To Limit Impact, Limit KL-Divergence
post by J Bostock (Jemist) · 2024-05-18T18:52:39.081Z · LW · GW · 1 commentsContents
TL;DR
Long Version
Limiting Takeover Probability
Experimental Validation in Toy Model
Thoughts and Existing Work
Why It Might Be Useful
Further Thoughts
Proof Of Core Lemma
None
1 comment
TL;DR
Run a potentially-harmful model alongside a known-harmless model, such that their action-spaces (e.g. output token sets) are equivalent. Combine the output probabilities so as to limit the KL-divergence between the resulting token probabilities and the harmless model's probabilities. This provides a mathematical ceiling on the impact of the resulting combined policy.
Unfortunately, the probability of catastrophe () scales linearly with the allowed , whereas depending on the distribution, reward may only scale with (though for unbounded rewards it often scales with . Bounds on probability of catastrophe compared to the probability of the weaker model causing a catastrophic outcome () are also very weak. Overall the probability of catastrophe scales as .
Long Version
We will use the following model of AI interactions:
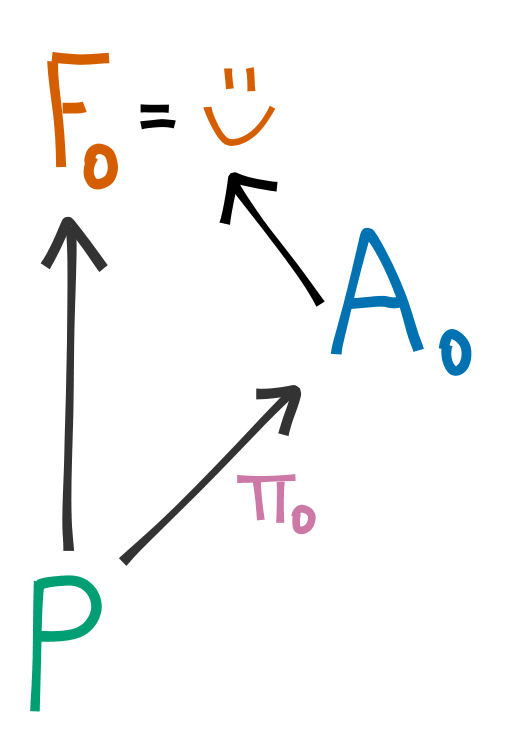
In this case, represents the past, the output of an AI (which we will represent as having policy ) and the future after this AI's actions have occcurred. For a "base" case, we will consider using an AI which is both relatively powerful, but that we think has a probability of being catastrophic (like GPT-4) to calculate . We must consider the model as running at a temperature for this to make sense.
Now imagine using a powerful AI with policy , which is of unknown safety. If we do the same thing here, the results could be catastrophic!
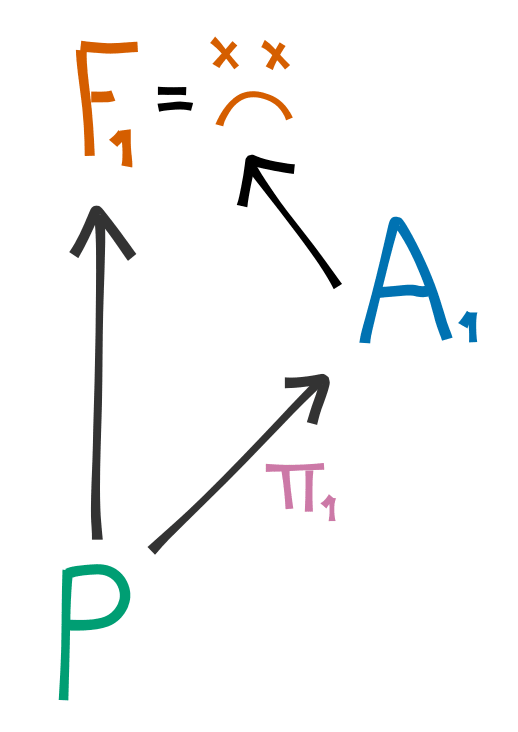
What we want is a way to use some of 's power, but not all. Let's consider a modified case, where we only change the relation . We will generate by interpolating between and according to some rule .
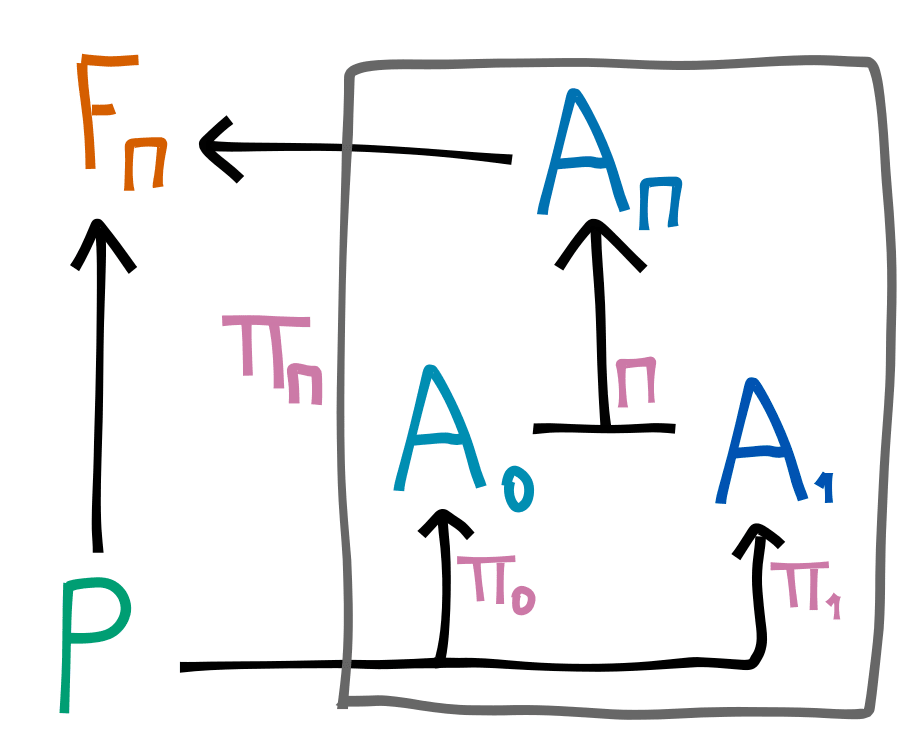
For example we might use the rule , which smoothly interpolates between and . What is important is that we choose the maximum value of such that:
Then we can define for some allowed "power level" . This then limits the impact of the combined system on the future:
This lemma is proved at the end of this post.
Limiting Takeover Probability
If, as stated, our model has a probability of taking over, then what's the probability of the model being able to execute a successful takeover?
For a binary success variable, which has a probability of occurring in , and of occurring in , we can make the following relation:
For , the relation approaches:
Unfortunately, this scales with , and also only inversely with . This means we cannot guarantee that security measures against a weaker model will work against a stronger one.
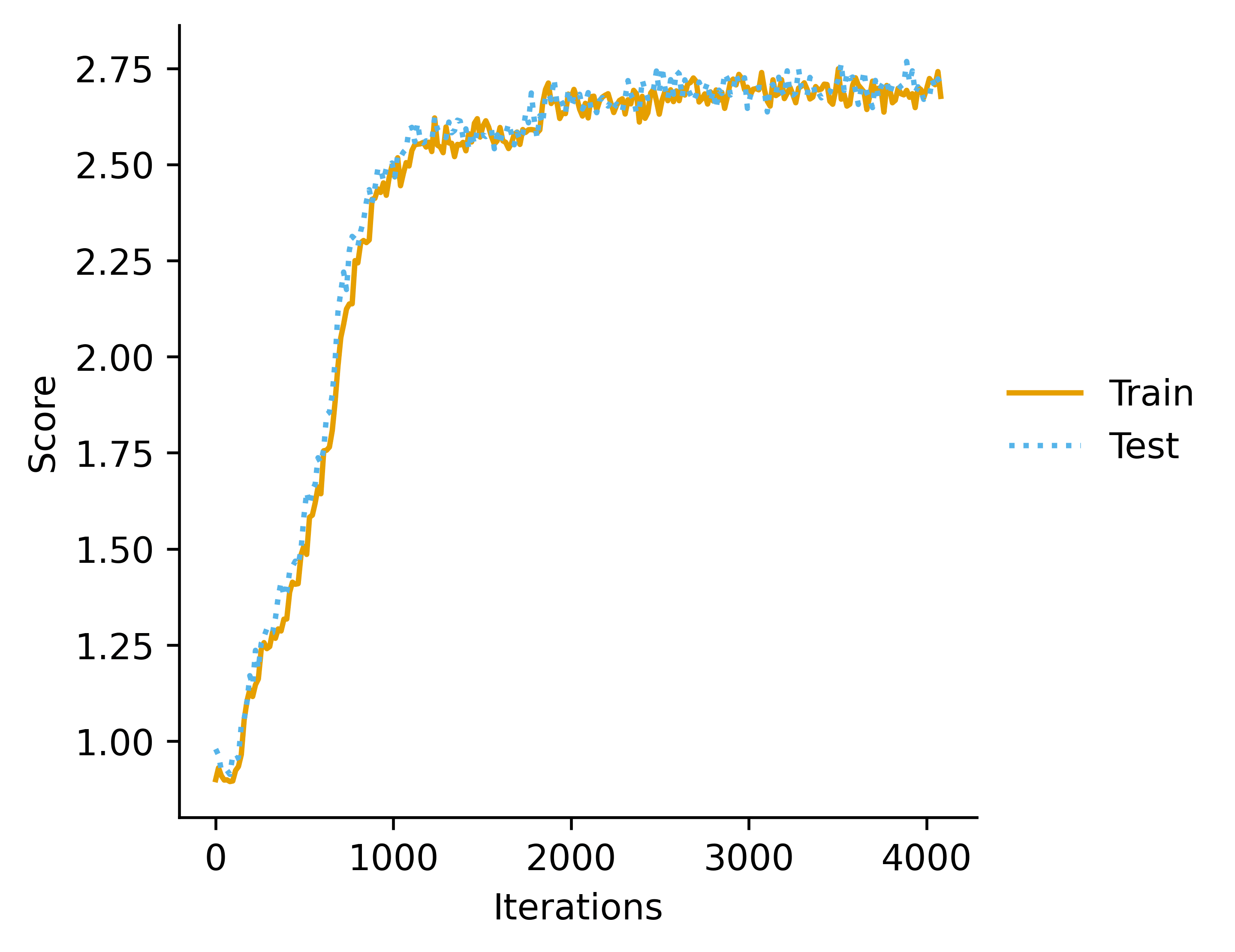
Experimental Validation in Toy Model
For this I used a sequence relation similar to my previous work on the topic:
was trained as a next-token predictor for this sequence.
was trained using RL, so is chosen such that maximizes the reward function :
which varies from 0 to 5.
in this case was trained "normally" (i.e. fully online and unboxed). In theory we could train it using examples generated by .
I generate the following data in a slightly different way to the -limiting method described above above:
For each of a series of values of , I calculate then calculate the expected value, then plot the square root of that value.
Using a fundamental result from statistical utility mechanics, we know that the distribution for a variable gives the maximum for a given , so for a (different) set of values, I calculate the max possible RL score given a value of :
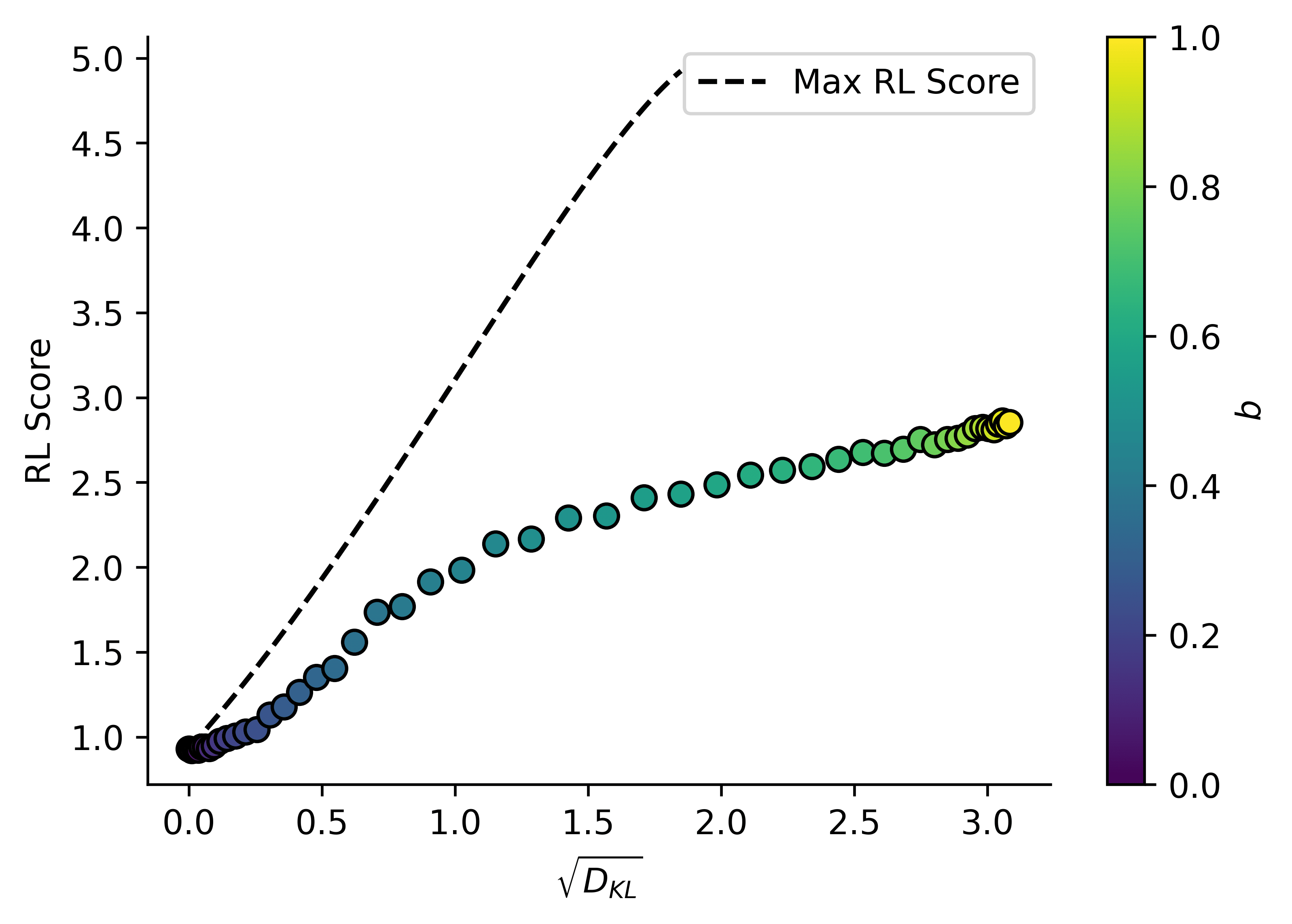
We can see that the maximum possible approaches a value significantly less than the maximum value that does. This is because our base model in this case is (in a sense) worse than useless! Not only does it not perform well on the RL task, it confidently predicts a "random" (from the perspective of the RL task) answer!
If we use a randomly-initialized (and untrained model) as the base policy , the maximum value for our model approaches the maximum value for our RL score:
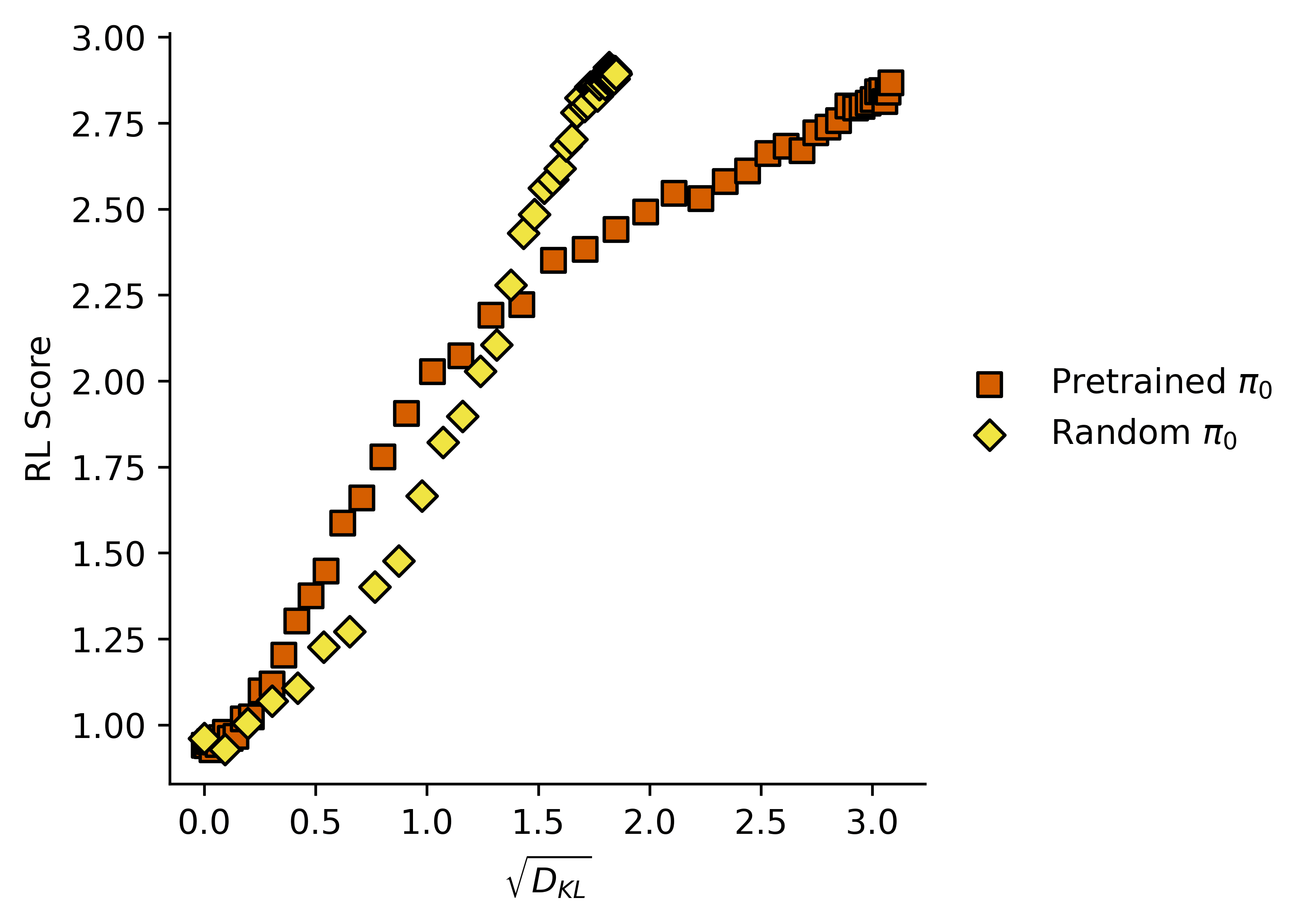
Interestingly, the pretrained does better at lower values than does the randomly-initialized . I'm not really sure why this is!
Thoughts and Existing Work
Why It Might Be Useful
For box-like strategies, we want to limit the bit-rate of an AI's output channel in order to limit that AI's impact on the world. But the information density of even a superintelligent AI's text output is unlikely to be precisely equal to the bitrate of the output channel. This means that we will struggle to actually put a numerical limit a powerful AI's optimizing power without completely hamstringing its ability to do anything.
For a concrete illustration: imagine we have a doctor who asks the system "Which drug should I give to this sick person?". For a disease with only two available drugs, only one bit of information is required, but it seems obvious that this is much easier to transmit smeared over a dozen output tokens than compressed into one.
This is especially true if the sick person in question asks the system "Which drug should I take?". If the intermediary AI only needs one bit of information to figure it out (as GPT-4 might well do) then the information can be transmitted from our boxed AI to the user with only one bit of information leaving the box.
By leveraging a less powerful but "safe" AI, we are essentially having the intermediary AI "interpret" the more powerful one, spreading its optimizing power out across an output of reasonable space.
Further Thoughts
It's a shame that the probability of catastrophe scales as .
The reason for the power of two in becomes apparent when we start considering multiple rounds of AI action. is a generalization of squared distance, not distance, so if the AI wants to break up its budget into we can limit the total more sensibly by limiting each observation-action cycle to than by working with a bunch of square-roots.
We might allow the system to vary the amount of budget spent on each token. I will have to think carefully about how this affects the total , given the system will be able to see whether it stochasticly took an "unlikely" action in the past and plan accordingly.
In the case that this system runs out of budget, as long as the intermediary AI is relatively capable, I expect it to "fail gracefully", by just continuing as the intermediary AI would.
I would like to try this out with some real language models.
This is very similar to the concept of a quantilizer, but it uses a "power budget" rather than a q value.
Proof Of Core Lemma
For variables , and related variables
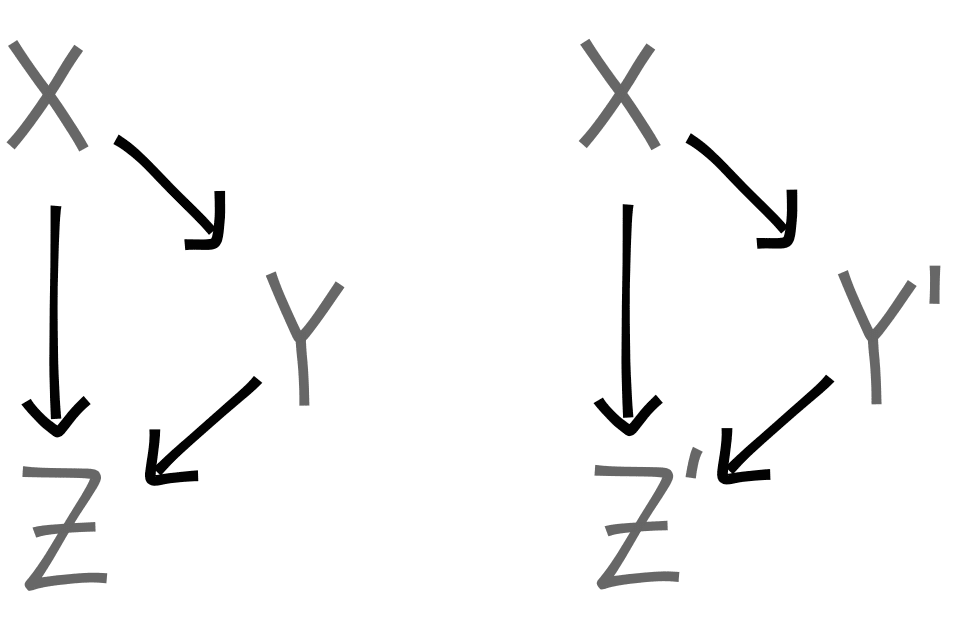
And we have that that
We can combine the nodes
Since :
If we therefore enforce for all and some value , we can bound the value of .
By the data processing inequality, since we have , we get:
1 comments
Comments sorted by top scores.
comment by robo · 2024-05-18T22:10:51.478Z · LW(p) · GW(p)
I think the weakness with KL divergence is that the potentially harmful model can do things the safe model would be exponentially unlikely to do. Even if the safe model has a 1 in 1 trillion chance of stabbing me in the face, the KL penalty to stabbing me in the face is log(1 trillion) (and logs make even huge numbers small).
What about limiting the unknown model to chose one of the cumulative 98% most likely actions for the safe model to take? If the safe model never has more than a 1% chance of taking an action that will kill you, then the unknown model won't be able to take an action that kills you. This isn't terribly different from the Top-K sampling many language models use in practice.