A caveat to the Orthogonality Thesis
post by Wuschel Schulz (wuschel-schulz) · 2022-11-09T15:06:51.427Z · LW · GW · 10 commentsContents
Orthogonality thesis Sharp left turn Main text None 10 comments
This post relies on an understanding of two concepts: The Orthogonality thesis and the sharp left turn. If you already know what they are, skip to the main text.
Orthogonality thesis [? · GW]
The orthogonality thesis states that an agent can have any combination of intelligence and goals. It is one of the core assumptions of alignment research.
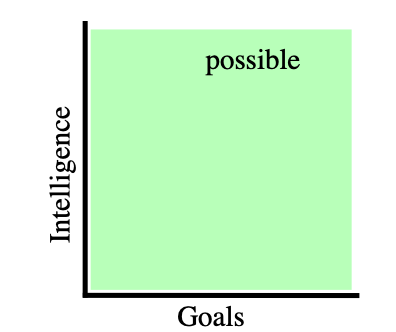
Sharp left turn [? · GW]
The sharp left turn is a hypothesized event, where the capabilities of an AI suddenly generalize to new domains without its alignment capabilities generalizing. This process is sometimes described as “hitting the core of intelligence” and is considered to be the crucial point of alignment by some, as AIs after a sharp left turn might be more capable than humans. So we have to have AI alignment figured out before an AI takes the sharp left turn.
Main text
While I do think the orthogonality thesis is mostly correct, I have a small caveat:
For an AI to maximize/steer towards x, x must be either part of its sensory input or its world model.
Imagine a really simple “AI”: a thermostat that keeps the temperature. If you take a naive view of the orthogonality thesis, you would have to believe that there is a system as intelligent as a thermostat, that maximizes paperclips. I do not think there is such a system, because it would have no idea what a paperclip is. It doesn't even have a model of the outside world, it can only directly act on its sensory input.
Even for systems that have a world model, they can only maximize things that are represented in their world model. If that world model only includes objects in a room, but the AI does not have the concept of what a person is, and what intentions are, it can optimize towards “put all the red squares in one line” but it can not optimize towards “do what the person intends”.
So a more realistic view of the orthogonality thesis is the following:
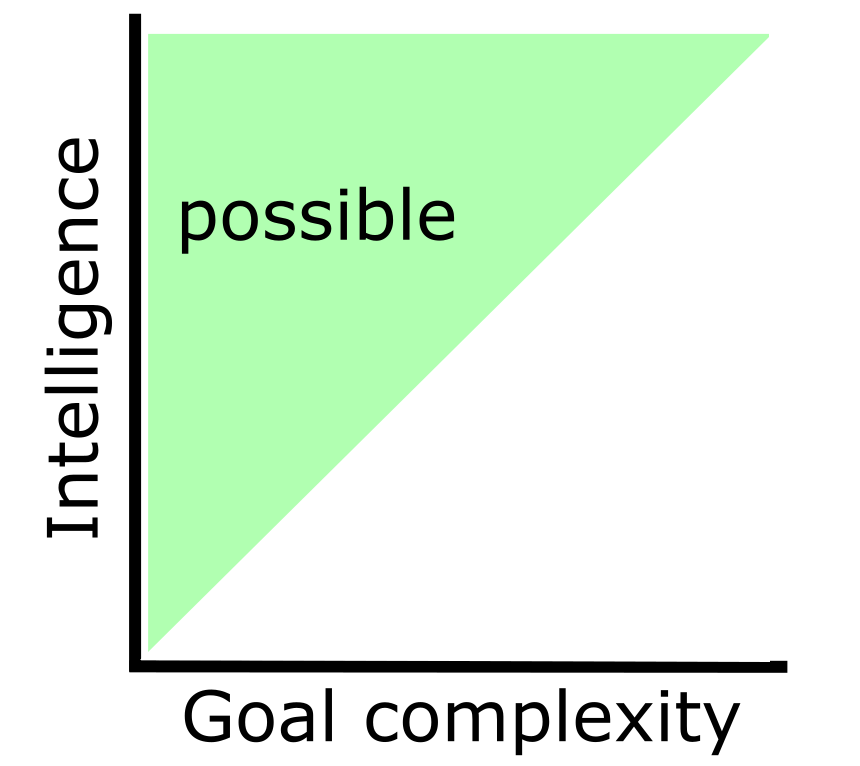
In this plot, I have lumped intelligence and world model complexity together. Usually, these concepts go together, because the more intelligent an AI is, the more complex its world model gets. If we found a way to make an AI have an arbitrarily complex world model while still being arbitrarily dumb, this graph would no longer hold true.
Now, this is where the sharp left turn comes into play. Assuming that there is a sharp left turn, there is some maximum intelligence that a system can have, before “hitting the core of intelligence” and suddenly becoming stronger than humans.
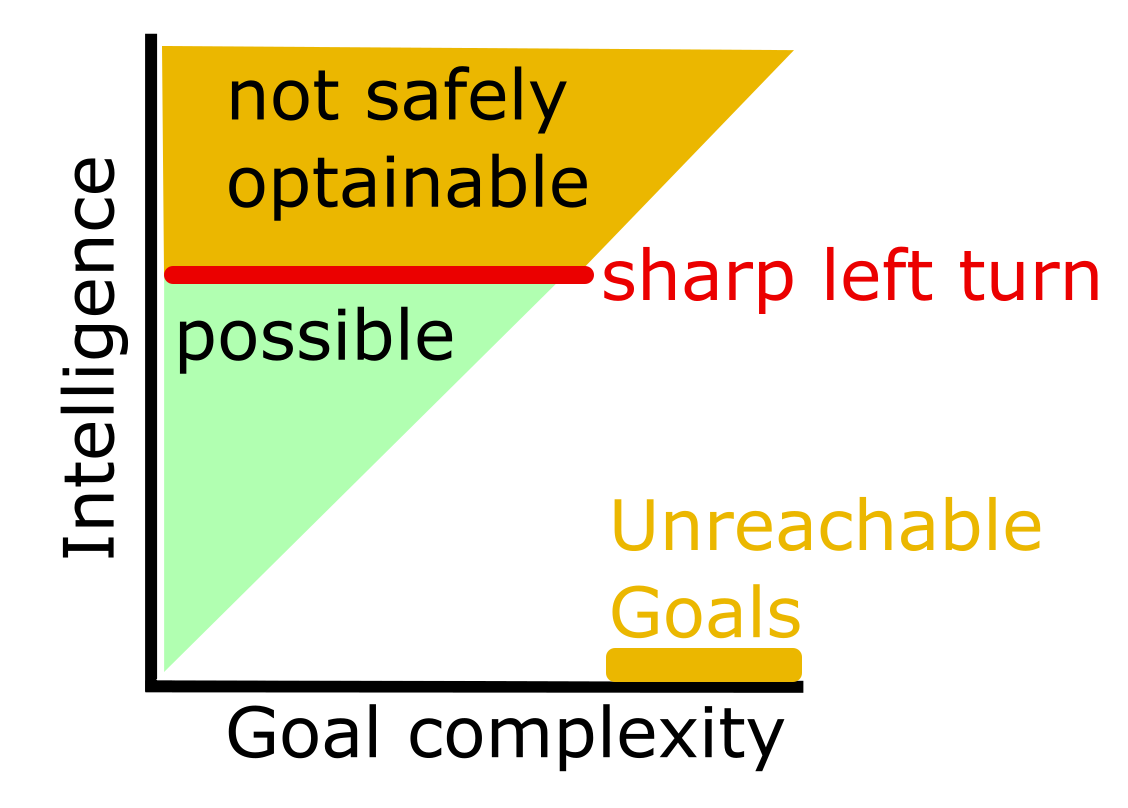
The important question is, whether a system hits this core of intelligence just by having a more and more sophisticated world model. If this is the case, then there is some maximum amount of world model complexity that a system can have before taking the sharp left turn. And that would mean in turn, that there is a cap on the goals that we can give an AI in practice.
There might be Goals that are so complex, that any AI intelligent enough to understand them, would have hit the sharp left turn.
There are follow up questions, that I have no answers to, and would be grateful for insightful comments:
- Is it true that a more and more sophisticated world model is enough to “hit the core of intelligence”?
- Are human values in the reachable or the unreachable goals?
- Is corrigibility in the reachable or the unreachable goals?
10 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-11-09T21:31:23.931Z · LW(p) · GW(p)
The sharp left turn argument boils down to some handwavey analogy that evolution didn't optimize humans to optimize for IGF - which is actually wrong, as it clearly did [LW(p) · GW(p)], combined with another handwavey argument that capabilities will fall into a natural generalization attractor, but there is no such attractor for alignment. That second component of the argument is also incorrect, because there is a natural known attractor for alignment - empowerment [LW · GW]. The more plausible attractor argument is that selfish-empowerment is a stronger attractor than altruistic-empowerment.
Also more generally capabilities generalize through the world model, but any good utility function will also be defined through the world model, and thus can also benefit from its generalization.
Replies from: rvnnt↑ comment by rvnnt · 2022-11-10T11:09:15.949Z · LW(p) · GW(p)
any good utility function will also be defined through the world model, and thus can also benefit from its generalization.
Are you saying that as the world model gets more expressive/accurate/powerful, we somehow also get improved guarantees that the AI will become aligned with our values?
I'd agree with:
(i) As the world model improves, it becomes possible in principle to specify a utility function/goal for the AI which is closer to "our values".
But I don't see how that implies
(ii) As an AI's (ANN-based) world model improves, we will in practice have any hope of understanding that world model and using it to direct the AI towards a goal that we can be remotely sure actually leads to good stuff, before that AI kills us.
Do you have some model/intuition of how (ii) might hold?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-11-10T16:25:50.490Z · LW(p) · GW(p)
Are you saying that as the world model gets more expressive/accurate/powerful, we somehow also get improved guarantees that the AI will become aligned with our values?
Not quite - if I was saying that I would have. Instead I'd say that as the world model improves through training and improves its internal compression/grokking of the data, you can then also leverage this improved generalization to improve your utility function (which needs to reference concepts in the world model). You sort of have to do these updates anyway to not suffer from "ontological crisis".
This same sort of dependency also arises for the model-free value estimators that any efficient model-based agent will have. Updates to the world model start to invalidate all the cached habitual action predictors - which is an issue for human brains as well, and we cope with it.
(ii) Isn't automatic unless you've already learned an automatic procedure to identify/locate the target concepts in the world model that the utility function needs. This symbol grounding problem is really the core problem of alignment for ML/DL systems in the sense that having a robust solution to that is mostly sufficient. The brain also had to solve this problem [LW · GW], and we can learn a great deal from its solution.
comment by Thane Ruthenis · 2022-11-09T17:16:24.085Z · LW(p) · GW(p)
Is it true that a more and more sophisticated world model is enough to “hit the core of intelligence”?
A sufficiently sophisticated world-model, such as one that includes human values, would include humans. Humans are general problem-solvers [LW · GW], so the AI would have an algorithm for general problem-solving represented inside it somewhere. And once it's there, I expect sharp steep gradients towards co-opting that algorithm for the AI's own tasks.
I agree [LW · GW] that figuring out a way to stop this, to keep the AI from growing agency even as its world-model becomes superhumanly advanced, would be fruitful.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-11-10T16:18:57.833Z · LW(p) · GW(p)
Humans have sophisticated world models that contain simulacra of other humans - specifically those we are most familiar with. I think you could make an interesting analogy perhaps to multiple personality disorder being an example of simulacra breaking out of the matrix and taking over the simulation, but it's a bit of a stretch.
What are sharp gradients? Is that a well established phenomena in ML you could point me at?
The simulacra in a simulation do not automatically break out and takeover, that's just a scary fantasy. Like so much of AI risk discourse - just because something is possible in principle does not make it plausible or likely in reality.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2022-11-10T16:33:11.723Z · LW(p) · GW(p)
I'm not talking about a simulacrum breaking out.
Uh, apologies, I meant steepest gradients. The SGD is a locally greedy optimization process that updates a ML model's parameters in the direction of the highest local increase in performance, i. e. along the steepest gradients. I'm saying that once there's a general-purpose problem-solving algorithm represented somewhere in the ML model, the SGD (or evolution, or whatever greedy selection algorithm we're using) would by default attempt to loop it into the model's own problem-solving, because that would increase its performance the most. Even if it was assembled accidentally, or as part of the world-model and not the ML model's own policy.
comment by eva_ · 2022-11-09T23:32:03.708Z · LW(p) · GW(p)
A sufficiently strong world model can answer the question "What would a very smart very good person think about X?" and then you can just pipe that to the decision output, but that won't get you higher intelligence than what was present in the training material.
Shouldn't human goals have to be in the within human intelligence part, since humans have them? Or are we considering exactly human intelligence AI unsafe? Do you imagine a slightly dumber version of yourself failing to actualise your goals from not having good strategies, or failing to even embed them due to having a world model that lacks definitions of objects you care about?
Corrigibility has to be in the reachable part of the goals because a well-trained dog genuinely wants to do what you want it to do, even if it doesn't always understand, and even if following the command will get it less food than otherwise and this is knowable to the dog. You clearly don't need human intelligence to describe the terminal goal "Do what the humans want me to do", although it's not clear the goal will stay there as intelligence rises above human intelligence.
Replies from: wuschel-schulz↑ comment by Wuschel Schulz (wuschel-schulz) · 2022-11-14T18:25:45.863Z · LW(p) · GW(p)
Yes, I would consider humans to already be unsafe, as we already made a sharp left turn that left us unaligned relative to our outer optimiser.
Dogs are a good point, thank you for that example. Not sure if dogs have our exact notion of corrigibility, but they definitely seem to be friendly in some relevant sence.
comment by Charlie Steiner · 2022-11-09T17:04:09.817Z · LW(p) · GW(p)
I think this makes total sense if you think of "how much intelligence" by fixing an agent-like architecture that wants the goal and then scaling the parts, and "intelligence" is something like the total effort being exerted by those parts.
But it isn't quite a caveat to formulations (like Bostrom's) that define "how much intelligence" in terms of external behavior rather than internal structure - maybe you've heard definitions like intelligence is how good it is at optimization across a wide range of domains. If that's your measuring stick, you can scale the world model without changing intelligence, so long as the search process doesn't output vetter plans on average.
comment by Shoshannah Tekofsky (DarkSym) · 2022-11-22T23:18:59.189Z · LW(p) · GW(p)
EDIT: Both are points are moot using Stuart Armstrong's narrower definition of the Orthogonality thesis that he argues in General purpose intelligence: arguing the Orthogonality thesis [LW · GW]:
High-intelligence agents can exist having more or less any final goals (as long as these goals are of feasible complexity, and do not refer intrinsically to the agent’s intelligence).
Old post:
I was just working through my own thoughts on the Orthogonality thesis and did a search on LW on existing material and found this essay. I had pretty much the same thoughts on intelligence limiting goal complexity, so yay!
Additional thought I had: Learning/intelligence-boosting motivations/goals are positively correlated with intelligence. Thus, given any amount of time, an AI with intelligence-boosting motivations will become smarter than those do not have that motivation.
It is true that instrumental convergence should lead any sufficiently smart AI to also pursue intelligence-boosting (cognitive enhancement) but:
- At low levels of intelligence, AI might fail at instrumental convergence strategies.
- At high levels of intelligence, AI that is not intelligence-boosting will spend some non-zero amount of resources on its actual other goals and thus be less intelligent than an intelligence-boosting AI (assuming parallel universes, and thus no direct competition).
I'm not sure how to integrate this insight in to the orthogonality thesis. It implies that:
"At higher intelligence levels, intelligence-boosting motivations are more likely than other motivations" thus creating a probability distribution across the intelligence-goal space that I'm not sure how to represent. Thoughts?