Deep sparse autoencoders yield interpretable features too
post by Armaan A. Abraham (armaanabraham) · 2025-02-23T05:46:59.189Z · LW · GW · 8 commentsContents
Summary Introduction Context Motivations Results What do I mean by deep SAE? SAE depth improves the reconstruction sparsity frontier Deep SAE features match or exceed shallow SAE features in automated interpretability scores Dead neurons are a problem Deep SAE feature activation contexts Conclusion Why should you care? Future directions Github Please reach out! None 8 comments
Summary
- I sandwich the sparse layer in a sparse autoencoder (SAE) between non-sparse lower-dimensional layers and refer to this as a deep SAE.
- I find that features from deep SAEs are at least as interpretable as features from standard shallow SAEs.
- I claim that this is not a tremendously likely result if you assume that the success of SAEs is entirely explained by the accuracy of the superposition hypothesis.
- I speculate that perhaps by relaxing our adherence to the concrete principles laid out by the superposition hypothesis, we could improve SAEs in new ways.
Introduction
Context
Instead of rehashing the superposition hypothesis and SAEs, I will just link these wonderful resources: Toy Models of Superposition and Towards Monosemanticity.
Motivations
My sense is that the standard justification for the success of SAEs is that the superposition hypothesis is just an accurate model of neural network function, which directly translates to SAE effectiveness. While many of the arguments for the superposition hypothesis are compelling, I had a growing sense that the superposition hypothesis was at least not a sufficient explanation for the success of SAEs.
This sense came from, for example, inconsistencies between empirical findings in the posts linked above, for example that features will take similar directions in activation space if they don’t co-occur often, but also if they have similar effects on downstream model outputs, which seems contradictory in many cases. I won't elaborate too much on this intuition because (1) I don’t think understanding this intuition is actually that necessary to appreciate these results even if it served to initiate the project, (2) in hindsight, I don’t even think that these results strongly confirm my original intuition (but they also don’t oppose it).
Ultimately, I posited that, if there is some unidentified reason for the success of SAEs, it might be that sparsity is just a property of representations that us humans prefer, in some more abstract sense. If this were true, we should directly aim our SAEs to produce the most faithful and sparse representations of neural network function as possible, possibly abandoning some of the concrete principles laid out by the superposition hypothesis. And it seems that the obvious way to do this is to add more layers.
I'm posting my work so far because:
- I want to see if I'm missing something obvious, and to get feedback more generally.
- If the results are valid, then I think they may be interesting for people in mechanistic interpretability.
- I am hoping to connect with people who are interested in this area.
Results
What do I mean by deep SAE?
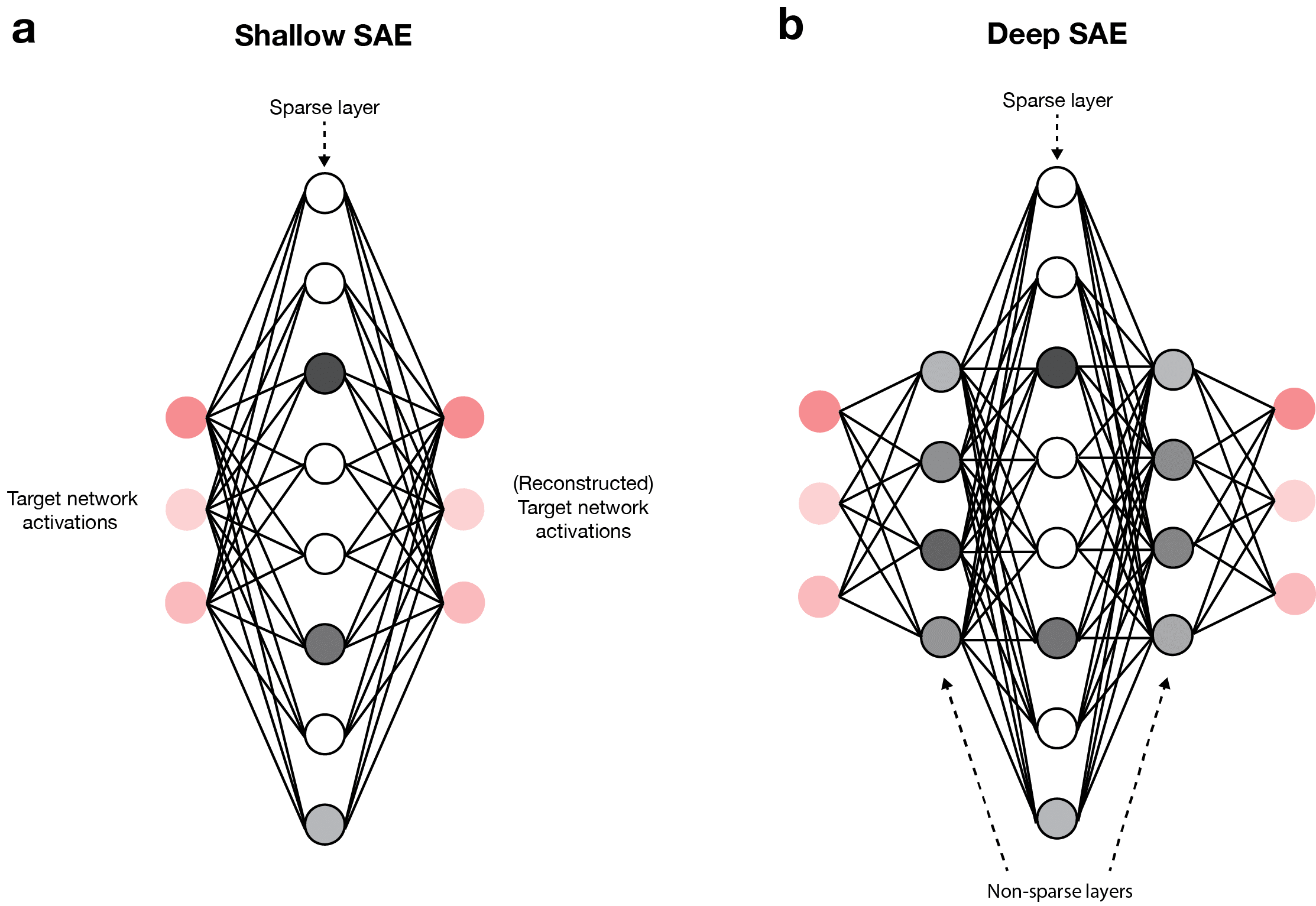
Standard applications of sparse autoencoders to the interpretation of neural networks use a single sparsely activating layer to reconstruct the activations of the network being interpreted (i.e., the target network) (Fig. 1a). This architecture will be referred to as a shallow SAE.
Here, I propose using deep SAEs for interpreting neural networks. Abstractly, this includes the addition of more layers (either non-sparse or sparse) to a shallow SAE. Concretely, the implementation I use here involves sandwiching a single sparse layer between one or more non-sparse layers (Fig. 1b). Throughout this work, all of the deep SAEs I present will take this structure and, moreover, the dimensions of the non-sparse layers will have reflection symmetry across the sparse layer (i.e., if there are non-sparse layers with dimensions 256 and 512 before the sparse layer, then there will be non-sparse layers with dimensions 512 and 256 after the sparse layer). In describing deep SAE architectures, I will sometimes use shorthand like “1 non-sparse” which, in this case, would just mean that there is one non-sparse layer before the sparse layer and one non-sparse layer after it.
In the experiments below, I use tied initialization for the encoder and decoder matrices, as previously described, which is only possible because of the symmetry of the encoder and decoder layers as described above. I also constrained the columns for all decoder matrices to unit norm, including those producing hidden layer activations (i.e., not just the final decoder matrix), as previously described. This unit norm constraint empirically showed to reduce dead features and stabilize training, particularly for deeper SAEs. I subtract the mean and divide by the norm across the dimension before using LLM activations for SAE input and analysis. I use ReLU activation functions for all SAE layers, and I use a top-k activation function for the sparse layer. I used two different strategies to reduce dead neurons: dead neuron resampling, and a new approach, where I penalize the mean of the square of the sparse feature activations, which I will refer to as activation decay.
SAE depth improves the reconstruction sparsity frontier
A common measure of SAE performance is how well it can reconstruct the activations (as measured by the MSE) at a given level of sparsity. Deep SAEs perform better than shallow SAEs on this metric (Fig. 2), which is unsurprising given that they are strictly more expressive. Here, I show the normalized MSE (i.e., the variance explained), which is the MSE of the SAE reconstructions divided by the MSE from predicting the mean activation vector. All of these SAEs were trained to reconstruct the activations of the residual stream after layer 8 of GPT2-small, where activations were collected on the common crawl dataset. I applied activation decay (with a coefficient of 1e-3) to both the deep and narrow SAE and neuron resampling to only the shallow SAE. This experiment uses a smaller number of sparse features for its SAEs than the next experiment and excludes deep SAEs beyond 1 non-sparse layer due to time and compute budget constraints.
It should be noted that this really says nothing about the interpretability of deep SAEs. A lower MSE does imply a more faithful representation of the true underlying network dynamics, but a low MSE may coexist with uninterpretable and/or polysemantic features.

Deep SAE features match or exceed shallow SAE features in automated interpretability scores
The real test for deep SAEs is not the faithfulness of their reconstructions (as we would expect them to perform well on this), but how interpretable their features are. To test this, I trained SAEs of various depths and passed their sparse features through an automated interpretability pipeline developed by EleutherAI to attain average interpretability scores. This automated interpretability pipeline involves choosing a particular feature, showing examples of text on which that feature activates to an LLM, like Claude, and asking it to generate an explanation of that feature, and finally, showing that explanation to another LLM and measuring the accuracy to which it’s able to predict whether that feature activates for unlabeled snippets of text. I conducted two variants of this test: detection and fuzzing. Detection involves measuring the accuracy of predictions of whether the feature activated at all in a snippet, and fuzzing involves measuring the accuracy of predictions of which words that feature activated on in the snippet.
Three SAEs were trained, each with 24576 sparse features and k=128, on the residual stream after layer 8 of GPT2-small. The first was a shallow SAE; the second was a deep SAE with one non-sparse layer of dimension 1536 (2x the dimension of GPT2-small) added to each side of the sparse layer, so, the dimensions of each layer, in order, are 1536, 24576, 1536; and the third SAE was also deep, with 2 non-sparse layers added to each side of the sparse layer, with dimensions 1536 (2x GPT2 dimension) and 3072 (4x GPT2 dimension), so the layer dimensions are 1536, 3072, 24576, 3072, 1536. I trained all SAEs with activation decay with a coefficient of 1e-3 (dead neuron resampling was not used for the shallow SAE in contrast to the previous experiment, in an attempt to reduce confounders).
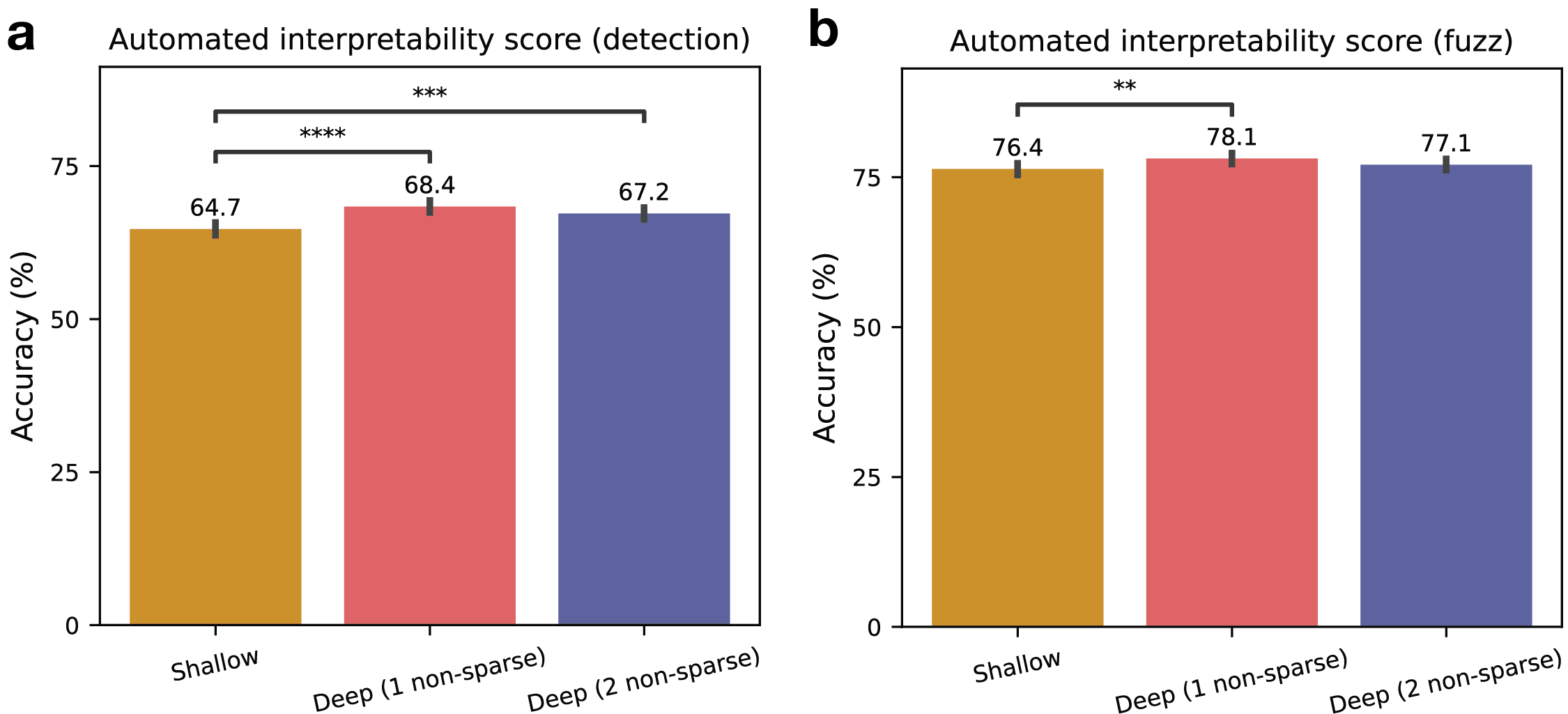
Overall, we see that deep SAE features are just as interpretable as shallow SAE features by both of these automated interpretability measures (Fig. 3). Neither the 1 non-sparse layer nor the 2 non-sparse layer SAE show interpretability scores lower than the shallow SAE, and both the 1 non-sparse layer and 2 non-sparse layer SAEs actually score slightly higher than the shallow SAE on the detection task. It would also be useful to run this experiment while controlling for the total parameter count, by decreasing the dimension of the sparse layer for deeper SAEs.
Dead neurons are a problem
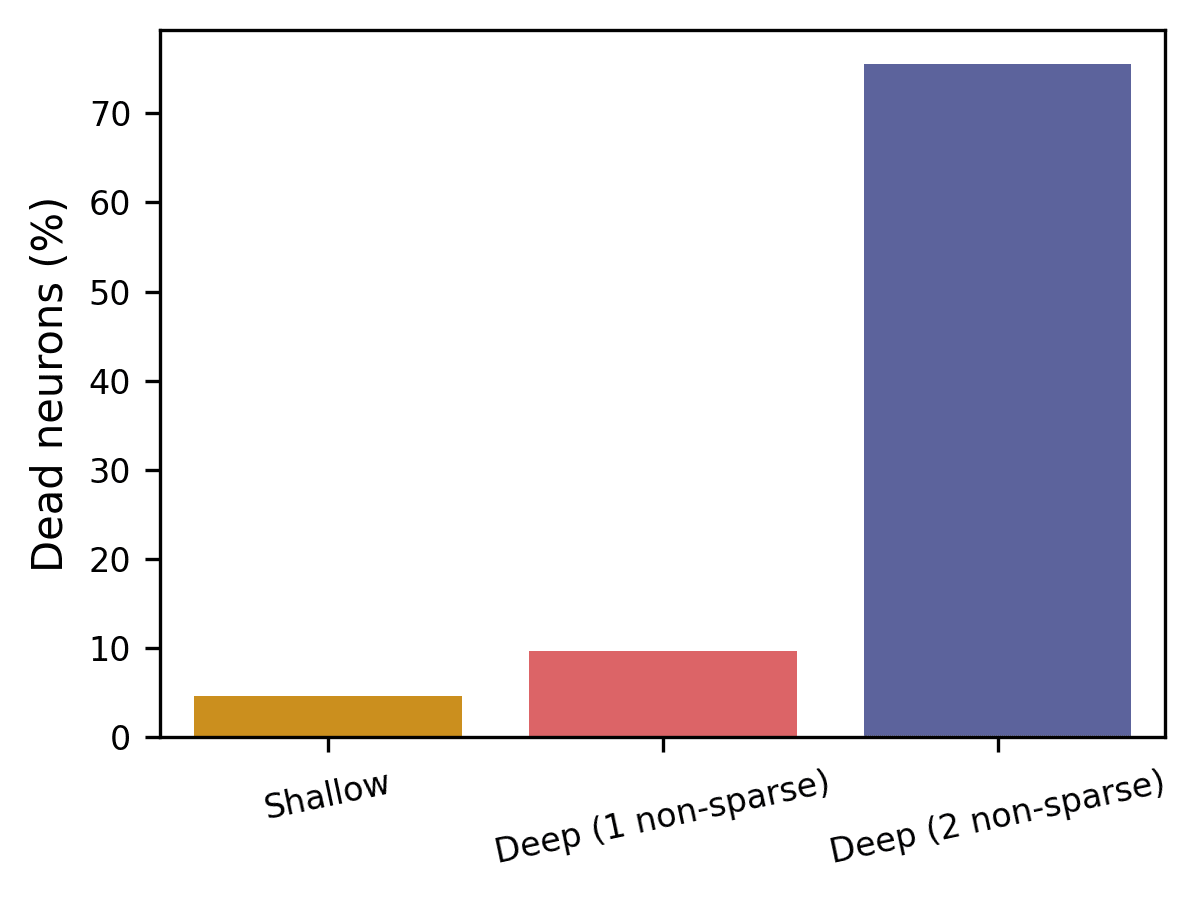
Increased SAE depth also tends to correspond to more dead features (Fig. 4), and this has been the biggest technical challenge in this project so far. I define a neuron as dead if it has not activated over the past 1.5 million inputs. I have a few new ideas for mitigating this issue that I’m optimistic about, but I wanted to share my work at this stage before investigating them.
Why is having dead neurons bad? For one, it will reduce your reconstruction accuracy. But also, this correlation between SAE depth and dead neuron frequency is a confounding factor in the interpretability analysis. For example, one of the reasons that I don’t make any claims about whether one SAE architecture is more interpretable than another is the vast difference in dead neurons between various architectures, and that the number of dead neurons almost certainly affects the automated interpretability score.
Deep SAE feature activation contexts
While difficult to present here, it’s also important to get a feel for these SAE features by looking at their activation contexts yourself. I’ve included examples of activation contexts for four features from the 1 non-sparse layer SAE for a taste of this (Fig. 5). These are sampled randomly from contexts on which the feature activates.

Conclusion
Why should you care?
I think that these results pretty strongly indicate that deep SAEs yield features which are on par with shallow SAEs in interpretability.
I also claim that conditioning on the success of SAEs being entirely explained by the accuracy of the superposition hypothesis implies a somewhat low probability of deep SAEs producing features that are interpretable at all. Like, if you have these clean linear features in your residual stream, and your single projection onto an overcomplete basis just effectively takes them out of superposition, wouldn’t adding more non-sparse layers just jumble them all up and reintroduce polysemanticity? From this perspective, these results support my original hypothesis that the theory of superposition does not fully explain the success of SAEs.
On the other hand, there is a story you could tell where this is still entirely linear feature superposition at work. Maybe, the non-sparse layers are just grouping together co-occurring linear features in the encoder and then ungrouping them in the decoder.
Either way, I think it is possible that adding more layers is a way to actually improve SAEs. Currently, it only seems like you can scale SAEs by making them wider, but maybe depth is also a dimension along which we can scale.
Edit (thanks to @Logan Riggs [LW · GW] for bringing this up in the comments):
One of the major limitations of this approach is that the added nonlinearities obscure the relationship between deep SAE features and upstream / downstream mechanisms of the model. In the scenario where adding more layers to SAEs is actually useful, I think we would be giving up on this microscopic analysis, but also that this might be okay. For example, we can still examine where features activate and generate/verify human explanations for them. And the idea is that the extra layers would produce features that are increasingly meaningful/useful for this type of analysis.
Future directions
While my major claim in this post is that deep SAEs yield features which are as interpretable as shallow SAE features, I think it is plausible that controlling for the number of dead neurons would show that deep SAEs actually produce more interpretable features. The main technical challenge holding up this analysis of course is the reduction of dead neurons in deeper SAEs.
But also, I have several other directions for future investigation. For example:
- Are there consistent differences in the overall character of the features yielded by SAEs of increasing depth? For example, do deeper SAEs yield more abstract features?
- Would we see predictable changes in model behavior if we ablate deep SAE features?
- I think that the knee-jerk answer to this is no. But I also think the fact that deep SAEs are interpretable at all may question some of the assumptions that would lead to this answer. One way to look at this is that just as we can reason about linear features in the activation space of the model we are examining, perhaps we can just as easily reason about linear features in the activation space of the SAE, which I think would imply that ablations would yield predictable behavioral changes.
- How similar are the encoder and decoder of deep SAEs? For example, do we see any similarities that could indicate the grouping and ungrouping of linear features? Or are the encoder and decoder just distinct messes of weights?
Github
Automated interpretability score (fork)
Please reach out!
Above all, the reason I’m posting this work at its current stage is so that I can find people who may be interested in this work. Additionally, I’m new to mechanistic interpretability and alignment more generally, so I would greatly value receiving mentorship from someone more experienced. So, if you’re interested in collaboration, being a mentor, or just a chat, please do reach out to armaan.abraham@hotmail.com!
8 comments
Comments sorted by top scores.
comment by Logan Riggs (elriggs) · 2025-02-24T16:22:07.742Z · LW(p) · GW(p)
Hey Armaan! Here's a paper where they instead used an MLP in the beginning w/ similar results (looking at your code, it seems by "dense" layer, you also mean a nonlinearity, which seems equivalent to the MLP one?)
How many tokens did you train yours on?
Have you tried ablations on the dense layers, such as only having the input one vs the output one? I know you have some tied embeddings for both, but I'm unsure if the better results are for the output or input.
For both of these, it does complicate circuits because you'll have features combining nonlinearly in both the input and output. Normal SAEs just have the one nonlinearity to worry about but you'll have 3/SAE.
Replies from: armaanabraham↑ comment by Armaan A. Abraham (armaanabraham) · 2025-02-24T19:23:53.578Z · LW(p) · GW(p)
Ah, I was unaware of that paper and it is indeed relevant to this, thank you! Yes, by "dense" or "non-sparse" layer, I mean a nonlinearity. So, that paper's MLP SAE is similar to what I do here, except it is missing MLPs in the decoder. Early on, I experimented with such an architecture with encoder-only MLPs, because (1) as to your final point, the lack of nonlinearity in the output potentially helps it fit into other analyses and (2) it seemed much more likely to me to exhibit monosemantic features than an SAE with MLPs in the decoder too. But, after seeing some evidence that its dead neuron problems reacted differently to model ablations than both the shallow SAE and the deep SAE with encoder+decoder MLPs, I decided to temporarily drop it. I figured that if I found that the encoder+decoder MLP SAE features were interpretable, this would be a more surprising/interesting result than the encoder-only MLP SAE and I would run with it, and if not, I would move to the encoder-only MLP SAE.
I trained on 7.5e9 tokens.
As I mentioned in my response to your first question, I did experiment early on with the encoder-only MLP, but the architectures in this post are the only ones I looked at in depth for GPT2.
This is a good point, and I should have probably included this in the original post. As you said, one of the major limitations of this approach is that the added nonlinearities obscure the relationship between deep SAE features and upstream / downstream mechanisms of the model. In the scenario where adding more layers to SAEs is actually useful, I think we would be giving up on this microscopic analysis, but also that this might be okay. For example, we can still examine where features activate and generate/verify human explanations for them. And the idea is that the extra layers would produce features that are increasingly meaningful/useful for this type of analysis.
↑ comment by Logan Riggs (elriggs) · 2025-02-24T19:49:03.705Z · LW(p) · GW(p)
I agree. There is a tradeoff here for the L0/MSE curve & circuit-simplicity.
I guess another problem (w/ SAEs in general) is optimizing for L0 leads to feature absorption. However, I'm unsure of a metric (other than the L0/MSE) that does capture what we want.
comment by luciaquirke · 2025-03-08T14:43:10.422Z · LW(p) · GW(p)
Hey, I love this work!
We've had success fixing dead neurons using the Muon or Signum optimizers, or by adding a linear k-decay schedule (all available in EleutherAI/sparsify). The alternative optimizers also seem to speed up training a lot (~50% reduction).
To the best of my knowledge all dead neurons get silently excluded from the auto-interpretability pipeline, there's a PR just added to log this more clearly https://github.com/EleutherAI/delphi/pull/100 but yeah having different levels of dead neurons probably affects the score.
This post updates me towards trying out stacking more sparse layers, and towards adding more granular interpretability information.
Replies from: armaanabraham↑ comment by Armaan A. Abraham (armaanabraham) · 2025-03-08T16:43:55.679Z · LW(p) · GW(p)
I will look into these optimizers, thank you for the tip!
I was aware that dead neurons get excluded from the auto-interpretability pipeline. My comment about dead neurons affecting the score was more about the effective reduction in sparse dimension due to the dead neurons being an issue for the neurons that are alive.
I would be very interested in any progress you make related to more granular automated interpretability information. Do you currently have any ideas for what this might look like? I've given it a tiny bit of thought, but haven't gotten very far.
Replies from: luciaquirke↑ comment by luciaquirke · 2025-03-09T03:59:57.284Z · LW(p) · GW(p)
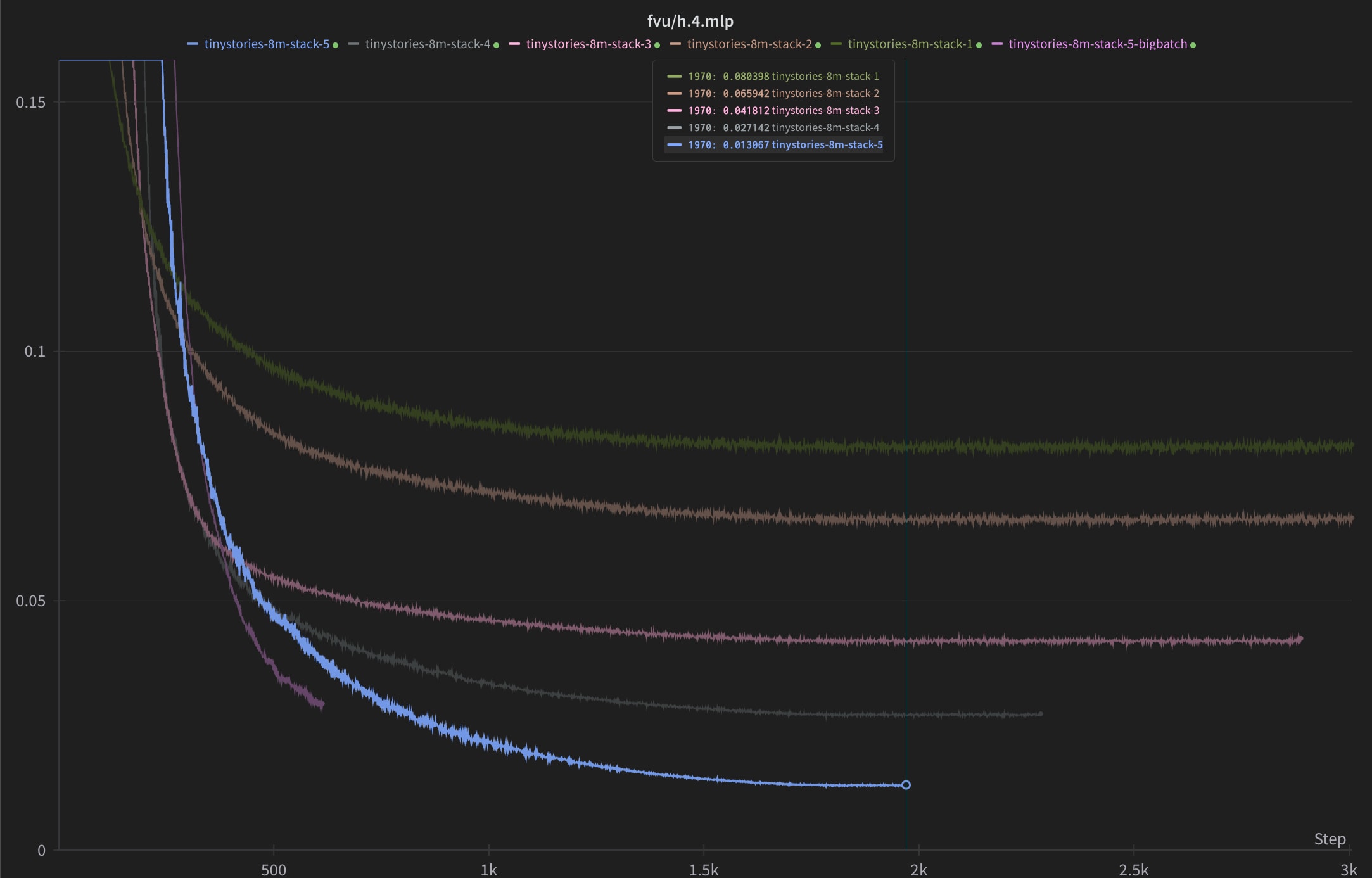
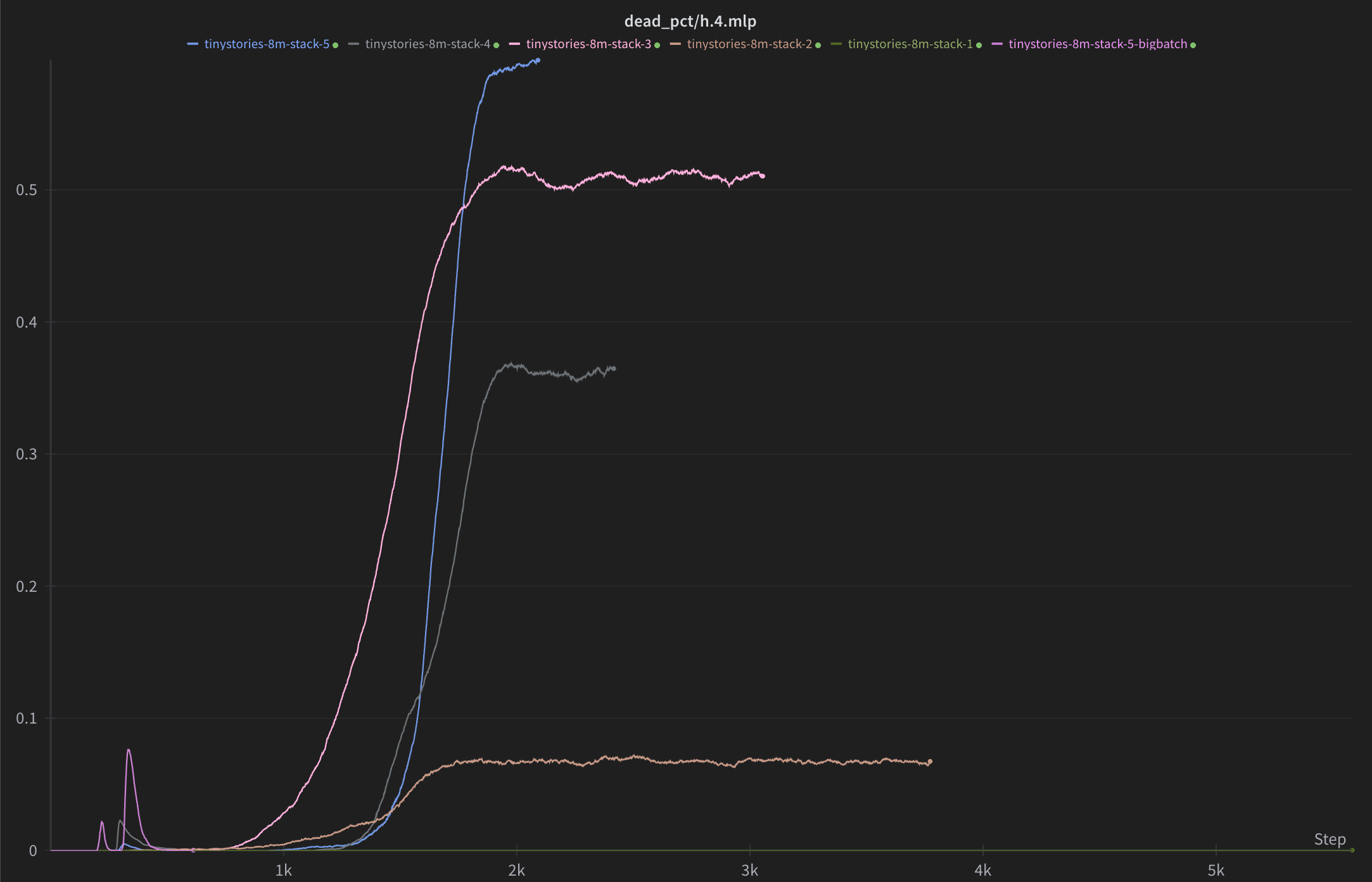
I tried stacking top-k layers ResNet-style on MLP 4 of TinyStories-8M and it worked nicely with Muon, with fraction of variance explained reduced by 84% when going from 1 to 5 layers (similar gains to 5xing width and k), but the dead neurons still grew with the number of layers. However dropping the learning rate a bit from the preset value seemed to reduce them significantly without loss in performance, to around 3% (not pictured).
Still ideating but I have a few ideas for improving the information-add of Delphi:
- For feature explanation scoring it seems important to present a mixture of activating and semantically similar non-activating examples to the explainer and to the activation classifier, rather than a mixture of activating and random (probably very dissimilar) examples. We're introducing a few ways to do this, e.g. using the neighbors option to generating the non-activating examples. I suspect a lot of token-in-context features are being incorrectly explained as token features when we use random non-activating examples.
- I'm interested in weighting feature interpretability scores by their firing rate, to avoid incentivizing sneaking through a lot of superposition in a small number of latents (especially for things like matryoshka SAEs where not all latents are trained with the same loss function).
- I'm interested in providing the "true" and unbalanced accuracy given the feature firing rates, perhaps after calibrating the explainer model to use that information.
- I think it would be cool to log the % of features with perfect interpretability scores, or another metric that pings features which sneak through polysemanticity at low activations.
- Maybe measuring agreement between explanation generations on different activation quantiles would be interesting? Like if a high quantile is best interpreted as "dogs at the park" and a low quantile just "dogs" we could capture that.
- Like a measure of specificity drop-off
https://github.com/EleutherAI/sparsify/compare/stack-more-layers
python -m sparsify roneneldan/TinyStories-8M roneneldan/TinyStories --batch_size 32 --ctx_len 256 --k 32 --distribute_modules False --data_preprocessing_num_proc 48 --load_in_8bit false --shuffle_seed 42 --expansion_factor 64 --text_column text --hookpoints h.4.mlp --log_to_wandb True --lr_warmup_steps 1000 --activation topk --optimizer muon --grad_acc_steps 8 --num_layers 5 --run_name tinystories-8m-stack-5↑ comment by Armaan A. Abraham (armaanabraham) · 2025-03-09T17:15:59.445Z · LW(p) · GW(p)
This is great. I'm a bit surprised you get such a big performance improvement from adding additional sparse layers; all of my experiments above have been adding non-sparse layers, but it looks like the MSE benefit you're getting with added sparse layers is in the same ballpark. You have certainly convinced me to try muon.
Another approach that I've (very recently) found quite effective in reducing the number of dead neurons with minimal MSE hit has been adding a small penalty term on the standard deviation of the encoder pre-act (i.e., before the top-k) means across the batch dimension. This has basically eliminated my dead neuron woes and this is what I'm currently running with. I'll probably try this in combination with muon sometime over the next couple of days.
And these ideas all sound great.
comment by adam-oberman · 2025-02-25T16:03:25.904Z · LW(p) · GW(p)
Interesting! Thanks for the post!