CNN feature visualization in 50 lines of code
post by StefanHex (Stefan42) · 2022-05-26T11:02:45.146Z · LW · GW · 4 commentsContents
4 comments
[My project for AGI Safety Fundamentals programme (~Oct 2021). Code & pictures below.]
To me, reading about Feature Visualization felt like one of the most revealing insights about CNNs in the last years. Seeing the idea "this node finds eyes, this node finds mouths, the combination detects faces" (oversimplified) actually implemented by the CNN was a pleasant surprise, as in, it suggests we might actually understand how NNs work. There's more reading on the programme website here, I can highly recommend the articles by Chris Olah's group on distill.
Seeing this I think many of us immediately want to try this, and play around with it. There is of course the OpenAI Microscope to look at results, and the Lucid library, but I wanted to actually reproduce the idea myself without relying on a somewhat black box (big library / OpenAI Microscope).
Almost all tutorials I found however used Lucid, and this really cool write-up "How to visualize convolutional features in 40 lines of code" unfortunately starts with from fastai.conv_learner import *. In retrospective I think I could understand this now, but I didn't, and finding out which parts were fastai functions and what they do was rather tricky. I also didn't manage to install the required (older) version of fastai.
So I decided to have a go myself, and, luckily, I found that "DeepDream" is based a very similar idea and I could adopt most code from this notebook from Google AI. This isn't actually too complicated, especially broken down to the bare minimum:
- A trained network whose features we want to visualize
- A loop to maximize the activation of a targeted node
- A few lines to make and show an image.
The whole code runs in about a minute on my laptop (no GPU).
- The first part is easy, we get the pre-trained network from tensorflow.
import tensorflow as tf
base_model = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
- The next part in the code (it's mostly comments really), see the comments marked with
#for explanations:
def maximize_activation(starting_img,\
target_layer="mixed0", target_index=0,\
steps=10, step_size=0.1):
# Take the network and cut it off at the layer we want to analyze,
# i.e. we only need the part from the input to the target_layer.
target = [base_model.get_layer(target_layer).output]
part_model = tf.keras.Model(inputs=base_model.input, outputs=target)
# The next part is the function to maximize the target layer/node by
# adjusting the input, equivalent to the usual gradient descent but
# gradient ascent. Run an optimization loop:
def gradient_ascent(img, steps, step_size):
loss = tf.constant(0.0)
for n in tf.range(steps):
# As in normal NN training, you want to record the computation
# of the forward-pass (the part_model call below) to compute the
# gradient afterwards. This is what tf.GradientTape does.
with tf.GradientTape() as tape:
tape.watch(img)
# Forward-pass (compute the activation given our image)
activation = part_model(tf.expand_dims(img, axis=0))
# The activation will be of shape (1,N,N,L) where N is related to
# the resolution of the input image (assuming our target layer is
# a convolutional filter), and L is the size of the layer. E.g. for a
# 256x256 image in "block4_conv1" of VGG19, this will be
# (1,32,32,512) -- we select one of the 512 nodes (index) and
# average over the rest (you can average selectively to affect
# only part of the image but there's not really a point):
loss = tf.math.reduce_mean(activation[:,:,:,target_index])
# Get the gradient, i.e. derivative of "loss" with respect to input
# and normalize.
gradients = tape.gradient(loss, img)
gradients /= tf.math.reduce_std(gradients)
# In the final step move the image in the direction of the gradient to
# increate the "loss" (our targeted activation). Note that the sign here
# is opposite to the typical gradient descent (our "loss" is the target
# activation which we maximize, not something we minimize).
img = img + gradients*step_size
img = tf.clip_by_value(img, -1, 1)
return loss, img
# Preprocessing of the image (converts from [0..255] to [-1..1]
img = tf.keras.applications.inception_v3.preprocess_input(starting_img)
img = tf.convert_to_tensor(img)
# Run the gradient ascent loop
loss, img = gradient_ascent(img, tf.constant(steps), tf.constant(step_size))
# Convert back to [0..255] and return the new image
img = tf.cast(255*(img + 1.0)/2.0, tf.uint8)
return img
- Finally apply this procedure to a random image:
import numpy as np
import matplotlib.pyplot as plt
starting_img = np.random.randint(low=0,high=255,size=(300,300,3), dtype=np.uint8)
optimized_img = maximize_activation(starting_img, target_layer="block4_conv1", target_index=47, steps=10, step_size=0.1)
plt.imshow(np.array(optimized_img))
And here we go!
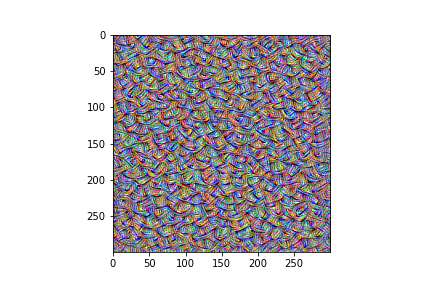
Looks like features. Now let's try to reproduce one of the OpenAI microscope images, node 4 of layer block4_conv1 -- here is my version:
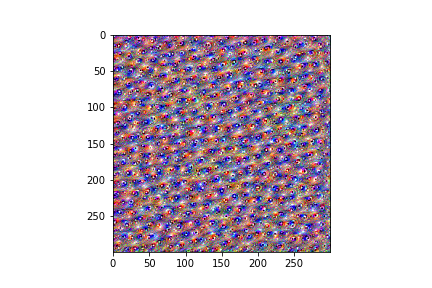
And the OpenAI Microscope image:

Not identical, but clearly the same feature in both visualizations!
Finally here is a run with InceptionV3, just for the pretty pictures, this time starting with a non-random (black) image. And an animation of the image after every iteration.


Note: There's an optional bit to improve the speed (by about a factor of 2 on my laptop), just add this decorator in front of the gradient_ascent function:
@tf.function(
# Decorator to increase the speed of the gradient_ascent function
input_signature=(
tf.TensorSpec(shape=[None,None,3], dtype=tf.float32),
tf.TensorSpec(shape=[], dtype=tf.int32),
tf.TensorSpec(shape=[], dtype=tf.float32),)
)
def gradient_ascent(img, steps, step_size): ...
This is basically how far I got in the time, the code can be found on my GitHub (link). But I do plan to look at some more interpretability techniques (maybe something for transformers or RL?) or more general AGI Safety ideas in the future!
Feel free to post a comment or send me a message if you have any questions or anything really, happy to chat about these things!
I just want to thank the organizers of the AGI Safety Fundamentals programme again, for setting up the programme and all their support. I can highly recommend the programme, as well as the well-curated curriculum here if you just want to read through it yourself.
4 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-05-23T06:55:53.055Z · LW(p) · GW(p)
Super cool, thanks!
Image interpretability seems mostly so easy because humans are already really good at interpreting 2D images with local structure. But thinking about this does suggest an idea for language model interpretability - how practical is it to find text that a) has high probability according to the prior distribution, b) strongly activates one attention head or feed-forward neuron or something, c) only weakly activates other parts of the transformer (within some reference class)? Probably this has already been tried somewhere and gotten middling results.
Replies from: Frederik, Stefan42↑ comment by Tom Lieberum (Frederik) · 2022-05-26T13:02:48.826Z · LW(p) · GW(p)
On priors, I wouldn't worry too much about c), since I would expect a 'super stimulus' for head A to not be a super stimulus for head B.
I think one of the problems is the discrete input space, i.e. how do you parameterize sequence that is being optimized?
One idea I just had was trying to fine-tune an LLM with a reward signal given by for example the magnitude of the residual delta coming from a particular head (we probably something else here, maybe net logit change?). The LLM then already encodes a prior over "sensible" sequences and will try to find one of those which activates the head strongly (however we want to operationalize that).
↑ comment by StefanHex (Stefan42) · 2022-05-26T09:45:26.928Z · LW(p) · GW(p)
Image interpretability seems mostly so easy because humans are already really good
Thank you, this is a good point! I wonder how much of this is humans "doing the hard work" of interpreting the features. It raises the question of whether we will be able to interpret more advanced networks, especially if they evolve features that don't overlap with the way humans process inputs.
The language model idea sounds cool! I don't know language models well enough yet but I might come back to this once I get to work on transformers.
comment by Tom Lieberum (Frederik) · 2022-05-26T12:43:30.179Z · LW(p) · GW(p)
Very cool to see new people joining the interpretability field!
Some resource suggestions:
If you didn't know already, there is a TF2 port of Lucid, called Luna:
There is also Lucent, which is Lucid for PyTorch: (Some docs written by me for a slightly different version)
For transformer interpretability you might want to check out Anthropic's work on transformer circuits, Redwood Research's interpretability tool, or (shameless plug) Unseal.