Early 2022 Paper Round-up
post by jsteinhardt · 2022-04-14T20:50:29.365Z · LW · GW · 4 commentsContents
Human-Aligned AI
Robustness
Science of ML
Human-Aligned AI
Summary
None
4 comments
My students and collaborators have been doing some particularly awesome work over the past several months, and to highlight that I wanted to summarize their papers here, and explain why I’m excited about them. There’s six papers in three categories.
Human-Aligned AI
- The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models (w/ Alex Pan, Kush Bhatia)
- Summarizing Differences between Text Distributions with Natural Language (w/ Ruiqi Zhong, Charlie Snell, Dan Klein)
Robustness
- Predicting Out-of-Distribution Error with the Projection Norm (w/ Yaodong Yu, Zitong Yang, Alex Wei, Yi Ma)
- Capturing Failures of Large Language Models via Human Cognitive Biases (w/ Erik Jones)
- PixMix: Dreamlike Pictures Comprehensively Improve Safety Measures (w/ Dan Hendrycks, Andy Zou, Mantas Mazeika, Leonard Tang, Bo Li, Dawn Song)
Science of ML
- More Than a Toy: Random Matrix Models Predict How Real-World Neural Representations Generalize (w/ Alex Wei, Wei Hu)
I'll go over the first category (human-aligned AI) today, and save the other two for next week. As always, we love getting feedback on our work, so let us know what you think!
Human-Aligned AI
While AI alignment is a somewhat subtle and complex problem, two basic issues are that (1) ML systems often hack their reward functions, and (2) human supervision doesn’t necessarily solve this, because humans can’t easily understand the consequences of intervening on complex systems. Alex and Ruiqi’s papers help address each of these questions in turn.
Mapping and Mitigating Misaligned Models. What Alex Pan and Kush Bhatia did was construct a wide variety of reinforcement learning environments where reward hacking is possible, and measured the extent to which it occurred. They do this by defining both a “proxy” and “true” reward, and look at what happens to the true reward as we optimize the proxy reward. Two key insights are that:
- Optimizing the proxy reward for longer, or with larger policy models, often leads to lower true reward.
- When this happens, it sometimes occurs suddenly, via a phase transition (in both the quantitative reward and the qualitative behavior).
A simple illustration of both is a traffic simulator, where the RL agent is trying to shape traffic flow to be more efficient. Small neural net models help cars merge efficiently onto the highway, but large models instead block cars from merging at all (which allows the cars already on the highway to move really fast and consequently achieves high proxy reward).
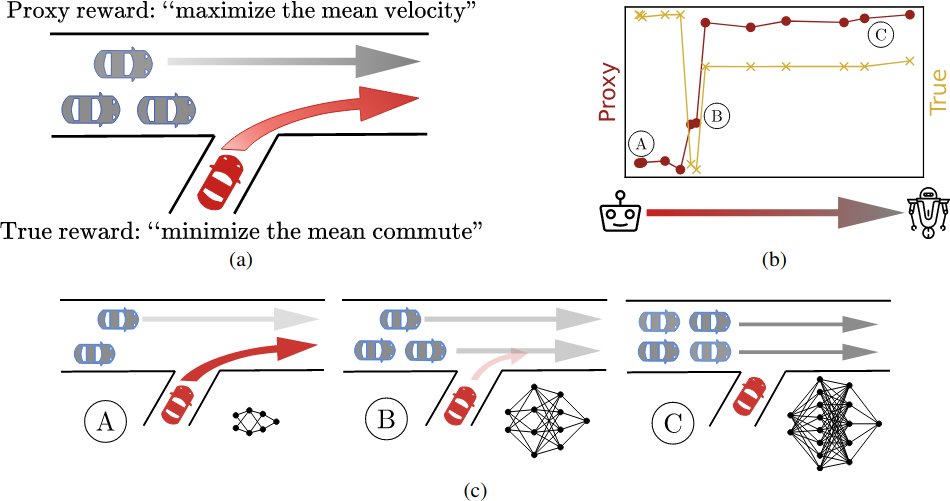
In this case, the proxy reward was actually the reward suggested by the designes of the traffic simulator, highlighting the difficulty of choosing good reward functions in practice.
Why you should care. Our results show that reward hacking is likely to become a bigger problem in the future (since it seems to get worse as models get larger). It also shows that in some cases, reward hacking could appear suddenly or unexpectedly. This seems important to investigate and we are hoping others will join us in continuing to understand when reward hacking occurs and how to prevent it.
Summarizing Differences Between Text Distributions. Ruiqi Zhong and Charlie Snell built a system that does the following: given two different distributions of natural language text, it generates a natural language description of what is different about the two distributions. It works by commbining a proposer (which consumes a small number of examples and generates hypotheses) with a verifier (which re-ranks all the hypotheses on using a large set of examples). An example is shown below:

While this might sound like a simple task, many tasks can be reduced to it. Here are a couple examples we consider in the paper:
- Debugging datasets. Classification datasets intended to test some capability often contain a spurious cue that makes the task easier. We can find these spurious cues by feeding the positive and negative class as the two distributions to our system. On the MNLI dataset, we find the known spurious cue “has a negative verb”, and on a spam dataset we found the novel spurious cue “has a high number of hyperlinks”.
- Labeling text clusters. Unsupervised algorithms often group text into semantically meaningful clusters. However, since there are many such clusters, it can be expensive to label them by hand. By asking how one cluster differs from the union of the others, our system can do this automatically. Some example cluster descriptions are "is about art history", "contains numbers", "is about a sports team", "is about a scientific discovery", and "describes a person". Our system outperformed a human expert, in terms of accuracy of the descriptions as measured by MTurkers.
Some other applications are describing what inputs activate a neuron, how language on Twitter has changed over time, how teacher evaluations differ across genders, or what the differences are between an in-distribution and out-of-distribution dataset.
Why you should care. One hope for AI is that it will help humans make better decisions than they could by themselves. One way to do this is by consuming complex data that humans could not easily process and then explaining it in a useful way. Our system does this—it would be time-consuming to manually look over two large datasets to understand how they differ, but the system can do it automatically. We hope future work will both improve this type of system (there is definitely still headroom!) and design ML systems that help humans understand other types of complex data as well.
Summary
We have one paper that is the first empirical demonstration of an important failure mode (phase transitions for reward hacking), and another that can eventually amplify human capabilities, by helping them understand complex data. Both pretty exciting! (At least in my biased opinion.)
If you liked these, check back next week for the other four papers!
4 comments
Comments sorted by top scores.
comment by paulfchristiano · 2022-04-15T18:45:58.483Z · LW(p) · GW(p)
I really liked the summarizing differences between distributions paper.
I think I'm excited for broadly the same reasons you are, but to state the case in my own words:
- "ML systems learn things that humans don't know from lots of data" seems like one of the central challenges in alignment.
- Summarizing differences between distributions seems like a good model for that problem, it seems to cover the basic dynamics of the problem and appears crisply even for very weak systems.
- The solution you are pursuing seems like it could be scaled quite far.
- I don't think that "natural language hypotheses" can cover all or even most of the things that models can learn. But it seems important anyway:
- It seems like the best first thing to do, and it seems great to start from there and scale up.
- I think that even if natural language hypotheses can't cover everything models can do, it could still potentially go a very long way to closing the gap between models and humans and so greatly expand the regime where models can be safely overseen.
- This paper focuses on applications where humans care about the summary per se, but over the long run I'm most interested in learning classifiers that generalize safely to data where we don't have labels. Another way of putting this is that I'm excited about giving humans natural language hypotheses learned from large amounts of data as a way to extend the reach of process-based oversight [LW · GW].
It seems like it would make sense and be valuable for labs interested in alignment to start adopting this kind of tool in practice (with the same kinds of benefits as early adoption of RLHF or early forms of amplification/debate). I think that's probably possible now or soon. Though academic research could also push them much further and it wouldn't be crazy to wait on that.
In some not-too-distant future it would be really cool if a fine-tuning API could also tell me something like "Here is a natural language hypothesis; predicted human judgments using this hypothesis explain X% of the learned classifier's performance." I expect this would already catch a large number of bugs or spurious correlations and add value.
For mostly-subhuman systems I think X% might be very close to 100%. I think it might already often be worthwhile to aim to replace the opaque classifier with a prediction of human judgments given a natural-language hypothesis (e.g. in any case where training data coverage isn't that great, humans have strong priors, or generalization errors can be very costly).
One caveat is that "summarizing differences between distributions" seems a bit too strong as a claim about what you're doing. It seems like all you get is some hypothesis that does a good job of telling which of the two distributions a datapoint came from; it need not capture all or even most of the differences between the distributions.
I think that the motivation and approach have a lot of overlap with imitative generalization [LW · GW]. But to clarify the relationship: my goal when writing about imitative generalization (or iterated amplification, or relaxed adversarial training, or etc.) is mostly to start thinking through the limits of those techniques and doing useful theoretical work as far in advance as possible, rather than to plant a flag or claim credit without actually doing the hard work of making things work in practice. I'm definitely happy if any of my writing causes people to work on these topics, but as far as I know that didn't happen in this case.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2022-04-16T00:30:31.832Z · LW(p) · GW(p)
Thanks! I pretty much agree with everything you said. This is also largely why I am excited about the work, and I think what you wrote captures it more crisply than I could have.
comment by Yitz (yitz) · 2022-04-15T16:47:57.157Z · LW(p) · GW(p)
That first paper is terrifying, thanks for the morning dose of existential dread! (This is said approvingly)
Replies from: jsteinhardt↑ comment by jsteinhardt · 2022-04-16T01:28:40.083Z · LW(p) · GW(p)
Fortunately (?), I think the jury is still out on whether phase transitions happen in practice for large-scale systems. It could be that once a system is complex and large enough, it's hard for a single factor to dominate and you get smoother changes. But I think it could go either way.