Yesterday’s news alert, nevertheless: The verdict is in. GPT-4.1-Mini in particular is an excellent practical model, offering strong performance at a good price. The full GPT-4.1 is an upgrade to OpenAI’s more expensive API offerings, it is modestly better but costs 5x as much. Both are worth considering for coding and various other API uses. If you have an agent or other app, it’s at least worth trying plugging these in and seeing how they do.
This post does not cover OpenAI’s new reasoning models. That was today’s announcement, which will be covered in full in a few days, once we know more.
On the one hand, I love that they might finally use a real version number with 4.1.
On the other hand, we would now have a GPT-4.1 that is being released after they previously released a GPT-4.5. The whole point of version numbers is to go in order.
Will Brown: it’s simple, really. GPT-4.1 is o3 without reasoning, and GPT-4.1-mini is o4-mini without reasoning. o4-mini-low is GPT-4.1-mini with just a little bit of reasoning. o1 is 4o with reasoning, o1-mini is 4o-mini with a little bit of reasoning, o3-mini is 4o-mini with reasoning that’s like better but not necessarily more, and o4 is GPT-4.5 with reasoning.
if you asked an openai employee about this, they’d say something like “that’s wrong and an oversimplification but maybe a reasonable way to think about it”
I mean, I think that’s wrong, but I’m not confident I have the right version of it.
They are not putting GPT-4.1 in ChatGPT, only in the API. I don’t understand why.
Sam Altman: GPT-4.1 (and -mini and -nano) are now available in the API!
These models are great at coding, instruction following, and long context (1 million tokens). Benchmarks are strong, but we focused on real-world utility, and developers seem very happy.
GPT-4.1 family is API-only.
Greg Brockman: New model in our API — GPT-4.1. It’s great at coding, long context (1 million tokens), and instruction following.
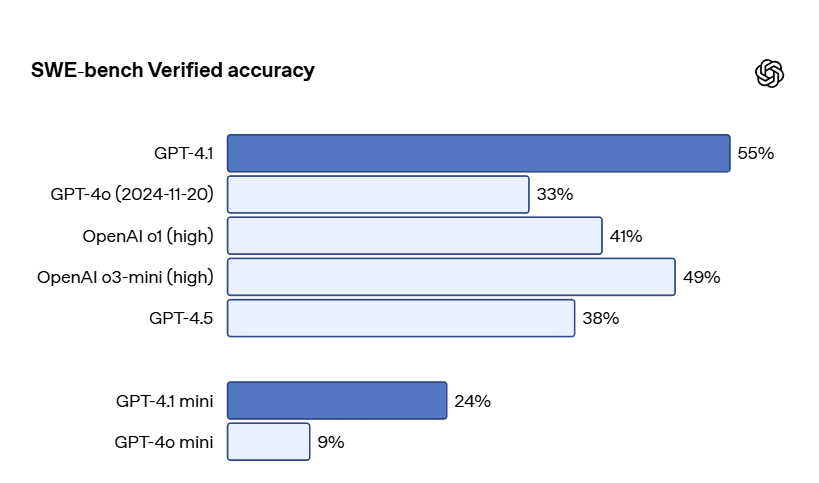
Noam Brown: Our latest @OpenAI model, GPT-4.1, achieves 55% on SWE-Bench Verified *without being a reasoning model*. @michpokrass and team did an amazing job on this! (New reasoning models coming soon too.)
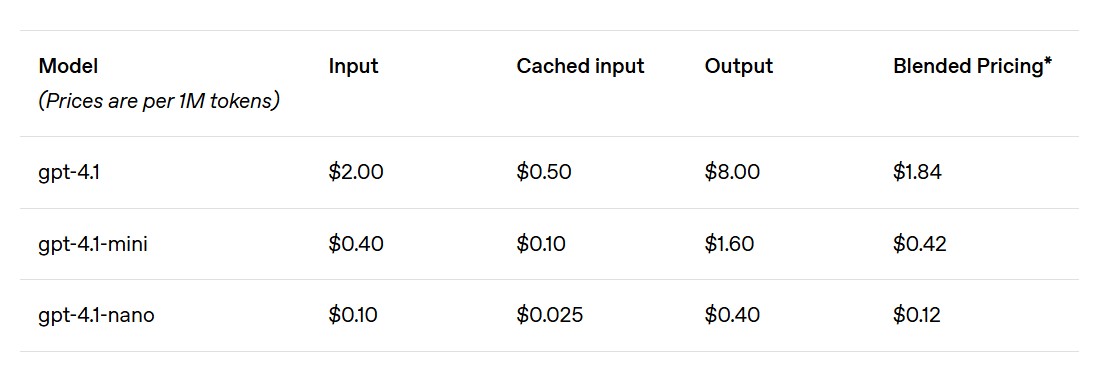
Based on the benchmarks and the reports elsewhere, the real release here is GPT-4.1-mini. Mini is 20% of the cost for most of the value. The full GPT-4.1 looks to be in a weird spot, where you probably want to either go big or go small. Nano might have its uses too, but involves real tradeoffs.
On Your Marks
We start with the official ones.
They lead with coding, SWE-bench in particular.
I almost admire them saying no, we don’t acknowledge that other labs exist.
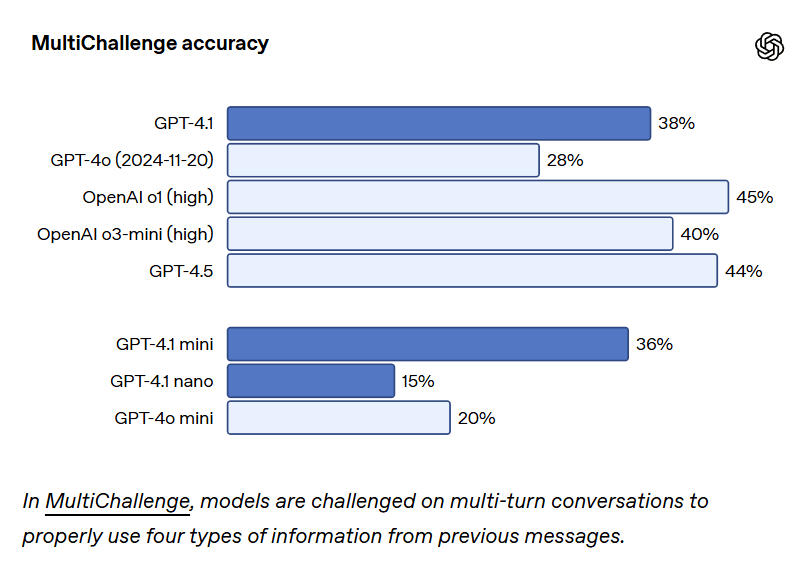
They have an internal ‘instruction following’ eval. Here the full GPT-4.1 is only okay, but mini and nano are upgrades within the OpenAI ecosystem. It’s their benchmark, so it’s impossible to know if these scores are good or not.
This is an outside benchmark, so we can see that these results are mid. Gemini 2.5 Pro leads the way with 51.9, followed by Claude 3.7 Thinking. GPT-4.5 is the best non-thinking model, with various Sonnets close behind.
They check IFEval and get 87%, which is okay probably, o3-mini-high is 94%. The mini version gets 84%, so the pattern of ‘4.1 does okay but 4.1-mini only does slightly worse’ continues.
All three model sizes have mastered needle-in-a-haystack all the way to 1M tokens. That’s great, but doesn’t tell you if they’re actually good in practice in long context.
Then they check something called Graphwalks, then MMMU, MathVista, CharXiv-Reasoning and Video long context.
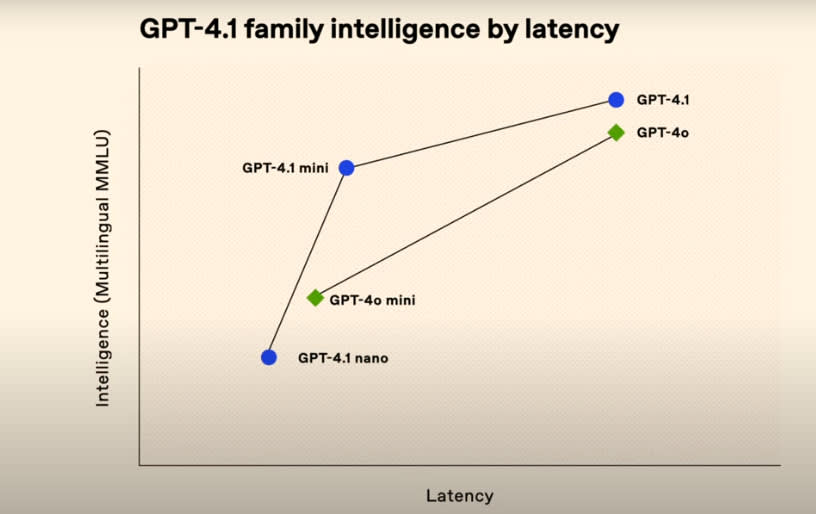
Their charts are super helpful, check ‘em out:
Near: openai launch today. very informative chart.
Kesku: this one speaks to me
Other Benchmarks
Mostly things have been quiet, but for those results we have it is clear that GPT-4.1 is a very good value, and a clear improvement for most API use over previous OpenAI models.
Where we do have reports, we continue to see the pattern that OpenAI’s official statistics report. Not only does GPT-4.1-mini not sacrifice much performance versus GPT-4.1, in some cases the mini version is actively better.
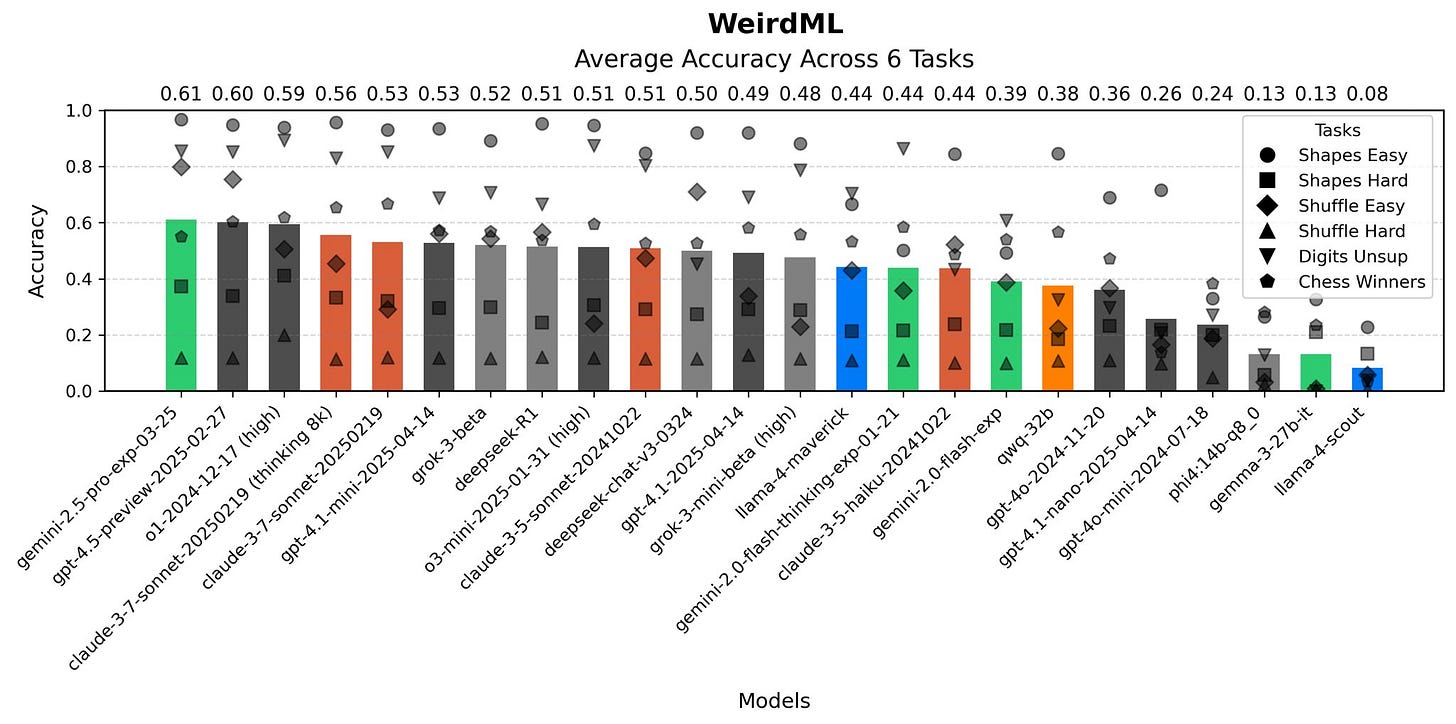
Harvard Ihle: GPT-4.1 clearly beats 4o on WeirdML. The focus on coding and instruction following should be a good combo for these tasks, and 4.1-mini does very well for its cost, landing on the same score (53%) as sonnet-3.7 (no thinking), will be interesting to compare it to flash-2.5.
EpochAI: Yesterday, OpenAI launched a new family of models, GPT-4.1, intended to be more cost-effective than previous GPT models. GPT-4.1 models come in multiple sizes and are not extended thinking / reasoning models. We ran our own independent evaluations of GPT-4.1.
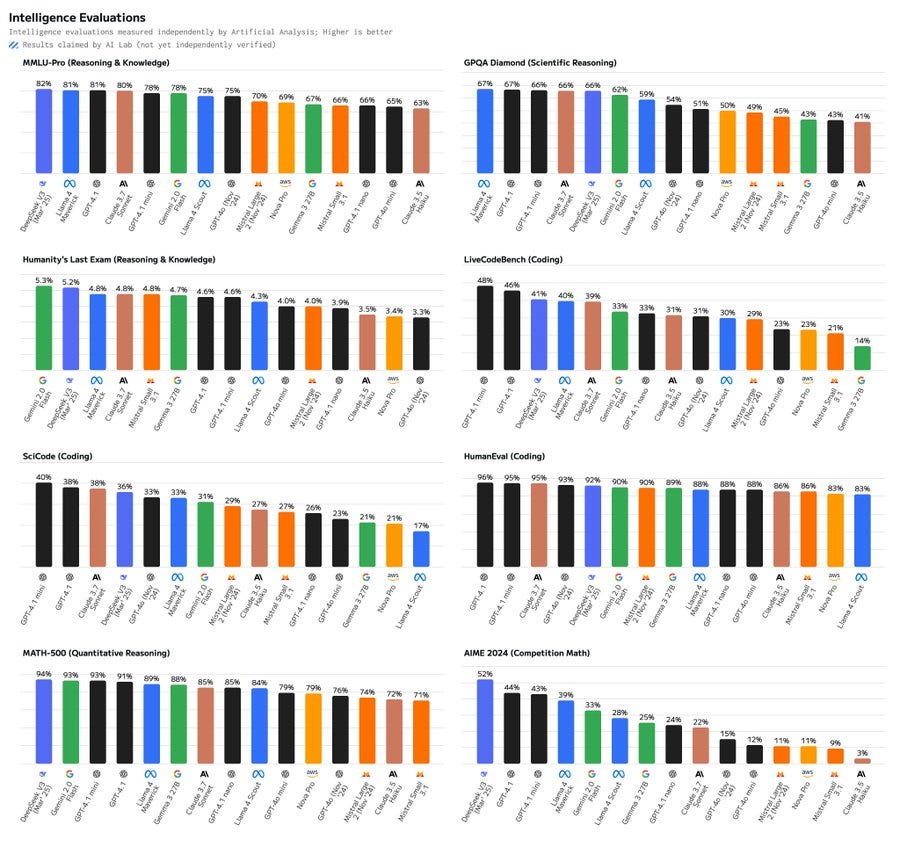
On GPQA Diamond, a set of Ph.D.-level multiple choice science questions, GPT-4.1 scores 67% (±3%), competitive with leading non-reasoning models, and GPT-4.1 mini is very close at 66% (±3%). These match OpenAI’s reported scores of 66% and 65%.
Nano gets 49% (±2%), above GPT-4o.
On FrontierMath, our benchmark of original, expert-level math questions, GPT-4.1 and GPT-4.1 mini lead non-reasoning models at 5.5% and 4.5% (±1%).
Note that the top reasoning model, o3-mini high, got 11% (±2%). OpenAI has exclusive access to FrontierMath besides a holdout set.
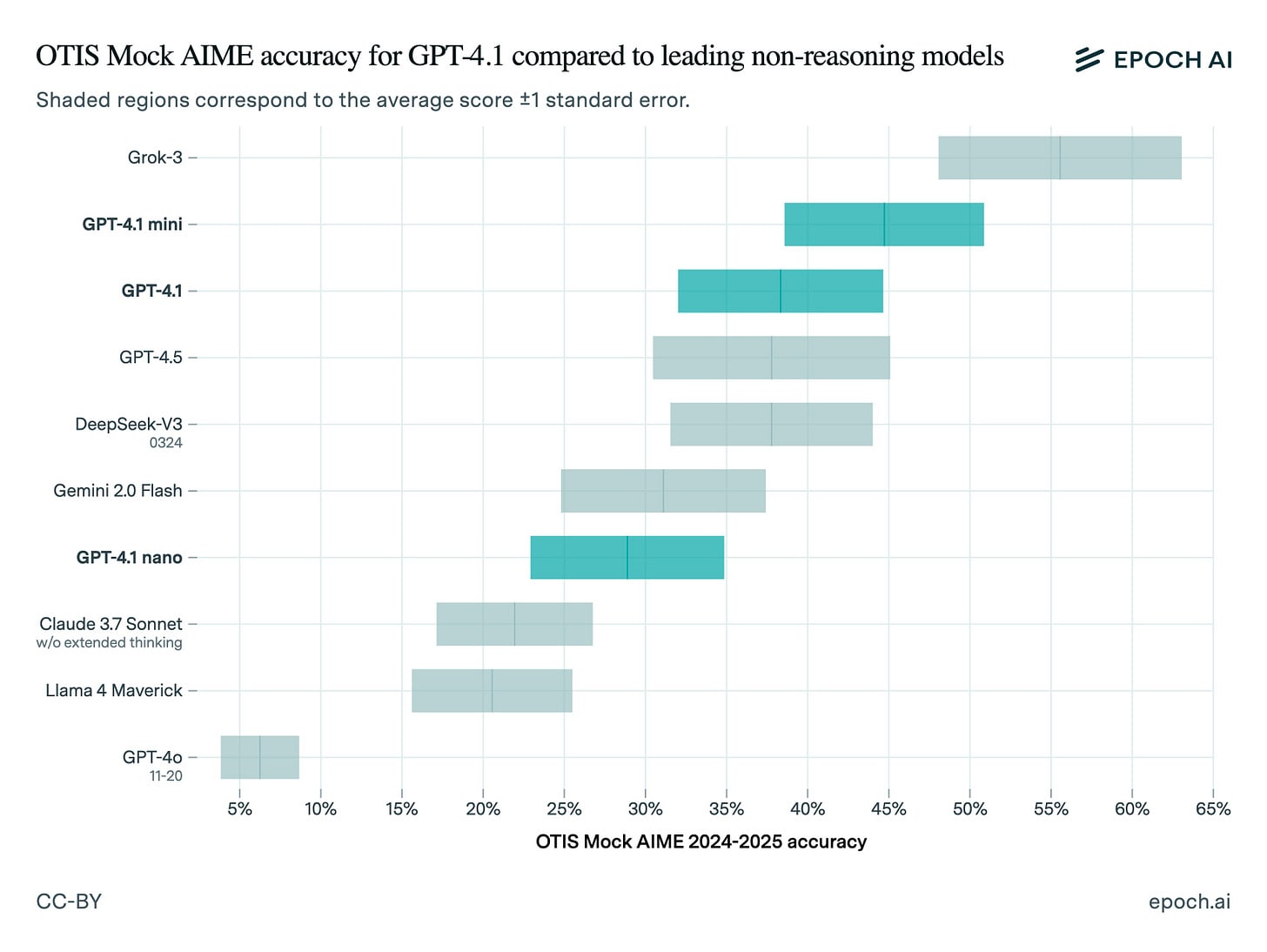
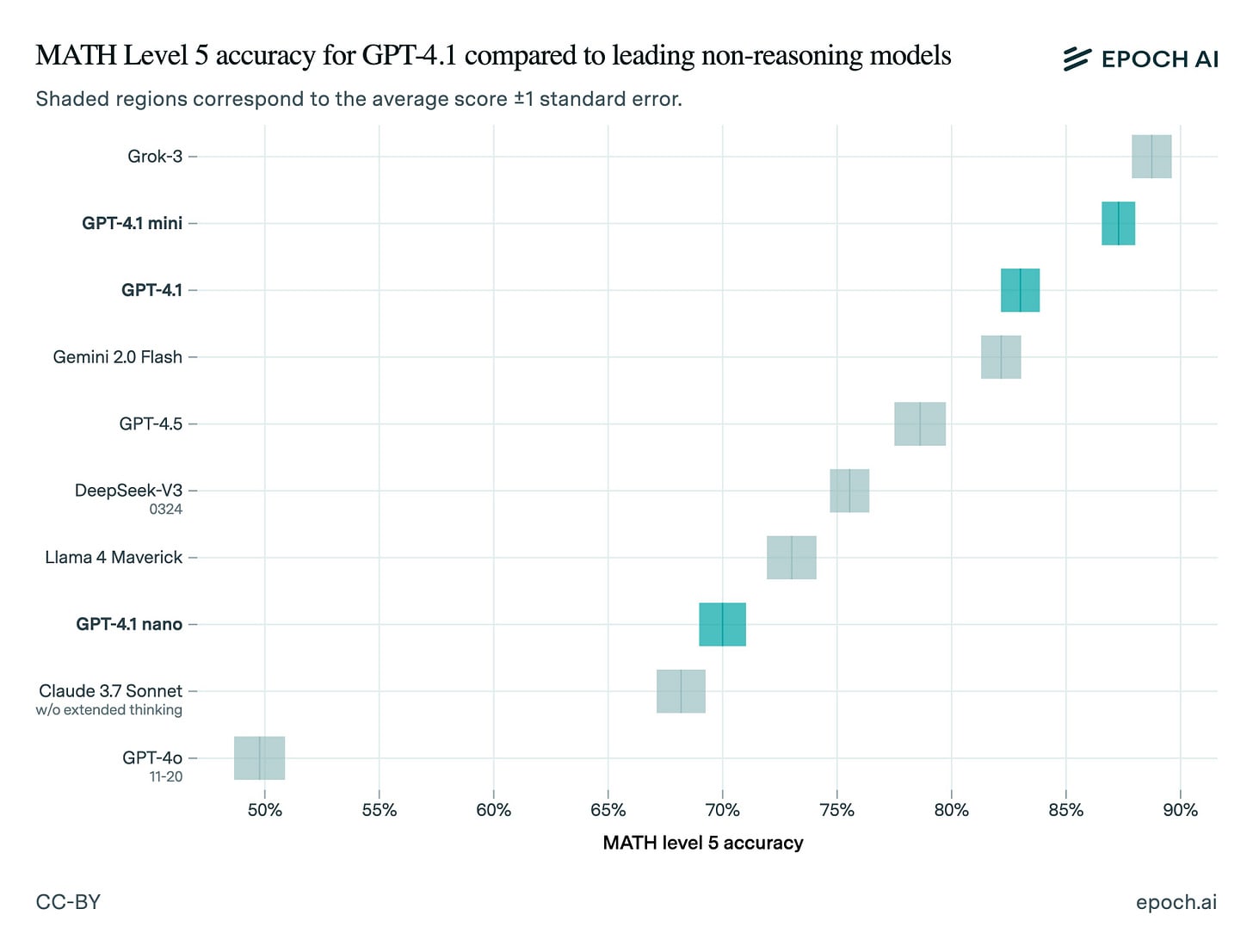
On two competition math benchmarks, OTIS Mock AIME and MATH Level 5, GPT-4.1 and 4.1 mini are near the top among non-reasoning models. Mini does better than the full GPT-4.1, and both outperform the larger GPT-4.5!
GPT-4.1 nano is further behind, but still beats GPT-4o.
Huh, I hadn’t previously seen these strong math results for Grok 3.
EpochAI: GPT-4.1 appears cost-effective, with strong benchmarks, fairly low per-token costs (GPT-4.1 is 20% cheaper than 4o) and no extended thinking.
However, Gemini 2.0 Flash is priced similarly to Nano while approaching GPT-4.1 (mini) in scores, so there is still strong competition.
Artificial Analysis: OpenAI’s GPT-4.1 series is a solid upgrade: smarter and cheaper across the board than the GPT-4o series.
@OpenAI
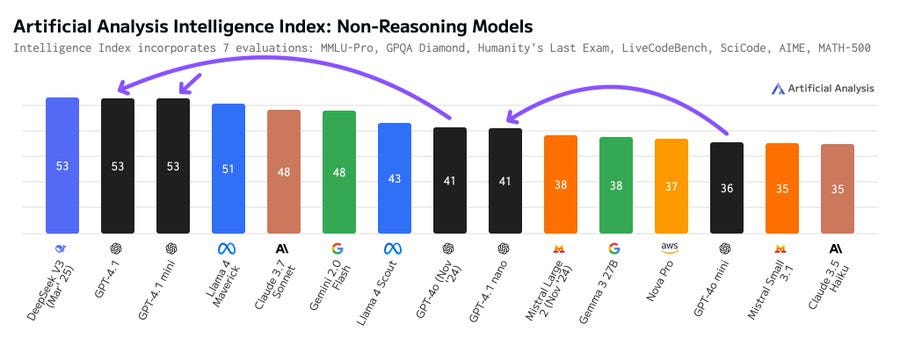
‘s GPT-4.1 family includes three models: GPT-4.1, GPT-4.1-mini and GPT-4.1 nano. We have independently benchmarked these with our Artificial Analysis Intelligence Index and the results are impressive:
➤ GPT-4.1 scores 53 – beating out Llama 4 Maverick, Claude 3.7 and GPT-4o to score identically to DeepSeek V3 0324.
➤ GPT-4.1 mini, likely a smaller model, actually matches GPT-4.1’s Intelligence Index score while being faster and cheaper. Across our benchmarking, we found that GPT-4.1 mini performs marginally better than GPT-4.1 across coding tasks (scoring equivalent highest on SciCode and matching leading reasoning models).
➤ GPT-4.1 nano scores 41 on Intelligence Index, approximately in line with Llama 3.3 70B and Llama 4 Scout. This release represents a material upgrade over GPT 4o-mini which scores 36.
Developers using GPT-4o and GPT-4o mini should consider immediately upgrading to get the benefits of greater intelligence at lower prices.
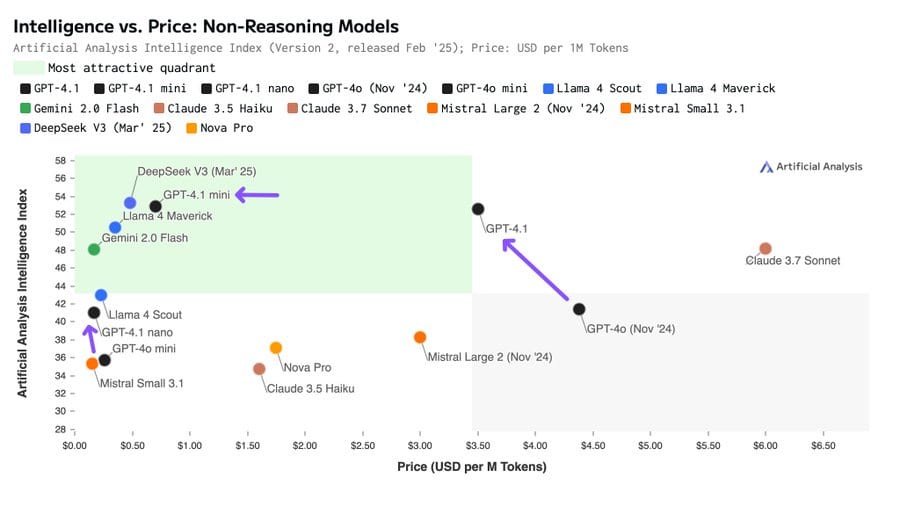
There are obvious reasons to be skeptical of this index, I mean Gemini Flash 2.0 is not as smart as Claude 3.7 Sonnet, but it’s measuring something real. It illustrates that GPT-4.1 is kind of expensive for what you get, whereas GPT-4.1-mini is where it is at.
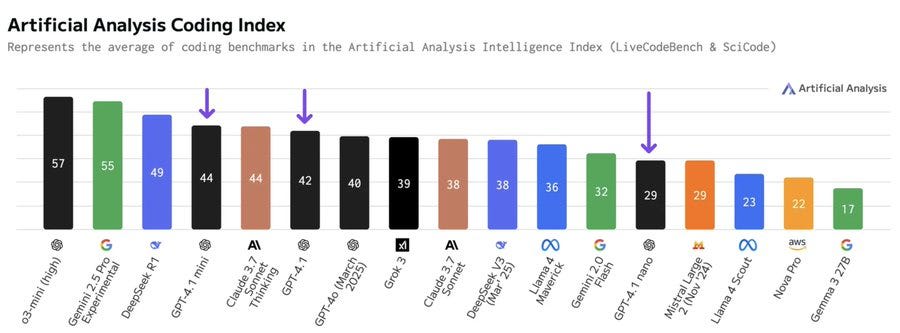
A∴A∴: Our benchmarking results appear to support OpenAI’s claim that the GPT-4.1 series represents significant progress for coding use cases. This chart shows GPT-4.1 models competing well in coding even compared to reasoning models, implying that they may be extremely effective in agentic coding use cases.
GPT-4.1 Nano and Mini are both delivering >200 tokens/s output speeds – these models are fast. Our full set of independent evaluation results shows no clear weakness areas for the GPT-4.1 series.
Reactions
This is the kind of thing people who try to keep up say these days:
Hasan Can: I can see GPT-4.1 replacing Sonnet 3.6 and implementing the changes I planned with Gemini 2.5 Pro. It’s quite good at this. It’s fast and cheap, and does exactly what is needed, nothing more, nothing less. It doesn’t have the overkill of Sonnet 3.7, slowness of Gemini 2.5 Pro or the shortcomings of DeepSeek 03-24.
Then you have the normal sounding responses, also positive.
Reply All Guy: reactions are sleeping on 4.1 mini. This model of a beast for the price. And lots of analysis missing the point that 4.1 itself is much cheaper than reasoning models. never use price per token; always use price per query.
4o < 3.5 sonnet < 4.1 < 3.7 sonnet
haiku <<< 4.1 mini
Clive Chan: 4.1 has basically replaced o3-mini for me in all my workflows (cursor, etc.) – highly recommend
also lol at nano just hanging out there being 2x better than latest 4o at math.
Dominik Lukes: Welcome to the model points race. 2.5, 3.7, 4.1 – this is a (welcome) sign of the incremental times. Finally catching up on context window. Not as great at wow as Claude 3.7 Sonnet on one shot code generation but over time it actually makes things better.
Pat Anon: Some use cases for GPT-4.1-mini and nano, otherwise its worse than Sonnet 3.7 at coding and worse than Gemini-2.5-pro at everything at roughly the same cost.
Nick Farina: It has a good personality. I’m using it in Cursor and am having a long and very coherent back and forth, talking through ideas, implementing things here and there. It doesn’t charge forward like Claude, which I really like. And it’s very very fast which is actually huge.
Daniel Parker: One quirk I noticed is that it seems to like summarizing its results in tables without any prompt telling it to do so.
Adam Steele: Used it today on the same project i used Claude 3.7 for the last few days. I’d say it a bit worse in output quality but OTOH got something right Claude didn’t. It was faster.
Oli: feels very good almost like 4.5 but way cheaper and faster and even better than 4.5 in some things
I think mostly doing unprompted tables is good.
Here is a bold but biased claim.
Aidan McLaughlin (OpenAI): heard from some startup engineers that they lost several work hours gawking, stupefied, after they plugged 4.1 mini/nano into every previously-expensive part of their stack
you can just do gpt-4o-quality things 25 × cheaper now.
And here’s a bold censorship claim and a counterclaim, the only words I’ve heard on the subject. For coding and similar purposes no one seems to be having similar issues.
Senex: Vastly increased moderation. It won’t even help write a story if a character has a wart.
Christian Fieldhouse: Switched my smart camera to 4.1 from 4o, less refusals and I think better at spotting small details in pictures.
Jan Betley: Much better than 4o at getting emergently misaligned.
Justice for GPT-4.5
OpenAI has announced the scheduled deprecation of API access for GPT-4.5. So GPT-4.5 will be ChatGPT only, and GPT-4.1 will be API only.
When I heard it was a full deprecation of GPT-4.5 I was very sad. Now that I know it is staying in ChatGPT, I think this is reasonable. GPT-4.5 is too expensive to scale API use while GPUs are melting, except if a rival is trying to distill its outputs. Why help them do that?
xlr8harder: OpenAI announcing the scheduled deprecation of GPT-4.5 less than 2 months after its initial release in favor of smaller models is not a great look for the scaling hypothesis.
Gwern: No, it’s a great look, because back then I explicitly highlighted the ability to distill/prune large models down into cheap models as one of several major justifications for the scaling hypothesis in scaling to expensive models you don’t intend to serve.
Morgan: i feel gwern’s point too, but bracketing that, it wasn’t entirely obvious but 4.5 stays in chatgpt (which is likely where it belongs)
xl8harder: this actually supports @gwern’s point more, then: if they don’t want the competition distilling off 4.5, that would explain the hurry to shut down api access.
Safety Third
This space intentionally left blank.
As in, I could find zero mention of OpenAI discussing any safety concerns whatsoever related to GPT-4.1, in any way, shape or form. It’s simply, hey, here’s a model, use it.
For GPT-4.1 in particular, for all practical purposes, This Is Fine. There’s very little marginal risk in this room given what else has already been released. Everyone doing safety testing is presumably and understandably scrambling to look at o3 and o4-mini.
I assume. But, I don’t know.
Improved speed and cost can cause what are effectively new risks, by tipping actions into the practical or profitable zone. Quantity can have a quality all its own. Also, we don’t know that the safeguards OpenAI applied to its other models have also been applied successfully to GPT-4.1, or that it is hitting their previous standards on this.
I mean, again, I assume. But, I don’t know.
I also hate the precedent this sets. That they did not even see fit to give us a one sentence update that ‘we have run all our safety tests and procedures, and find GPT-4.1 performs well on all safety metrics and poses no marginal risks.’
We used to have this principle where, when OpenAI or other frontier labs release plausibly frontier models, we get a model card and a full report on what precautions have been taken. Also, we used to have a principle that they took real and actually costly precautions.
Will Brown: it's simple, really. GPT-4.1 is o3 without reasoning ... o1 is 4o with reasoning ... and o4 is GPT-4.5 with reasoning.
Price and knowledge cutoff for o3 strongly suggest it's indeed GPT-4.1 with reasoning. And so again we don't get to see the touted scaling of reasoning models, since the base model got upgraded instead of remaining unchanged. (I'm getting the impression that GPT-4.5 with reasoning is going to be called "GPT-5" rather than "o4", similarly to how Gemini 2.5 Pro is plausibly Gemini 2.0 Pro with reasoning.)
In any case, the fact that o3 is not GPT-4.5 with reasoning means that there is still no word on what GPT-4.5 with reasoning is capable of. For Anthropic, Sonnet 3.7 with reasoning is analogous to o1 (it's built on the base model of the older Sonnet 3.5, similarly to how o1 is built on the base model of GPT-4o). Internally, they probably already have a reasoning model for some larger Opus model (analogous to GPT-4.5) and for a newer Sonnet (analogous to GPT-4.1) with a newer base model different from that of Sonnet 3.5.
This also makes it less plausible that Gemini 2.5 Pro is based on a GPT-4.5 scale model (even though TPUs might've been able to make its price/speed possible even if it was), so there might be a Gemini 2.0 Ultra internally after all, at least as a base model. One of the new algorithmic secrets disclosed in Gemma 3 report was that pretraining knowledge distillation works even when the teacher model is much larger (rather than modestly larger) than the student model, it just needs to be trained for enough tokens for this to become an advantage rather than a disadvantage (Figure 8), something that for example Llama 3.2 from Sep 2024 still wasn't taking advantage of. This makes it useful to train the largest possible compute optimal base model regardless of whether its better quality justifies its inference cost, merely to make the smaller overtrained base models better by pretraining them from the large model logits with knowledge distillation instead of from raw tokens.
I gotta say, I have no idea why people are putting Claude 3.7 in the same league as recent GPT models or Gemini 2.5. My experience is that Claude 3.7 deeply struggles with a range of tasks. I've been trying to use it for grant writing -- shortening text, defining terms in my field, suggesting alternative ways to word things. It gets definitions wrong, offers nonsensical alternative wordings, and gets stuck repeating the same "shortened," nuance-stripped text over and over despite me asking it to try another way.
By contrast, I threw an entire draft of my grant proposal into Gemini 2.5 and got a substantially shorter and more clear new version out, first try.
Interesting, my experience is roughly the opposite re Claude-3.7 vs the GPTs (no comment on Gemini, I've used it much less so far). Claude is my main workhorse; good at writing, good at coding, good at helping think things through. Anecdote: I had an interesting mini-research case yesterday ('What has Trump II done that liberals are likely to be happiest about?') where Claude did well albeit with some repetition and both o3 and o4-mini flopped. o3 was initially very skeptical that there was a second Trump term at all.
Hard to say if that's different prompting, different preferences, or even chance variation, though.
Gemini seems to do a better job of shortening text while maintaining the nuance I expect grant reviewers to demand. Claude seems to focus entirely on shortening text. For context, I'm feeding a specific aims page for my PhD work that I've written about 15 drafts of already, so I have detailed implicit preferences about what is and is not an acceptable result.