Analogical Reasoning and Creativity
post by jacob_cannell · 2015-07-01T20:38:38.658Z · LW · GW · Legacy · 15 commentsContents
Introduction Under the Hood Conceptual Abstractions and Cortical Maps The Hippocampal Association Engine Cultivate memetic heterogeneity and heterozygosity Genetic heterozygosity is the quality of having two different alleles at a gene locus; summed over the organism this leads to a different but related concept of diversity. Construct and maintain clean conceptual taxonomies Conclusion None 15 comments
This article explores analogism and creativity, starting with a detailed investigation into IQ-test style analogy problems and how both the brain and some new artificial neural networks solve them. Next we analyze concept map formation in the cortex and the role of the hippocampal complex in establishing novel semantic connections: the neural basis of creative insights. From there we move into learning strategies, and finally conclude with speculations on how a grounded understanding of analogical creative reasoning could be applied towards advancing the art of rationality.

- Introduction
- Under the Hood
- Conceptual Abstractions and Cortical Maps
- The Hippocampal Association Engine
- Cultivate memetic heterogeneity and heterozygosity
- Construct and maintain clean conceptual taxonomies
- Conclusion
Introduction
The computer is like a bicycle for the mind.
-- Steve Jobs
The kingdom of heaven is like a mustard seed, the smallest of all seeds, but when it falls on prepared soil, it produces a large plant and becomes a shelter for the birds of the sky.
-- Jesus
Sigmoidal neural networks are like multi-layered logistic regression.
-- various
The threat of superintelligence is like a tribe of sparrows who find a large egg to hatch and raise. It grows up into a great owl which devours them all.
-- Nick Bostrom (see this video)
Analogical reasoning is one of the key foundational mechanisms underlying human intelligence, and perhaps a key missing ingredient in machine intelligence. For some - such as Douglas Hofstadter - analogy is the essence of cognition itself.[1]
Steve Job's bicycle analogy is clever because it encapsulates the whole cybernetic idea of computers as extensions of the nervous system into a single memorable sentence using everyday terms.
A large chunk of Jesus's known sayings are parables about the 'Kingdom of Heaven': a complex enigmatic concept that he explains indirectly through various analogies, of which the mustard seed is perhaps the most memorable. It conveys the notions of exponential/sigmoidal growth of ideas and social movements (see also the Parable of the Leaven), while also hinting at greater future purpose.
In a number of fields, including the technical, analogical reasoning is key to creativity: most new insights come from establishing mappings between or with concepts from other fields or domains, or from generalizing existing insights/concepts (which is closely related). These abilities all depend on deep, wide, and well organized internal conceptual maps.
Under the Hood
You can think of the development of IQ tests as a search for simple tests which have high predictive power for g-factor in humans, while being relatively insensitive to specific domain knowledge. That search process resulted in a number of problem categories, many of which are based on verbal and mathematical analogies.
The image to the right is an example of a simple geometric analogy problem. As an experiment, start a timer before having a go at it. For bonus points, attempt to introspect on your mental algorithm.
Solving this problem requires first reducing the images to simpler compact abstract representations. The first rows of images then become something like sentences describing relations or constraints (Z is to ? as A is to B and C is to D). The solution to the query sentence can then be found by finding the image which best satisfies the likely analogous relations.
Imagine watching a human subject (such as your previous self) solve this problem while hooked up to a future high resolution brain imaging device. Viewed in slow motion, you would see the subject move their eyes from location to location through a series of saccades, while various vectors or mental variable maps flowed through their brain modules. Each fixation lasts about 300ms[2], which gives enough time for one complete feedforward pass through the dorsal vision stream and perhaps one backwards sweep.

The output of the dorsal stream in inferior temporal cortex (TE on the bottom) results in abstract encodings which end up in working memory buffers in prefrontal cortex. From there some sort of learned 'mental program' implements the actual analogy evaluations, probably involving several more steps in PFC, cingulate cortex, and various other cortical modules (coordinated by the Basal Ganglia and PFC). Meanwhile the eye frontal fields and various related modules are computing the next saccade decision every 300ms or so.
If we assume that visual parsing requires one fixation on each object and 50ms saccades, this suggests that solving this problem would take a typical brain a minimum of about 4 seconds (and much longer on average). The minimum estimate assumes - probably unrealistically - that the subject can perform the analogy checks or mental rotations near instantly without any backtracking to help prime working memory. Of course faster times are also theoretically possible - but not dramatically faster.
These types of visual analogy problems test a wide set of cognitive operations, which by itself can explain much of the correlation with IQ or g-factor: speed and efficiency of neural processing, working memory, module communication, etc.
However once we lay all of that aside, there remains a core dependency on the ability for conceptual abstraction. The mapping between these simple visual images and their compact internal encodings is ambiguous, as is the predictive relationship. Solving these problems requires the ability to find efficient and useful abstractions - a general pattern recognition ability which we can relate to efficient encoding, representation learning, and nonlinear dimension reduction: the very essence of learning in both man and machine[3].
The machine learning perspective can help make these connections more concrete when we look into state of the art programs for IQ tests in general and analogy problems in particular. Many of the specific problem subtypes used in IQ tests can be solved by relatively simple programs. In 2003, Sange and Dowe created a simple Perl program (less than 1000 lines of code) that can solve several specific subtypes of common IQ problems[4] - but not analogies. It scored an IQ of a little over 100, simply by excelling in a few categories and making random guesses for the remaining harder problem types. Thus its score is highly dependent on the test's particular mix of subproblems, but that is also true for humans to some extent.
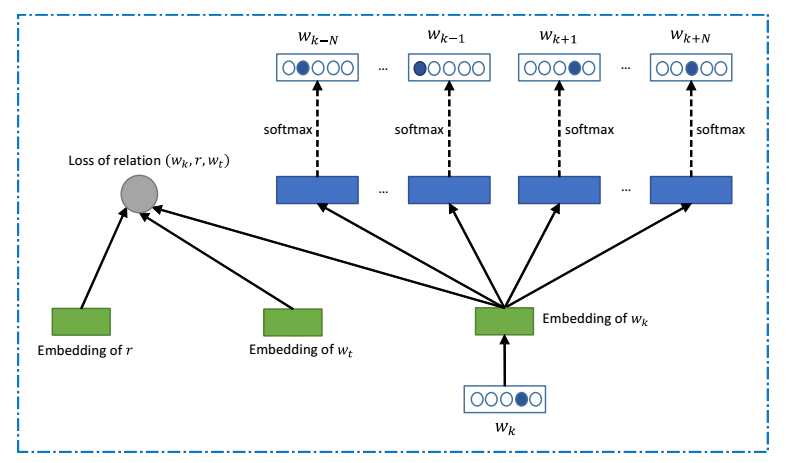
The IQ test sub-problems that remain hard for computers are those that require pattern recognition combined with analogical reasoning and or inductive inference. Precise mathematical inductive inference is easier for machines, whereas humans excel at natural reasoning - inference problems involving huge numbers of variables that can only be solved by scalable approximations.

The word vector embedding is learned as a component of an ANN trained via backprop on a large corpus of text data - Wikipedia. This particular model is rather complex: it combines a multi-sense word embedding, a local sliding window prediction objective, task-specific geometric objectives, and relational regularization constraints. Unlike the recent crop of general linguistic modeling RNNs, this particular system doesn't model full sentence structure or longer term dependencies - as those aren't necessary for answering these specific questions. Surprisingly all it takes to solve the verbal analogy problems typical of IQ/SAT/GRE style tests are very simple geometric operations in the word vector space - once the appropriate embedding is learned.
As a trivial example: "Uncle is to Aunt as King is to ?" literally reduces to:
Uncle + X = Aunt, King + X = ?, and thus X = Aunt-Uncle, and:
? = King + (Aunt-Uncle).
The (Aunt-Uncle) expression encapsulates the concept of 'femaleness', which can be combined with any male version of a word to get the female version. This is perhaps the simplest example, but more complex transformations build on this same principle. The embedded concept space allows for easy mixing and transforms of memetic sub-features to get new concepts.
Conceptual Abstractions and Cortical Maps
The success of these simplistic geometric transforms operating on word vector embeddings should not come as a huge surprise to one familiar with the structure of the brain. The brain is extraordinarily slow, so it must learn to solve complex problems via extremely simple and short mental programs operating on huge wide vectors. Humans (and now convolutional neural networks) can perform complex visual recognition tasks in just 10-15 individual computational steps (150 ms), or 'cortical clock cycles'. The entire program that you used to solve the earlier visual analogy problem probably took on the order of a few thousand cycles (assuming it took you a few dozen seconds). Einstein solved general relativity in - very roughly - around 10 billion low level cortical cycles.
The core principle behind word vector embeddings, convolutional neural networks, and the cortex itself is the same: learning to represent the statistical structure of the world by an efficient low complexity linear algebra program (consisting of local matrix vector products and per-element non-linearities). The local wiring structure within each cortical module is equivalent to a matrix with sparse local connectivity, optimized heavily for wiring and computation such that semantically related concepts cluster close together.

(Concept mapping the cortex, from this research page)
The image above is from the paper "A Continous Semantic Space Describes the Representation of Thousands of Object and Action Categories across the Human Brain" by Huth et al.[5] They used fMRI to record activity across the cortex while subjects watched annotated video clips, and then used that data to find out roughly what types of concepts each voxel of cortex responds to. It correctly identifies the FFA region as specializing in people-face things and the PPA as specializing in man-made objects and buildings. A limitation of the above image visualizations is that they don't show response variance or breadth, so the voxel colors are especially misleading for lower level cortical regions that represent generic local features (such as gabor edges in V1).
The power of analogical reasoning depends entirely on the formation of efficient conceptual maps that carve reality at the joints. The visual pathway learns a conceptual hierarchy that builds up objects from their parts: a series of hierarchical has-a relationships encoded in the connections between V1, V2, V4 and so on. Meanwhile the semantic clustering within individual cortical maps allows for fast computations of is-a relationships through simple local pooling filters.
An individual person can be encoded as a specific active subnetwork in the face region, and simple pooling over a local cluster of neurons across the face region can then compute the presence of a face in general. Smaller local pooling filters with more specific shapes can then compute the presence of a female or male face, and so on - all starting from the full specific feature encoding.
The pooling filter concept has been extensively studied in the lower levels of the visual system, where 'complex' cells higher up in V1 pool over 'simple' cell features: abstracting away gabor edges at specific positions to get edges OR'd over a range of positions (CNNs use this same technique to gain invariance to small local translations).
This key semantic organization principle is used throughout the cortex: is-a relations and more general abstractions/invariances are computed through fast local intramodule connections that exploit the physical semantic clustering on the cortical surface, and more complex has-a relations and arbitrary transforms (ex: mapping between an eye centered coordinate basis and a body centered coordinate basis) are computed through intermodule connections (which also exploit physical clustering).
The Hippocampal Association Engine
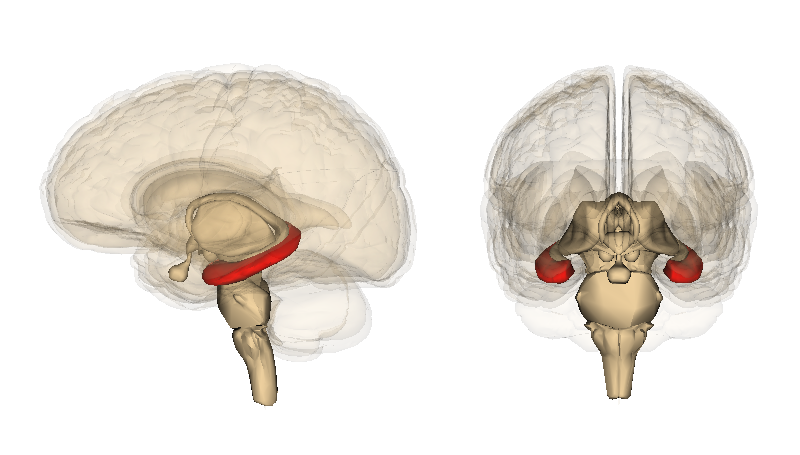
The Hippocampus is a tubular seahorse shaped module located in the center of the brain, to the exterior side of the central structures (basal ganglia, thalamus). It is the brain's associative database and search engine responsible for storing, retrieving, and consolidating patterns and declarative memories (those which we are consciously aware of and can verbally declare) over long time scales beyond the reach of short term memory in the cortex itself.
A human (or animal) unfortunate enough to suffer complete loss of hippocampal functionality basically loses the ability to form and consolidate new long term episodic and semantic memories. They also lose more recent memories that have not yet been consolidated down the cortical hierarchy. In rats and humans, problems in the hippocampal complex can also lead to spatial navigation impairments (forgetting current location or recent path), as the HC is used to compute and retrieve spatial map information associated with current sensory impressions (a specific instance of the HC's more general function).
In terms of module connectivity, the hippocampal complex sits on top of the cortical sensory hierarchy. It receives inputs from a number of cortical modules, largely in the nearby associative cortex, which collectively provide a summary of the recent sensory stream and overall brain state. The HC then has several sub circuits which further compress the mental summary into something like a compact key which is then sent into a hetero-auto-associative memory circuit to find suitable matches.
If a good match is found, it can then cause retrieval: reactivation of the cortical subnetworks that originally formed the memory. As the hippocampus can't know for sure which memories will be useful in the future, it tends to store everything with emphasis on the recent, perhaps as a sort of slow exponentially fading stream. Each memory retrieval involves a new decoding and encoding to drive learning in the cortex through distillation/consolidation/retraining (this also helps prevent ontological crisis). The amygdala is a little cap on the edge of the hippocampus which connects to the various emotion subsystems and helps estimate the importance of current memories for prioritization in the HC.
A very strong retrieval of an episodic memory causes the inner experience of reliving the past (or imagining the future), but more typical weaker retrievals (those which load information into the cortex without overriding much of the existing context) are a crucial component in general higher cognition.
In short the computation that the HC performs is that of dynamic association between the current mental pattern/state loaded into short term memory across the cortex and some previous mental pattern/state. This is the very essence of creative insight.
Associative recall can be viewed as a type of pattern recognition with the attendant familiar tradeoffs between precision/recall or sensitivity/specificity. At the extreme of low recall high precision the network is very conservative and risk averse: it only returns high confidence associations, maximizing precision at the expense of recall (few associations found, many potentially useful matches are lost). At the other extreme is the over-confident crazy network which maximizes recall at the expense of precision (many associations are made, most of which are poor). This can also be viewed in terms of the exploitation vs exploration tradeoff.
This general analogy or framework - although oversimplified - also provides a useful perspective for understanding both schizotypy and hallucinogenic drugs. There is a large body of accumulated evidence in the form of use cases or trip reports, with a general consensus that hallucinogens can provide occasional flashes of creative insight at the expense of pushing one farther towards madness.
From a skeptical stance, using hallucinogenic drugs in an attempt to improve the mind is like doing surgery with butter-knives. Nonetheless, careful exploration of the sanity border can help one understand more on how the mind works from the inside.
Cannabis in particular is believed - by many of its users - to enhance creativity via occasional flashes of insight. Most of its main mental effects: time dilation, random associations, memory impairment, spatial navigation impairment, etc appear to involve the hippocampus. We could explain much of this as a general shift in the precision/recall tradeoff to make the hippocampus less selective. Mainly that makes the HC just work less effectively, but it also can occasionally lead to atypical creative insights, and appears to elevate some related low level measures such as schizotypy and divergent thinking[7]. The tradeoff is one must be willing to first sift through a pile of low value random associations.
Cultivate memetic heterogeneity and heterozygosity
Fluid intelligence is obviously important, but in many endeavors net creativity is even more important.
Of all the components underlying creativity, improving the efficiency of learning, the quality of knowledge learned, and the organizational efficiency of one's internal cortical maps are probably the most profitable dimensions of improvement: the low hanging fruits.
Our learning process is largely automatic and subconscious : we do not need to teach children how to perceive the world. But this just means it takes some extra work to analyze the underlying machinery and understand how to best utilize it.
Over long time scales humanity has learned a great deal on how to improve on natural innate learning: education is more or less learning-engineering. The first obvious lesson from education is the need for curriculum: acquiring concepts in stages of escalating complexity and order-dependency (which of course is already now increasingly a thing in machine learning).
In most competitive creative domains, formal education can only train you up to the starting gate. This of course is to be expected, for the creation of novel and useful ideas requires uncommon insights.
Memetic evolution is similar to genetic evolution in that novelty comes more from recombination than mutation. We can draw some additional practical lessons from this analogy: cultivate memetic heterogeneity and heterozygosity.
The first part - cultivate memetic heterogeneity - should be straightforward, but it is worth examining some examples. If you possess only the same baseline memetic population as your peers, then the chances of your mind evolving truly novel creative combinations are substantially diminished. You have no edge - your insights are likely to be common.
To illustrate this point, let us consider a few examples:
Geoffrey Hinton is one of the most successful researchers in machine learning - which itself is a diverse field. He first formally studied psychology, and then artificial intelligence. His various 200 research publications integrate ideas from statistics, neuroscience and physics. His work on boltzmann machines and variants in particular imports concepts from statistical physics whole cloth.
Before founding DeepMind (now one of the premier DL research groups in the world), Demis Hassabis studied the brain and hippocampus in particular at the Gatsby Computational Neuroscience Unit, and before that he worked for years in the video game industry after studying computer science.
Before the Annus Mirabilis, Einstein worked at the patent office for four years, during which time he was exposed to a large variety of ideas relating to the transmission of electric signals and electrical-mechanical synchronization of time, core concepts which show up in his later thought experiments.[8]
Creative people also tend to have a diverse social circle of creative friends to share and exchange ideas across fields.
Genetic heterozygosity is the quality of having two different alleles at a gene locus; summed over the organism this leads to a different but related concept of diversity.
Within developing fields of knowledge we often find key questions or subdomains for which there are multiple competing hypotheses or approaches. Good old fashioned AI vs Connectionism, Ray tracing vs Rasterization, and so on.
In these scenarios, it is almost always better to understand both viewpoints or knowledge clusters - at least to some degree. Each cluster is likely to have some unique ideas which are useful for understanding the greater truth or at the very least for later recombination.
This then is memetic heterozygosity. It invokes the Jain version of the blind men and the elephant.
Construct and maintain clean conceptual taxonomies
Formal education has developed various methods and rituals which have been found to be effective through a long process of experimentation. Some of these techniques are still quite useful for autodidacts.
When one sets out to learn, it is best to start with a clear goal. The goal of high school is just to provide a generalist background. In college one then chooses a major suitable for a particular goal cluster: do you want to become a computer programmer? a physicist? a biologist? etc. A significant amount of work then goes into structuring a learning curriculum most suitable for these goal types.
Once out of the educational system we all end up creating our own curriculums, whether intentionally or not. It can be helpful to think strategically as if planning a curriculum to suit one's longer term goals.
For example, about four years ago I decided to learn how the brain works and how AGI could be built in particular. When starting on this journey, I had a background mainly in computer graphics, simulation, and game related programming. I decided to focus about equally on mainstream AI, machine learning, computational neuroscience, and the AGI literature. I quickly discovered that my statistics background was a little weak, so I had to shore that up. Doing it all over again I may have started with a statistics book. Instead I started with AI: a modern approach (of course I mostly learn from the online research literature).
Learning works best when it is applied. Education exploits this principle and it is just as important for autodidactic learning. The best way to learn many math or programming concepts is learning by doing, where you create reasonable subtasks or subgoals for yourself along the way.
For general knowledge, application can take the form of writing about what you have learned. Academics are doing this all the time as they write papers and textbooks, but the same idea applies outside of academia.
In particular a good exercise is to imagine that you need to communicate all that you have learned about the domain. Imagine that you are writing a textbook or survey paper for example, and then you need to compress all that knowledge into a summary chapter or paper, and then all of that again down into an abstract. Then actually do write up a summary - at least in the form of a blog post (even if you don't show it to anybody).
The same ideas apply on some level to giving oral presentations or just discussing what you have learned informally - all of which are also features of the academic learning environment.
Early on, your first attempts to distill what you have learned into written form will be ... poor. But doing this process forces you to attempt to compress what you have learned, and thus it helps encourage the formation of well structured concept maps in the cortex.
A well structured conceptual map can be thought of as a memetic taxonomy. The point of a taxonomy is to organize all the invariances and 'is-a' relationships between objects so that higher level inferences and transformations can generalize well across categories.
Explicitly asking questions which probe the conceptual taxonomy can help force said structure to take form. For example in computer science/programming the question: "what is the greater generalization of this algorithm?" is a powerful tool.
In some domains, it may even be possible to semi-automate or at least guide the creative process using a structured method.
For example consider sci-fi/fantasy genre novels. Many of the great works have a general analogical structure based on real history ported over into a more exotic setting. The foundation series uses the model of the fall of the roman empire. Dune is like Lawrence of Arabia in space. Stranger in a Strange Land is like the Mormon version of Jesus the space alien, but from Mars instead of Kolob. A Song of Fire and Ice is partly a fantasy port of the war of the roses. And so on.
One could probably find some new ideas for novels just by creating and exploring a sufficiently large table of historical events and figures and comparing it to a map of the currently colonized space of ideas. Obviously having an idea for a novel is just the tiniest tip of the iceberg in the process, but a semi-formal method is interesting nonetheless for brainstorming and applies across domains (others have proposed similar techniques for generating startup ideas, for example).
Conclusion
We are born equipped with sophisticated learning machinery and yet lack innate knowledge on how to use it effectively - for this too we must learn.
The greatest constraint on creative ability is the quality of conceptual maps in the cortex. Understanding how these maps form doesn't automagically increase creativity, but it does help ground our intuitions and knowledge about learning, and could pave the way for future improved techniques.
In the meantime: cultivate memetic heterogeneity and heterozygosity, create a learning strategy, develop and test your conceptual taxonomy, continuously compress what you learn by writing and summarizing, and find ways to apply what you learn as you go.
15 comments
Comments sorted by top scores.
comment by Gunnar_Zarncke · 2015-07-02T20:27:34.626Z · LW(p) · GW(p)
Quite a good compression of your engagement in the topics. Did this develop from your 'unread blog posts' on the topics?
A suggest you move this to Main; the small number of typos will not hurt I assume.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-03T07:44:55.034Z · LW(p) · GW(p)
I've already read through it twice and didnt see the typos - pm me? I can't see them after a while.
This is still kinda rough draftish. In part it's my queued answer for the next time someone says ... "but machines will never be creative", as my last post was the cached answer for everything along the lines of "but we have no idea how the brain works."
Replies from: Gunnar_Zarncke, darius↑ comment by Gunnar_Zarncke · 2015-07-03T21:03:59.456Z · LW(p) · GW(p)
Uh, I think that I saw some (like the their above) but I'm not native speaker so you can't trust me on such things. I seem to remember that katydee offered spellchecking.
comment by passive_fist · 2015-07-04T22:05:00.263Z · LW(p) · GW(p)
The HC then has several sub circuits which further compress the mental summary into something like a compact key which is then sent into a hetero-auto-associative memory circuit to find suitable matches.
This use of a symbolic key-store system is one that I think gets downplayed a lot by machine learning/neural network perspectives on how the brain works. I also fear you might be downplaying it a bit as well. In the book Memory and the Computational Brain, Gallistel and King make the pretty convincing argument that a lot of what goes in the brain must be various types of symbolic representation and processing. They show a few examples of types of processing that simply can't be achieved with the kinds of neural networks used in most "deep learning" approaches.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-07T05:08:17.013Z · LW(p) · GW(p)
Agree it is important; I emphasize it in this post and my previous one.
We can differentiate between learning at two levels: circuit level and program/symbolic level. Learning a direct circuit to solve the problem works well when you have lots of time/data, the problem is very important/frequent, and latency/speed is crucial. This is deep learning with standard feedforward and or RNNs, similar to what the cortex & cerebellum does.
There is also program/symbolic level learning, which is important when you have small amounts of data and need to learn fast, and lower speed is acceptable. This involves learning a 'program' level solution, which can be much more compact than a circuit level solution for some more complex problems where the minimal depth circuit is too high. It also allows for much faster learning in some cases. The brain implements program/symbolic learning with networks using the PFC for short term memory and the hippocampus for medium/long term memory, coordinated with the cortex & cerbellum by the basal ganglia.
Program/symbolic learning is a new 'hot' upcoming area of research in DL: neural turing machines, memory networks, learning program execution, etc. The inductive program learning field has been working on similar stuff, but the new DL approaches have the huge scaling advantages of modern SGD + ANN systems.
Replies from: passive_fist↑ comment by passive_fist · 2015-07-07T06:41:33.301Z · LW(p) · GW(p)
I encourage you to read Gallistel's work, and also the recent experimental work of Hesslow's group (I can provide references if you want). It runs contradictory to the viewpoint you're expressing.
Learning a direct circuit to solve the problem works well when you have lots of time/data, the problem is very important/frequent, and latency/speed is crucial.
Gallistel shows that even when these criteria are met some problems are simply infeasible to learn with 'standard' perceptron nets.
This is deep learning with standard feedforward and or RNNs, similar to what the cortex & cerebellum does.
Hesslow's work shows that the cerebellum carries out processing that is far more sophisticated than a standard feedforward network or RNN.
The brain implements program/symbolic learning with networks using the PFC for short term memory and the hippocampus for medium/long term memory
There is no evidence for this, and based on the aforementioned work, there's no reason to think there ever will be evidence for this.
The inductive program learning field has been working on similar stuff
AI and machine learning work is separate from what I'm saying. Indeed the machine learning people have been coming up with amazing advances and models that learn very well; but there is no evidence that any of this has a direct analogue in the brain. It probably has an indirect analogue, but likely no direct one.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-07T16:10:58.810Z · LW(p) · GW(p)
I encourage you to read Gallistel's work, and also the recent experimental work of Hesslow's group (I can provide references if you want).
The 2009 book you linked? I browsed the chapter contents. If there is anything new/interesting in there for me, it would only be in a couple of chapters. If there is some specific experimental evidence of importance - please provide links. I've browsed Gallistel's publication list. I don't see anything popping out as relevant.
Gallistel shows that even when these criteria are met some problems are simply infeasible to learn with 'standard' perceptron nets.
Link? Sounds uninteresting and not new. There are limits to what any particular model can learn, and 'Standard' perceptron nets aren't especially interesting. There is a body of work in DL on learning theory, and I doubt that Gallistel has much to contribute there - being in cog sci.
Hesslow's work shows that the cerebellum carries out processing that is far more sophisticated than a standard feedforward network or RNN.
I'm beyond skeptical - especially given that a standard RNN (or a sufficiently deep feedforward net) is a universal approximator. You are referring to Germund Hesslow? Which publication?
.The brain implements program/symbolic learning with networks using the PFC for short term memory and the hippocampus for medium/long term memory
There is no evidence for this, and based on the aforementioned work, there's no reason to think there ever will be evidence for this.
Which part? It should be obvious the brain can learn mental programs - and I gave many examples such as reading. The short term memory role of stripes in PFC is well established, although all cortical regions are recurrent and thus have some memory capacity - the PFC appears to be specialized. The BG's role in controlling the cortex, especially the PFC loops, is pretty well established and I linked to the supporting research in my brain ULM post. The hippocampus's role in longer term memory - also well established.
Replies from: passive_fist↑ comment by passive_fist · 2015-07-08T21:33:10.273Z · LW(p) · GW(p)
I'm really glad that you're interested in this subject.
I recommend the 2009 book for the argument it presents that a symbolic key-value-store memory seems to be necessary for a lot of what the brains of humans and various other animals do. You say it has 'nothing new', so I assume then that you're already familiar with this argument.
Link? Sounds uninteresting and not new. I'm beyond skeptical - especially given that a standard RNN (or a sufficiently deep feedforward net) is a universal approximator.
You're referring to the Cybenko theorem and other theorems, which only establish 'universality' for a very narrow definition of 'universal'. In particular, a feedforward neural net lacks persistent memory. RNNs do not necessarily solve this problem! In many (not all, but the most common) RNN formulations, what exists is simply a form of 'volatile' memory that is easily overwritten when new training data emerges. In contrast, experiments involving https://en.wikipedia.org/wiki/Eyeblink_conditioning show that nervous systems store persistent memories. In particular, if you train an individual to respond to a conditioning stimulus, and then later 'un-train' the individual, and then attempt to train the individual again, they will learn much faster than the first time. A persistent change to the neural network structure has occurred. There have been various ways of trying to get around this problem of RNNs such as https://en.wikipedia.org/wiki/Long_short_term_memory but they wind up being either incredibly large (the Cybenko theorem does not place a limit on the size of the net) and thus infeasible, or otherwise ineffective.
Why ineffective? Experiments show why. Hesslow's recent experiment on cerebellar Purkinje cells: http://www.pnas.org/content/111/41/14930.short shows that this mechanism of learning spatiotemporal behavior and storing it persistently can be isolated to a single cell. This is very significant. It shows that not only the perceptron model, but even the Hodgkin-Huxley model is woefully inadequate for describing neural behavior.
The entire argument around the difference between the 'standard' neural network way of doing things and the way the brain seems to do things revolves around symbolic processing, as I said. In particular, any explanation of memory must be able to explain its persistence, the fact that symbolic information (numbers, etc.) can be stored and retrieved, and this all occurs persistently. Especially, the property of retrieval is often misunderstood. Retrieval means that, given some 'key' or 'pointer' to a memory, we can retrieve that memory. Often, network/associative explanations of memory revolve around purely associative memories. That is, memories of the form where if you have part of the memory, the system gives you back the rest of the memory. This is all well and good, but to actually form a general-purpose memory you need to do something somewhat different: be able to recall the memory when all you have is just a pointer to the memory (as is done in the main memory of a computer). This can be implemented in an associative memory but it requires two additional mechanisms: A mechanism to associate a pointer with a memory, and a mechanism to integrate the memory and pointer together in an associative structure. We do not yet know what form such a mechanism takes in the brain.
Gallistel's other ideas - like using RNA or DNA to store memories - seem dubious and ill-supported by evidence. But he's generally right about the need for a compact symbolic memory system.
Replies from: jacob_cannell, Darklight↑ comment by jacob_cannell · 2015-07-10T00:13:05.317Z · LW(p) · GW(p)
I recommend the 2009 book for the argument it presents that a symbolic key-value-store memory seems to be necessary for a lot of what the brains of humans and various other animals do. You say it has 'nothing new', so I assume then that you're already familiar with this argument.
I actually said:
If there is anything new/interesting in there for me, it would only be in a couple of chapters.
The whole symbolic key-value-store memory is a main key point of my OP and my earlier brain article. "Memory and the computational brain", from what I can tell, seems to provide a good overview of the recent neuroscience stuff which I covered in my ULM post. I'm not disparaging the book, just saying that it isn't something that I have time to read at the moment, and most of the material looks familiar.
There have been various ways of trying to get around this problem of RNNs such as https://en.wikipedia.org/wiki/Long_short_term_memory but they wind up being either incredibly large (the Cybenko theorem does not place a limit on the size of the net) and thus infeasible, or otherwise ineffective.
LSTM is already quite powerful, and new variants - such as the recent grid LSTM - continue to expand the range of what can feasibly be learned. In many ways their learning abilities are already beyond the brain (see the parity discussion in the other thread).
That being said, LSTM isn't everything, and a general AGI will also need a memory-based symbolic system, which can excel especially at rapid learning from few examples - as discussed. Neural turing machines and memory networks and related are now expanding into that frontier. You seem to be making a point that standard RNNs can't do effective symbolic learning - and I agree. That's what the new memory based systems are for.
Why ineffective? Experiments show why. Hesslow's recent experiment on cerebellar Purkinje cells: http://www.pnas.org/content/111/41/14930.short shows that this mechanism of learning spatiotemporal behavior and storing it persistently can be isolated to a single cell. This is very significant.
Ok, I read enough of that paper to get the gist. I don't think it's that significant. Assuming their general conclusion is correct and they didn't make any serious experimental mistakes, all that they have shown is that the neuron itself can learn a simple timing response. The function they learned only requires that the neuron model a single parameter - a t value. We have already known for a while that many neurons feature membrane plasticity and other such mechanisms that effectively function as learnable per-neuron parameters that effect the transfer function. This has been known and even incorporated into some ANNs and found to be somewhat useful. It isn't world changing. The cell isn't learning a complex spatiotemporal pattern - such as entire song. It's just learning a single or a handful of variables.
↑ comment by Darklight · 2015-07-10T00:29:25.698Z · LW(p) · GW(p)
What do you actually think memories are? Memories are simply reconstructions of a prior state of the system. When you remember something, your brain literally returns at least partially to the neural state of activation that it was in which you originally perceived the event you are remembering.
What do you think the "pointer" or "key" to a memory in the human brain is? Generally, it involves priming. Priming is simply presenting a stimulus that has been associated with the prior state.
The "persistent change" you're looking for is exactly how artificial neural networks learn. They change the strength of the connections between the neurons.
Symbol processing is completely possible with an associative network system. The symbol is encoded as a particular pattern of neuronal activations. The visual letter "A" is actually a state in the visual cortex when a certain combination of neurons are firing in response to the pattern of brightness contrast signals that rod and cone cells generate when we see an "A". The sound "A" is similarly encoded and our brain learns to associate the two together. Eventually, there is a higher layer neuron, or pattern of neurons that activate most strongly when we see or hear an "A", and this "symbol" can then be combined or associated with other symbols to create words or otherwise processed by the brain.
You don't need some special mechanism. An associative memory can store any memory input pattern completely, assuming it has enough neurons in enough layers to reconstruct most of the possible states of input.
Key or Pointer based memory retrieval can be completely duplicated by just associating the key or pointer to the memory state, such that priming the network with the key or pointer reconstructs the original state.
Replies from: passive_fist↑ comment by passive_fist · 2015-07-11T09:37:20.319Z · LW(p) · GW(p)
Key or Pointer based memory retrieval can be completely duplicated by just associating the key or pointer to the memory state, such that priming the network with the key or pointer reconstructs the original state.
Yes this is why I said you can implement general-purpose memory with associative memory. However, you need two additional mechanisms which the naive associative view doesn't address: You need the ability to create a pointer for a newly-generated memory and to associate this together with the memory. The basic RNN-based associative memory formulation does not have this mechanism, and we have no idea what form this mechanism takes in the brain. Also, you need the ability to work directly on pointers and to store pointers themselves in memory locations which can then be pointed to. However, this is more a processing constraint.
Replies from: Darklight↑ comment by Darklight · 2015-07-11T19:34:13.210Z · LW(p) · GW(p)
You're assuming that a Von Neumann Architecture is a more general-purpose memory than an associative memory system, when in fact, it's the other way around.
To get your pointer-based memory, you just have to construct a pointer as a specific compression or encoding of the memory in the associative network. For instance, you could mentally associate the number 2015 with a series of memories that have occurred in the last six months. In the future, you could then retrieve all memories that have been "hashed" to that number just by being primed with the number.
Remember that even on a computer, a pointer is simply a numerical value that represents the "address" of the particular segment of data that we want to retrieve. In that sense, it is a symbol that connects to and represents some symbols, not unlike a variable or function.
We can model this easily in an associative memory without any additional mechanisms, simply by having a multi-layer model that can combine and abstract different features of the input space into what are essentially symbols or abstract representations.
Von Neumann Architecture digital computers are nothing more than physical symbol processing systems. Which is to say that it is just one of many possible implementations of Turing Machines. According to Hava Siegelmann, a recurrent neural network with real precision weights would be, theoretically speaking, a Super Turing Machine.
If that isn't enough, there are already models called Neural Turing Machines that combine recurrent neural networks with the Von Neumann memory model to create networks that can directly interface with pointer-based memory.
Replies from: passive_fist↑ comment by passive_fist · 2015-07-11T22:12:10.910Z · LW(p) · GW(p)
To get your pointer-based memory, you just have to construct a pointer as a specific compression or encoding of the memory in the associative network.
Again, that's what I'm saying. How do you get from a memory to a pointer? We do not yet know how the brain does this. We have models that can do this, but very little experimental data. We of course know that it's possible, we just don't know the form this mechanism takes in the brain.
You're assuming that a Von Neumann Architecture is a more general-purpose memory than an associative memory system, when in fact, it's the other way around.
I'm assuming nothing of the sort. I'm not talking about which kind of memory is more general purpose (and, really, you have to take into account memory plus processing to be able to talk about generality in this sense). I'm talking about what the brain does. The usual 'associative memory' view says that all we have is an associative/content-addressable memory system. That's fine, but it's like saying the brain is made up of neurons. It lacks descriptive power. I want to know the specifics of how memory formation and recall happens, not hand-waving. Theoretical descriptions can help, but without experimental evidence they are of limited utility in understanding the brain.
That's why the Hesslow experiment is so intriguing: It is actual experimental evidence that clearly illustrates what a single neuron is capable of learning and shows that even when it comes to such a drastically reduced and simplified system, our understanding is still very limited.
According to Hava Siegelmann, a recurrent neural network with real precision weights would be, theoretically speaking, a Super Turing Machine.
This is irrelevant as real precision weights are physically impossible.