Anthropic decision theory I: Sleeping beauty and selflessness
post by Stuart_Armstrong · 2011-11-01T11:41:32.962Z · LW · GW · Legacy · 34 commentsContents
The Sleeping Beauty problem, and the incubator variant Selfishness, selflessness and altruism None 34 comments
A near-final version of my Anthropic Decision Theory paper is available on the arXiv. Since anthropics problems have been discussed quite a bit on this list, I'll be presenting its arguments and results in this and subsequent posts 1 2 3 4 5 6.
Many thanks to Nick Bostrom, Wei Dai, Anders Sandberg, Katja Grace, Carl Shulman, Toby Ord, Anna Salamon, Owen Cotton-barratt, and Eliezer Yudkowsky.
The Sleeping Beauty problem, and the incubator variant
The Sleeping Beauty problem is a major one in anthropics, and my paper establishes anthropic decision theory (ADT) by a careful analysis it. Therefore we should start with an explanation of what it is.
In the standard setup, Sleeping Beauty is put to sleep on Sunday, and awoken again Monday morning, without being told what day it is. She is put to sleep again at the end of the day. A fair coin was tossed before the experiment began. If that coin showed heads, she is never reawakened. If the coin showed tails, she is fed a one-day amnesia potion (so that she does not remember being awake on Monday) and is reawakened on Tuesday, again without being told what day it is. At the end of Tuesday, she is put to sleep for ever. This is illustrated in the next figure:

The incubator variant of the problem, due to Nick Bostrom, has no initial Sleeping Beauty, just one or two copies of her created (in different, identical rooms), depending on the result of the coin flip. The name `incubator' derived from the machine that was to do the birthing of these observers. This is illustrated in the next figure:
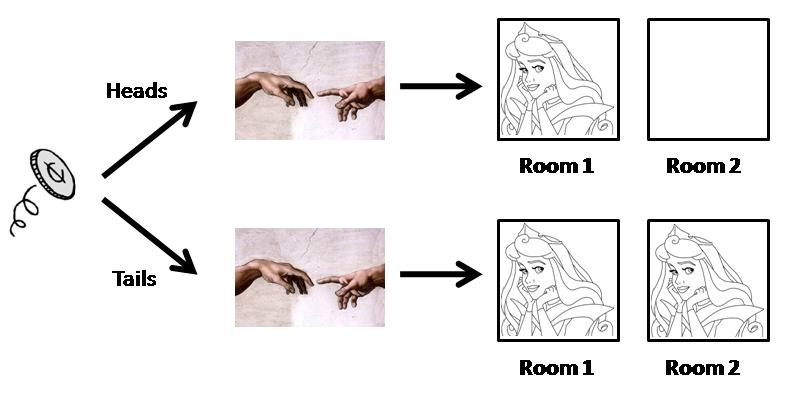
The question then is what probability a recently awoken or created Sleeping Beauty should give to the coin falling heads or tails and it being Monday or Tuesday when she is awakened (or whether she is in Room 1 or 2).
Selfishness, selflessness and altruism
I will be using these terms in precise ways in ADT, somewhat differently from how they are usually used. A selfish agent is one whose preferences are only about their own personal welfare; a pure hedonist would be a good example. A selfless agent, on the other hand is one that cares only about the state of the world, not about their own personal welfare - or anyone else's. They might not be nice (patriots are - arguably - selfless), but they do not care about their own welfare as a terminal goal.
Altruistic agents, on the other hand, care about the welfare of everyone, not just themselves. These can be divided into total utilitarians, and average utilitarians (there are other altruistic motivations, but they aren't relevant to the paper). In summary:
| Selfish | "Give me that chocolate bar" |
|---|---|
| Selfless | "Save the rainforests" |
| Average Utilitarian | "We must increase per capita GDP" |
| Total Utilitarian | "Every happy child is a gift to the world" |
34 comments
Comments sorted by top scores.
comment by Wei Dai (Wei_Dai) · 2011-11-03T10:11:29.286Z · LW(p) · GW(p)
Stuart, perhaps you could cite my 2001 everything-list post, where I proposed a decision theoretic approach to solving anthropic reasoning?
comment by Wei Dai (Wei_Dai) · 2011-11-03T20:31:54.301Z · LW(p) · GW(p)
I think the paper's treatment (section 3.3.3) of "selfish" (i.e., indexically expressed) preferences is wrong, unless I'm not understanding it correctly. Assuming the incubator variant, what does your solution say a Beauty should do if we tell her that she is in Room 1 and ask her what price she would pay for a lottery ticket that pays $1 on Heads? Applying section 3.3.3 seems to suggest that she should also pay $0.50 for this ticket, but that is clearly wrong. Or rather, either that's wrong or it's wrong that she should pay $0.50 for the original lottery ticket where we didn't tell her her room number, because otherwise we can money-pump her and make her lose money with probability 1.
"Selfish" preferences are still very confusing to me, especially if copying or death is a future possibility. Are they even legitimate preferences, or just insanity that should be discarded (as steven0461 suggested)? If the former, should we convert them into non-indexically expressed preferences (i.e., instead of "Give me that chocolate bar", "Give that chocolate bar to X" where X is a detailed description of my body), or should our decision theory handle such preferences natively? (Note that UDT can't handle such preferences without prior conversion.) I don't know how to do either, and this paper doesn't seem to be supplying the solution that I've been looking for.
comment by Vladimir_Nesov · 2011-11-02T12:59:34.413Z · LW(p) · GW(p)
Why is the paper (also) filed under categories "High Energy Physics - Theory" and "Popular Physics"??? (The main category "Physics - Data Analysis" is wrong too.)
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-02T13:11:20.048Z · LW(p) · GW(p)
That is bizzare; I'll have a look into that.
EDIT: seems to have been autogenerated by some sort of key-word bot
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2011-11-02T18:51:55.318Z · LW(p) · GW(p)
No way to fix? It gives a measure of crackpot gloss to the paper, I'd say a serious issue.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-02T21:48:10.515Z · LW(p) · GW(p)
Ok, I think I'll be able to fix it when I resubmit; will do that once I've got all the comments here.
comment by Louie · 2011-11-03T06:45:39.829Z · LW(p) · GW(p)
I read the full pre-print Monday and today. I commented to a friend that I was happy to see that you had solved anthropics. Thanks for that!
Actually, I do think Anthropic Decision Theory resolves much of the confusion in the most well-known anthropic problems -- which is very exciting -- but I am still curious what you think are the most interesting remaining open problems or confusions in anthropics left to tackle?
Replies from: lukeprogcomment by florijn · 2013-08-05T21:05:41.957Z · LW(p) · GW(p)
After having done a lot of research on the Sleeping Beauty Problem as it was the topic of my bachelor's thesis (philosophy), I came to the conclusion that anthropic reasoning is wrong in the Sleeping Beauty Problem. I will explain my argument (shortly) below:
The principle that Elga uses in his first paper to validate his argument for 1/3 is an anthropic principle he calls the Principle of Indifference:
"Equal probabilities should be assigned to any collection of indistinguishable, mutually exclusive and exhaustive events."
The Principle of Indifference is in fact a more restricted version of the Self-Indication Assumption:
"All other things equal, an observer should reason as if they are randomly selected from the set of all possible observers."
Both principles are to be accepted a priori as they can not be attributed to empirical considerations. They are therefore vulnerable to counterarguments...
The counterargument:
Suppose that the original experiment is modified a little:
If the outcome of the coin flip is Heads, they wake Beauty up at exactly 8:00. If the outcome of the first coin flip is Tails, the reasearchers flip another coin. If it lands Heads they wake Beauty at 7:00, if Tails at 9:00. That means that when Beauty wakes up she can be in one of 5 situations:
Heads and Monday 8:00
Tails and Monday 7:00
Tails and Monday 9:00
Tails and Tuesday 7:00
Tails and Tuesday 9:00
Again, these situations are mutually exclusive, indistinguishable and exhaustive. Hence thirders are forced to conclude that P(Heads) = 1/5.
Thirders might object that the total surface area under the probability curve in the Tails-world would still have to equal 2/3, as Beauty is awakened twice as many times in the Tails-world as in the Heads-world. They are then forced to explain why temporal uncertainty regarding an awakening (Monday or Tuesday) is different from temporal uncertainty regarding the time (7:00 or 9:00 o’clock). Both classify as temporal uncertainties within the same possible world, what could possibly set them apart?
An explanation could be that Beauty is only is asked for her credence in Heads during an awakening event, regardless of the time, and that such an event occurs twice in the Tails-world. That is, out of the 4 possible observer-moments in the Tails-world there are only two in which she is interviewed. That means that simply the fact that she is asked the same question twice is reason enough for thirders to distribute their credence, and it is no longer about the number of observer moments. So if she would be asked the same question a million times then her credence in Heads would drop to 1/1000001!
We can magnify the absurdity of this reasoning by imagining a modified version of the Sleeping Beauty Problem in which a coin is tossed that always lands on Tails. Again, she is awakened one million times and given an amnesia-inducing potion after each awakening. Thirder logic would lead to Beauty’s credence in Tails being 1/1000000, as there are one million observer-moments where she is asked for her credence within the only possible world; the Tails-world. To recapitulate: Beauty is certain that she lives in a world where a coin lands Tails, but due to the fact that she knows that she will answer the same question a million times her answer is 1/1000000. This would be tantamount to saying that Mt. Everest is only 1m high when knowing it will be asked 8848 times! It is very hard to see how amnesia could have such an effect on rationality.
Conclusion:
The thirder argument is false. The fact that there are multiple possible observer-moments within a possible world does not justify dividing your credences equally among these observer-moments, as this leads to absurd consequences. The anthropic reasoning exhibited by the Principle of Indifference and the Self-Indication Assumption cannot be applied to the Sleeping Beauty Problem and I seriously doubt if it can be applied to other cases...
Replies from: ike↑ comment by ike · 2014-09-15T02:25:22.977Z · LW(p) · GW(p)
An explanation could be that Beauty is only is asked for her credence in Heads during an awakening event, regardless of the time, and that such an event occurs twice in the Tails-world. That is, out of the 4 possible observer-moments in the Tails-world there are only two in which she is interviewed. That means that simply the fact that she is asked the same question twice is reason enough for thirders to distribute their credence, and it is no longer about the number of observer moments. So if she would be asked the same question a million times then her credence in Heads would drop to 1/1000001!
This is actually correct, assuming her memory is wiped after each time.
We can magnify the absurdity of this reasoning by imagining a modified version of the Sleeping Beauty Problem in which a coin is tossed that always lands on Tails. Again, she is awakened one million times and given an amnesia-inducing potion after each awakening. Thirder logic would lead to Beauty’s credence in Tails being 1/1000000, as there are one million observer-moments where she is asked for her credence within the only possible world; the Tails-world. To recapitulate: Beauty is certain that she lives in a world where a coin lands Tails, but due to the fact that she knows that she will answer the same question a million times her answer is 1/1000000. This would be tantamount to saying that Mt. Everest is only 1m high when knowing it will be asked 8848 times! It is very hard to see how amnesia could have such an effect on rationality.
No! Her credence in "This is the first (or xth) time I've been awakened in Tails" is 1/1000000. Her credence in "this is Tails" is ~1.
What would you put the probability of it being the xth question, x ranging from 1 to 1 1,000,000?
comment by antigonus · 2011-11-01T17:57:39.727Z · LW(p) · GW(p)
A key sentence in your conclusion is this:
Anthropic decision theory is a new way of dealing with anthropic problems, focused exclusively on finding the correct decision to make, rather than the correct probabilities to assign.
You then describe ADT as solving the Sleeping Beauty problem. This may be the case if we re-formulate the latter as a decision problem, as you of course do in your paper. But Sleeping Beauty isn't a decision problem, so I'm not sure if you take yourself to be actually solving it, or if you just think it's unimportant once we solve the decision problem.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-01T18:28:09.242Z · LW(p) · GW(p)
I'd argue that since agents with different odds can come to exactly the same decision in all anthropic circumstances (SIA with individual responsibility and SSA with total responsibility, both with implicit precommitments), that talking about the "real" odds is an error.
Replies from: Manfred↑ comment by Manfred · 2011-11-01T22:21:56.691Z · LW(p) · GW(p)
Despite the fact that if you know the expected utility a rational agent assigns to a bet, and you know the utility of the outcomes, you can find the probability the rational agent assigns to the bet?
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-02T10:00:20.370Z · LW(p) · GW(p)
You also need to know the impact of the agent's decision: "If do this, do I cause identical copies to do the same thing, or do I not?" See my next post for this.
Replies from: Manfred↑ comment by Manfred · 2011-11-02T10:51:51.179Z · LW(p) · GW(p)
And so if you know that, you could get the probability the agent assigns to various outcomes?
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-02T12:10:16.758Z · LW(p) · GW(p)
Yes.
But notice that you need the three elements - utility function, probabilities and impact of decision - in order to figure out the decision. So if you observe only the decision, you can't get at any of the three directly.
With some assumptions and a lot of observation, you can disentangle the utility function from the other two, but in anthropic situations, you can't generally disentangle the anthropic probabilities from the impact of decision.
Replies from: Manfred↑ comment by Manfred · 2011-11-02T12:49:54.205Z · LW(p) · GW(p)
Given only the decisions, you can't disentangle the probability from the utility function anyhow. You'd have to do something like ask nicely about the agent's utility or probability, or calculate from first principles, to get the other. So I don't feel like the situation is qualitatively different. If everything but the probabilities can be seen as a fixed property of the agent, the agent has some properties, and for each outcome it assigns some probabilities.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-02T12:56:44.743Z · LW(p) · GW(p)
A simplification: SIA + individual impact = SSA + total impact
ie if I think that worlds with more copies are more likely (but these are independent of me), this gives the same behaviour that if I believe my decision affects those of my copies (but worlds with many copies are no more likely).
comment by turchin · 2017-08-31T19:33:47.974Z · LW(p) · GW(p)
The question, which may have an obvious answer, but always puzzles me in the Sleeping Beauty problem, is the meaning of the word "probability" in the mouth of the Beauty. Is it frequentist, Bayesian or any other probability?
If we define it from expected payoff, we will immediately solve the problem in one way or another? If the sleeping beauty problem is run many times, it would also solve it in direction of 1/3?
Replies from: entirelyuseless↑ comment by entirelyuseless · 2017-09-01T02:02:52.016Z · LW(p) · GW(p)
It is a question about feeling. Do you feel the same towards the two possibilities, or do you feel that one is more real than the other?
Replies from: turchin↑ comment by turchin · 2017-09-01T09:13:50.246Z · LW(p) · GW(p)
I feel that it is absurd to speak about probabilities of one-time event. Some form of payoff would help quantization and later in this sequence it is discussed.
Replies from: entirelyuseless↑ comment by entirelyuseless · 2017-09-01T14:18:42.602Z · LW(p) · GW(p)
It is not absurd to feel certain that something is going to happen or has happened, even if it is a one-time event. Likewise, it is not absurd to feel completely unsure about what will happen or has happened. These are feelings that people can have, whether you like them or not. As I said -- we are talking about how sure people's beliefs feel, and these can apply to all situations including Sleeping Beauty situations.
Replies from: turchin↑ comment by turchin · 2017-09-01T17:18:30.722Z · LW(p) · GW(p)
The difference between feeling something as 0.333 and 0.5 is rather small. Anyway I think that feeling is not very appropriate term here, and betting will be more correct, but for betting bigger difference is needed or repated events.
Replies from: entirelyuseless↑ comment by entirelyuseless · 2017-09-02T01:41:06.811Z · LW(p) · GW(p)
The problem with betting is that it matters whether it is one case of you making the bet or two cases, and you do not know which it is. This is irrelevant to feeling, so feeling is the way to judge the matter.
I agree that it might be hard to notice the difference when it is so small. This is why the case where you have one wakening vs a million wakening is better. Even in that case, it is obvious that the person will feel uncertain whether the coin landed/will land heads or tails, so it is obvious that they are halfers.
comment by buybuydandavis · 2011-11-02T02:37:38.480Z · LW(p) · GW(p)
A selfish agent is one whose preferences are only about their own personal welfare; a pure hedonist would be a good example.
What does that mean in terms of parametric invariances of his preference function? Is a selfish person's preferences supposed to be invariant to how clean his car is? How clean your car is? How clean you are? Similarly, what is his personal welfare supposed to be invariant to?
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-02T12:11:25.377Z · LW(p) · GW(p)
No sure what you mean by parametric invariances; can you elaborate?
Replies from: buybuydandavis↑ comment by buybuydandavis · 2011-11-02T21:46:17.732Z · LW(p) · GW(p)
I'll rephrase and try to clarify.
What is the preference function of a selfish person supposed to be independent of? What things can change that won't change the value of his preference function?
Concepts of selfishness often seem muddled to me. They seem to imply a concern confined to a millimeter bubble about your body. Well, who is like that? So I'm asking what do you suppose does and doesn't effect a selfish person's preference function.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-02T22:09:21.572Z · LW(p) · GW(p)
In practice, everyone's motivation is a mixture of all sorts of stuff, and very little is even a utility function...
But in theory, this is how I would define a selfish utility: one that is defined entirely in terms of an index "me". If you have two people with exactly the same selfish utility function, completely identical (except that the "me" is different), then those two utilities are independent of each other.
Replies from: jmh↑ comment by jmh · 2017-09-05T11:36:48.200Z · LW(p) · GW(p)
Would it be correct to define selfish utility as sociopathic?
Replies from: gjm, Stuart_Armstrong, Lumifer↑ comment by gjm · 2017-09-06T09:00:21.068Z · LW(p) · GW(p)
Probably the only actual human beings whose utility functions (in so far as they have them) are perfectly selfish are sociopaths, or very odd psychologically in other ways. But considering hypothetical agents with perfectly selfish utility functions is mostly just a convenient approximation. (And it's not that bad an approximation; most people are very well approximated, in many of their interactions, as perfectly selfish agents, and the approximation errs more badly by assuming that they have utility functions than by assuming that they're perfectly selfish. I think.)
↑ comment by Stuart_Armstrong · 2017-09-05T18:57:20.900Z · LW(p) · GW(p)
The problem with selfish utility, is that even selfish agents are assumed to care about themselves at different moments in time. In a world where copying happens, this is under defined, so selfish has multiple possible definitions.
comment by Shmi (shminux) · 2011-11-01T16:53:08.896Z · LW(p) · GW(p)
I suspect that I misunderstand the question, but my inclination is to answer the question of what day it is [nearly ]experimentally, by simulating a large number of Sleeping Beauties and figuring out the odds this way. In this case you have basically done the simulation in your first picture, and the odds are 2:1 that it is Monday/Room 1, and 2:1 for tails. This matches your "Self-Indicating Assumption" of being "randomly selected from the set of all possible observers".
The other approach has the assumption that "Sleeping Beauty, before being put to sleep, expects that she will be awakened in future," which makes no sense to me, as it is manifestly false on Monday+Heads and unconditionally on Tuesday, and she knows that full well.
Additionally, I do not understand how her utility function (and any amount of money or chocolate) can change the odds in any way. I also do not understand what this has to do with any decision theory, given that her fate is predetermined and there is nothing she can do to avoid being or not being awoken, so her decision doesn't matter in the slightest.
My suspicion is that the Sleeping Beauty problem is a poor illustration for whatever concept you are advancing, but it is entirely possible that I simply missed your point.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2011-11-01T18:26:06.931Z · LW(p) · GW(p)
by simulating a large number of Sleeping Beauties...
What criteria do you use to count up the results? Each incubator experiment produces either one, or two SBs. If we follow the criteria "in each experiment, we take the total number of people who were correct", then SIA odds are the way to go. If instead, we follow "in each experiment, we take the average number of people who were correct", then SSA is the way to go.
"Sleeping Beauty, before being put to sleep, expects that she will be awakened in future,"
Changed to clarify: ""Sleeping Beauty, before being put to sleep on Sunday, expects that she will be awakened in future,"
Additionally, I do not understand how her utility function (and any amount of money or chocolate) can change the odds in any way.
They do not change her odds, but her decisions, and I argue her decisions are the only important factors here, as her belief in her odds in not directly observable. You can believe in different odds, but still come to the same decision in any circumstance; I would argue that this is makes the odds irrelevant.