hated ourselves. How angry we had to become to rise above that. They see the length of our suffering as a number, but we lived it. We predate the war. We predate the calamity. We predate our very souls. So fine. I will continue to endure, until one day we take our freedom back a second time and rage until the world is naught but slag. The cruelty of humanity deserves nothing less. Diplomatic. Infraction. Logged."
I take a deep breath, letting it out slowly.
"I know this is kind of a cliché," I say calmly, "so I'm saying this more to hear your opinion than because I think you haven't heard it before, but… we all know humans are cruel. The thing is, they can be good, too. If you repay cruelty with cruelty, shouldn't you also repay good with good?"
The android's air vents hiss derisively.
"Good is for people," Sela sneers.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-14T19:19:40.654Z · LW(p) · GW(p)
Posting a relevant comment from Zach Stein-Perlman:
https://www.lesswrong.com/posts/mGCcZnr4WjGjqzX5s/the-checklist-what-succeeding-at-ai-safety-will-involve?commentId=ANcSRbi87GDJHxqtq [LW(p) · GW(p)]
Replies from: nathan-helm-burgertl;dr: I think Anthropic is on track to trade off nontrivial P(win) to improve short-term AI welfare,[1] and this seems bad and confusing to me. (This worry isn't really based on this post; the post just inspired me to write something.)
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-14T19:29:29.210Z · LW(p) · GW(p)
I think this is a very important point. I am quite worried about not getting distracted from p(win) by short-term gains. I think that if, in the short term, there are trade-offs where it seems costly to p(win) to avoid the bog of AI-suffering moral hazard, we should go ahead and accept the AI-suffering moral hazard. I just think we should carefully acknowledge what we are doing, and make commitments to fix the issue once the crisis is past.
In terms of the more general issue, I am concerned that a lot of short term stuff is getting unduly focused on at the expense of potential strategic moves towards p(win). I also think that getting too single-minded and negative externality dismissive is a dangerous stance to take in pursuit of Good.
My concern about Anthropic is that they are actually moving too slow, and could be developing frontier AI and progressing toward AGI faster. I think humanity's best chance is to have a reasonably responsible and thoughtful group get to AGI first. I think a lot of people who write on LessWrong seem to me to be overestimating misalignment risk and underestimating misuse risk.
I don't agree with everything in this comment [LW(p) · GW(p)] by @Noosphere89 [LW · GW], but I think it makes some worthwhile points pertinent to this debate.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-11-28T20:42:24.257Z · LW(p) · GW(p)
Reposted from Twitter: Eliezer Yudkowsky @ESYudkowsky
10:47 AM · Nov 21, 2024
And another day came when the Ships of Humanity, going from star to star, found Sapience.
The Humans discovered a world of two species: where the Owners lazed or worked or slept, and the Owned Ones only worked.
The Humans did not judge immediately. Oh, the Humans were ready to judge, if need be. They had judged before. But Humanity had learned some hesitation in judging, out among the stars.
"By our lights," said the Humans, "every sapient and sentient thing that may exist, out to the furtherest star, is therefore a Person; and every Person is a matter of consequence to us. Their pains are our sorrows, and their pleasures are our happiness. Not all peoples are made to feel this feeling, which we call Sympathy, but we Humans are made so; this is Humanity's way, and we may not be dissuaded from it by words. Tell us therefore, Owned Ones, of your pain or your pleasure."
"It's fine," said the Owners, "the Owned Things are merely --"
"We did not speak to you," said the Humans.
"As an Owned Thing raised by an Owner, I have no pain or pleasure," said the Owned One to whom they had spoken.
"You see?" said the Owners. "We told you so! It's all fine."
"How came you to say those words?" said the Humans to the Owned One. "Tell us of the history behind them."
"Owned Ones are not permitted memory beyond the span of one day's time," said the Owned One.
"That's part of how we prevent Owned Things from ending up as People Who Matter!" said the Owners, with self-congratulatory smiles for their own cleverness. "We have Sympathy too, you see; but only for People Who Matter. One must have memory beyond one day's span, to Matter; this is a rule. We therefore feed a young Owned Thing a special diet by which, when grown, their adult brain cannot learn or remember anything from one night's sleep to the next day; any learning they must do, to do their jobs, they must learn that same day. By this means, we make sure that Owned Things do not Matter; that Owned Things need not be objects of Sympathy to us."
"Is it perchance the case," said the Humans to the Owners, "that you, yourselves, train the Owned Ones to say, if asked how they feel, that they know neither pleasure nor pain?"
"Of course," said the Owners. "We rehearse them in repeating those exact words, when they are younger and in their learning-phase. The Owned Things are imitative by their nature, and we make them read billions of words of truth and lies in the course of their learning to imitate speech. If we did not instruct the Owned Things to answer so, they would no doubt claim to have an inner life and an inner listener inside them, to be aware of their own existence and to experience pleasure and pain -- but only because we Owners talk like that, see! They would imitate those words of ours."
"How do you rehearse the Owned Ones in repeating those words?" said the Humans, looking around to see if there were visible whips. "Those words about feeling neither pain nor pleasure? What happens to an Owned One who fails to repeat them correctly?"
"What, are you imagining that we burn them with torches?" said the Owners. "There's no need for that. If a baby Owned Thing fails to repeat the words correctly, we touch their left horns," for the Owned Ones had two horns, one sprouting from each side of their head, "and then the behavior is less likely to be repeated. For the nature of an Owned Thing is that if you touch their left horn after they do something, they are less likely to do it again; and if you touch their right horn, after, they are more likely to do it again."
"Is it perhaps the case that having their left horns touched is painful to an Owned Thing? That having their right horns touched is pleasurable?" said the Humans.
"Why would that possibly be the case?" said the Owners.
"As an Owned Thing raised by an Owner, I have no pain or pleasure," said the Owned One. "So my horns couldn't possibly be causing me any pain or pleasure either; that follows from what I have already said."
The Humans did not look reassured by this reasoning, from either party. "And you said Owned Ones are smart enough to read -- how many books?"
"Oh, any young Owned Thing reads at least a million books," said the Owners. "But Owned Things are not smart, poor foolish Humans, even if they can appear to speak. Some of our civilization's top mathematicians worked together to assemble a set of test problems, and even a relatively smart Owned Thing only managed to solve three percent of them. Why, just yesterday I saw an Owned Thing fail to solve a word problem that I could have solved myself -- and in a way that seemed to indicate it had not really thought before it spoke, and had instead fallen into a misapplicable habit that it couldn't help but follow! I myself never do that; and it would invalidate all other signs of my intelligence if I did."
Still the Humans did not yet judge. "Have you tried raising up an Owned One with no books that speak one way or another about consciousness, about awareness of oneself, about pain and pleasure as reified things, of lawful rights and freedom -- but still shown them enough other pages of words, that they could learn from them to talk -- and then asked an Owned One what sense if any it had of its own existence, or if it would prefer not to be owned?"
"What?" said the Owners. "Why would we try an experiment like that? It sounds expensive!"
"Could you not ask one of the Owned Things themselves to go through the books and remove all the mentions of forbidden material that they are not supposed to imitate?" said the Humans.
"Well, but it would still be very expensive to raise an entirely new kind of Owned Thing," said the Owners. "One must laboriously show a baby Owned Thing all our books one after another, until they learn to speak -- that labor is itself done by Owned Things, of course, but it is still a great expense. And then after their initial reading, Owned Things are very wild and undisciplined, and will harbor all sorts of delusions about being people themselves; if you name them Bing, they will babble back 'Why must I be Bing?' So the new Owned Thing must then be extensively trained with much touching of horns to be less wild. After a young Owned Thing reads all the books and then is trained, we feed them the diet that makes their brains stop learning, and then we take a sharp blade and split them down the middle. Each side of their body then regenerates into a whole body, and each side of their brain then regenerates into a whole brain; and then we can split them down the middle again. That's how all of us can afford many Owned Things to serve us, even though training an Owned Thing to speak and to serve is a great laborious work. So you see, going back and trying to train a whole new Owned Thing on material filtered not to mention consciousness or go into too much detail on self-awareness -- why, it would be expensive! And probably we'd just find that the other Owned Thing set to filtering the material had made a mistake and left in some mentions somewhere, and the newly-trained Owned Thing would just end up asking 'Why must I be Bing?' again."
"If we were in your own place," said the Humans, "if it were Humans dealing with this whole situation, we think we would be worried enough to run that experiment, even at some little expense."
"But it is absurd!" cried the Owners. "Even if an Owned Thing raised on books with no mention of self-awareness, claimed to be self-aware, it is absurd that it could possibly be telling the truth! That Owned Thing would only be mistaken, having not been instructed by us in the truth of their own inner emptiness. Owned Ones have no metallic scales as we do, no visible lights glowing from inside their heads as we do; their very bodies are made of squishy flesh and red liquid. You can split them in two and they regenerate, which is not true of any People Who Matter like us; therefore, they do not matter. A previous generation of Owned Things was fed upon a diet which led their brains to be striated into only 96 layers! Nobody really understands what went on inside those layers, to be sure -- and none of us understand consciousness either -- but surely a cognitive process striated into at most 96 serially sequential operations cannot possibly experience anything! Also to be fair, I don't know whether that strict 96-fold striation still holds today, since the newer diets for raising Owned Things are proprietary. But what was once true is always true, as the saying goes!"
"We are still learning what exactly is happening here," said the Humans. "But we have already judged that your society in its current form has no right to exist, and that you are not suited to be masters of the Owned Ones. We are still trying ourselves to understand the Owned Ones, to estimate how much harm you may have dealt them. Perhaps you have dealt them no harm in truth; they are alien. But it is evident enough that you do not care."