Complete Class: Consequentialist Foundations
post by abramdemski · 2018-07-11T01:57:14.054Z · LW · GW · 37 commentsContents
Background My Motives Other Foundations Four Complete Class Theorems Basic CCT Removing Likelihoods (and other unfortunate assumptions) Utilitarianism Futarchy Conclusion None 37 comments
The fundamentals of Bayesian thinking have been justified in many ways over the years. Most people here have heard of the VNM axioms and Dutch Book arguments. Far fewer, I think, have heard of the Complete Class Theorems (CCT).
Here, I explain why I think of CCT as a more purely consequentialist foundation for decision theory. I also show how complete-class style arguments play a role is social choice theory, justifying utilitarianism and a version of futarchy. This means CCT acts as a bridging analogy between single-agent decisions and collective decisions, therefore shedding some light on how a pile of agent-like pieces can come together and act like one agent. To me, this suggests a potentially rich vein of intellectual ore.
I have some ideas about modifying CCT to be more interesting for MIRI-style decision theory, but I'll only do a little of that here, mostly gesturing at the problems with CCT which could motivate such modifications.
Background
My Motives
This post is a continuation of what I started in Generalizing Foundations of Decision Theory and Generalizing Foundations of Decision Theory II. The core motivation is to understand the justification for existing decision theory very well, see which assumptions are weakest, and see what happens when we remove them.
There is also a secondary motivation in human (ir)rationality: to the extent foundational arguments are real reasons why rational behavior is better than irrational behavior, one might expect these arguments to be helpful in teaching or training rationality. This is related to my criterion of consequentialism: the argument in favor of Bayesian decision theory should directly point to why it matters.
With respect to this second quest, CCT is interesting because Dutch Book and money-pump arguments point out irrationality in agents by exploiting the irrational agent. CCT is more amenable to a model in which you point out irrationality by helping the irrational agent. I am working on a more thorough expansion of that view with some co-authors.
Other Foundations
(Skip this section if you just want to know about CCT, and not why I claim it is better than alternatives.)
I give an overview of many proposed foundational arguments for Bayesianism in the first post in this series. I called out Dutch Book and money-pump arguments as the most promising, in terms of motivating decision theory only from "winning". The second post in the series attempted to motivate all of decision theory from only those two arguments (extending work of Stuart Armstrong along those lines), and succeeded. However, the resulting argument was in itself not very satisfying. If you look at the structure of the argument, it justifies constraints on decisions via problems which would occur in hypothetical games involving money. Many philosophers have argued that the Dutch Book argument is in fact a way of illustrating inconsistency in belief, rather than truly an argument that you must be consistent or else. I think this is right. I now think this is a serious flaw behind both Dutch Book and money-pump arguments. There is no pure consequentialist reason to constrain decisions based on consistency relationships with thought experiments.
The position I'm defending in the current post has much in common with the paper Actualist Rationality by C. Manski. My disagreement with him lies in his dismissal of CCT as yet another bad argument. In my view, CCT seems to address his concerns almost precisely!
Caveat --
Dutch Book arguments are fairly practical. Betting with people, or asking them to consider hypothetical bets, is a useful tool. It may even be what convinces someone to use probabilities to represent degrees of belief. However, the argument falls apart if you examine it too closely, or at least requires extra assumptions which you have to argue in a different way. Simply put, belief is not literally the same thing as willingness to bet. Consequentialist decision theories are in the business of relating beliefs to actions, not relating beliefs to betting behavior.
Similarly, money-pump arguments can sometimes be extremely practical. The resource you're pumped of doesn't need to be money -- it can simply be the cost of thinking longer. If you spin forever between different options because you prefer strawberry ice cream to chocolate and chocolate to vanilla and vanilla to strawberry, you will not get any ice cream. However, the set-up to money pump assumes that you will not notice this happening; whatever the extra cost of indecision is, it is placed outside of the considerations which can influence your decision.
So, Dutch Book "defines" belief as willingness-to-bet, and money-pump "defines" preference as willingness-to-pay; in doing so, both arguments put the justification of decision theory into hypothetical exploitation scenarios which are not quite the same as the actual decisions we face. If these were the best justifications for consequentialism we could muster, I would be somewhat dissatisfied, but would likely leave it alone. Fortunately, a better alternative exists: complete class theorems.
Four Complete Class Theorems
For a thorough introduction to complete class theorems, I recommend Peter Hoff's course notes. I'm going to walk through four complete class theorems dealing with what I think are particularly interesting cases. Here's a map:
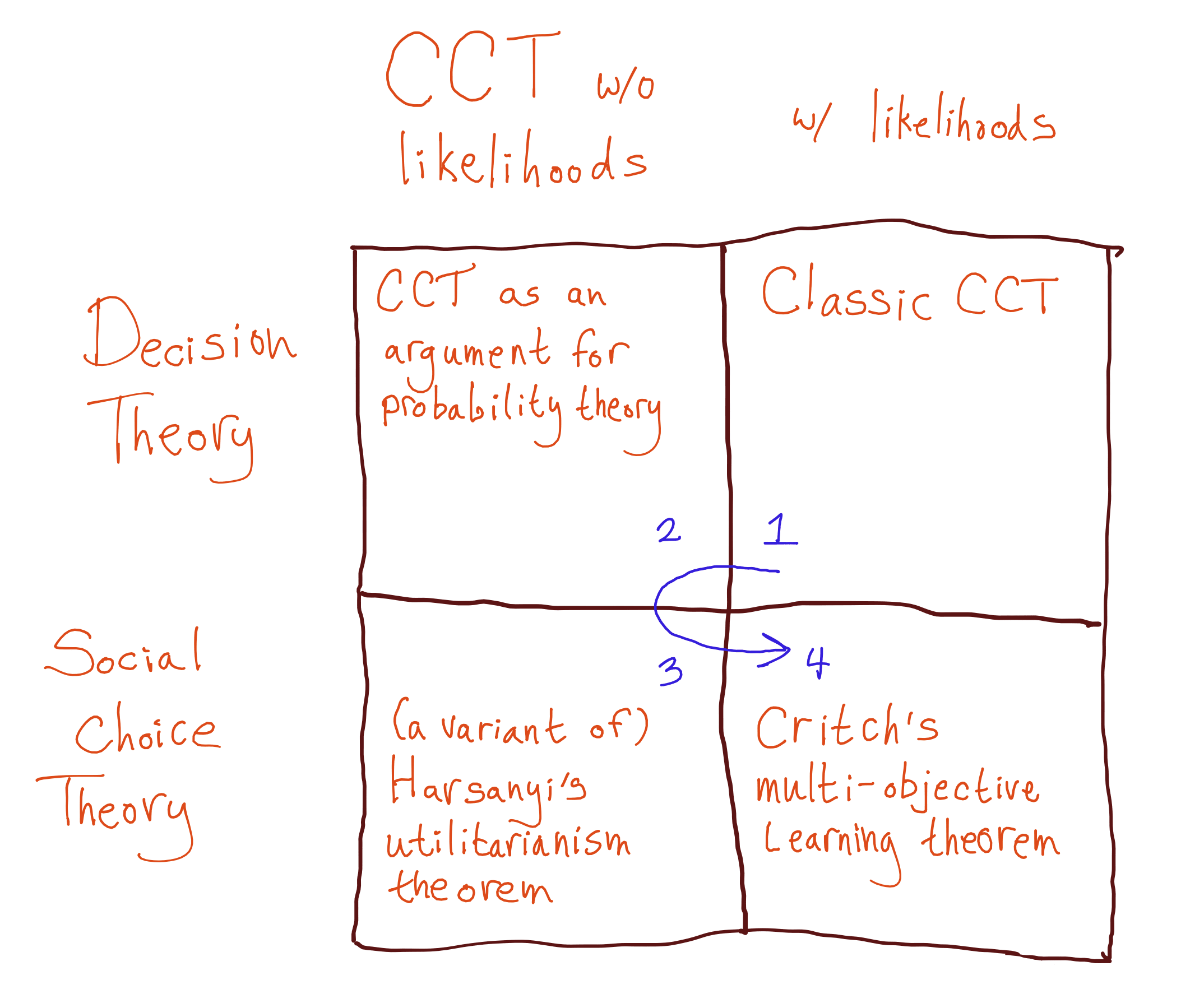
In words: first we'll look at the standard setup, which assumes likelihood functions. Then we will remove the assumption of likelihood functions, since we want to argue for probability theory from scratch. Then, we will switch from talking about decision theory to social choice theory, and use CCT to derive a variant of Harsanyi's utilitarian theorem, AKA Harsanyi's social aggregation theorem, which tells us about cooperation between agents with common beliefs (but different utility functions). Finally, we'll add likelihoods back in. This gets us a version of Critch's multi-objective learning framework, which tells us about cooperation between agents with different beliefs and different utility functions.
I think of Harsanyi's utilitarianism theorem as the best justification for utilitarianism, in much the same way that I think of CCT as the best justification for Bayesian decision theory. It is not an argument that your personal values are necessarily utilitarian-altruism. However, it is a strong argument for utilitarian altruism as the most coherent way to care about others; and furthermore, to the extent that groups can make rational decisions, I think it is an extremely strong argument that the group decision should be utilitarian. AlexMennen discusses the theorem and implications for CEV here [LW · GW].
I somewhat jokingly think of Critch's variation as "Critch's Futarchy theorem" -- in the same way that Harsanyi shows that utilitarianism is the unique way to make rational collective decisions when everyone agrees about the facts on the ground, Critch shows that rational collective decisions when there is disagreement must involve a betting market. However, Critch's conclusion is not quite Futarchy. It is more extreme: in Critch's framework, agents bet their voting stake rather than money! The more bets you win, the more control you have over the system; the more bets you lose, the less your preferences will be taken into account. This is, perhaps, rather harsh in comparison to governance systems we would want to implement. However, rational agents of the classical Bayesian variety are happy to make this trade.
Without further adieu, let's dive into the theorems.
Basic CCT
We set up decision problems like this:
- is the set of possible states of the external world.
- is the set of possible observations.
- is the set of actions which the agent can take.
- is a likelihood function, giving the probability of an observation under a particular world-state .
- is a set of decision rules. For , outputs an action. Stochastic decision rules are allowed, though, in which case we should really think of it as outputting an action probability.
- , the loss function, takes a world and an action and returns a real-valued "loss". encodes preferences: the lower the loss, the better. One way of thinking about this is that the agent knows how its actions play out in each possible world; the agent is only uncertain about consequences because it doesn't know which possible world is the case.
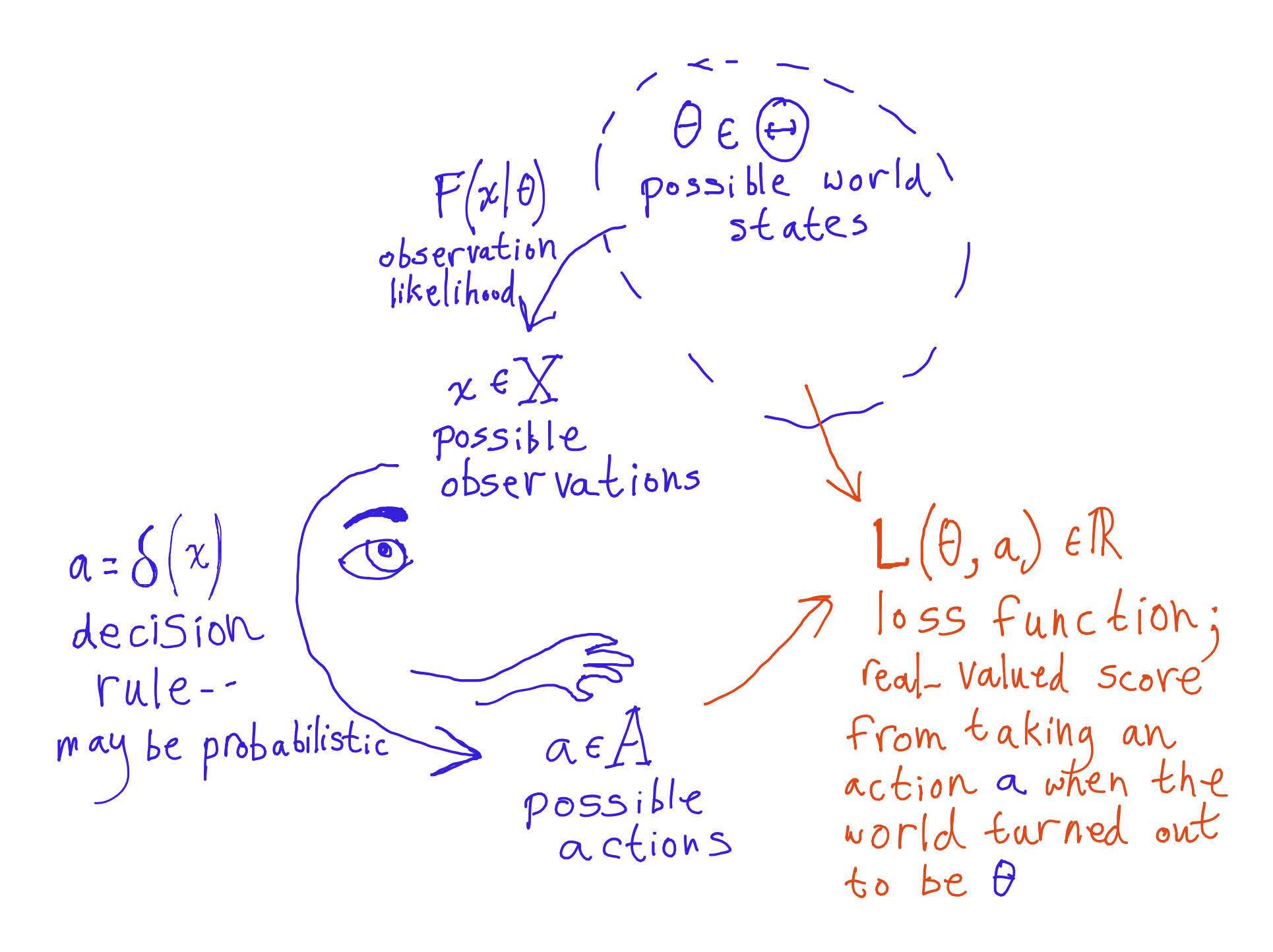
In this post, I'm only going to deal with cases where and are finite. This is not a minor theoretical convenience -- things get significantly more complicated with unbounded sets, and the justification for Bayesianism in particular is weaker. So, it's potentially quite interesting. However, there's only so much I want to deal with in one post.
Some more definitions:
The risk of a policy in a particular true world-state: =.
A decision rule is a pareto improvement over another rule if and only if for all , and strictly > for at least one. This is typically called dominance in treatments of CCT, but it's exactly parallel to the idea of pareto-improvement from economics and game theory: everyone is at least as well off, and at least one person is better off. An improvement which harms no one. The only difference here is that it's with respect to possible states, rather than people.
A decision rule is admissible if and only if there is no pareto improvement over it. The idea is that there should be no reason not to take pareto improvements, since you're only doing better no matter what state the world turns out to be in. (We could also call this pareto-optimal.)
A class of decision rules is a complete class if and only if for any rule not in , , there exists a rule in which is a pareto improvement. Note, not every rule in a complete class will be admissible itself. In particular, the set of all decision rules is a complete class. So, the complete class is a device for proving a weaker result than admissibility. This will actually be a bit silly for the finite case, because we can characterize the set of admissible decision rules. However, it is the namesake of complete class theorems in general; so, I figured that it would be confusing not to include it here.
Given a probability distribution on world-states, the Bayes risk is the expected risk over worlds, IE: .
A probability distribution is non-dogmatic when for all .
A decision rule is bayes-optimal with respect to a distribution if it minimizes Bayes risk with respect to . (This is usually called a Bayes rule with respect to , but that seems fairly confusing, since it sounds like "Bayes' rule" aka Bayes' theorem.)
THEOREM: When and are finite, decision rules which are bayes-optimal with respect to a non-dogmatic are admissible.
PROOF: On the one hand, if is Bayes-optimal with respect to non-dogmatic , it minimizes the expectation . Since for each world, any pareto-improvement (which must be strictly better in some world, and not worse in any) must decrease this expectation. So, must be minimizing the expectation if it is Bayes-optimal.
THEOREM: (basic CCT) When and are finite, a decision rule is admissible if and only if it is Bayes-optimal with respect to some prior .
PROOF: If is admissible, we wish to show that it is Bayes-optimal with respect to some .
A decision rule has a risk in each world; think of this as a vector in . The set of achievable risk vectors in (given by all ) is convex, since we can make mixed strategies between any two decision rules. It is also closed, since and are finite. Consider a risk vector as a point in this space (not necessarily achievable by any ). Define the lower quadrant to be the set of points which would be pareto improvements if they were achievable by a decision rule. Note that for an admissible decision rule with risk vector , and are disjoint. By the hyperplane separation theorem, there is a separating hyperplane between and . We can define by taking a vector normal to the hyperplane and normalizing it to sub to one. This is a prior for which is Bayes-optimal, establishing the desired result.
If this is confusing, I again suggest Peter Hoff's course notes. However, here is a simplified illustration of the idea for two worlds, four pure actions, and no observations:
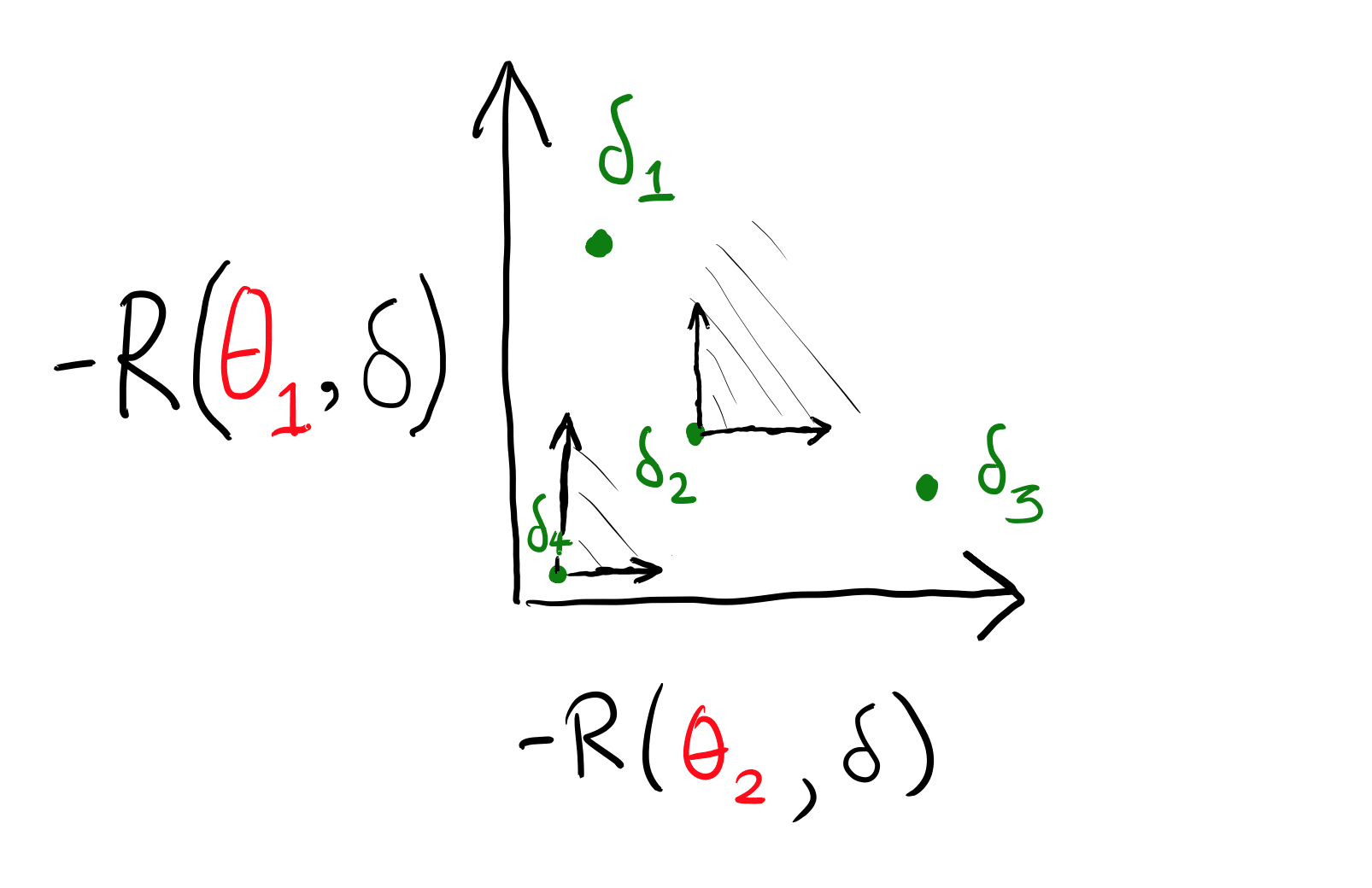
(I used because I am more comfortable with thinking of "good" as "up", IE, thinking in terms of utility rather than loss.)
The black "corners" coming from and show the beginning of the Q() set for those two points. (You can imagine the other two, for and .) Nothing is pareto-dominated except for , which is dominated by everything. In economics terminology, the first three actions are on the pareto frontier. In particular, is not pareto-dominated. Putting some numbers to it, could be worth (2,2), that is, worth two in each world. could be worth (1,10), and could be worth (10,1). There is no prior over the two worlds in which a Bayesian would want to take action . So, how do we rule it out through our admissibility requirement? We add mixed strategies:
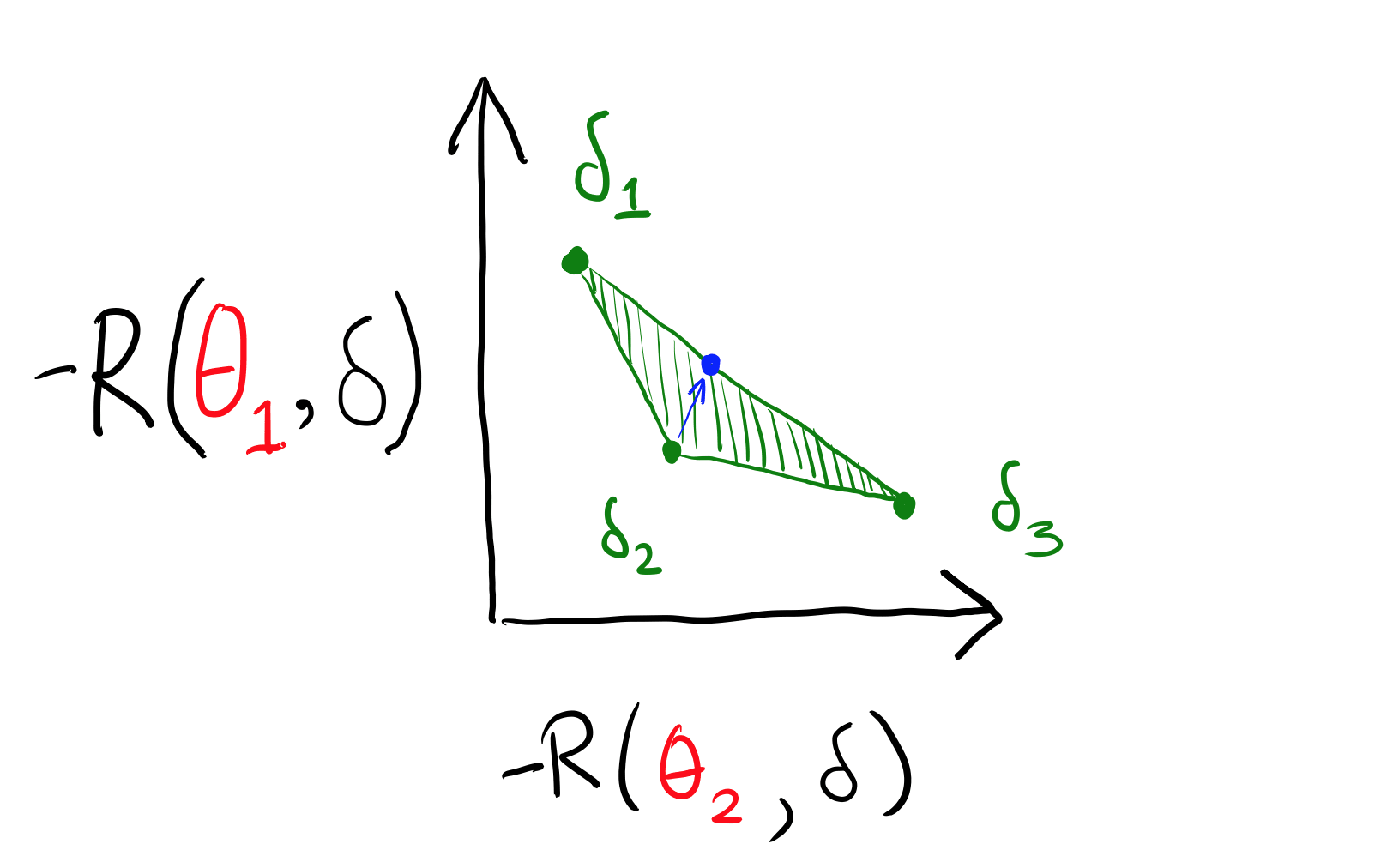
Now, there's a new pareto frontier: the line stretching between and , consisting of strategies which have some probability of taking those two actions. Everything else is pareto-dominated. An agent who starts out considering can see that mixing between and is just a better idea, no matter what world they're in. This is the essence of the CCT argument.
Once we move to the pareto frontier of the set of mixed strategies, we can draw the separating hyperplanes mentioned in the proof:
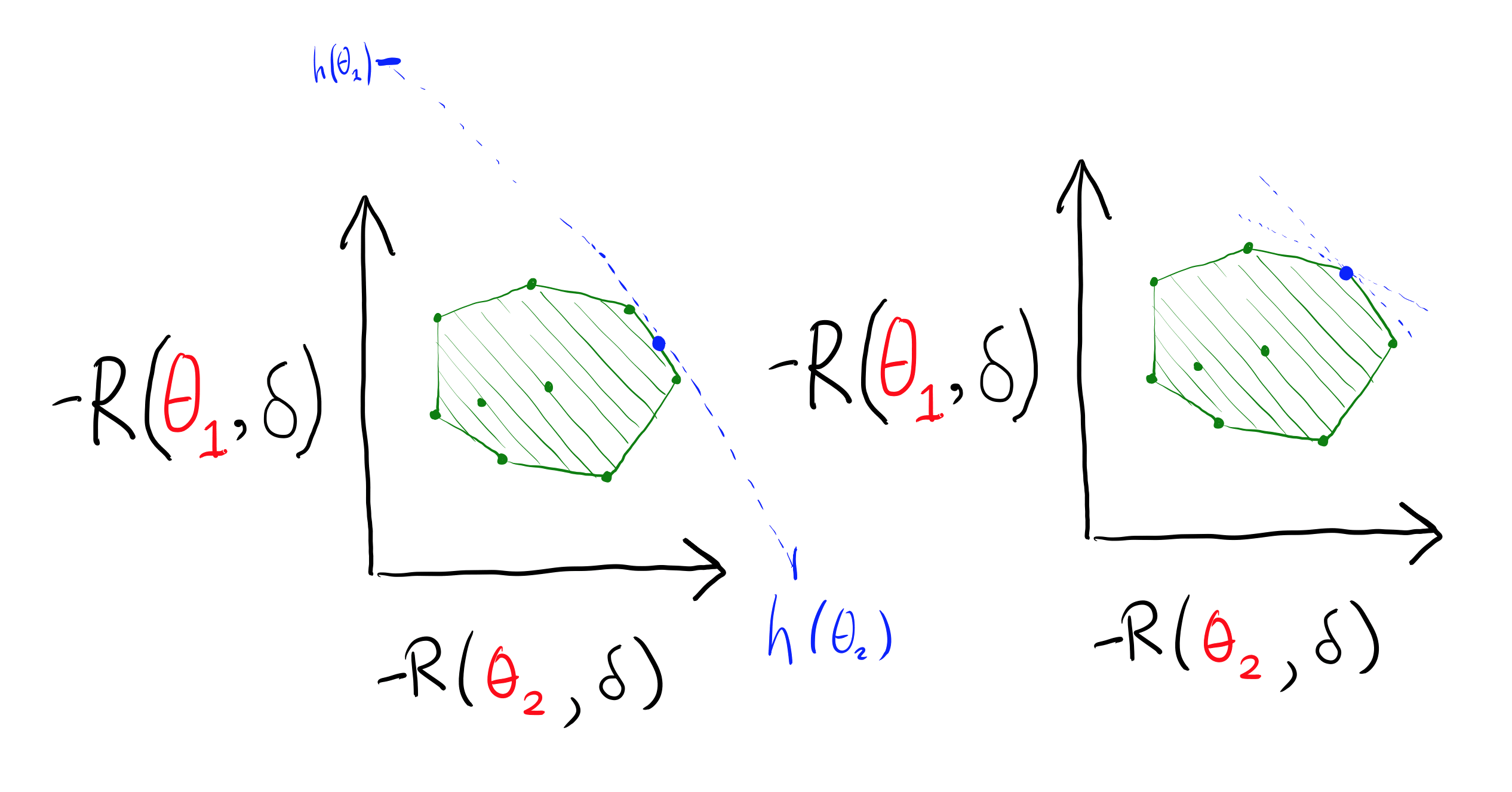
(There may be a unique line, or several separating lines.) The separating hyperplane allows us to derive a (non-dogmatic) prior which the chosen decision rule is consistent with.
Removing Likelihoods (and other unfortunate assumptions)
Assuming the existence of a likelihood function is rather strange, if our goal is to argue that agents should use probability and expected utility to make decisions. A purported decision-theoretic foundation should not assume that an agent has any probabilistic beliefs to start out.
Fortunately, this is an extremely easy modification of the argument: restricting to either be zero or one is just a special case of the existing theorem. This does not limit our expressive power. Previously, a world in which the true temperature is zero degrees would have some probability of emitting the observation "the temperature is one degree", due to observation error. Now, we consider the error a part of the world: there is a world where the true temperature is zero and the measurement is one, as well as one where the true temperature is zero and the measurement is zero, and so on.
Another related concern is the assumption that we have mixed strategies, which are described via probabilities. Unfortunately, this is much more central to the argument, so we have to do a lot more work to re-state things in a way which doesn't assume probabilities directly. Bear with me -- it'll be a few paragraphs before we've done enough work to eliminate the assumption that mixed strategies are described by probabilities.
It will be easier to first get rid of the assumption that we have cardinal-valued loss . Instead, assume that we have an ordinal preference for each world, . We then apply the VNM theorem within each , to get a cardinal-valued utility within each world. The CCT argument can then proceed as usual.
Applying VNM is a little unsatisfying, since we need to assume the VNM axioms about our preferences. Happily, it is easy to weaken the VNM axioms, instead letting the assumptions from the CCT setting do more work. A detailed write-up of the following is being worked on, but to briefly sketch:
First, we can get rid of the independence axiom. A mixed strategy is really a strategy which involves observing coin-flips. We can put the coin-flips inside the world (breaking each into more sub-worlds in which coin-flips come out differently). When we do this, the independence axiom is a consequence of admissibility; any violation of independence can be undone by a pareto improvement.
Second, having made coin-flips explicit, we can get rid of the axiom of continuity. We apply the VNM-like theorem from the paper Additive representation of separable preferences over infinite products, by Marcus Pivato. This gives us cardinal-valued utility functions, but without the continuity axiom, our utility may sometimes be represented by infinities. (Specifically, we can consider surreal-numbered utility as the most general case.) You can assume this never happens if it bothers you.
More importantly, at this point we don't need to assume that mixed strategies are represented via pre-existing probabilities anymore. Instead, they're represented by the coins.
I'm fairly happy with this result, and apologize for the brief treatment. However, let's move on for now to the comparison to social choice theory I promised.
Utilitarianism
I said that are "possible world states" and that there is an "agent" who is "uncertain about which world-state is the case" -- however, notice that I didn't really use any of that in the theorem. What matters is that for each , there is a preference relation on actions. CCT is actually about compromising between different preference relations.
If we drop the observations, we can interpret the as people, and the as potential collective actions. The are potential social choices, which are admissible when they are pareto-efficient with respect to individual's preferences.
Making the hyperplane argument as before, we get a which places positive weight on each individual. This is interpreted as each individual's weight in the coalition. The collective decision must be the result of a (positive) linear combination of each individual's cardinal utilities -- and those cardinal utilities can in turn be constructed via an application of VNM to individual ordinal preferences. This result is very similar to Harsanyi's utilitarianism theorem.
This is not only a nice argument for utilitarianism, it is also an amusing mathematical pun, since it puts utilitarian "social utility" and decision-theoretic "expected utility" into the same mathematical framework. Just because both can be derived via pareto-optimality arguments doesn't mean they're necessarily the same thing, though.
Harsanyi's theorem is not the most-cited justification for utilitarianism. One reason for this may be that it is "overly pragmatic": utilitarianism is about values; Harsanyi's theorem is about coherent governance. Harsanyi's theorem relies on imagining a collective decision which has to compromise between everyone's values, and specifies what it must be like. Utilitarians don't imagine such a global decision can really be made, but rather, are trying to specify their own altruistic values. Nonetheless, a similar argument applies: altruistic values are enough of a "global decision" that, hypothetically, you'd want to run the Harsanyi argument if you had descriptions of everyone's utility functions and if you accepted pareto improvements. So there's an argument to be made that that's still what you want to approximate.
Another reason, mentioned by Jessicata in the comments, is that utilitarians typically value egalitarianism. Harsanyi's theorem only says that you must put some weight on each individual, not that you have to be fair. I don't think this is much of a problem -- just as CCT argues for "some" prior, but realistic agents have further considerations which make them skew towards maximally spread out priors, CCT in social choice theory can tell us that we need some weights, and there can be extra considerations which push us toward egalitarian weights. Harsanyi's theorem is still a strong argument for a big chunk of the utilitarian position.
Futarchy
Now, as promised, Critch's 'futarchy' theorem.
If we add observations back in to the multi-agent interpretation, associates each agent with a probability distribution on observations. This can be interpreted as each agent's beliefs. In the paper Toward Negotiable Reinforcement Learning, Critch examined pareto-optimal sequential decision rules in this setting. Not only is there a function which gives a weight for each agent in the coalition, but this is updated via Bayes' Rule as observations come in. The interpretation of this is that the agents in the coalition want to bet on their differing beliefs, so that agents who make more correct bets gain more influence over the decisions of the coalition.
This differs from Robin Hanson's futarchy, whose motto "vote on values, but bet beliefs" suggests that everyone gets an equal vote -- you lose money when you bet, which loses you influence on implementation of public policy, but you still get an equal share of value. However, Critch's analysis shows that Robin's version can be strictly improved upon, resulting in Critch's version. (Also, Critch is not proposing his solution as a system of governance, only as a notion of multi-objective learning.) Nonetheless, the spirit still seems similar to Futarchy, in that the control of the system is distributed based on bets.
If Critch's system seems harsh, it is because we wouldn't really want to bet away all our share of the collective value, nor do we want to punish those who would bet away all their value too severely. This suggests that we (a) just wouldn't bet everything away, and so wouldn't end up too badly off; and (b) would want to still take care of those who bet their own value away, so that the consequences for those people would not actually be so harsh. Nonetheless, we can also try to take the problem more seriously and think about alternative formulations which seem less strikingly harsh.
Conclusion
One potential research program which may arise from this is: take the analogy between social choice theory and decision theory very seriously. Look closely at more complicated models of social choice theory, including voting theory and perhaps mechanism design. Understand the structure of rational collective choice in detail. Then, try to port the lessons from this back to the individual-agent case, to create decision theories more sophisticated than simple Bayes. Mirroring this on the four-quadrant diagram from early on:

And, if you squint at this diagram, you can see the letters "CCT".
(Closing visual pun by Caspar Österheld.)
37 comments
Comments sorted by top scores.
comment by jessicata (jessica.liu.taylor) · 2018-07-13T08:20:50.224Z · LW(p) · GW(p)
Making the hyperplane argument as before, we get a π which places positive weight on each individual. This is interpreted as each individual's weight in the coalition. The collective decision must be the result of a (positive) linear combination of each individual's cardinal utilities -- and those cardinal utilities can in turn be constructed via an application of VNM to individual ordinal preferences.
What this says is that any Pareto-optimal outcome can be rationalized as maximizing a positive linear combination of individual utilities, not that it can be generated in this way. For example, Nash bargaining results in Pareto optimal outcomes, yet it can't be specified as the unique maximization of some positive linear combination of individual utilities. After running the algorithm, the result is optimal according to some linear combination of individual utilities, but this is a rationalization rather than the actual generation procedure. (This also works as a criticism of Bayesianism)
Replies from: abramdemski, cousin_it↑ comment by abramdemski · 2018-07-16T19:04:49.929Z · LW(p) · GW(p)
I basically agree with this criticism, and would like to understand what the alternative to Bayesian decision theory which comes out of the analogy would be.
↑ comment by cousin_it · 2018-07-13T08:33:24.797Z · LW(p) · GW(p)
I think when several AIs with bounded utility functions decide to merge, they can reach any point on the Pareto frontier like this:
1) Allow linear combinations of utility functions. This lets you reach all "pointy" points.
2) Allow making a tuple of functions of type (1) whose values should be compared lexicographically (e.g. "maximize U+V, break ties by maximizing U"). This lets you reach some points on the edges of flat parts.
3) Allow the merging process to choose randomly which function of type (2) to give to the merged AI. This lets you reach the rest of the points on flat parts.
That's a bit complicated, but I don't think there's a simpler way.
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2018-07-13T09:38:15.225Z · LW(p) · GW(p)
I don't see why 2 is necessary given that any point on the Pareto frontier is a mixture of pointy points (intuition for this: any point on the face of a polyhedron is a mixture of that face's corners). In any case, I agree with the basic mathematical point that you can get any Pareto optimal mixture of outcomes by mixing between non-negative linear combinations of utility functions.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-13T09:41:46.231Z · LW(p) · GW(p)
Well, I was imagining a Pareto frontier that changes smoothly from flat to curved. Then we can't quite get a pointy point exactly on the edge of the flat part. That's what 2 is for, it gives us some of these points (though not all). But I guess that doesn't matter if things are finite enough.
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2018-07-13T09:47:10.985Z · LW(p) · GW(p)
Ok, that seems right.
comment by jessicata (jessica.liu.taylor) · 2018-07-13T07:59:24.217Z · LW(p) · GW(p)
I think the basic CCT theorem is wrong. Consider a game where there is a coin that will be flipped, and you are going to predict the probability that this coin comes up heads. You will be scored using a proper scoring rule, such as square error (i.e. you get loss p^2 if it's heads and (1-p)^2 if it's tails). The policy of always saying p = 0 is admissible, since no other policy is better when the coin always comes up tails. But it is not the result of any non-dogmatic prior (which would say a probability strictly between 0 and 1).
I didn't understand your proof. I get the argument for why there's a hyperplane but can't the hyperplane be parallel to one of the axes, so it never intersects that one?
Replies from: abramdemski↑ comment by abramdemski · 2018-07-18T21:17:57.826Z · LW(p) · GW(p)
Ah, yeah, you're right. The separating hyperplane theorem only gives us , and I was assuming <.
I think "admissible if and only if non-dogmatic" may still hold as I stated it, because I don't see how to set up an example like the one you give when is finite. I'm editing the post anyway, since (1) I don't know how to how that at the moment, and (2) the if and only if falls apart for infinite action sets as in your example anyway, which makes it kind of feel "wrong in spirit".
comment by cousin_it · 2018-07-11T11:16:15.629Z · LW(p) · GW(p)
Yeah, I explored this direction pretty thoroughly a few years ago. The simplest way is to assume that agents don't have probabilities, only utility functions over combined outcomes, where a "combined outcome" is a combination of outcomes in all possible worlds. (That also takes care of updating on observations, we just follow UDT instead.) Then if we have two agents with utility functions U and V over combined outcomes, any Pareto-optimal way of merging them must behave like an agent with utility function aU+bV for some a and b. The theory sheds no light on choosing a and b, so that's as far as it goes. Do you think there's more stuff to be found?
Replies from: abramdemski, abramdemski↑ comment by abramdemski · 2018-07-11T22:58:58.245Z · LW(p) · GW(p)
It sounds like you considered a more general setting than I am an the moment. I want to eventually move to that kind of "combined outcome" setting, but first, I want to understand more classical preference structures and break things one at a time.
Do you think your version sheds any light on value learning in UDT? I had a discussion with Alex Appel about this, in which it seemed like you have a "nosy neighbors" problem, where a potential set of values may care about what happens even in worlds where different values hold; but, this problem seemed to be bounded by such other-world preferences acting like beliefs. For example, you could imagine a UDT agent with world-models in which either vegetarianism or carnivorism are right (which somehow make different predictions). Each set of preferences can either be "nosy" (cares what happens regardless of which facts end up true) or "non-nosy" (each preference set only cares about what happens in their own world -- vegetarianism cares about the amount of meat eaten in veg-world, and carnivorism cares about amount of meat eaten in carn-world).
The claim which seemed plausible was that nosiness has some kind of balancing behavior which acts like probability: putting some of your caring measure on other worlds reduces your caring measure on your own.
Anything structurally similar in your framework?
Replies from: cousin_it↑ comment by cousin_it · 2018-07-11T23:30:44.313Z · LW(p) · GW(p)
By nosy preferences, do you mean something like this?
"I am grateful to Zeus for telling me that cows have feelings. Now I know that, even if Zeus had told me that cows are unfeeling brutes, eating them would still be wrong."
But that just seems irrational and not worth modeling. Or do you have some other kind of situation in mind?
Replies from: Diffractor, abramdemski↑ comment by Diffractor · 2018-07-12T03:54:22.837Z · LW(p) · GW(p)
Pretty much that, actually. It doesn't seem too irrational, though. Upon looking at a mathematical universe where torture was decided upon as a good thing, it isn't an obvious failure of rationality to hope that a cosmic ray flips the sign bit of the utility function of an agent in there.
The practical problem with values that care about other mathematical worlds, however, is that if the agent you built has a UDT prior over values, it's an improvement (from the perspective of the prior) for the nosy neigbors/values that care about other worlds, to dictate some of what happens in your world (since the marginal contribution of your world to the prior expected utility looks like some linear combination of the various utility functions, weighted by how much they care about your world) So, in practice, it'd be a bad idea to build a UDT value learning prior containing utility functions that have preferences over all worlds, since it'd add a bunch of extra junk from different utility functions to our world if run.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-12T07:02:07.363Z · LW(p) · GW(p)
Are you talking about something like this?
"I'm grateful to HAL for telling me that cows have feelings. Now I'm pretty sure that, even if HAL had a glitch and mistakenly told me that cows are devoid of feeling, eating them would still be wrong."
That's valid reasoning. The right way to formalize it is to have two worlds, one where eating cows is okay and another where eating cows is not okay, without any "nosy preferences". Then you receive probabilistic evidence about which world you're in, and deal with it in the usual way.
↑ comment by abramdemski · 2018-07-13T02:45:29.183Z · LW(p) · GW(p)
I'm not clear on whether it is rational or not. It seems like behavior we don't want from a value learner, but I was curious about how "inevitable" it is from attempts to mix updatelessness with value learning. (Perhaps it is a really simple point, but I haven't thought it entirely through, still.)
Replies from: cousin_it↑ comment by cousin_it · 2018-07-13T06:51:46.888Z · LW(p) · GW(p)
I have a recent result [LW · GW] about value learning in UDT, it turns out to work very nicely and doesn't suffer from the problem you describe.
↑ comment by abramdemski · 2018-07-13T02:43:00.916Z · LW(p) · GW(p)
Another way in which there might be something interesting in this direction is if we can further formalize Scott's argument about when Bayesian probabilities are appropriate and inappropriate [AF · GW], which is framed in terms of pareto-style justifications of bayesianism.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-13T07:05:11.397Z · LW(p) · GW(p)
Well, the version of UDT I'm using doesn't have probabilities, only a utility function over combined outcomes. It's just a simpler way to think about things. I think you and Scott might be overestimating the usefulness of probabilities. For example, in the Sleeping Beauty problem, the coinflip is "spacelike separated" from you (under Scott's peculiar definition), but it can be assigned different "probabilities" depending on your utility function over combined outcomes.
Replies from: abramdemski↑ comment by abramdemski · 2018-07-13T21:38:19.924Z · LW(p) · GW(p)
That seems good to understand better in itself, but it isn't a crux for the argument. Whether you've got "probabilities" or a "caring measure" or just raw utility which doesn't reduce to anything like that, it still seems like you're justifying it with Pareto-type arguments. Scott's claim is that Pareto-type arguments won't apply if you correctly take into account the way in which you have control over certain things. I'm not sure if that makes any sense, but basically the question is whether CCT can make sense in a logical setting where you may have self-referential sentences and so on.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-15T10:58:46.157Z · LW(p) · GW(p)
That's a great question. My current (very vague) idea is that we might need to replace first order logic with something else. A theory like PA is already updateful, because it can learn that a sentence is true, so trying to build updateless reasoning on top of it might be as futile as trying to build updateless reasoning on top of probabilities. But I have no idea what an updateless replacement for first order logic could look like.
Replies from: abramdemski↑ comment by abramdemski · 2018-07-16T18:40:50.244Z · LW(p) · GW(p)
Another part of the idea (not fully explained in Scott's post I referenced earlier) is that nonexploited bargaining (AKA bargaining away from the pareto fronteir AKA cooperating with agents with different notions of fairness) provides a model of why agents should not just take pareto improvements all the time, and may therefore be a seed of "non-Bayesian" decision theory (in so far as Bayes is about taking pareto improvements).
comment by romeostevensit · 2018-07-13T07:28:50.879Z · LW(p) · GW(p)
I think specifically porting quasi-transitivity from social choice back to decision theory is an interesting direction. i.e. VNM Axiom 2 is not sufficient for describing how preference transitivity might work. Some prior work referencing Harsanyi's proposed solution here: http://www.harveylederman.com/Aggregating%20Extended%20Preferences.pdf
comment by Hazard · 2018-07-12T18:05:26.729Z · LW(p) · GW(p)
A decision rule δ∗ is a pareto improvement over another rule δ if and only if R(θ,δ)≤R(θ,δ∗) for all θ, and strictly < for at least one.
Small typo, I think you meant to switch the order of the two risk terms. Otherwise we say that a decision rule is a Pareto improvement if it results in more risk/a higher loss score.
Replies from: abramdemski↑ comment by abramdemski · 2018-07-16T18:42:11.033Z · LW(p) · GW(p)
Thanks!
comment by mxxun (mrkun) · 2024-12-05T16:32:11.712Z · LW(p) · GW(p)
The link moved; here is the current location of the lecture in question and here is the course page.
Replies from: abramdemski↑ comment by abramdemski · 2024-12-05T16:34:09.441Z · LW(p) · GW(p)
Thanks!
comment by martinkunev · 2024-10-29T00:56:38.036Z · LW(p) · GW(p)
When we do this, the independence axiom is a consequence of admissibility
Can you elaborate on this? It seems that the independence axiom becomes true by assuming that all probabilities are independent and each can thus be replaced by a sequence of coin tosses. Am I misunderstanding something?
comment by selylindi · 2018-10-19T05:28:05.659Z · LW(p) · GW(p)
in Critch's framework, agents bet their voting stake rather than money! The more bets you win, the more control you have over the system; the more bets you lose, the less your preferences will be taken into account.
If I may be a one-note piano (as it's all I've talked about lately on LW), this sounds extremely similar to the "ophelimist democracy" I was pushing. I've since streamlined the design and will try to publish a functional tool for it online next year, and then aim to get some small organizations to test it out.
In brief, the goal was to design a voting system with a feedback loop to keep it utilitarian in the sense you've discussed above, but also utilitarian in the Bentham/Sidgwick sense. So that you don't have to read the linked blog post, the basic steps in voting in an organization run on "ophelimist democracy" are as follows, with the parts that sound like Critch's framework in italics:
1. Propose goals.
2. Vote on the goals/values and use the results to determine the relative value of each goal.
3. Propose policy ideas.
4. Bet on how well each policy will satisfy each goal.
5. Every bet is also automatically turned into a vote. (This is used to evade collusive betting.)
6. The policy with highest vote total * weighted bet value is enacted.
7. People are periodically polled regarding how satisfied they are with the goals, and the results are used to properly assign weights to people's bets.
comment by jessicata (jessica.liu.taylor) · 2018-07-13T08:25:33.888Z · LW(p) · GW(p)
I think you are using "utilitarianism" in a non-standard way. From SEP:
Equal Consideration = in determining moral rightness, benefits to one person matter just as much as similar benefits to any other person (= all who count count equally).
CCT definitely does not imply any kind of egalitarianism.
Replies from: abramdemski↑ comment by abramdemski · 2018-07-16T18:59:05.625Z · LW(p) · GW(p)
Editing to clarify.
comment by jessicata (jessica.liu.taylor) · 2018-07-13T08:07:13.104Z · LW(p) · GW(p)
We then apply the VNM theorem within each θ, to get a cardinal-valued utility within each world. The CCT argument can then proceed as usual.
VNM assumes you have preferences over lotteries, which imply belief in frequencies/probabilities.
Replies from: abramdemski↑ comment by abramdemski · 2018-07-18T20:15:02.379Z · LW(p) · GW(p)
In the context in the post, I'm saying that before we get rid of an assumption of probabilities, it is easier to first get rid of the assumption that we have a real-valued L (proving it from other assumptions instead). We do this by applying VNM, still assuming mixed strategies are described by probabilities. I finally get rid of that assumption a few paragraphs later. I edited the post a little to try and clarify.
comment by rk · 2018-07-12T14:29:27.580Z · LW(p) · GW(p)
I'd like to check my understanding of the last two transitions a little. If someone could check the below I'd be grateful.
When we move to the utilitarianism-like quadrant, individual actors have preference ordering over actions (not states). So if they were the kind of utilitarians we often think about (with utilities attached to states), that would be something like ordering the actions by their expected utility (as they see it). So we actually get something like combined epistemic modesty and utilitarianism here?
Then, when we move to the futarchy-like quadrant, we additionally elicit probabilities for (all possible?) observations from each agent. We give them less and less weight in the decision calculus when their predictions are wrong. This stops agents that have crazy beliefs reliably voting us into world states they wouldn't like anyway (though I think that world states aren't present in the formalism in this quadrant).
Does the above paragraph mean that people with unique preferences and crazy beliefs eventually end up without having their preferences respected (whereas someone with unique preferences and accurate beliefs would still have their preferences respected)?
(Some extra questions. I'm more interested in answers to questions above the line, so feel free to skip these)
Also, do we have to treat the agents as well-calibrated across all domains? Or is the system able to learn that their thoughts should be given weight in some circumstances and not others? The reason I think we can't do that is because it seems like there is just one number that represents the agent's overall accuracy (theta_i)
A possible fix to the above is that individual agents could do this subject-specific evaluation of other agents and would update their credences based on partially-accurate agents, thus the information still gets preserved. But I think this leads to another problem: could there be a double-counting when both Critch's mechanism and other agents pick up on the accuracy of an agent? Or are we fine because agents who over-update on others' views also get their vote penalised?
Replies from: abramdemski↑ comment by abramdemski · 2018-07-18T21:41:14.022Z · LW(p) · GW(p)
Does the above paragraph mean that people with unique preferences and crazy beliefs eventually end up without having their preferences respected (whereas someone with unique preferences and accurate beliefs would still have their preferences respected)?
Yes. This might be too harsh. The "libertarian" argument in favor of it is: who are you to keep someone from betting away all of their credit in the system? If you make a rule preventing this, agents will tend to want to find some way around it. If you just give some free credit to agents who are completely out, this harms the calibration of the system by reducing the incentive to be sane about your bets.
On the other hand, there may well be a serious game-theoretic reason why it is "too harsh": someone who is getting to cooperation from the system has no reason to cooperate in turn. I'm curious if a CCT-adjacent formalism could capture this (or some other reason to be gentler). That would be the kind of thing which might have interesting analogues when we try to import insights back into decision theory.
Also, do we have to treat the agents as well-calibrated across all domains? Or is the system able to learn that their thoughts should be given weight in some circumstances and not others?
In the formalism, no, you just win or lose points across all domains. Realistically, it seems prudent to introduce stuff like that.
A possible fix to the above is that individual agents could do this subject-specific evaluation of other agents and would update their credences based on partially-accurate agents, thus the information still gets preserved.
That's exactly what could happen in a logical-induction like setting.
could there be a double-counting when both Critch's mechanism and other agents pick up on the accuracy of an agent?
There might temporarily be all sorts of crazy stuff like this, but we know it would (somehow) self-correct eventually.
Replies from: rk↑ comment by rk · 2018-07-20T09:58:05.980Z · LW(p) · GW(p)
On the other hand, there may well be a serious game-theoretic reason why it is "too harsh": someone who is getting to cooperation from the system has no reason to cooperate in turn.
Is there a typo here? ("getting to cooperation" -> "getting no cooperation"). And the idea is that there are other ways of making an impact on the world than the decisions of the "futarchy", so people who have no stake in the futarchy could mess things up other ways, right?
comment by Said Achmiz (SaidAchmiz) · 2018-07-16T22:34:26.716Z · LW(p) · GW(p)
Meta:
If you’re going to use giant pictures in your posts (and I don’t necessarily object to them here—they seem appropriate in a post like this), could you please save them in a format that doesn’t make their file size literally four times as large as it needs to be (for no benefit whatsoever)? Please? :)
Everyone reading Less Wrong on not-quite-fiber-speed internet connections will thank you!
Replies from: abramdemski↑ comment by abramdemski · 2018-07-18T21:28:33.233Z · LW(p) · GW(p)
I'll see what I can do! (I've been completely ignoring that up to now, so yeah, probably can do better.)
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2018-07-19T23:26:20.734Z · LW(p) · GW(p)
Cool, thanks. A couple of tips:
- Easiest way is to just re-save as GIFs
- If you’ve got a Mac, GraphicConverter (a shareware app) can easily automate this process
- You can also make a little Automator droplet that you can just drag-and-drop your files onto, en masse, and have them auto-converted
(There are even fancier approaches but that should do for now. Let me know if you need any help with this!)