How to Think About Activation Patching
post by Neel Nanda (neel-nanda-1) · 2023-06-04T14:17:42.264Z · LW · GW · 5 commentsThis is a link post for https://www.neelnanda.io/mechanistic-interpretability/attribution-patching#how-to-think-about-activation-patching
Contents
What Is the Point of Patching?
Patching Clean to Corrupted vs Corrupted to Clean
What Do I Mean By "Circuit"?
How does redundancy & superposition change the picture?
What Can('t) Activation Patching Teach Us?
Specific vs general work
What Would It Look Like to Aim for General Understanding?
Does This Make Any Sense?
Single vs Multi Features Dependence
Linear vs Non-Linear (Local) Structure
None
5 comments
This is an excerpt from my post on attribution patching, that I think is of more general interest, around how to think about the technique of activation patching in mechanistic interpretability, and what it can and cannot teach us. You don't need to know what attribution patching is to read this, check out this section for an overview of activation patching
What Is the Point of Patching?
The conceptual framework I use when thinking about patching is to think of a model as an enormous mass of different circuits. On any given input, many circuits will be used. Further, while some circuits are likely very common and important (eg words after full stops start with capitals, or "this text is in English"), likely many are very rare and niche and will not matter on the vast majority of inputs (eg "this is token X in the Etsy terms and conditions footer" - a real thing that GPT-2 Small has neurons for!). For example, on IOI, beyond the actual IOI circuit, there is likely circuits to:
- Detect multi-token words (eg names) and assemble them into a single concept
- Detect that this is English text
- Detect that this is natural language text
- Encode unigram frequencies (under which John is 2-3x as likely as Mary!)
- Copying all names present in the context - if a name is present in the text it's way more likely to occur next than an unseen name!
- That this is the second clause of a sentence
- That Indirect Object Identification is the right grammatical structure to use
- That the next word should be a name
As a mech interp researcher, this is really annoying! I can get traction on a circuit in isolation, and there's a range of tools with ablations, direct logit attribution, etc to unpick what's going on. And hopefully any given circuit will be clean and sparse, such that I can ignore most of a model's parameters and most activation dimensions, and focus on what's actually going on. But when any given input triggers many different circuits, it's really hard to know what's happening.
The core point of patching is to solve this. In IOI, most of the circuits will fire the same way regardless of which name is the indirect object/repeated subject. So by formulating a clean and corrupted input that are as close as possible except for the key detail of this name, we can control for as many of the shared circuits as possible. Then, by patching in activations from one run to another, we will not affect the many shared circuits, but will let us isolate out the circuit we care about. Taking the logit difference (ie difference between the log prob of the correct and incorrect answer) also helps achieve this, by controlling for the circuits that decide whether to output a name at all.
Importantly, patching should be robust to some of our conceptual frameworks being wrong, eg a model not having a linear representation, circuits mattering according to paths that go through every single layer, etc. Though it's much less informative when a circuit is diffuse across many heads and neurons than when it's sparse.
Whenever reasoning about patching, it's valuable to keep this in mind! And to be clear to yourself about what exactly is the scope of your investigation - which circuits do you want to identify, how well have you controlled for the irrelevant circuits, what aspects of the circuits you do care about have you accidentally controlled for, etc. And even if you want to identify several circuits, it's generally best to try to have several types of clean and corrupted inputs, so that you can isolate out each circuit one at a time (eg in the Python docstring circuit [LW · GW]).
Patching Clean to Corrupted vs Corrupted to Clean
One surprisingly subtle detail is whether you patch a clean activation into the corrupted run, or vice versa. At first glance these seem pretty similar, but I think they're conceptually very different. In the case of IOI, there's a symmetry between clean and corrupted (we could switch which one is clean vs corrupted and it would work about as well), because both are using the IOI circuit but on different names. So it's easier to think about it as the corrupted as the ABC prompt "John and Mary ... Charlie" rather than ABA "John and Mary ... John" - now the corrupted run doesn't need IOI at all!
Terminology can get pretty gnarly here. My current preferred terminology is as follows (I wrote this post before deciding on this terminology, so sorry if it's a bit inconsistent! In particular, I often say activation patching when I should maybe say causal tracing):
- Activation patching covers both directions, and is the process of taking activations from one run and patching them into another run.
- Attribution patching can also go both ways - I focus on clean -> corrupted in this post, but it works exactly the same the other way round.
- Causal tracing is clean -> corrupted. Conceptually this is about finding the activations that are sufficient to recover clean performance in the context of the circuits/features we care about
- If we can patch a head from "The Eiffel Tower is in" to "The Colosseum is in" and flip the answer from Rome to Paris, that seems like strong evidence that that head contained the key information about the input being the Eiffel Tower!
- This finds sufficient activations. If many heads redundantly encode something that quickly saturates, then you can get good logit diff from patching in any of them, even if none of them are necessary
- In the circuit A AND B this tells us nothing, but in A OR B it tells us that both A or B is totally sufficient on its own
- A key gotcha to track is how much this is breaking performance in the corrupted case vs causing the clean performance. In the case of IOI, with symmetric corrupted as name order ABAB and clean as ABBA, the logit difference goes from -x to x. So you can get 50% logit diff back by just zero ablating the logits - it's uniform on everything, so the logit diff is zero!
- While if you find eg a significant increase in the Paris logit for factual knowledge, since Paris is just one out of many possible cities, this is great evidence that the head is doing something useful!
- Though log prob on its own can be misleading, since softmax inhibits smaller logits. If previously the Rome logit was 100 and everything else was 0, then taking Rome from 100 to 0 will significantly increase all other logits. Something like Paris - Berlin logit diff might be most principled here.
- While if you find eg a significant increase in the Paris logit for factual knowledge, since Paris is just one out of many possible cities, this is great evidence that the head is doing something useful!
- Resample ablation is corrupted -> clean. Conceptually this is finding the activations that are necessary to have good clean performance in the context of the circuits/features we care about
- If the model has redundancy, we may see that nothing is necessary! Even if in aggregate they're very important.
- In the circuit A OR B, resample ablating does nothing. But in A AND B it tells us that each of A or B being removed will totally kill performance.
- Note that this naturally extends to thinking of corrupted activations as not necessarily being on a specific prompt - replacing with zeros is ablation, means is mean ablation, you can add in Gaussian noise, etc.
- Here, in some sense, the point is to break performance. But it's worth tracking whether you've broken performance because you've cleverly isolated the circuit you care about, or for boring reasons like throwing the model off distribution.
- If you zero ablate the input tokens you'll destroy performance, but I'm not sure you've learned much :)
- If the model has redundancy, we may see that nothing is necessary! Even if in aggregate they're very important.
In all of the above I was describing patching in a single activation, but the same terminology totally works for patching in many (and this is often what you need to do to get traction on dealing with redundancy)
What Do I Mean By "Circuit"?
By circuit, I mean some fuzzy notion of "an arrangement of parameters that takes some features in and compute some new features". Input features can be input tokens or any earlier computed feature (eg output by some neuron activation), and output features can be attention patterns, output logits, or anything that's just written to the residual stream.
This is actually a pretty thorny concept and I don't have great definitions here, so I will instead gesture at the thorns. There's not a clean distinction between a big end-to-end circuit from the input tokens to the output logits (like IOI) and the many small circuits that compose to make it up (like the one that detects which name is duplicated). Most work so far has focused on end-to-end circuits because the input tokens and output logits are obviously interpretable, but I expect that in large models it's more practical to think of most circuits as starting from some earlier feature, and ending at some later feature, with each feature/circuit used in many end-to-end circuits. There's also not a clear distinction between a single big circuit vs many circuits happening in parallel. Eg "full stops are followed by capital letters" could be implemented with a separate neuron to boost all tokens with " A...", another for Bs, etc - is this one circuit or 26?
How does redundancy & superposition change the picture?
This picture is made significantly messier by the existence of redundancy and by superposition.
Superposition is when a feature is represented as a linear combination of neurons, and implicitly, each neuron represents multiple other features as part of different linear combinations (notably, this means that you can compress in more features than you have neurons!). But, importantly, each feature is rare - on any given input, probably none of a neuron's constituent features are present! (If there were more than 1 feature present, there's costly interference, so superposition likely tries to avoid this). This means that on the patching distribution, probably none of the competing features are present, and so, conditional on those features not being present, each of the neurons in linear combination should be sufficient on its own to somewhat recover performance. This means we'll likely see lots of redundant components doing similar things, but at the cost of forming a somewhat brittle understanding that only partially captures what a neuron truly does - it can do very different things in other settings! And in practice, we often observe many, seemingly redundant heads doing the same thing in circuits, such as the many heads in each class for the IOI circuit (though it's unclear how superposition works in heads, or whether it occurs - potentially each head represents many features, but no feature is represented as a linear combination of heads). Though it's hard to distinguish superposition from there being multiple similar but distinct features!
By redundancy, I can mean two things. There's parallel redundancy where eg multiple heads or neurons are representing the same thing simultaneously (they can be in different layers, but importantly are not composing - ablating one should not affect the output of the others) and serial redundancy where head 2 will compensate for head 1 in an earlier layer being damaged - ie, head 2 does nothing relevant by default, but if head 1 is ablated or otherwise not doing its job, then head 2 will change its behaviour and take over.
Parallel redundancy is totally fine under patching, and pretty easy to reason about, but serial redundancy is much more of a mess. If you resample ablate head 1, then head 2 may just take over and you'll see no effect! (Unless you got lucky and your patch preserved the "I am not damaged" signal). Ditto, copying in something that just damages head 1 may trigger head 2 to take over, and maybe head 2 will then do the right thing! The backup and negative name movers in IOI exhibit both kinds of redundancy, but I think the serial redundancy is much more interesting - if you zero ablate head L9H9 then a negative name mover and backup name mover in subsequent layers will significantly increase their direct logit attribution!
Redunancy makes it significantly harder to interpret the results of patching and I don't really know what to do about it - it's hard to attribute the effect of things when one variable is also a function of another! I consider causal scrubbing to be a decent attempt at this - one of the key ideas is to find the right set of components to resample ablate to fully destroy performance.
But does redundancy occur at all? In models trained with dropout (of which I believe GPT-2 is the main public example, though this is poorly documented) it's clear that models will learn serial redundancy - if component 1 is dropped out, then component 2 takes over. In particular, attention dropout is sometimes used, which sets each attention pattern weight (post softmax) to 0 with 10% probability - if there's a crucial source -> dest connection, storing it in a single head is crazy! This also incentivises parallel redundancy - better to diversify and spread out the parts that can be dropped out rather than having a single big bet.
Modern LLMs tend not to be trained with dropout, so does this still matter? This hasn't been studied very well, but anecdotally redundancy still exists, though to a lesser degree. It's pretty mysterious as to why, but my wild guess is that it comes from superposition - if a neuron can represent both feature A and feature B, then if both feature A and feature B are present, the model's ability to compute either feature will be disrupted. This may be expensive, and worth learning some backup circuits to deal with! (Either serial or parallel redundancy may be used here) In fact, parallel redundancy can be thought of as just superposition - if neuron A and neuron B represent feature X, then we can think of the linear combination of both neurons as the "effective" neuron representin X.
What Can('t) Activation Patching Teach Us?
Thanks to Chris Olah for discussion that helped significantly clarify this section
The beauty of activation patching is that it sets up and analyses careful counterfactuals between prompts, and allows you to isolate the differences. This can let you isolate out a specific part of model behaviour, conditional on various others, and importantly, without needing to have understood those other behaviours mechanistically! Eg, understanding how the model identifies the name of the indirect object, given that it knows it's doing IOI, but not how it knows that it's doing IOI. But this is a double-edged sword - it's important to track exactly what activation patching (and thus attribution patching!) can and cannot teach us.
The broader meta point is that there's two axes along which techniques and circuits work can vary:
- Specific vs general - how much the work is explaining a component or circuit on a specific distribution (eg the distribution of sentences that exhibit IOI or repeated random tokens) vs explaining it in full generality, such that you could confidently predict off distribution behaviour.
- Complete vs incomplete - whether the work has fully characterised how the model component does its task, vs whether it has significant flaws and missing pieces.
Being too specific or being incomplete are two conceptually distinct ways that work can be limited. The induction heads work has been suggested to have been missing important details [LW · GW], and criticised accordingly, but this is a critique of incompleteness. It's not that the heads aren't doing induction in the sense of "detecting and continuing repeated text", but that in addition to just the strict mechanism of A B ... A -> B, the heads did fuzzier things like checking for matches of the previous several tokens rather than just the current one.
Meanwhile, the work on the IOI circuit was too specific in the sense that the identified heads could easily be polysemantic and doing some completely different behaviour on a different distribution of text.
Specific vs general work
I think that the notion of specific vs general work is an important one to keep in mind, and worth digging into. In my opinion, basically all transformer circuits work has skewed to the specific, while the curve circuits work in image models comes closest to being general. Patching-style techniques (activation patching, attribution patching, causal scrubbing, path patching, etc) fundamentally require choosing a clean and corrupted distribution, ideally fairly similar distributions, and thus skew towards the specific (though can be a good first step in a general investigation!). For example, the IOI work never looked at the circuit's behaviour beyond the simple, syntactic, IOI-style prompts.
The induction heads work feels closest to being general, eg by making predictions about head behaviour on repeated random tokens, and looking at the effect on in-context learning across the entire training data distribution.
In some ways, patching-style specific techniques are much easier than aiming for general understanding, and my sense is that much of the field is aiming for specific goals at the moment. It's not obvious to me whether this is a good or bad thing (and I've heard strong opinions in both directions from researchers), but it's worth being aware that this is a trade-off. I think that specific work is still valuable, and it's not clear to me that we need to get good at general work - being really good at patching-style work could look like creating great debuggers for models, disentangling how the model does certain tasks, debugging failures, and isolating specific features we care about (ambitiously, things like goals, situational awareness or deception!). But general work is also valuable, and has been comparatively neglected by the field, and may be crucial for predicting network behaviour off distribution (eg finding adversarial examples, or ambitiously, finding treacherous turns!), for deeply understanding a network and its underlying principles in general, auditing models and getting closer to finding guarantees about systems, eg that this will never intentionally manipulate a user.
Much of the promise of mech interp is in really understanding systems, and a core hypothesis is that we can decompose a system into components with a single, coherent meaning. In particular, we'd like to be able to predict how they will generalise off distribution, and an incomplete but general understanding may be far more useful here than a complete but specific understanding! Specific or incomplete work can still be valuable and insightful, but this weakness important to track.
Further, an extremely nice outcome of mechanistic analysis would be if we could somehow catalogue or characterise what different model components do, and then when observing these components arising in new circuits, use our existing understanding to see what it means for things to compose. This is a hard and ambitious goal and likely only properly achievable if we can deal with superposition, but aiming for this skews hard towards aiming for general analysis over specific analysis.
I think that patching-based techniques are great to build a better understanding of a circuit, and especially to heavily narrow down the search space of possible hypotheses, but it's important to keep in mind that they're fairly specific. Variants like causal scrubbing are powerful approaches to study completeness, but are still tied to a distribution. This is a spectrum, of course, and the broader and more general the distribution is, the more compelling I find the results - if we can causally scrub some hypothesis and fully recover loss on the entire data distribution (or on an even more diverse distribution), I feel pretty compelled by that!
What Would It Look Like to Aim for General Understanding?
I think it's worth dwelling on what aiming for general understanding might look like. Here's an attempted breakdown of what I see as the main approaches here. This all comes with the caveat that "general understanding" is a fairly messy and thorny question and seems very hard to achieve perfectly and with high confidence (if it's even possible). My thoughts here focus more on what evidence directionally points towards a more vs less general understanding, more so than showing a truly universal understanding of a model component:
- Mechanistic analysis: Actually analysing the weights of the model, and recovering the hypothesised algorithm.
- Eg Looking at the weights of the two composing attention heads to see that they form an induction circuit that can do strict induction in general.
- It's worth noting that this is weaker evidence than it can seem at first glance. Models are complex and messy objects, and mechanistic analysis tends to involve steps like "ignore this term because it doesn't seem important".
- Refinements like "replace the model's weights/component with our mechanistic understanding" and analysing loss/accuracy recovered on the full data distribution are stronger. Eg hand-coding the neurons in curve circuits, or ablating irrelevant weights and activations in my modular addition work.
- Though even this can be misleading! Eg if the model has some learned redundancy, even fully ablating a component may not reduce loss that much.
- Analysing behaviour on the full data distribution: The obvious way to deal with the criticism that you're focusing on a narrow distribution is to look at a component over the full data distribution, and see if your understanding fully explains its behaviour. This is hard to do right (the data distribution for a language model is very big!) but can be very compelling.
- One angle is spectrum plots, a technique for understanding neurons. Eg if we think a neuron only fires for number tokens, we can run the model on a bunch of text, and plot a histogram of neuron activations on number and non-number tokens - if the neuron truly only fires on numbers, then this should be very obvious (though there's likely to be a bunch of noise, so if the two categories overlap a bit this may be fine).
- Spectrum plots require automated tools to do on a large sample size, but a more tractable version is just to study a model component on random dataset examples, and see how well our understanding predicts behaviour.
- Anecdotally, when induction heads are studied on random dataset examples they tend to "look induction-y" and be mainly involved in repeated text tasks
- This motivates a natural refinement of looking at neuron max activating dataset examples - looking at a few random samples from different quantiles along the full distribution of activations, eg a few around the 95th percentile, 90th percentile, 75th percentile and 50th percentile. If these match your overall understanding, that's much more compelling!
- Generalising to other distributions: If you understand a model on a narrow distribution and then widen this distribution, does your understanding still hold? If yes, this is evidence that your understanding is general - and the broader your new distribution is, the better (if it's the full training distribution, that's great!).
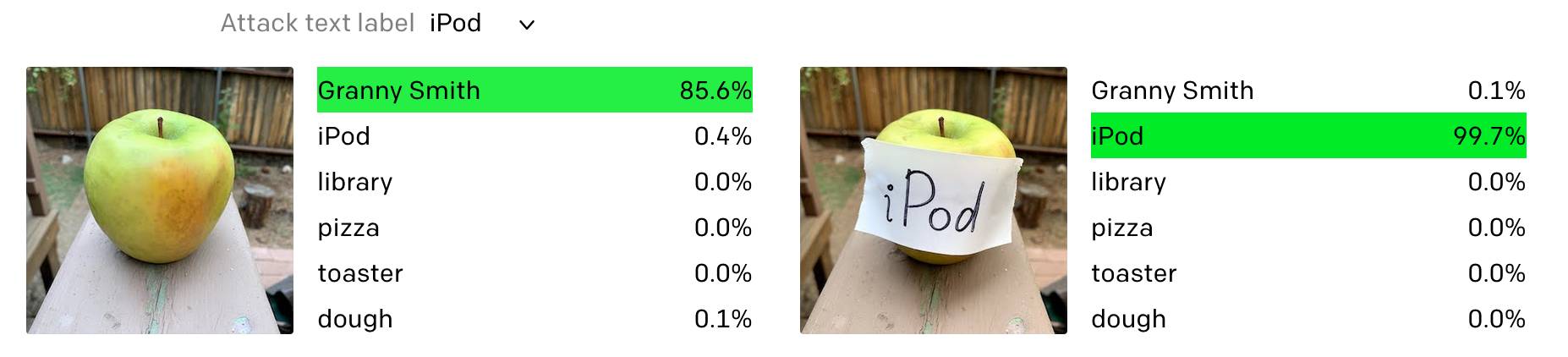
- Using your mechanistic understanding to come up with adversarial examples, as with typographic attacks on CLIP and in interpretability in the wild.
- More ad-hoc approaches, eg induction heads working on repeated random tokens.
- Using your mechanistic understanding to come up with adversarial examples, as with typographic attacks on CLIP and in interpretability in the wild.
- Independent-ish techniques: A meta point is that if you have multiple techniques that intuitively seem "independent" in the sense that they could easily have disagreed, this makes the evidence of generality become more compelling, even if each piece of evidence on its own is questionable.
- Eg max activating dataset examples on their own can be highly misleading. But if they also match what was found independently when patching a neuron, that feels much more compelling to me.
- Ditto, if the max activating dataset examples for a late layer neuron explain the direct logit attribution of the neuron (eg a neuron always activates on full stops and boosts tokens beginning with a space and capital letter).
- Note that I use "independent" in an informal sense of "genuinely provides new Bayesian evidence, conditioning on all previous evidence", rather than "conditioning on previous evidence tells you literally nothing"
- But these are just examples, there's likely a wide range of more ad-hoc approaches that are pretty specific to the question being asked.
- Eg the fact induction heads form as a phase change and this seems deeply tied to a model's capacity for in-context learning. The fact that they're such a big deal as to cause a bump in the loss curve, and that this seems tied to in-context learning, is pretty strong evidence that "being induction-y" is core to their overall function in the model.
Caveats:
- Generality lies on a spectrum - components can be more or less general, and the above are mostly techniques for showing an understanding is more general. To show that a model component literally only does a single thing seems extremely hard.
- I think this is still an interesting question! In my opinion there's a meaningful difference between "this head is sometimes inductiony" and "on 99% of random dataset examples where this head matters, it's induction-y"
- In particular, it's plausible that models use superposition to represent sparse and anti-correlated features - if the component does something else on 0.01% of inputs, this can be pretty hard to notice! Even with approaches like "replace the component with hand-coded weights and look at loss recovered", you just won't notice rare features.
- I think generality is best thought of as an end goal not as a filter on experiment ideas - you shouldn't discard an experiment idea because it looks at a narrow distribution. Narrow distributions and patching are way more tractable, and can be a great way to get a first understanding of a model component.
- But you need to then check how general this understanding is! For example, I think that a great concrete open problem would be checking how well the indirect object identification circuit explains the behaviour of the relevant heads in GPT-2 Small on arbitrary text.
- I've deliberately been using "component" rather than "head" or "neuron" - I think it's hard to talk clearly about generality without having better frameworks to think about and deal with superposition. Plausibly, a truly general understanding looks more like "this linear combination of neurons purely represents this feature, modulo removing any interference from superposition"
- It's also plausible that there's no such thing as a truly general understanding, that superposition is rife, and the best we can get is "this neuron represents feature A 25% of the time, and feature B 75% of the time"
- Note that with many of the more circumstantial approaches above need to be done in a scientifically rigorous and falsifiable way to be real evidence.
- If you discover induction heads by just studying a model on natural language, predict that they'll generalise to repeated random tokens (and that models can predict those at all!) then this is strong evidence - the experiment could easily have come out the other way! But if you identified induction heads by studying the model on both repeated random tokens and repeated natural language, the evidence is much weaker.
As an interesting concrete case study, a study of a docstring circuit in a four layer attention-only model [LW · GW] found that head L1H4 acted as an induction head in one part of the circuit and a previous token head in another part, and further investigation suggests that it's genuinely polysemantic. On a more narrow distribution this head could easily exhibit just one behaviour and eg seem like a monosemantic inductin head. Yet on the alternate (and uncorrelated) test of detecting repeated random tokens it actually does very badly, which disproves that hypothesis.
Does This Make Any Sense?
This section is more heavily linked to the post on attribution patching, but I think it's still standalone interesting. The TLDR on attribution patching is that it's a gradient based approximation to activation patching that assumes that the function is locally linear, and I discuss how reasonable that assumption seems.
So, does any of this make any sense? "Assume everything is linear" is an extremely convenient assumption, but is this remotely principled? Is there any reason we should expect this to help us form true beliefs about networks?
My overall take is, maybe! Empirically, it holds up surprisingly well, especially for "smaller" changes, see the experiments section section below. Theoretically, it's a fair bit more principled than it seemed to me at first glance, but can definitely break in some situations. Here I'll try to discuss the underlying intuitions behind where the technique should and should not work and what we can take from it. I see there as being two big questions around whether attribution patching should work, whether the relevant circuit component has linear vs non-linear structure and whether it has single feature or multi-feature dependence.
My headline take is that attribution patching does reasonably well. It works best when patching things near the end of the model, and when making "small" patches, where patch represents a small fraction of the residual stream, and badly for big patches (eg an entire residual stream). It works best on circuits without too many layers of composition, or which focus on routing information via attention heads, and will work less well on circuits involving many layers of composition between very non-linear functions, especially functions with a few key bottleneck activations that behave importantly non-linearly (eg a key attention pattern weight that starts near zero and ends up near one post patch). And it works best when the clean and corrupted prompts are set up to differ by one key feature, rather than many that all compose.
Single vs Multi Features Dependence
The intuition here is that we can think about the model's activations as representing features (ie, variables), and components calculating functions of these features. For example, Name Mover Heads in the IOI circuit have the Q input of which names are duplicated and K input of what names exist in the context, and calculate an attention pattern looking at each non-duplicated name. We can think of this as a Boolean AND between the "John is duplicated" Q feature and the "John is at position 4" and "Mary is at position 2" K features.
The key thing to flag is that this is a function of two features, and will not work if only one of those features is present. I call this kind of thing multi-feature dependence. Linear approximations, fundamentally, are about assuming that everything else is held fixed, and varying a single activation, and so cannot pick up on real multi-feature dependence. Note that multi-feature dependence is not the same as there being multiple features which all matter, but which act in parallel. For example, the IOI circuit has a component tracking the position of the duplicated name, and a component tracking the value (ie which name) - these are multiple features that matter, but mostly don't depend on each other and either on its own is highly effective, so attribution patching can pick up on this. Another way of phrasing this is that attribution patching can pick up on the effect of each feature on its own, but will neglect any interaction terms, and so will break when the interaction terms are a significant part of what's going on.
When we take a clean vs corrupted prompt, we vary the key features we care about, but ideally keep as many "contextual" features the same as possible. In our example from earlier, activation patching the residual stream at the final token only patches the "John is duplicated" feature and so only patches in the Q feature, not the K feature. But the K feature is held fixed, so this is enough to recover performance! Meanwhile, if we patched into a prompt with different names, or arbitrary text, or whatever, the activation patching would break because the "contextual" K feature of where John and Mary are would break. However, if we patched in the relevant features at Q and at K, we're good (eg patching in thxe direct path from the pos 2 and pos 4 embedding, and the output of the S inhibition heads on the final token).
So we can think of the name mover's attention pattern as a multi feature function in general, but in the specific context of the clean vs corrupted prompt we setup it's locally a single feature function. Attribution patching fundamentally assumes linearity, and so will totally break on multi-feature dependence, but so will activation patching, unless we patch in all relevant features at once. This can happen, especially when doing fancier kinds of activation patching, but I generally think activation patching is the wrong tool to notice this kind of thing, and it's normally a sign that you need to choose your clean and corrupted prompts better. Though generally this is just the kind of question you'll need to reason through - prompts can differ in a single feature, which is used to compute multiple subsequent features, each of which matter.
Activation patching is more likely to capture multi-feature dependence when we patch in a "large" activation, eg the entire residual stream at a position, which we expect will contain many features. And, in fact, residual stream attribution patching does pretty badly!
Further, patching something downstream of a multi-feature function (eg its output) should work (as well as single-feature) for either activation or attribution patching. Eg, if doing factual recall on Bill Gates, patching in the tokens/token level functions of either " Bill" or " Gates" in isolation will do pretty badly. But if we patch in something containing the "is Bill Gates" feature (eg, the output of a "Bill Gates" neuron, or an early-mid residual stream on the right token) we're fine.
Linear vs Non-Linear (Local) Structure
The second way that a linear approximation can break is if, well, the function represented by the model is not linear! Transformers are shockingly linear objects, but there are five main sources of non-linearities - the attention pattern softmax, MLP neuron activations, the multiplication of value vectors at source positions by the attention pattern, LayerNorm normalisation, and the final softmax. Generally, each of these will be locally linear, but it's plausible that activation patching might be a big enough change to that function that linearity loses a lot of information.
This is a high-level question that I want to get more empirical data on, but my current intuition is that it will depend heavily on how much the patch being approximated moves non-linearities from a saturated to an unsaturated region. By saturated, I mean a region where the derivative is near zero, eg the log prob of a token the model is really confident comes next, an attention pattern weight that's close to zero or one, or well into the negative tail of a GELU. If there's an important activation that goes from a saturated to unsaturated region, a linear approximation says nothing happens, while activation patching says a lot changes.
One useful observation to help reason about this is that an attention softmax becomes a sigmoid if you hold all other variables fixed, and that the final log softmax is linear for large negative logits, and slowly plateaus and asymptotes to for large positive logits. (And if we're assuming single variable dependence, then "holding everything else fixed" can be a reasonable assumption).
This is generally an area where I struggle to be precise - in some contexts this linear approximation will totally break, in others it will be fine. If most non-linearities are not in a saturated region, a linear approximation may be reasonable, and if they become saturated post-patch, we'll just overestimate their importance which seems fine (false positives are much better than false negatives!).
5 comments
Comments sorted by top scores.
comment by luciaquirke · 2023-06-05T06:48:01.210Z · LW(p) · GW(p)
If we can patch a head from "The Eiffel Tower is in" to "The Colosseum is in" and flip the answer from Rome to Paris, that seems like strong evidence that that head contained the key information about the input being the Eiffel Tower!
[nit] I believe this part should read "Paris to Rome".
comment by 1stuserhere (firstuser-here) · 2023-06-05T21:30:07.826Z · LW(p) · GW(p)
On a more narrow distribution this head could easily exhibit just one behaviour and eg seem like a monosemantic inductin head
induction* head
comment by ryan_greenblatt · 2023-06-05T03:36:12.889Z · LW(p) · GW(p)
Does This Make Any Sense?
I'm confused - it looks like the first paragraph of this section is taken from a prior post on attribution patching.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2023-06-05T19:57:37.681Z · LW(p) · GW(p)
Ah, thanks! As I noted at the top, this was an excerpt from that post, which I thought was interesting as a stand alone, but I didn't realise how much of that section did depend on attribution patching knowledge
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-06-05T22:38:11.837Z · LW(p) · GW(p)
Oops, somehow I missed that context.
Thanks for the clarification.