Evaluating “What 2026 Looks Like” So Far
post by Jonny Spicer (jonnyspicer) · 2025-02-24T18:55:27.373Z · LW · GW · 5 commentsContents
Summary Methodology Results How accurate are Daniel’s predictions so far? Can LLMs extract and resolve predictions? Extraction Resolution Next Steps Appendix Prompts Raw data None 5 comments
Summary
In 2021, @Daniel Kokotajlo [LW · GW] wrote What 2026 Looks Like [LW · GW], in which he sketched a possible version of each year from 2022 - 2026. In his words:
The goal is to write out a detailed future history (“trajectory”) that is as realistic (to [him]) as [he] can currently manage
Given it’s now 2025, I evaluated all of the predictions contained in the years 2022-2024, and subsequently tried to see if o3-mini could automate the process.
In my opinion, the results are impressive (NB these are the human gradings of his predictions):
| Totally correct | Ambiguous or partially correct | Totally incorrect | Total | |
| 2022 | 7 | 1 | 1 | 9 |
| 2023 | 5 | 4 | 1 | 10 |
| 2024 | 7 | 4 | 5 | 16 |
| Total | 19 | 8 | 6 | 35 |
Given the scenarios Daniel gave were intended as simply one way in which things might turn out, rather than offered as concrete predictions, I was surprised that over half were completely correct, and I think he foresees the pace of progress remarkably accurately.
Experimenting with o3-mini showed some initial promise, but the results are substantially worse than human evaluations. I would anticipate being able to produce a very significant improvement by using a multi-step resolution flow with web search, averaging the resolution score across multiple models etc.
Methodology
I went through 2022, 2023 and 2024 and noted anything that could be reasonably stated as a meaningful prediction. Not all of them were purely quantitative, nor did I attempt to necessarily quantify each prediction - for example, the verbatim “The hype is building” in the 2022 section became “In 2022, the hype is building”. Some other interesting examples:
- 2023
- “The multimodal transformers are now even bigger; the biggest are about half a trillion parameters, costing hundreds of millions of dollars to train, and a whole year, and sucking up a significant fraction of the chip output of NVIDIA etc.”
- “The [AI safety] community begins a big project to build an AI system that can automate interpretability work;”
- 2024
- “Corps spend their money fine-tuning and distilling and playing around with their models, rather than training new or bigger ones.”
- “Someone had the bright idea of making the newsfeed recommendation algorithm gently ‘nudge’ people towards spewing less hate speech; now a component of its reward function is minimizing the probability that the user will say something worthy of censorship in the next 48 hours.”
I resolved them using the same framework for “smartness” that Arb used in their report evaluating the predictions of futurists [LW(p) · GW(p)] - namely, correctness (0-2) and difficulty (1-5), with the following scoring:
Correctness:
0 - unambiguously wrong;
1 - ambiguous or near miss;
2 - unambiguously right
Difficulty:
1 - was already generally known
2 - was expert consensus
3 - speculative but on trend
4 - above trend, or oddly detailed
5 - prescient, no trend to go off
I spent roughly an hour resolving the predictions, and mostly went off my intuition, occasionally using a shallow Google search where I was particularly unsure. I updated several of my correctness scores after sharing the initial evaluation with Eli Lifland (who didn’t carefully review all predictions so doesn’t endorse all scores).
Results
How accurate are Daniel’s predictions so far?
I think the predictions are generally very impressive. The decrease in accuracy between years is to be expected, particularly given the author’s aim of providing an account of the future they believe is likely to be directionally correct, rather than producing concrete predictions intended to be evaluated in this way. I think the overall pace of progress outlined is accurate.
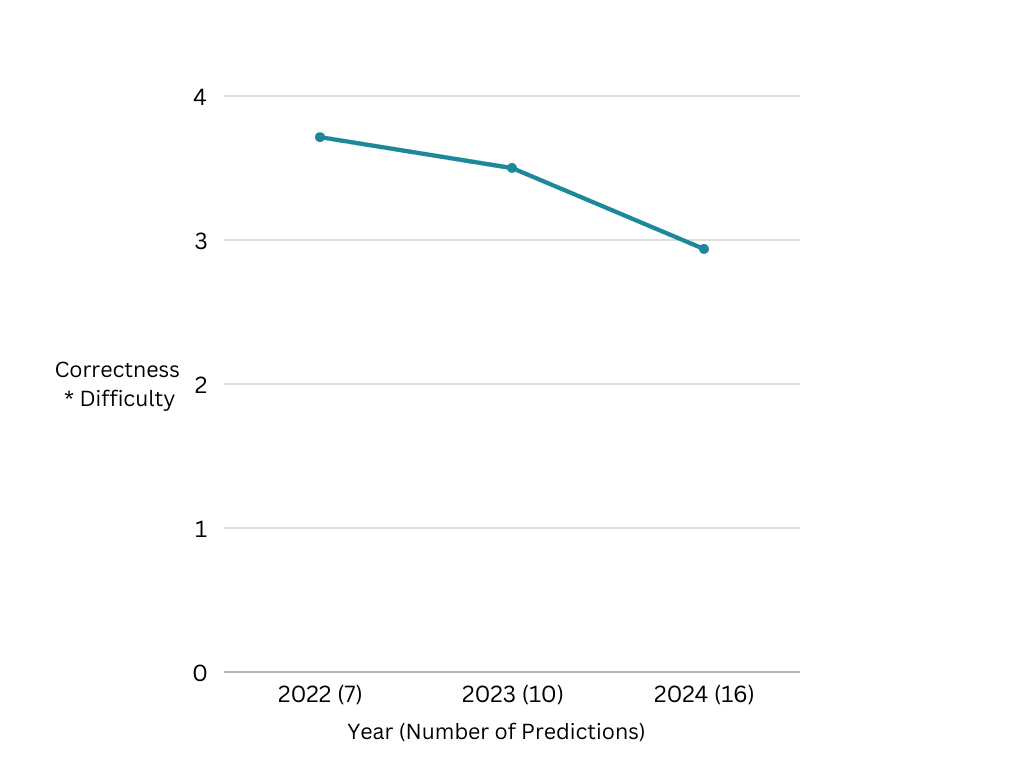
Based on my subjective application of the scoring system above, the most impressive predictions are the following (bear in mind the post was written in 2021, a year before the release of ChatGPT):
- “Revenue is high enough to recoup training costs within a year or so.” (2023)
- “We don’t see anything substantially bigger [than the previous year’s models.” (2024)
- “So, the most compute spent on a single training run is something like 5x10^25 FLOPs.” (2024)
I didn’t think any of the predictions made were especially bad - every prediction that I assigned a ‘0’ for correctness (i.e. unambiguously wrong) had at least a 3 for difficult (i.e. more speculative than expert consensus on the scoring framework). With that being said, the ones that seemed most off to me were:
- “But the hype begins to fade as the unrealistic expectations from 2022-2023 fail to materialize. We have chatbots that are fun to talk to, at least for a certain userbase, but that userbase is mostly captured already and so the growth rate has slowed.” (2024)
- “The chip shortage starts to finally let up, not because demand has slackened but because the industry has had time to build new fabs. Lots of new fabs.” (2024)
- According to Wikipedia, 7 new semiconductor fabs came online between 2022 and 2024, of which only 3 seem capable of producing AI-relevant chips, and none of which are capable of producing the most advanced chips.
I found the average correctness score (0-2) to be 1.43, and the average smartness score (correctness * difficulty on a 1-5 scale) to be 3.37. For some reference, in the Arb report, Isaac Asimov’s average correctness score was 0.82 and his average smartness was 2.50, however this is a somewhat unfair comparison due to the vastly different timeframes involved (Asimov’s predictions were an average of 36 years away from the date he made them). If further predictors were evaluated using the same scoring rubric, a more direct comparison between them would be possible.
Skimming the predictions, I have the sense that the ones about specific technical claims are generally more accurate than the ones about broader societal impacts.
Similarly, the predictions are (to my eye) under-optimistic on capabilities.
Can LLMs extract and resolve predictions?
I used o3-mini-2025-01-31 with `reasoning_effort = high` for all model calls. Given the model’s knowledge cutoff is October 2023, I only evaluated it on the 2022 and 2023 predictions.
The input text was split into chunks containing <= 1000 tokens, ensuring paragraphs are maintained. The prediction extraction part of the script does two passes - an initial one where it’s asked to extract all the predictions and a second one where it’s given the existing predictions alongside the input text and asked to produce more. I tried various strategies and this was the one that extracted the closest amount of predictions to the manual evaluation.
Extraction
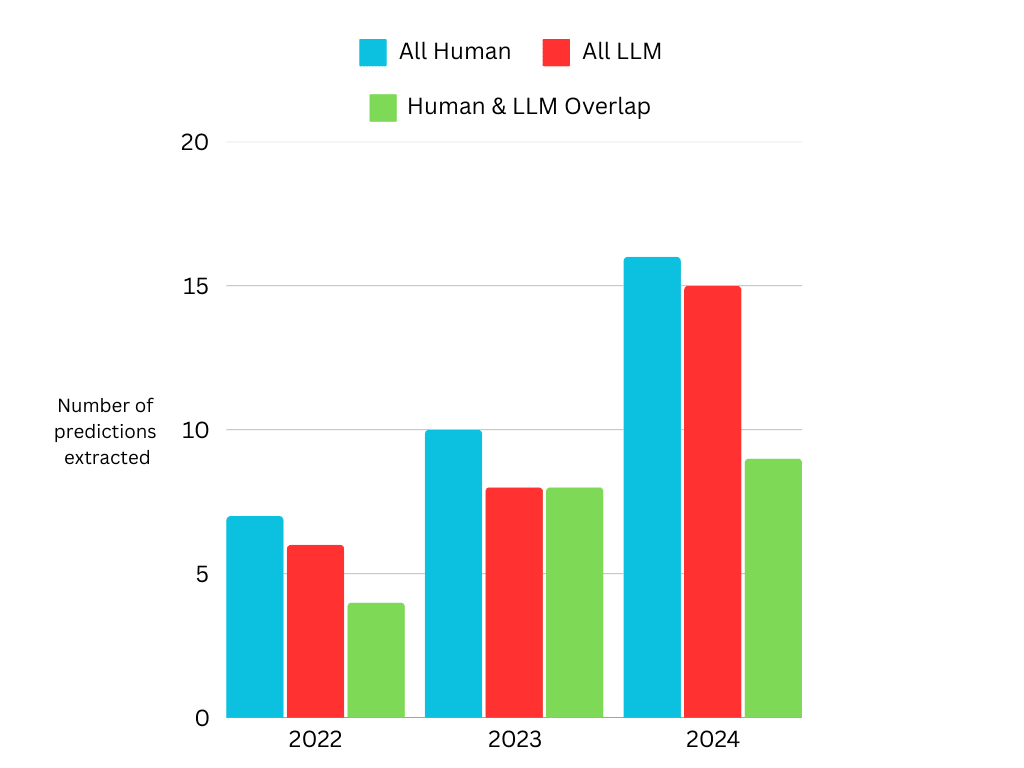
LLMs seem promising at extracting predictions from text, when compared to a human baseline. I recorded 33 predictions total, the model recorded 29 of which I judged 23 to be valid. There were two predictions I missed that the model found:
- “And some of these models are being trained not to maximize “conversion rate” in the sense of “they clicked on our ad and bought a product,” but in the sense of “Random polling establishes that consuming this content pushes people towards opinion X, on average.” Political campaigns do this a lot in the lead-up to Harris’ election. (Historically, the first major use case was reducing vaccine hesitancy in 2022.)”
- The prediction therein being: “By 2022, one of the first major public implementations of AI-driven persuasion will occur in campaigns aimed at reducing vaccine hesitancy.”
- I missed this one as it was an implicit prediction about 2022, but was in the 2024 section.
- “[EDIT: The day after posting this, it has come to my attention that in China in 2021 the market for chatbots is $420M/year, and there are 10M active users. This article claims the global market is around $2B/year in 2021 and is projected to grow around 30%/year. I predict it will grow faster. NEW EDIT: See also xiaoice.]”
- The prediction therein being: “By 2022, the global chatbot market (already around $2B/year in 2021 and projected to grow at 30% per year) will actually experience a growth rate that exceeds the original 30% annual projection.”
- I misread the aside and didn’t pick up on the prediction it contained, despite it explicitly containing the word “predict” 🤦
The model does make some unfortunate errors though, with several failure modes including:
- Merging multiple predictions into one
- E.g. LLM’s prediction: “By 2023, the largest multimodal transformer models will have 500 billion parameters and require one year of training costing hundreds of millions of dollars.”
- Verbatim text: “The multimodal transformers are now even bigger; the biggest are about half a trillion parameters, costing hundreds of millions of dollars to train, and a whole year, and sucking up a significant fraction of the chip output of NVIDIA etc.” (2023)
- Hallucinating resolution years
- E.g. LLM’s prediction “By 2030, the Chinese government will leverage AI-enabled propaganda to accelerate its timeline for annexing Taiwan, reflecting a significant shift in strategic objectives.”
- Verbatim text: “In China and various other parts of the world, AI-persuasion/propaganda tech is being pursued and deployed with more gusto. The CCP is pleased with the progress made assimilating Xinjiang and Hong Kong, and internally shifts forward their timelines for when Taiwan will be safely annexable.” (2024)
- Missing predictions altogether, e.g. not extracting anything from any of the following sections:
- “Some of the bureaucracies create a “stream of consciousness” of text (each forward pass producing notes-to-self for the next one) but even with fine-tuning this doesn’t work nearly as well as hoped; it’s easy for the AIs to get “distracted” and for their stream of consciousness to wander into some silly direction and ultimately produce gibberish.” (2024)
- “It’s easy to make a bureaucracy and fine-tune it and get it to do some pretty impressive stuff, but for most tasks it’s not yet possible to get it to do OK all the time.” (2024)
- “The AIs don't do any clever deceptions of humans, so there aren’t any obvious alignment warning shots or fire alarms.” (2024)
NB: in the figure below, there is a significant difference between the additional “LLM only” predictions in 2022 and 2024. In 2022, the two additional predictions were ones that I judged to be valid and missed in my evaluation. In 2024, the additional predictions the LLM made are not clearly distinct or valid in the same way.
Resolution
Resolution was mediocre with the crude techniques I used, but also showed some promise. The model’s resolutions in this instance were handicapped by not having access to web search, which I did use to help resolve a handful of the predictions. The average correctness score delta was 0.75, which is huge given the score is bounded 0-2. The average difficulty score delta was 0.83, still somewhat large given the score is bounded 1-5.
I found the rationales provided by the models explaining their score generally compelling. Where we disagreed, it was often the case that it seemed they were lacking some piece of information that might’ve been retrievable with web search.
The one exception was when the model quite happily resolved a prediction from 2030. While it would be trivial to implement a basic check to prevent this, it was still interesting to me that the model would happily hallucinate a plausible-sounding answer.
Next Steps
I am seeking feedback on this work, particularly with regards to whether I should invest further time into it. The current system for resolving predictions is far too crude; I have started working on an agent-based workflow that can use web search in order to get closer to human resolution. I am cautiously optimistic that I could reduce the correctness score delta to ~0.2 with such a system, which I think would be much more acceptable. I haven’t tested prediction extraction on texts with predictions less explicit than the ones above, and would anticipate needing to spend some time refining that aspect of the system to handle such texts too.
The questions I am trying to answer are:
- Would having a system that could extract predictions from text (e.g. LessWrong posts, newspaper articles, podcast transcripts) be interesting/valuable?
- If yes, would you prefer a series of reports (like this one, but more in-depth), or a leaderboard/database of evaluations?
- What kind of scoring framework could be applied in order to meaningfully assess an evaluatee’s level of insight and prescience, given their statements will extremely rarely be explicit predictions?
- Contingent on the above, what would need to be demonstrated in order for you to trust the outputs of an LLM-based system that was performing the scoring?
Thanks to Eli Lifland, Adam Binksmith and David Mathers for their feedback on drafts of this post.
Appendix
Prompts
Raw data
The evaluation data Google sheet is available here.
5 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-02-24T19:20:36.895Z · LW(p) · GW(p)
Thanks for doing this! I had been hoping someone would do basically exactly this sort of analysis. :)
Replies from: Mo Nastri↑ comment by Mo Putera (Mo Nastri) · 2025-02-26T07:21:49.974Z · LW(p) · GW(p)
I'm curious now, given how accurate your forecasts have turned out and maybe taking into account Jonny's remark that "the predictions are (to my eye) under-optimistic on capabilities", what are the most substantive changes you'd make to your 2025-26 predictions?
comment by Oscar (Oscar Delaney) · 2025-03-12T16:02:43.648Z · LW(p) · GW(p)
Nice!
For the 2024 prediction "So, the most compute spent on a single training run is something like 5x10^25 FLOPs." you cite v3 as having been trained on 3.5e24 FLOP, but that is outside an OOM. Whereas Grok-2 was trained in 2024 with 3e25, so seems to be a better model to cite?
Replies from: jonnyspicer↑ comment by Jonny Spicer (jonnyspicer) · 2025-03-19T15:05:47.859Z · LW(p) · GW(p)
That's a much better source, I've updated the spreadsheet accordingly, thanks!
comment by Lowe Lundin (lowe-lundin) · 2025-04-22T09:02:38.403Z · LW(p) · GW(p)
Totally correct Ambiguous or partially correct Totally incorrect Total 2022 7 1 1 9 2023 5 4 1 10 2024 7 4 5 16 Total 19 8 6 35
There seems to be a summarization problem here where 1+4+4=8 and 1+1+5=6 rather than 9 and 7. So total predictions 2022-2024 should be 37 and not 35.