Worries About AI Are Usually Complements Not Substitutes
post by Zvi · 2025-04-25T20:00:03.421Z · LW · GW · 1 commentsContents
1 comment
A common claim is that concern about [X] ‘distracts’ from concern about [Y]. This is often used as an attack to cause people to discard [X] concerns, on pain of being enemies of [Y] concerns, as attention and effort are presumed to be zero-sum.
There are cases where there is limited focus, especially in political contexts, or where arguments or concerns are interpreted perversely. A central example is when you site [ABCDE] then they’ll find what they consider the weakest one and only consider or attack that, silently discarding the rest entirely. Critics of existential risk do that a lot.
So it does happen. But in general one should assume such claims are false.
Thus, the common claim that AI existential risks ‘distract’ from immediate harms. It turns out Emma Hoes checked, and the claim simply is not true.

The way Emma frames worries about AI existential risk in her tweet – ‘sci-fi doom’ – is beyond obnoxious and totally inappropriate. That only shows she was if anything biased in the other direction here. The finding remains the finding.
Emma Hoes:
New paper out in @PNASNews! Existential AI risks do **not** distract from immediate harms. In our study (n = 10,800), people consistently prioritize current threats – bias, misinformation, job loss – over sci-fi doom!
Title: Existential Risk Narratives About AI Do Not Distract From Its Immediate Harms.
Abstract: There is broad consensus that AI presents risks, but considerable disagreement about the nature of those risks. These differing viewpoints can be understood as distinct narratives, each offering a specific interpretation of AI’s potential dangers.
One narrative focuses on doomsday predictions of AI posing long-term existential risks for humanity.
Another narrative prioritizes immediate concerns that AI brings to society today, such as the reproduction of biases embedded into AI systems.
A significant point of contention is that the “existential risk” narrative, which is largely speculative, may distract from the less dramatic but real and present dangers of AI.
We address this “distraction hypothesis” by examining whether a focus on existential threats diverts attention from the immediate risks AI poses today. In three preregistered, online survey experiments (N = 10,800), participants were exposed to news headlines that either depicted AI as a catastrophic risk, highlighted its immediate societal impacts, or emphasized its potential benefits.
Results show that
i) respondents are much more concerned with the immediate, rather than existential, risks of AI, and
ii) existential risk narratives increase concerns for catastrophic risks without diminishing the significant worries respondents express for immediate harms. These findings provide important empirical evidence to inform ongoing scientific and political debates on the societal implications of AI.
That seems rather definitive. It also seems like the obvious thing to assume? Explaining a new way [A] is scary is not typically going to make me think another aspect of [A] is less scary. If anything, it tends to go the other way.
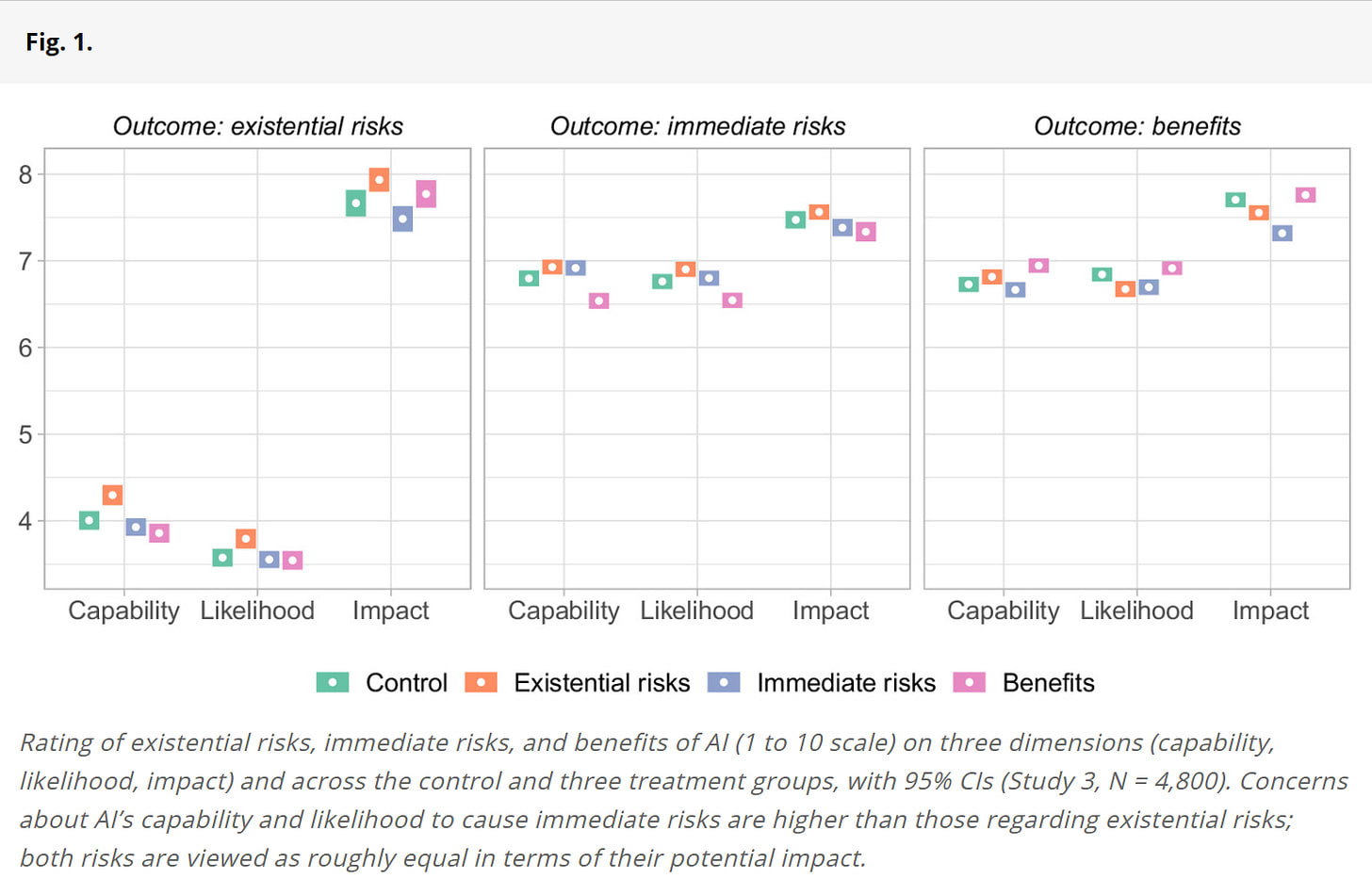
This shows that not only did information about existential risks not decrease concern about immediate risks, it seems to clearly increase it, at least as much as information about those immediate risks.
I note that this does not obviously indicate that people are ‘more concerned’ with immediate risk, only that they see it as less likely. Which is totally fair, it’s definitely less likely than the 100% chance of immediate risks. The impact measurement is higher.
Kudos to Arvind Narayanan. You love to see people change their minds and say so:
Arvind Narayanan: Nice paper. Also a good opportunity for me to explicitly admit that I was wrong about the distraction argument.
(To be clear, I didn’t change my mind yesterday because of this paper; I did so over a year ago and have said so on talks and podcasts since then.)
There are two flavors of distraction concerns: one is at the level of individual opinions studied in this paper, and the other is at the level of advocacy coalitions that influence public policy.
But I don’t think the latter concern has been borne out either. Going back to the Biden EO in 2023, we’ve seen many examples of the AI safety and AI ethics coalitions benefiting from each other despite their general unwillingness to work together.
If anything, I see that incident as central to the point that if anything what’s actually happening is that AI ‘ethics’ concerns are poisoning the well for AI existential risk concerns, rather than the other way around. This has gotten so bad that the word ‘safety’ has become anathema to the administration and many on the hill. Those people are very willing to engage with the actual existential risk concerns once you have the opportunity to explain, but this problem makes it hard to get them to listen.
We have a real version of this problem when dealing with different sources of AI existential risk. People will latch onto one particular way things can go horribly wrong, or even one particular detailed scenario that leads to this, often choosing the one they find least plausible. Then they either:
- Explain why they think this particular scenario is dumb, thus making new entities that are smarter and more capable than humans is a perfectly safe thing to do.
- OR they then explain why we need to plan around preventing that particular scenario, or solving that particular failure mode, and dismiss that this runs smack into a different failure mode, often the exact opposite one.
The most common examples of problem #2 is when people have concerns about either Centralization of Power (often framing even ordinary government or corporate actions as a Dystopian Surveillance State or with similar language), or the Bad Person Being in Charge or Bad Nation Winning. Then they claim this overrides all other concerns, usually walking smack into misalignment (as in, they assume we will be able to get the AIs to do what we want, whereas we have no idea how to do that) and often also the gradual disempowerment problem.
The reason there is a clash there is that the solutions to the problems are in conflict. The things that solve one concern risk amplifying the other, but we need to solve both sides of the dilemma. Solving even one side is hard. Solving both at once, while many things work at cross-purposes, is very very hard.
That’s simply not true when trading off mundane harms versus existential risks. If you have a limited pool of resources to spend on mitigation, then of course you have to choose. And there are some things that do trade off – in particular, some short term solutions that would work now, but wouldn’t scale. But mostly there is no conflict, and things that help with one are neutral or helpful for the other.
1 comments
Comments sorted by top scores.
comment by Knight Lee (Max Lee) · 2025-04-26T00:51:06.706Z · LW(p) · GW(p)
Are there any suggestions for how to get this message across? To all those AI x-risk disbelievers?