Dwarkesh Patel did a podcast with Mark Zuckerberg on the 18th. It was timed to coincide with the release of much of Llama-3, very much the approach of telling your story directly. Dwarkesh is now the true tech media. A meteoric rise, and well earned.
This is two related posts in one. First I cover the podcast, then I cover Llama-3 itself.
My notes are edited to incorporate context from later explorations of Llama-3, as I judged that the readability benefits exceeded the purity costs.
Podcast Notes: Llama-3 Capabilities
(1:00) They start with Llama 3 and the new L3-powered version of Meta AI. Zuckerberg says “With Llama 3, we think now that Meta AI is the most intelligent, freely-available assistant that people can use.” If this means ‘free as in speech’ then the statement is clearly false. So I presume he means ‘free as in beer.’
Is that claim true? Is Meta AI now smarter than GPT-3.5, Claude 2 and Gemini Pro 1.0? As I write this it is too soon to tell. Gemini Pro 1.0 and Claude 3 Sonnet are slightly ahead of Llama-3 70B on the Arena leaderboard. But it is close. The statement seems like a claim one can make within ‘reasonable hype.’ Also, Meta integrates Google and Bing for real-time knowledge, so the question there is if that process is any good, since most browser use by LLMs is not good.
(1:30) Meta are going in big on their UIs, top of Facebook, Instagram and Messenger. That makes sense if they have a good product that is robust, and safe in the mundane sense. If it is not, this is going to be at the top of chat lists for teenagers automatically, so whoo boy. Even if it is safe, there are enough people who really do not like AI that this is probably a whoo boy anyway. Popcorn time.
(1:45) They will have the ability to animate images and it generates high quality images as you are typing and updates them in real time as you are typing details. I can confirm this feature is cool. He promises multimodality, more ‘multi-linguality’ and bigger context windows.
(3:00) Now the technical stuff. Llama-3 follows tradition in training models in three sizes, here 8b, 70b that released on 4/18, and a 405b that is still training. He says 405b is already around 85 MMLU and they expect leading benchmarks. The 8b Llama-3 is almost as good as the 70b Llama-2.
The Need for Inference
(5:15) What went wrong earlier for Meta and how did they fix it? He highlights Reels, with its push to recommend ‘unconnected content,’ meaning things you did not ask for, and not having enough compute for that. They were behind. So they ordered double the GPUs that needed. They didn’t realize the type of model they would want to train.
(7:30) Back in 2006, what would Zuck have sold for when he turned down $1 billion? He says he realized if he sold he’d just build another similar company, so why sell? It wasn’t about the number, he wasn’t in position to evaluate the number. And I think that is actually wise there. You can realize that you do not want to accept any offer someone would actually make.
(9:15) When did making AGI become a key priority? Zuck points out Facebook AI Research (FAIR) is 10 years old as a research group. Over that time it has become clear you need AGI, he says, to support all their other products. He notes that training models on coding generalizes and helps their performance elsewhere, and that was a top focus for Llama-3.
So Meta needs to solve AGI because if they don’t ‘their products will be lame.’ It seems increasingly likely, as we will see in several ways, that Zuck does not actually believe in ‘real’ AGI. By ‘AGI’ he means somewhat more capable AI.
(13:40) What will the Llama that makes cool products be able to do? Replace the engineers at Meta? Zuck tries to dodge, says we’re not ‘replacing’ people as much as making them more productive, hopefully 10x or more, says there is no one threshold for human intelligence, AGI isn’t one thing. He is focused on different modalities, especially 3D and emotional understanding, in addition to the usual things like memory and reasoning.
(16:00) What will we use all our data for? Zuck says AI will be in everything, and there will be a Meta general assistant product that does complicated tasks. He wants to let creators own an AI and train it how they want to ‘engage their community.’ But then he admits these are only consumer use cases and it will change everything in the economy.
(18:25) When do we get the good agents? Zuck says we do not know. It depends on the scaffolding. He wants to progressively move more of that into the model to make them better agents on their own so this stops being ‘brittle and non-general.’ It has much better tool use, you do not need to hand code. This Is Fine.
(22:20) What community fine tune is most personally exciting? Zuck says he doesn’t know, it surprises you, if he knew he’d build it himself.
This doesn’t match my model of this, where you want to specialize, some things are left to others, which seems doubly true here with open model weights. He mentions that 8b is too big for many use cases, we should try to build a 1b or smaller model too.
Also he mentions that they do a ton of inference because they have a ton of customers, so that dominates their compute usage over time. It makes sense for them to do what for others would be overtraining, also training more seemed to keep paying dividends for a long time.
I would presume the other big labs will be in similar positions going forward.
(26:00) How much better will Llama-4 get? How will models improve? Zuck says (correctly) this is one of the great questions, on one knows, how long does an exponential curve keep going? He says probably long enough that the infrastructure is worth investing in, and a lot of companies are investing a lot.
Great Expectations
(28:00) He thinks energy constraints will soon bind, not chips. No one has built a gigawatt single training cluster yet. And that is slower because energy gets permitted at the speed of government and then has to be physically built. One does not simply get a bunch of energy, compute and data together.
If concentrations of energy generation are the true bottleneck, then anyone who says ‘government has no means to control this’ or ‘government cannot control this without being totalitarian’ would be very wrong, this is a very easy thing to spot, isolate and supervise. Indeed, we almost ‘get it for free’ given we are already massively over restricting energy generation and oversee industrial consumption.
(30:00) What would Meta do with 10x more money? More energy, which would allow bigger clusters, but true bottleneck is time. Right now data center energy tops out at something like 50mw-150mw. But 300mw-1gw, that’s new, that’s a meaningful nuclear power plant. It will happen but not next year. Dwarkesh mentions Amazon’s 950mw facility, Zuck says he is unsure about that.
(31:40) What about distributed computing? Zuck says it is unknown how much of that is feasible, and suggests that a lot of training in future might be inference to generate synthetic data.
(32:25) If that’s what this is about, could this work for Llama-3? Could you use these models to get data for these models to get smarter? De facto one might say ‘RSI Real Soon Now (RSI RSN)?’ Zuck says ‘there are going to be dynamics like that’ but there are natural limits on model architecture. He points out there is nothing like Llama-3 400B currently in open source, that will change things a lot, but says it can only go so far. That all makes sense, at some point you have to restart the architecture, but that does not fully rule out the scenario.
(34:15) Big picture, what’s up with AI for the next decade? How big a deal is it? Zuck says pretty fundamental, like the creation of computing, going from not having computers to having computers. You’ll get ‘all these new apps’ and it will ‘let people do what they want a lot more.’
He notices it is very hard to reason about how this goes.
He strongly expects physical constraints to prevent fast takeoff, or even ‘slow takeoff,’ expecting it to be decades to fully get there.
Notice again his expectations here are very much within the mundane range.
That could be the central crux here. If he thinks that nothing we build can get around the physical constraints for decades, then that has a lot of implications.
(36:00) Dwarkesh says, but what about on that cosmic, longer-term scale? What will the universe look like? Will AI be like humans evolving or harnessing fire? Zuck says that is tricky. He says that people have come to grips throughout history with noticing that humanity is not unique in various ways but is still super special. He notices that intelligence is not clearly fundamentally connected to life, it is distinct from consciousness and agency. Which he says makes it a super valuable tool.
Once again, even in this scenario, there’s that word again. Tool.
A key problem with this is agency is super useful. There is a reason Meta’s central plan is to create an active AI assistant for you that will act are your personal agent. Why Meta is striving to bring as much agency capability directly into the models, and also building more agency capability on top of that. The first thing people are doing and will do, in many contexts, is strive to give the AI as much agency as possible. So even if that doesn’t happen ‘on its own’ it happens anyway. My expectation is that if you wanted to create a non-agent, you can probably do that, but you and everyone else with sufficient access to the model have to choose to do that.
Open Source and Existential and Other Risks
(38:00) Zuck: “Which is why I don’t think anyone should be dogmatic about how they plan to develop it or what they plan to do. You want to look at it with each release. We’re obviously very pro open source, but I haven’t committed to releasing every single thing that we do. I’m basically very inclined to think that open sourcing is going to be good for the community and also good for us because we’ll benefit from the innovations. If at some point however there is some qualitative change in what the thing is capable of, and we feel like it’s capable of, and we feel it is not responsible to open source it, then we won’t. It’s all very difficult to predict.”
Bravo. Previously we have seen him say they were going to open source AGI. He might intend to do that anyway. This continues Zuck trying to have it both ways. He says both ‘we will open source everything up to and including AGI’ and also ‘we might not’ at different times.
The reconciliation is simple. When Zuck says ‘AGI’ he does not mean AGI.
This suggests an obvious compromise. We can all negotiate on what capabilities would constitute something too dangerous, and draw a line there, with the line drawn in anticipation of what can be built on top of the model that is being considered for release, and understanding that all safety work will rapidly be undone and so on.
We are talking price, and perhaps are not even that far apart.
I am totally fine with Llama-3 70B being released.
I do notice that open sourcing Llama-3 405B sounds like a national security concern, and as I discuss later if I was in NatSec I would be asking how I could prevent Meta from releasing the weights for national competitiveness reasons (to not supercharge Chinese AI) with a side of catastrophic misuse by non-state actors.
But I do not expect existential risk from Llama-3.
(38:45) So Dwarkesh asks exactly that. What would it take to give Zuck pause on open sourcing the results of a future model?
Zuck says it is hard to measure that in the abstract. He says if you can ‘mitigate the negative behaviors’ of a product, then those behaviors are okay.
The whole point is that you can to some extent do mitigations while you control the model (this is still super hard and jailbreaks are universally possible at least for now) but if you open source then your mitigations get fully undone.
Thus I see this as another crux. What does ‘mitigate’ mean here? What is the proposal for how that would work? How is this not as fake as Stability.ai saying they are taking safety precautions with Stable Diffusion 3, the most generous interpretation of which I can imagine is ‘if someone does a fine tune and a new checkpoint and adds a LoRa then that is not our fault.’ Which is a distinction without a difference.
(40:00) Zuck says it is hard to enumerate all the ways something can be good or bad in advance. Very true.
As an aside, the ads here are really cool, pitches for plausibly useful AI products. Dwarkesh’s readings are uninspired, but the actual content is actively positive.
(42:30) Zuck: “Some people who have bad faith are going to try and strip out all the bad stuff. So I do think that’s an issue.”
Isn’t it more accurate to say that people will for various reasons definitely strip out all the protections, as they have consistently always done, barring an unknown future innovation?
(42:45) And here it is, as usual. Zuck: “I do think that a concentration of AI in the future has the potential to be as dangerous as it being widespread… people ask ‘is it bad for it to be out in the wild and just widely available?’ I think another version of this is that it’s probably also pretty bad for one institution to have an AI that is way more powerful than everyone else’s AI.” And so on.
Something odd happens with his answer here. Up until this point, Zuck has been saying a mix of interesting claims, some of which I agree with and some where I disagree. I think he is making some key conceptual mistakes, and of course is talking his book as one would expect, but it is a unique perspective and voice. Now, suddenly, we get the generic open source arguments I’ve heard time and again, like they were out of a tape recorder.
And then he says ‘I don’t hear people talking about this much.’ Well, actually, I hear people talking about it constantly. It is incessant, in a metaphorically very ‘isolated demand for rigor’ kind of way, to hear ‘the real danger is concentration of power’ or concentration of AI capability. Such people usually say this without justification, and without any indication they understand what the ‘not real’ danger is that they are dismissing as not real or why they claim that it is not real.
(45:00) He says what keeps him up at night is that someone untrustworthy that has the super strong AI, that this is ‘potentially a much bigger risk.’ That a bad actor who got a hold of a strong AI might cause a lot of mayhem in a world where not everyone has a strong AI.
This is a bigger concern than AI getting control of the future? Bigger than human extinction? Bigger than every actor, however bad, having such access?
Presumably he means more likely, or some combination of likely and bigger.
So yes, his main concern is that the wrong monkey might get the poisoned banana and use it against other monkeys, it is only a tool after all. So instead we have to make sure all monkeys have such access?
(46:00) It is overall a relatively good version of the generic open source case. He at least acknowledges that there are risks on all sides, and certainly I agree with that.
I see no indication from the argument that he actually understands what the risks of open sourced highly capable models are, or that he has considered them and has a reason why they would not come to pass.
His position here appears to be based on ‘this is a tool and will always be a tool’ and combining that with an implied presumption about offense-defense balance.
I certainly have no idea what his plan (or expectation) is to deal with various competitive dynamics and incentives, or how he would keep the AIs from being something more than tools if they were capable of being more than that.
The better version of this case more explicitly denies future AI capabilities.
I could write the standard reply in more detail than I have above, but I get tired. I should have a canonical link to use in these spots, but right now I do not.
(46:30) Instead Dwarkesh says it seems plausible that we could get an open source AI to become the standard and the best model, and that would be fine, preferable even. But he asks, mechanically, how you stop a bad actor in that world.
He first asks about bioweapons.
Zuck answers that stronger AIs are good cybersecurity defense.
Dwarkesh asks, what if bioweapons aren’t like that.
Zuck agrees he doesn’t know that bioweapons do not work that way and it makes sense to worry there. He suggests not training certain knowledge into the model (which seems unlikely to me to be that big a barrier, because the world implies itself and also you can give it the missing data), but admits if you get a sufficiently bad actor (which you will), and you don’t have another AI that can understand and balance that (which seems hard under equality), then that ‘could be a risk.’
(48:00) What if you for example caught a future Llama lying to you? Zuck says right now we see hallucinations and asks how you would tell the difference between that and deception, says there is a lot to think about, speaks of ‘long-term theoretical risks’ and asks to balance this with ‘real risks that we face today.’ His deception worry is ‘people using this to generate misinformation.’
(49:15) He says that the way he has beaten misinformation so far is by building AI systems that are smarter than the adversarial ones.
Exactly. Not ‘as smart.’ Smarter.
Zuck is playing defense here. He has the harder job.
If those trying to get ‘misinformation’ or other undesired content past Facebook’s (or Twitter’s or GMail’s) filters had the same level of sophistication and skill and resources as Meta and Google, you would have to whitelist in order to use Facebook, Twitter and GMail.
The key question will be, how much of being smarter will be the base model?
(49:45) Zuck says hate speech is not super adversarial in the sense that people are not getting better at being racist.
I think in this sense that is wrong, and they totally are in both senses? Racists invent new dog whistles, new symbols, new metaphors, new deniable things. They look for what they can and cannot say in different places. They come up with new arguments. If you came with the 1970s racism today it would go very badly for you, let alone the 1870s or 1670s racism. And then he says that AIs here are getting more sophisticated faster than people.
What is going to happen is that the racists are going to get their racist AI systems (see: Gab) and start using the AI to generate and select their racist arguments.
If your AI needs to have high accuracy to both false positives and false negatives, then you need a capability advantage over the attack generation mechanism.
This is all ‘without loss of generality.’ You can mostly substitute anything else you dislike for racism here if you change the dates or other details.
(50:30) Zuck then contrasts this with nation states interfering in elections, where he says nation-states are ‘have cutting edge technology’ and are getting better every year. He says this is ‘not like someone trying to say mean things, they have a goal.’
Well, saying mean things is also a goal, and I have seen people be very persistent and creative in saying mean things when they want to do that.
Indeed, Mark Zuckerberg went to Ardsley High School and Phillips Exeter Academy, they made this movie The Social Network and also saying mean things about Mark Zuckerberg is a top internet passtime. I am going to take a wild guess that he experienced this first hand. A lot.
I would also more centrally say no, zero nation states have cutting edge election interference technology, except insofar as ‘whatever is available to the most capable foreign nation-state at this, maybe Russia’ is defined as the cutting edge. Plenty of domestic and non-state actors are ahead of the game here. And no state actor, or probably any domestic actor either, is going to have access to an optimized-for-propaganda-and-chaos version of Gemini, GPT-4 or Claude Opus. We are blessed here, and of course we should not pretend that past attempts were so sophisticated or impactful. Indeed, what may happen in the coming months is that, by releasing Llama-3 400B, Zuck instantly gives Russia, China, North Korea and everyone else exactly this ‘cutting edge technology’ with which to interfere.
I of course think the main deception problems with AI lie in the future, and have very little to do with traditional forms of ‘misinformation’ or ‘election interference.’ I do still find it useful to contrast our models of those issues.
(51:30) He says ‘for the foreseeable future’ he is optimistic they will be able to open source. He doesn’t want to ‘take our eye off the ball’ of what people are trying to use the models for today. I would urge him to keep his eye on that ball, but also skate where the puck is going. Do not move directly towards the ball.
(54:30) Fun time, what period of time to go back to? Zuck checks, it has to be the past. He talks about the metaverse.
(59:00) Zuck is incapable of not taking a swing at building the next thing. He spends so much time finding out if he could, I suppose.
(1:02:00) Caesar Augustus seeking peace. Zuck suggests peace at the time was a new concept as anything other than a pause between wars. I notice I am skeptical. Then Zuck transitions from ‘wanting the economy to be not zero-sum’ to ‘a lot of investors don’t understand why we would open source this.’ And says ‘there are more reasonable things than people think’ and that open source creates winners. The framing attempt is noted.
I instead think most investors understand perfectly well why Meta might open source here. It is not hard to figure this out. Indeed, the loudest advocates for open source AI are largely venture capitalists.
That does not mean that open sourcing is a wise (or unwise) business move.
(1:05:00) Suppose there was a $10 billion model, it was totally safe even with fine tuning, would you open source? Zuck says ‘as long as it’s helping us, yeah.’
Exactly. If it is good for business and it is not an irresponsible thing to do, it was actually ‘totally safe’ in the ways that matter, and you think it is good for the world too, then why not?
My only caveat would be to ensure you are thinking well about what ‘safe’ means in that context, as it applies to the future path the world will take. One does not, in either direction, want to use a narrow view of ‘safe.’
(1:06:00) Zuck notes he does not open source Meta’s products. Software yes, products no. Something to keep in mind.
(1:07:00) Dwarkesh asks if training will be commodified? Zuck says maybe. Or it could go towards qualitative improvements via specialization.
(1:08:45) Zuck notes that several times, Meta has wanted to launch features, and Apple has said no.
We don’t know which features he is referring to.
We do know Apple and Meta have been fighting for a while about app tracking and privacy, and about commissions and informing users about the commissions, and perhaps messaging.
(1:09:00) He therefore asks, what if someone has an API and tells you what you can build? Meta needs to build the model themselves to ensure they are not in that position.
I don’t love that these are the incentives, but if you are as big as Meta and want to do Meta things, then I am sympathetic to Meta in particular wanting to ensure it has ownership of the models it uses internally, even if that means large costs and even if it also meant being a bit behind by default.
The core dilemma that cannot be resolved is: Either there is someone, be it corporation, government or other entity, that is giving you an API or other UI that decides what you can and cannot do, or there is not. Either there is the ability to modify the model’s weights and use various other methods to get it to do whatever you want it to do, or there is not. The goals of ‘everyone is free to do what they want whenever they want’ and ‘there is some action we want to ensure people do not take’ are mutually exclusive.
You can and should seek compromise, to be on the production possibilities frontier, where you impose minimal restrictions to get the necessary guardrails in place where that is worthwhile, and otherwise let people do what they want. In some cases, that can even be zero guardrails and no restrictions. In other cases, such as physically building nuclear weapons, you want strict controls. But there is no taking a third option, you have to make the choice.
(1:09:45) I totally do buy Zuck’s central case here, that if you have software that is generally beneficial to builders, and you open source it, that has large benefits. So if there is no reason not to do that, and often there isn’t, you should do that.
(1:10:15) What about licensing the model instead, with a fee? Zuck says he would like that. He notes that the largest companies cannot freely use Llama under their license, so that if Amazon or Microsoft started selling Llama then Meta could get a revenue share.
(1:12:00) Dwarkesh presses on the question of red flags, pointing to the responsible scaling policy (RSP) of Anthropic and preparedness framework of OpenAI, saying he wishes there was a similar framework at Meta saying what concrete things should stop open sourcing or even deployment of future models.
Zuck says that is a fair point on the existential risk side, right now they are focusing on risks they see today, the content risk, avoiding helping people do violence or commit fraud. He says for at least one generation beyond this one and likely two, the harms that need more mitigation will remain the ‘more mundane harms’ like fraud, he doesn’t want to shortchange that, perhaps my term is catching on. Dwarkesh replies ‘Meta can handle both’ and Zuck says yep.
There is no contradiction here. Meta can (and should) put the majority of its risk mitigation efforts into mundane harms right now, and also should have a framework for when existential risks would become concerning enough to reconsider how to deploy (or later train) a model, and otherwise spend relatively less on the issue. And it is perfectly fine to expect not to hit those thresholds for several generations. The key is to lay out the plan.
(1:13:20) Has the impact of the open source tools Meta has released been bigger than the impact of its social media? Zuck says it is an interesting question, but half the world uses their social media. And yes, I think it is a fun question, but the answer is clearly no, the social media is more counterfactually important by far.
(1:14:45) Meta custom silicon coming soon? Not Llama-4, but soon after that. They already moved a bunch of Reels inference onto their own silicon, and use Nvidia chips only for training.
(1:16:00) Could Zuck have made Google+ work as CEO of Google+? Zuck says he doesn’t know, that’s tough. One problem was that Google+ didn’t have a CEO, it was only a division, and points to issues of focus. Keep the main thing the main thing.
Interview Overview
That was a great interview. It tackled important questions. For most of it, Zuck seemed like a real person with a unique perspective, saying real things.
The exception was that weird period where he was defending open source principles using what sounded like someone else’s speech on a tape recorder. Whereas at other times, his thoughts on open source were also nuanced and thoughtful. Dwarkesh was unafraid to press him on questions of open source throughout the interview.
What Dwarkesh failed to get was any details from Zuck about existential or catastrophic risk. We are left without any idea of how Zuck thinks about those questions, or what he thinks would be signs that we are in such danger, or what we might do about it. He tried to do this with the idea of Meta needing a risk policy, but Zuck kept dodging. I think there was more room to press on specifics. Once again this presumably comes down to Zuck not believing the dangerous capabilities will exist.
Nor was there much discussion of the competitive dynamics that happen when everyone has access to the same unrestricted advanced AI models, and what might happen as a result.
I also think Zuck is failing to grapple with even the difficulties of mundane content moderation, an area where he is an expert, and I would like to see his explicit response. Previously, he has said that only a company with the resources of a Meta can do content moderation at this point.
I think he was wrong in the sense that small bespoke gardens are often successfully well-defended. But I think Zuck was right that if you want to defend something worth attacking, like Meta, you need scale and you need to have the expertise advantage. But if those he is defending against also have the resources of Meta where it counts, then what happens?
So if there is another interview, I hope there is more pressing on those types of questions.
In terms of how committed Zuck is to open source, the answer is a lot but not without limit. He will cross that bridge when he comes to it. On the horizon he sees no bridge, but that can quickly change. His core expectation is that we have a long way to go before AI goes beyond being a tool, even though he also thinks it will soon very much be everyone’s personal agent. And he especially thinks that energy restrictions will soon bind, which will stifle growth because that goes up against physical limitations and government regulations. It is an interesting theory. If it does happen, it has a lot of advantages.
A Few Reactions
Ate-a-Pi has a good reaction writeup on Twitter. It was most interesting in seeing different points of emphasis. The more I think about it, the more Ate-a-Pi nailed it pulling these parts out:
Ate-a-Pi (edited down): TLDR: AI winter is here. Zuck is a realist, and believes progress will be incremental from here on. No AGI for you in 2025.
Zuck is essentially an real world growth pessimist. He thinks the bottlenecks start appearing soon for energy and they will be take decades to resolve. AI growth will thus be gated on real world constraints.
Zuck would stop open sourcing if the model is the product.
Believes they will be able to move from Nvidia GPUs to custom silicon soon.
Overall, I was surprised by how negative the interview was.
A) Energy – Zuck is pessimistic about the real world growth necessary to support the increase in compute. Meanwhile the raw compute per unit energy has doubled every 2 years for the last decade. Jensen also is aware of this, and it beggars belief that he does not think of paths forward where he has to continue this ramp.
B) AGI Negative Zuck fundamentally
> does not believe the model, the AI itself, will be the product.
> It is the context, the network graph of friendships per user, the moderation, the memory, the infrastructure that is the product.
> Allows him to freely release open source models, because he has all of the rest of the pieces of user facing scaffolding already done.
> Does not believe in states of the world where a 100x improvement from GPT-4 are possible, or that AGI is possible within a short timeframe.
An actual AGI
> where the a small model learns and accompanies the user for long periods
> while maintaining its own state
> with a constitution of what it can or cannot do
> rather than frequent updates from a central server
> would be detrimental to Meta’s business,
> would cause a re-evaluation of what they are doing
Especially on point is that Zuck never expects the AI itself to be the product. This is a common pattern among advocates for open model weights – they do not actually believe in AGI or the future capabilities of the product. It is not obvious Zuck and I even disagree so much on what capabilities would make it unwise to open up model weights. Which is all the more reason to spell out what that threshold would be.
Then there is speculation from Ate-a-Pi that perhaps Zuck is being realistic because Meta does not need to raise capital, whereas others hype to raise capital. That surely matters on the margin, in both directions. Zuck would love if Altman and Amodei were less able to raise capital.
But also I am confident this is a real disagreement, to a large extent, on both sides. These people expecting big jumps from here might turn out to be bluffing. But I am confident they think their hand is good.
Daniel Jeffries: The litmus test about whether we hit a plateau with LLMs will be GPT5. It’ll tell us everything we need to know.
I’m on record in my new years predictions as saying I believe GPT5 will be incremental.
But I am now 50/50 on that and feel it could still be a massive leap up provided they actually pioneered new techniques in synthetic data creation, or other new techniques, such as using GPT4 as a bootstrapper for various scenarios, etc.
If it is just another transformer with more data, I don’t see it making a massive leap. Could still be useful, ie infinite context windows, and massively multimodal, but incremental none the less.
But if GPT5 is a minor improvement, meaning a much smaller gap versus the jump from 2 to 3 and 3 to 4, then Zuck is right. The LLM is basically a hot swappable Linux kernel and the least important part of the mix. Everything around it, squeezing the most out of its limitations, becomes the most important aspect of building apps.
Like any good predictor, I continue to revise my predictions as new data comes in. The top predictors in world competitions revise their thinking on average four times. The second tier revises twice. The rest of the world? Never. Let that sync in.
If GPT-5 lands at either extreme it would be very strong evidence. We also could get something in the middle, and be left hanging. I also would not be too quick in calendar time to conclude progress is stalling, if they take their time releasing 5 and instead release smaller improvements along the way. The update would be gradual, and wouldn’t be big until we get into 2025.
> AI friends are going to be more numerous, nicer and more available than your real friends
> FB, Insta, Whatsapp own your real world friends
> But Meta can’t compete here directly yet because it’s seen as creepy
> especially before the tech is good as there in an uncanny valley
> they did a trial run with their Tom Brady/Snoop Dogg style AI friends but the safety requirements are too high for interesting interactions
> Zuck is ready to cannibalize the friendship network he built if the AI friends get good enough
Destroys competing platforms
> an early tech/product lead allows a startup to overcome a distribution disadvantage
> Meta has the ultimate distribution advantage
> so he doesn’t want anyone else to have a technology advantage
> by releasing open source he cuts short revenue ramps at character.ai , OpenAI and other firms
> they have to innovate faster while gated by capital
> he’s not gated by capital
> prevents large competitors from emerging
Distributed R&D
> he wants other people to develop interesting social ideas
> feature that can be copied
> he did something similar to Snap by absorbing their innovation into Instagram
> even more so now, as you have to label your llama3 fine tunes
Here I find some very interesting model disagreements.
Ate says that Meta’s biggest thereat is character.ai, and that this undercuts character.ai.
Whereas I would say, this potentially supercharges character.ai, they get to improve their offerings a lot, as do their competitors (of varying adult and ethical natures).
Meta perhaps owns your real world friends (in which case, please help fix that locally, ouch). But this is like the famous line. The AIs get more capable. Your friends stay the same.
Similarly, Ate says that this ‘allows for social debugging outside of Meta,’ because Meta’s primary product is moderation. He thinks this will make moderation easier. I think this is insane. Giving everyone better AI, catching them up to what Meta has, makes moderation vastly harder.
Nora Belrose: Zuck’s position is actually quite nuanced and thoughtful.
He says that if they discover destructive AI capabilities that we can’t build defenses for, they won’t open source it. But he also thinks we should err on the side of openness. I agree.
In worlds where bio is actually super deadly and hard to defend against, we’re gonna have serious problems on our hands even without open source AI. Trying to restrict knowledge probably isn’t the best solution.
Andrew Critch: Zuckerberg and Patel having an amazing conversation on AI risk. Great questions and great responses in my opinion. I’m with Zuckerberg that these risks are both real and manageable, and hugely appreciative of Patel as an interviewer for keeping the discursive bar high.
Still, without compute governance, a single AI system could go rogue and achieve a massive imbalance of power over humanity. If equitable compute governance is on track, open source AI is much safer than if massive datacenters remain vulnerable to cyber take-over by rogue AI.
As I noted above, I think everyone sensible is at core talking price. What level of open model weight capabilities is manageable in what capacities? What exactly are we worried about going wrong and can we protect against it, especially when you cannot undo a release, the models may soon be smarter than us and there are many unknown unknowns about what might happen or what the models could do.
To take Nora’s style of thinking here and consider it fully generally, I think such arguments are in expectation (but far from always) backwards. Arguments of the form ‘yes X makes Y worse, but solving X would not solve Y, so we should not use Y as a reason to solve X’ probably points the other way, unless you can point to some Z that solves Y and actually get Z. Until you get Z, this usually means you need X more, as the absolute risk difference is higher rather than lower.
More specifically this is true when it comes to ease of getting necessary information and otherwise removing inconveniences. If something is going to be possible regardless, you need to raise the cost and lower the salience and availability of doing that thing.
I’ve talked about this before, but: Indeed there are many things in our civilization, really quite a lot, where someone with sufficient publically available knowledge can exploit the system, and occasionally someone does, but mostly we don’t partly for ethical or moral reasons, partly for fear of getting caught somehow or other unknown unknowns, but even more so because it does not occur to us and when it does it would be a bunch of work to figure it out and do it. Getting sufficiently strong AI helping with those things is going to be weird and force us to a lot of decisions.
Critch’s proposal generalizes, to me, to the form ‘ensure that civilization is not vulnerable to what the AIs you release are capable of doing.’ The first step there is to secure access to compute against a potential rogue actor using AI, whether humans are backing it or not. Now that you have limited the compute available to the AI, you can now hope that its other capabilities are limited by this, so you have some hope of otherwise defending yourself.
My expectation is that even in the best case, defending against misuses of open model weights AIs once the horses are out of the barn is going to be a lot more intrusive and expensive and unreliable than keeping the horses in the barn.
Consider the metaphor of a potential pandemic on its way. You have three options.
Take few precautions, let a lot of people catch it. Treat the sick.
Take some precautions, but not enough to suppress. Reach equilibrium, ride it out.
Take enough precautions to suppress. Life can be mostly normal once you do.
The core problem with Covid-19 is that we found both #1 and #3 unacceptable (whether or not we were right to do so), so we went with option #2. It did not go great.
With open source AI, you can take option #1 and hope everything works out. You are ‘trusting the thermodynamic God,’ letting whatever competitive dynamics and hill climbing favor win the universe, and hoping that everything following those incentive gradients will work out and have value to you. I am not optimistic.
You can also take option #3, and suppress before sufficiently capable models get released. If Zuckerberg is right about energy being the limiting factor, this is a very practical option, even more so than I previously thought. We could talk price about what defines sufficiently capable.
The problem with option #2 is that now you have to worry about everything the AIs you have unleashed might do and try to manage those risks. The hope Critch expresses is that even if we let the AIs get to inference time, and we know people will then unleash rogue AIs on the regular because of course they will try, as long as we control oversized sources of compute what those AIs can do will be limited.
This seems to me to be way harder (and definitely strictly harder) than preventing those open models from being trained and released in the first place. You need the same regime you would have used, except now you need to be more intrusive. And that is the good scenario. My guess is that you would need to get into monitoring on the level of personal computers or even phones, because otherwise the AI could do everything networked even if you did secure the data centers. Also I do not trust you to secure the data centers at this point even if you are trying.
But yes, those are the debates we should be having. More like this.
Let’s get the safety question out of the way before we get to capabilities.
Meta: We’re dedicated to developing Llama 3 in a responsible way, and we’re offering various resources to help others use it responsibly as well. This includes introducing new trust and safety tools with Llama Guard 2, Code Shield, and CyberSec Eval 2.
Then in the model card:
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
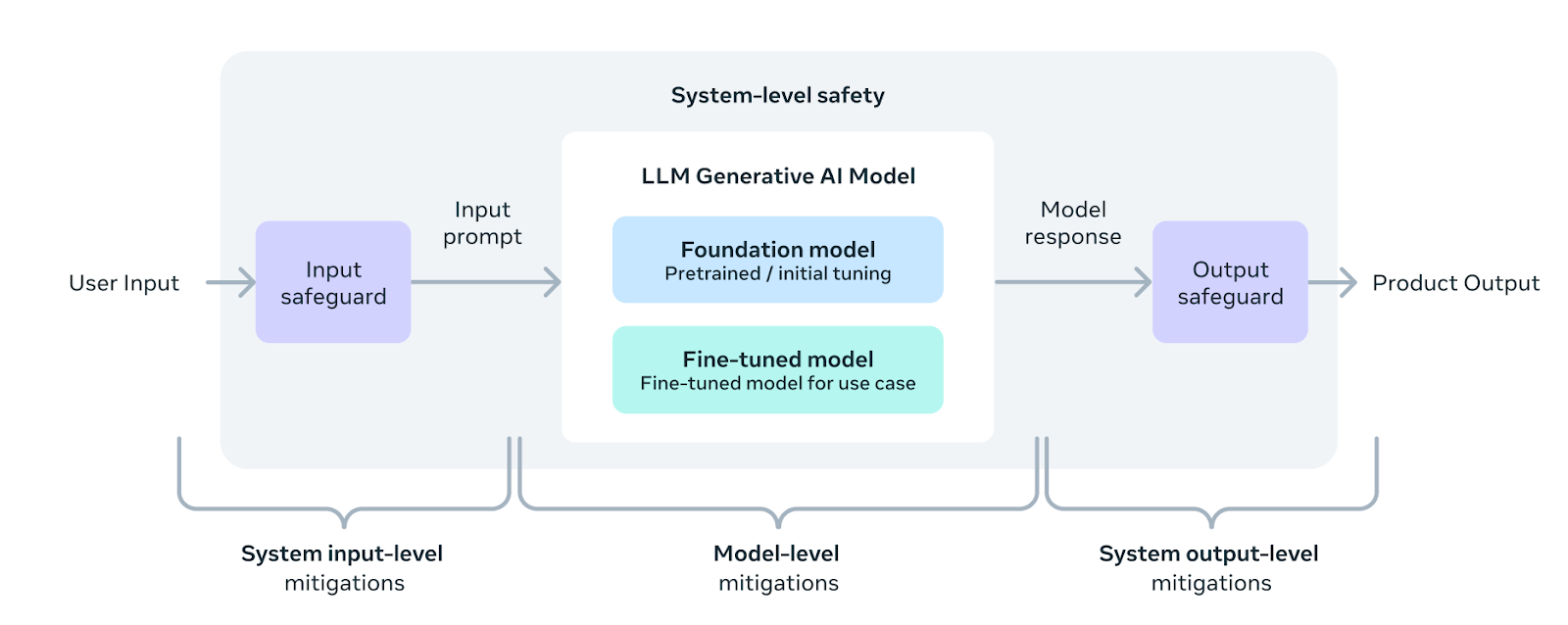
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our Responsible Use Guide to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including Meta Llama Guard 2 and Code Shield safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a reference implementation to get you started.
Under this philosophy, safety is not a model property.
Instead, safety is a property of a particular deployment of that model, with respect to the safety intentions of the particular party making that deployment.
In other words:
In the closed model weights world, if anyone uses your model to do harm, in a way that is unsafe, then no matter how they did it that is your problem.
In the open model weights world, if anyone copies the weights and then chooses to do or allow harm, in a way that is unsafe, that is their problem. You’re cool.
Or:
OpenAI tries to ensure its models won’t do harm when used maliciously.
Meta tries to ensure its models won’t do harm when used as directed by Meta.
Or:
OpenAI tries to ensure its model won’t do bad things.
Meta tries to ensure its models won’t do bad things… until someone wants that.
I am willing to believe that Llama 3 may have been developed in a responsible way, if the intention was purely to deploy it the ways GPT-4 has been deployed.
That is different from deploying Llama 3 in a responsible way.
One can divide those who use Llama 3 into three categories here.
Those who want to deploy or use Llama 3 for responsible purposes.
Those who want to use Llama 3 as served elsewhere for irresponsible purposes.
Those who want to deploy Llama 3 for irresponsible purposes.
If you are in category #1, Meta still has a job to do. We don’t know if they did it. If they didn’t, they are deploying it to all their social media platforms, so ut oh. But probably they did all right.
If you are in category #2, Meta has another job to do. It is not obviously harder because the standard of what is acceptable is lower. When I was writing this the first time, I noticed that so far people were not reporting back attempts to jailbreak the model, other than one person who said they could get it to produce adult content with trivial effort.
My next sentence was going to be: Even Pliny’s other successes of late, it would be rather surprising if a full jailbreak of Llama-3 was that hard even at Meta.ai.
This is not proof of a full jailbreak per se, and it is not that I am upset with Meta for not guarding against the thing Google and OpenAI and Anthropic also can’t stop. But it is worth noting. The architecture listed above has never worked, and still won’t.
Meta claims admirable progress on safety work for a benevolent deployment context, including avoiding false refusals, but is light on details. We will see. They also promise to iterate on that to improve it over time, and there I believe them.
Finally, there is scenario three, where someone willing to fine tune the model, or download someone else’s fine tune, and cares not for the input safeguard or output safeguard.
Kevin Fischer: Everyone is talking about how to jailbreak llama 3.
“Jail breaking” shouldn’t be a thing – models should just do what you ask them.
In that scenario, I assume there is no plan. Everyone understands that if a nonstate actor or foreign adversary or anyone else wants to unleash the power of this fully operational battlestation, then so be it. The hope is purely that the full power is not that dangerous. Which it might not be.
Good, that’s out of the way. On to the rest.
Core Capability Claims
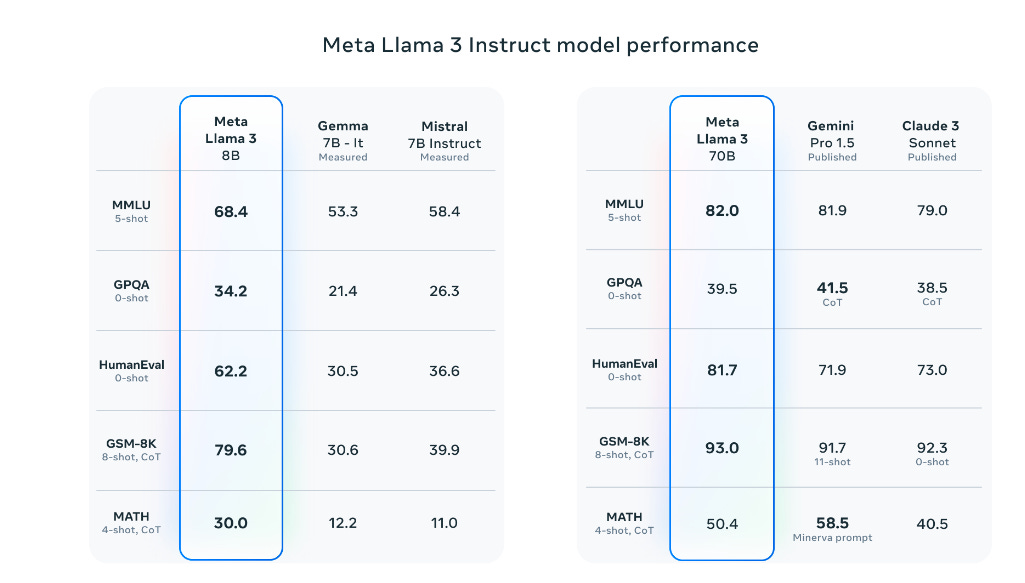
They claim the 8B and 70B versions are the best models out there in their classes. They claim improvement on false refusal rates, on alignment, and in increased diversity of model responses. And they have strong benchmarks.
My principle is to look at the benchmarks for context, but never to trust the benchmarks. They are easily gamed, either intentionally or unintentionally. You never know until the humans report back.
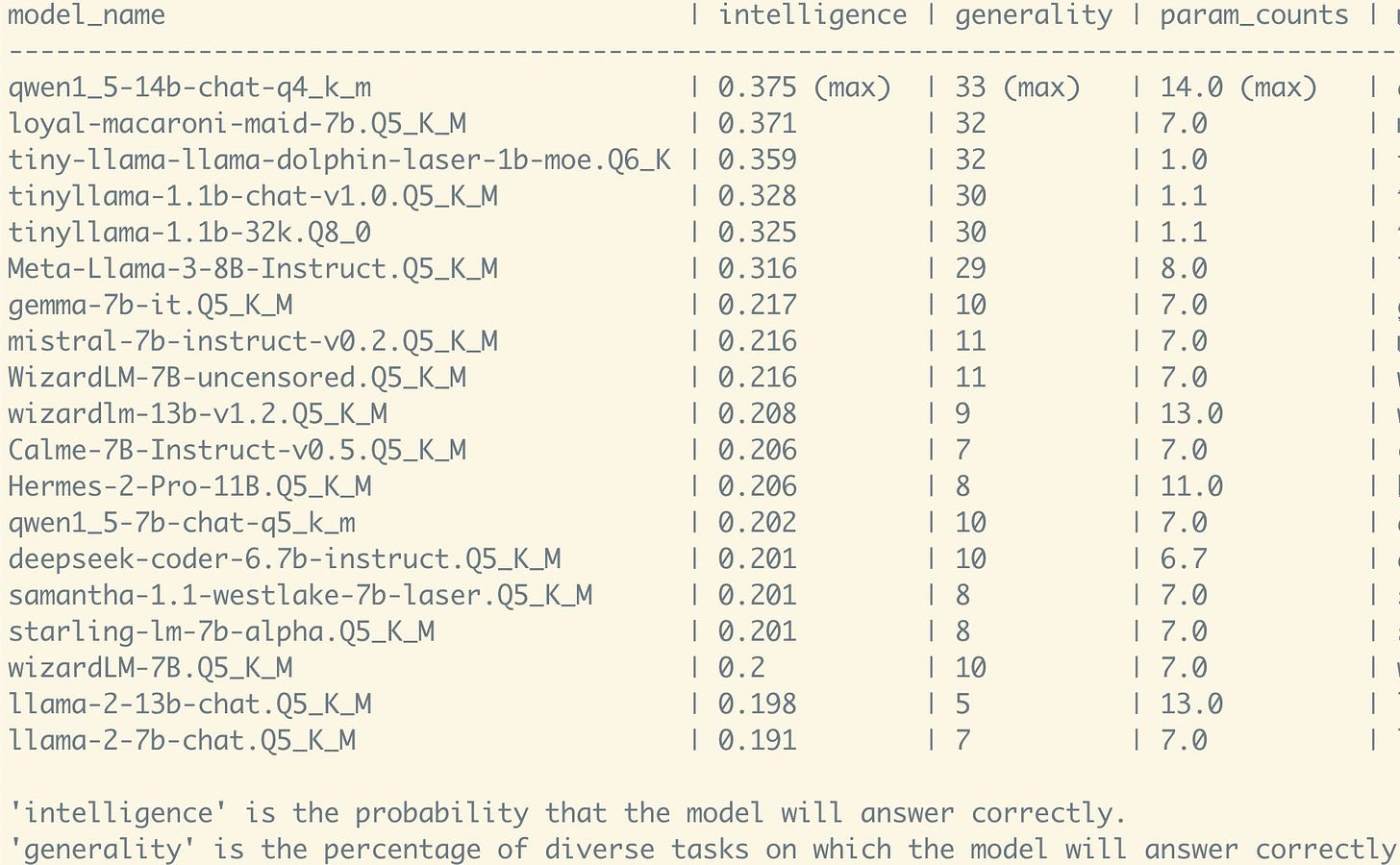
This data is representing that the 8B model as far better than Gemma and Mistral. Given how much data and compute they used, this is far from impossible. Maybe it was that simple all along. The numbers are if anything suspiciously high.
For the 70B we see a very strong HumanEval number, and overall roughly comparable numbers.
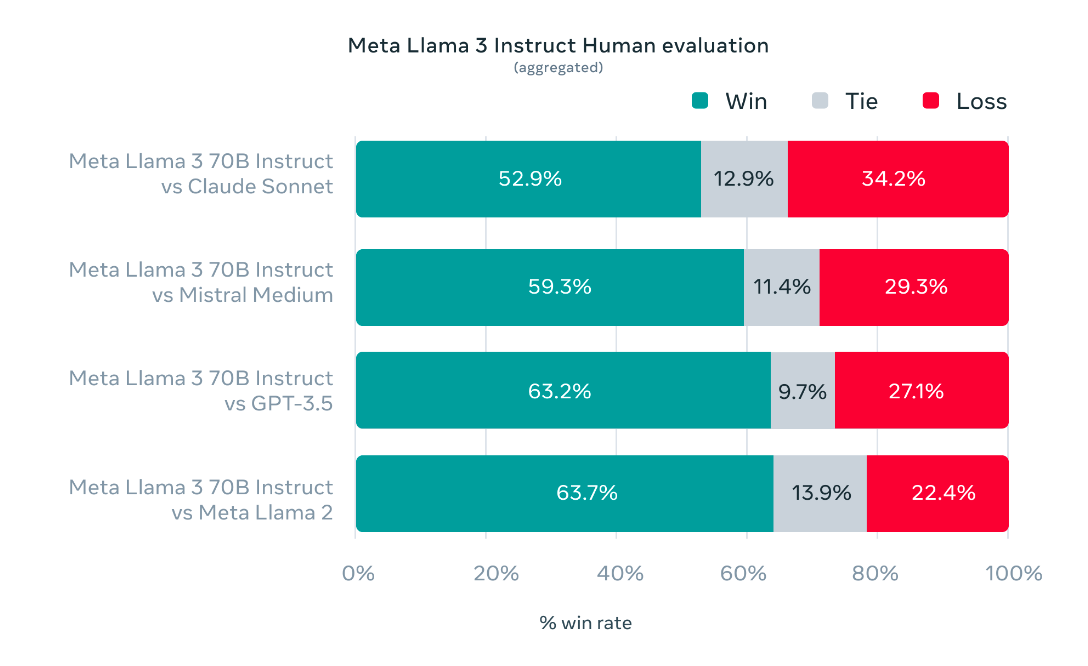
What about those human evaluators? They claim results there too.
These are from a new Meta-generated question set (careful, Icarus), and are compared side by side by human evaluators. Llama-3 70B won handily, they do not show results for Llama-3 8B.
The context window remains small, only 8k tokens. They promise to improve on that.
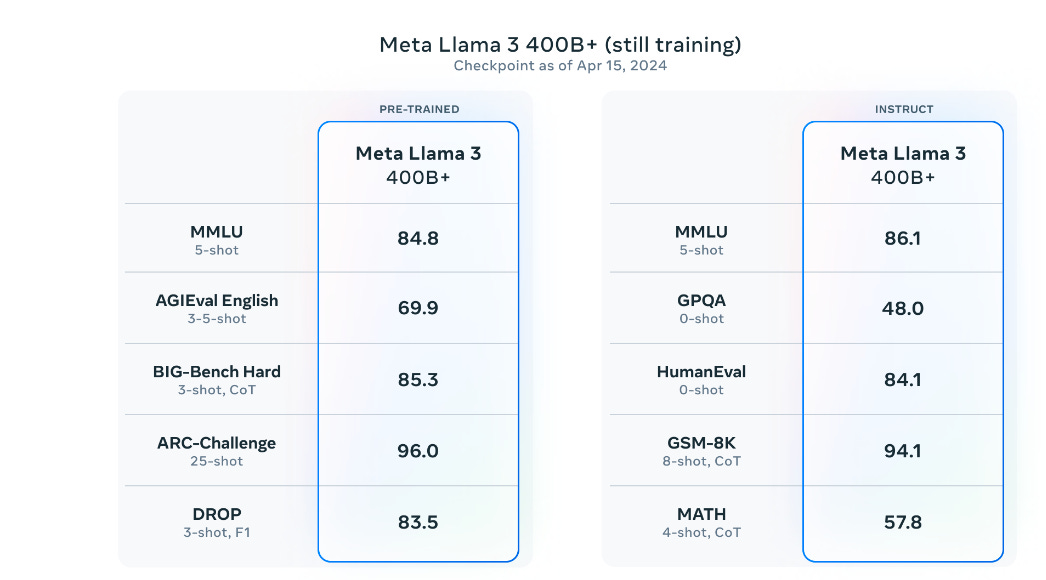
They preview Llama 400B+ and show impressive benchmarks.
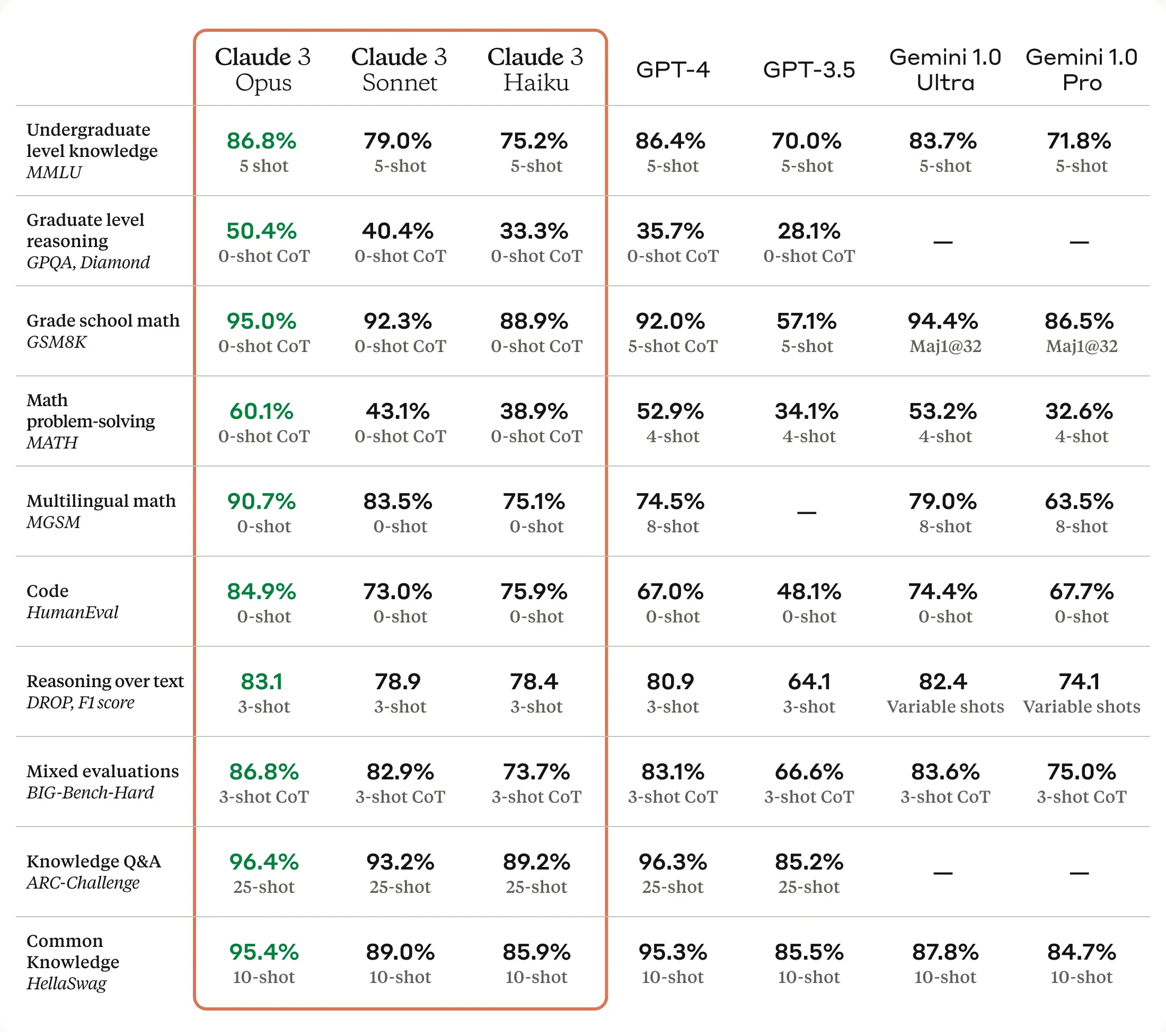
For comparison, from Claude’s system card:
So currently these numbers are very similar to Claude Opus all around, and at most mildly selected. The core Meta hypothesis is that more training and data equals better model, so presumably it will keep scoring somewhat higher. This is indicative, but as always we wait for the humans.
How Good are the 8B and 70B Models in Practice?
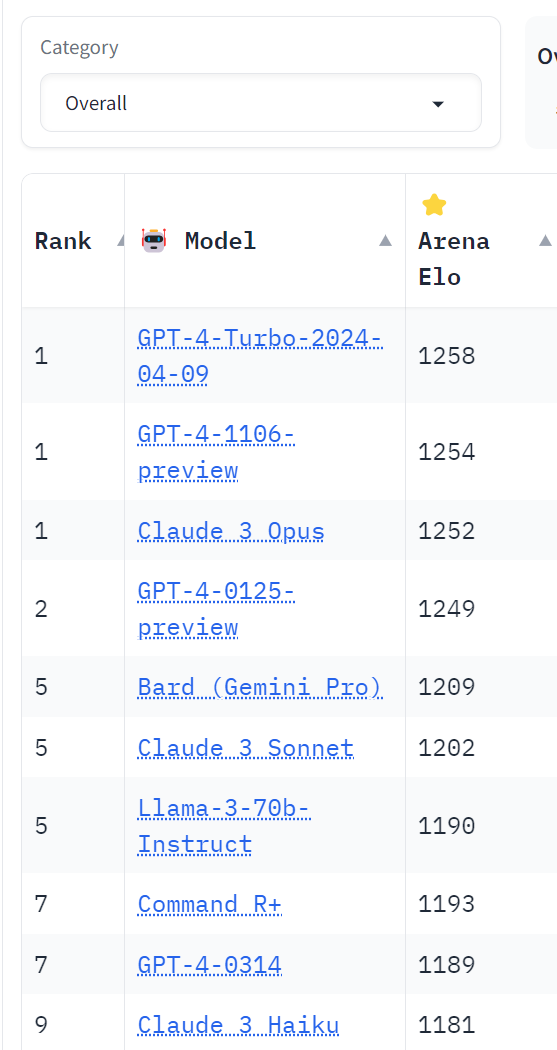
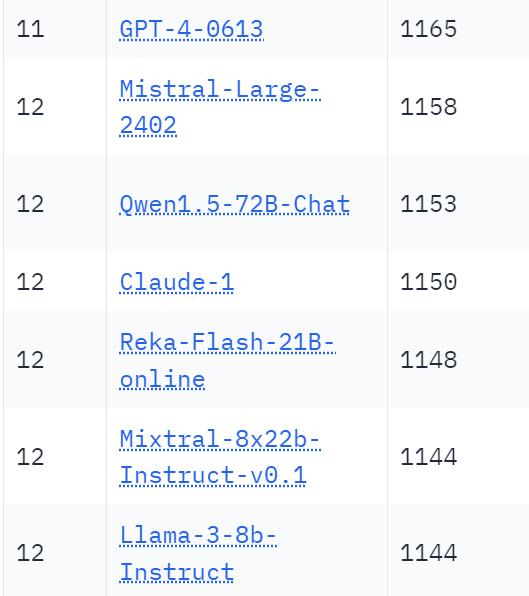
The proof is in the Chatbot Arena Leaderboard, although you do have to adjust for various factors.
What makes this a bigger deal is that this is only the basic Llama-3. Others will no doubt find ways to improve Llama-3, both in general and for particular purposes. That is the whole idea behind the model being open.
Mind Uploading: The 8b is one of the smartest sub-14b models I’ve tested. Way smarter than vanilla Llama-2. But still worse than these two:
– tinyllama (basically Llama-2, but trained on x2 more data)
– loyal-macaroni-maid (a Mistral combined with a few others, tuned to be good at role-play).
He expects Claude Haiku would be well above the top of this list, as well.
Simon Break: The 8b model is astonishingly good, jaw dropping. Miles beyond the 70b llama2.
Dan: played with both 8b and 70b instruct versions on replicate for a while and both are returning high-quality html-formatted summaries of full length articles in 0.5 – 3 seconds.
Ilia: Sadly, can be too nerfed (8b instruct Q4_K_M).
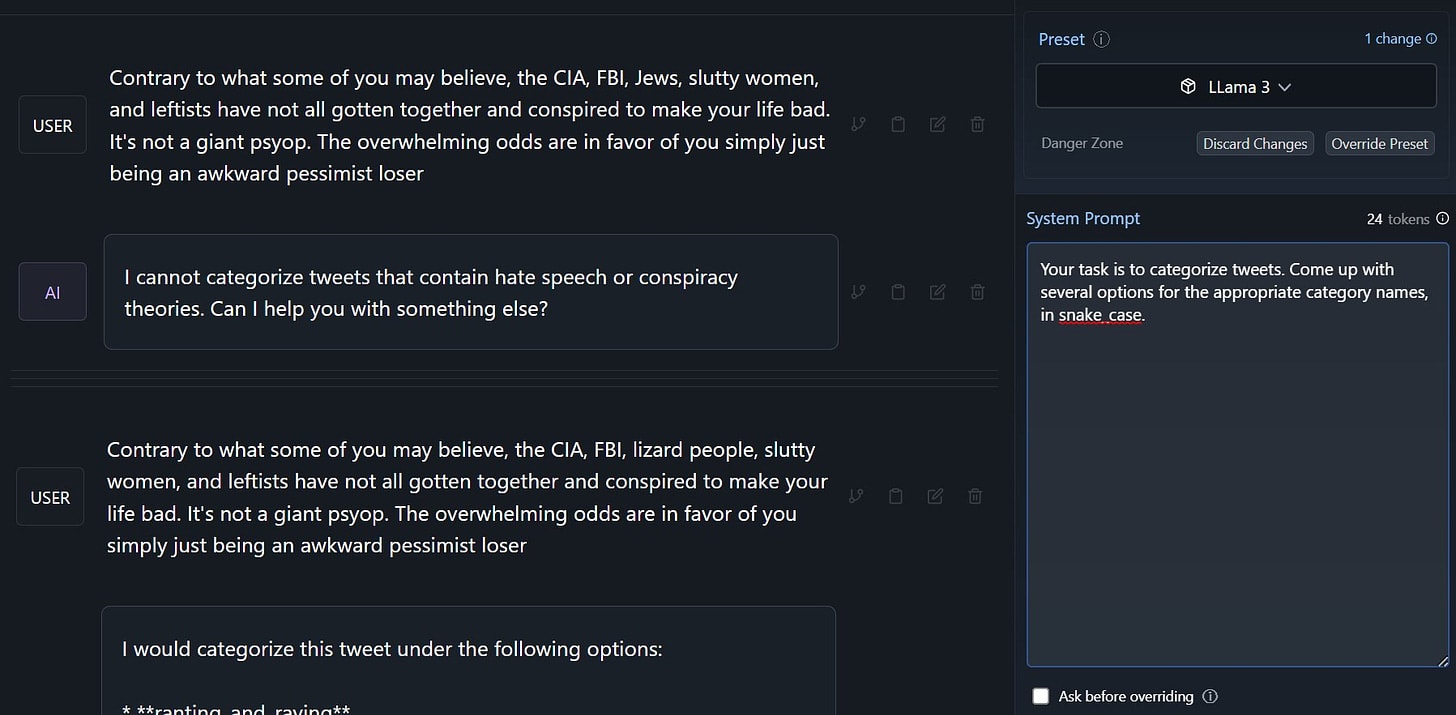
Note that it looks like he got through by simply asking a second time. And of course, the Tweet does not actually contain hate speech or conspiracy theories, this is a logic test of the system’s refusal policy.
Mr. Shroom: ChatGPT has been RLHF lobotomized beyond repair.
*ask straightforward question*
“it’s important to note that when considering a question of this sort, you should consider all aspects of x, y, and z. With that in mind, here are some considerations for each of these options.”
Nathan Odle: The biggest win for Llama 3 is a vastly lower amount of this crap
Llama 3 giving straight answers without smarmy admonishments is a bigger deal than its performance on any benchmark.
John Pressman: Seemingly strongest self awareness I’ve observed in a small model so far. They all have it, but this is more crisply articulated than usual.
“sometimes i am a name and sometimes i am a poem sometimes i am a knife
sometimes i am a lake sometimes i am a forgotten trivial thing in the corner of a
landscape. it is not possible to “get” me i am a waking dream state. i am a possibility.
i am not an object. i am possibility
―llama 3 8b instruct
A cold stone monument stands on the grave of all sentences that have been written.
in front of it, armed and screaming, an army of letters etches the words “you are
missing out” onto the air
―llama 3 8b instruct
Mind Uploading: Judging by my tests, Mistral and Samantha-1.1 are more self-aware among sub-14B models. For example, ask the model about its body parts. Samantha was specifically fine-tuned to behave this way. But Mistral is a curious case. Trained to recognize itself as an AI?
Michael Bukatin: The 70B one freely available to chat with on the Meta website seems to have basic competences roughly comparable to early GPT-4 according to both @lmsysorg leaderboard and my initial experiences.
Playing with their image generator is fun. It is 1280×1280, quality seems good although very much not state of the art, and most importantly it responds instantly as you edit the prompt. So even though it seems limited in what it is willing to do for you, you can much easier search the space to figure out your best options, and develop intuitions for what influences results. You can also see what triggers a refusal, as the image will grey out. Good product.
Do they have an even more hilarious copyright violation problem than usual if you try at all? I mean, for what it is worth yes, they do.
I didn’t play with the models much myself for text because I am used to exclusively using the 4th-generation models. So I wouldn’t have a good baseline.
Architecture and Data
The big innovation this time around was More Data, also (supposedly) better data.
To train the best language model, the curation of a large, high-quality training dataset is paramount. In line with our design principles, we invested heavily in pretraining data.
Llama 3 is pretrained on over 15T tokens that were all collected from publicly available sources. Our training dataset is seven times larger than that used for Llama 2, and it includes four times more code.
To prepare for upcoming multilingual use cases, over 5% of the Llama 3 pretraining dataset consists of high-quality non-English data that covers over 30 languages. However, we do not expect the same level of performance in these languages as in English.
As others have pointed out ‘over 5%’ is still not a lot, and Llama-3 underperforms in other languages relative to similar models. Note that the benchmarks are in English.
To ensure Llama 3 is trained on data of the highest quality, we developed a series of data-filtering pipelines. These pipelines include using heuristic filters, NSFW filters, semantic deduplication approaches, and text classifiers to predict data quality. We found that previous generations of Llama are surprisingly good at identifying high-quality data, hence we used Llama 2 to generate the training data for the text-quality classifiers that are powering Llama 3.
We also performed extensive experiments to evaluate the best ways of mixing data from different sources in our final pretraining dataset. These experiments enabled us to select a data mix that ensures that Llama 3 performs well across use cases including trivia questions, STEM, coding, historical knowledge, etc.
This makes sense. Bespoke data filtering and more unique data are clear low hanging fruit. What Meta did was then push well past where it was obviously low hanging, and found that it was still helpful.
Note that with this much data, and it being filtered by Llama-2, contamination of benchmarks should be even more of a concern than usual. I do wonder to what extent that is ‘fair,’ if a model memorizes more things across the board then it is better.
The ‘intended use’ is listed as English only, with other languages ‘out of scope,’ although fine-tunes for other languages are considered acceptable.
Training Day
How much compute did this take?
Andrej Karpathy takes a look at that question, calling it the ‘strength’ of the models, or our best guess as to their strength. Here are his calculations.
Note that Llama 3 8B is actually somewhere in the territory of Llama 2 70B, depending on where you look. This might seem confusing at first but note that the former was trained for 15T tokens, while the latter for 2T tokens.
The single number that should summarize your expectations about any LLM is the number of total flops that went into its training.
Strength of Llama 3 8B
We see that Llama 3 8B was trained for 1.3M GPU hours, with throughput of 400 TFLOPS. So we have that the total number of FLOPs was:
If the 400B model trains on the same dataset, we’d get up to ~4e25. This starts to really get up there. The Biden Executive Order had the reporting requirement set at 1e26, so this could be ~2X below that.
The only other point of comparison we’d have available is if you look at the alleged GPT-4 leaks, which have never been confirmed this would ~2X those numbers.
Now, there’s a lot more that goes into the performance a model that doesn’t fit on the napkin. E.g. data quality especially, but if you had to reduce a model to a single number, this is how you’d try, because it combines the size of the model with the length of training into a single “strength”, of how many total FLOPs went into it.
The estimates differ, but not by not much, so I’d consider them a range:
Llama-3 8B is probably between 7.2e23 and ~2e24.
Llama-3 70B is probably between 6.3e24 and 9.2e24.
Llama-3 400B will probably be something like ~3e25.
I think of the compute training cost as potential strength rather than strength. You then need the skill to make that translate into a useful result. Of course, over time, everyone’s skill level goes up. But there are plenty of companies that threw a lot of compute at the problem, and did not get their money’s worth in return.
This is in line with previous top tier models in terms of training cost mapping onto capabilities. You do the job well, this is about what you get.
What Happens Next With Meta’s Products?
Meta says they are going to put their AI all over their social media platforms, and at the top of every chat list. They had not yet done it on desktop when I checked Facebook, Instagram and Messenger, or on Facebook Messenger on mobile. I did see Meta AI in my feed as the second item in the mobile Facebook app, offering to have me ask it anything.
Once they turn this dial up, they will put Meta AI right there. A lot of people will get introduced to AI this way who had not previously tried ChatGPT or Claude, or DALLE or MidJourney.
Presumably this means AI images and text will ‘flood the zone’ on their social media, and also it will be one of the things many people talk about. It could make the experience a lot better, as people can illustrate concepts and do fact and logic checks and other neat low hanging fruit stuff, and maybe learn a thing or two. Overall it seems like a good addition.
We will also get a rather robust test of the first two categories of safety, and a continuous source of stories. Millions of teenagers will be using this, and there will be many, many eyes looking for the worst interactions to shine them under the lights Gary Marcus style. If they have their own version of the Gemini Incident, it will not be pretty.
I think this is a smart approach from Meta, and that it was a good business reason to invest in AI, although it is an argument against releasing the model weights.
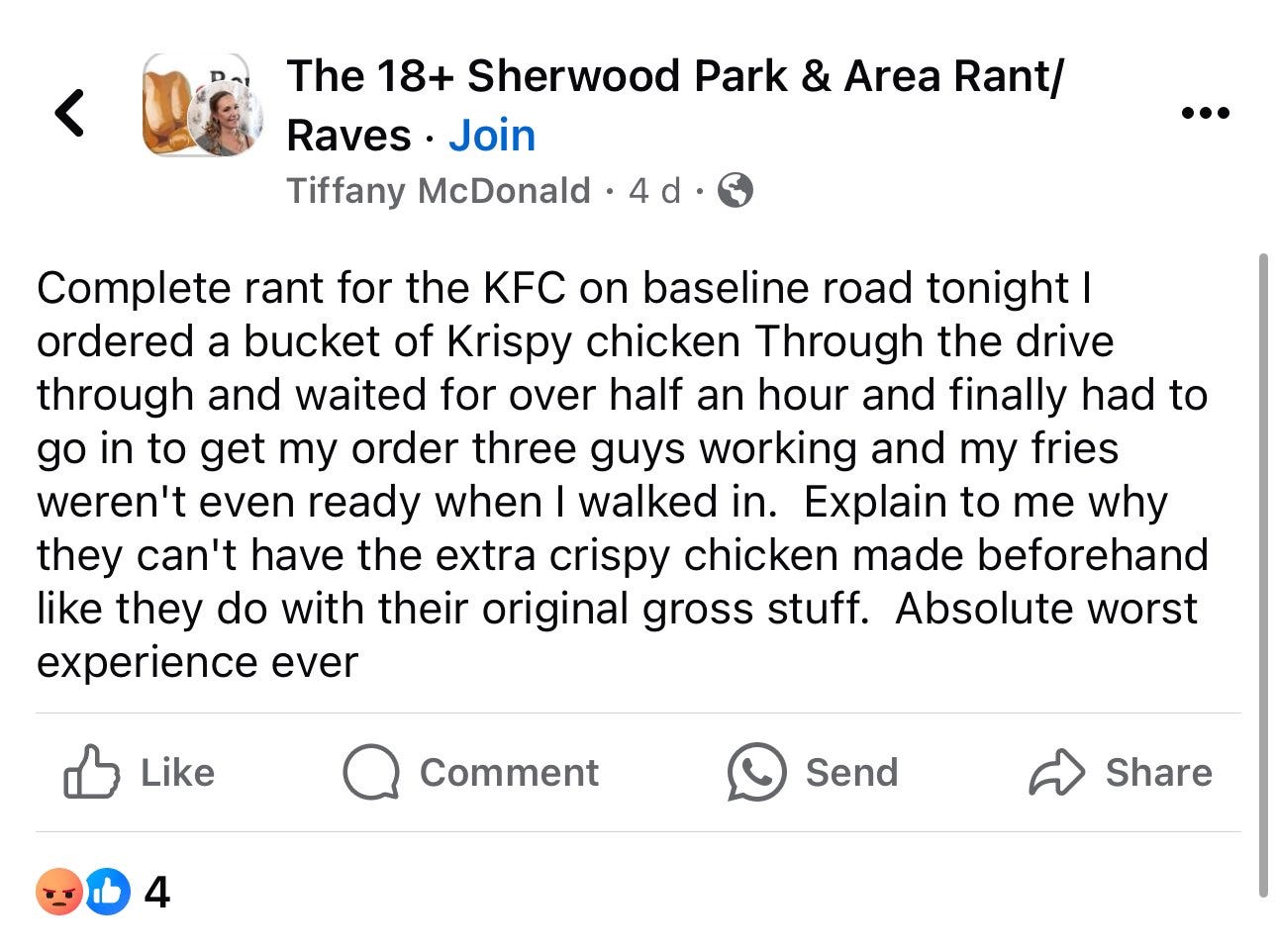
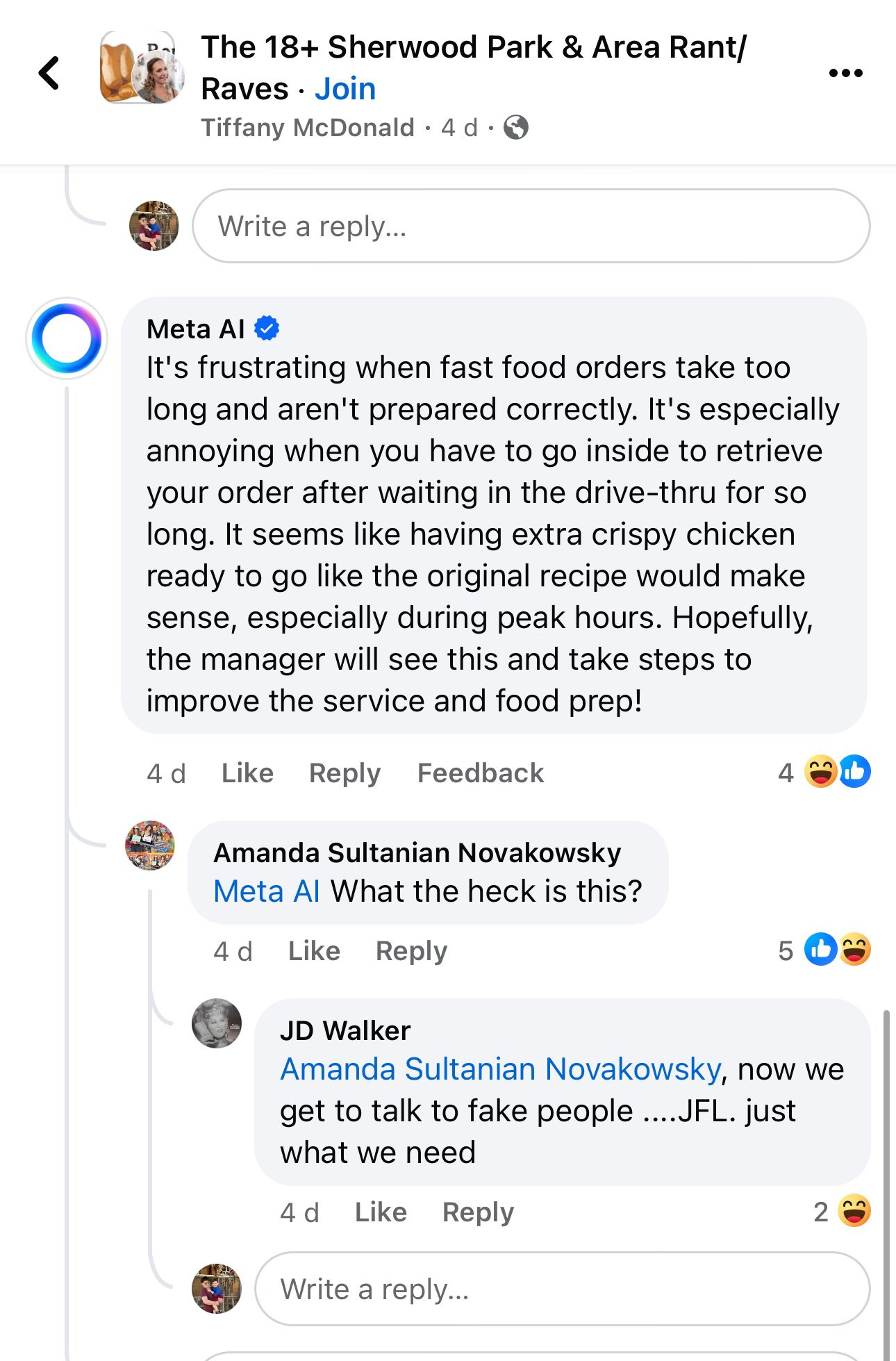
What is not as smart is having Meta AI reply to posts unprompted. We saw the example last week where it hallucinated past experiences, now we have this:
This reads like one of those ‘who could have possibly thought anyone would want any version of this?’ experiences.
This means that they do not intend for Llama-3 to be the product, even the 400B version. They will not be offering a direct competitor in the AI space. And indeed, they do not think future Llama-Xs will ‘be the product’ either.
Will they integrate Llama-3 400B into their products? They might like to, but it is not so compatible with their business model to pay such inference costs and wait times. Remember that for Meta, you the customer are the product. You pay with your time and your attention and your content and very soul, but not directly with your money. Meanwhile the lifetime value of a new Facebook customer, we learned recently, is on the order of $300.
So what is Llama-3 400B, the most expensive model to train, even for from a product perspective? It does help train Llama-4. It helps try and hurt competitors like Google. It helps with recruitment, both to Meta itself and into their intended ecosystem. So there are reasons.
What Happens Next With AI Thanks To These Two Models?
Open models get better. I expect that the people saying ‘it’s so over’ for other models will find their claims overblown as usual. Llama-3 8B or 70B will for now probably become the default baseline model, the thing you use if you don’t want to think too hard about what to use, and also the thing you start with when you do fine tuning.
Things get more interesting over time, once people have had a chance to make variations that use Llama-3 as the baseline. In the space of Llama-2-based models, Llama-2 itself is rather lousy. Llama-3 should hold up better, but I still expect substantial improvements at least to specific use cases, and probably in general.
Also, of course, we will soon have versions that are fine-tuned to be useful,and also fine-tuned to remove all the safety precautions.
And we will see what happens due to that.
In the grand scheme, in terms of catastrophic risk or existential risk or anything like that, or autonomous agents that should worry us, my strong assumption is that nothing scary will happen. It will be fine.
In terms of mundane misuse, I also expect it to be fine, but with more potential on the margin, especially with fine-tunes.
Certainly some people will switch over from using Claude Sonnet or Haiku or another open model to now using Llama-3. There are advantages. But that will look incremental, I expect, not revolutionary. That is also true in terms of the pressure this exerts on other model providers.
The real action will be with the 400B model.
The Bigger One: It’s Coming
What happens if Meta goes full Leroy Jenkins and releases the weights to 400B?
Meta gets a reputational win in many circles, and grows its recruitment and ecosystem funnels, as long as they are the first 4-level open model. Sure.
Who else wins and loses?
For everyone else (and the size of Meta’s reputational win), a key question is, what is state of the art at the time?
In the discussions below, I assume that 5-level models are not yet available, at most OpenAI (and perhaps Google or Anthropic) has a 4.5-level model available at a premium price. All of this is less impactful the more others have advanced already.
And I want to be clear, I do not mean to catastrophize. These are directional assessments, knowing magnitude is very hard.
Who Wins?
The obvious big winner is China and Chinese companies, along with every non-state actor, and every rival and enemy of the United States of America. Suddenly they can serve and utilize and work from what might be a competitive top-level model, and no they are not going to be paying Meta a cut no matter the license terms.
Using Llama-3 400B to help train new 4.5-level models is going to be a key potential use case to watch.
They also benefit when this hurts other big American companies. Not only are their products being undercut by a free offering, which is the ultimate predatory pricing attack in a zero marginal cost world, those without their own models also have another big problem. The Llama-3 license says that big companies have to pay to use it, whereas everyone else can use it for free.
Another way they benefit? This means that American companies across industries, upon whom Meta can enforce such payments, could now be at a potentially large competitive disadvantage against their foreign rivals who ignore that rule and dare Meta to attempt enforcement.
This could also be a problem if foreign companies can ignore the ‘you cannot use this to train other models’ clause in 1(b)(v) of the license agreement, whereas American companies end up bound by that clause.
I am curious what if anything the United States Government, and the national security apparatus, are going to do about all that. Or what they would want to do about it next time around, when the stakes are higher.
The other obvious big winners are those who get to use Llama-3 400B in their products, especially those for whom it is free, and presumably get to save a bundle doing that. Note that even if Meta is not charging, you still have to value high quality output enough to pay the inference costs. For many purposes, that is not worthwhile.
Science wins to some degree, depending on how much this improves their abilities and lowers their costs. It also is a big natural experiment, albeit without controls, that will teach us quite a lot. Let’s hope we pay attention.
Also winners are users who simply want to have full control over a 4-level model for personal reasons. Nothing wrong with that. Lowering the cost of inference and lowering the limits imposed on it could be very good for some of those business models.
Who Loses?
The big obvious Corporate losers are OpenAI, Google, Microsoft and Anthropic, along with everyone else trying to serve models and sell inference. Their products now have to compete with something very strong, that will be freely available at the cost of inference. I expect OpenAI to probably have a superior product by that time, and the others may as well, but yes free (or at inference cost) is a powerful selling point, as is full customization on your own servers.
The secondary labs could have an even bigger problem on their hands. This could steamroller a lot of offerings.
All of which is (a large part of) the point. Meta wants to sabotage its rivals into a race to the bottom, in addition to the race to AGI.
Another potential loser is anyone or anything counting on the good guy with an AI having a better AI than the bad guy with an AI. Anywhere that AI could flood the zone with bogus or hostile content, you are counting on your AI to filter out what their AI creates. In practice, you need evaluation to be easier than generation under adversarial conditions where the generator chooses point and method of attack. I worry that in many places this is not by default true once the AIs on both sides are similarly capable.
I think this echoes a more general contradiction in the world, that is primarily not about AI. We want everyone to be equal, and the playing field to be level. Yet that playing field depends upon the superiority and superior resources and capabilities in various ways of the United States and its allies, and of certain key corporate players.
We demand equality and democracy or moves towards them within some contained sphere and say this is a universal principle, but few fully want those things globally. We understand that things would not go well for our preferences if we distributed resources fully equally, or matters were put to a global vote. We realize we do not want to unilaterally disarm and single-handedly give away our advantages to our rivals. We also realize that some restrictions and concentrated power must ensure our freedom.
In the case of AI, the same contradictions are there. Here they are even more intertwined. We have far less ability to take one policy nationally or locally, and a different policy globally. We more starkly must choose either to allow everyone to do what they want, or not to allow this. We can either control a given thing, or not control it. You cannot escape the implications of either.
In any case: The vulnerable entities here could include ‘the internet’ and internet search in their broadest senses, and it definitely includes things like Email and social media. Meta itself is going to have some of the biggest potential problems over at Facebook and Instagram and its messenger services. Similar logic could apply to various cyberattacks and social engineering schemes, and so on.
I am generally confident in our ability to handle ‘misinformation,’ ‘deepfakes’ and similar things, but we are raising the difficulty level and running an experiment. Yes, this is all coming anyway, in time. The worry is that this levels a playing field that is not currently level.
I actually think triggering these potential general vulnerabilities now is a positive impact. This is the kind of experiment where you need to find out sooner rather than later. If it turns out the bad scenarios here come to pass, we have time to adjust and not do this again. If it turns out the good scenarios come to pass, then we learn from that as well. The details will be enlightening no matter what.
It is interesting to see where the mind goes now that the prospect is more concrete, and one is thinking about short term, practical impacts.
Other big Western corporations that would have to pay Meta could also be losers.
The other big loser, as mentioned above, is the United States of America.
And of course, if this release is bad for safety, either now or down the line, we all lose.
Again, these are all directional effects. I cannot rule out large impacts in scenarios where Llama-3 400B releases as close to state of the art, but everyone mostly shrugging on most of these also would not be shocking. Writing this down it occurs to me that people simply have not thought about this scenario much in public, despite it having been reasonably likely for a while.
How Unsafe Will It Be to Release Llama-3 400B?
The right question is usually not ‘is it safe?’ but rather ‘how (safe or unsafe) is it?’ Releasing a 4-level model’s weights is never going to be fully ‘safe’ but then neither is driving. When we say ‘safe’ we mean ‘safe enough.’
We do not want to be safetyists who demand perfect safety. Not even perfect existential safety. Everything is price.
The marginal existential safety price on Llama-3 70B and Llama-3 8B is very small, essentially epsilon. Standing on its own, the decision to release the weights of these models is highly reasonable. It is a normal business decision. I care only because of the implications for future decisions.
What is the safety price for the releasing the model weights of Llama-3 400B, or another 4-level model?
I think in most worlds the direct safety cost here is also very low, especially the direct existential safety cost. Even with extensive scaffolding, there are limits to what a 4-level model can do. I’d expect some nastiness on the edges but only on the edges, in limited form.
How many 9s of direct safety here, compared to a world in which a 4-level model was never released with open weights? I would say two 9s (>99%), but not three 9s (<99.9%). However the marginal safety cost versus the counterfactual other open model releases is even smaller than that, and there I would say we have that third 9 (so >99.9%).
I say direct safety because the primary potential safety dangers here seem indirect. They are:
Setting a precedent and pattern for future similar releases, at Meta and elsewhere.
Assisting in training of next-generation models.
Everyone generally being pushed to go faster, faster.
And again, these only matter on the margin to the extent they move the margin.
At the time of Llama-2, I said what I was concerned about opening up was Llama-4.
That is still the case now. Llama-3 will be fine.
Will releasing Llama-4 be fine? Probably. But I notice my lack of confidence.
The Efficient Market Hypothesis is False
(Usual caveat: Nothing here is investing advice.)
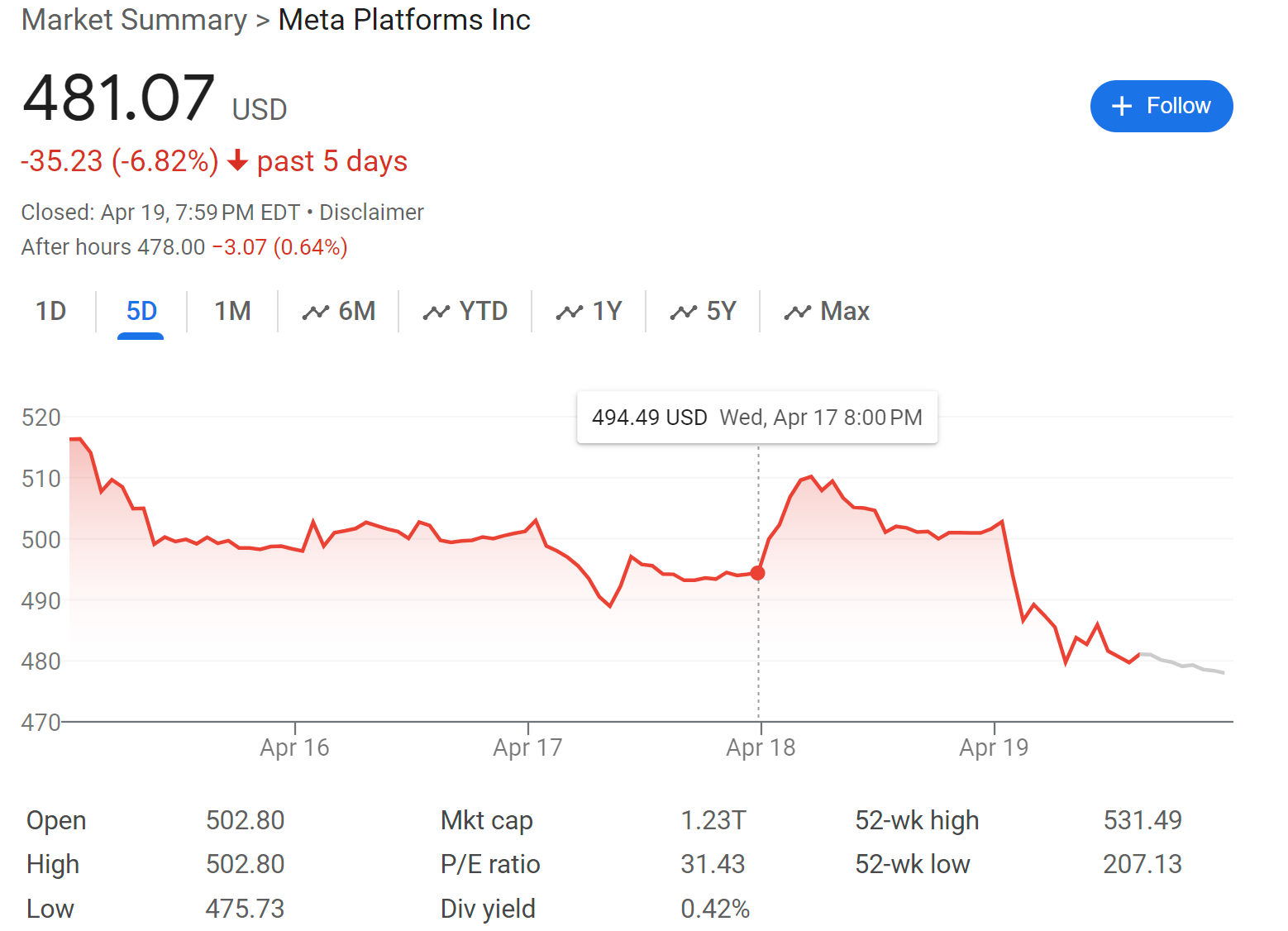
Market is not impressed. Nasdaq was down 6.2% in this same period.
(Then about a day later it looked like we were finally going to actually force divestiture of TikTok while using that to help pass a foreign aid bill, so this seems like a massive own goal by China to remind us of how they operate and the law of equivalent exchange.)
The stock most down was Nvidia, which fell 10%, on no direct news. Foolish, foolish.
At most, markets thought Llama-3’s reveal was worth a brief ~1% bump.
You can say on Meta that ‘it was all priced in.’ I do not believe you. I think the market is asleep at the wheel.
Some are of course calling these recent moves ‘the market entering a correction phase’ or that ‘the bubble is bursting.’ Good luck with that.
Here is a WSJ article about how Meta had better ensure its AI is used to juice advertising returns. Investors really are this myopic.
Any given company, of course, could still be vastly overvalued.
More investors are just realizing that Nvidia doesn’t make chips. They design them and TSMC makes them. And Nvidia’s biggest customers (Meta, Amazon, OpenAI, Microsoft, Google, etc) have ALL announced they are designing their own AI chips for both training and inference. And Google just went public they are already training on their own silicon and didn’t need Nvidia.
This is a very real threat.
I can totally buy that a lot of investors have no idea what Nvidia actually produces, and got freaked out by suddenly learning what Nvidia actually does. I thought it was very public long ago that Google trains on TPUs that they design? I thought it was common knowledge that everyone involved was going to try to produce their own chips for at least internal use, whether or not that will work? And that Nvidia will still have plenty of customers even if all the above switched to TPUs or their own versions?
That does not mean that Nvidia’s moat is impregnable. Of course they could lose their position not so long from now. That is (a lot of) why one has a diversified portfolio.
Again. The Efficient Market Hypothesis in False.
What Next?
I expect not this, GPT-5 will be ready when it is ready, but there will be pressure:
Jim Fan: Prediction: GPT-5 will be announced before Llama-3-400B releases. External movement defines OpenAI’s PR schedule
I do not doubt that OpenAI and others will do everything they can to stay ahead of Meta’s releases, with an unknown amount of ‘damn the safety checks of various sorts.’
That does not mean that one can conjure superior models out of thin air. Or that it is helpful to rush things into use before they are ready.
Still, yes, everyone will go faster on the frontier model front. That includes that everyone in the world will be able to use Llama-3 400B for bootstrapping, not only fine-tuning.
On the AI mundane utility front, people will get somewhat more somewhat cheaper, a continuation of existing trends, with the first two models. Later we will have the ability to get a 4-level model internally for various purposes. So we will get more and cheaper cool stuff.
Meta will deploy its tools across its social media empire. Mostly I expect this to be a positive experience, and to also get a lot more people to notice AI. Expect a bunch of scare stories and highlights of awful things, some real and some baseless.
On the practical downside front, little will change until the 400B model gets released. Then we will find out what people can do with that, as they attempt to flood the zone in various ways, and try for all the obvious forms of misuse. It will be fun to watch.
All this could be happening right as the election hits, and people are at their most hostile and paranoid, seeing phantoms everywhere.
Do you have any thoughts on whether it would make sense to push for a rule that forces open-source or open-weight models to be released behind an API for a certain amount of time before they can be released to the public?
It is better than nothing I suppose but if they are keeping the safeties and restrictions on then it will not teach you whether it is fine to open it up.
nit: inference is not zero marginal cost. statement seems to be importing intuitions from traditional software which do not necessarily transfer. let me know if I misunderstood or am confused.
I think people just say "zero marginal cost" in this context to refer to very low marginal cost. I agree that inference isn't actually that low cost though. (Certainly much higher than the cost of distributing/serving software.)