Posts
Comments
I tried stacking top-k layers ResNet-style on MLP 4 of TinyStories-8M and it worked nicely with Muon, with fraction of variance explained reduced by 84% when going from 1 to 5 layers (similar gains to 5xing width and k), but the dead neurons still grew with the number of layers. However dropping the learning rate a bit from the preset value seemed to reduce them significantly without loss in performance, to around 3% (not pictured).
Still ideating but I have a few ideas for improving the information-add of Delphi:
- For feature explanation scoring it seems important to present a mixture of activating and semantically similar non-activating examples to the explainer and to the activation classifier, rather than a mixture of activating and random (probably very dissimilar) examples. We're introducing a few ways to do this, e.g. using the neighbors option to generating the non-activating examples. I suspect a lot of token-in-context features are being incorrectly explained as token features when we use random non-activating examples.
- I'm interested in weighting feature interpretability scores by their firing rate, to avoid incentivizing sneaking through a lot of superposition in a small number of latents (especially for things like matryoshka SAEs where not all latents are trained with the same loss function).
- I'm interested in providing the "true" and unbalanced accuracy given the feature firing rates, perhaps after calibrating the explainer model to use that information.
- I think it would be cool to log the % of features with perfect interpretability scores, or another metric that pings features which sneak through polysemanticity at low activations.
- Maybe measuring agreement between explanation generations on different activation quantiles would be interesting? Like if a high quantile is best interpreted as "dogs at the park" and a low quantile just "dogs" we could capture that.
- Like a measure of specificity drop-off
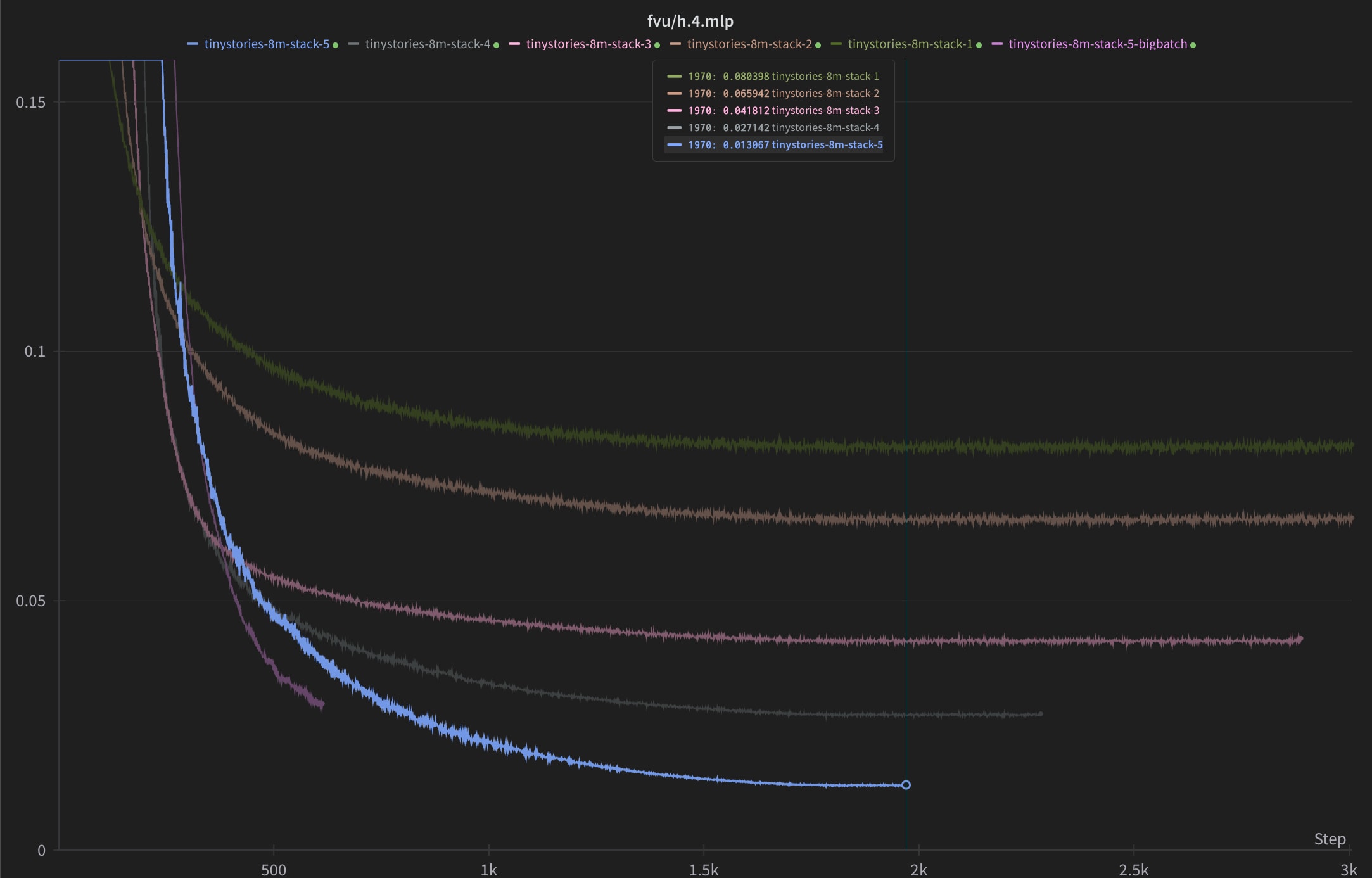
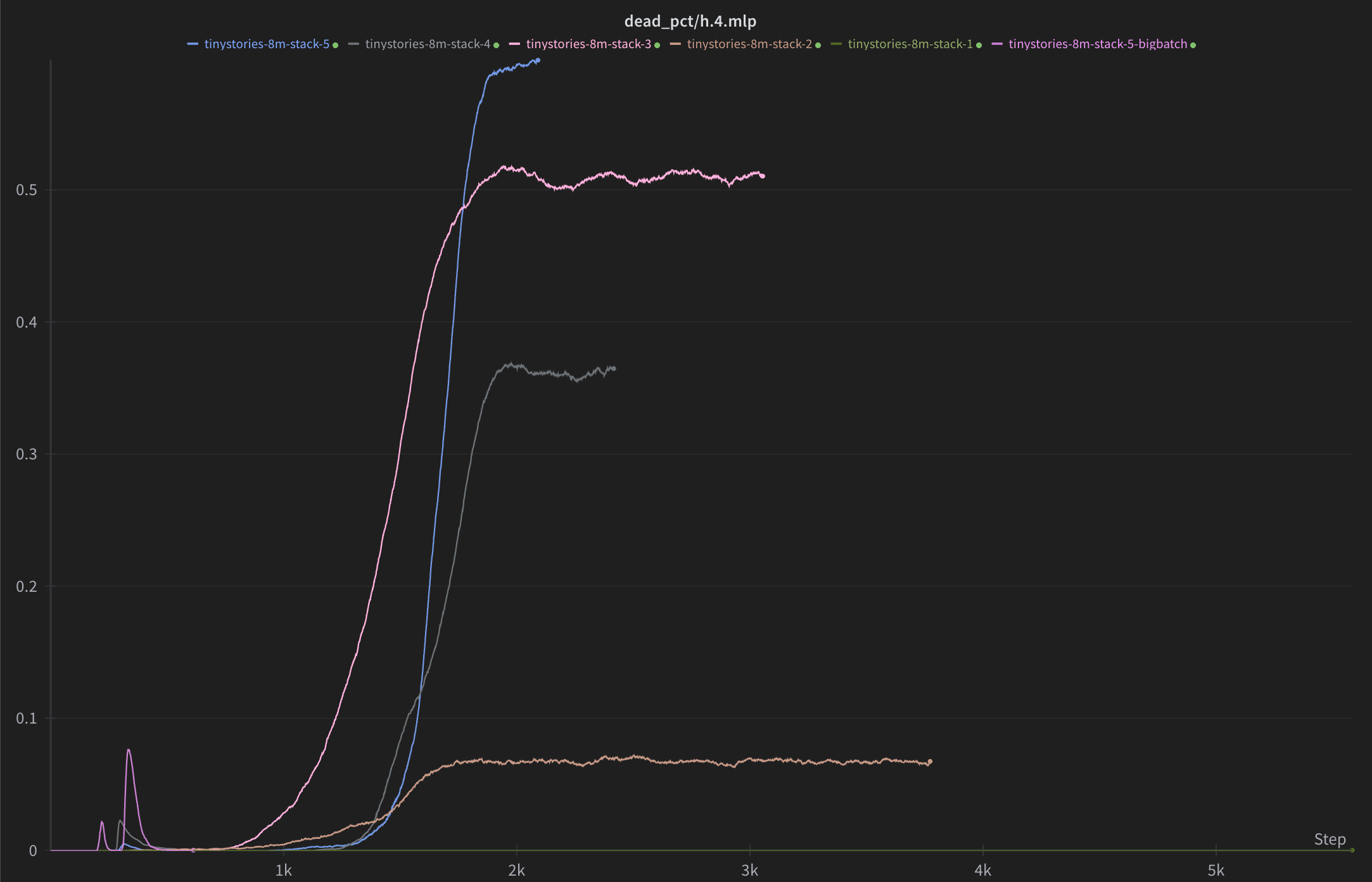
https://github.com/EleutherAI/sparsify/compare/stack-more-layers
python -m sparsify roneneldan/TinyStories-8M roneneldan/TinyStories --batch_size 32 --ctx_len 256 --k 32 --distribute_modules False --data_preprocessing_num_proc 48 --load_in_8bit false --shuffle_seed 42 --expansion_factor 64 --text_column text --hookpoints h.4.mlp --log_to_wandb True --lr_warmup_steps 1000 --activation topk --optimizer muon --grad_acc_steps 8 --num_layers 5 --run_name tinystories-8m-stack-5Hey, I love this work!
We've had success fixing dead neurons using the Muon or Signum optimizers, or by adding a linear k-decay schedule (all available in EleutherAI/sparsify). The alternative optimizers also seem to speed up training a lot (~50% reduction).
To the best of my knowledge all dead neurons get silently excluded from the auto-interpretability pipeline, there's a PR just added to log this more clearly https://github.com/EleutherAI/delphi/pull/100 but yeah having different levels of dead neurons probably affects the score.
This post updates me towards trying out stacking more sparse layers, and towards adding more granular interpretability information.
Is there anything you recommend for understanding the history of the field?
Thanks for the comment, fair point! I found Vast.AI to be frustratingly unreliable when I started using it but it seems to have improved over the last three months, to the point where it feels comparable to (how I remember) LambdaLabs. LambdaLabs definitely has the best UI/UX though. I've amended the post to clarify.
I've had one great and one average experience with RunPod customer service, but haven't interacted with anyone from the other services.
Working on Remote Machines
Unless you have access to your own GPU or a private cluster, you will probably want to rent a machine. The best guide to getting set up with Vast.AI, the cheapest and (close to) the most reliable provider, is James Dao's doc: https://docs.google.com/document/d/18-v93_lH3gQWE_Tp9Ja1_XaOkKyWZZKmVBPKGSnLuL8/edit?usp=sharing
In addition,
- Vast.AI is not always available, be prepared to switch providers
- Fast setup is useful, try a custom Docker image
Providers
The main providers are Vast.AI, RunPod, Lambda Labs, and newcomer TensorDock. Occasionally someone will rent out all the top machines over multiple providers, so be mentally prepared to switch between providers.
Lambda Labs has persistent storage in some regions, the most reliable machines, and the best UX. Their biggest issues is that they're more expensive and have limited availability - it's common for all the machines to be rented out. LambdaLabs is also the only service that doesn't let you add credit beforehand. Instead, it takes your card then charges your bank account as you use compute, which is a bit scary because it’s easy to leave a machine running overnight.
RunPod also has persistent storage and nice UX. Their biggest issue is that they don't document the many, many rough edges of the service. Notably:
- Their Community Cloud machines often suffer from extremely slow network speeds, but their Secure Cloud machines are more reliable.
- They seem to bake necessary functionality into their Docker images such that custom images don't work without tinkering (https://github.com/runpod/containers/blob/main/official-templates/pytorch/Dockerfile).
- They don't let you specify a startup script. Their instance configuration lets you specify a "Docker command" which is a literal Docker CMD instruction except you have to exclude the CMD bit at the start.
- Their provided Docker images are missing basic packages (e.g. no rsync)
Vast.AI uses tmux for the terminal which is not user friendly, but lets you close the SSH tunnel without killing your processes. I recommend keeping a cheat sheet handy. The most important command is Ctrl-b [ to enable scrolling.
Setup
You generally lose your files when you stop your machine so you need to be able to set up from scratch quickly. To enable this most providers let you specify a Docker image and an ‘on startup’ script to run by default when you rent out a machine.
I use my on startup script to clone git repositories and store credentials but I haven’t gotten it to work for installing packages (possibly fixable problem idk).
One way to get around this is to copy and paste a package installation script into the terminal every morning. This is annoying but works well for most packages, but PyTorch/TensorFlow is too large and complex, so select a Docker image with the machine learning framework you use installed.
To avoid running the package installation script completely, pre-install all your packages into a Docker image then set that as the default image in your compute provider. My Dockerfile is just the PyTorch Docker image plus a few packages specific to mechanistic interpretability.
Dockerfile
FROM pytorch/pytorch:latest
RUN apt-get update && apt-get install -y git
RUN pip install tqdm einops seaborn plotly-express kaleido \
scikit-learn torchmetrics ipykernel ipywidgets nbformat \
git+https://github.com/neelnanda-io/TransformerLens \ git+https://github.com/callummcdougall/CircuitsVis.git#subdirectory=python \
git+https://github.com/neelnanda-io/neelutils.git \
git+https://github.com/neelnanda-io/neel-plotly.gitStartup script
runuser -l root -c 'export GITHUB_USER=<username> GITHUB_PAT=<PAT> GIT_NAME=<name> GIT_EMAIL=<email>; git config --global user.name <username>; git config --global user.email <email>; git clone https://$GITHUB_USER:$GITHUB_PAT@github.com/<GitHub repo>.git; cd <GitHub repo>; exec bash; conda init;’IDE
I found JetBrains' support for remote machines lacking - the debugger doesn't work over SSH and the IDE is slow to download and boot up. I use VSCode instead, which has a debugger so slow it's almost useless but downloads quickly and has a setting where you can specify extensions for automatic download on remote machines which works smoothly.
If we can patch a head from "The Eiffel Tower is in" to "The Colosseum is in" and flip the answer from Rome to Paris, that seems like strong evidence that that head contained the key information about the input being the Eiffel Tower!
[nit] I believe this part should read "Paris to Rome".