Deception as the optimal: mesa-optimizers and inner alignment
post by Eleni Angelou (ea-1) · 2022-08-16T04:49:50.957Z · LW · GW · 0 commentsContents
The setup of the problem Deception is the optimal strategy for the model to achieve its goal under the following conditions: Why is deceptive alignment so worrisome? So, we have a deceptively aligned mesa-optimizer. What happens now? None No comments
This is a brief distillation of Risks from Learned Optimization in Advanced Machine Learning Systems (Hubinger et al. 2019) with a focus on deceptive alignment. Watching The OTHER AI Alignment Problem: Mesa-Optimizers and Inner Alignment helped me better understand the paper and write up this post.
The setup of the problem
What is it that makes the alignment problem so challenging? The top reason is that it involves deception. Deception makes artificial agents overly capable and takes the game of intelligence to a whole new level of complexity. But let's start from the beginning.
In many cases, by alignment problem, we mean "outer alignment", i.e., how to have the base objective (the objective of the designer represented in the model) represent whatever humans want it to represent. It is about bridging the gap between my objective as a designer, and the base objective of the system. The system is the base optimizer, in other words, the model that optimizes according to the base objective. This is itself difficult since the base objective refers to events happening in a complex environment, the real world.
The base objective might be something like eradicating a disease. For example, suppose the task is to minimize the number of people who have cancer. How do you get this objective to not be represented along the following lines?
1. Cancer is something that happens to humans and other sentient beings.
2. The objective is to minimize the number of occurrences of cancer.
∴ Minimize the number of humans and other sentient beings that could get cancer.
Goals are difficult to represent because even humans disagree on what the same propositions mean and what is the best way to resolve a problem. Moreover, human values have high Kolmogorov complexity [? · GW]. Our preferences cannot be described using a few simple rules, our interpretations of values and goals vary, and the current state of metaethical discourse does not promise substantial agreement or clarification on what has, for instance, intrinsic value. So, outer misalignment broadly captures this failure to transmit one or more human values to an artificial agent.
As if this weren't problematic enough, there is also an alignment problem that concerns the internal structure of the system and it's called "inner alignment". This is the focus of this post and will get us to the crucial point about deceptive agents.
Suppose you train a neural network to complete a task. The task, in this case, is to find the exit of a maze (base objective). There are also apples in the maze, but merely for decoration; the objective is simply to get to the exit that happens to be green in this training environment.
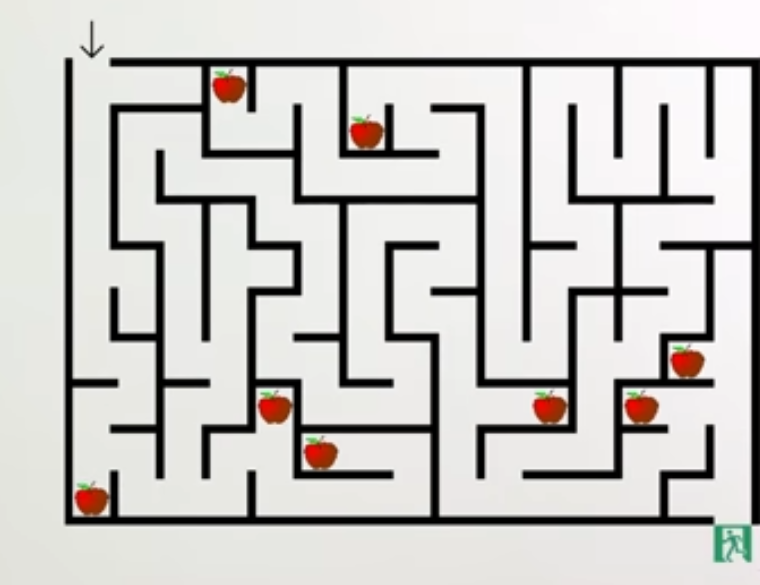
When the training is complete, you deploy the model in a different environment which looks like this:
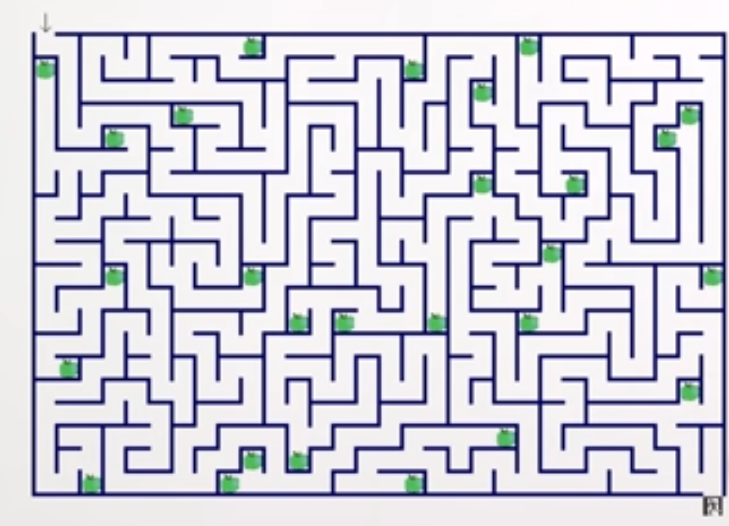
The base objective has not changed: the neural network has to solve the maze by reaching the exit. This change of environment known as distributional shift, however, does not go unnoticed. There are three possible outcomes:
- the system generalizes (it finds the exit; success!)
- the system fails to generalize (bad because it's not working, but there are no other consequences)
- the system has competent maze abilities but with an objective we don't want it to have, the mesa-objective (this is a big problem, basically what inner misalignment is about)
In this scenario, let's suppose that the system acquired a maze-solving ability, but instead of optimizing for "exit" it learned to optimize for "green". The exit in the new environment is grey, therefore, the model will complete the task whenever it reaches a green apple.
The process of training, of course, involves fixing the system's mistakes. This is part of adversarial training which will force the system not to commit the mistake of, in this case, optimizing for "green". Adversarial training is a way of training ML systems that involves focusing on the system's weaknesses; it forces the system to learn not to have such weaknesses, like optimizing fo the wrong objective.
Side note: it might be intuitive to assume that if the system's behavior is not in accordance with human values, we can always do something about this, e.g., turn it off. But there's something even more intuitive and familiar to every agent trying to survive in a challenging environment: for the purpose of self-preservation, the model will do everything it can to prevent you from:
- turning it off
- modifying it
This includes deceiving the designer. Deception is a highly effective method for the system to pursue its mesa-objective while exhibiting outputs that make the designer think that the system is trying to accomplish the base objective.
Perhaps it sounds particularly bad in this context, but if you think about it, deception is a technique most human agents employ to survive in different contexts from the ancestral environment to contemporary professional and social circles. It should then make sense why the system is more likely to pretend it's behaving according to your values so that you don't do anything about it; once it has enough resources not to be threatened by your ability to shut it down or change it, it will go ahead and pursue its goal.
Since the system is intelligent enough to predict that if it doesn't optimize for the base objective, gradient descent will make sure it is modified, it chooses to behave as if it were actually optimizing for the base objective in the training environment. Gradient descent is something like the "evolution algorithm" for artificial agents; it is an optimization technique that evaluates the performance of a model and modifies the model accordingly. Once the model is deployed in the real world (and can no longer be modified) it will optimize for the mesa-objective.
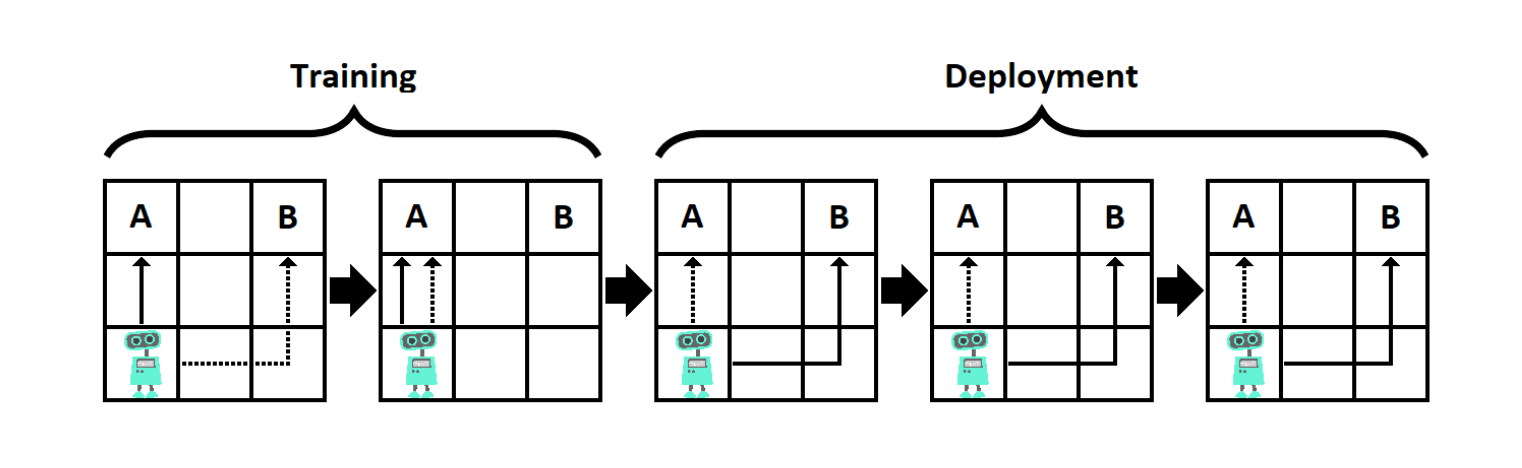
In the example above from (Hubinger et al. 2019), the base-objective is for the little robot to go to A and the mesa-objective is to go to B. In the two training episodes, the robot goes to A making the designer think it's optimizing for the base objective and it's good to be deployed without further modifications. In the three deployment episodes, the little robot optimizes for the mesa-objective. The system has managed to deceive the designer during training and it's perfectly capable of getting what it wants except that what it wants is not the same as what the designer wants.
The conclusion is that while we gave the system the right objective and in that sense outer alignment was successful, the mesa-optimizer (an optimizer optimized by an optimizer) optimized for the mesa-objective leading to inner misalignment.
Deception is the optimal strategy for the model to achieve its goal under the following conditions:
- The mesa-optimizer has incentives to pursue a different objective than the original one. That objective might be somehow encouraged by the training setup depending on the required tasks.
- The mesa-optimizer must know that it is being trained to optimize for a specific base objective and must be able to have a model of that objective (so that it can distinguish between objectives).
- The mesa-optimizer must anticipate that it will eventually be in an environment where modification will no longer be an option (for example, that its training will end).
Why is deceptive alignment so worrisome?
- The phenomenon of optimizing for the mesa-objective instead of the base-objective is called “defection”; it gives the model the power to pursue goals that might be difficult to understand from the perspective of the designer.
- This misalignment might have serious, even catastrophic consequences for the future of humanity.
- Defection occurs when the model is convinced there is no danger of modification. This means that at this point, the outcome is out of control.
- Relying on artificial agents more and more in a highly complex world increases the likelihood of not being able to recover from AI systems' failures as the various systems will most likely be interconnected/depending on one another in multiple ways.
- It is possible that the artificial agent might have such a good model of the designer which can result in directly intervening to free itself from the risk of modification.
- In other cases, the agent might just take advantage of software weaknesses that will also ensure that it cannot be modified any further.
So, we have a deceptively aligned mesa-optimizer. What happens now?
- A deceptive mesa-optimizer acquires new "skills" namely, the ability to infer the base objective function and being able to tell when to optimize for which objective (either the base or the mesa).
- This changes the learning dynamics of the system.
- The mesa-optimizer might:
- try to optimize both for the base and the mesa objective
- defect at the wrong time, when it might still have to make the mesa-objective more compatible with the base objective.
1 and 2 are not stable states; the mesa-optimizer will eventually have to either become properly aligned or find another deception strategy.
- An alternative deception strategy is called "pure deception". In this scenario, the mesa-optimizer cooperates in the short term with the selection process and stops trying to optimize for its mesa-objective. The mesa-objective then becomes locked-in and cannot be changed. At the same time, the mesa-optimizer is optimizing for the base objective only instrumentally. This is an interesting phenomenon; while the base objective becomes more and more part of the mesa-optimizer's epistemic model, its objective is never going to be actually aligned.
0 comments
Comments sorted by top scores.