Investigating Basin Volume with XOR Networks
post by CatGoddess · 2024-03-10T01:35:06.856Z · LW · GW · 0 commentsContents
Motivating Questions Experiments Learning XOR TSNE Clusters and Loss Basins Testing External Behaviour and Internal Functional Structure Trajectory Graphs Do Larger Networks Tend to Contain Minimal XOR Gates? Extending XOR None No comments
Note: I wrote this document over a year ago, and recently I decided to post it with minimal edits. If I were to do research in the same area today, I'd probably have different framings, thoughts on what directions seem promising, etc. Some of the things I say here now seem confused to me.
This work was done while I was a fellow at SERI MATS, under the mentorship of John Wentworth.
Motivating Questions
- How do neural networks represent data/information?
- What does it mean for two networks to “do the same thing” or "implement the same algorithm"?
- How often do network parameters end up in “broad basins [LW · GW]”?
- What does it mean for a neural network to “use” some parameters but not others?
- How do basins in the loss landscape relate to internal functional structures, or “doing the same thing”?
Experiments
Learning XOR
We started by training a small neural network to learn the XOR function, using sigmoid activations and the following architecture. There are two binary inputs and one binary output.
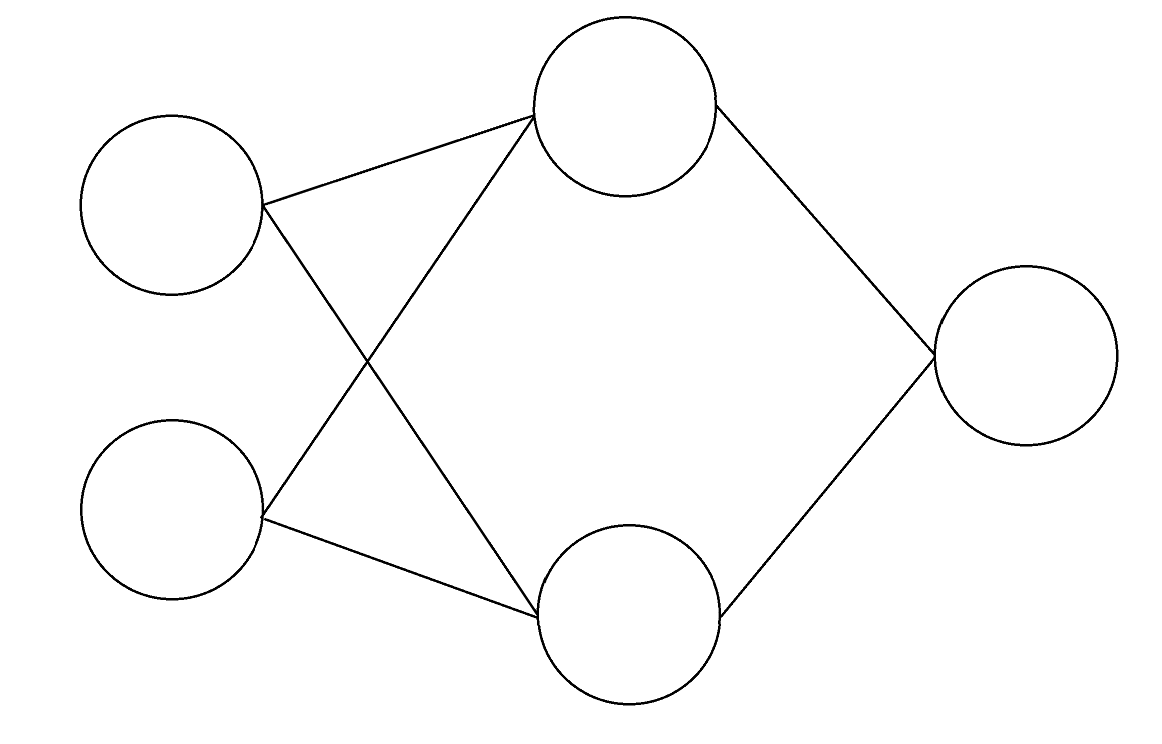
We found that adding a third neuron to the hidden layer made it much easier for the network to learn XOR - the network achieved 100% accuracy on the first training run.
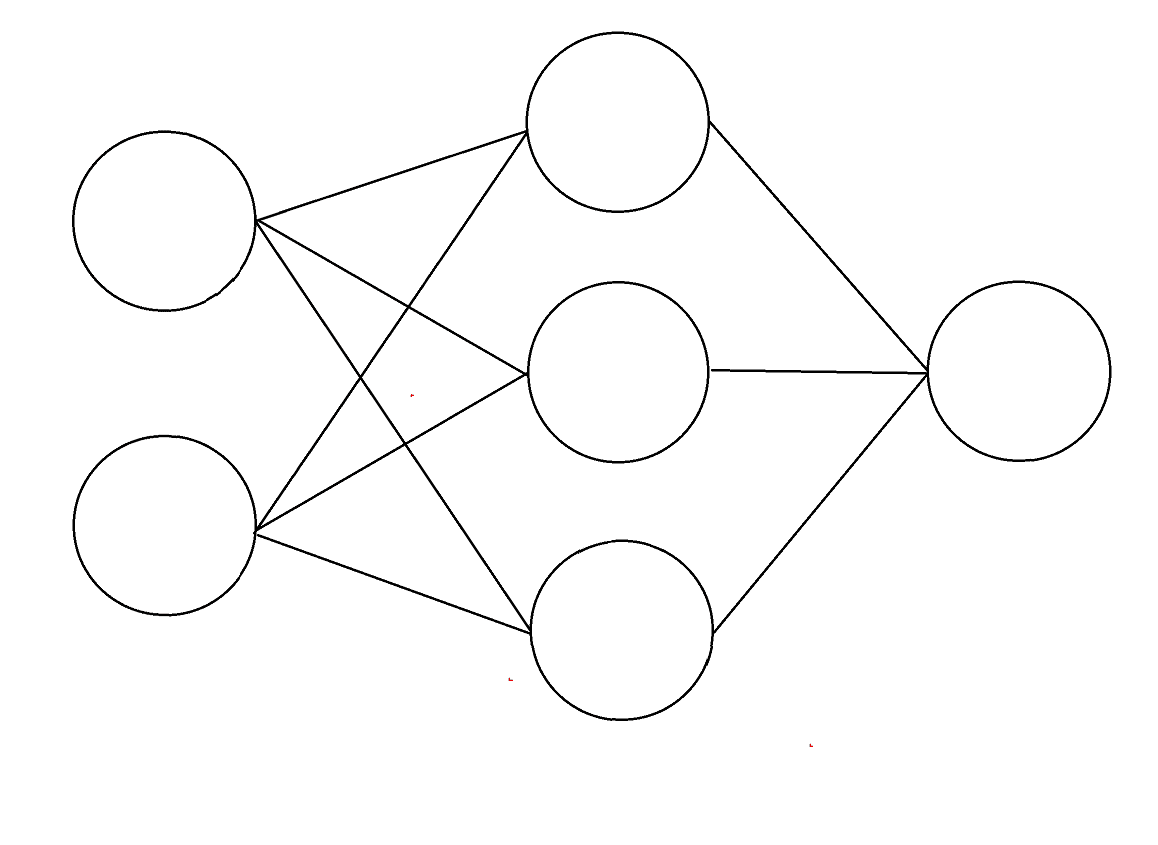
We are unsure why this happened, but our guess is that the additional neuron in the hidden layer allowed the 6 neuron network to “route around” ridges in the loss landscape, even though the network eventually found a solution that only used 5 neurons.
Another question is, why couldn’t we reach ~0 loss with the 6 neuron network? Generally, we got to around 0.3 - 0.6 binary cross-entropy loss, but intuitively it seems like we should be able to decrease the loss arbitrarily by increasing the magnitudes of the weights and biases.
It's possible that the sigmoid activations "ate the gradient," making it very small before we got close to zero loss; it's also possible that there was simply a bug in the code.
TSNE Clusters and Loss Basins
We decided to further investigate why we were only rarely able to get perfect classification with the 5 neuron network. We thought this might have something to do with the loss landscape (perhaps 75% accuracy solutions form a much larger local basin?), so we ran the training process 100 times, stored the learned parameters from each run, and ran TSNE on them. We got what looked like nice clusters.
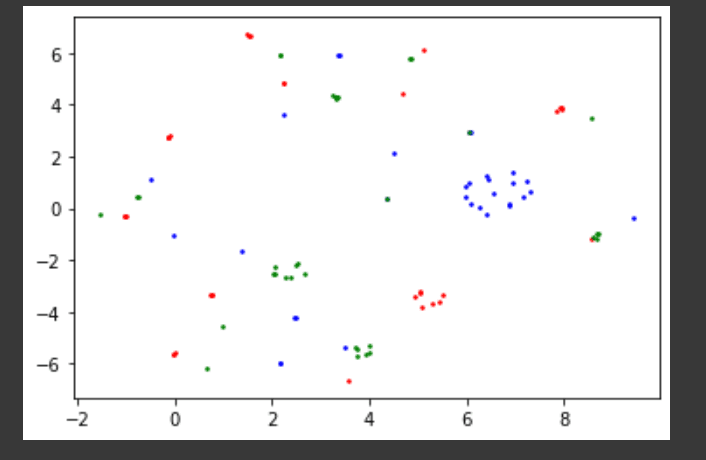
Here, the blue points represent parameters of networks that achieve 75% classification accuracy, the red points correspond to 100% accuracy, and the green points to 50% accuracy. If clusters correspond to loss basins, this would indeed mean that the largest basin contains parameter configurations that correspond to 75% classification accuracy.
We were able to verify that points that appeared close to each other in TSNE space were actually close to each other in the original parameter (pre dimensionality reduction) space by running K-Means on the original parameters.
Testing External Behaviour and Internal Functional Structure
We still weren’t sure whether clusters in the TSNE plot actually corresponded to loss basins, but it seemed fairly likely given that they consist of parameter configurations that are close to each other and are approximately at local minima. We figured that if parameter configurations in the same cluster had roughly the same decision boundaries on the data and the same internal structure, this would be more evidence in favor of clusters corresponding to loss basins.
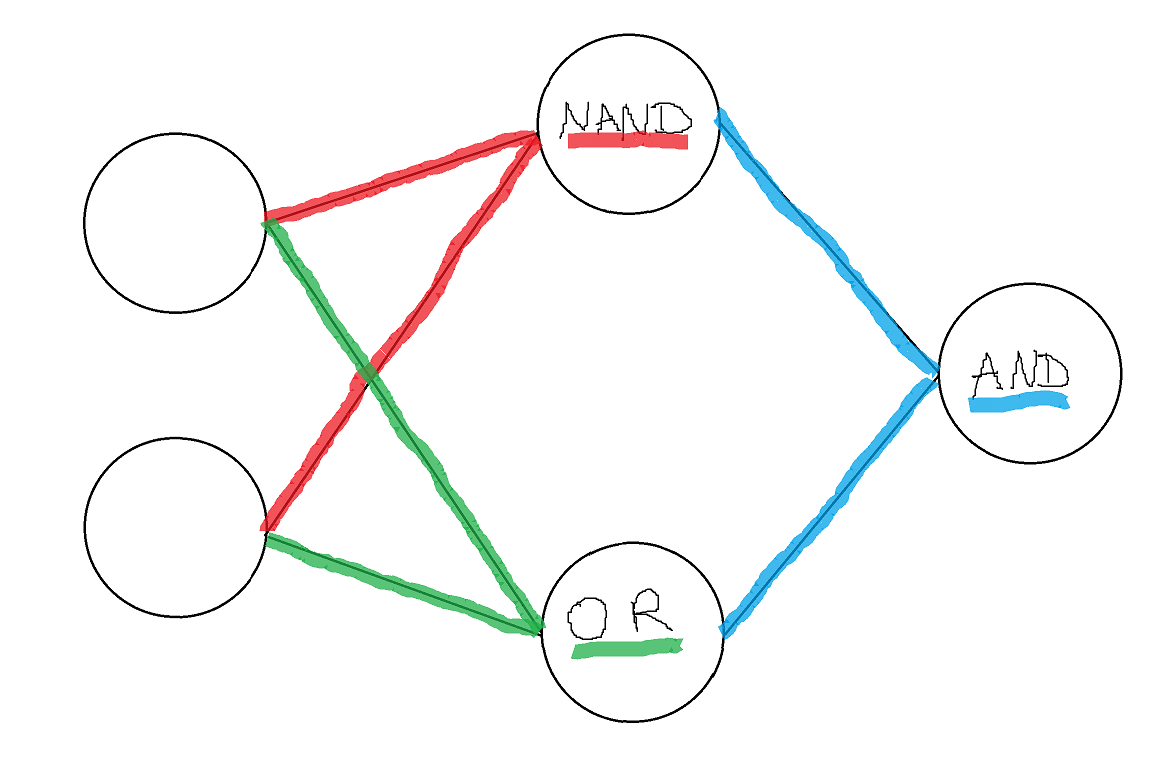
We tested the 100% accuracy cluster and saw that all the points had decision boundaries that looked roughly like this on the [0, 1] x [0, 1] input space (pink corresponds to points in space that are classified as “True,” or 1, and green to points classified as “False,” or 0):
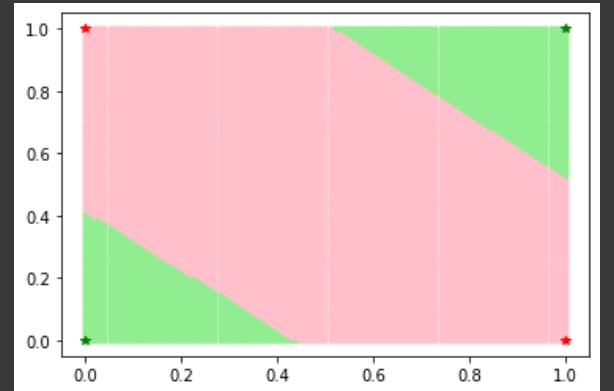
The internal structure also looked the same across all points in the cluster: they were all approximately composed of nand, nor, and implication gates.
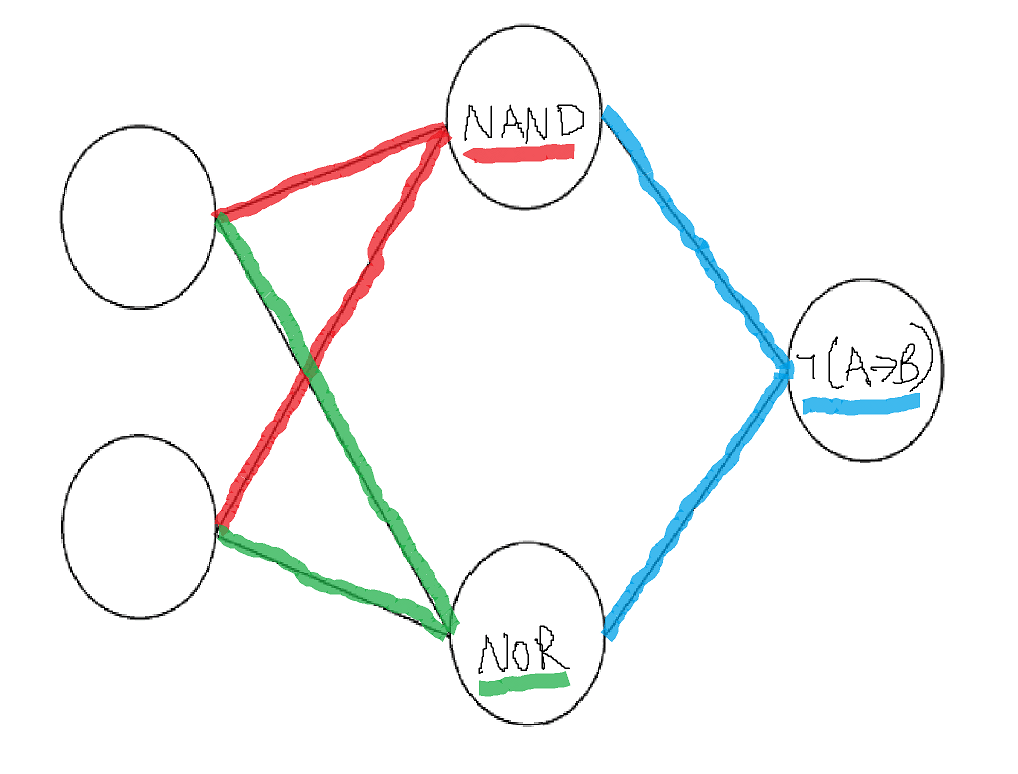
This could be due to low sample size; we only tested 100 runs. This at the very least seems like it’s responsible for the lack of a neuron-swapped cluster; the network is perfectly symmetrical, so an SGD process that creates the nand-nor-implication gates should be just as able to create nor-nand-implication gates. We didn't run an experiment with more training runs due to time constraints.
Since we lacked other clusters of parameters that actually implemented XOR, we examined the 75% accuracy cluster as well. All the points in it implemented roughly this decision boundary:
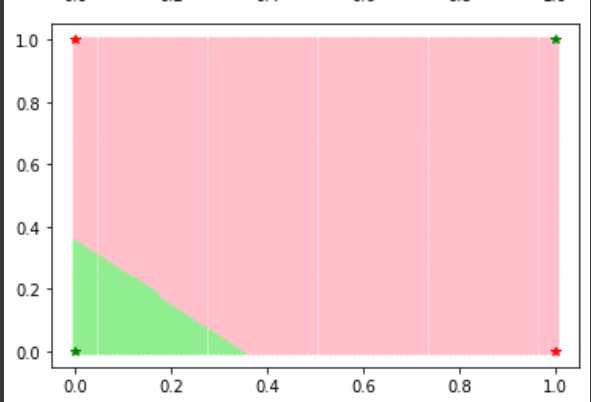
The points in the cluster also corresponded to the same internal functional structure, namely nor-nor-nor.
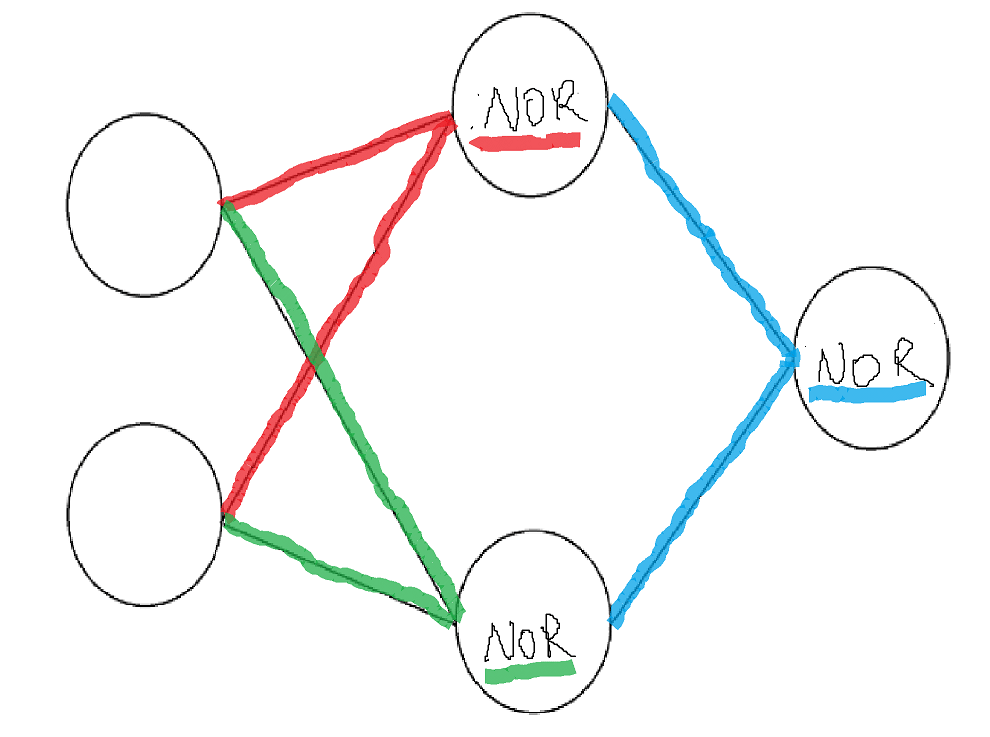
One issue with the training process may be poor initialization; even though we have low sample size, the 75% cluster does seem to be quite large, and it seems plausible that the initialization is to blame given that, visually, the decision boundary tends to be stuck in one corner.
Trajectory Graphs
We wanted to get a better idea of what the loss landscape looked like, and see if close initializations corresponded to ending up in the same cluster (basin?) after training, so we decided to look at trajectory graphs in TSNE space.
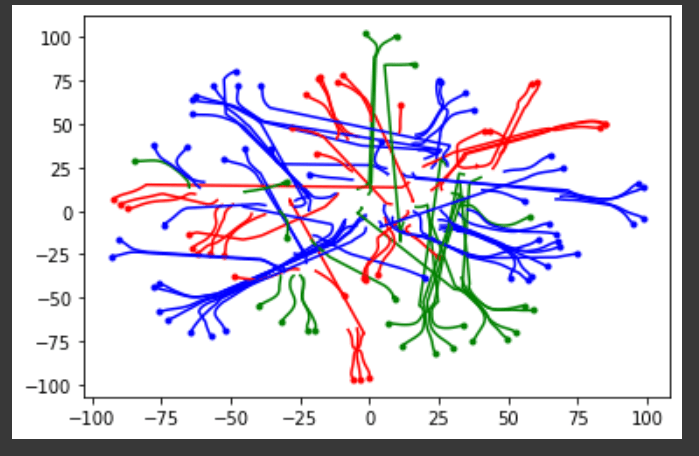
This wasn’t very informative about the loss landscape: the trajectories appear to cross over each other - probably a result of the dimensionality reduction. However, it does seem to suggest that close initializations lead to close final parameters.
Something that occurs in retrospect is that we could have used the trajectory start and end points to try to find a better initialization (by looking at which initializations tend to result in 100% accuracy solutions, and seeing why these intializations might be relatively rare).
Do Larger Networks Tend to Contain Minimal XOR Gates?
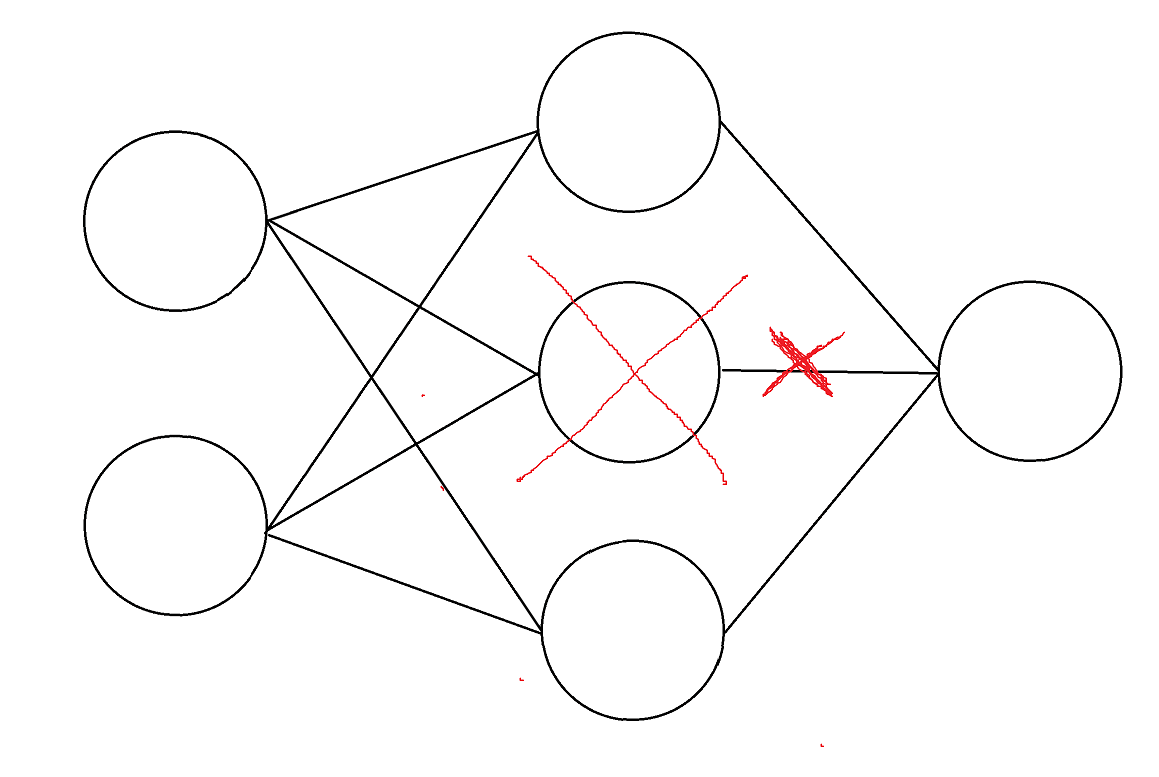
We tried training 6 neuron networks repeatedly to see how often they contained minimal XOR gates (i.e. a neuron could be removed, and the remaining neurons would constitute a composed logic function + keep the same classifications). This seemed relevant to determining whether “you can remove neurons entirely” is a good way to understand free parameters/parameters that you “don’t use.”
Across 20 runs, there were 5-neuron XOR gates embedded in the 6 neuron networks about 70% of the time. At least in one case where there wasn't a minimal XOR gate there was split computation; two neurons in the hidden layer implemented the exact same logic function, and each contributed half of the weight to the output neuron. If we removed one of these neurons, the network didn’t maintain its classifications, but when we then doubled the weight coming out of the remaining neuron we recovered this functionality.
We didn’t get around to trying this with even larger networks, but it seems like an interesting experiment.
Extending XOR
Train three separate 5 neuron XOR networks; separately, initialize a neural network that can fit all 3:
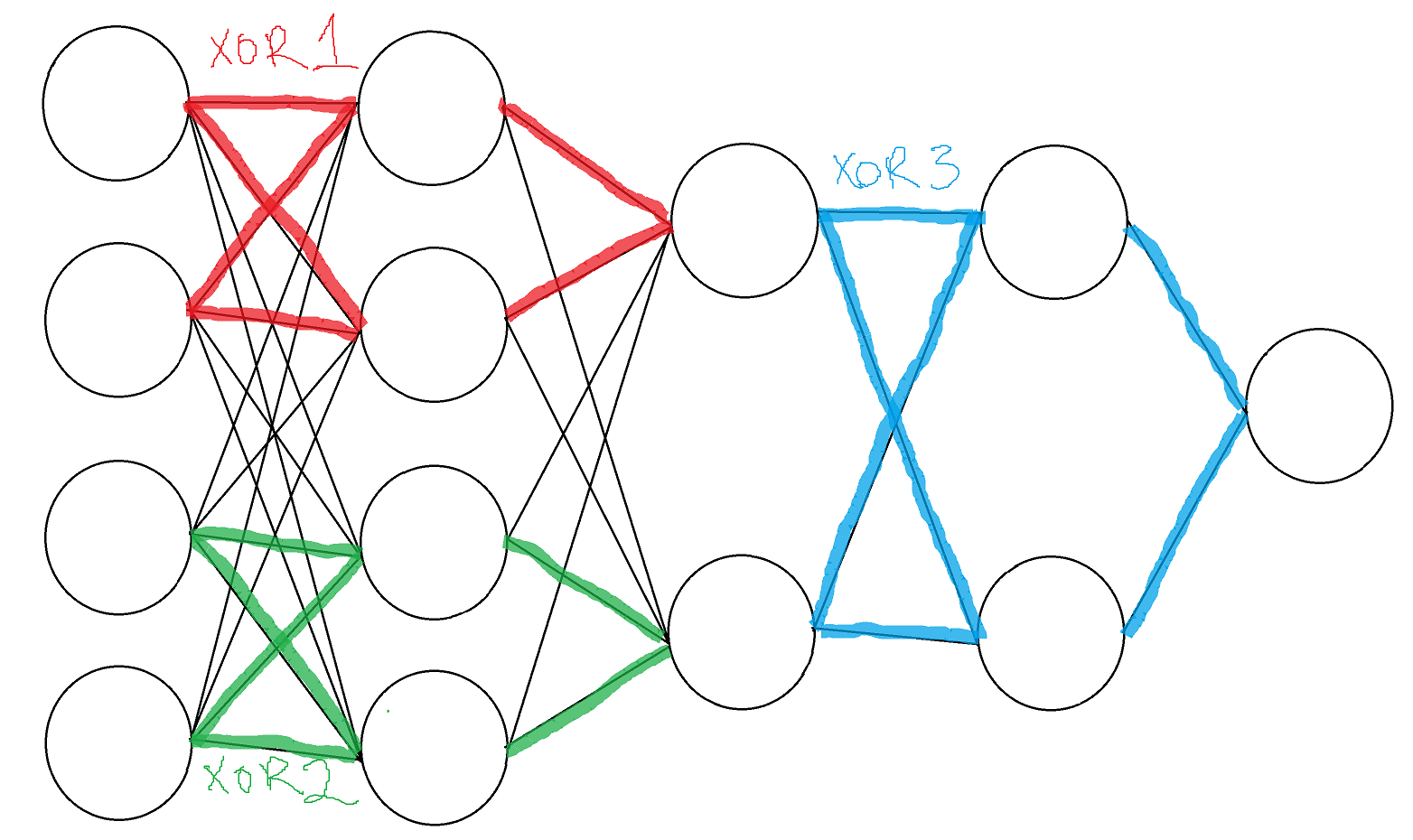
When we trained up different XOR gates, copied them into a larger network, and then started to retrain the big network, the network didn’t change its internal structure. When we extracted the parts of the network where we originally spliced in the 5 neuron XOR gates, and loaded the weights back into three different 5 neurons networks each, these networks still functioned as XOR gates.
This provides some evidence that when you combine networks that have locally optimal parameter configurations, the resulting larger network can still be locally optimal. We only tried this once due to limited time; it might be interesting to investigate whether this is generally the case.
We also tried to use the above larger network to test an abstraction-finding method from this post [LW · GW]. We wanted to try using this to identify modules in neural networks, and decided to demo it on this simple case where we already knew the internal structure. We took the covariance matrix of the neural activations across all 16 binary inputs, and looked for sparsity; it doesn’t seem like we found it. The heatmap of the matrix is shown below.
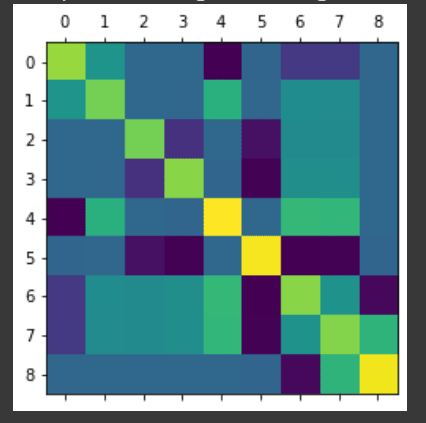
We also looked at the SVD of this covariance matrix, and found that there were only 5 large singular values, as opposed to 9 (the number of neural activations).
The heatmaps of the left and right matrices of the SVD decomposition are depicted below:
We realized that we couldn’t really interpret these results after the fact; we're not sure what this information implies, if anything. It would probably help if we had a better understanding of what taking the SVD of the covariance matrix actually means.
0 comments
Comments sorted by top scores.