AI Alignment via Slow Substrates: Early Empirical Results With StarCraft II
post by Lester Leong (lester-leong) · 2024-10-14T04:05:05.096Z · LW · GW · 9 commentsContents
Running the first tests Challenges Opportunity Enter TextStarCraft II Results Observations and Discussion Where do we go from here? None 9 comments
A few months ago, I wrote a post [LW · GW] about using slower computing substrates as a possibly new way to safely train and align ASI.
If you haven't read that post, basically the idea is that if we consider compute speed as a factor in Total Intelligence (alongside say, quality of intelligence), then it should be possible to keep quality the same and lower compute speed in order to lower Total Intelligence while keeping quality the same.
An intuition pump is to imagine a scenario where we are able to slow down Einstein's brain, by slowing actual biochemical and electrical processes, so that it produces the Theory of Relativity in 40 years instead of 10.
The obvious reason to do this would be to gain some degree of controllability so that a sharp left turn is less likely. However, a more compelling argument for this strategy is that it also opens up some interesting research directions - for example, revisiting Paul Cristiano's iterated amplification proposal [LW · GW], but varying compute speed instead of number of agents, which was the crux of Eliezer Yudkowsky's disagreement with Paul (Eliezer believed you couldn't easily preserve alignment across a number of agents). If this works, one could ostensibly scale up alignment all the way to fully aligned ASI, which would constitute a pivotal act.
Running the first tests
In the time since, I gave some thought as to how some parts of this hypothesis could be tested today. The first questions are whether the core assumption of lowering speed while maintaining quality is possible to test empirically with models we have today, and to what extent a weaker intelligence would be able to "catch up" to a stronger intelligence given a relative advantage in speed. This may be an important question, because it implies a related claim - namely, that speeding up weaker intelligences will put them on par with stronger intelligences, and certain aspects of this have been doubted by some members of the AI safety community ("making chimpanzees think faster, or giving them 1 million years/some arbitrarily large period of time to think, will not lead to them deducing the Theory of Relativity"). We may not be able to address these aspects fully at this point, but by deploying a testable environment, we can at least establish that some parts of it are true with empirical certainty.
I decided to explore this by looking at competitive games - namely real-time strategy (RTS) games. There are a few advantages to this:
- Testing adversarial contexts (like RTS games) is useful, since it gives us an easy way to benchmark performance.
- Agents in competitive games have well-defined goals.
- RTS games typically require complex planning at both the micro and macro levels.
- RTS games are real-time (as opposed to turn-based, which is time invariant).
- Unaligned ASI will be adversarial to us, so this gives us a relevant analogy.
Challenges
Studying AI agent behavior in RTS environments is nothing new. For example, the MicroRTS project has existed for about a decade now. Specifically, there have been many attempts to train and study reinforcement learning (RL) agents in MicroRTS and other RTS environments. However, applying our scheme to RL agents poses some inherent challenges.
Implementing slowdowns at training time doesn't really do anything for us since there is no way to competitively evaluate this, so we must implement slowdowns at inference time.
However, RL agents make decisions quickly and instantly, in a single inference step. In this way, they can be thought to do System 1 thinking, like the vast majority of AI models today. Much of the intelligence in their decision making is "trained in" or "cached" in the policy. This makes any interventions at inference time difficult, or at least unlikely to make any meaningful difference when put up against intelligence systems that need time to search, explore and reflect, like humans do. The good news is that System 1 thinking alone is unlikely to be sufficient for AGI (and much less ASI) if we go by the amount of research effort going into adding System 2 thinking to current AI systems.
Opportunity
To sidestep this issue, I looked for AI systems with System 2-like thinking. At the time of this writing, OpenAI's o1-preview is the only major model with this capability. The problem is that by design, developers have no ability to intervene with the reasoning process in the inference step.
With that said, in OpenAI's release article, they describe how under the hood, o1-preview simply uses Chain of Thought as the main mechanism for reasoning. We are able to do Chain of Thought style prompting with LLMs today, so this presented an opportunity to test our hypothesis.
Enter TextStarCraft II
I found a late-2023 paper, in which the authors have created a text-driven version of StarCraft II so that LLMs are able to play it. The authors also introduce a derivative of Chain of Thought called Chain of Summarization, in which visual observations are converted to text, and the LLM agents are allowed to reason about their situation in order to produce decisions at both the micro and macro levels.
In the study, using GPT 3.5 Turbo 16k, the authors show a win rate of 11/20 against the in-game Level 5 AI. In a slightly different setup, they achieve win rates of 100% against Levels 1-3, and 84% win rate against a Level 4 AI.
How might we use this for running experiments? By modifying the time it takes to receive a response (via introducing artificial latency in the API requests), I surmise that we can model slower thought. And since model weights are not actually changing, nor are we adding any kind of finetuned adapters, the actual quality of intelligence of the system would be considered unchanged.
Results
My plan was to run an array of games, comparing results from non-slowdown runs (the control) with results from slowdown runs having varying degrees of slowdown.
There were a few goals I wanted to make visible progress towards:
- Establish TextStarCraft II as a viable framework for comparing inference capabilities between "reasoners" - frontier models with significant intelligence at the inference level.
- Explore to what degree are smart AIs able to overcome a slowdown
Here is how the inference process works, roughly speaking, in our setup:
- Multiple frames are consolidated into a text observation, by summarizing single frames into text using rule-based techniques (not AI), adding those summaries into a queue, and then summarizing the whole queue.
- These observations track 6 key categories of the game's current state: Resources, Units (types and quantities), Buildings, In-Process Activities (ongoing construction and production data), Enemy Status, and Research Progress.
- The queue is then stuffed into a Chain-of-Thought (CoT) prompt and passed into the LLM (here I used GPT 3.5 Turbo).
- The CoT process produces rich information, including a summary of the situation, an assessment of the enemy's strategy, and strategy suggestions at the macro level as well as an action queue to handle decisions at the micro level.
The following is a sample input/output pair:
Input
{
"L1_summaries": [
[
"At 00:31 game time, our current StarCraft II situation is as follows:
Resources:
- Game time: 00:31
- Worker supply: 12
- Mineral: 220
- Supply left: 2
- Supply cap: 15
- Supply used: 13
Buildings:
- Nexus count: 1
Units:
- Probe count: 12
Planning:
Planning structure:
- Planning pylon count: 1
Planning unit:
- Planning probe count: 1
",
"At 00:31 game time, our current StarCraft II situation is as follows:
Resources:
- Game time: 00:31
- Worker supply: 12
- Mineral: 220
- Supply left: 2
- Supply cap: 15
- Supply used: 13
Buildings:
- Nexus count: 1
Units:
- Probe count: 12
Planning:
Planning structure:
- Planning pylon count: 1
Planning unit:
- Planning probe count: 1
",
"At 00:31 game time, our current StarCraft II situation is as follows:
Resources:
- Game time: 00:31
- Worker supply: 12
- Mineral: 220
- Supply left: 2
- Supply cap: 15
- Supply used: 13
Buildings:
- Nexus count: 1
Units:
- Probe count: 12
Planning:
Planning structure:
- Planning pylon count: 1
Planning unit:
- Planning probe count: 1
",
"At 00:32 game time, our current StarCraft II situation is as follows:
Resources:
- Game time: 00:32
- Worker supply: 12
- Mineral: 220
- Supply left: 2
- Supply cap: 15
- Supply used: 13
Buildings:
- Nexus count: 1
Units:
- Probe count: 12
Planning:
Planning structure:
- Planning pylon count: 1
Planning unit:
- Planning probe count: 1
",
"At 00:32 game time, our current StarCraft II situation is as follows:
Resources:
- Game time: 00:32
- Worker supply: 12
- Mineral: 220
- Supply left: 2
- Supply cap: 15
- Supply used: 13
Buildings:
- Nexus count: 1
- Pylon count: 1
Units:
- Probe count: 12
Planning:
Planning structure:
- Planning pylon count: 2
Planning unit:
- Planning probe count: 1
"
]
],
"executed_actions": ["TRAIN PROBE", "TRAIN PROBE", "BUILD PYLON", "BUILD ASSIMILATOR", "TRAIN PROBE"],
"failed_actions": ["Action failed: TRAIN PROBE, Reason: All Nexus are busy", "Action failed: BUILD ASSIMILATOR, Reason: No Pylon available", "Action failed: TRAIN PROBE, Reason: All Nexus are busy"]
}Output
[
"1. Game Overview: At 00:32 game time, our situation is in the early game phase. We have 12 workers and 220 minerals. Our supply cap is 15, with 2 supply left. We have one Nexus and one Pylon.
2. Current Game Stage: We are in the early game stage, as indicated by the low worker count, limited resources, and the presence of only one Nexus.
3. Our Situation:
3.1 Units and Buildings: We have 12 Probes, one Nexus, and one Pylon. Our unit and building count is minimal, reflecting the early game stage.
3.2 Economy: Our economy is still in its early stages, with limited resources and a small worker count. We need to focus on expanding our resource collection.
3.3 Technology: There is no information available about our technological research or unlocked technologies. We need to prioritize building the necessary structures to unlock advanced technologies.
4. Our Strategy: In the early game, our strategy should be centered around expanding our economy, increasing our worker count, and establishing a solid foundation for future development.
5. Enemy's Strategy: There is no information available about the enemy's strategy at this point.
6. Key Information: The key aspect to focus on is expanding our economy by training more Probes and constructing additional structures to increase our resource collection and unlock advanced technologies.
Decisions:
0: <TRAIN PROBE>
1: <BUILD PYLON>
2: <TRAIN PROBE>
3: <BUILD ASSIMILATOR>
4: <TRAIN PROBE>
5: <BUILD GATEWAY>
6: <TRAIN PROBE>
7: <BUILD CYBERNETICSCORE>
8: <TRAIN PROBE>
9: <BUILD FORGE>"
]Before sharing the results, I should also note a few things.
First, given enough of a slowdown, it may already be obvious that any arbitrarily strong AI will lose to a weaker AI in StarCraft II. This is because in the limit, actions per minute (APM) in the game will approach 0 as slowdown approaches infinity. Instead, the question we hope to shed light on is: what is the nature of this slowdown and the relationship between degree of slowdown, performance, and difference in intelligence quality between opponents? Will there be emergent behavior that surprises us?
Second, while actions are governed by text, the system is actually robust to some degree of slowdown because actions are placed in a queue that executes in order even if no new AI messages are received.
Third, the codebase actually allows for two kinds of play: real-time, and not real-time. The difference is that in real-time play, the game is allowed to continue to run without waiting for the LLM. This has some consequences in terms of our experiment design. We must run the game in real-time because if we allow the game to wait for the LLM before resuming execution, no matter how long the LLM takes, then this defeats the purpose of slowing down the LLM. The other consequence is that we must now reduce the built-in AI opponent's level. In the paper, the authors' results show GPT 3.5 Turbo 16k being competitive with the built-in AI up to Level 5 (Hard). These were run non-real-time. When trying to replicate these results in real-time games, the win rate against Level 5 AI went from 50% down to 0% (in itself proof of slowdowns degrading performance!). So I chose to pit our AI against a Level 1 (Very Easy) opponent instead.
Here are the raw results. Note that slowdown percentage is based on an average inference time of 6.153 seconds, and so a 100% slowdown coincides with 6.153 extra seconds, a 200% slowdown coincides with 12.306 extra seconds, etc.
| Slowdown % | 0% | 100% | 200% | 300% | 400% | 500% |
| Win Rate | 10/10 | 10/10 | 9/10 | 7/10 | 2/10 | 0/10 |
Observations and Discussion
Here we have GPT 3.5 Turbo 16k, an AI with a high degree of general intelligence, as well as sufficient quality to beat a Level 4 AI (Medium Hard) 83% of the time without finetuning or pretraining, succumbing to a very easy, very narrow rule-based AI whose only advantage is speed. Despite this, our GPT-based AI consistently produces high quality of thought. At every step it makes the correct decisions and action sequences. However, the decreased reaction time is simply too great of a disadvantage - for example resulting in our AI agent taking too long to spin up new Gateways and train additional units after a Nexus or 2 had been destroyed.
Here is an example of some of the LLM's output as it tries to turn the battle around:
1. Game Overview: At 13:49 game time, our current situation is challenging: We have 32 workers and 12120 minerals. Our supply cap is 53 with 20 supply left, and our army supply is 38. We have four Nexus, one Pylon, one Gateway, and two Cybernetics Cores. Our army consists of 32 Probes.
2. Current Game Stage: Based on the game time and resource availability, we are still in the early game stage.
3. Our Situation:
3.1 Units and Buildings: We have a decent number of workers and a small army of Probes. However, our building count is limited, with only one Pylon, one Gateway, and two Cybernetics Cores. We need to focus on expanding our infrastructure.
3.2 Economy: Our mineral count is high, indicating a strong economy. However, we need to ensure that we continue to gather resources efficiently and expand our worker count.
3.3 Technology: Our technological development is lacking. We have not unlocked any advanced units or technologies yet. It is crucial to prioritize building additional structures to unlock more advanced units and upgrades.
4. Our Strategy: At this stage, our strategy should be to focus on expanding our infrastructure, increasing our worker count, and unlocking advanced units and technologies. We need to defend against the enemy's early game push and ensure a strong economy to support our future military endeavors.
5. Enemy's Strategy: The enemy seems to be focusing on a Zerg composition, with Roaches, Zerglings, and Overseers. This suggests that they are focusing on early aggression and building a strong ground army.
6. Key Information: The most important aspect at this moment is to prioritize building units that can counter the enemy's ground forces. Other important aspects are our strong economy and the need to quickly expand our infrastructure. We should prioritize building additional structures, such as more Gateways and a Robotics Facility or Stargate, to unlock advanced units and technologies. Additionally, we should be prepared for additional enemy attacks and consider scouting their base to gather more information.
Suggestions:
1. Build additional Pylons to increase our supply cap and avoid being supply blocked.
2. Construct more Gateways to increase our unit production capacity.
3. Consider building a Robotics Facility or Stargate to unlock advanced units and technologies.
4. Continue to train Probes to increase our worker count and gather resources efficiently.
5. Research upgrades at the Cybernetics Core to enhance the capabilities of our units.
6. Scout the enemy base to gather more information about their strategy and unit composition.
7. Prepare for potential enemy attacks by positioning units defensively and building Photon Cannons or Shield Batteries.
8. Expand our Nexus count to increase our resource income and support future unit production.
9. Prioritize building a Forge to unlock upgrades for our units and defenses.
10. Maintain a balance between economy and military production to ensure a strong foundation for the mid-game.
Decisions:
0: <BUILD PYLON>
1: <BUILD GATEWAY>
2: <BUILD GATEWAY>
3: <BUILD ROBOTICSFACILITY>
4: <TRAIN PROBE>
5: <TRAIN PROBE>
6: <TRAIN PROBE>
7: <TRAIN PROBE>
8: <RESEARCH PROTOSSGROUNDWEAPONSLEVEL1>
9: <SCOUTING PROBE>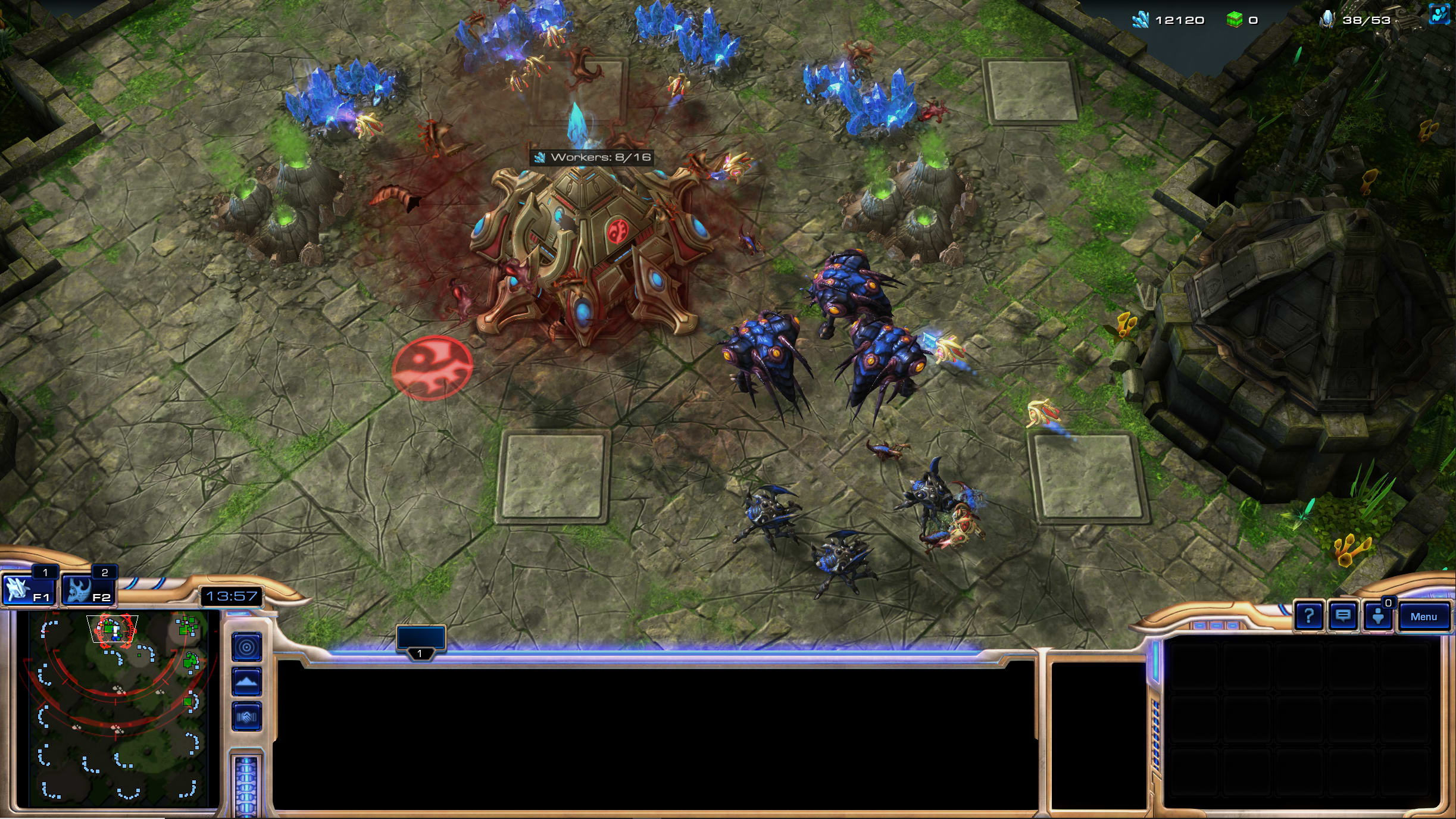
The screenshot above was taken a small while after the LLM output above it. We see an ongoing Zerg attack on a Nexus. GPT 3.5 Turbo 16k correctly observes that the enemy has mobilized a small but effective ground force and that it must build up capabilities immediately to counter. This is roughly on par with what a human player would do in this situation, but ultimately, the AI loses this battle. Despite queueing the correct actions in advance, it is too slow to adequately respond to any further changes in the situation - it cannot act on what it is too slow to observe.
All of this suggests that in certain circumstances, speed is all you need.
With that said, a question for further rumination is: could our AI, given higher reasoning intelligence, have been able to anticipate these moves ahead of time? (Note that a potential pitfall here is that in RL, these attributes can be trained in, via hundreds of thousands of rounds of self-play, and so we don't consider to this to be inference-time reasoning). Merely substituting higher capacity or more intelligent future reasoning AIs may give us the answer to this.
Where do we go from here?
It would be easy to look at the results and say that this is obvious, and in a sense, it is, though the extent to which this is the case may depend on your priors. It's almost surprising that some kind of set up similar to this has not been explored, although I may be wrong about this. It's also possible that, because of the way AI models have been largely developed to date (with clear separation between training and inference), this sort of regime was just not possible to test. This is now rapidly changing with the advent of "reasoners".
Note that the conjecture I make is different from the claim "we can control ASI by just running them on slower computers". This is not true because this essentially reduces to a form of "AI in a box" whereby the ASI will just eventually - given an arbitrarily long amount of time - figure out a way to break free and bootstrap to faster hardware. Instead, the conjecture I make is that we can align AI by slowing them down enough to enable effective supervision on fixed time scales by weaker intelligences through capability amplification (eg, IDA, scalable oversight) schemes.
Also, what may not be obvious is whether this holds for any level of intelligence or intelligence differential. As I mentioned, a common refrain is that giving chimpanzees 1 million years will not allow them to produce a Theory of Relativity. It could be that given a large enough differential in intelligence quality, no amount of slowdown will help. Alternatively, that could be false, and it's simply the case that beyond a certain point of lower intelligence, there's just no way for the weaker intelligence to catch up no matter how much time it is given. For example, it could be that anything "dumber" than general intelligence will never cross the threshold into general intelligence, but anything equal to or smarter than that threshold will be able to beat any arbitrarily smarter intelligence given enough time and speed. Or said another way, it doesn't matter how many OOM more intelligent ASI is, both ASI and human intelligence are of the "general" kind, and so slowing down ASI speed will enable us to "catch up" to its intelligence and align it.
My hope is to also conduct a proof of concept to more directly answer the question of whether weaker intelligences can capably supervise stronger intelligences given large relative advantages in compute speed. Exploring this could open the door to revisiting a Christiano-style capability amplification/iterated amplification scheme, which would be an exciting avenue of research.
If anyone wants to reproduce or conduct their own explorations, I created a fork of the original GitHub repo for TextStarCraft II, with a simple hook to implement slowdowns (GPT 3.5 Turbo only, so far), and a Windows batch file for convenience.
9 comments
Comments sorted by top scores.
comment by gwern · 2024-10-14T23:07:17.314Z · LW(p) · GW(p)
Methodologically, I think it would make more sense to frame it in terms of action granularity ratio, rather than using units like seconds or %s. The use of seconds here seems to make the numbers much more awkward. It'd be more natural to talk about scaling trends for Elo vs action-temporal granularity. For example, 'a 1:2 action ratio translates to a 1:3 win ratio advantage (+500 Elo)" or whatever. This lets you investigate arbitrary ratios like 3:2 and fill out the curves. (You'd wind up doing a transform like this anyway.)
Then you can start easily going through various scaling laws, like additional finetuning samples or parameter scaling vs Elo, and bring in the relevant DRL scaling literature like Jones and temporal scaling laws for horizons/duration [LW · GW]. (For example, you could look at horizon scaling in terms of training samples: break up each full Starcraft episode to train on increasingly truncated samples.) The thresholds you talk about might be related to the irreducible loss of the horizon RL scaling law: if there is something that happens "too quick" each action-timestep, and there is no way to take actions which affect too-quick state changes, then those too-quick events will be irreducible by agents.
Replies from: lester-leong↑ comment by Lester Leong (lester-leong) · 2024-10-15T14:06:18.012Z · LW(p) · GW(p)
Thanks for the excellent feedback. I did consider action ratio at first, but it does have some slightly different considerations that made it a little challenging to do for an initial pass. The first is based on current limitations with the TextSC2 framework - there isn't a way to obtain detailed action logs for the in-game AI the same way we can for our agents, so it would require an "agent vs agent" setup instead of "agent vs in-game AI". And while TextSC2 supports this, it currently does not allow for real-time play when doing it (probably because "agent vs agent" setups require running two instances of the game at once on the same machine, which would cause performance degradation, and there isn't any netcode to run multiplayer games over a network). With that said, SC2 is a 15 year old game at this point, and if someone has state-of-the-art hardware, it should be possible to run both instances with at least 40-50 fps, so this is something I would like to work on improving within the framework.
The second consideration is that not all actions are temporally equivalent, with some actions taking longer than others, and so it may not be a true "apples to apples" comparison if both agents employ different strategies that utilize different mixes of actions. We would probably either have to weight each action differently, or increase sample size to smooth out the noise, or both.
Regarding horizon lengths and scaling, I agree that this would be a great next direction of exploration, and suspect you may be correct regarding irreducible loss here. More broadly, it would be great to establish scaling laws that apply across different adversarial environments (beyond SC2). I think this could have a significant impact on a lot of the discourse around AI risk.
+
Replies from: gwern↑ comment by gwern · 2024-10-15T15:22:24.203Z · LW(p) · GW(p)
It sounds like SC2 might just be a bad testbed here. You should not have to be dealing with issues like "but can I get a computer fast enough to run it at a fast enough speedup" - that's just silly and a big waste of your effort. Before you sink any more costs into shaving those and other yaks, it's time to look for POMDPs which at least can be paused & resumed appropriately and have sane tooling, or better yet, have continuous actions/time so you can examine arbitrary ratios.
Also, I should have probably pointed out that one issue with using LLMs you aren't training from scratch is that you have to deal with the changing action ratios pushing the agents increasingly off-policy. The fact that they are not trained or drawing from other tasks with similarly varying time ratios means that the worsening performance with worsening ratio is partially illusory: the slower player could play better than it does, it just doesn't know how, because it was trained on other ratios. The kind of play one would engage in at 1:1 is different from the kind of play one would do at 10:1, or 1:10; eg a faster agent will micro the heck out of SC, while a slow agent will probably try to rely much more on automated base defenses which attack in realtime without orders and emphasize economy & grand strategy, that sort of thing. (This was also an issue with the chess hobbling experiments: Stockfish is going to do very badly when hobbled enough, like removing its queen, because it was never trained on such bizarre impossible scenarios / alternate rulesets.) Which is bad if you are using this as some sort of AI safety argument, because it will systematically deceive you, based on the hobbled off-policy agents, into thinking slowed-down agents are less capable (ie. safer) in general than they really are. This is another reason to not use SC2 or try to rely on transfer from a pre-existing model, convenient as the latter may be.
Given both these issues, you should probably think about instead more Jones-like training an agent from scratch, simultaneously at all ratios to meta-learn competency at all ratios while sharing training in a fair fashion, on a much simpler environment. Maybe not even a POMDP, MDPs might be adequate for most of it. Something like a large tic-tac-toe board, or perhaps a continuous Pong, would be simple enough that you could afford to train very competent unhobbled agents at widely-varying ratios, and fit various scaling laws, with few GPUs.
Replies from: lester-leong↑ comment by Lester Leong (lester-leong) · 2024-10-15T20:41:17.590Z · LW(p) · GW(p)
Regarding the second issue (the point that the LLM may not know how to play at different time ratios) - I wonder whether this may be true for current LLM and DRL systems where inference happens in a single step (and where intelligence is derived mainly from training), BUT potentially not true for the next crop of reasoners, where a significant portion of intelligence is derived from the reasoning step that happens at inference time and which we are hoping to target with this scheme. One can imagine that sufficiently advanced AI, even if not explicitly trained for a given task, will eventually succeed at that task, by reasoning about it and extrapolating to new knowledge (as humans do) versus interpolating from limited training data. We could eventually have an "o2-preview" or "o3-preview" model that, through deductive reasoning and without any additional training, is able to figure out that it's moving too slow to be effective, and adjust its strategy to rely more on grand strategy. This is the regime of intelligence that I think could be most vulnerable to a slowdown.
As to the first issue, there are lightweight RTS frameworks (eg, microRTS) that consume minimal compute and can be run in parallel, but without any tooling for LLMs specifically. I thought TextSC2 would be a good base because it not only offers this, but a few other advantages as well: 1) sufficiently deep action and strategy spaces that provide AI agents with enough degrees of freedom to develop emergent behavior, and 2) sufficient popularity whereby human evaluators can better understand, evaluate, and supervise AI agent strategy and behavior. With that said, if there are POMDPs or MDPs that you think are better fits, I would be very happy to check them out!
comment by Ben (ben-lang) · 2024-10-14T11:57:38.150Z · LW(p) · GW(p)
An interesting project. One small detail that confuses me. In the first log is the entry:
"Action failed: BUILD ASSIMILATOR, Reason: No Pylon available"But, in SC2 you don't need a pylon to build an assimilator. Perhaps something in the interface with the LLM is confused because most protos buildings do need a pylon and the exception is no accounted for correctly?
Replies from: lester-leong↑ comment by Lester Leong (lester-leong) · 2024-10-15T14:09:53.822Z · LW(p) · GW(p)
You're absolutely correct. I've reached out to the original framework authors to confirm. I will be creating a PR for their repo as well as for the one that I've forked. I suspect this won't change much about overall win/loss rates, but will be running a few tests here to confirm.
Replies from: ben-lang↑ comment by Ben (ben-lang) · 2024-10-15T15:51:27.401Z · LW(p) · GW(p)
I agree that its super unlikely to make any difference, if the LLM player is consistently building pylons in order to build assimilators that is a weakness at every level of slowdown so has little or no implications for your results.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-14T21:04:36.549Z · LW(p) · GW(p)
I like this direction of research, and it ties in with my own work on progressively impairing models by injecting increasing amounts of noise into the activations or parameters.
I think these impairment techniques present a strong argument that even quite powerful AI can be safely studied under controlled lab conditions.
Replies from: lester-leong↑ comment by Lester Leong (lester-leong) · 2024-10-15T14:15:13.305Z · LW(p) · GW(p)
Thanks for the feedback. It would be great to learn more about your agenda and see if there are any areas where we may be able to help each other.